第四章作业的需求:

——————————————————————————————————————————————————
当然,我自然是认为这个作业是比较简单的,
我这次采用的对象是三个博客地址:
先用进程池对三个博客url进行爬虫抓取,每一个博客url使用BeautifulSoup进行抓取每一篇文章的url地址,生成文章url列表,
(重点来了,我们知道,异步的爬虫是跳不过SSL验证的,这个需要吹一下强大的requests模块。)
然后将得到的文章url列表进行地址净化,也就是把url中的https通过re正则表达式修改成http,
最后得到三个博客文章的文章url列表,将这些放入异步框架进行全部下载,于是就完成了进程池+异步框架的爬虫功能。
———————————————————————————————————————————————————————
当然,我对爬虫的探索没有到此结束。
后来想想,太过于没有技术含量,于是就暂时先提交作业,继续往下学习,找一个有空的时间进行升级,
升级的方式就是,将每一个文章url进行数据清洗,提取出文章的内容下载下来。
而这个时候,我们放弃使用BeautifulSoup模块,改用Xpath方法!!
正好也有个理由好好学习一下XPath模块,学习这个需要用到谷歌的Xpath-helper插件就可以了。
————————————————————————————————————————————————
Xpath教学震撼来袭!!!
咳咳,先别激动,还是先写完作业的总结提交吧,日后进行学习Xpath的时候,
做一些xpath爬虫案例,必会出一篇xpath为知笔记提交。
——————————————————————————————————————————————————-
现在,我们着重来总结一下本次作业遇到的问题,以下是大纲:
①在项目工程配置文件目录中,各个文件定位环境的问题
②两个文件都需要打印日志的时候,日志台重复输出的问题
③创建文件夹的时候,取名会忽略掉这个/,但是从url提取名字的时候,需要去掉/
④使用BeautifulSoup抓取url的时候,不要直接抓取目标列表,应当分两步。
⑤异步爬虫是跳不过SSL验证的,使用异步之前需要加工url列表
———————————————————————————————————————————————-
①在项目工程配置文件目录中,各个文件定位环境的问题
我们知道,运行多个文件的时候,工作环境路径是不一样的,为了让每个文件中固定应该的运行环境路径,
我们通常会开头定位好环境路径。
错误的姿势示范:
你这样把绝对路径直接导入进去,考虑过导师的感受吗?
导师批改作业肯定要试运行啊,他又没有你这样的路径啊,给导师带来麻烦多不好啊!
正确的姿势示范: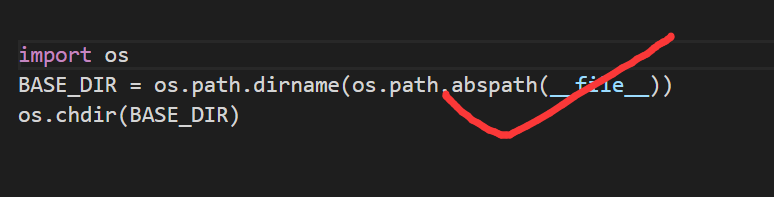
强制定位到此文件所在目录,要是导师批改你的作业能够直接运行文件成功,一定会感动地痛哭流涕!!!
这需要我解释吗?
os.path.abspath(file) :显示出本文件的绝对路径
os.path.dirname() : 显示出此路径的最后一个文件夹路径,换句话就是说此文件所在的目录
os.chdir() :将当前工作环境切换到此路径
学会了上面就不用再傻傻地传入当前路径来定位当前工作环境了!放到任何地方都能运行!!
但是!!!!!!!!!
在我的长期学习中,我用的是一个终极地超级定位方法,每个文件也一直采纳着这个标准,这样也能更加好地避免一些无法引入同目录的其他文件的问题,那就是采用强制父级目录定位。
以图片为例子,我们做小项目不都是采用工程配置文件吗: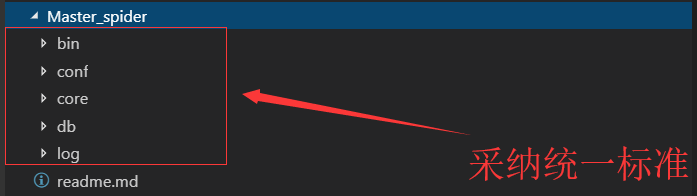
我的意思是说,假如我们要运行core文件夹里面的一个py文件,这个py文件的工作环境路径是这个父目录Master_spider!
当然,所有的py文件都是用父级目录为当前工作环境,而不是当前目录。
采纳这样的标准,有什么好处呢,引用同目录的文件不再失败,存储文件到哪儿更加方便。
最最最重要的还是,所有的程序入口都是在bin里面的main.py代码执行的,
那么main.py想要引用不就是通过父级目录定位来import的吗?为什么不干脆全部统一呢?
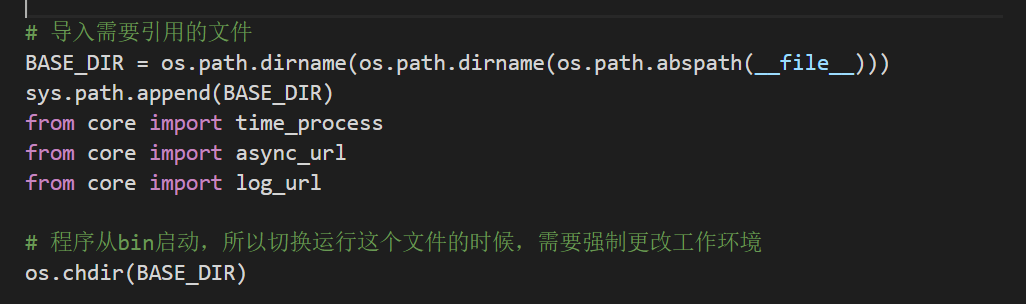

你们可以看到,我所有的py文件都加入了这些,这样工作环境再也不会混乱了,换句话说
所有的py文件的所有工作环境全部统一定位到Master_spider文件夹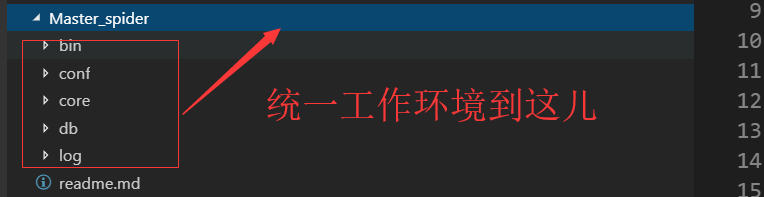
如果你们不采用我的方法,那好,你试想一下这种情况吧
有些py文件定位到core,有些py文件定位到bin,创建log文件,生成数据位置因为py文件的不同变得指向不明
你们迟早被这些微小的混乱影响了大局。
————————————————————————————————————————————————————————————
②两个文件都需要打印日志的时候,日志台重复输出的问题
问题也是来源于上面,当我们多个py文件都要打印日志的时候,如果我们对每一个py文件都创造日志台对象,
最终日志台的输出就会出现复读机的情况。
解决的方案自然是,只需要一个文件创造日志台对象,其他的py文件使用获取日志台对象的方法,让整个工程运行起来只有一个日志台对象,杜绝了复读的情况:
一个文件创造日志台对象,定义好日志台的名字:
其他的文件通过日志台名字统一获取已存在的日志台:
———————————————————————————————————————————————————————-
③创建文件夹的时候,取名会忽略掉这个/,但是从url提取名字的时候,需要去掉/
我写作业的时候,遇到的很蠢的bug,让我欲哭无泪。
我需要自动生成文件夹,自然是根据我抓取的url进行提取名字分析的
https://www.cnblogs.com/Masterpaopao/
以这个url为例子,那我就是要创造叫Masterpaopao的文件夹,但是我提取名字的时候是提取到了Masterpaopao/,
然而创建文件夹的过程会把这个/给去掉,于是成功地创建了叫Masterpaopao的文件夹,
但当我要同样的方法去访问这个文件夹的时候,却报错了,报错说,Masterpaopao/ 文件夹不存在。
哭了!于是我用正则的方法去掉了/,当然切片操作也可以:
———————————————————————————————————————————————————————-
④使用BeautifulSoup抓取url的时候,不要直接抓取目标列表,应当分两步。
老生常谈了,BeautifulSoup绝对不适合用来直接抓取目标数据形成列表的方法,
需要先抓住这些目标列表的父节点,然后再对这个父节点再来一次find_all操作,完成目标数据列表的提取。
也就是说需要两次find_all操作,第一次对目标数据的父节点,第二次才是对目标数据。
———————————————————————————————————————————————————————————
⑤异步爬虫是跳不过SSL验证的,使用异步之前需要加工url列表
这个就是很精彩的操作了,很简单,异步的爬虫框架跳不过SSL验证。所以需要将url里面的https修改成http。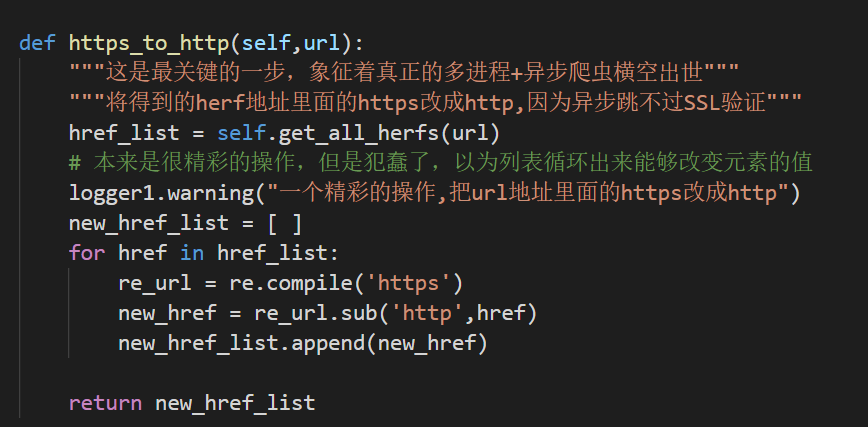
还是一样的,通过正则表达式,对每一个url地址进行修改。
不知道你们注意到我的注释了没有,我写代码的时候,又犯蠢了。你们看看我原来写的: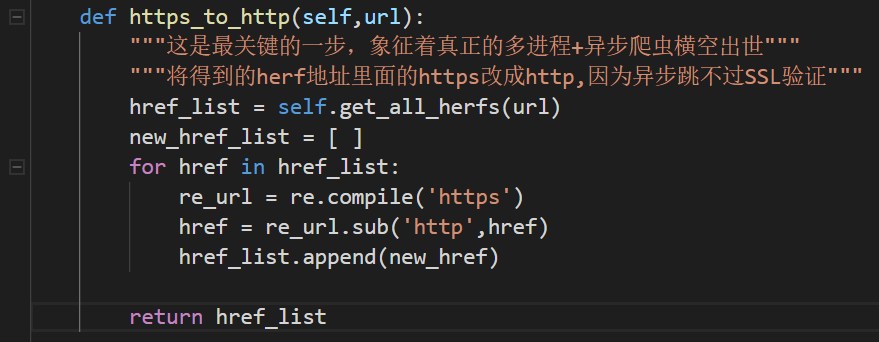
你们看懂我这张图所犯的低级纯错误了吗?欢迎来评论区写下答案!
谢谢大家的浏览!
下期预告!第四模块第五章作业的总结!估计在这两天完成!


若有收获,就点个赞吧
0 人点赞
