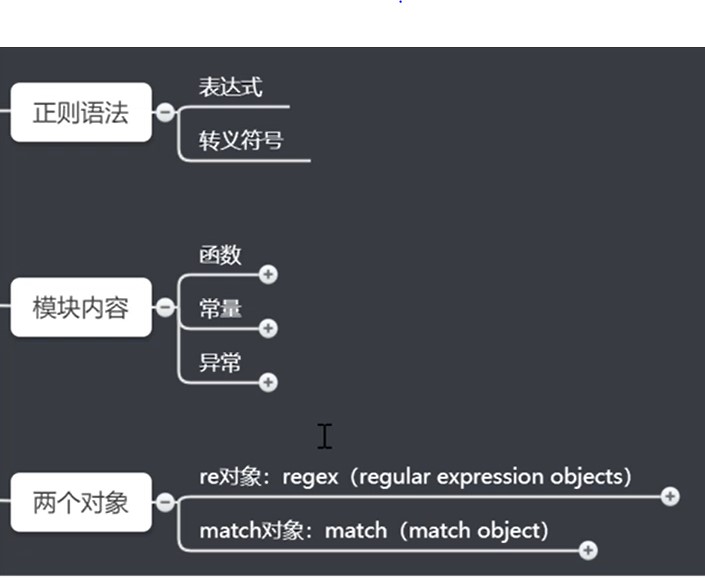
正则表达式
why what how
why:从大量文本中查找规则字符串,比字符串各种查找都快,利用C语言的匹配引擎,广泛用于各种搜索,查找,爬虫
what:
正则->代数, 变量替换(用一些规定好的符号取匹配有规则的文本)
英文:regular
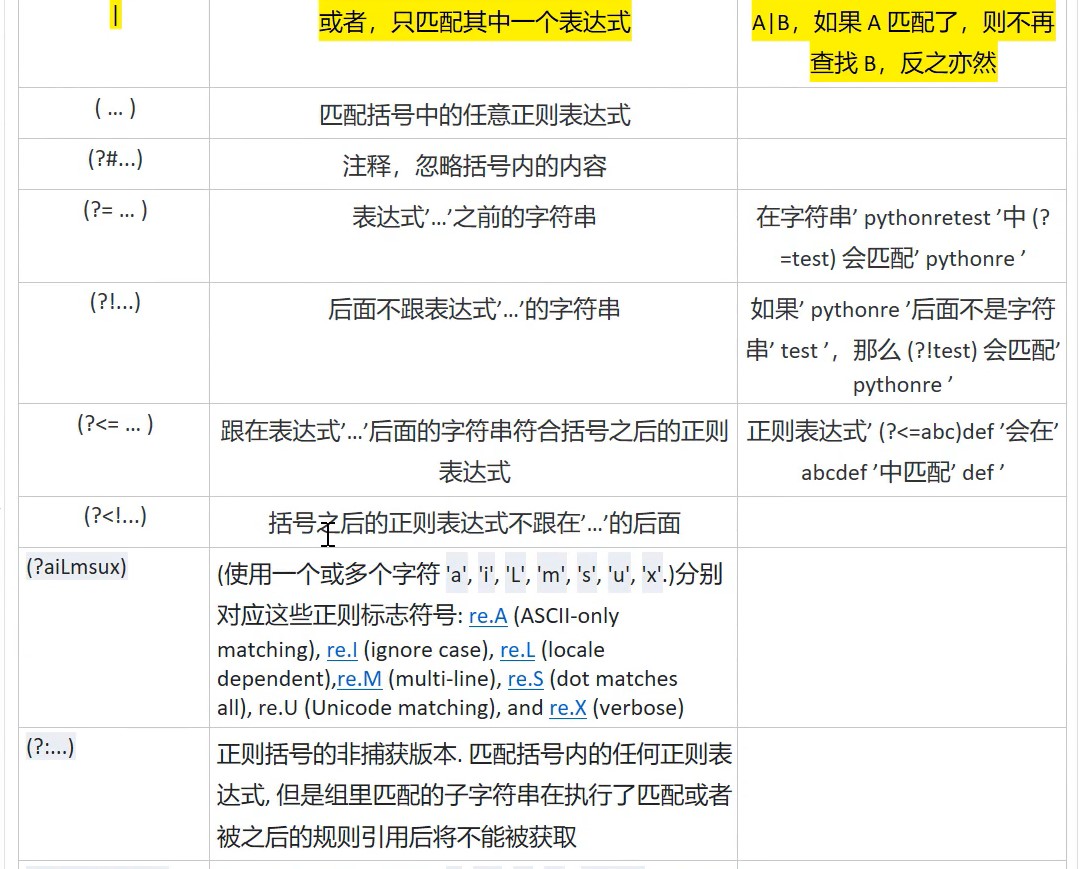
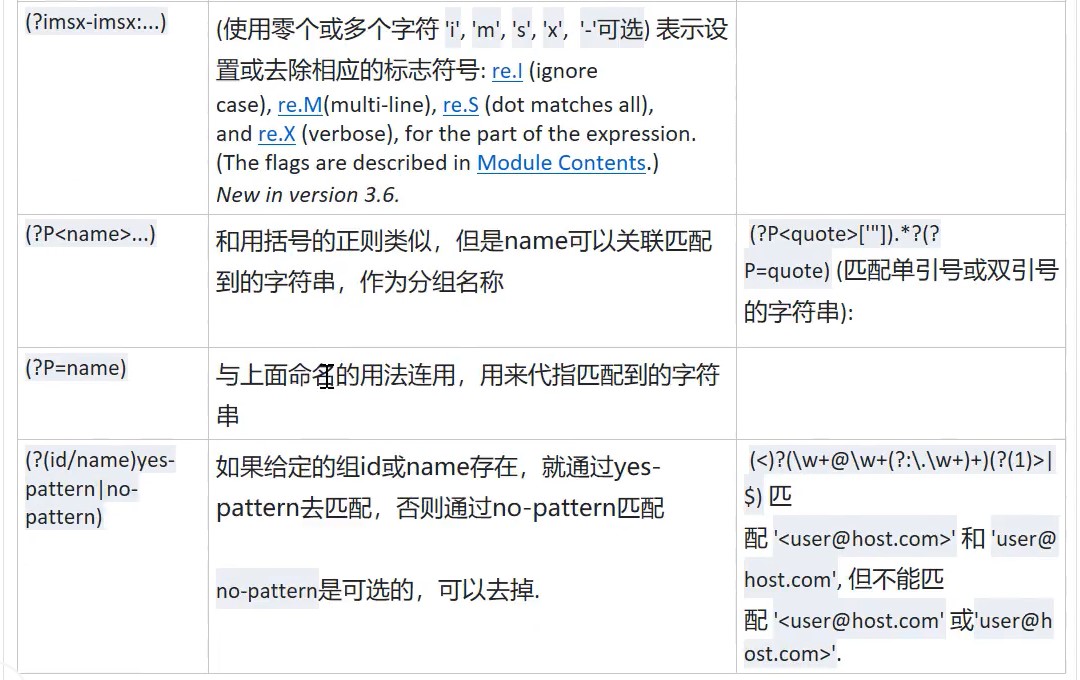
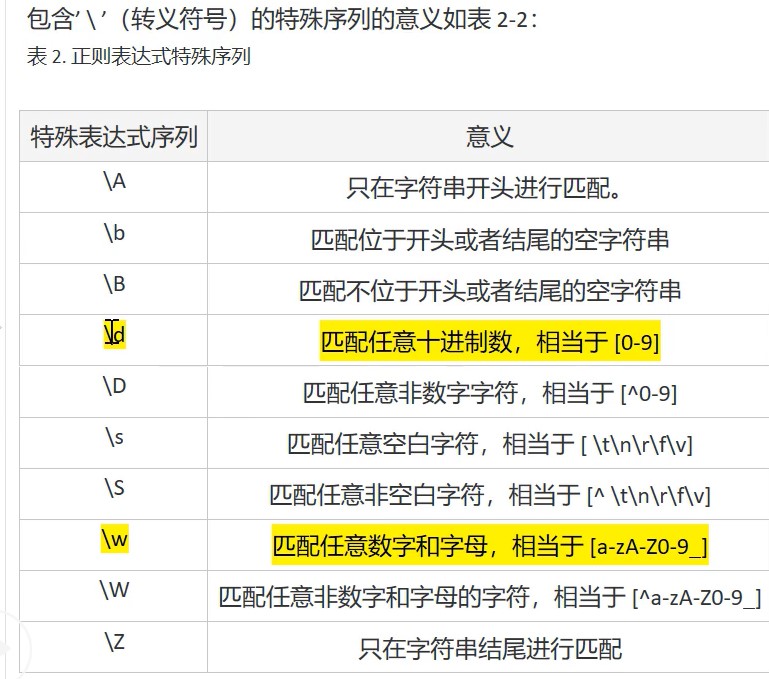
正则表达式的语法
.: 表示任意字符,如果说指定了DOTALL的标识,就表示包括新行在内的所有字符,^: 表示字符串开头$: 表示字符串结尾,例如:’test’可以匹配’test’和’testtool’,但’test$’只能匹配’test’。*,+,?: 添加到要匹配的目标后面


练习工具
国外工具
-
国内工具
开源中国
- 网址
- tool.oschina.net/regex
-
re模块使用说明(hit and run)
函数
complie编译函数会返回一个正则表达式regex对象,代表一种匹配关系
search函数,match函数会返回一种match对象
split会返回一个列表,分割的结果
findall返回列表
finditer返回迭代器
sub替换函数返回字符串
subn返回元组
escape会返回字符串,包含各种正则中的字符
purge清除函数常量:
常量就是前面函数中的flags的内容
- 常量的大小写一定是严格区分的,代表的含义通常是不同的对象:
regex对象:
-
使用方法示例:
import re
- re.compile()创建一个正则对象regex,一个变量多次使用

- 使用regex
- regex = re.compile(pattern) # regex可以多次使用
- result = regex.match(string) # 具体使用regex
- 使用match
- match = re.match(pattern, string) # match对象,每次使用都要生成
- 使用regex查找一个字符串,返回被匹配的 对象
-
重点的匹配符和函数的用法
匹配符
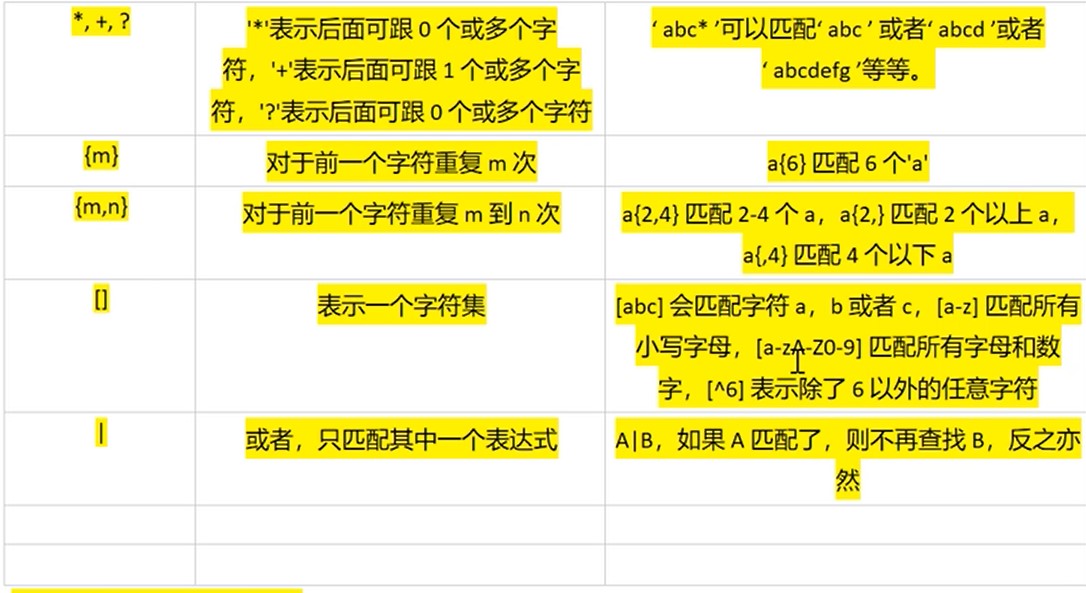
a{m, }表示匹配m个到无限个a
###重点函数
- re.compile(pattern, flags=0)
- re.search(pattern, string, flags=0)
- re.match(pattern, string, flags=0)
match函数与search函数不同,search函数是在一整个字符串中寻找符合模式的,match函数是必须从第一个字符开始匹配,如果第一个匹配上在匹配第二个,直到所有的都匹配上才算匹配上如果想分组匹配
分组的实现方式是给正则表达式加上(),就可以让括号内的单独成为一个正则表达式(并且会根据括号出现的位置给每一个括号赋予序号,可以用于字符串的重组替换)
IP地址的匹配
错误的方式:
(\d[1,3].){3}\d[1,3]
这种方式会匹配到大于255的情况
- 正确的方式
r’((2[0-4]\d|25[0-5]|[01]?\d\d?).){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
注意命名规则
比如用regex匹配IP
re_ip = re.compile(r’’’
((2[0-4]\d # 200-249
|25[0-5] # 250-255
|[01]?\d\d?).){3} # 0-199 这三项合起来表示0-255,加一个.表示.,{3}表示重复3次
(2[0-4]\d|25[0-5]|[01]?\d\d?)’) # 0-255
compile(r’’)其中的r表示raw,使用最原始的正则表达式
匹配要不要贪心一点
findall函数,和match、search函数用法相同,但是它会返回一个list,找到在字符串中所有符合模式的字符串
学习网站:
http://www.cnblogs.com/graphics/archieve/2010/06/02/1749707.html
只匹配双引号中的内容
re_quote = re.compile(r’”(.)”‘)
.表示任意字符,任意个数,如果加上?代表任意个数但是取尽可能少的情况(并不是所有的双引号包含的情况下取中间个数最少的那个,而是在有多种选择的的情况下,取那种最少字符的那种情况,比如说三个双引号连起来的时候:
“yes.” phone says “no”
如果使用贪心的方法,会变成
“yes.” phone says “no”
如果是加了?,则只会匹配出两个较短的情况:
[‘yes.’, ‘no.’]
)
re_quote = re.compile(r’”(.*?)”‘)
正则匹配可以直接换掉内容吗
可以,使用
regex.sub(str, s)函数,把s中符合regex的部分都替换成str
如何使用分组的序号进行重组和替换
import re
s = ‘替换日期格式:10/01/2008, 12/25/2008’
re_date = re.compile(r’(\d+)/(\d+)/(\d+)’)
re_date.sub(r’\3-\2-\1’, s)
‘替换日期格式:2008-01-10, 2008-25-12’
如何用sub替换掉空格(处理狗屎pdf文件必备)
- 知识点:\s表示空白字符,+表示1个或多个,\s+表示一个及一个以上的空格(如制表符就是4个空格,通常情况下)
- 示例代码:
>import re
s = ‘ zby 是 天下 第一 大 帅 哥 ! ! ! ! ‘
re_space = re.compile(r’\s+’)
re_space.sub(‘’, s)
‘zby是天下第一大帅哥!!!!’
案例1:寻找联系方式
知识点

使用vscode写一段代码
tips:在vscode中直接输入ifm可以直接输出main函数的代码
示例代码:
import rere_phone = re.compile(r'\d{3}-\d{8}|\d{4}-\d{7}')def find_phone(s: str)->list:return re_phone.findall(s)def main():s = '010-87595623,0234-5689496,hmm'print(find_phone(s))if __name__ == "__main__":main()
案例:登录验证正则版

做一个登录验证的一段代码,具备功能:
import re
re_phone = re.compile(r'\d{3}-\d{8}|\d{4}-\d{7}')
re_chinese = re.compile(r'^[\u4e00-\u9fa5]{1,8}$')
re_pwd = re.compile(r'[a-zA-Z]\w{7,17}')
def find_phone(s: str)->list:
'''查找所有手机号,返回列表'''
return re_phone.findall(s)
def verify_ch(re_obj, text):
'''判断是否是汉字,是返回True,否则返回False'''
if re_obj.match(text):
return True
else:
return False
def verify_pwd(re_obj, text):
'''判断密码是否是字母开头,8-18位仅包含字母数字下划线,是返回True,否则返回False'''
if re_obj.match(text):
return True
else:
return False
def main():
user1 = 'zby'
user2 = '赵博元'
pwd1 = 'zhao139319'
pwd2 = '1zhao234'
print(verify_ch(re_chinese, user1) and '用户名1合格' or '用户名1不合格')
print(verify_ch(re_chinese, user2) and '用户名2合格' or '用户名2不合格')
print(verify_pwd(re_pwd, pwd1) and '密码1合格' or '密码1不合格')
print(verify_pwd(re_pwd, pwd2) and '密码2合格' or '密码2不合格')
if __name__ == "__main__":
main()


若有收获,就点个赞吧
0 人点赞
