本节要点:根据上一节的 “中国式排名” 加大难度做“分组中国式排名”。
先看我们的需求:
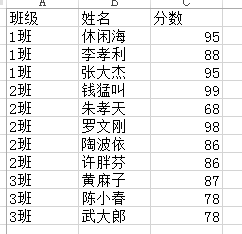
我们要根据班级对学生做成绩的排名,实现的效果图如下:
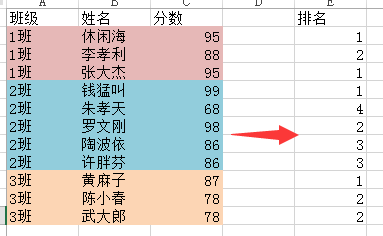
还是根据上一节的思路来完成,首先我们进入到 Power Query 界面,将原始数据复制成三份。

首先我们处理 “索引表”,删除不需要的“姓名” 一列,选中剩余的两列(一定要选中两列),做删除重复项的操作。
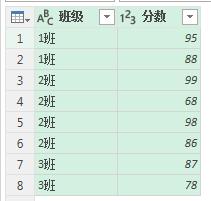
接下来我们给上面的结果加一列序号(从 0 开始),还需要计算每个班级不重复的记录个数以及序号最小值。
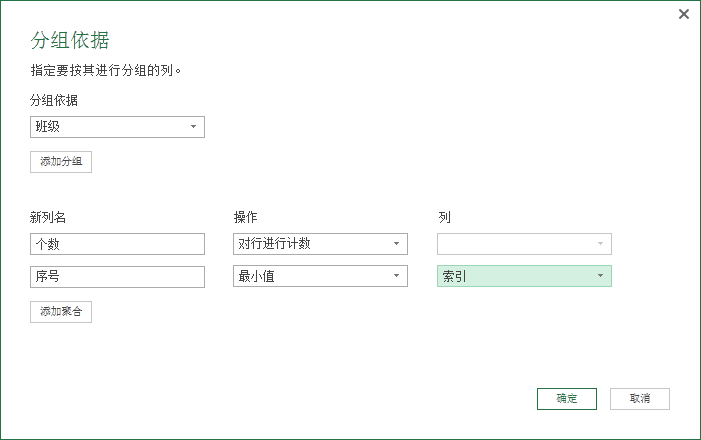
结果如下:
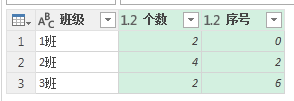
再次给它添加一列索引,这次是从 1 开始的索引列,为了是区分哪个班级。

这样,我们对于 “索引表” 的整理就完成了。
接下里我们在 “表 1” 当中进行处理,需要取到 “索引表” 里面的 “个数” 以及 “索引” 两列。
“个数” 是为了进行扩展多少行,进行比较。
而 “索引” 是为了区分到底是哪个班级。
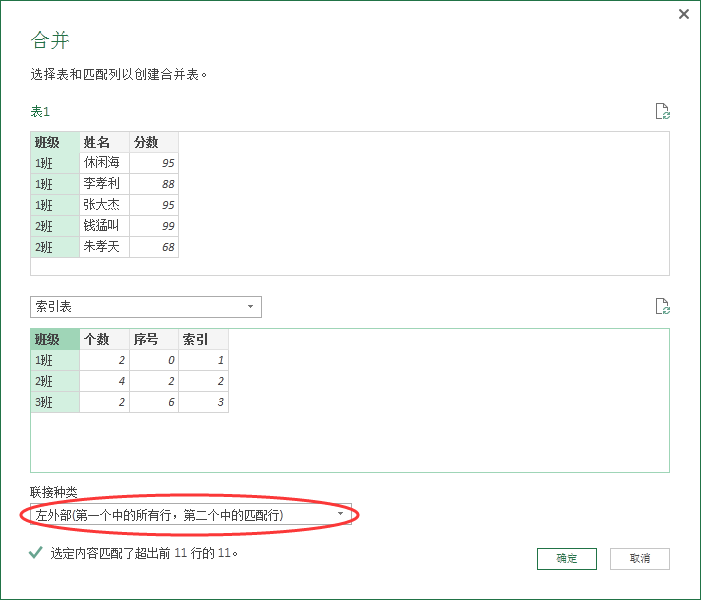
展开里面的 “个数“以及” 索引“。
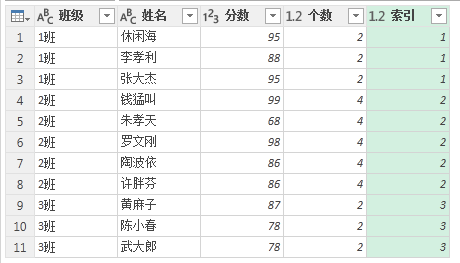
接下来就是我们熟悉的扩展了。
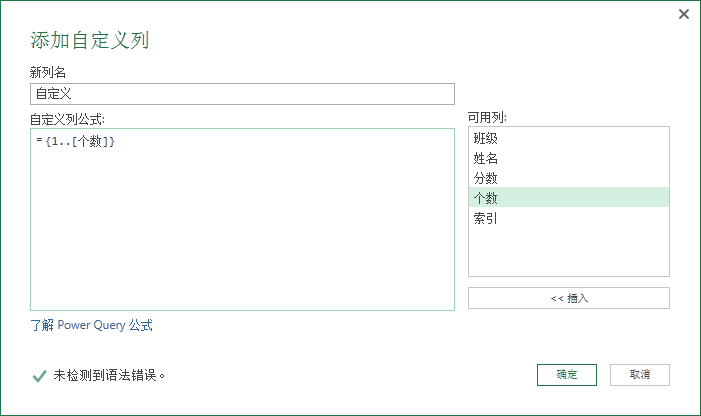
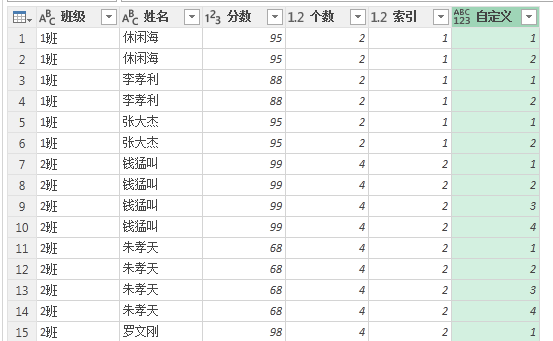
现在我们需要将最后两列进行合并,并去掉” 个数 “列。
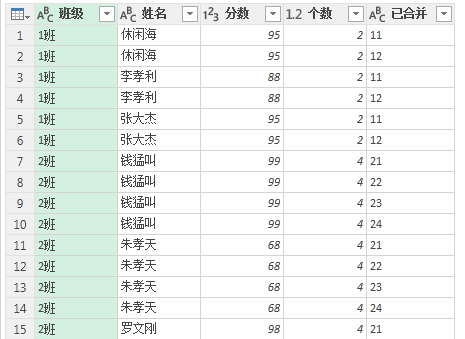
现在我们来看这个” 已合并 “一列的数据。
是班级 + 不重复的值。
这样一来我们对” 表 1“的处理也基本完成。
下面再来改造一下” 表 2“。
同样删除不需要的” 姓名 “一列,选中剩余的两列,进行删除重复项。
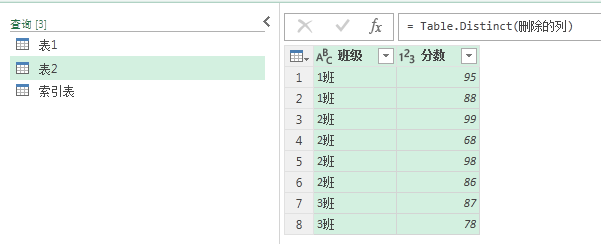
下面同样要对”表 2“和”索引表 “进行结合,得到” 序号 “和” 索引“列。
其实这个” 序号 “就是每一个班级的最小值。
” 索引 “依旧是为了区分班级。
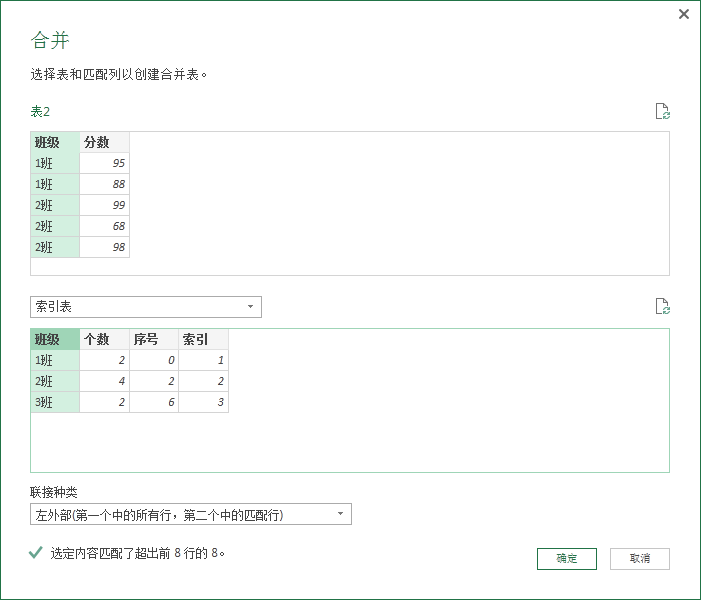
扩展我们需要的两列。
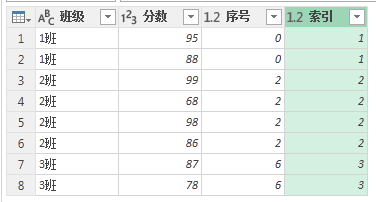
我们给” 表 2“再添加一列索引列。

我们用新添加的索引列去减去前面的” 序号 “列,就得到了每个班级的序号。
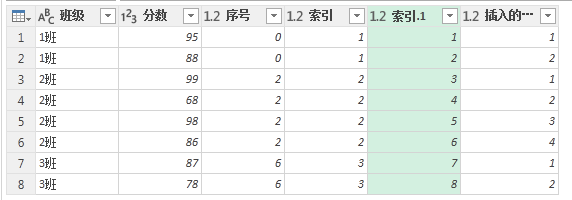
将第四列和第六列进行合并,去掉第三列和第五列。
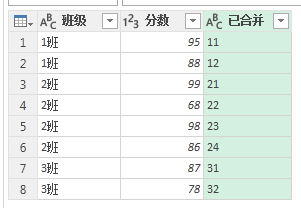
这样一来,我们对于数据的处理基本完成了。
可以对” 表 1“和” 表 2“进行对应起来了。
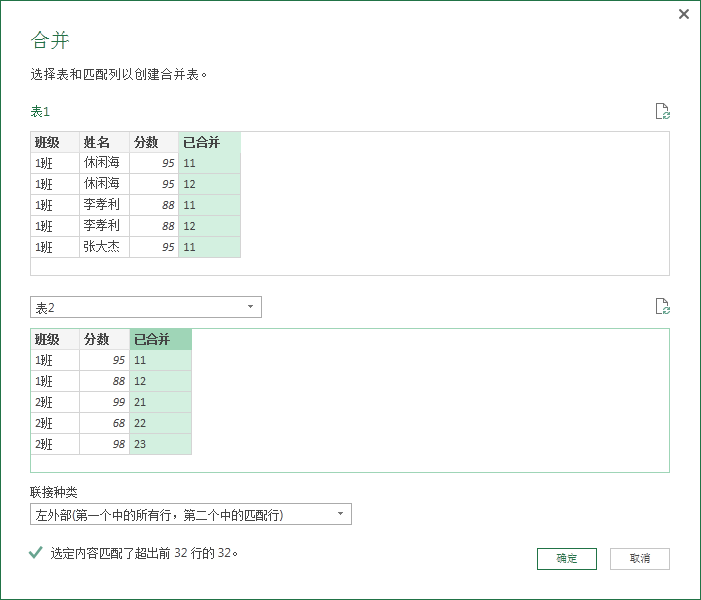
仅仅需要扩展它的分数列即可。
随后跟之前一节的处理是一样的,添加条件列。
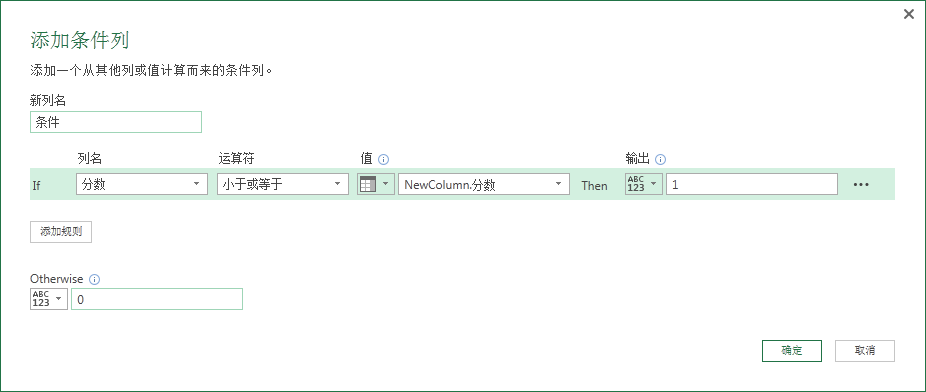
然后我们使用分组依据对分数求平均值,对条件求和。

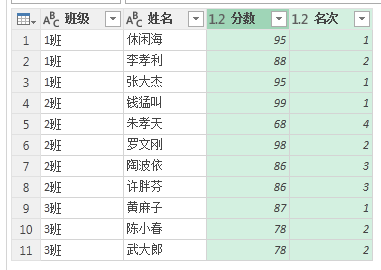
加上前缀后缀。
上传到工作簿即可。
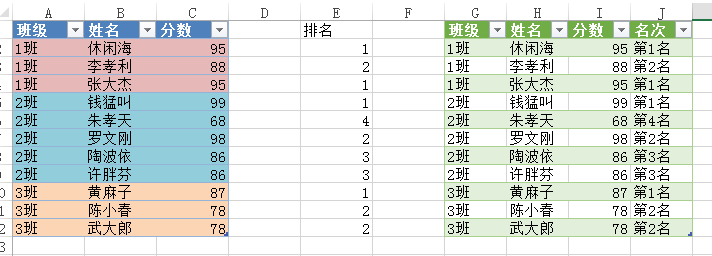
跟我们开始分析的是一毛一样的。
同样对数据源进行添加删除操作的时候,刷新右表即可。
https://saper.blog.csdn.net/article/details/54561814

若有收获,就点个赞吧
0 人点赞
