
经常听别人说 Python 在数据领域有多厉害,结果学了很长时间,连数据处理都麻烦得要死。后来才发现,原来不是 Python 数据处理厉害,而是他有数据分析神器—— pandas
前言
本系列有一篇文章是关于 pandas 实现 Excel 中的分列功能,后来有小伙伴问我,怎么实现 Excel 中固定列宽分列功能。这次就看看几个奇葩的数据案例。
案例1
某公司系统,有一 id 列,其中一部分是表示用户出生日期:

- 怎么可以从中把日期值提取出来呢
Excel 上可以用分列功能:
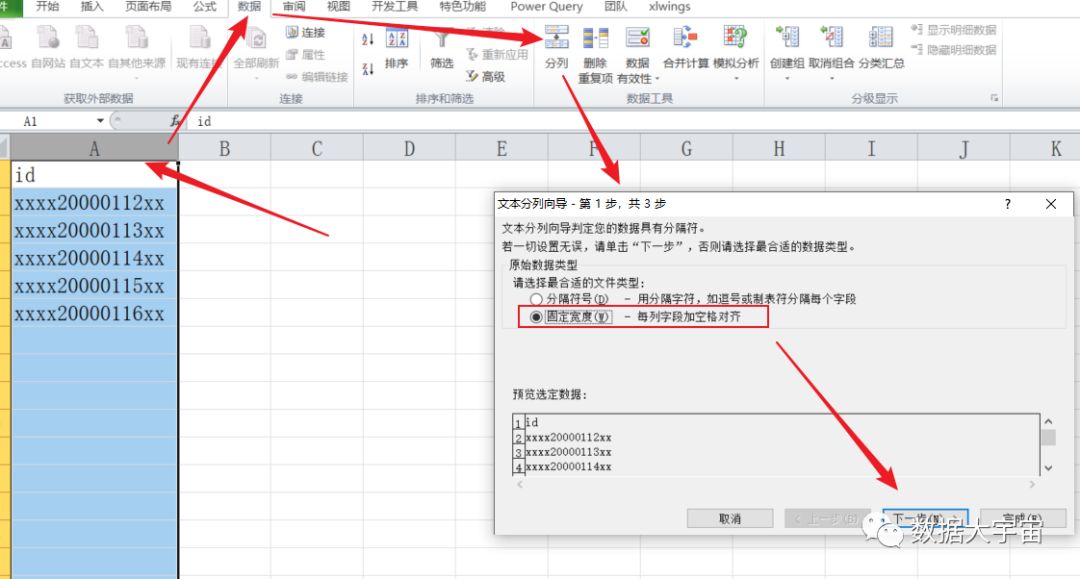
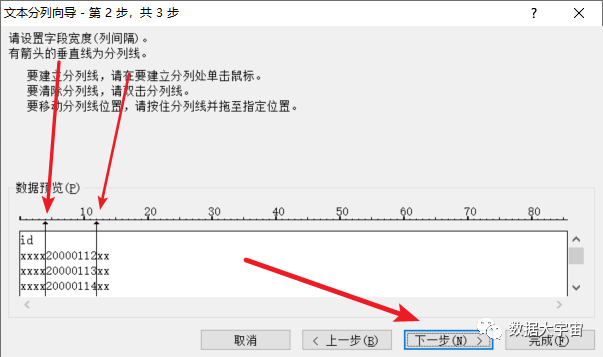
- 结果会把数据分成3列
pandas 中,我们不需要用 split ,而是直接用切片提取:
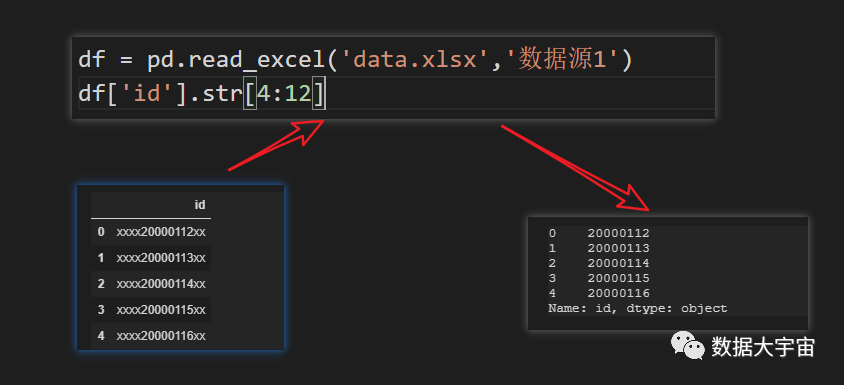
- df.str[4:12],意思是,截取从第5个至第13个(不包含第13个)之间的内容
df.str[4:12] 相当于 df.str.slice(4,12)
案例2
有些系统有时候不会太人性化,比如,id 中的日期的起始位置是不固定的:
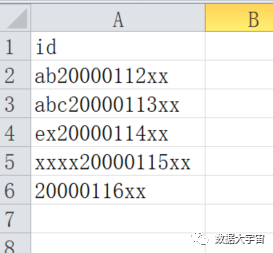
- 日期起始位置不固定,但如果从反向来说是固定的
pandas 中的文本切片与 Python 中的切片一样,因此我们可以这样处理:
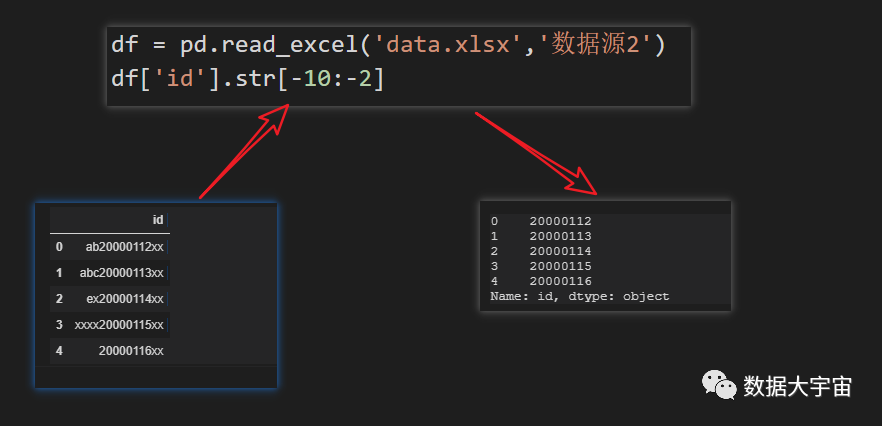
- 用负数表示从反方向计算截取范围
案例3
这是一个”抬杠案例”:
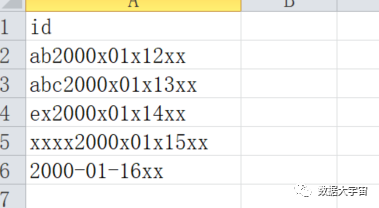
- 开始位置不固定,并且,日期之间还有不固定的分隔符号
我们当然可以用正则表达式提取,这次我选用一种特别的方式完成:
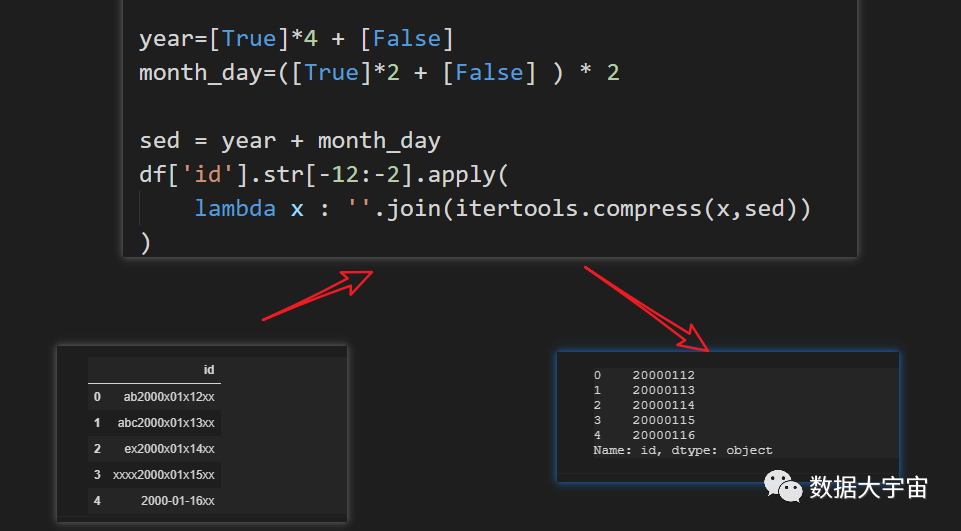
- 注意,我们使用了 itertools.compress ,要导入该模块。 import itertools
相信很多人不理解其中的原理,特别是其中的 sed 构造,看看下面的对应图:
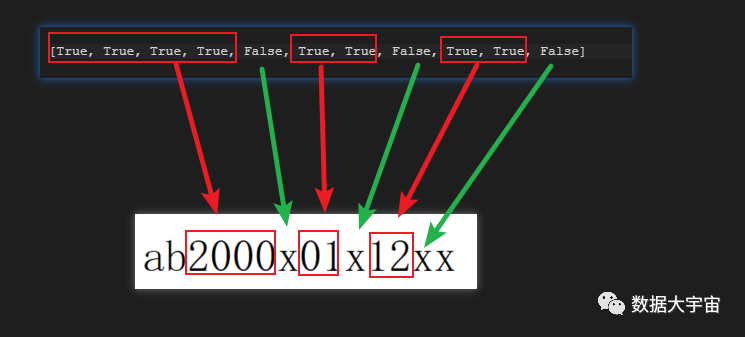
- itertools.compress() ,他的作用就是按照一个 bool 列表,把其中的 True 对应另外一个序列同位置上的元素给筛选出来
你 get 到了吗?
总结
- 分列只是提取内容的一种方式,别一遇到分列,则只考虑 str.split
- str.slice 或 str[] ,可以像 Python 切片一样做处理
- 用好 itertools.compress,可以进行有规则并且连续内容的提取
需要源码的小伙伴,公众号发送”数据处理”
如果希望从零开始学习 pandas ,那么可以看看我的 pandas 专栏。
扫描二维码
获取更多精彩
壹伴编辑器


若有收获,就点个赞吧
0 人点赞
