经常听别人说 Python 在数据领域有多厉害,结果学了很长时间,连数据处理都麻烦得要死。后来才发现,原来不是 Python 数据处理厉害,而是他有数据分析神器—— pandas
前言
本系列已经有一篇文章介绍 pandas 中实现 Excel 的 vlookup 函数的方式,但是 vlookup 中还有一个”模糊匹配”的功能,主要用于分段匹配,今天就来看看 pandas 中是如何做到同等效果。
案例1
今天,你接到一份紧急的临时需求,数据表格如下:
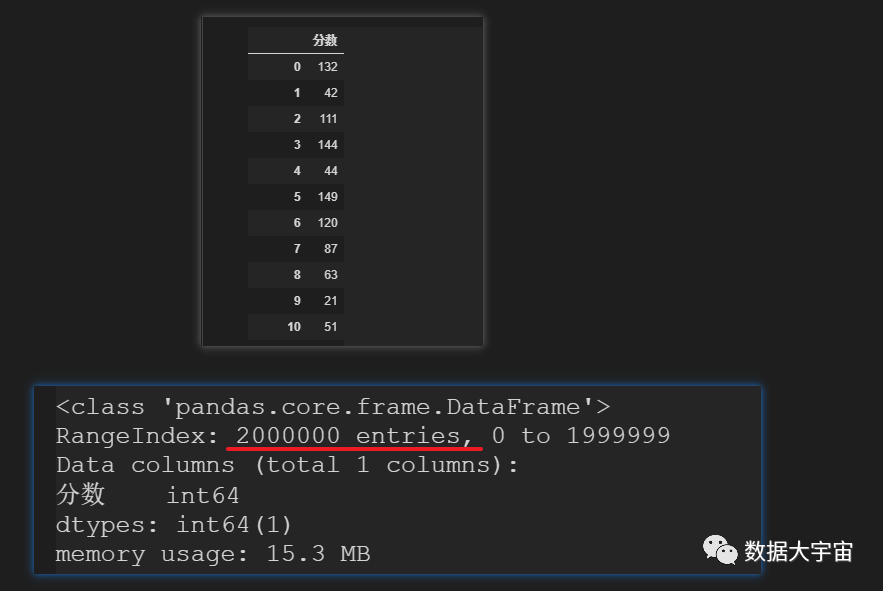
- 200百万行的记录
- 需要按照 分数 列,按规则计算出 评级
规则表如下:
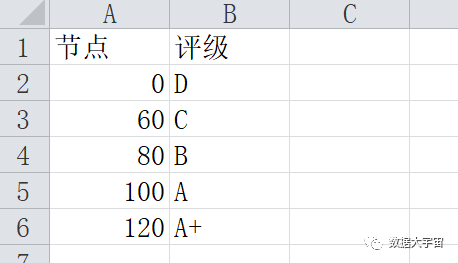
- 这是特意为 Vlookup 而设计的规则表
若按 pandas 来设计规则表,那么 Vlookup 的解决方式就会很麻烦。
怎么办?数据多到 Excel 也打不开,管你是 Vlookup 还是 Xlookup 也没用。
多功能的 Vlookup
由于这次数据太多,用 Excel 已经不能打开此文件,因此我用少量数据简单演示一下如何用 Vlookup 解决此问题:
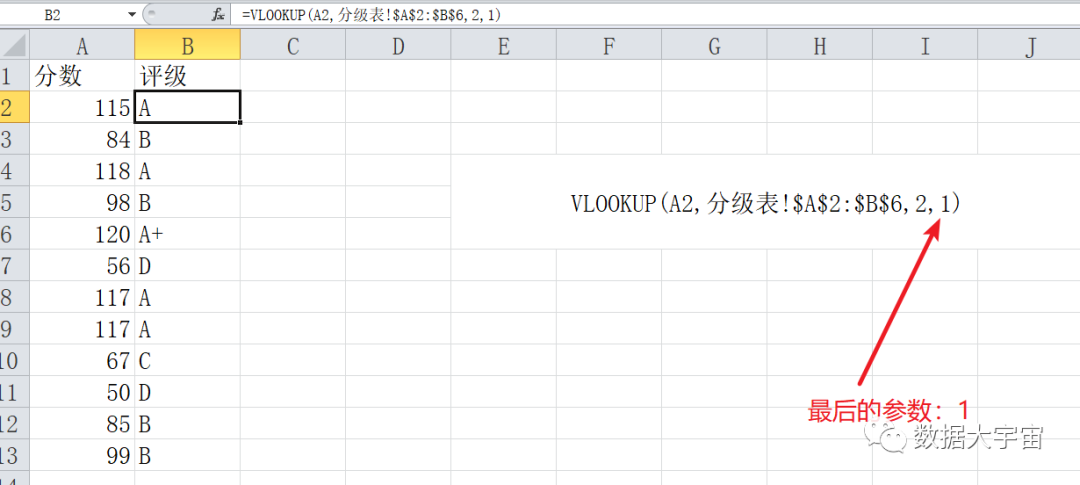
- 其实就是最后一个参数输入 1(True),即可
- 很重要一点,规则表的 值 列,记得要排好序,否则结果错乱你也不知道
pandas 中的分段匹配
这种需求在数据处理一般称为”分箱”,pandas 中使用 cut 方法做到:

- 我们从 csv 读取数据,从 Excel 中读取规则表
- 注意这是 pandas 的顶层方法,因此是 pd.cut()
- 第1参数传入判断数据列
- 第2参数传入规则表的 值 ,但是 cut 方法必需给定所有区间的边界。像本例子的规则表,没有高于120分的结束边界,我们需要添加一个很大的值作为结束边界
- 参数 right,设置为 False ,只是为了与 vlookup 效果一致而已,表示:”右区间边界开放”,比如:120分,被划分到 A+ 评级
- 参数 labels,就是返回的结果
可以看到 pandas 可以轻松从任意数据源中读取数据,本例中即使你的数据源在各种数据库也是没问题
注意,bins 没有升序排序时,会报错。这是非常好的设计
看文字很难理解,看看这个示意图,应该清晰很多:
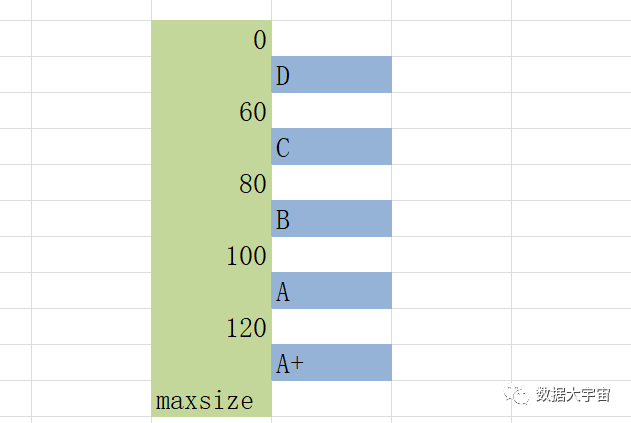
案例2:自动划分
在实际分析工作中,你可能一开始并不清楚到底规则表的各个节点怎么定义才合理。
比如你现在希望划分3个段,但你不知道各个段之间的边界怎么定义才合理。那么可以这样子调用 cut 方法:
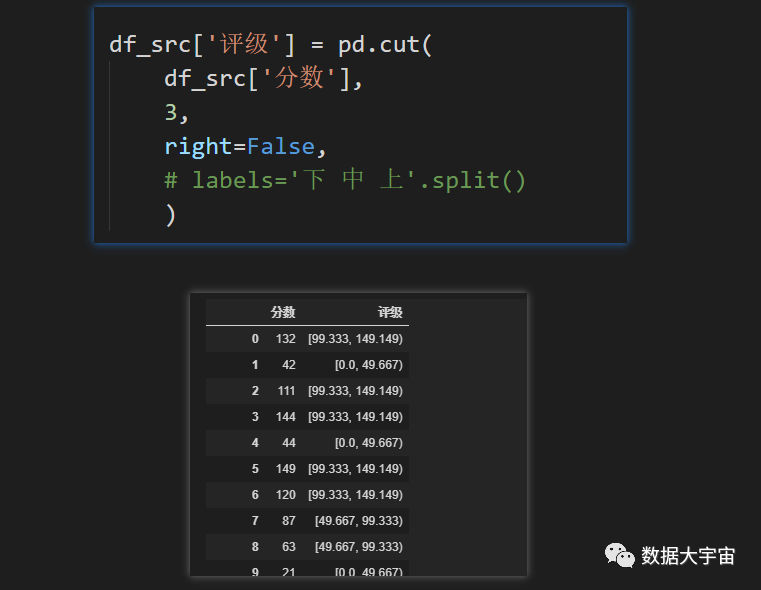
- cut 方法的第2参数,我们指定3,表示划分3段
- 不指定参数 labels,这可以看到划分的区间。
你也可以指定 labels:
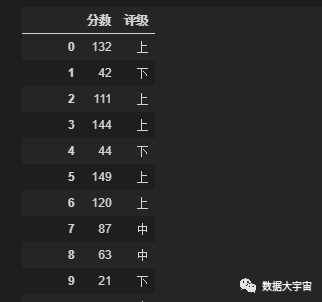

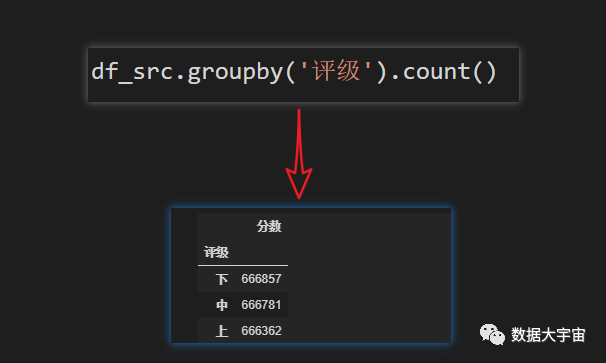
最后的划分结果尽可能每个区间数量平衡,来看看各区间的数量:
总结
- pd.cut() ,对数据做分箱处理
- 参数 bins 可以指定自己的规则表,也可以直接指定划分段数目
- 指定划分段数目时,会自动定义各个划分区间
- 当指定的 bins 规则表没有升序排序时,会报错
需要源码的小伙伴,公众号发送”数据处理”
如果希望从零开始学习 pandas ,那么可以看看我的 pandas 专栏。
扫描二维码
获取更多精彩
数据大宇宙


若有收获,就点个赞吧
0 人点赞
