
此系列文章收录在公众号中:数据大宇宙 > 数据处理 >E-pd
经常听别人说 Python 在数据领域有多厉害,结果学了很长时间,连数据处理都麻烦得要死。后来才发现,原来不是 Python 数据处理厉害,而是他有数据分析神器—— pandas
前言
本系列上一节已经介绍了最简单的 shift 方法应用,这一节将结合其他技巧,解决诸如”某城市一年最大连续没下雨天数”的问题。
Excel 中的实现方式直观简单
如下一份简单的记录表:
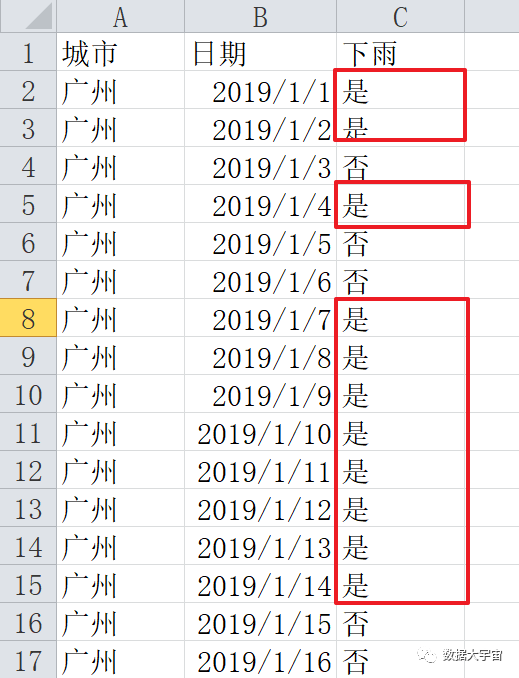
需要根据这份数据,得到最长连续下雨天数是多少,是几号到几号
上图红框是一部分符合条件的,其中最长的红框是需要的结果
按照惯例,先看看如果在 Excel 上是怎么得到结果:
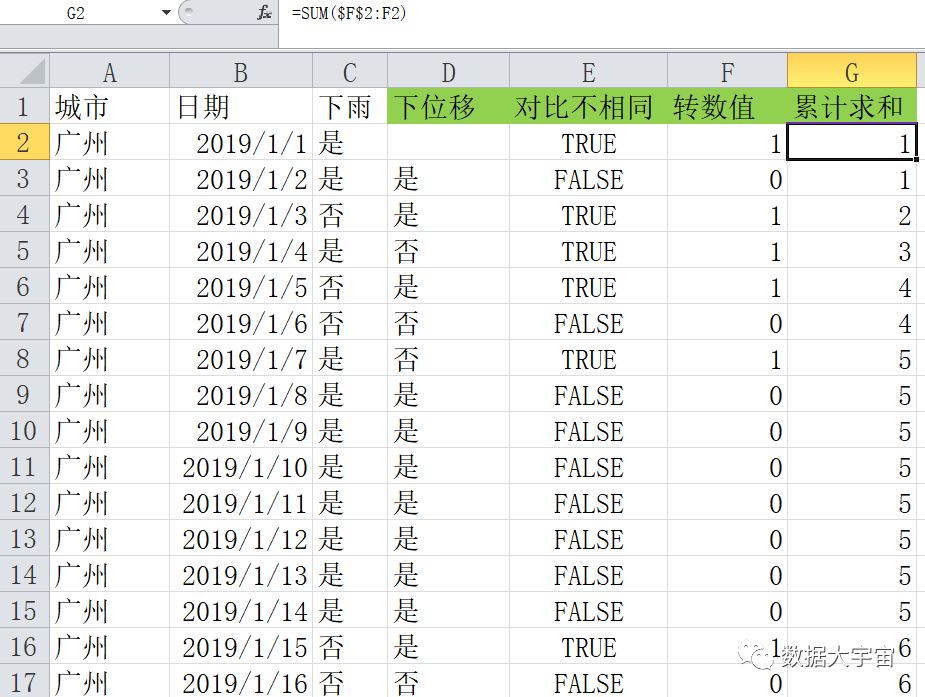
D列 到 G列 是辅助列
D列:是C列 的下位移列(不理解的看上期文章)
E列:对比 C列 与 D列 是否不一样
F列:对 E列 的结果数值化,True 为1,False 为0
G列:累计求和,上图可直接看到 G2 单元格的公式,不多说了
注意看 G列 的内容,相当于根据 C列的内容,相同连续值被划分到一个独立的编号
接下来只需要条件筛选+分组统计,即可简单求出结果
后面的条件筛选+分组不再用 Excel 操作了(因为操作比较麻烦)
pandas 中的对应实现
现在关键是怎么在 pandas 中完成上述 Excel 中的操作,实际非常简单:
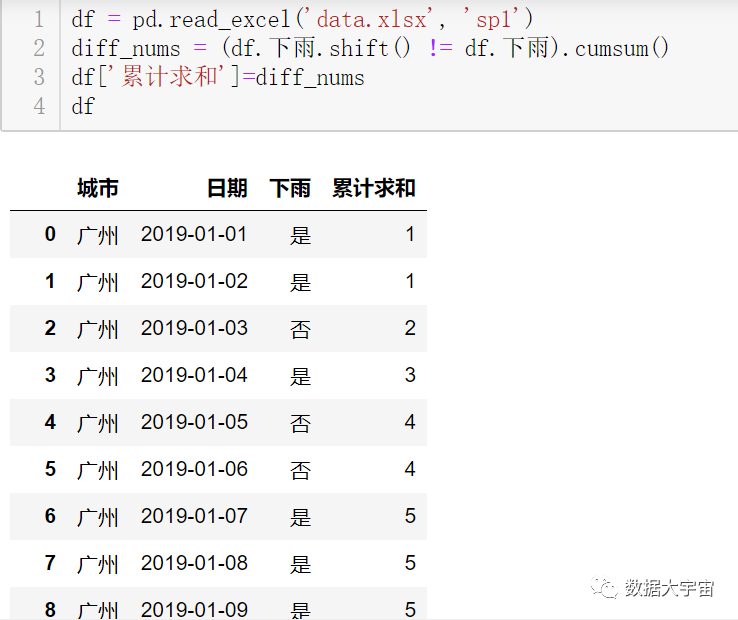
行2:简单完成
df.下雨.shift() 相当于 Excel 操作中的 D列
(df.下雨.shift() != df.下雨) 相当于 Excel 操作中的 E列
.cumsum() 相当于 Excel 操作中的 G列
接下来是分组统计,pandas 的分组其实不需要把辅助列加到 DataFrame 上的:
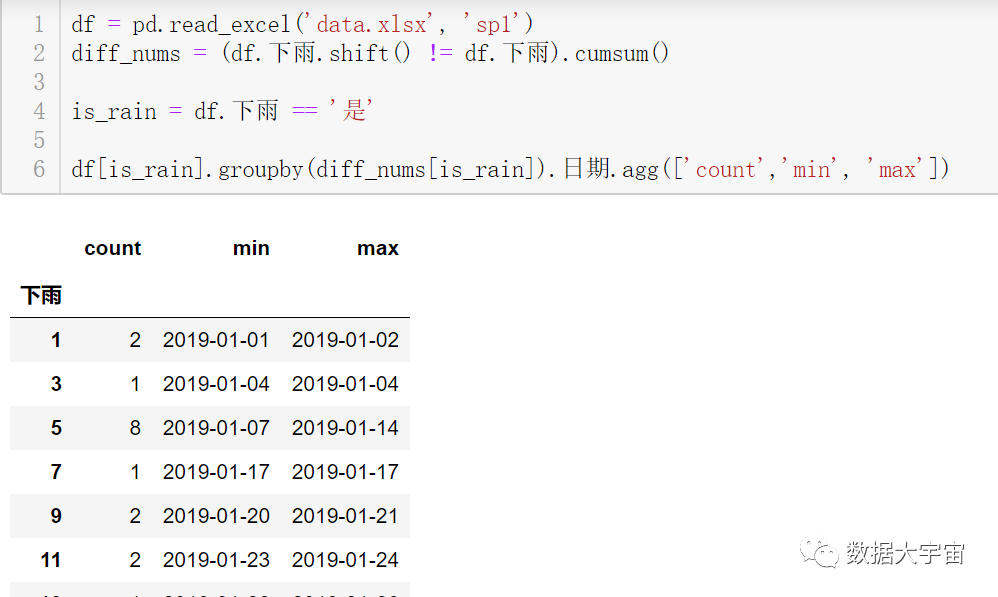
行4:筛选下雨的行的条件
行6:先对 df 过滤下雨的行,按 diff_nums 分组统计
结果是一下子统计出各个连续下雨的天数与日期范围
结果是需要得到其中 count 列的最大值的行:
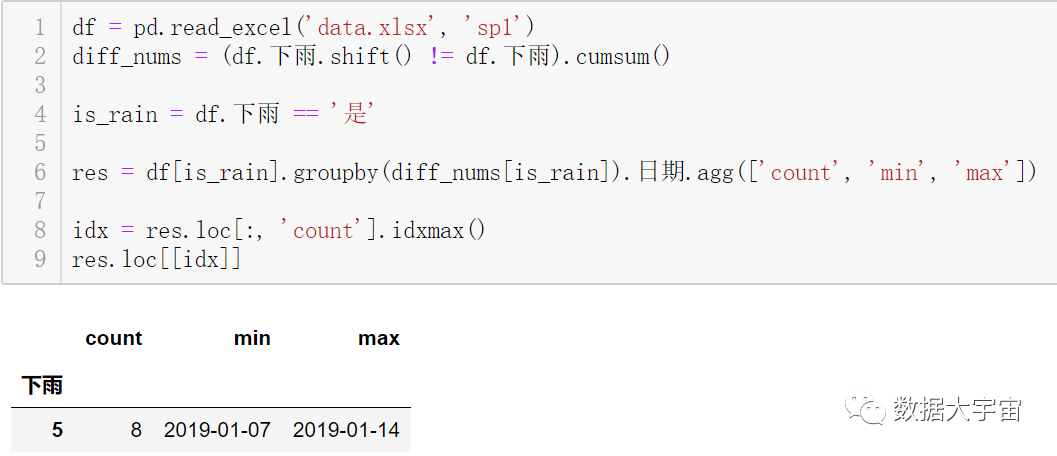
- 行8:使用 idxmax 得到最大值的行索引值
总结
本文重点:
Series.shift + cumsum ,能实现连续符合条件的区域编号
此技巧能解决很多实际问题
需要源码的小伙伴,公众号发送”数据处理”
觉得写得不错,点击右下方”在看”
如果希望从零开始学习 pandas ,那么可以看看我的 pandas 专栏。
扫描二维码
获取更多精彩
数据大宇宙


若有收获,就点个赞吧
0 人点赞
