
一、筛选功能
(一)加载Excel数据
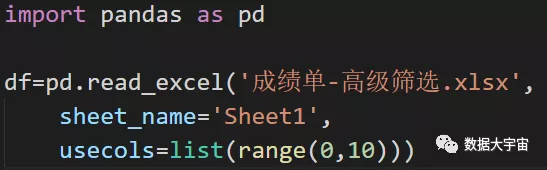
import pandas as pddf = pd.read_excel('数据.xlsx',sheet_name = 'data')
- pd.read_excel,加载数据
第一个参数,指定数据源路径
注意绝对路径与相对路径
sheet_name ,指定读取工作表
- 由于工作表中有多余的列数据,我们只需要前10列,因此指定 usecols 参数。
他接受一个列表。list(range(0,10)),其实相当于[0,1,2…………,9]的一个列表 - 参数详解可参照read_excel参数详解
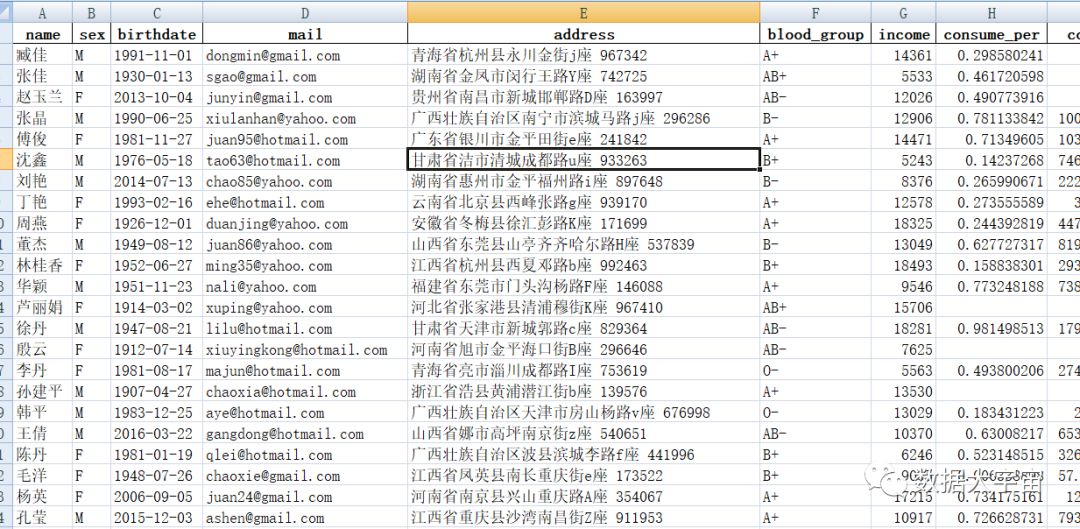
- 本文示例数据如下:
(二)按位置(索引)筛选
# 筛选第3行到第6行df.loc[2:5]
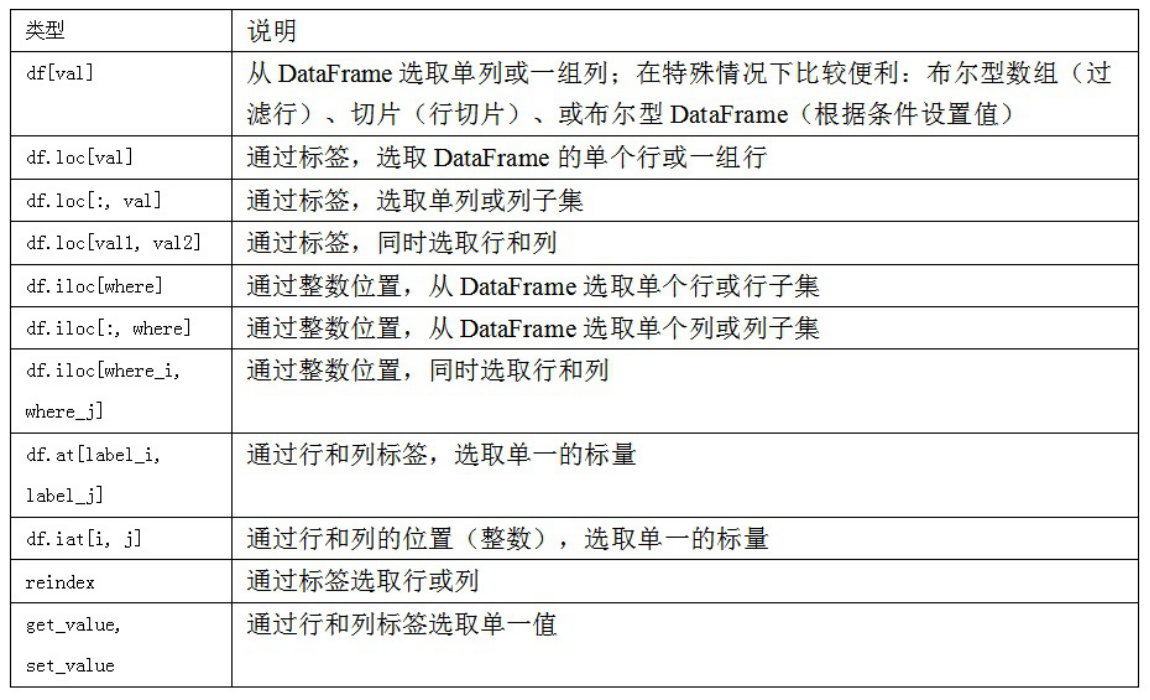
1、按索引筛选
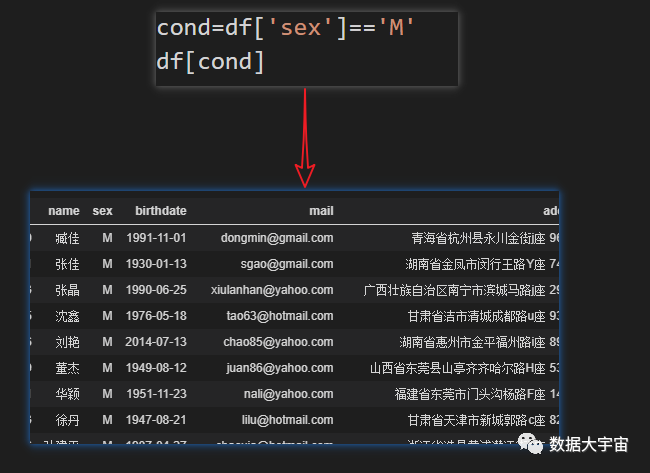
2、按值筛选
1.单条件按值筛选

3、query方法
1.单条件筛选
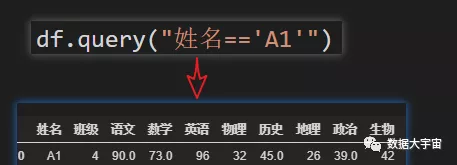
2.多条件筛选

- query 方法,可以直接接受一个查询字符串,是不是很像 Sql 呢
指定多个值也很简单,”血型是A+或B-“,如下:


4.接受外部变量

- 筛选班级为4,5,7的

- 查询字符串要使用外部变量,只需要写 “@+变量名字” 即可
5.按新增求和列筛选

- 第一句,添加新列,总和列。
pandas 新增列非常简单,df[新列名字]=新列值,即可 - df.loc[:,’语文’:’生物’] ,是获取语文到生物之间的列的数据
- .sum(axis=1) ,横向求和。
因为 pandas 可以灵活对行或列做运算,通过 axis 即可表达运算是对行还是列操作。 -
6.嵌套逻辑关系符

query 中的查询字符串可以使用 python 中的逻辑关键字 and 或 or 这些都可以
4、模糊筛选
- 筛选首字母A的数据

- 血型 列是文本类型,因此可以用 .str ,从而使用一系列文本快捷方法
- “住址内容包含 天津市 3字”的记录。如下:

- “住址内容有 x座 ,x是字母a至c,大小写都算”
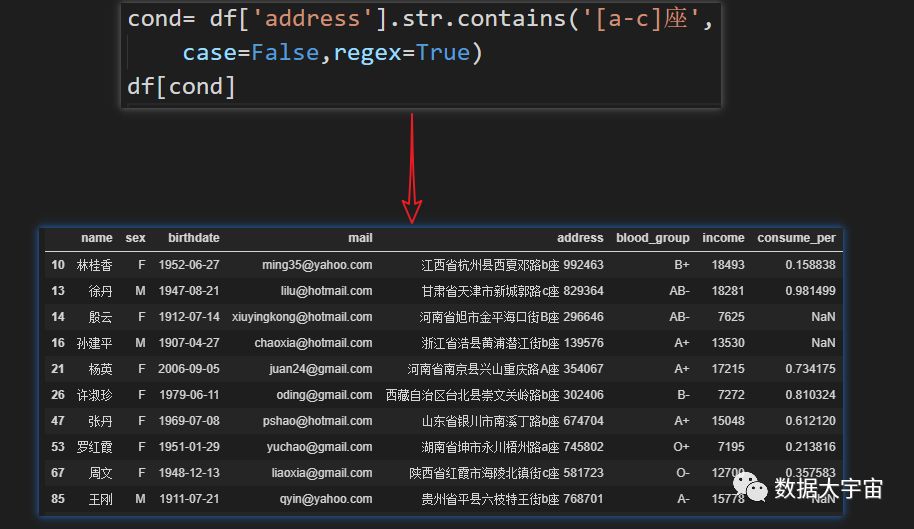
- contains 方法可以用正则表达式
- contains 函数用法
Series.str.contains(pat, case=True, flags=0, na=nan, regex=True)是否包含查找的字符串 参数: pat : 字符串/正则表达式 case : 布尔值, 默认为True.如果为True则匹配敏感(大小写敏感) flags : 整型,默认为0(没有flags) na : 默认为NaN,替换缺失值. regex : 布尔值, 默认为True.如果为真则使用re.research,否则使用Python 返回值: 布尔值的序列(series)或数组(array)
(二)高级筛选

- 总分高于平均分的学生

- 总分高于所在班级平均分的学生
.groupby(‘班级’) ,按班级分组
.apply ,对每组查询总分超出平均分的记录。这里的 query 字符串与上一例子是一样的
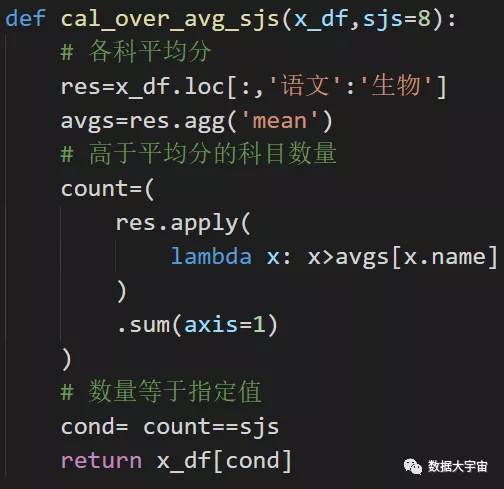
- 定义一个方法,这有利于重用逻辑
- 前2句,先求出每科平均分
- 然后求出每位学生高于平均分的科目数量 count
- 最后简单判断一下,即可得到结果
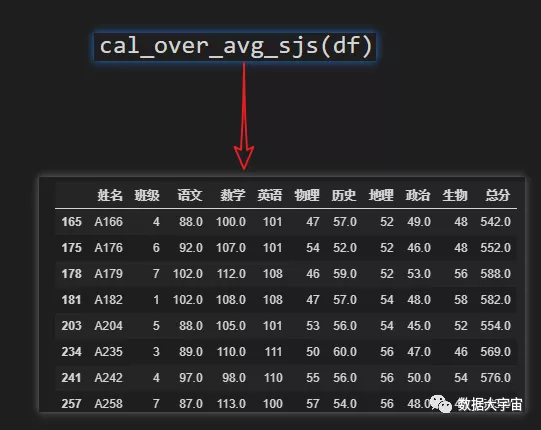
- 调用函数,求出全级8科成绩均大于平均分的学生
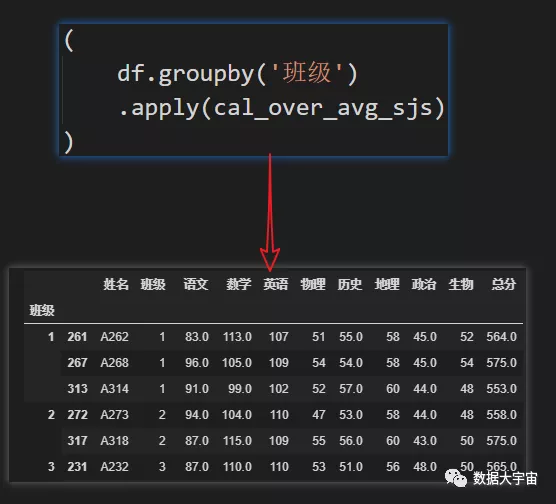
- 按班级分组,每班中8科成绩均大于平均分的学生
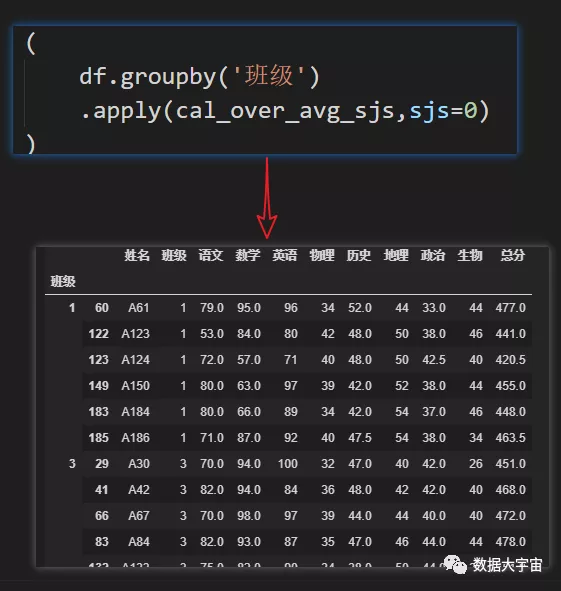
- 添加参数”sjs”
- “8科成绩都低于班内平均水平的学生”

若有收获,就点个赞吧
0 人点赞
