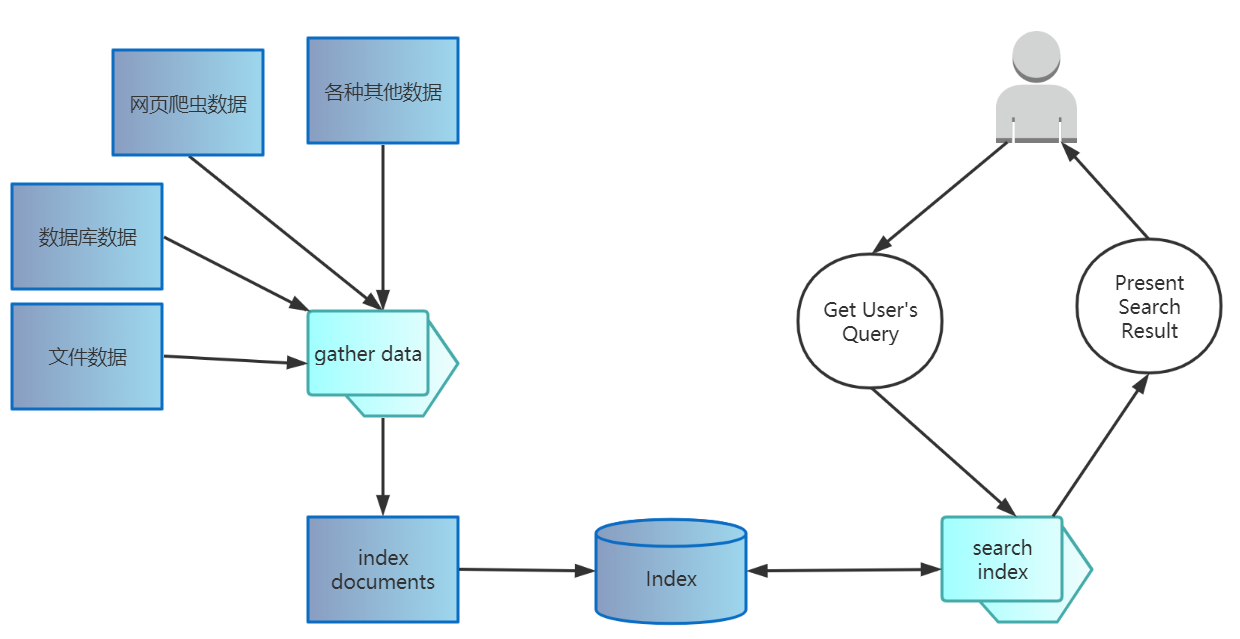
1. Elasticsearch核心概念和原理
1.1 Elasticsearch 特点
分布式、高性能、高可用、可伸缩、易维护 Elasticsearch≈搜索引擎
- 分布式的搜索,存储和数据分析引擎
- 面向开发者友好,屏蔽了Lucene的复杂特性,集群自动发现(cluster discovery)
- 自动维护数据在多个节点上的建立
- 会帮我做搜索请求的负载均衡
- 自动维护冗余副本,保证了部分节点宕机的情况下仍然不会有任何数据丢失
- Elasticsearch基于Lucene提供了很多高级功能:复合查询、聚合分析、基于地理位置等。
- 对于大公司,可以构建几百台服务器的大型分布式集群,处理PB级别数据;对于小公司,开箱即用,门槛低上手简单
相遇传统数据库,提供了全文检索,同义词处理(美丽的cls>漂亮的cls),相关度排名。聚合分析以及海量数据的近实时(NTR)处理,这些传统数据库完全做不到。
1.2 Elasticsearch 的使用场景
百度(全文检索、高亮、搜索推荐)
- 各大网站的用户行为日志(用户点击、浏览、收藏、评论)
- BI(Business Intelligence商业智能),数据分析:数据挖掘统计。
- Github:代码托管平台,几千亿行代码
ELK:Elasticsearch(数据存储)、Logstash(日志采集)、Kibana(可视化)
1.3 Elasticsearch 核心概念
node(节点),就是一个一个Elasticsearch实例,只不过由于他们在一个集群中的,所以每个Elasticsearch是一个节点。
- cluster(集群):由多个node节点组成 每个集群至少包含两个节点.
- doc(文档):Elasticsearch中最小的数据单元,类似于关系型数据库中的表。但是在Elasticsearch中表现为JSON格式。这很像MongoDB。
- field(字段):一个数据字段,与index和type一起,可以定位一个doc
- type(类型):逻辑上的数据分类,es 7.x中删除了type的概念
- index(索引):索引,一类相同或者类似的doc,比如一个员工索引,商品索引。
- shard分片:
- 一个index包含多个shard,默认5个primary-shard,默认每个primary-shard分配一个read-shard,P的数量在创建索引的时候设置,如果想修改,需要重建索引。
- 每个shard都是一个Lucene实例,有完整的创建索引的处理请求能力。
- Elasticsearch会自动在nodes上为我们做shard均衡。
- 一个doc是不可能同时存在于多个primary-shard中的,但是可以存在于多个read-shard中。
- primary-shard和对应的read-shard不能同时存在于同一个节点,所以最低的可用配置是两个节点,互为主备。
1.4 全文检索
我们生活中的数据总体分为2种:结构化数据和非结构化数据。
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:又叫做
**全文数据**,指不定长或无固定格式的数据,如邮件,word文档等。
当然有的地方还会提到第三种,半结构化数据,如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
按照数据的分类,搜索也分为2种:
对结构化数据的搜索:
如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
对非结构化数据的搜索:
由于非结构化数据没有规律性,所以如windows的搜索文件内容,Linux下的grep命令,这些都是顺序扫描,搜索目标集越大,性能越慢。例如在windows中如果你有一个80G硬盘,如果想在上面找到一个内容包含某字符串的文件,不花他几个小时,怕是做不到。Linux下的grep命令也是这一种方式。大家可能觉得这种方法比较原始,但对于小数据量的文件,这种方法还是最直接,最方便的。但是对于大量的文件,这种方法就很慢了。
所以需要一个更好的检索方式, 全文检索就提供了这么一个思路,全文检索的基本思路是:**将非结构化数据中的关键信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。** 这些重新组织的信息,我们称之**索引**。
**这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。**
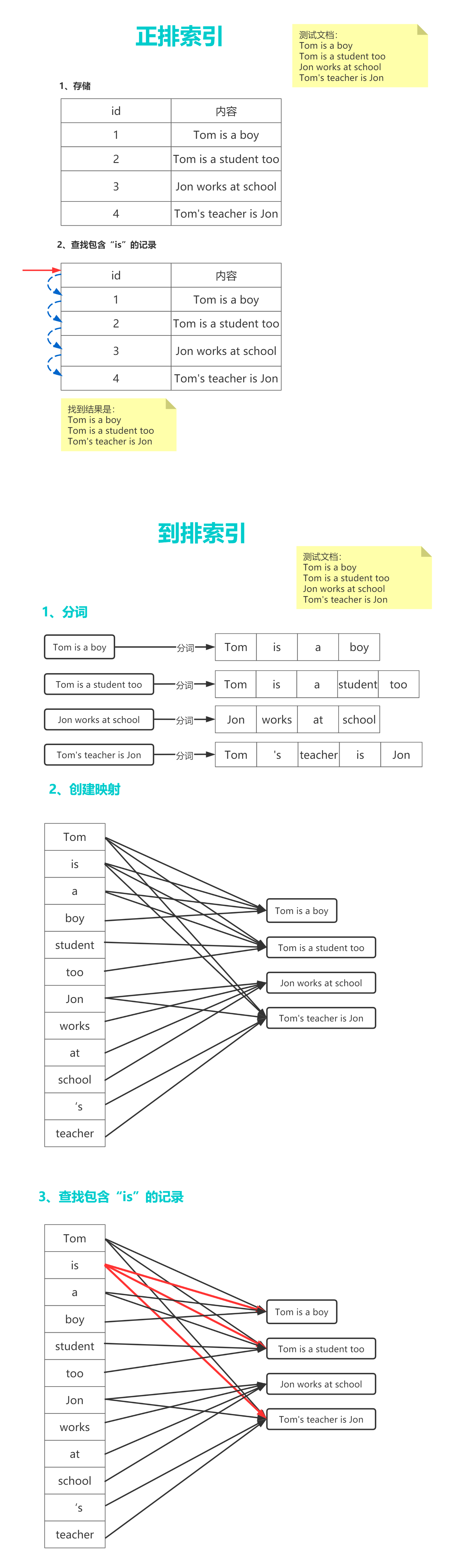
1.4 倒排索引
倒排索引和正排索引的区别:
正排索引:**正排索引以每个记录的id为索引**,对应的是id所对应的记录。 查找记录内某个内容时,需要遍历整个id库,从而找到id对应的记录匹配到某个内容。 正排索引的特点是插入速度快,查找性能差。正排索引的实现:mysql、oracle等关系型数据库。
倒排索引:**倒排索引以每个关键词为索引**,对应的的关键词在所有记录中出现的次数的列表,查找某个关键词时可以直接命中对应的记录。但是由于插入时要维护关键词和文档的列表。所以插入性能会很慢。
2. 安装环境
(Windows和Linux:课件中我整理了图文安装教程,如果遇到问题可以自行百度,难度不大,实在不行也可以问我,这里就不演示步骤了)
2.1 安装Elasticsearch
假设:
- Elasticsearch的解压目录为
{ES_source_path}
- 下载
请进官网下载:http://elastic.co/
国内镜像:https://mirrors.huaweicloud.com/elasticsearch
解压
$ tar xf elasticsearch-7.11.1-linux-x86_64.tar.gz
启动Elasticsearch
$ {ES_source_path}/bin/elasticsearch
或者
$ {ES_source_path}/bin/elasticsearch -d
“-d”是后台启动
验证
打开浏览器输入:http://{Elasticsearch安装服务器的ip}:9200, 看到一串json表示安装成功
{"name" : "iZ2ze8b3wpoxtvocjln8osZ","cluster_name" : "elasticsearch","cluster_uuid" : "PObK89hjTWyUmlVvmF1M7g","version" : {"number" : "7.11.1","build_flavor" : "default","build_type" : "tar","build_hash" : "ff17057114c2199c9c1bbecc727003a907c0db7a","build_date" : "2021-02-15T13:44:09.394032Z","build_snapshot" : false,"lucene_version" : "8.7.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"}
【安装Elasticsearch注意事项】:
- 安装Elasticsearch之前必须安装JDK,因为Elasticsearch是依赖java的。
- 系统环境变量中必须要有“
JAVA_HOME” - Elasticsearch不能使用root账号启动,所以在linux中必须创建一个非root账号来启动Elasticsearch。
假设:Elasticsearch解压目录为: /root/soft/elasticsearch/elasticsearch-7.11.1
a. 创建用户 {user_name}
$ adduser {user_name}
b. 创建用户密码,需要输入两次
$ passwd {user_name}
c. 将对应的文件夹权限赋予给创建的账户(根目录开始就要给)
$ chown -R {user_name}:{user_name} /root
d. 切换至{user_name}用户
$ su {user_name}
e. 启动elasticsearch
$ /root/soft/elasticsearch/elasticsearch-7.11.1/bin/elasticsearch -d
- 报错“max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]”
a. 切换到root用户,执行命令:
$ sysctl -w vm.max_map_count=262144
b. 查看结果:
$ sysctl -a|grep vm.max_map_count$ vm.max_map_count = 262144
c. 永久解决办法
在/etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
执行“sysctl -p”
$ sysctl -p
- 无法外网访问9200端口
- 首先确定linux是否开启了防火墙,如果是阿里云ECS请打开9200端口
- 因为Elasticsearch监听的事本地回环端口,所以只能本地访问。解决方法:
在最下面加入两个配置:$ vim {ES_source_path}/conf/elasticsearch.yml
然后重启Elasticsearch即可。network.host: 0.0.0.0discovery.seed_hosts: ["127.0.0.1", "[::1]"]
Elasticsearch开发模式和生产模式
开发模式:
默认配置(未配置发现设置),用于学习阶段。在同一台机器上解压多个Elasticsearch并启动,Elasticsearch会自动发现并形成集群。
生产模式:
修改配置文件内容会触发Elasticsearch的引导检查(CPU、内存、线程、JVM、网络、磁盘等等),如果有一项不合格Elasticsearch会阻止启动,所以学习阶段不建议修改集群相关的配置。
Elasticsearch在生产环境中不建议使用docker部署,因为:
- Elasticsearch在生产环境中基本上是要使用整台机器的资源的。
- Elasticsearch的部署极其简单,不需要docker。
2.2 安装Kibana
(从版本6.0.0开始,Kibana仅支持64位操作系统。)
- 下载
https://www.elastic.co/cn/downloads/kibana
https://mirrors.huaweicloud.com/kibana
- 启动
依然是开箱即用
Linux:./kibana
Windows:.\kibana.bat
- 验证
linux下不挂起运行:
nohup /root/soft/kibana/kibana-7.11.1-linux-x86_64/bin/kibana > /dev/null 2>&1 &
如果windows版本启动时提示无法运行此程序,换个低版本的kibana即可。
2.3 安装elasticsearch-head插件(选装)
提供可视化的操作页面对Elasticsearch搜索引擎进行各种设置和数据检索功能,可以很直观的查看集群的健康状况,索引分配情况,还可以管理索引和集群以及提供方便快捷的搜索功能等等。
假设:
- elasticsearch-head的下载目录为
{elasticsearch-head_downland_path} - elasticsearch-head的解压目录为
{elasticsearch-head_source_path}
下载elasticsearch-head
$ git clone https://github.com/mobz/elasticsearch-head
elasticsearch-head依赖于node和grunt管理工具,所以需要下载,已有请忽略。
$ yum install node -y$ npm install -g grunt-cli
启动elasticsearch-head
$ cd {elasticsearch-head_source_path}$ npm run start
2.5 Elasticsearch基础操作
1、集群健康
健康值检查
$ curl http://127.0.0.1:9200/_cat/health$ curl http://127.0.0.1:9200/_cluster/health
健康值状态说明
green:所有primary和replica均为active,集群健康
yellow:至少一个replica不可用,但是所有primary均为active,数据仍然是可以保证完整性的。
red:至少有一个primary为不可用状态,数据不完整,集群不可用。
2、基础CRUD
创建索引
{index_name}$ curl -X PUT http://{elasticsearch-ip}:9200/{index_name}?pretty{"acknowledged" : true,"shards_acknowledged" : true,"index" : "product"}
查询索引:GET _cat/indices?v
$ curl http://{elasticsearch-ip}:9200/_cat/health?vepoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent1614058851 05:40:51 elasticsearch green 1 1 0 0 0 0 0 0 - 100.0%
删除索引:DELETE /
{index_name}?pretty$ curl -X DELETE http://{elasticsearch-ip}:9200/{index_name}?pretty{"acknowledged" : true}
向
{index_name}索引下插入数据:$ curl -X PUT http://{elasticsearch-ip}:9200/{index_name}/_doc/{id}{"_index" : "product","_type" : "_doc","_id" : "10","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 25,"_primary_term" : 1}
更新数据
全量替换,就是再插入一遍数据,但是version会递增, result会变为updated
$ curl -X PUT http://{elasticsearch-ip}:9200/{index_name}/_doc/{id} -d '{"name":"xiaomi phone","desc":"shouji zhong de zhandouji","price":3999,"tags":["xingjiabi","fashao","buka"]}' -H 'Content-Type:application/json'{"_index":"product","_type":"_doc","_id":"10","_version":2,"result":"updated","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":26,"_primary_term":1}
指定字段更新
- 删除数据
$ curl -X DELETE http://{Elasticsearch-ip}:9200/{index_name}/_doc/{id}
3. Elasticsearch分布式文档系统
3.1 Elasticsearch如何实现高可用
- Elasticsearch在分配单个索引的分片时会将每个分片尽可能分配到更多的节点上。但是,实际情况取决于集群拥有的分片和索引的数量以及它们的大小,不一定总是能均匀地分布。
- Elasticsearch不允许primary和它的replica放在同一个节点中,并且同一个节点不接受完全相同的两个replica
3.2 容错机制
- 主节点(master-node)
- 主节点,每个集群都有且只有一个
- 尽量避免Master节点
node.data = true
- 投票节点(voting-node)
node.voting_only = true(仅投票节点,即使配置了data.master = true,也不会参选, 但是仍然可以作为数据节点)。
- 协调节点(coordinating-node)
每一个节点都隐式的是一个协调节点,如果同时设置了data.master = false和data.data=false,那么此节点将成为仅协调节点。
- master候选节点(master-eligible-node)
- 数据节点(data-node)
- Ingest node
- 机器学习节点(machine-learning-node)
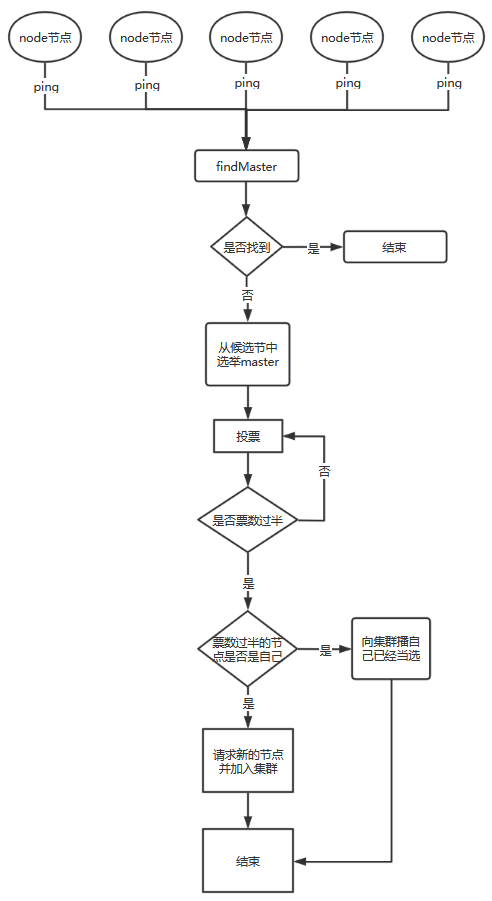
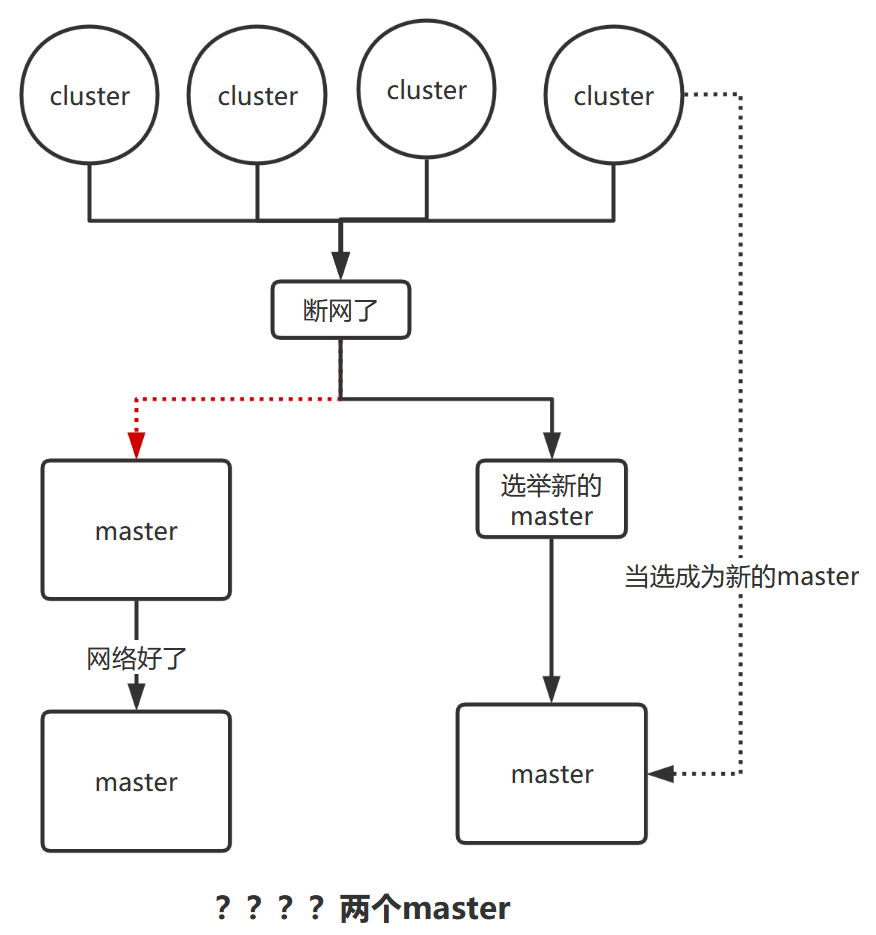
脑裂问题:
3.3 关于master节点和data节点
| 节点 | node.master | node.data | 说明 |
|---|---|---|---|
| master和data | true | true | 这是Elasticsearch节点默认配置,既作为候选节点又作为数据节点,这样的节点一旦被选举为master,压力是比较大的,通常来说master节点应该只承担较为轻量级的任务,比如创建删除索引,分片均衡等。 |
| master候选节点 | true | false | 只作为候选节点,不作为数据节点,可参选master节点,当选后成为真正的master节点。 |
| 仅协调节点 | false | false | 既不当候选节点,也不作为数据节点,那就是仅协调节点,负责负载均衡 |
| 数据节点 | false | true | 不作为候选节点,但是作为数据节点,这样的节点主要负责数据存储和查询服务。 |
3.4 图解容错机制
- 第一步:master选举(假如宕机节点是master)
脑裂:可能会产生多个Master节点
解决:discovery.zen.minimum_master_nodes=N/2+1
- 第二步:
replica容错,新的(或者原有)master节点会将丢失的primary对应的某个副本提升为primary
- 第三步
master节点会尝试重启故障机
- 第四步
数据同步,master会将宕机期间丢失的数据同步到重启机器对应的分片上去
3.5 总结
如何提高Elasticsearch分布式系统的可用性以及性能最大化:
- 每台节点的shard数量越少,每个shard分配的CPU、内存和IO资源越多,单个shard的性能越好,当一台机器一个shard时,单个shard性能最好。
- 稳定的master节点对于群集健康非常重要!理论上讲,应该尽可能的减轻master节点的压力,分片数量越多,master节点维护管理shard的任务越重,并且节点可能就要承担更多的数据转发任务,可增加“仅协调”节点来缓解master节点和data节点的压力,但是在集群中添加过多的仅协调节点会增加整个集群的负担,因为选择的主节点必须等待每个节点的集群状态更新确认。
- 反过来说,如果相同资源分配相同的前提下,shard数量越少,单个shard的体积越大,查询性能越低,速度越慢,这个取舍应根据实际集群状况和结合应用场景等因素综合考虑。
- 数据节点和master节点一定要分开,集群规模越大,这样做的意义也就越大。
- 数据节点处理与数据相关的操作,例如CRUD,搜索和聚合。这些操作是I/O,内存和CPU密集型的,所以他们需要更高配置的服务器以及更高的带宽,并且集群的性能冗余非常重要。
- 由于仅投票节不参与master竞选,所以和真正的master节点相比,它需要的内存和CPU较少。但是,所有候选节点以及仅投票节点都可能是数据节点,所以他们都需要快速稳定低延迟的网络。
- 高可用性(HA)群集至少需要三个主节点,其中至少两个不是仅投票节点。即使其中一个节点发生故障,这样的群集也将能够选举一个主节点。生产环境最好设置3台仅Master候选节点(
node.master = true`` node.data = true) - 为确保群集仍然可用,集群不能同时停止投票配置中的一半或更多节点。只要有一半以上的投票节点可用,群集仍可以正常工作。这意味着,如果存在三个或四个主节点合格的节点,则群集可以容忍其中一个节点不可用。如果有两个或更少的主机资格节点,则它们必须都保持可用
4. Elasticsearch查询语法
4.1 timeout
假设用户查询结果有1W条数据,但是需要10s才能查询完毕,但是用户设置了1s的timeout,那么不管当前一共查询到了多少数据,都会在1s后Elasticsearch讲停止查询,并返回当前已查询到的数据。
默认没有timeout,如果设置了timeout,那么会执行timeout机制。
GET /{index_name}/_search?timeout=1s/ms/m
4.2 Elasticsearch常用查询
- 插入一些测试用的小米手机产品数据 ```json PUT /product/_doc/1 { “name” : “xiaomi phone”, “desc” : “shouji zhong de zhandouji”, “price” : 3999, “tags”: [ “xingjiabi”, “fashao”, “buka” ] }
PUT /product/_doc/2 { “name” : “xiaomi nfc phone”, “desc” : “zhichi quangongneng nfc,shouji zhong de jianjiji”, “price” : 4999, “tags”: [ “xingjiabi”, “fashao”, “gongjiaoka” ] }
PUT /product/_doc/3 { “name” : “nfc phone”, “desc” : “shouji zhong de hongzhaji”, “price” : 2999, “tags”: [ “xingjiabi”, “fashao”, “menjinka” ] }
PUT /product/_doc/4 { “name” : “xiaomi erji”, “desc” : “erji zhong de huangmenji”, “price” : 999, “tags”: [ “low”, “bufangshui”, “yinzhicha” ] }
PUT /product/_doc/5 { “name” : “hongmi erji”, “desc” : “erji zhong de kendeji”, “price” : 399, “tags”: [ “lowbee”, “xuhangduan”, “zhiliangx” ] }
<a name="aEVyA"></a>## 4.3 RESTFul API查询查询所有:```sqlselect * from product;
GET /product/_search
查询name中包含“xiaomi”的数据
select * from product where name like "%xiaomi%";
GET /product/_search?q=name:xiaomi
排序+分页:
select * from product order by price asc limit 2,2;
GET /product/_search?from=1&size=2&sort=price:asc
查询name中包含”xiaomi”的数据并排序后每2条数据为一页,获取第2页
select * from product where name like "%xiaomi%" order by price asc limit 2,2;
GET /product/_search?q=name:xiaomi&from=1&size=2&sort=price:asc
4.4 match分词匹配
match_all:匹配所有
#查询所有相关数据GET /product/_search{"query":{"match_all": {}}}
match:分词匹配
#查询name中与“nfc”相关的数据GET /product/_search{"query": {"match": {"name": "nfc"}}}
multi_match:分词匹配多项
#查询查询name和desc中都和“nfc”相关数据GET /product/_search{"query": {"multi_match": {"query": "nfc","fields": ["name","desc"]}}}
4.5 sort 排序
#查询name和desc中都与“nfc”相关数据,并按照价格倒序排序GET /product/_search{"query": {"multi_match": {"query": "nfc","fields": ["name","desc"]}},"sort": [{"price": {"order": "desc"}}],}
4.5 from+size 分页
#查询name和desc中都和“nfc”的相关数据,并按照价格倒序排序后,每2条数据为一页,获取第二页数据GET /product/_search{"query": {"multi_match": {"query": "nfc","fields": ["name","desc"]}},"sort": [{"price": {"order": "desc"}}],"from": 1,"size": 2}
deep paging
假设有5万条数据,分散在5个shard里面,那个每个shard里面是1万条数据,现在要按照某个字段排序后按照每页10条分页,然后取出第500页的数据来。
GET /product/_search{"query": {"multi_match": {}},"sort": [{"price": {"order": "desc"}}],"from": 500,"size": 10}
Elasticsearch经过计算得出每个分片要排序后获取0~500*100+10=5010条数据,然后把这些分片数据集合到一起再次进行排序,获取第5000~5010条数据。
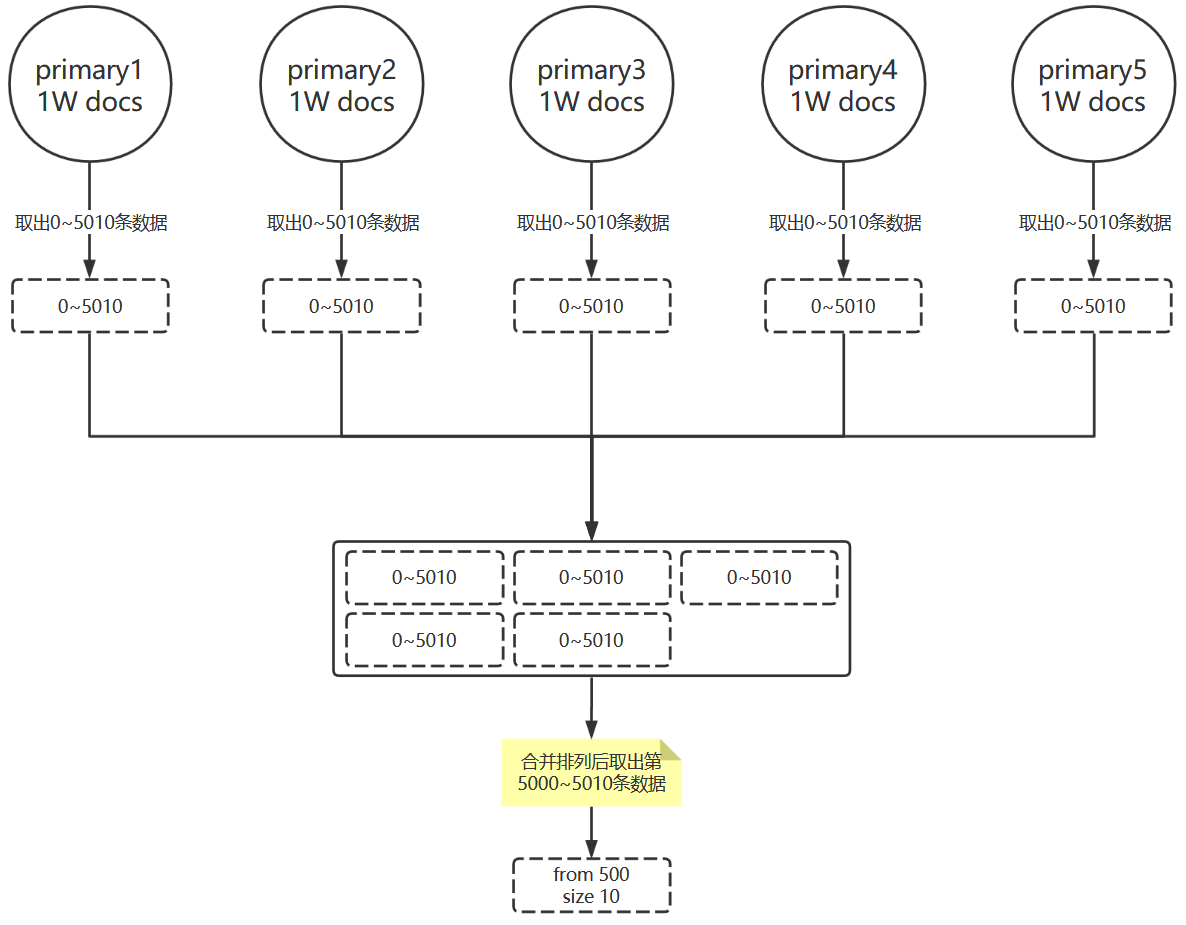
deep pageing分页总结:
- 当你的数据超过1W,不要使用deep pageing
- 返回结果不要超过1000个,500以下为宜。
deep pageing解决办法:
使用scroll_search(只能下一页,没办法上一页,不适合实时查询)
scroll (deep paging优化)
第一次查询时url后面增加一个参数?scroll={超时时间}{超时时间单位m/h/}, 第一次查询的结果会返回一个scroll_id, 以后的查询只需要指定scroll_id就可以。
- 第1次查询:
GET /order/_search?scroll=1m{"query": {"match": {"insuranceCompany": "平安"}},"_source": ["insuranceCompany","orderNo","premium"],"sort": [{"premium": {"order": "desc"}}]}
- 以后的查询
GET /_search/scroll?pretty{"scroll":"{超时时间}{超时时间单位}","scroll_id":"{第一次scroll查询结果中的scroll_id}"}
需要注意:
- 如果遇到“No search context found for id [577]”错误请调大scroll等待时间重来。
- 以后的查询不要忘记加
scroll
4.7 _source 取特定字段
#只查询name中和“nfc”相关的数据的name字段和price字段。GET /product/_search{"query":{"match": {"name": "nfc"}},"_source": ["name","price"]}
4.7 range范围查询
类似于SQL里面的 between…and…
GET baobei-product-pro-2021.04/_search{"query": {"bool": {"filter": [{"range": {"time.keyword": {"format": "yyyy-MM-dd HH:mm:ss.SSS","gte": "2021-04-15 10:00:09.000","lte": "2021-04-15 10:00:10.999"}}}]}}}
4.8 全文检索
match
GET /product/_search{"query": {"match": {"name": "xiaomi nfc zhineng phone"}}}#验证分词GET /_analyze{"analyzer": "standard","text":"xiaomi nfc zhineng phone"}
match_phrase
短语搜索,和全文检索相反,“nfc phone”会作为一个短语去检索
GET /product/_search{"query": {"match_phrase": {"name": "nfc phone"}}}
4.9 term 不被分词匹配
GET /product/_search{"query": {"term": {"name": "nfc"}}}
match和term区别:
GET /product/_search{"query": {"term": {"name": "nfc phone" //这里因为没有分词,所以查询没有结果}}}GET /product/_search{"query": {"bool": {"must": [{"term":{"name":"nfc"}},{"term":{"name":"phone"}}]}}}GET /product/_search{"query": {"terms": {"name":["nfc","phone"]}}}GET /product/_search{"query": {"match": {"name": "nfc phone"}}}
4.10 filter 查询和过滤
bool
bool可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值。bool可以和 must、must_not、should、filter组合使用
- must:必须满足
子句(查询)必须出现在匹配的文档中,并将有助于得分。
- must_not:必须不满足 不计算相关度分数
子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被忽略,并且子句被视为用于缓存。由于忽略计分,0因此将返回所有文档的分数
- should:可能满足,类似于SQL中的or
子句(查询)应出现在匹配的文档中。
- filter 过滤器 不计算相关度分数,重要☆
子句(查询)必须出现在匹配的文档中。但是不像 must查询的分数将被忽略。filter子句在filter上下文中执行,这意味着计分被忽略,并且子句被考虑用于缓存。
"minimum_should_match": {N}最少应该匹配N个。
bool案例
首先筛选name中包含“xiaomi phone”并且价格大于1999的数据(不排序),然后搜索name包含“xiaomi”并且 desc 中包含“shouji”
GET /product/_search{"query": {"bool": {"must": [{"match": { "name": "xiaomi" }},{"match": { "desc": "shouji" }}],"filter": [{"match_phrase": { "name":"xiaomi phone"}},{"range": {"price": { "gt": 1999 }}}]}}}
bool多条件 name包含xiaomi 不包含erji 描述里包不包含nfc都可以,价钱要大于等于4999
GET /product/_search{"query": {"bool":{#name中必须包含“xiaomi”"must": [{"match": { "name": "xiaomi"}}],#name中必须不能包含“erji”"must_not": [{"match": { "name": "erji"}}],#should中至少满足0个条件,参见下面的minimum_should_match的解释"should": [{"match": {}}],#筛选价格大于4999的doc"filter": [{"range": {"price": { "gt": 4999 }}}]}}}
bool嵌套查询:
1) minimum_should_match:参数指定should返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句,而没有must或 filter子句,则默认值为1。否则,默认值为0
GET /product/_search{"query": {"bool": {"must": [{"match": {"name": "nfc"}}],"should": [{"range": {"price": { "gt": 1999 }}},{"range": {"price": { "gt": 3999 }}}],"minimum_should_match": 1}}}
bool案例:
GET /product/_search{"query": {"bool": {"filter": {"bool": {"should": [{ "range": {"price": {"gt": 1999}}},{ "range": {"price": {"gt": 3999}}}],"must": [{ "match": {"name": "nfc"}}]}}}}}
(6) Compound queries:组合查询
① 想要一台带NFC功能的 或者 小米的手机 但是不要耳机
SELECT*from productwhere(`name` like "%xiaomi%" or `name` like '%nfc%')AND `name` not LIKE '%erji%'
GET /product/_search{"query": {"constant_score": {"filter": {"bool": {"should": [{"term": { "name": "xiaomi" }},{"term": { "name": "nfc" }}],"must_not": [{"term": { "name": "erji" }}]}},"boost": 1.2}}}
② 搜索一台“xiaomi nfc phone”或者一个加个区间在“399~2999”之间的“erji”
select*from productwherename like '%xiaomi nfc phone%'OR( name like '%erji%' and price > 399 and price <=2999);
GET /product/_search{"query": {"constant_score": {"filter": {"bool": {"should": [{"match_phrase": {"name": "xiaomi nfc phone"}},{"bool": {"must": [{"term": { "name": "phone" }},{"range": {"price": { "lte": "2999" }}}]}}]}}}}}
(7) Highlight search:
GET /product/_search{"query": {"match_phrase": {"name": "nfc phone"}},"highlight": {"fields": {"name": {}}}}
- filter缓存原理:图解
| [“Tom is a boy”,”Tom’s teacher is Jon”,”Jon works at school”,”Tom is a student too”] | ||||
|---|---|---|---|---|
| Tom | [1,1,0,1] | |||
| is | [1,1,0,1] | |||
| a | [1,0,0,1] | |||
| boy | [1,0,0,0] | |||
| Jon | [0,1,1,0] | |||
| hahahaha | [0,0,0,0] |
4.12 aggs 聚合查询
以applicantName分组查询相同的applicantName的总量。
GET /product/_search?timeout=1000m{"aggs": {"{自定义聚合的名字}": {"terms": {"field": "applicantName.keyword"}}},"size": 0}
查询premium大于1小于2的数据,并以applicantName分组查询相同的applicantName的总量。
GET /product/_search?timeout=1000m{"query": {"bool": {"filter": {"range": { //用range指定范围查询"premium": {"gte": 1,"lte": 2}}}}},"aggs": {"{自定义聚合的名字}": {"terms": {"field": "applicantName.keyword"}}},"size": 0}
平均价格
#平均价格GET /product/_search{"aggs": {"tag_agg_avg": {"terms": {"field": "tags.keyword","order": {"avg_price": "desc"}},"aggs": {"avg_price": {"avg": {"field": "price"}}}}},"size":0}
安保费分组后的平均保费
GET /product/_search{"aggs": {"tag_agg_group": {"range": {"field": "price","ranges": [{"from": 100,"to": 1000},{"from": 1000,"to": 3000},{"from": 3000}]},"aggs": {"price_agg": {"avg": {"field": "price"}}}}},"size": 0}
4.12 _mget批量查询
_mget只支持元数据(metadata)查询, 一般常见的元数据有3个,分别是: _index(索引名字)、_type(文档类型)、_id(id)。
所以可以写成下面这样:GET _mget{"docs":[{"_index" : "{索引名字}","_type":"{类型名字}","_id" : "{id}"},{"_index" : "{索引名字}","_type":"{类型名字}","_id" : "{id}"},{"_index" : "{索引名字}","_type":"{类型名字}","_id" : "{id}"}]}
只查询某些字段:
GET _mget{"docs":[{"_index" : "order","_type":"_doc","_id" : "1","_source":["proCode","rate","premium"] # 指定某些字段},{"_index" : "order","_id" : "1","_source":{"exclude":["userId"] #不包含某些字段}},{"_index" : "order","_type":"_doc","_id" : "1","_source":{"include":["proCode","rate","premium"] # 指定某些字段}}]}
如果 exclude 和 include 同时出现时, Elasticsearch会执行inlcude操作
如果是一个索引内的批量查询可以在URL上指定索引名字
GET {索引名字}/_mget{"docs":[{ "_id" : "{id}", "_type":"{类型名字}" },{ "_id" : "{id}", "_type":"{类型名字}" },{ "_id" : "{id}", "_type":"{类型名字}" },{ "_id" : "{id}", "_type":"{类型名字}" }]}
如果是一个索引和一个类型内内的批量查询可以在URL上指定索引名字和类型名字
GET {索引名字}/{类型名字}/_mget{"docs":[{ "_id" : "{id}" },{ "_id" : "{id}" },{ "_id" : "{id}" },{ "_id" : "{id}" }]}
一个索引内、一个类型、一个id内的批量查询
GET {索引名字}/{类型名字}/_mget{"ids":["{id}","{id}","{id}","{id}"]}
4.13 _bulk 批量操作
_bulk的模板为为:
POST _bulk{"<action>":{"_index":"<索引名字>","_id":"<id>"}}\n{doc}\n{"<action>":{"_index":"<索引名字>","_id":"<id>"}}\n{doc}\n
action必须是下面4种之一
| action | 说明 |
|---|---|
index |
如果文档不存在就创建他,如果文档存在就更新他 |
create |
如果文档不存在就创建他,但如果文档存在就返回错误, 使用时一定要在metadata设置_id值,他才能去判断这个文档是否存在 |
update |
更新一个文档,如果文档不存在就返回错误使用时也要给_id值,且后面文档的格式和其他人不一样,需要注意的是,使用update,下一行的文档内容需要用”doc“包起来。 |
delete |
删除一个文档,如果要删除的文档id不存在,就返回错误使用时也必须在metadata中设置文档_id,且后面不能带一个doc,因为没意义,他是用_id去删除文档的 |
metadata : 设置这个文档的metadata,像是_id、_index、_type
doc : 就是一般的文档数据。
_bulk 批量插入
所以一个批量插入的demo是下面这样的:
POST /_bulk{"index":{"_index":"order","_id":"1"}}{"age":"18","name":"wanfan1"}{"index":{"_index":"order","_id":"2"}}{"age":"19","name":"wanfan2"}{"index":{"_index":"order","_id":"3"}}{"age":"20","name":"wanfan3"}
_bulk批量修改
需要注意的是:update的内容要要在doc内,doc内才是你要修改的内容。
POST _bulk{ "update" : {"_id" : "1", "_index" : "index1", "retry_on_conflict" : 3} }{ "doc" : {"field" : "value"} }{ "update" : { "_id" : "0", "_index" : "index1", "retry_on_conflict" : 3} }{ "script" : { "source": "ctx._source.counter += params.param1", "lang" : "painless", "params" : {"param1" : 1}}, "upsert" : {"counter" : 1}}{ "update" : {"_id" : "2", "_index" : "index1", "retry_on_conflict" : 3} }{ "doc" : {"field" : "value"}, "doc_as_upsert" : true }{ "update" : {"_id" : "3", "_index" : "index1", "_source" : true} }{ "doc" : {"field" : "value"} }{ "update" : {"_id" : "4", "_index" : "index1"} }{ "doc" : {"field" : "value"}, "_source": true}
_bulk文件
还可以把请求体数据写在文件里面:
在**$ES_HOME**里,新建一文件,命名为requests.json
$ cd $ES_HOME$ echo -e '{"index":{"_index":"order","_id":"1"}}\n{"age":"18","name":"wanfan1"}\n{"index":{"_index":"order","_id":"2"}}\n{"age":"19","name":"wanfan2"}\n{"index":{"_index":"order","_id":"3"}}\n{"age":"20","name":"wanfan3"}\n' > requests.json$ curl -H "Content-Type: application/json" -XPOST 'http://{ES服务器ip}:9200/_bulk' --data-binary @requests.json
_bulk需要注意的坑
- 数据必须是一行一行,不能换行,必须紧凑。
- 每一行必须跟随一个换行符,java代码可以用
System.lineSeparator()获取。 - 请求头必须是
Content-Type: application/x-ndjson - 最后一行数据后面也需要一个换行符。
- 如果是delete操作,下一行不需要doc。
- 各种action可以混合使用。
**_bulk**文件方式插入
新建文件 person.json
{"index":{"_index":"person","_type":"_doc","_id":451}}{"birdthday":"2000-04-23","color":"Yellow","create_time":"2010-07-09 04:44:46","name":"应民印","weight":70.03,"addr":"新疆乌鲁木齐市米东南路东四巷661号","age":42,"height":176.38,"tags":["易怒","勇敢","健谈","卑鄙"]}{"index":{"_index":"person","_type":"_doc","_id":452}}{"birdthday":"1973-06-14","color":"Yellow","create_time":"1985-03-01 05:44:46","name":"束禽油","weight":42.94,"addr":"安徽省安庆市大观区石狮路16号","age":43,"height":167.88,"tags":["胸无大志","贪小便宜","易怒","木讷","外向开朗","好吃懒做","温柔"]}
插入
curl -H "Content-Type: application/json" -XPOST http://localhost:9200/_bulk --data-binary @person.json
4.14 constant_score 忽略TF/IDF算法
有时我们不需要TF/IDF。我们想知道的只是一个特定的单词是否出现在了字段中。比如我们搜索日志中出现的异常, 我们不需要相关度评分,我们只需要日志中包含“Exception”或者“异常”就可以了。 可以使用constant_score。
GET baobei-product-pro-2021.03/_search{"query": {"bool": {"should": [{"constant_score": {"filter": {"match_phrase":{"msg":"Exception"}},"boost": 1.5 //Exception 这个比较重要,权重大一点}},{"constant_score": {"filter": {"match_phrase":{"msg":"异常"}},"boost": 1.2 //这个没上一个重要,权重小一点}}]}}}
使用match_phrase不会被分词

若有收获,就点个赞吧
0 人点赞
