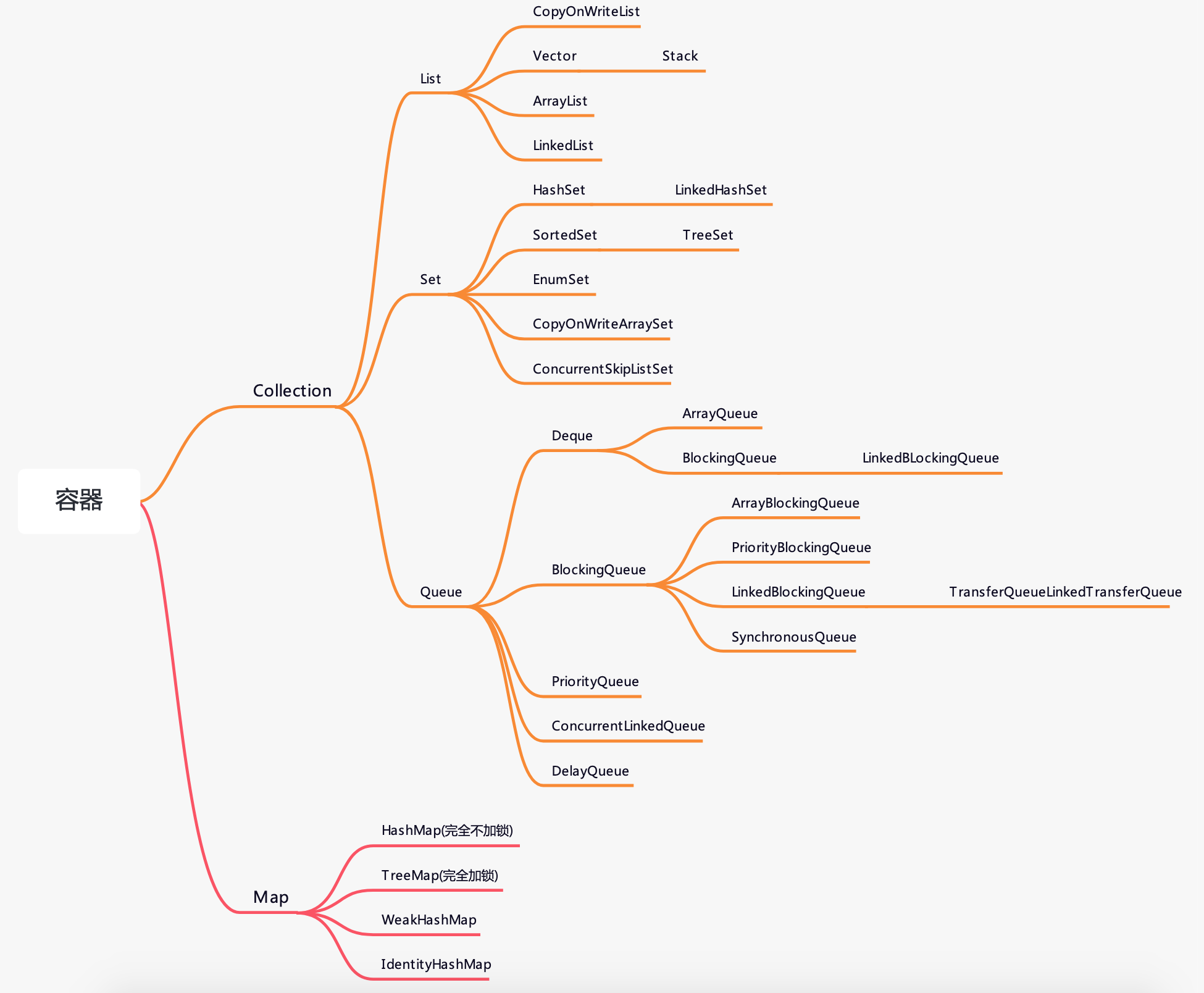
1. Map
1.1 Map集合性能测试
import java.math.BigDecimal;import java.util.*;import java.util.concurrent.*;/*** 测试写入性能: 启动500个线程,每个线程装载20000对数据,总共装载10000000对数据。 观察耗时* 测试读取性能: 启动500个线程, 每个线程循环10W次读取集合内的数据。观察耗时*/public class TestMapsWriteAndReadPerformance {private static int COUNT = 10000000; //集合内键值对总数private static int THREAD_COUNT = 500; //总线程数private static UUID[][] KEYS_ARRAY = new UUID[THREAD_COUNT][COUNT/THREAD_COUNT]; //key数组private static UUID[][] VALUES_ARRAY = new UUID[THREAD_COUNT][COUNT/THREAD_COUNT]; //value数组//待测试的集合private static List<Map<UUID, UUID>> mapList = new ArrayList<>();//初始化key和value的二维数组static {for (int i = 0; i < THREAD_COUNT; i++){for (int j = 0; j < COUNT/THREAD_COUNT; j++) {KEYS_ARRAY[i][j] = UUID.randomUUID();VALUES_ARRAY[i][j] = UUID.randomUUID();}}}/*** 测试各集合写入性能方法, 把10000000个键值对分成500页,每页启动一个线程分别装载.* @param map 具体的集合类,HashTable、HashMap、SynchronizedHashMap、ConcurrentHashMap* @return 耗时时长* @throws InterruptedException*/private static BigDecimal testWritePerformance(Map map) throws InterruptedException {//设置门闩等到线程都执行完然后打印执行时间CountDownLatch countDownLatch = new CountDownLatch(THREAD_COUNT);//启动500个线程,每个线程往m里面装一页数据。Thread[] threads = new Thread[THREAD_COUNT];for (int i = 0; i < THREAD_COUNT; i++) {UUID[] keys = KEYS_ARRAY[i];UUID[] values = VALUES_ARRAY[i];threads[i] = new Thread(()->{for (int j = 0; j < COUNT/THREAD_COUNT; j++){map.put(keys[j],values[j]);}countDownLatch.countDown();//门栓-1});}//计时开始BigDecimal timeStarted = new BigDecimal(System.currentTimeMillis());//启动所有线程Arrays.asList(threads).forEach(Thread::start);//门栓等待所有线程执行完countDownLatch.await();//计时结束BigDecimal timeEnd = new BigDecimal(System.currentTimeMillis());return timeEnd.subtract(timeStarted).divide(new BigDecimal(1000));}/*** 测试各集合读取性能方法, 启动500个线程, 每个线程循环10W次读取集合内的数据。* @param map 具体的集合类,HashTable、HashMap、SynchronizedHashMap、ConcurrentHashMap* @return 耗时时长* @throws InterruptedException*/private static BigDecimal testReadPerformance(Map map) throws InterruptedException {//设置门闩等到线程都执行完然后打印执行时间CountDownLatch countDownLatch = new CountDownLatch(THREAD_COUNT);//开始读取Thread[] threads = new Thread[THREAD_COUNT];for (int i = 0; i < THREAD_COUNT; i++) {UUID[] keys = KEYS_ARRAY[i];threads[i] = new Thread(()->{for (int j = 0; j < COUNT/THREAD_COUNT; j++) {map.get(keys[j]);}countDownLatch.countDown();//门栓-1});}//计时开始BigDecimal timeStarted = new BigDecimal(System.currentTimeMillis());//启动所有线程Arrays.asList(threads).forEach(Thread::start);//门栓等待所有线程执行完countDownLatch.await();//计时结束BigDecimal timeEnd = new BigDecimal(System.currentTimeMillis());return timeEnd.subtract(timeStarted).divide(new BigDecimal(1000));}public static void main(String[] args) throws InterruptedException {mapList.add(new Hashtable<>());mapList.add(Collections.synchronizedMap(new HashMap()));mapList.add(new ConcurrentHashMap<>());mapList.add(new ConcurrentSkipListMap<>());for (Map<UUID, UUID> map : mapList) {BigDecimal writeTime = testWritePerformance(map); //写入性能BigDecimal readTime = testReadPerformance(map); //读取性能System.out.println(map.getClass().getSimpleName()+"写入了"+map.size()+"对数据, 耗时"+writeTime+"ms, 读取"+COUNT/THREAD_COUNT+"次, 耗时"+readTime+"ms");}}}
运行结果:
Hashtable写入了10000000对数据, 耗时7.902ms, 读取20000次, 耗时3.688ms SynchronizedMap写入了10000000对数据, 耗时5.395ms, 读取20000次, 耗时1.952ms ConcurrentHashMap写入了10000000对数据, 耗时12.405ms, 读取20000次, 耗时0.31ms ConcurrentSkipListMap写入了10000000对数据, 耗时9.181ms, 读取20000次, 耗时6.06ms
1.2 为什么HashMap线程不安全?
因为JDK1.8时 HashMap在发生key冲突时超过8个,自动转化为红黑树, 假如多个线程操put同一个key,有的线程还在操作,其他线程已经在尝试转红黑树了。 这样会发生冲突。
1.3 跳表(SkipList)和 ConcurrentSkipListMap
1.3.1 什么是跳表
传统意义的单链表是一个线性结构,向有序的链表中插入一个节点需要O(n)的时间,查找操作需要O(n)的时间。
跳跃表的简单示例:
如果我们使用上图所示的跳跃表,就可以减少查找所需时间为O(n/2),因为我们可以先通过每个节点的最上面的指针先进行查找,这样子就能跳过一半的节点。
比如我们想查找19, 首先和6比较,大于6之后,在和9进行比较,然后在和17进行比较, 比较到21的时候,发现21大于19,说明查找的点在17和21之间,从这个过程中,我们可以看出,查找的时候跳过了3、7、12等点,因此查找的复杂度为O(n/2)。
查找的过程如下图:
其实,上面基本上就是跳跃表的思想,每一个结点不单单只包含指向下一个结点的指针,可能包含很多个指向后续结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。对于一个链表内每一个结点包含多少个指向后续元素的指针,后续节点个数是通过一个随机函数生成器得到,这样子就构成了一个跳跃表。
随机生成的跳跃表可能如下图所示:

跳跃表其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
“Skip lists are data structures that use probabilistic balancing rather than strictly enforced balancing. As a result, the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees. ”
译文:跳跃表使用概率均衡技术而不是使用强制性均衡技术,因此,对于插入和删除结点比传统上的平衡树算法更为简洁高效。
跳表是一种随机化的数据结构,目前开源软件 Redis 和 LevelDB 都有用到它。
跳跃的思想在其他地方也有应用,比如:内存对齐。
1.3.2 SkipList的操作
1.3.2.1 查找
查找就是给定一个key,查找这个key是否出现在跳跃表中,如果出现,则返回其值,如果不存在,则返回不存在。我们结合一个图就是讲解查找操作,如下图所示:
如果我们想查找19是否存在?如何查找呢?我们从头结点开始,首先和9进行判断,此时大于9,然后和21进行判断,小于21,此时这个值肯定在9结点和21结点之间,此时,我们和17进行判断,大于17,然后和21进行判断,小于21,此时肯定在17结点和21结点之间,此时和19进行判断,找到了。具体的示意图如图所示:
1.3.2.2 插入
插入包含如下几个操作:1、查找到需要插入的位置 2、申请新的结点 3、调整指针。
我们结合下图进行讲解,查找路径如下图的灰色的线所示 申请新的结点如17结点所示, 调整指向新结点17的指针以及17结点指向后续结点的指针。这里有一个小技巧,就是使用update数组保存大于17结点的位置,update数组的内容如红线所示,这些位置才是有可能更新指针的位置。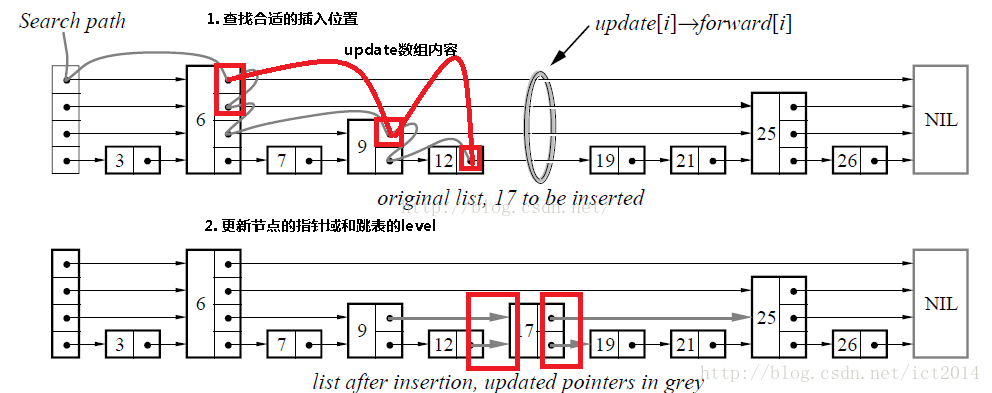
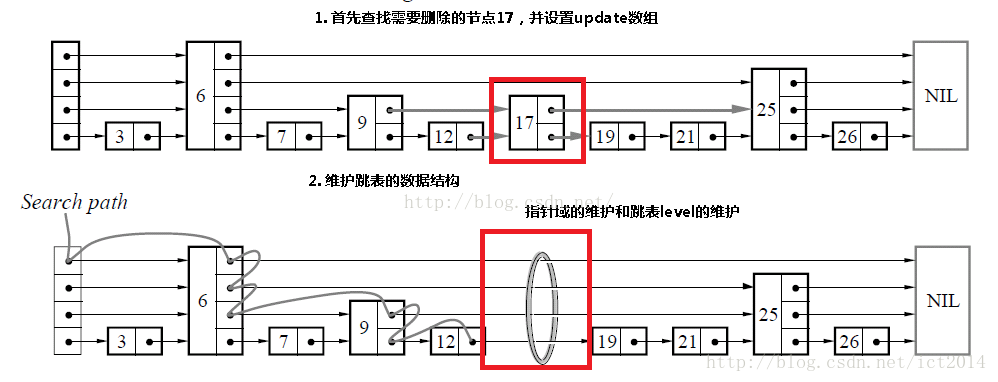
1.3.2.3 删除
删除操作类似于插入操作,包含如下3步:1、查找到需要删除的结点 2、删除结点 3、调整指针
1.3.3 Key-Value数据结构
目前常用的key-value数据结构有三种:Hash表、红黑树、SkipList,它们各自有着不同的优缺点(不考虑删除操作):
Hash表:插入、查找最快,为O(1);如使用链表实现则可实现无锁;数据有序化需要显式的排序操作。
红黑树:插入、查找为O(logn),但常数项较小;无锁实现的复杂性很高,一般需要加锁;数据天然有序。
SkipList:插入、查找为O(logn),但常数项比红黑树要大;底层结构为链表,可无锁实现;数据天然有序。
如果要实现一个key-value结构,需求的功能有插入、查找、迭代、修改,那么首先Hash表就不是很适合了,因为迭代的时间复杂度比较高;而红黑树的插入很可能会涉及多个结点的旋转、变色操作,因此需要在外层加锁,这无形中降低了它可能的并发度。而SkipList底层是用链表实现的,可以实现为lock free,同时它还有着不错的性能(单线程下只比红黑树略慢),非常适合用来实现我们需求的那种key-value结构。
LevelDB、Reddis的底层存储结构就是用的SkipList。
1.3.4 ConcurrentHashMap 类
JDK为我们提供了很多Map接口的实现,使得我们可以方便地处理Key-Value的数据结构。
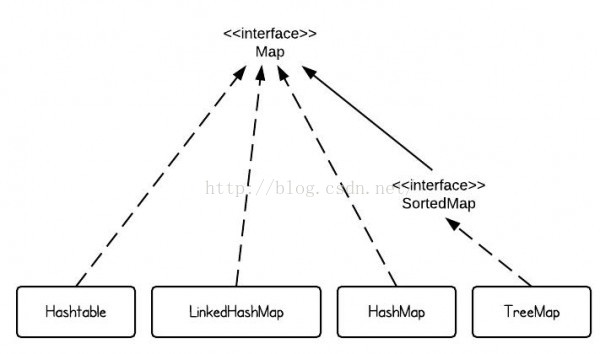
当我们希望快速存取HashMap。
当我们希望在多线程并发存取ConcurrentHashMap。
TreeMap则会帮助我们保证数据是按照Key的自然顺序或者compareTo方法指定的排序规则进行排序。
OK,那么当我们需要多线程并发存取
也许,我们可以选择ConcurrentTreeMap。不好意思,JDK没有提供这么好的数据结构给我们。
当然,我们可以自己添加lock来实现ConcurrentTreeMap,但是随着并发量的提升,lock带来的性能开销也随之增大。
Don’t cry……,JDK6里面引入的ConcurrentSkipListMap也许可以满足我们的需求
1.3.4.1 什么是ConcurrentSkipListMap
ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表。内部是SkipList(跳表)结构实现,在理论上能够O(log(n))时间内完成查找、插入、删除操作。
1.3.4.2 ConcurrentSkipListMap的存储结构
ConcurrentSkipListMap存储结构跳跃表(SkipList):
1、最底层的数据节点按照关键字升序排列。
2、包含多级索引,每个级别的索引节点按照其关联数据节点的关键字升序排列。
3、高级别索引是其低级别索引的子集。
4、如果关键字key在级别level=i的索引中出现,则级别level<=i的所有索引中都包含key。
2. Collection
2.1 List
2.1.1 List 集合性能测试
import java.math.BigDecimal;import java.util.*;import java.util.concurrent.CopyOnWriteArrayList;import java.util.concurrent.CountDownLatch;import java.util.stream.IntStream;/*** 启动500个线程, 每个线程向集合内写入/读取1000个随机double, 观察其写入和读取性能.*/public class TestListWriteAndReadPerformance {private static int COUNT = 1000; //集合内键值对总数private static int THREAD_COUNT = 500; //总线程数//待测试的集合private static List<List<Double>> testLists = new ArrayList<>();//填充static {testLists.add(new CopyOnWriteArrayList<>());// testLists.add(new ArrayList<>());testLists.add(Collections.synchronizedList(new ArrayList<Double>()));}/*** 测试写入性能* @param list* @return 方法执行耗时* @throws InterruptedException*/private static BigDecimal testWritePerformance(List list) throws InterruptedException {//设置门闩等到线程都执行完然后打印执行时间CountDownLatch countDownLatch = new CountDownLatch(THREAD_COUNT);Thread[] threads = new Thread[THREAD_COUNT];Random random = new Random();IntStream.range(0,THREAD_COUNT).forEach(e->{threads[e] = new Thread(()->{IntStream.range(0,COUNT).forEach(i->{list.add(random.nextDouble());});countDownLatch.countDown();});});//计时开始BigDecimal timeStarted = new BigDecimal(System.currentTimeMillis());//启动所有线程Arrays.asList(threads).forEach(Thread::start);//门栓等待所有线程执行完countDownLatch.await();//计时结束BigDecimal timeEnd = new BigDecimal(System.currentTimeMillis());return timeEnd.subtract(timeStarted).divide(new BigDecimal(1000));}/*** 测试读取性能* @param list* @return 方法执行耗时* @throws InterruptedException*/private static BigDecimal testReadPerformance(List list) throws InterruptedException {//设置门闩等到线程都执行完然后打印执行时间CountDownLatch countDownLatch = new CountDownLatch(THREAD_COUNT);Thread[] threads = new Thread[THREAD_COUNT];Random random = new Random();IntStream.range(0,THREAD_COUNT).forEach(e->{threads[e] = new Thread(()->{IntStream.range(0,COUNT).forEach(i->{list.get(i);});countDownLatch.countDown();});});//计时开始BigDecimal timeStarted = new BigDecimal(System.currentTimeMillis());//启动所有线程Arrays.asList(threads).forEach(Thread::start);//门栓等待所有线程执行完countDownLatch.await();//计时结束BigDecimal timeEnd = new BigDecimal(System.currentTimeMillis());return timeEnd.subtract(timeStarted).divide(new BigDecimal(1000));}public static void main(String[] args) throws InterruptedException {for (List<Double> list : testLists) {BigDecimal writeTime = testWritePerformance(list); //写入性能BigDecimal readTime = testReadPerformance(list); //读取性能System.out.println(list.getClass().getName()+"写入"+list.size()+"条数据, 耗时"+writeTime+"s, 读取"+list.size()+"条数据, 耗时"+readTime+"s");}}}
java.util.concurrent.CopyOnWriteArrayList写入500000条数据, 耗时81.575s, 读取500000条数据, 耗时0.039s java.util.Collections$SynchronizedRandomAccessList写入500000条数据, 耗时0.102s, 读取500000条数据, 耗时0.043s
2.1.2 从一个售票业务说起
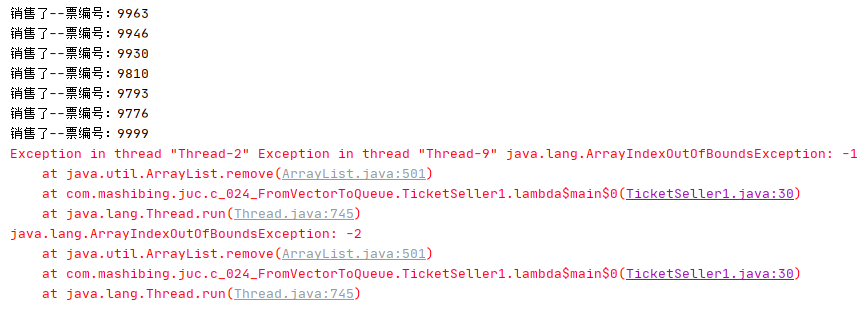
有N张火车票,每张票都有一个编号。 同时有10个窗口对外售票。 请写一个模拟程序。 分析下面的程序可能会产生哪些问题?重复销售?超量销售?
import java.util.*;import java.util.concurrent.ConcurrentLinkedQueue;/*** 有100000张火车票,每张票都有一个编号* 同时有10个窗口对外售票* 请写一个模拟程序** 分析下面的程序可能会产生哪些问题?* 重复销售?超量销售?*/public class TicketSeller {private static int COUNT = 100000; //总票数private static int THREAD_COUNT = 10; //总线程数/*** 售票* @param list*/static void sale(List list){for (int i = 0; i < THREAD_COUNT; i++) {new Thread(()->{while(list.size() > 0) {System.out.println("销售了--" + list.remove(0));}}).start();}}/*** 售票* @param queue*/static void sale(Queue queue){for (int i = 0; i < THREAD_COUNT; i++) {new Thread(()->{while(true) {String s = (String) queue.poll();if(s == null) break;else System.out.println("销售了--" + s);}}).start();}}public static void main(String[] args) {//ArrayListList<String> arrayListtickets = new ArrayList<>();//填满1W张票for(int i = 0; i< COUNT; i++) arrayListtickets.add("票编号:" + i);//售票//sale(arrayListtickets);//VectorVector<String> vertorTickets = new Vector<>();//填满1W张票for(int i = 0; i< COUNT; i++) vertorTickets.add("票编号:" + i);//售票// sale(vertorTickets);//LinkedListList<String> linkedListtickets = new LinkedList<>();//填满1W张票for(int i = 0; i< COUNT; i++) linkedListtickets.add("票编号:" + i);//售票// sale(linkedListtickets);//QueueQueue<String> queueTickets = new ConcurrentLinkedQueue<>();//填满1W张票for(int i = 0; i< COUNT; i++) queueTickets.add("票编号:" + i);sale(queueTickets);}}
运行结果:
2.1.3 CopyOnWriteArrayList
写入时复制(CopyOnWrite,简称COW)思想是计算机程序设计领域中的一种优化策略。其核心思想是,如果有多个调用者(Callers)同时要求相同的资源(如内存或者是磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者视图修改资源内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。此做法主要的优点是如果调用者没有修改资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
CopyOnWrite的缺点
- 内存占用问题
- 数据一致性问题:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的数据能马上能读到,请不要使用CopyOnWrite容器。
- 写入时性能极低,极低,极低!!!
CopyOnWrite的应用场景**
CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新的场景,假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单每天晚上更新一次。当用户搜索时,会检查当前关键字在不在黑名单当中,如果在,则提示不能搜索。
2.1.4 synchronizedList
2.2 Queue
2.2.1. ConcurrentLinkedQueue
ConcurrentLinkedQueue 从名字上就可以看出它是一个线程安全的 链表结构 队列, 而且它是一个无界队列。
ConcurrentLinkedQueue 的非阻塞算法实现可概括为下面 5 点:
- 使用 CAS 原子指令来处理对数据的并发访问,这是非阻塞算法得以实现的基础。
- head/tail 并非总是指向队列的头 / 尾节点,也就是说允许队列处于不一致状态。 这个特性把入队 / 出队时,原本需要一起原子化执行的两个步骤分离开来,从而缩小了入队 / 出队时需要原子化更新值的范围到唯一变量。这是非阻塞算法得以实现的关键。
- 由于队列有时会处于不一致状态。为此,ConcurrentLinkedQueue 使用三个不变式来维护非阻塞算法的正确性。
- 以批处理方式来更新 head/tail,从整体上减少入队 / 出队操作的开销。
- 为了有利于垃圾收集,队列使用特有的 head 更新机制;为了确保从已删除节点向后遍历,可到达所有的非删除节点,队列使用了特有的向后推进策略。
2.2.2. BlockingQueue
BlockingQueue即阻塞队列,它是基于ReentrantLock,依据它的基本原理,我们可以实现Web中的长连接聊天功能,当然其最常用的还是用于实现生产者与消费者模式,大致如下图所示: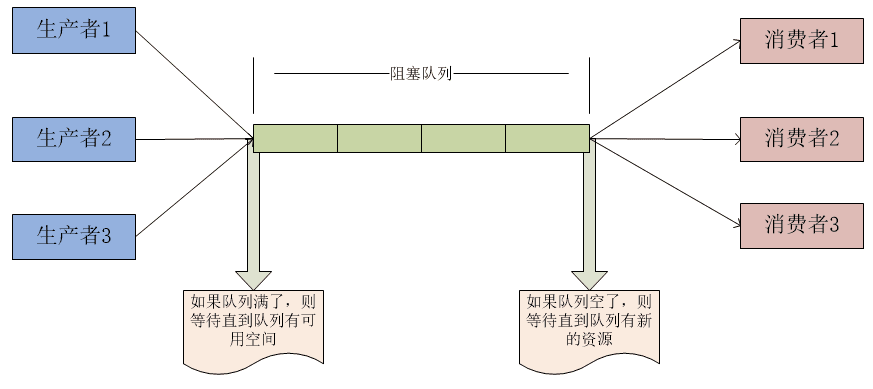
在Java中,
BlockingQueue是一个接口,它的实现类有ArrayBlockingQueue、DelayQueue、LinkedBlockingDeque、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue等,它们的区别主要体现在存储结构上或对元素操作上的不同,但是对于take与put操作的原理,却是类似的。
BlockingQueue**入队操作**
//入队不阻塞boolean offer(E e);//入队阻塞-如果队列满了,一直阻塞,直到队列不满了或者线程被中断-->阻塞void put(E e) throws InterruptedException;/*** 在队尾插入一个元素,,如果队列已满,则进入等待,直到出现以下三种情况* 1. 阻塞被唤醒* 2. 等待时间超时* 3. 当前线程被中断*/boolean offer(E e, long timeout, TimeUnit unit)throws InterruptedException;
BlockingQueue**出队操作**
//不阻塞出队:如果没有元素,直接返回null;如果有元素,出队E poll();//阻塞出队:如果队列空了,一直阻塞,直到队列不为空或者线程被中断-->阻塞E take() throws InterruptedException;/*** 如果队列不空,出队;如果队列已空且已经超时,返回null;* 如果队列已空且时间未超时,则进入等待,直到出现以下三种情况:* 1. 被唤醒* 2. 等待时间超时* 3. 当前线程被中断*/E poll(long timeout, TimeUnit unit)throws InterruptedException;
2.2.2.1 LinkedBlockingQueue
LinkedBlockingQueue是一个基于链表实现的可选容量的阻塞队列。队头的元素是插入时间最长的,队尾的元素是最新插入的。新的元素将会被插入到队列的尾部。
LinkedBlockingQueue的容量限制是可选的,如果在初始化时没有指定容量,那么默认使用int的最大值作为队列容量。
LinkedBlockingQueue内部是使用链表实现一个队列的,但是却有别于一般的队列,在于该队列至少有一个节点,头节点不含有元素。
LinkedBlockingQueue中维持两把锁,一把锁用于入队,一把锁用于出队,这也就意味着,同一时刻,只能有一个线程执行入队,其余执行入队的线程将会被阻塞;同时,可以有另一个线程执行出队,其余执行出队的线程将会被阻塞。换句话说,虽然入队和出队两个操作同时均只能有一个线程操作,但是可以一个入队线程和一个出队线程共同执行,也就意味着可能同时有两个线程在操作队列,那么为了维持线程安全,LinkedBlockingQueue使用一个AtomicInterger类型的变量表示当前队列中含有的元素个数,所以可以确保两个线程之间操作底层队列是线程安全的。
2.2.2.2 ArrayBlockingQueue
ArrayBlockingQueue底层是使用一个数组实现队列的,并且在构造ArrayBlockingQueue时需要指定容量,也就意味着底层数组一旦创建了,容量就不能改变了,因此ArrayBlockingQueue是一个容量限制的阻塞队列。因此,在队列全满时执行入队将会阻塞,在队列为空时出队同样将会阻塞。
ArrayBlockingQueue的并发阻塞是通过ReentrantLock和Condition来实现的,ArrayBlockingQueue内部只有一把锁,意味着同一时刻只有一个线程能进行入队或者出队的操作。
2.2.2.3 DelayQueue
DelayQueue是一个无界的BlockingQueue,用于放置实现了Delayed接口的对象,其中的对象只能在其到期时才能从队列中取走。这种队列是有序的,即队头对象的延迟到期时间最长。注意:不能将null元素放置到这种队列中。
DelayQueue只能添加(offer/put/add)实现了Delayed接口的对象,意思是说我们不能想往DelayQueue里添加什么就添加什么,不能添加int、也不能添加String进去,必须添加我们自己的实现了Delayed接口的类的对象:
import lombok.Data;import lombok.ToString;import lombok.experimental.Accessors;import java.util.concurrent.DelayQueue;import java.util.concurrent.Delayed;import java.util.concurrent.TimeUnit;public class DelayQueueExample {public static void main(String[] args) throws InterruptedException {//创建延迟阻塞队列DelayQueue<MyDelayedTask> delayQueue = new DelayQueue<>();//新线程往队列里面插入不同执行时间的任务new Thread(()->{delayQueue.offer(new MyDelayedTask().setName("task1").setTime(10000));delayQueue.offer(new MyDelayedTask().setName("task2").setTime(3900));delayQueue.offer(new MyDelayedTask().setName("task3").setTime(1900));delayQueue.offer(new MyDelayedTask().setName("task4").setTime(5900));delayQueue.offer(new MyDelayedTask().setName("task5").setTime(6900));delayQueue.offer(new MyDelayedTask().setName("task6").setTime(7900));delayQueue.offer(new MyDelayedTask().setName("task7").setTime(4900));}).start();//不断从队列里面取出任务while (true){System.out.println(delayQueue.take());}}//实现Delayed接口。@Data@Accessors(chain = true)@ToStringprivate static class MyDelayedTask implements Delayed{private String name;private long start = System.currentTimeMillis();private long time;/*** 需要实现的接口,获得延迟时间 用过期时间-当前时间* @param timeUnit* @return*/@Overridepublic long getDelay(TimeUnit timeUnit) {return timeUnit.convert((start+time) - System.currentTimeMillis(),TimeUnit.MILLISECONDS);}/*** 用于延迟队列内部比较排序 当前时间的延迟时间 - 比较对象的延迟时间* @param delayed* @return*/@Overridepublic int compareTo(Delayed delayed) {MyDelayedTask myDelayedTask = (MyDelayedTask) delayed;return (int) (this.getDelay(TimeUnit.MILLISECONDS) - delayed.getDelay(TimeUnit.MILLISECONDS));}}}
执行结果:
DelayQueueExample.MyDelayedTask(name=task3, start=1609600175055, time=1900) DelayQueueExample.MyDelayedTask(name=task2, start=1609600175055, time=3900) DelayQueueExample.MyDelayedTask(name=task7, start=1609600175055, time=4900) DelayQueueExample.MyDelayedTask(name=task4, start=1609600175055, time=5900) DelayQueueExample.MyDelayedTask(name=task5, start=1609600175055, time=6900) DelayQueueExample.MyDelayedTask(name=task6, start=1609600175055, time=7900) DelayQueueExample.MyDelayedTask(name=task1, start=1609600175055, time=10000)
DelayQueue应用场景:**
- 淘宝订单业务:下单之后如果三十分钟之内没有付款就自动取消订单。
- 饿了吗订餐通知:下单成功后60s之后给用户发送短信通知。
- 关闭空闲连接。服务器中,有很多客户端的连接,空闲一段时间之后需要关闭之。
- 缓存。缓存中的对象,超过了空闲时间,需要从缓存中移出。
- 任务超时处理。在网络协议滑动窗口请求应答式交互时,处理超时未响应的请求等。
2.2.2.4 SynchronousQueue
SynchronousQueue是一个比较特别的队列,它的目的在于两个线程之间的通讯。而不是业务上的通讯。SynchronousQueue是一个经典的生产者消费者的实现,SynchronousQueue里面没有缓冲区, 或者可以理解为只能存储一个元素的位置,所以, 一个线程向SynchronousQueue放入元素,另一个SynchronousQueue线程必须取出这个元素,其他线程才能继续往里面放。反之亦然。由于SynchronousQueue实现了BlockingQueue,所以它的take和put都是阻塞操作。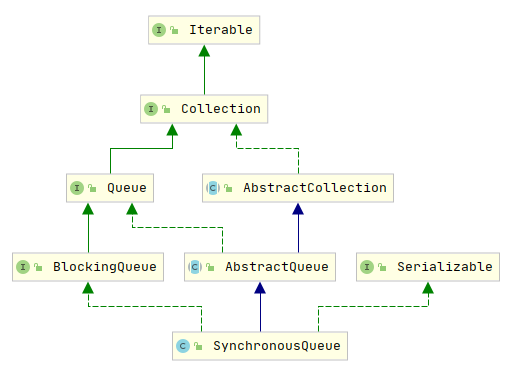
import java.util.Scanner;import java.util.concurrent.BlockingQueue;import java.util.concurrent.SynchronousQueue;public class SynchronusQueue {public static void main(String[] args){BlockingQueue<String> strs = new SynchronousQueue<>();Thread t1 = new Thread(()->{try {String currentName = Thread.currentThread().getName();while (true){System.out.println("线程"+currentName+"取出数据: "+strs.take());}} catch (InterruptedException e) {e.printStackTrace();}},"t1");Thread t2 = new Thread(()->{String currentName = Thread.currentThread().getName();String str = null;;Scanner scanner = new Scanner(System.in);while (!"end".equals(str = scanner.nextLine())){try {System.out.println("线程"+currentName+"放入数据: "+str);strs.put(str);} catch (InterruptedException e) {e.printStackTrace();}}},"t2");t1.start();t2.start();}}
运行结果:
111 线程t2放入数据: 111 线程t1取出数据: 111 222 线程t2放入数据: 222 线程t1取出数据: 222 333 线程t2放入数据: 333 线程t1取出数据: 333 444 线程t2放入数据: 444 线程t1取出数据: 444 555 线程t2放入数据: 555
线程t1取出数据: 555
2.2.2.5 TransferQueue
我们知道 SynchronousQueue 内部无法存储元素,当要添加元素的时候,需要阻塞,不够完美,LinkedBolckingQueue 则内部使用了大量的锁,性能不高。
两两结合,岂不完美?性能又高,又不阻塞。有! TransferQueue!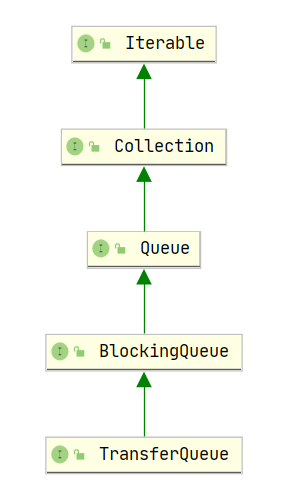
TransferQueue的主要方法解析:
public interface TransferQueue<E> extends BlockingQueue<E> {// 如果可能,立即将元素转移给等待的消费者。// 更确切地说,如果存在消费者已经等待接收它(在 take 或 timed poll(long,TimeUnit)poll)中,则立即传送指定的元素,否则返回 false。boolean tryTransfer(E e);// 将元素转移给消费者,如果需要的话等待。// 更准确地说,如果存在一个消费者已经等待接收它(在 take 或timed poll(long,TimeUnit)poll)中,则立即传送指定的元素,否则等待直到元素由消费者接收。void transfer(E e) throws InterruptedException;// 上面方法的基础上设置超时时间boolean tryTransfer(E e, long timeout, TimeUnit unit) throws InterruptedException;// 如果至少有一位消费者在等待,则返回 trueboolean hasWaitingConsumer();// 返回等待消费者人数的估计值int getWaitingConsumerCount();}
LinkedTransferQueue是 SynchronousQueue 和 LinkedBlockingQueue 的合体,性能比 LinkedBlockingQueue 更高(没有锁操作),比 SynchronousQueue能存储更多的元素。
当 put 时,如果有等待的线程,就直接将元素 “交给” 等待者, 否则直接进入队列。put和 transfer 方法的区别是,put 是立即返回的, transfer 是阻塞等待消费者拿到数据才返回。transfer方法和 SynchronousQueue的 put 方法类似。
2.2.3 PriorityQueue
PriorityQueue是基于优先堆的一个无界队列,这个优先队列中的元素可以默认自然排序或者通过提供的Comparator(比较器)在队列实例化的时排序。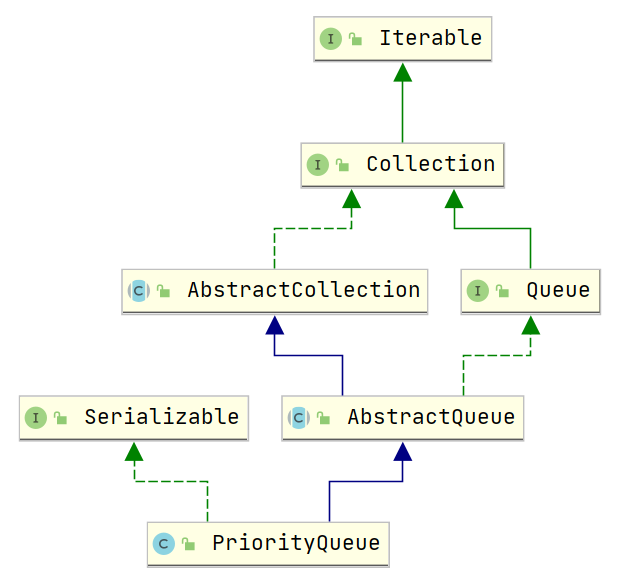
优先队列不允许空值,而且不支持non-comparable(不可比较)的对象,比如用户自定义的类。优先队列要求使用Java Comparable和Comparator接口给对象排序,并且在排序时会按照优先级处理其中的元素。
优先队列的头是基于自然排序或者Comparator排序的最小元素。如果有多个对象拥有同样的排序,那么就可能随机地取其中任意一个。当我们获取队列时,返回队列的头对象。
优先队列的大小是不受限制的,但在创建时可以指定初始大小。当我们向优先队列增加元素的时候,队列大小会自动增加。
PriorityQueue是非线程安全的,所以Java提供了PriorityBlockingQueue(实现BlockingQueue接口)用于Java多线程环境。
import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import lombok.ToString;import java.util.Comparator;import java.util.PriorityQueue;import java.util.Queue;import java.util.Random;public class PriorityQueueExample {private static int queueLength = new Random().nextInt(20);public static void main(String[] args) {//优先队列自然排序示例Queue<Integer> integerPriorityQueue = new PriorityQueue<>(queueLength);//填充Random random = new Random();for (int i = 0; i < queueLength; i++) {integerPriorityQueue.add(random.nextInt(100));}//打印for (int i = 0; i < queueLength; i++) {System.out.print(integerPriorityQueue.poll()+" ");}System.out.println();//优先队列使用示例Queue<Person> personPriorityQueue = new PriorityQueue<Person>(queueLength, idComparator);//填充for(int i=0;i<queueLength;i++){int age = random.nextInt(100);String name = "名字"+age;personPriorityQueue.add(new Person(age,name));}//打印for (int i = 0; i < queueLength; i++) {System.out.println(personPriorityQueue.poll());}}//匿名Comparator实现public static Comparator<Person> idComparator = new Comparator<Person>(){@Overridepublic int compare(Person p1, Person p2) {return p1.getAge()-p2.getAge();}};@Data@AllArgsConstructor@NoArgsConstructor@ToStringprivate static class Person{private int age;private String name;}}
结果:
3 4 11 11 30 51 63 79 81 95 PriorityQueueExample.Person(age=4, name=名字4) PriorityQueueExample.Person(age=8, name=名字8) PriorityQueueExample.Person(age=10, name=名字10) PriorityQueueExample.Person(age=30, name=名字30) PriorityQueueExample.Person(age=30, name=名字30) PriorityQueueExample.Person(age=54, name=名字54) PriorityQueueExample.Person(age=67, name=名字67) PriorityQueueExample.Person(age=71, name=名字71) PriorityQueueExample.Person(age=73, name=名字73) PriorityQueueExample.Person(age=83, name=名字83)

若有收获,就点个赞吧
0 人点赞
