1. 原因原理
CPU发生指令重排序的原因主要是因为CPU的运行速度远远高于其他设备。 大概CPU的运行速度是内存的100倍。 时硬盘的1000000倍。 假如说。CPU要从硬盘读取一个数据,那么CPU发出读取指令后就会一直等待很长很长时间,CPU只能在那干等,其实等待的这个时间CPU可以做很多事情。 所以会有指令重排序的出现。就是CPU自己认为不相干的两条指令,他可以打乱执行列表的顺序来执行。已达到提高执行效率的目的。
比如说下面的指令列表:
- 读取内存数据到变量A上
- 将读取到的A+1
- 计算1+2的结果
- 计算3+4的结果
发生指令重排序之后的顺序可能是这样的:
- 读取内存数据到 A上
- 计算1+2的结果
- 计算3+4的结果
- 将读取到的A+1
需要的注意的是:只有CPU自己认为是两条不相干的指令才会发生重排序,假若第二条指令需要第一条指令的结果那个就不会发生指令重排序。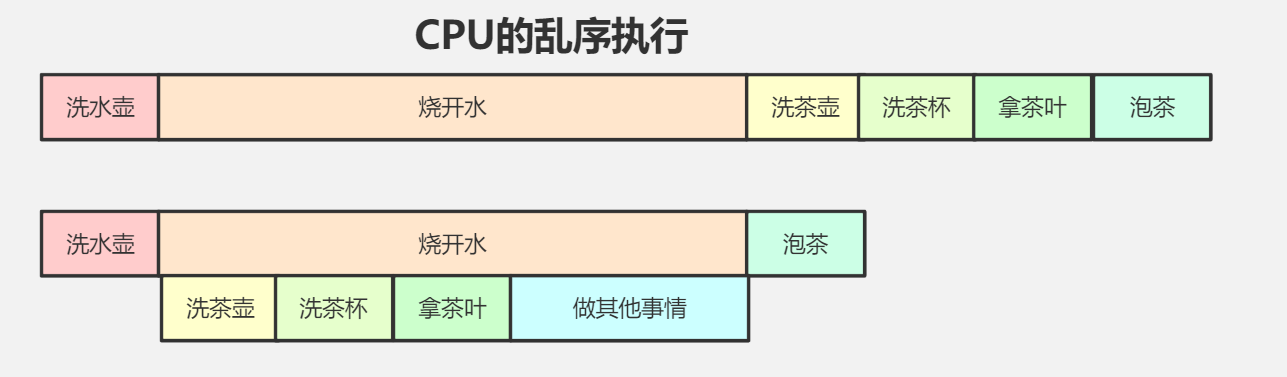
2. 乱序执行的证明
public class Disorder {private static int x = 0, y = 0;private static int a = 0, b =0;public static void main(String[] args) throws InterruptedException {int i = 0;for(;;) {i++;x = 0; y = 0;a = 0; b = 0;Thread one = new Thread(new Runnable() {public void run() {//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.//shortWait(100000);a = 1;x = b;}});Thread other = new Thread(new Runnable() {public void run() {b = 1;y = a;}});one.start(); other.start();one.join(); other.join();if(x == 0 && y == 0) {String result = "第" + i + "次 (" + x + "," + y + ")";System.err.println(result);break;}}}}
3. 禁止CPU乱序执行
3.1 CPU层面禁止
Intel的CPU使用CPU原语(mfence lfence sfence) 或者锁总线sfence(save fence) : 写屏障,sfence 前的写操作指令必须在sfence 后的写操作指令之前完成。lfence(load fence) : 读屏障,lfence 前读操作的指令必须在lfence 后的读操作指令之前完成。mfence(save fence) : 读写屏障,mfence 的读写指令必须在mfence 后的读写指令之前完成。
3.2 汇编层面禁止
LOCK指令前缀会设置处理器的LOCK#信号(译注:这个信号会使总线锁定,阻止其他处理器接管总线访问内存),直到使用LOCK前缀的指令执行结束,这会使这条指令的执行变为原子操作。在多处理器环境下,设置LOCK#信号能保证某个处理器对共享内存的独占使用。
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
3.3 JVM层面禁止
8个hanppens-before原则
4个内存屏障 (LL LS SL SS)
as-if-serial : 不管硬件什么顺序,单线程执行的结果不变,看上去像是serial
JVM级别如何规范(JSR133)
LoadLoad屏障: 对于这样的语句Load1; LoadLoad; Load2 在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障: 对于这样的语句Store1; StoreStore; Store2 在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障: 对于这样的语句Load1; LoadStore; Store2 在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障: 对于这样的语句Store1; StoreLoad; Load2 在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
volatile的实现细节:
- 字节码层面使用了JVM的指令:
ACC_VOLATILE - JVM层面 volatile内存区的读写操作前后都加了屏障指令。
StoreStoreBarrier屏障 volatile 写操作 StoreLoadBarrier屏障
LoadLoadBarrier屏障 volatile 读操作 LoadStoreBarrier屏障
对于OC来讲,JVM再复杂也只是一个应用程序,所以不管JVM如何实现内存屏障,都要依赖于底层的内存屏障(OS+汇编+硬件)实现。

若有收获,就点个赞吧
0 人点赞
