1. Callable
有两种创建线程的方法-一种是通过创建Thread类,另一种是通过使用Runnable创建线程。但是,Runnable缺少的一项功能是,当线程终止时(即run() 完成时),我们无法使线程返回结果。为了支持此功能,Java中提供了Callable接口。
- 为了实现Runnable,需要实现不返回任何内容的run() 方法,而对于
Callable,需要实现在完成时返回结果的call() 方法。请注意,不能使用Callable创建线程,只能使用Runnable创建线程。 - 另一个区别是call() 方法可以引发异常,而run() 则不能。
- 为实现Callable而必须重写call方法。
import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import lombok.SneakyThrows;import java.text.SimpleDateFormat;import java.util.ArrayList;import java.util.Date;import java.util.List;import java.util.Random;import java.util.concurrent.*;/*** 启动11个线程, 10个线程计算从0至100的累加和,第11个线程计算10个线程的结果和并输出。* 请使用Callable和Thread分别实现*/public class CallableAndThread {public static void main(String[] args) throws InterruptedException, ExecutionException {System.out.println(new CallableExample().test());System.out.println(new ThreadExample().test());}}/*** CallableExample*/class CallableExample{/*** 使用Executors.newFixedThreadPool创建线程池* @return* @throws ExecutionException* @throws InterruptedException*/public int test() throws ExecutionException, InterruptedException {//线程池内线程数量int TASK_COUNT = 10;//线程池存储线程ExecutorService pool = Executors.newFixedThreadPool(TASK_COUNT);//结果集收集结果List<Future<Integer>> resultFutureList = new ArrayList<Future<Integer>>();//执行线程,收集结果for (int i = 0; i < TASK_COUNT; i++) {MyCallable myCallable = new MyCallable("线程"+i);Future<Integer> future = pool.submit(myCallable);resultFutureList.add(future);}//计算总和Future<Integer> sumFuture =pool.submit(new Callable<Integer>() {@Overridepublic Integer call() throws Exception {int sum = 0;for (int i = 0; i < TASK_COUNT; sum += resultFutureList.get(i).get(), i++);return sum;}});//线程池关闭pool.shutdown();return sumFuture.get();}/*** 实现Callable接口*/@Data@AllArgsConstructor@NoArgsConstructorprivate static class MyCallable implements Callable<Integer>{//线程名称private String threadName;@Overridepublic Integer call() throws Exception {Random random = new Random();int sleepTimes = random.nextInt(10);System.out.println(threadName+"睡眠"+sleepTimes+"秒..., 当前时间"+ new SimpleDateFormat("HH:mm:ss").format(new Date()));TimeUnit.SECONDS.sleep(sleepTimes);Integer sum = 0;for (int i = 0; i <= 100; sum += i, i++);System.out.println(threadName+"计算结果"+sum+",完成时间:"+new SimpleDateFormat("HH:mm:ss").format(new Date()));return sum;}}}/*** ThreadExample*/class ThreadExample{/*** 线程直接使用new Thread来创建* @return*/public int test() throws InterruptedException {int THREAD_COUNT = 10;MyRunnable[] myRunnables = new MyRunnable[THREAD_COUNT];for (int i = 0; i < THREAD_COUNT; i++) {myRunnables[i] = new MyRunnable();new Thread(myRunnables[i],"线程"+i).start();}//收集结果int sum = 0;for (int i = 0; i < THREAD_COUNT; sum += myRunnables[i].get().intValue(), i++);return sum;}/*** 实现Runnable*/@Datapublic static class MyRunnable implements Runnable{private Integer sum = 0;@SneakyThrows@Overridepublic void run() {Random random = new Random();int sleepTimes = random.nextInt(10);System.out.println(Thread.currentThread().getName()+"睡眠"+sleepTimes+"秒..., 当前时间"+ new SimpleDateFormat("HH:mm:ss").format(new Date()));TimeUnit.SECONDS.sleep(sleepTimes);for (int i = 0; i <= 100; this.sum += i, i++);System.out.println(Thread.currentThread().getName()+"计算结果"+sum+",完成时间:"+new SimpleDateFormat("HH:mm:ss").format(new Date()));//唤醒其他线程synchronized(this){notifyAll();}}/*** 同步方法获取结果值* @return* @throws InterruptedException*/public synchronized Integer get() throws InterruptedException {while (this.sum == 0){wait();}return this.sum;}}}
Callable 与Thread的区别:
- 最大的区别是Callable有返回值,而Thread没有。
- Callable必须配合线程池和Future类使用。Thread不需要,它自己可以单独使用。
- Callable不能创建线程,但是Thread可以。
说到底: Callable就是为了线程池准备的,而Thread就是为了独立运行使用。
2. CompletableFuture
import lombok.AllArgsConstructor;import lombok.Data;import lombok.ToString;import java.util.ArrayList;import java.util.Collections;import java.util.List;import java.util.Random;import java.util.concurrent.CompletableFuture;import java.util.concurrent.TimeUnit;/*** 假设你能提供这样一种服务:* 给你一个渠道列表, 里面包含各种电商的渠道, 你要从这些渠道里面获取某个商品的价格,然后找出最低的价格打印出来。*/public class CompletableFutureDemo {//渠道列表private static List<Channel> channelList = Collections.synchronizedList(new ArrayList<>());static {channelList.add(new Channel("淘宝",1.00));channelList.add(new Channel("天猫",2.00));channelList.add(new Channel("拼多多",3.00));channelList.add(new Channel("美团",4.00));}/*** 随机睡眠一段时间,模拟网络请求爬取数据*/private static void delay() throws InterruptedException {int delayTime = new Random().nextInt(5000);TimeUnit.MILLISECONDS.sleep(delayTime);System.out.println("线程睡眠了"+delayTime+"毫秒");}public static void main(String[] args) {long start = System.currentTimeMillis();CompletableFuture<Double>[] completableFutures = new CompletableFuture[channelList.size()];for (int i = 0; i < channelList.size(); i++) {int j = i;completableFutures[i] = CompletableFuture.supplyAsync(() -> {try {delay();} catch (InterruptedException e) {e.printStackTrace();}return channelList.get(j).getPrice();});}CompletableFuture.allOf(completableFutures).join();long end = System.currentTimeMillis();System.out.println("耗时"+(end-start)+"毫秒");}/*** 渠道类*/@Data@AllArgsConstructor@ToStringprivate static class Channel{private String name; //渠道名字private Double price; //商品在该渠道内的价格}}
3. ThreadPoolExecutor
3.1 ThreadPoolExecutor 继承结构
3.2 ThreadPoolExecutor 的7个构造参数
/*** Creates a new {@code ThreadPoolExecutor} with the given initial* parameters.** @param corePoolSize the number of threads to keep in the pool, even* if they are idle, unless {@code allowCoreThreadTimeOut} is set* 核心线程数量:* @param maximumPoolSize the maximum number of threads to allow in the* pool* 最大线程数量:* @param keepAliveTime when the number of threads is greater than* the core, this is the maximum time that excess idle threads* will wait for new tasks before terminating.* 超时时间:线程池内不是核心线程的线程运行完毕后的等待时间, 超出后自行销毁。* @param unit the time unit for the {@code keepAliveTime} argument* 超时时间单位:* @param workQueue the queue to use for holding tasks before they are* executed. This queue will hold only the {@code Runnable}* tasks submitted by the {@code execute} method.* 工作队列: 必须是阻塞队列* @param threadFactory the factory to use when the executor* creates a new thread* 线程工厂:JDK自带默认Executors.defaultThreadFactory()* @param handler the handler to use when execution is blocked* because the thread bounds and queue capacities are reached* 拒绝策略:JDK自带4个拒绝策略,默认为Abort抛异常策略* @throws IllegalArgumentException if one of the following holds:<br>* {@code corePoolSize < 0}<br>* {@code keepAliveTime < 0}<br>* {@code maximumPoolSize <= 0}<br>* {@code maximumPoolSize < corePoolSize}* @throws NullPointerException if {@code workQueue}* or {@code threadFactory} or {@code handler} is null*/public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
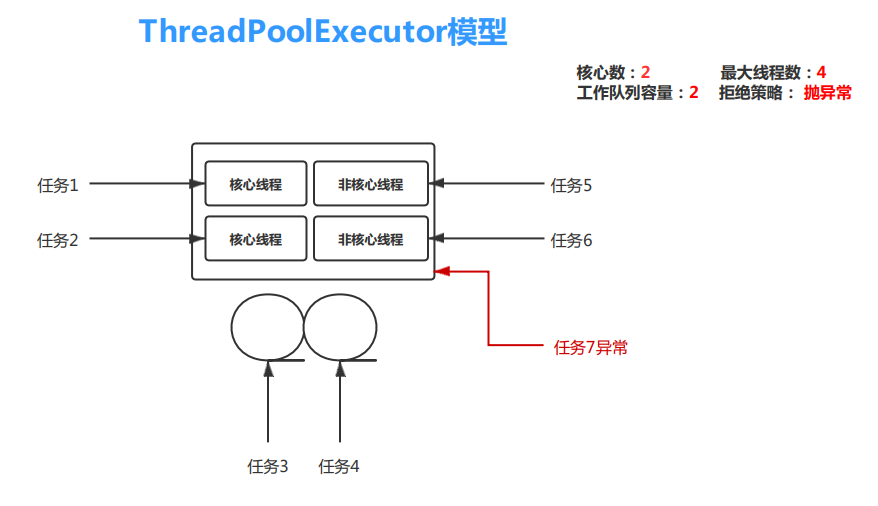
3.3 ThreadPoolExecutor 模型
3.4 ThreadPoolExecutor 的4个特性
import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;public class ThreadPoolExecutorDemo {/*** 特性1: 如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队*/private static void test1() throws InterruptedException {//核心线程2个, 最大线程3个, 超时60秒,工作队列容量1,ThreadPoolExecutor pool = new ThreadPoolExecutor(2,3,60L, TimeUnit.SECONDS,new ArrayBlockingQueue<>(1));pool.execute(()->run("任务1",0,TimeUnit.SECONDS)); //执行任务1TimeUnit.SECONDS.sleep(2); //主线程睡眠2秒,保证线程1先执行完pool.execute(()->run("任务2",0,TimeUnit.SECONDS)); //执行任务2pool.shutdown(); //关闭线程池System.out.println("特性1: 如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队");}/*** 特性2: 当池中正在运行的线程数大于等于corePoolSize时,新插入的任务进入workQueue排队(如果workQueue长度允许),等待空闲线程来执行。*/private static void test2() throws InterruptedException {//核心线程2个, 最大线程3个, 超时60秒,工作队列容量1,ThreadPoolExecutor pool = new ThreadPoolExecutor(2,3,60L, TimeUnit.SECONDS,new ArrayBlockingQueue<>(1));pool.execute(()->run("任务1",2,TimeUnit.SECONDS)); //执行任务1pool.execute(()->run("任务2",2,TimeUnit.SECONDS)); //执行任务2pool.execute(()->run("任务3",0,TimeUnit.SECONDS)); //执行任务3pool.shutdown();//关闭线程池//从实验结果上看,任务3会等待任务2执行完之后,有了空闲线程,才会执行。并没有新建线程执行任务3,这时maximumPoolSize=3这个参数不起作用。System.out.println("特性2: 当池中正在运行的线程数大于等于corePoolSize时,新插入的任务进入workQueue排队(如果workQueue长度允许),等待空闲线程来执行。");}/*** 特性3: 当队列里的任务数达到上限,并且池中正在运行的线程数小于maximumPoolSize,对于新加入的任务,新建线程。*/private static void test3() throws InterruptedException {//核心线程2个, 最大线程3个, 超时60秒,工作队列容量2ThreadPoolExecutor pool = new ThreadPoolExecutor(2,3,60L, TimeUnit.SECONDS,new ArrayBlockingQueue<>(2));pool.execute(()->run("任务1",5,TimeUnit.SECONDS)); //执行任务1pool.execute(()->run("任务2",5,TimeUnit.SECONDS)); //执行任务2pool.execute(()->run("任务3",0,TimeUnit.SECONDS)); //执行任务3pool.execute(()->run("任务4",0,TimeUnit.SECONDS)); //执行任务4pool.execute(()->run("任务5",0,TimeUnit.SECONDS)); //执行任务5pool.shutdown();//关闭线程池//当任务4进入队列时发现队列的长度已经到了上限,所以无法进入队列排队,而此时正在运行的线程数(2)小于maximumPoolSize所以新建线程执行该任务。//创建的新线程消费了队列里面所有任务System.out.println("特性3: 当队列里的任务数达到上限,并且池中正在运行的线程数小于maximumPoolSize,对于新加入的任务,新建线程。");}/*** 特性4:当队列里的任务数达到上限,并且池中正在运行的线程数等于maximumPoolSize,对于新加入的任务,执行拒绝策略(线程池默认的拒绝策略是抛异常)。*/private static void test4() throws InterruptedException {//核心线程2个, 最大线程3个, 超时60秒,工作队列容量1, 调用者执行策略。ThreadPoolExecutor pool = new ThreadPoolExecutor(2, 3, 60L, TimeUnit.SECONDS,new ArrayBlockingQueue<>(1),Executors.defaultThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy()); //调用者执行策略,溢出的任务由调用者(这里是main)执行。pool.execute(()->run("任务1",5,TimeUnit.SECONDS)); //执行任务1pool.execute(()->run("任务2",5,TimeUnit.SECONDS)); //执行任务2pool.execute(()->run("任务3",5,TimeUnit.SECONDS)); //执行任务3pool.execute(()->run("任务4",5,TimeUnit.SECONDS)); //执行任务4pool.execute(()->run("任务5",5,TimeUnit.SECONDS)); //执行任务5pool.shutdown();//当任务5加入时,队列达到上限,池内运行的线程数达到最大,故执行默认的拒绝策略,抛异常。System.out.println("特性4:当队列里的任务数达到上限,并且池中正在运行的线程数等于maximumPoolSize,对于新加入的任务,执行拒绝策略(线程池默认的拒绝策略是抛异常)。");}/*** 执行的任务* @param taskName 任务名称* @param sleepTime 睡眠时间* @param timeUnit 时间单位*/private static void run(String taskName,long sleepTime,TimeUnit timeUnit){try {timeUnit.sleep(sleepTime);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(taskName+",执行线程"+Thread.currentThread().getName());}public static void main(String[] args) throws InterruptedException {// System.out.println("测试特性1");// test1();// System.out.println();// System.out.println("测试特性2");// test2();// System.out.println("测试特性3");// test3();// System.out.println("测试特性4");// test4();}}
结果:
测试特性1 线程pool-1-thread-1执行任务1 线程pool-1-thread-2执行任务2 特性1: 如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队
测试特性2 特性2: 当池中正在运行的线程数大于等于corePoolSize时,新插入的任务进入workQueue排队(如果workQueue长度允许),等待空闲线程来执行。 线程pool-1-thread-2执行任务2 线程pool-1-thread-1执行任务1 线程pool-1-thread-2执行任务3
测试特性3 特性3: 当队列里的任务数达到上限,并且池中正在运行的线程数小于maximumPoolSize,对于新加入的任务,新建线程。 线程pool-1-thread-3执行任务5 线程pool-1-thread-3执行任务3 线程pool-1-thread-3执行任务4 线程pool-1-thread-1执行任务1 线程pool-1-thread-2执行任务2
测试特性4 线程pool-1-thread-2执行任务2 线程pool-1-thread-1执行任务1 线程pool-1-thread-3执行任务4 线程main执行任务5 特性4:当队列里的任务数达到上限,并且池中正在运行的线程数等于maximumPoolSize,对于新加入的任务,执行拒绝策略(线程池默认的拒绝策略是抛异常)。 线程pool-1-thread-2执行任务3
- 如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队
- 当池中正在运行的线程数大于等于corePoolSize时,新插入的任务进入workQueue排队(如果workQueue长度允许),等待空闲线程来执行。
- 当队列里的任务数达到上限,并且池中正在运行的线程数小于maximumPoolSize,对于新加入的任务,新建线程。
- 当队列里的任务数达到上限,并且池中正在运行的线程数小于maximumPoolSize,对于新加入的任务,新建线程。
由此可见:任务的分配顺序是:核心线程->队列->最大线程->拒绝策略。
3.5 ThreadPoolExecutor 拒绝策略
JDK默认提供4种拒绝策略:
new ThreadPoolExecutor.AbortPolicy(); //抛异常new ThreadPoolExecutor.CallerRunsPolicy(); //调用者处理任务new ThreadPoolExecutor.DiscardPolicy(); //直接扔掉new ThreadPoolExecutor.DiscardOldestPolicy(); //扔掉最老任务
自定义拒绝策略:
实现RejectedExecutionHandler接口
/*** 自定义拒绝策略*/public class MyRejectedExecutionHandler implements RejectedExecutionHandler {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {System.out.println("任务保存至kafka");}}
3.6 ThreadPoolExecutor 源码分析
1、常用变量的解释
// 1. `ctl`,可以看做一个int类型的数字,高3位表示线程池状态,低29位表示worker数量private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));// 2. `COUNT_BITS`,`Integer.SIZE`为32,所以`COUNT_BITS`为29private static final int COUNT_BITS = Integer.SIZE - 3;// 3. `CAPACITY`,线程池允许的最大线程数。1左移29位,然后减1,即为 2^29 - 1private static final int CAPACITY = (1 << COUNT_BITS) - 1;// runState is stored in the high-order bits// 4. 线程池有5种状态,按大小排序如下:RUNNING < SHUTDOWN < STOP < TIDYING < TERMINATEDprivate static final int RUNNING = -1 << COUNT_BITS;private static final int SHUTDOWN = 0 << COUNT_BITS;private static final int STOP = 1 << COUNT_BITS;private static final int TIDYING = 2 << COUNT_BITS;private static final int TERMINATED = 3 << COUNT_BITS;// Packing and unpacking ctl// 5. `runStateOf()`,获取线程池状态,通过按位与操作,低29位将全部变成0private static int runStateOf(int c) { return c & ~CAPACITY; }// 6. `workerCountOf()`,获取线程池worker数量,通过按位与操作,高3位将全部变成0private static int workerCountOf(int c) { return c & CAPACITY; }// 7. `ctlOf()`,根据线程池状态和线程池worker数量,生成ctl值private static int ctlOf(int rs, int wc) { return rs | wc; }/** Bit field accessors that don't require unpacking ctl.* These depend on the bit layout and on workerCount being never negative.*/// 8. `runStateLessThan()`,线程池状态小于xxprivate static boolean runStateLessThan(int c, int s) {return c < s;}// 9. `runStateAtLeast()`,线程池状态大于等于xxprivate static boolean runStateAtLeast(int c, int s) {return c >= s;}
2、构造方法
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {// 基本类型参数校验if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();// 空指针校验if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;// 根据传入参数`unit`和`keepAliveTime`,将存活时间转换为纳秒存到变量`keepAliveTime `中this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}
3、提交执行task的过程
public void execute(Runnable command) {if (command == null)throw new NullPointerException();/** Proceed in 3 steps:** 1. If fewer than corePoolSize threads are running, try to* start a new thread with the given command as its first* task. The call to addWorker atomically checks runState and* workerCount, and so prevents false alarms that would add* threads when it shouldn't, by returning false.** 2. If a task can be successfully queued, then we still need* to double-check whether we should have added a thread* (because existing ones died since last checking) or that* the pool shut down since entry into this method. So we* recheck state and if necessary roll back the enqueuing if* stopped, or start a new thread if there are none.** 3. If we cannot queue task, then we try to add a new* thread. If it fails, we know we are shut down or saturated* and so reject the task.*/int c = ctl.get();// worker数量比核心线程数小,直接创建worker执行任务if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}// worker数量超过核心线程数,任务直接进入队列if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();// 线程池状态不是RUNNING状态,说明执行过shutdown命令,需要对新加入的任务执行reject()操作。// 这儿为什么需要recheck,是因为任务入队列前后,线程池的状态可能会发生变化。if (! isRunning(recheck) && remove(command))reject(command);// 这儿为什么需要判断0值,主要是在线程池构造方法中,核心线程数允许为0else if (workerCountOf(recheck) == 0)addWorker(null, false);}// 如果线程池不是运行状态,或者任务进入队列失败,则尝试创建worker执行任务。// 这儿有3点需要注意:// 1. 线程池不是运行状态时,addWorker内部会判断线程池状态// 2. addWorker第2个参数表示是否创建核心线程// 3. addWorker返回false,则说明任务执行失败,需要执行reject操作else if (!addWorker(command, false))reject(command);}
4、addworker方法源码解析
private boolean addWorker(Runnable firstTask, boolean core) {retry:// 外层自旋for (;;) {int c = ctl.get();int rs = runStateOf(c);// 这个条件写得比较难懂,我对其进行了调整,和下面的条件等价// (rs > SHUTDOWN) ||// (rs == SHUTDOWN && firstTask != null) ||// (rs == SHUTDOWN && workQueue.isEmpty())// 1. 线程池状态大于SHUTDOWN时,直接返回false// 2. 线程池状态等于SHUTDOWN,且firstTask不为null,直接返回false// 3. 线程池状态等于SHUTDOWN,且队列为空,直接返回false// Check if queue empty only if necessary.if (rs >= SHUTDOWN &&! (rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty()))return false;// 内层自旋for (;;) {int wc = workerCountOf(c);// worker数量超过容量,直接返回falseif (wc >= CAPACITY ||wc >= (core ? corePoolSize : maximumPoolSize))return false;// 使用CAS的方式增加worker数量。// 若增加成功,则直接跳出外层循环进入到第二部分if (compareAndIncrementWorkerCount(c))break retry;c = ctl.get(); // Re-read ctl// 线程池状态发生变化,对外层循环进行自旋if (runStateOf(c) != rs)continue retry;// 其他情况,直接内层循环进行自旋即可// else CAS failed due to workerCount change; retry inner loop}}boolean workerStarted = false;boolean workerAdded = false;Worker w = null;try {w = new Worker(firstTask);final Thread t = w.thread;if (t != null) {final ReentrantLock mainLock = this.mainLock;// worker的添加必须是串行的,因此需要加锁mainLock.lock();try {// Recheck while holding lock.// Back out on ThreadFactory failure or if// shut down before lock acquired.// 这儿需要重新检查线程池状态int rs = runStateOf(ctl.get());if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {// worker已经调用过了start()方法,则不再创建workerif (t.isAlive()) // precheck that t is startablethrow new IllegalThreadStateException();// worker创建并添加到workers成功workers.add(w);// 更新`largestPoolSize`变量int s = workers.size();if (s > largestPoolSize)largestPoolSize = s;workerAdded = true;}} finally {mainLock.unlock();}// 启动worker线程if (workerAdded) {t.start();workerStarted = true;}}} finally {// worker线程启动失败,说明线程池状态发生了变化(关闭操作被执行),需要进行shutdown相关操作if (! workerStarted)addWorkerFailed(w);}return workerStarted;}
5、线程池worker任务单元
private final class Workerextends AbstractQueuedSynchronizerimplements Runnable{/*** This class will never be serialized, but we provide a* serialVersionUID to suppress a javac warning.*/private static final long serialVersionUID = 6138294804551838833L;/** Thread this worker is running in. Null if factory fails. */final Thread thread;/** Initial task to run. Possibly null. */Runnable firstTask;/** Per-thread task counter */volatile long completedTasks;/*** Creates with given first task and thread from ThreadFactory.* @param firstTask the first task (null if none)*/Worker(Runnable firstTask) {setState(-1); // inhibit interrupts until runWorkerthis.firstTask = firstTask;// 这儿是Worker的关键所在,使用了线程工厂创建了一个线程。传入的参数为当前workerthis.thread = getThreadFactory().newThread(this);}/** Delegates main run loop to outer runWorker */public void run() {runWorker(this);}// 省略代码...}
6、核心线程执行逻辑-runworker
final void runWorker(Worker w) {Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;// 调用unlock()是为了让外部可以中断w.unlock(); // allow interrupts// 这个变量用于判断是否进入过自旋(while循环)boolean completedAbruptly = true;try {// 这儿是自旋// 1. 如果firstTask不为null,则执行firstTask;// 2. 如果firstTask为null,则调用getTask()从队列获取任务。// 3. 阻塞队列的特性就是:当队列为空时,当前线程会被阻塞等待while (task != null || (task = getTask()) != null) {// 这儿对worker进行加锁,是为了达到下面的目的// 1. 降低锁范围,提升性能// 2. 保证每个worker执行的任务是串行的w.lock();// If pool is stopping, ensure thread is interrupted;// if not, ensure thread is not interrupted. This// requires a recheck in second case to deal with// shutdownNow race while clearing interrupt// 如果线程池正在停止,则对当前线程进行中断操作if ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();// 执行任务,且在执行前后通过`beforeExecute()`和`afterExecute()`来扩展其功能。// 这两个方法在当前类里面为空实现。try {beforeExecute(wt, task);Throwable thrown = null;try {task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {afterExecute(task, thrown);}} finally {// 帮助gctask = null;// 已完成任务数加一w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {// 自旋操作被退出,说明线程池正在结束processWorkerExit(w, completedAbruptly);}}
4. JDK自带的线程池
4.1 单例线程池
ExecutorService service = Executors.newSingleThreadExecutor();
单例线程池是一个只有1个线程的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行。
4.2 缓存线程池
ExecutorService service = Executors.newCachedThreadPool();
缓存线程池是一个可缓存线程的线程池,如果线程池长度超过处理需求,可以灵活回收空闲线程,若无可回收则新建线程。
4.3 定长线程池
final int cpuCoreNum = 4;ExecutorService service = Executors.newFixedThreadPool(cpuCoreNum);
定长线程池可以控制线程最大并发数,超过的线程会在队列中等待。
4.4 定时计划线程池
ScheduledExecutorService service = Executors.newScheduledThreadPool(4);
定时计划线程池支持定时及周期性任务执行。
5. ForkJoinPool
ForkJoinPool 适合于把一个大任务切分成很多很多的小任务来执行, 执行后汇总结果。
- 分解汇总的任务
- 用很少的线程可以执行很多的任务(子任务)TPE做不到先执行子任务
- 适用于CPU密集型场景
5.1 WorkStealingPool
WorkStealingPool 与 ThreadPoolExecutor不同的地方在于WorkStealingPool是每一个线程都维护了一个队列,如果一个线程执行完自己的队列的任务后,会从其他线程的尾部“偷”一个任务过来执行。所以这个线程池叫做WorkStealingPool
ExecutorService service = Executors.newWorkStealingPool();
6. 定义多少线程合适

- Ncpu: 是CPU的数量,可以通过
_Runtime.getRuntime().availableProcessors();_获取 - Ucpu:是期望CPU的使用率,比如期望CPU满载则 Ucpu = 1。
- W/C:CPU的等待时间/执行时间(Wait/Computation)

若有收获,就点个赞吧
0 人点赞
