缓存行
根据程序局部性原理,现在的程序的内存很多都是连续的, CPU在取出一个变量后很大可能会取出和它紧邻的下一个或者上一个内存地址, 所以现在的CPU在读取变量时不会只读取一个, 而是把和它紧邻的地址都取出来. 这一串紧邻的地址被称为**缓存行**.
缓存行的大小默认是64个字节.
缓存行越大,局部性空间效率越高,但读取时间慢
缓存行越小,局部性空间效率越低,但读取时间快
取一个工业折中值,目前多用64字节. 这是总线传输一次数据的最大量.
伪共享
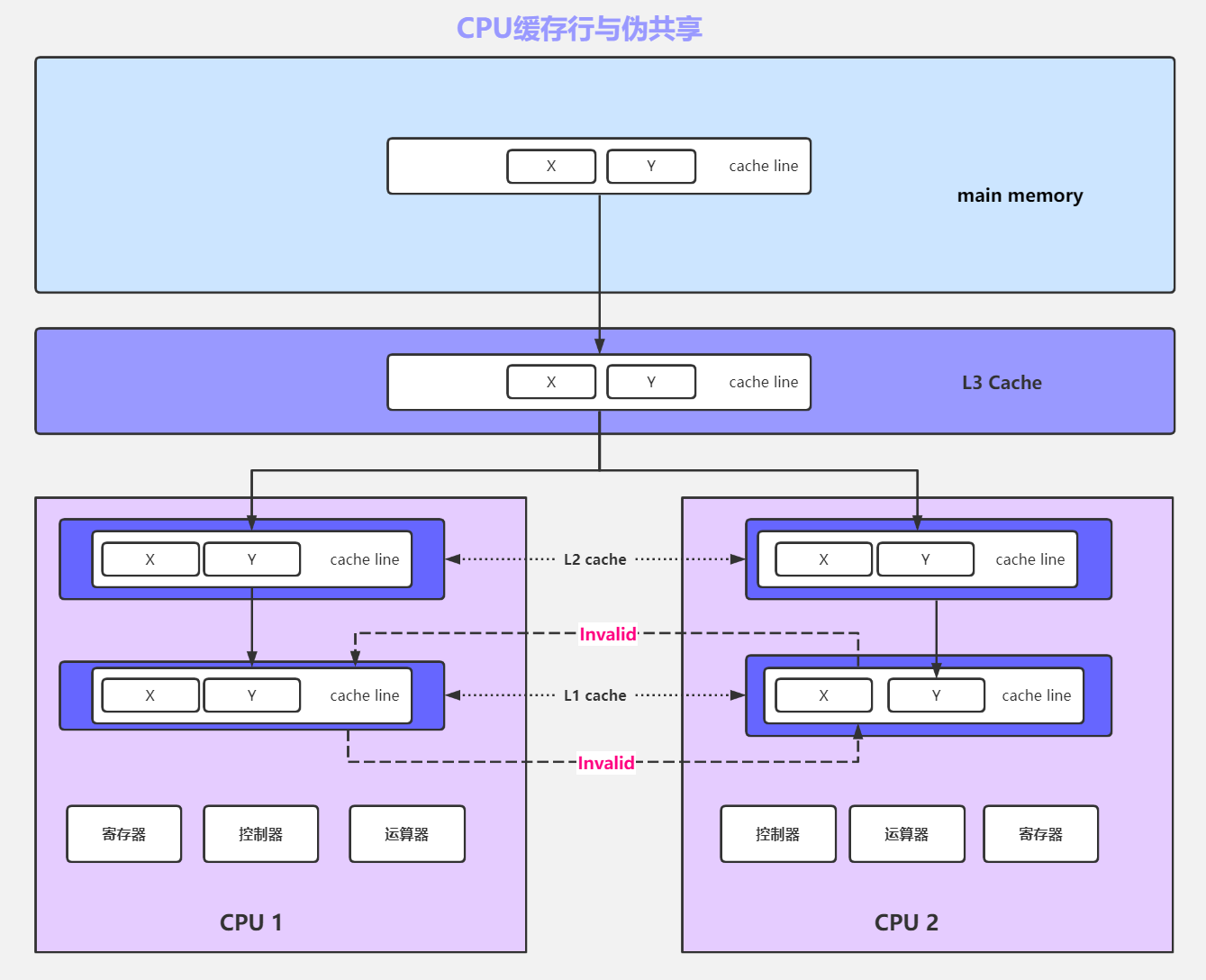
缓存行的机制确能加快程序的性能,但是也会引发伪共享的问题。 所谓的伪共享是由于缓存行的机制和MESI的机制天生的的缺陷产生的问题。解释如下:
当变量x、y在一个缓存行内且被CPU1、CPU2同时读取, CPU1只是用x,CPU2只使用y, 由于MESI的机制,CPU1修改x后要通知CPU2当前缓存行失效,但是CPU2根本就没有使用变量x,却依然要放弃现在整个缓存行进而再次读取一次。 反之亦然,如果运行速度过快,CPU1和CPU2之间要一直不断地互相通知对方缓存行失效,这种
伪共享会影响性能。
证明伪共享**:
//程序1public class CacheLinePadding1 {public static volatile long[] arr = new long[2];public static void main(String[] args) throws Exception {//修改1亿次 arr[0] 的值Thread t1 = new Thread(()->{for (long i = 0; i < 100_0000_0000L; i++) {arr[0] = i;}});//修改1亿次 arr[1] 的值Thread t2 = new Thread(()->{for (long i = 0; i < 100_0000_0000L; i++) {arr[1] = i;}});final long start = System.nanoTime();t1.start();t2.start();t1.join();t2.join();System.out.println((System.nanoTime() - start)/100_0000);//英特尔4核8线程运算10次的结果如下//7628、7716、7400、7754、7789、7621、7864、7755、7343、7587}}
//程序2public class CacheLinePadding2 {public static volatile long[] arr = new long[16];public static void main(String[] args) throws Exception {//修改1亿次 arr[0] 的值Thread t1 = new Thread(()->{for (long i = 0; i < 100_0000_0000L; i++) {arr[0] = i;}});//修改1亿次 arr[1] 的值Thread t2 = new Thread(()->{for (long i = 0; i < 100_0000_0000L; i++) {arr[8] = i;}});final long start = System.nanoTime();t1.start();t2.start();t1.join();t2.join();System.out.println((System.nanoTime() - start)/100_0000);//英特尔4核8线程运算10次的结果如下//5517、5386、5572、5856、5455、5828、5463、5678、5514、5378}}
从程序上来讲,应该是两个程序一样快,因为都是修改2个变量100亿次,但是最终结果是程序2要比程序1快, 因为程序2 避免了MESI协议。
程序2因为前后使用7个long类型填充, 占满了一次缓存行。每次修改不用走MESI协议.所以程序2要比程序1运行快.
对于有些特别敏感的数字,会存在线程高竞争的访问,为了保证不发生伪共享,可以使用缓存航对齐的编程方式
JDK7中,很多采用long padding提高效率(程序2的方法)
JDK8,加入了@Contended注解(实验)需要加上:JVM -XX:-RestrictContended

若有收获,就点个赞吧
0 人点赞
