5. Script
Elasticsearch支持3种脚本语言:Groovy(1.4.x - 5.0 )、painless、experssion。Groovy:
安全性问题Elasticsearch5.0以后已经放弃。painless:
painless是一种专门用于Elasticsearch的简单,用于内联和存储脚本,类似于Java,也有注释、关键字、类型、变量、函数等,安全的脚本语言。它是Elasticsearch的默认脚本语言,可以安全地用于内联和存储脚本。expression:
每个文档的开销较低:表达式的作用更多,可以非常快速地执行,甚至比编写native脚本还要快,支持javascript语法的子集:单个表达式。缺点:只能访问数字,布尔值,日期和geo_point字段,存储的字段不可用.
脚本模板:
{METHOD} {_index}/{action}/{_id}{"script":{"lang": "painless/expression","source": "ctx._source.{field} {option} {值} "}}
使用 painless 脚本将 _index 为“order”_id 为 “1”的premium 字段减1
POST order/_update/1{"script":{"lang": "painless","source": "ctx._source.premium -= 1"}}
使用 painless 脚本将 _index 为“order”_id 为 “1”的tenderAddress字段后面拼接一个字符串”666”
POST order/_update/1{"script":{"lang": "painless","source": "ctx._source.tenderAddress +='66666' "}}
使用 painless 脚本删除 _index 为“order”_id 为 “1”的doc
POST order/_update/1{"script":{"lang": "painless","source": "ctx.op='delete'"}}
upsert是update+insert的简写。所以使用upsert后,如果doc存在的话则是更新操作, 如果doc不存在则是插入操作。
_index 为“order”_id 为 “1”的doc下的tags字段是一个数组。
POST order/_update/1{"script": {"lang": "painless","source": "ctx._source.tags.add(params.zhangdeshi)","params": {"zhangdeshi":"真TM帅","xiangeshi":"真JB差"}},"upsert": {"age":"30","name":"李明","tags":[]}}
使用expression表达式查询一个premium字段
GET {_index}/_search{"script_fields": {"{给查询结果起个名字}": {"script": {"lang": "expression","source":"doc['premium']"}}}}
使用expression表达式对premium字段打9折
GET {_index}/_search{"script_fields": {"{给查询结果起个名字}": {"script": {"lang": "expression","source":"doc['premium'].value*0.9"}}}}
使用painless 查询一个premium字段打9折、打8折,使用参数
GET order/_search{"script_fields": {"{给查询结果起个名字}": {"script": {"lang": "painless","source":"[doc['premium'].value*params.da9zhe,doc['premium'].value*params.da8zhe]","params": {"da9zhe":0.9,"da8zhe":0.8}}}}}
Stored script
先保存一个script模板
POST _scripts/{script-id}{"script": {"lang": "painless","source":"[doc['premium'].value*params.da9zhe,doc['premium'].value*params.da8zhe]","params": {"da9zhe":0.9,"da8zhe":0.8}}}
使用模板
POST order/_search{"script_fields": {"{给查询结果起个名字}": {"script": {"id":"{script-id}","params": {"da9zhe":0.009,"da8zhe":0.008}}}}}
使用自定义脚本,类似于存储过程,可以在里面写一些逻辑, if for 或者一些自定义运算。
POST order/_update/2{"script": {"lang": "painless","source": """ctx._source.premium *= ctx._source.rate;ctx._source.amount += params.danwei""","params": {"danwei":"万元"}}}
查找premium大于等于10小于等于205的数据,并统计查找到的数据的insuranceCompany字段字符的总数。
GET order/_search{"query": {"bool": {"filter": [{"range": {"premium": {"gte": 10,"lte": 205}}}]}},"aggs": {"{给聚合查村结果起个名字}": {"sum": {"script": {"lang": "painless","source": """int total = 0;for(int i = 0; i < doc['insuranceCompany.keyword'].length; i++){total++;}return total;"""}}}},"size": 0}
写入原理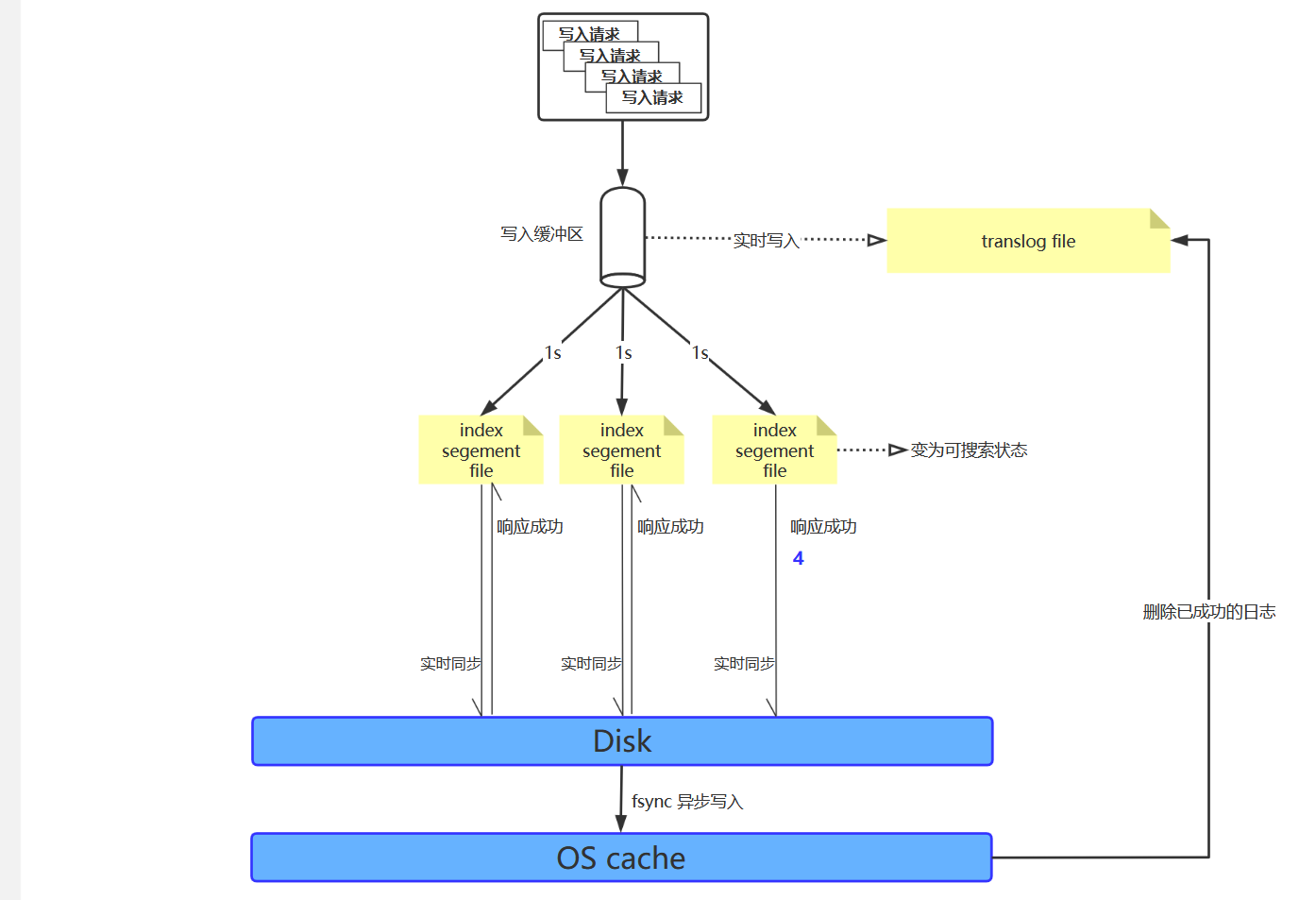
6. 分词器
分词器里面有3个最重要的属性:
char_filter
分词之前字符预处理,过滤无用字符、无用标签等。 比如: 《Elasticsearch》=> Elasticsearch 新年好 =>“新年好”。
tokenizer
真正分词用的
token_filter
停用词、时态转换、大小写转换、同义词转换、语气词处理等。 比如: has=>have
him=>he
apples=>apple
the/oh/a => 去掉
6.1 设置char_filter
- 新增索引名称为“my-index”,并指定分词器内的字符过滤器
```json
新增索引名称为“my-index”,并指定分词器内的字符过滤器
PUT my-index { “settings”: { “analysis”: { //指定字符过滤器,名字为“my-charfilter”,指定的字符会被转换为其他内容 “char_filter”: {
}, //指定分词器内的字符过滤器为我们上面定义好的字符过滤器“my-charfilter” “analyzer”: {"my-charfilter":{ //指定字符过滤器名字"type":"mapping", //指定过滤器类型"mappings":["&=>and","&&=>and","|=>or","||=>or"] //指定需要映射的字符}
} } } }"my-analyzer":{ //指定分词器的名字"tokenizer":"keyword","char_filter":["my-charfilter"] //指定要使用的字符过滤器}
测试 my-index的字符过滤器my-charfilter
GET my-index/_analyze { “analyzer”: “my-analyzer”, “text”: [“666&77&&8||”] }
结果:
{ “tokens” : [ { “token” : “666and77and8or”, “start_offset” : 0, “end_offset” : 11, “type” : “word”, “position” : 0 } ] }
2. 新增索引名称为“my-index”,并指定分词器内的字符过滤器为“html_strip”,并指定逃逸标签```json# 新增一个索引名字为my-index2 并指定字符过滤器PUT my-index2{"settings": {"analysis": {//指定字符过滤器的名字为“my-charfilter”,类型为“html_strip”,逃逸标签为["a","p"]"char_filter": {"my-charfilter":{ //指定字符过滤器名字"type":"html_strip", //指定过滤器类型"escaped_tags":["a","p"] //指定字符过滤器逃逸标签}},//指定词法分分词器的名字为my-analyzer,字符过滤器为我们上面定义好的my-charfilter"analyzer": {"my-analyzer":{ //指定分词器的名字"tokenizer":"keyword","char_filter":["my-charfilter"] //指定要使用的字符过滤器}}}}}# 测试GET my-index2/_analyze{"analyzer": "my-analyzer","text": ["<a><b>hello word</b></a>", "<p>hello word</p>"]}# 结果:{"tokens" : [{"token" : "666and77and8or","start_offset" : 0,"end_offset" : 11,"type" : "word","position" : 0}]}
- 用正则匹配,并替换指定的字符
```json
用正则匹配,并替换指定的字符
PUT my-index3 { “settings”: { “analysis”: { //设置字符过滤器 “char_filter”: {
}, //指定词法分分词器的名字为my-analyzer,字符过滤器为我们上面定义好的my-charfilter “analyzer”: {"my-charfilter":{ //指定字符过滤器名字"type":"pattern_replace", //指定过滤器类型"pattern":"(\\d+)-(?=\\d)", //指定正则"replacement":"$1_" //指定匹配后的替换字符}
} } } }"my-analyzer":{ //指定分词器的名字"tokenizer":"standard","char_filter":["my-charfilter"] //指定要使用的字符过滤器}
测试
GET my-index3/_analyze { “analyzer”: “my-analyzer”, “text”: “My credit card is 123-456-789” }
结果:
{
“tokens” : [
{
“token” : “My”,
“start_offset” : 0,
“end_offset” : 2,
“type” : “
<a name="sO5KC"></a>## 6.2 设置token filter什么都不带的```json#测试:GET _analyze{"tokenizer" : "standard", //标准tokenizer"filter" : ["lowercase"], //小写过滤"text" : "THE Quick FoX JUMPs" //测试内容}# 结果:{"tokens" : [{"token" : "the","start_offset" : 0,"end_offset" : 3,"type" : "<ALPHANUM>","position" : 0},{"token" : "quick","start_offset" : 4,"end_offset" : 9,"type" : "<ALPHANUM>","position" : 1},{"token" : "fox","start_offset" : 10,"end_offset" : 13,"type" : "<ALPHANUM>","position" : 2},{"token" : "jumps","start_offset" : 14,"end_offset" : 19,"type" : "<ALPHANUM>","position" : 3}]}
带脚本的
#测试GET /_analyze{"tokenizer" : "standard", //标准tokenizer"filter": [{"type": "condition", //条件过滤器"filter": [ "lowercase" ], //转换为小写"script": { //条件脚本,满足脚本内的条件即会进行转换"source": "token.getTerm().length() < 5"}}],"text": "THE QUICK BROWN FOX" //测试内容}结果:{"tokens" : [{"token" : "the","start_offset" : 0,"end_offset" : 3,"type" : "<ALPHANUM>","position" : 0},{"token" : "QUICK","start_offset" : 4,"end_offset" : 9,"type" : "<ALPHANUM>","position" : 1},{"token" : "BROWN","start_offset" : 10,"end_offset" : 15,"type" : "<ALPHANUM>","position" : 2},{"token" : "fox","start_offset" : 16,"end_offset" : 19,"type" : "<ALPHANUM>","position" : 3}]}
6.3 设置analyzer
停用词
PUT /my_index8{"settings": {"analysis": {//设置分词器"analyzer": {"my_analyzer":{ //名字为“my_analyzer”"type":"standard", //类型为标准类型"stopwords":"_english_" //停用词为英语语法里面的标准停用词}}}}}#测试GET my_index8/_analyze{"analyzer": "my_analyzer","text": "Teacher Ma is in the restroom"}#结果:{"tokens" : [{"token" : "teacher","start_offset" : 0,"end_offset" : 7,"type" : "<ALPHANUM>","position" : 0},{"token" : "ma","start_offset" : 8,"end_offset" : 10,"type" : "<ALPHANUM>","position" : 1},{"token" : "restroom","start_offset" : 21,"end_offset" : 29,"type" : "<ALPHANUM>","position" : 5}]}
6.4 设置analysis
PUT my-index9{"settings": {"analysis": {//设置字符过滤器"char_filter": {"test_char_filter": { //字符过滤器名字为“test_char_filter”"type": "mapping", //类型为mapping"mappings": [ "& => and", "| => or" ]}},//设置过滤器"filter": {"test_stopwords": { //过滤器名字为test_stopwords"type": "stop", //类型为stop"stopwords": ["is","in","at","the","a","for"]}},//设置分词器"tokenizer": {"punctuation": {"type": "pattern", //类型为正则匹配型"pattern": "[ .,!?]" //正则}},"analyzer": {"my_analyzer": { //分析器名字为my_analyzer"type": "custom", //设置type为custom告诉Elasticsearch我们正在定义一个定制分析器"char_filter": [ //设置字符过滤器一个是我们自定义的test_char_filter,一个是内置的html_strip"test_char_filter","html_strip"],"tokenizer": "standard", //设置tokenizer为standard"filter": ["lowercase","test_stopwords"]//设置过滤器为内置的lowercase和我们自定义的test_stopwords}}}}}# 测试GET my-index9/_analyze{"text": "Teacher ma & zhang also thinks [mother's friends] is good | nice!!!","analyzer": "my_analyzer"}#结果{"tokens" : [{"token" : "teacher","start_offset" : 0,"end_offset" : 7,"type" : "<ALPHANUM>","position" : 0},{"token" : "ma","start_offset" : 8,"end_offset" : 10,"type" : "<ALPHANUM>","position" : 1},{"token" : "and","start_offset" : 11,"end_offset" : 12,"type" : "<ALPHANUM>","position" : 2},{"token" : "zhang","start_offset" : 13,"end_offset" : 18,"type" : "<ALPHANUM>","position" : 3},{"token" : "also","start_offset" : 19,"end_offset" : 23,"type" : "<ALPHANUM>","position" : 4},{"token" : "thinks","start_offset" : 24,"end_offset" : 30,"type" : "<ALPHANUM>","position" : 5},{"token" : "mother's","start_offset" : 32,"end_offset" : 40,"type" : "<ALPHANUM>","position" : 6},{"token" : "friends","start_offset" : 41,"end_offset" : 48,"type" : "<ALPHANUM>","position" : 7},{"token" : "good","start_offset" : 53,"end_offset" : 57,"type" : "<ALPHANUM>","position" : 9},{"token" : "or","start_offset" : 58,"end_offset" : 59,"type" : "<ALPHANUM>","position" : 10},{"token" : "nice","start_offset" : 60,"end_offset" : 64,"type" : "<ALPHANUM>","position" : 11}]}
6.5 完整的mapping+analysis
PUT my_index12{"settings": {"analysis": {//设置字符过滤器"char_filter": {"test_char_filter": { //字符过滤器名字为“test_char_filter”"type": "mapping", //类型为mapping"mappings": [ "& => and", "| => or" ]}},//设置过滤器"filter": {"test_stopwords": { //过滤器名字为test_stopwords"type": "stop", //类型为stop"stopwords": ["is","in","at","the","a","for"]}},//设置分词器"tokenizer": {"punctuation": {"type": "pattern", //类型为正则匹配型"pattern": "[ .,!?]" //正则}},"analyzer": {"my_analyzer": { //分析器名字为my_analyzer"type": "custom", //设置type为custom告诉Elasticsearch我们正在定义一个定制分析器"char_filter": [ //设置字符过滤器一个是我们自定义的test_char_filter,一个是内置的html_strip"test_char_filter","html_strip"],"tokenizer": "standard", //设置tokenizer为standard"filter": ["lowercase","test_stopwords"]//设置过滤器为内置的lowercase和我们自定义的test_stopwords}}}},"mappings": {"properties": {//设置字段“name”"name": {"type": "text", //设置类型为文本类型"analyzer": "my_analyzer", //指定分词器"search_analyzer": "standard" //设置搜索时分词器},//设置字段“said”"said": {"type": "text", //设置类型为文本类型"analyzer": "my_analyzer", //指定分词器"search_analyzer": "standard" //设置搜索时分词器}}}}
6.6 中文分词器 ik
1. ik安装并使用
ik是一个java项目,使用maven构建,我们把它clone下来,使用maven命令package。在target/release/下面有个zip文件。elasticsearch-analysis-ik-7.4.0.zip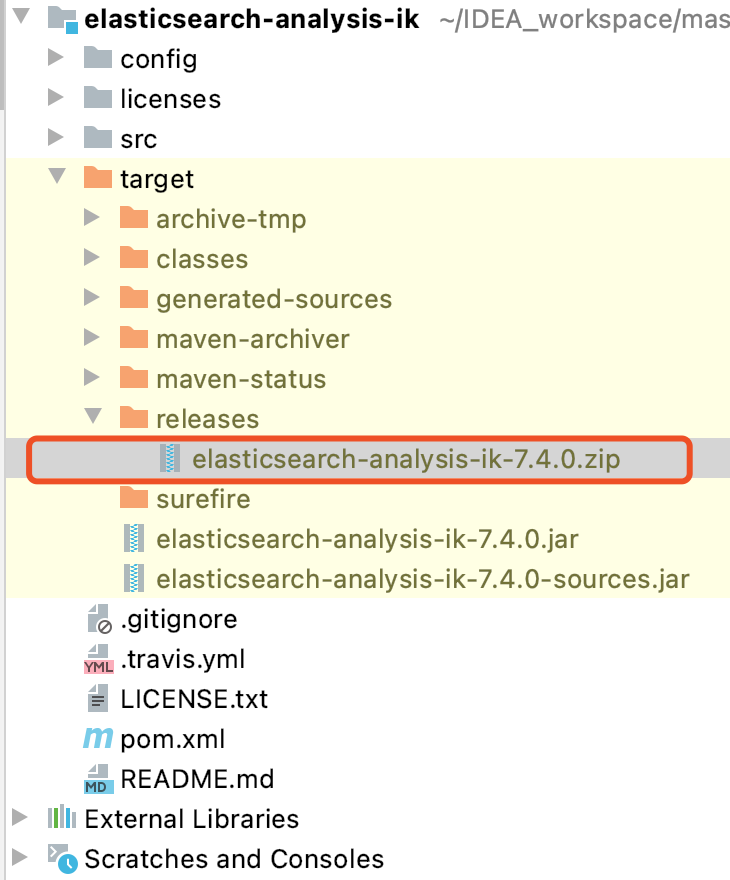
把 elasticsearch-analysis-ik-7.4.0.zip解压后是这个样子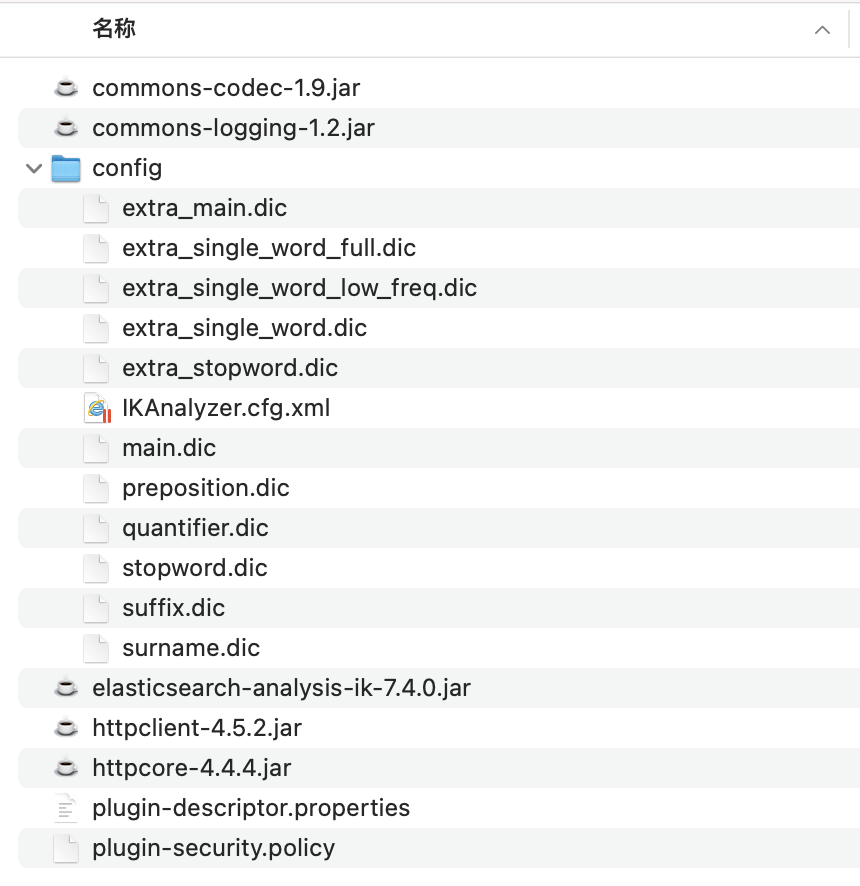
将这些文件全部copy至{``ES_source_path``}``/plugins/ik文件夹下面(需要在plugins下面创建ik文件夹)。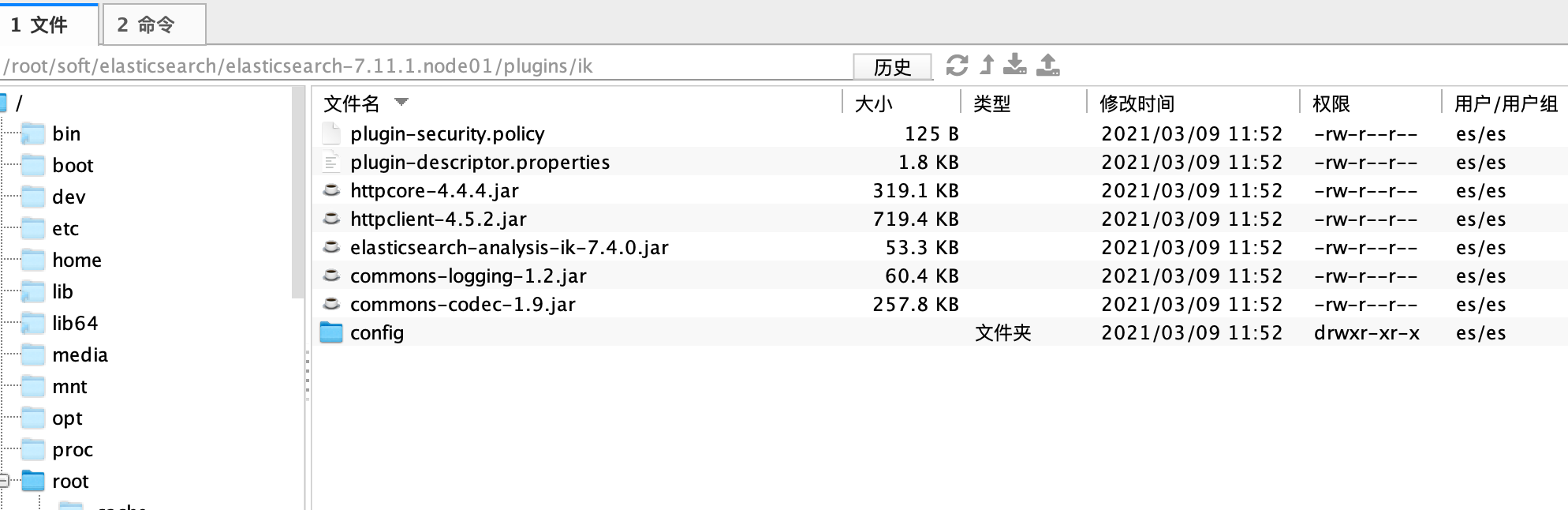
然后重启Elasticsearch。
测试 ik中文分词器 :
# 测试 ik中文分词器GET _analyze{"analyzer": "ik_max_word", //指定分词器为ik内置的两大分词器之一“ik_max_word”"text": [ "美国留给伊拉克的是个烂摊子吗" ] //测试数据}# 结果{"tokens" : [{"token" : "美国","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "留给","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 1},{"token" : "伊拉克","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 2},{"token" : "的","start_offset" : 7,"end_offset" : 8,"type" : "CN_CHAR","position" : 3},{"token" : "是","start_offset" : 8,"end_offset" : 9,"type" : "CN_CHAR","position" : 4},{"token" : "个","start_offset" : 9,"end_offset" : 10,"type" : "CN_CHAR","position" : 5},{"token" : "烂摊子","start_offset" : 10,"end_offset" : 13,"type" : "CN_WORD","position" : 6},{"token" : "摊子","start_offset" : 11,"end_offset" : 13,"type" : "CN_WORD","position" : 7},{"token" : "吗","start_offset" : 13,"end_offset" : 14,"type" : "CN_CHAR","position" : 8}]}
安装过程中可能遇到的问题:
java.lang.IllegalArgumentException: Plugin [analysis-ik] was built for Elasticsearch version 7.10.0 but version 7.10.1 is running
一看就是ik和Elasticsearch版本不匹配,我们需要把ik分词器内的Elasticsearch版本改为ik对应的版本。
编辑plugin-descriptor.properties文件:里面有个“elasticsearch.version” 将它改为Elasticsearch版本即可。
2. ik两种analyzer
ik_max_word:细粒度,一般都使用这个。ik_smart:粗粒度
3. config下的文件描述
- IKAnalyzer.cfg.xml : IK分词配置文件
- main.dic :主词库
- stopword.dic :英文停用词,不会建立在倒排索引中
- quantifier.dic :特殊词库:计量单位等
- suffix.dic :特殊词库:后缀名
- a. surname.dic :特殊词库:百家姓
- preposition :特殊词库:语气词
4. 如何热更新ik词库
方案一:修改IK源码,定时链接数据库,查询主词和停用词,更新到本机IK中。
方案二:定时调接口
目前该插件支持热更新 IK 分词,通过在 IKAnalyzer.cfg.xml 配置文件中提到的如下配置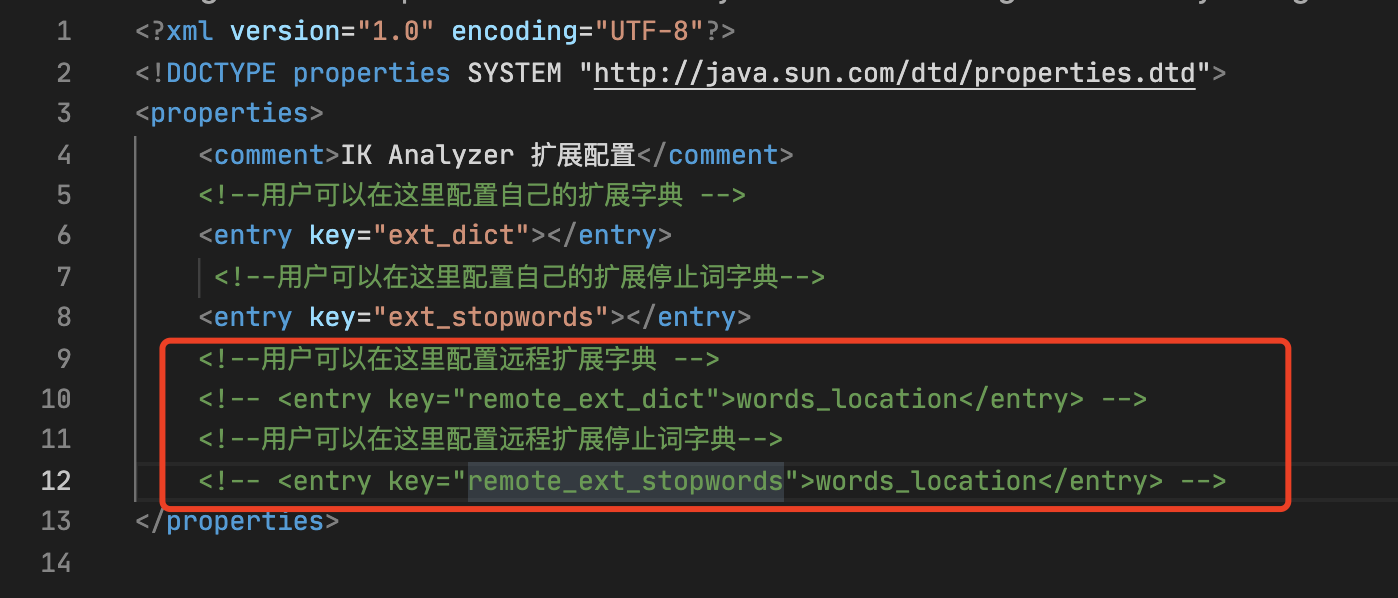
其中 words_location 是指一个 URL接口地址,该请求只需满足以下两点即可完成分词热更新。
- 该 http 请求需要返回两个头部(header),一个是
**Last-Modified**,一个是**ETag**,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。 - 该 http 请求返回的内容格式是
**一行一个分词**,换行符用** \n**即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
下面是用spring boot模拟的一个接口:
/*** 获取ik自定义词典* @param response*/@RequestMapping(value="/getCustomDict")public void getCustomDict(HttpServletResponse response){try {//具体数据可以连接数据库或者缓存类获取String[] dicWords = new String[]{"雷猴啊","割韭菜","996","实力装X","颜值担当"};//响应数据StringJoiner content = new StringJoiner(System.lineSeparator());for (String dicWord : dicWords) {content.add(dicWord);}response.setHeader("Last-Modified", String.valueOf(content.length()));response.setHeader("ETag",String.valueOf(content.length()));response.setContentType("text/plain; charset=utf-8");OutputStream out= response.getOutputStream();out.write(content.toString().getBytes("UTF-8"));out.flush();} catch (Exception e) {e.printStackTrace();}}
7. 前缀、通配符、正则、模糊查询
# 设置前缀索引PUT my_index{"mappings": {"properties": {"title":{ //字段名字"type": "text", //类型为文本类型"index_prefixes":{ //索引前缀设置"min_chars":2, //字段前缀最少2个字符生成索引"max_chars":4 //字段前缀最多4个字符生成索引}}}}}# 批量插入中文测试数据POST /my_index/_bulk{ "index": { "_id": "1"} }{ "title": "城管打电话喊商贩去摆摊摊" }{ "index": { "_id": "2"} }{ "title": "笑果文化回应商贩老农去摆摊" }{ "index": { "_id": "3"} }{ "title": "老农耗时17年种出椅子树" }{ "index": { "_id": "4"} }{ "title": "夫妻结婚30多年AA制,被城管抓" }{ "index": { "_id": "5"} }{ "title": "黑人见义勇为阻止抢劫反被铐住" }# 批量插入英文测试数据POST /my_index/_bulk{ "index": { "_id": "6"} }{ "title": "my english" }{ "index": { "_id": "7"} }{ "title": "my english is good" }{ "index": { "_id": "8"} }{ "title": "my chinese is good" }{ "index": { "_id": "9"} }{ "title": "my japanese is nice" }{ "index": { "_id": "10"} }{ "title": "my disk is full" }#前缀搜索GET my_index/_search{"query": {"prefix": { //prefix为前缀搜索"title": { //指定需要前缀搜索的字段名称"value": "城管" //指定字段值}}}}# 测试ik分词器GET /_analyze{"text": "城管打电话喊商贩去摆摊摊","analyzer": "ik_smart"}#通配符GET my_index/_search{"query": {"wildcard": {"title": {"value": "eng?ish"}}}}#通配符GET order/_search{"query": {"wildcard": {"insuranceCompany.keyword": {"value": "中?联合"}}}}#通配符GET product/_search{"query": {"wildcard": {"name.keyword": {"value": "xiaomi*nfc*","boost": 1.0}}}}#正则GET product/_search{"query": {"regexp": {"name": {"value": "[\\s\\S]*nfc[\\s\\S]*","flags": "ALL","max_determinized_states": 10000,"rewrite": "constant_score"}}}}# 模糊搜索fuzzyGET order/_search{"query": {"match": {"tenderAddress": { //指定需要搜索的字段的名字"query": "乔呗", //指定需要搜索的模糊值"fuzziness": "AUTO", //指定模糊模式,默认“AUTO”"operator": "or" //指定操作类型,默认“or”}}}}# 前缀短语搜索match_phrase_prefixGET /order/_search{"query": {//前缀短语搜索"match_phrase_prefix": {"bidInvationCenter": { //指定字段"query": "中国", //前缀短语值"analyzer": "ik_smart", //设置分词器"max_expansions": 1, //限制匹配的最大词项,参数告诉 match_phrase 查询词条相隔多远时仍然能将文档视为匹配 什么是相隔多远? 意思是说为了让查询和文档匹配你需要移动词条多少次?"slop": 2, //允许短语间的词项(term)间隔"boost": 1 //用于设置该查询的权重}}}}GET _search{"query": {"match_phrase_prefix": {"message": {"query": "quick brown f"}}}}
8. TF-IDF算法、Java API序幕
官网的资料才是最新的,最全的:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-overview.html
引入maven
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.11.1</version></dependency><repositories><repository><id>es-snapshots</id><name>elasticsearch snapshot repo</name><url>https://snapshots.elastic.co/maven/</url></repository></repositories><repository><id>elastic-lucene-snapshots</id><name>Elastic Lucene Snapshots</name><url>https://s3.amazonaws.com/download.elasticsearch.org/lucenesnapshots/83f9835</url><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots></repository>
8.1 基本增删改查
import org.apache.http.HttpHost;import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;import org.elasticsearch.action.admin.indices.delete.DeleteIndexResponse;import org.elasticsearch.action.bulk.BulkRequest;import org.elasticsearch.action.bulk.BulkResponse;import org.elasticsearch.action.delete.DeleteRequest;import org.elasticsearch.action.delete.DeleteResponse;import org.elasticsearch.action.get.GetRequest;import org.elasticsearch.action.get.GetResponse;import org.elasticsearch.action.index.IndexRequest;import org.elasticsearch.action.index.IndexResponse;import org.elasticsearch.action.update.UpdateRequest;import org.elasticsearch.action.update.UpdateResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.common.settings.Settings;import org.elasticsearch.common.xcontent.XContentType;import java.io.IOException;import java.util.HashMap;import java.util.Map;public class TestElasticsearch {public static void main(String[] args) throws IOException {RestHighLevelClient client = createClient();//创建链接,创建客户端try {// createIndex(client); //创建索引// addData(client); //添加数据// queryData(client); //查询数据// updateData(client); //修改数据// queryData(client); //查询数据// deleteData(client); //删除数据// deleteIndex(client); //删除索引bulk(client); //批量操作}catch (Exception e){e.printStackTrace();}finally {if (client != null){closeClient(client); //关闭客户端}}}/*** 创建链接,创建客户端* @return*/public static RestHighLevelClient createClient(){//创建链接,创建客户端HttpHost http9200 = new HttpHost("8.140.122.156", 9200, "http");// HttpHost http9201 = new HttpHost("8.140.122.156", 9201, "http");RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(http9200));return client;}/*** 关闭客户端* @param client* @throws IOException*/public static void closeClient(RestHighLevelClient client) throws IOException {client.close();}/*** 创建索引* PUT order1* {* "settings": {* "number_of_shards": 3,* "number_of_replicas": 2* },* "mappings": {* "properties": {* "id":{* "type": "long"* },* "age":{* "type": "short"* },* "mail":{* "type": "text",* "fields": {* "keyword" : {* "type" : "keyword",* "ignore_above" : 64* }* }* },* "name":{* "type": "text",* "fields": {* "keyword" : {* "type" : "keyword",* "ignore_above" : 64* }* }* },* "createTime":{* "type": "date",* "format": ["yyyy-MM-dd HH:mm:ss"]* }* }* }* }* @param client* @throws IOException*/public static void createIndex(RestHighLevelClient client) throws IOException {//设置3个分片,每个分片2副本Settings settings = Settings.builder().put("number_of_shards",3).put("number_of_replicas",2).build();//新增索引CreateIndexRequest createIndexRequest = new CreateIndexRequest("order1");createIndexRequest.mapping("properties","{\"id\":{\"type\":\"long\"},\"age\":{\"type\":\"short\"},\"mail\":{\"type\":\"text\",\"fields\":{\"keyword\":{\"type\":\"keyword\",\"ignore_above\":64}}},\"name\":{\"type\":\"text\",\"fields\":{\"keyword\":{\"type\":\"keyword\",\"ignore_above\":64}}},\"createTime\":{\"type\":\"date\",\"format\":[\"yyyy-MM-dd HH:mm:ss\"]}}",XContentType.JSON);createIndexRequest.settings(settings);//执行CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);System.out.println("创建索引结果: "+createIndexResponse.isAcknowledged());}/*** 插入数据** @param client* @throws IOException*/public static void addData(RestHighLevelClient client) throws IOException {//数据Map personMap = new HashMap();personMap.put("id",1);personMap.put("age",28);personMap.put("name","王帆");personMap.put("email","wangfan@yxinsur.com");personMap.put("createTime","2020-02-02 12:00:00");//新增索引IndexRequest indexRequest = new IndexRequest("order1","_doc","1");indexRequest.source(personMap);//执行IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);System.out.println("插入数据结果: "+indexResponse.toString());}/*** 查询数据* GET order1/_doc/1* @param client* @throws IOException*/public static void queryData(RestHighLevelClient client) throws IOException {//查询索引GetRequest getRequest = new GetRequest("order1","_doc","1");//执行GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);System.out.println("查询数据结果: "+getResponse.toString());}/*** 修改数据* PUT order1/_doc/1* {* "name": "王帆",* "age": 29,* "email": "wangfan@yxinsur.com"* }* @param client* @throws IOException*/public static void updateData(RestHighLevelClient client) throws IOException {//实际数据Map<String,Object> personMap = new HashMap<>();personMap.put("id",1);personMap.put("age",29);personMap.put("name","王帆");personMap.put("email","wangfan@yxinsur.com");personMap.put("createTime","2020-02-02 12:00:00");//修改索引UpdateRequest updateRequest = new UpdateRequest("order1","_doc","1");updateRequest.doc(personMap);//或者是upsert//updateRequest.upsert(person);//执行UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);System.out.println("修改数据结果: "+updateResponse.toString());}/*** 删除数据* DELETE order1/_doc/1* @param client* @throws IOException*/public static void deleteData(RestHighLevelClient client) throws IOException {//删除数据DeleteRequest deleteRequest = new DeleteRequest("order1","_doc","1");//执行DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);System.out.println("删除数据结果: "+deleteResponse.toString());}/*** 删除索引* DELETE order1/_doc/1* @param client* @throws IOException*/public static void deleteIndex(RestHighLevelClient client) throws IOException {//删除索引DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("order1");//执行DeleteIndexResponse deleteIndexResponse = client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);System.out.println("删除索引结果: "+deleteIndexResponse.isAcknowledged());}/*** 批量操作* @param client*/public static void bulk(RestHighLevelClient client) throws IOException {//准备数据Map<String,Object> personMap = new HashMap<>();personMap.put("id",2);personMap.put("age",29);personMap.put("name","王帆");personMap.put("email","wangfan@yxinsur.com");personMap.put("createTime","2020-02-02 12:00:00");//插入数据操作IndexRequest indexRequest2 = new IndexRequest("order1","_doc","2");indexRequest2.source(personMap,XContentType.JSON);IndexRequest indexRequest3 = new IndexRequest("order1","_doc","3");indexRequest3.source(personMap,XContentType.JSON);//修改数据操作personMap.put("age",30);UpdateRequest updateRequest = new UpdateRequest("order1","_doc","2");updateRequest.doc(personMap,XContentType.JSON);//删除数据操作DeleteRequest deleteRequest = new DeleteRequest("order1","_doc","2");//将操作都放入bulk里面BulkRequest bulkRequest = new BulkRequest();bulkRequest.add(indexRequest2);bulkRequest.add(indexRequest3);bulkRequest.add(updateRequest);bulkRequest.add(deleteRequest);//执行BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println("批量操作结果: "+bulkResponse.toString());}}
创建索引结果: true插入数据结果: IndexResponse[index=order1,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={“total”:3,”successful”:1,”failed”:0}] 查询数据结果: {“_index”:”order1”,”_type”:”_doc”,”_id”:”1”,”_version”:1,”found”:true,”_source”:{“createTime”:”2020-02-02 12:00:00”,”name”:”王帆”,”id”:1,”age”:28,”email”:”wangfan@yxinsur.com”},”fields”:{“_seq_no”:[0],”_primary_term”:[1]}}修改数据结果: UpdateResponse[index=order1,type=_doc,id=1,version=2,seqNo=1,primaryTerm=1,result=updated,shards=ShardInfo{total=3, successful=1, failures=[]}]查询数据结果: {“_index”:”order1”,”_type”:”_doc”,”_id”:”1”,”_version”:2,”found”:true,”_source”:{“createTime”:”2020-02-02 12:00:00”,”name”:”王帆”,”id”:1,”age”:29,”email”:”wangfan@yxinsur.com”},”fields”:{“_seq_no”:[1],”_primary_term”:[1]}}删除数据结果: DeleteResponse[index=order1,type=_doc,id=1,version=3,result=deleted,shards=ShardInfo{total=3, successful=1, failures=[]}]删除索引结果: true批量操作结果: org.elasticsearch.action.bulk.BulkResponse@793be5ca
9. ES集群部署
配置文件说明:
cluster.name:
整个集群的名称,整个集群使用一个名字,其他节点通过cluster.name发现集群。
node.name:
集群内某个节点的名称,其他节点可通过node.name发现节点,默认是机器名。
path.data:
数据存放地址,生产环境必须不能设置为es内部,否则es更新时会直接抹除数据
path.logs:
日志存在地址,生产环境必须不能设置为es内部,否则es更新时会直接抹除数据
bootstrap.memory_lock:
是否禁用swap交换区(swap交换区为系统内存不够时使用磁盘作为临时空间), 生产环境必须禁用
network.host:
当前节点绑定的Ip地址,切记一旦指定,则必须是这个地址才能访问,比如:如果配置为,127.0.0.1, 则必须只能是127.0.0.1才能访问, localhost 也不行。
http.port:
当前节点的服务端口号
transport.port:
当前节点的通讯端口号,集群内节点之间通讯使用此端口号, 比如选举master节点时。
discovery.seed_hosts:
必须把所有master节点的地址+端口都写进去。
cluster.initial_master_nodes:
集群初始化时会从这个列表中取出一个node.name选为master节点。
整个集群搭建模型:
| 节点名称 | node.master | node.data | 描述 |
|---|---|---|---|
| node01 | true | false | master节点 |
| node02 | true | false | master节点 |
| node03 | true | false | master节点 |
| node04 | false | true | 纯数据节点 |
| node05 | false | true | 纯数据节点 |
| node06 | false | false | 仅投票节点,路由节点 |
机器内网ip:172.27.229.9
集器外网ip:8.140.122.156
node01 配置:
cluster.name: my-applicationnode.name: node01path.data: /root/soft/elasticsearch/data/node01path.logs: /root/soft/elasticsearch/log/node01bootstrap.memory_lock: falsenetwork.host: 172.27.229.9http.port: 9200transport.port: 9300discovery.seed_hosts: ["172.27.229.9:9300", "172.27.229.9:9301","172.27.229.9:9302",]cluster.initial_master_nodes: ["node01","node02","node03"]http.cors.enabled: truehttp.cors.allow-origin: "*"node.master: truenode.data: falsenode.max_local_storage_nodes: 6
node02 配置:
cluster.name: my-applicationnode.name: node02path.data: /root/soft/elasticsearch/data/node02path.logs: /root/soft/elasticsearch/log/node02bootstrap.memory_lock: falsenetwork.host: 172.27.229.9http.port: 9201transport.port: 9301discovery.seed_hosts: ["172.27.229.9:9300", "172.27.229.9:9301","172.27.229.9:9302",]cluster.initial_master_nodes: ["node01","node02","node03"]http.cors.enabled: truehttp.cors.allow-origin: "*"node.master: truenode.data: falsenode.max_local_storage_nodes: 6
node03 配置:
cluster.name: my-applicationnode.name: node03path.data: /root/soft/elasticsearch/data/node03path.logs: /root/soft/elasticsearch/log/node03bootstrap.memory_lock: falsenetwork.host: 172.27.229.9http.port: 9202transport.port: 9302discovery.seed_hosts: ["172.27.229.9:9300", "172.27.229.9:9301","172.27.229.9:9302",]cluster.initial_master_nodes: ["node01","node02","node03"]http.cors.enabled: truehttp.cors.allow-origin: "*"node.master: truenode.data: falsenode.max_local_storage_nodes: 6
node04 配置:
cluster.name: my-applicationnode.name: node04path.data: /root/soft/elasticsearch/data/node04path.logs: /root/soft/elasticsearch/log/node04bootstrap.memory_lock: falsenetwork.host: 172.27.229.9http.port: 9203transport.port: 9303discovery.seed_hosts: ["172.27.229.9:9300", "172.27.229.9:9301","172.27.229.9:9302",]cluster.initial_master_nodes: ["node01","node02","node03"]http.cors.enabled: truehttp.cors.allow-origin: "*"node.master: falsenode.data: truenode.max_local_storage_nodes: 6
node05 配置:
cluster.name: my-applicationnode.name: node05path.data: /root/soft/elasticsearch/data/node05path.logs: /root/soft/elasticsearch/log/node05bootstrap.memory_lock: falsenetwork.host: 172.27.229.9http.port: 9204transport.port: 9304discovery.seed_hosts: ["172.27.229.9:9300", "172.27.229.9:9301","172.27.229.9:9302",]cluster.initial_master_nodes: ["node01","node02","node03"]http.cors.enabled: truehttp.cors.allow-origin: "*"node.master: falsenode.data: truenode.max_local_storage_nodes: 6
node05 配置:
cluster.name: my-applicationnode.name: node06path.data: /root/soft/elasticsearch/data/node06path.logs: /root/soft/elasticsearch/log/node06bootstrap.memory_lock: falsenetwork.host: 172.27.229.9http.port: 9205transport.port: 9305discovery.seed_hosts: ["172.27.229.9:9300", "172.27.229.9:9301","172.27.229.9:9302",]cluster.initial_master_nodes: ["node01","node02","node03"]http.cors.enabled: truehttp.cors.allow-origin: "*"node.master: falsenode.data: falsenode.max_local_storage_nodes: 6

若有收获,就点个赞吧
0 人点赞
