- 1. redis安装/部署
- 2. redis 存储类型
- 3. redis进阶
- 4. redis高可用
- logfile /var/log/redis_6379.log:注释掉日志文件
- When a replica loses its connection with the master, or when the replication
- is still in progress, the replica can act in two different ways:
- 当salve与master端开链接、或者正在进行复制数据时,salve会表现出2种不同的行为
- 1) if replica-serve-stale-data is set to ‘yes’ (the default) the replica will
- still reply to client requests, possibly with out of date data, or the
- data set may just be empty if this is the first synchronization.
- 1) 如果replica-serve-stale-data 设置为 ‘yes’(默认为yes) slave会一直响应客户端的请求,但是可能会丢失一段时间的数据,或者数据正好时空的。
- 2) if replica-serve-stale-data is set to ‘no’ the replica will reply with
- an error “SYNC with master in progress” to all the kind of commands
- but to INFO, replicaOF, AUTH, PING, SHUTDOWN, REPLCONF, ROLE, CONFIG,
- SUBSCRIBE, UNSUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE, PUBLISH, PUBSUB,
- COMMAND, POST, HOST: and LATENCY.
- 2) 如果replica-serve-stale-data 设置为 ‘no’ 则salve会响应错误给客户端,但是这类命令除外。。。。
- 5. redis代理
- 5. redis一般面试问题
- 6. redis配置文件全解析
- Redis 配置案例
#关于单位,当你需要指定内存的大小时,可以使用如下的单位来指定
#(译者注,为什么会存在1000为单位,我认为是考虑到硬盘的容量单位是以1000来进行计算而非程序中的1024)
#(因此 使用 1000为单位可以进一步地精确估算出所需的实际硬盘容量)
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 10241024 bytes
# 1g => 1000000000 bytes
# 1gb => 10241024*1024 bytes
#
# 单位是大小写不敏感的 所以 1GB 1Gb 1gB 是一样的 - GENERAL
- SNAPSHOTTING
- REPLICATION
- SECURITY
- LIMITS
- APPEND ONLY MODE
- http://redis.io/topics/persistence 获取更多的信息
appendonly no
# append only file 的名称 (默认是: “appendonly.aof”)
appendfilename “appendonly.aof”
# fsync() 调用告诉操作系统立即将数据写入到硬盘中,而不是写入到输出缓冲区
# 等待足够的数据再写入。一些操作系统会立即将数据写入到硬盘中,一些其他的
#操作系统则只是尽可能快地将数据写入硬盘中
#
#
# Redis支持三种不同的模式:
#
# no:不进行强制同步,仅仅让操作系统根据自身的决策写入到硬盘中。这种速度更快
# always:在每一次追加写入操作都采用强制同步,特点是慢,安全。
# everysec:每间隔一秒钟强制同步数据。折中的方案
#
#
# 默认采用 “everysec”作为速度和安全性之间的平衡方案
# 你将根据自己的需求决定采用更快的方案或者更安全的方案。
# 选择no,何时写入数据将由操作系统决定,你可以由此获取最快的速度
# 选择always,数据将立即写入到硬盘中,你可以获得更高的数据安全性
#
# 更多的信息可以从以下地址中获取:
# http://antirez.com/post/redis-persistence-demystified.html
#
# 如果不开启该选项默认使用”everysec”.
# appendfsync always
appendfsync everysec
# appendfsync no
#
#
# 当AOF的强制写入策略设置为 always 或者 everysec,并且一个后台保存进程
#(一个后台保存进程或者 AOF 日志后台重写)会占用硬盘的大量I/O资源,在一些linux
# 的配置中redis会因为 fsync() 调用而长期锁定。特别的是在目前我们没法解决这个问题
# 即使采用另外的线程来运行强制同步也会锁定住我们的 同步 write(2)调用
#
# 为了减轻这个问题,下面的选项将会在GBSAVE 或者BGREWRITEAOF运行时
# 预防主进程调用fsync()
#
# 这意味着当另一个 子进程在保存的时候,Redis的保存策略将处于”appendfsync none”这样的类似状态
# 在实际应用当中,这意味着在最坏的情况下将会失去30秒的日志(使用linux默认的设置)
#
#
# 如果你采用yes,那么将会存在一个潜在的隐患,不然请设置它为 “no”,
# 这是一个为了稳定的安全性选择
#
no-appendfsync-on-rewrite no
# 自动改写append only 文件.
#
# redis会在AOF日志文件增长到指定百分比的时候通过调用BGREWRITEAOF来自动重写日志文件
#
# 他是这样工作的:redis会记住最后一次改写后AOF文件的大小(如果重写自重启以来
#尚未发生,那么AOF文件的大小就是启动以来使用的大小)
#
#
# 这个基准值将会和当前值进行比较,如果当前值比设定的百分比还要大,重写事件就会发生。
#
# 并且你需要指定一个AOF重写的最小值,这用来避免当重写文件的百分比增长符合目标
# 但是整个文件依然很小的时候
#
#
# 将 auto-aof-rewrite-percentage 设置为0则可以关闭掉AOF自动重写的功能
#
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb">######################## APPEND ONLY MODE ###############################
# Redis默认使用异步存储数据到硬盘上.
#
# 这个模式非常合适一些应用,但是当redis的进程出现问题
# 或者停电的时候,会丢失一些写入的数据(丢失的多少根据保存点的设置)
#
#
# Append Only 文件(Append Only file),是一个备选的持久化模型,
# 它提供了更好的续航能力,对于一个使用默认数据同步文件策略的实例
#redis可能会因为一个戏剧性的灾难比如停电等丢失一秒钟的数据
#
#或者由于redis进程本身的错误仅仅写入一个数据,但操作系统一直运行
#
#
#
# AOF和RDB可以毫无问题地共存,因此你可以同时开启他们,
#
# 如果你开启了AOF,redis会在启动时加载AOF,因为AOF有更好的鲁棒性
#
# 你可以从 http://redis.io/topics/persistence 获取更多的信息
appendonly no
# append only file 的名称 (默认是: “appendonly.aof”)
appendfilename “appendonly.aof”
# fsync() 调用告诉操作系统立即将数据写入到硬盘中,而不是写入到输出缓冲区
# 等待足够的数据再写入。一些操作系统会立即将数据写入到硬盘中,一些其他的
#操作系统则只是尽可能快地将数据写入硬盘中
#
#
# Redis支持三种不同的模式:
#
# no:不进行强制同步,仅仅让操作系统根据自身的决策写入到硬盘中。这种速度更快
# always:在每一次追加写入操作都采用强制同步,特点是慢,安全。
# everysec:每间隔一秒钟强制同步数据。折中的方案
#
#
# 默认采用 “everysec”作为速度和安全性之间的平衡方案
# 你将根据自己的需求决定采用更快的方案或者更安全的方案。
# 选择no,何时写入数据将由操作系统决定,你可以由此获取最快的速度
# 选择always,数据将立即写入到硬盘中,你可以获得更高的数据安全性
#
# 更多的信息可以从以下地址中获取:
# http://antirez.com/post/redis-persistence-demystified.html
#
# 如果不开启该选项默认使用”everysec”.
# appendfsync always
appendfsync everysec
# appendfsync no
#
#
# 当AOF的强制写入策略设置为 always 或者 everysec,并且一个后台保存进程
#(一个后台保存进程或者 AOF 日志后台重写)会占用硬盘的大量I/O资源,在一些linux
# 的配置中redis会因为 fsync() 调用而长期锁定。特别的是在目前我们没法解决这个问题
# 即使采用另外的线程来运行强制同步也会锁定住我们的 同步 write(2)调用
#
# 为了减轻这个问题,下面的选项将会在GBSAVE 或者BGREWRITEAOF运行时
# 预防主进程调用fsync()
#
# 这意味着当另一个 子进程在保存的时候,Redis的保存策略将处于”appendfsync none”这样的类似状态
# 在实际应用当中,这意味着在最坏的情况下将会失去30秒的日志(使用linux默认的设置)
#
#
# 如果你采用yes,那么将会存在一个潜在的隐患,不然请设置它为 “no”,
# 这是一个为了稳定的安全性选择
#
no-appendfsync-on-rewrite no
# 自动改写append only 文件.
#
# redis会在AOF日志文件增长到指定百分比的时候通过调用BGREWRITEAOF来自动重写日志文件
#
# 他是这样工作的:redis会记住最后一次改写后AOF文件的大小(如果重写自重启以来
#尚未发生,那么AOF文件的大小就是启动以来使用的大小)
#
#
# 这个基准值将会和当前值进行比较,如果当前值比设定的百分比还要大,重写事件就会发生。
#
# 并且你需要指定一个AOF重写的最小值,这用来避免当重写文件的百分比增长符合目标
# 但是整个文件依然很小的时候
#
#
# 将 auto-aof-rewrite-percentage 设置为0则可以关闭掉AOF自动重写的功能
#
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
- http://redis.io/topics/persistence 获取更多的信息
- LUA SCRIPTING
- SLOW LOG
- LATENCY MONITOR
- Event notification
- http://redis.io/topics/keyspace-events
#
#
#对于一个实例,如果键空间事件通知是启用状态,当一个客户端执行在一个
#存储在Database 0名为”foo”的key的DEL(删除)操作时,
#有如下两条信息将会通过发布订阅系统产生
#
#
# PUBLISH keyspace@0:foo del
# PUBLISH keyevent@0:del foo
#
#
# 以下是可选的redis事件通知,每个类别的事件可以由一个字符进行描述
#
# K Keyspace events, published with keyspace@prefix.
# E Keyevent events, published with keyevent@prefix.
# g Generic commands (non-type specific) like DEL, EXPIRE, RENAME, …
# $ String commands
# l List commands
# s Set commands
# h Hash commands
# z Sorted set commands
# x Expired events (events generated every time a key expires)
# e Evicted events (events generated when a key is evicted for maxmemory)
# A Alias for g$lshzxe, so that the “AKE” string means all the events.
#
# The “notify-keyspace-events” takes as argument a string that is composed
# by zero or multiple characters. The empty string means that notifications
# are disabled at all.
#
# 例子1: 启用 list 和 generic 事件,
#
# notify-keyspace-events Elg
#
# 例子2 2: 要想订阅通道名为keyevent@0:expired 上expired keys的事件:
#
# notify-keyspace-events Ex
#
#
# 默认不启用所有的通知,因为大部分的用户不需要这些功能,而且这些功能会带来一些开销
#
# 如果你没有指定 K 或者 E,没有事件会被传递
#
notify-keyspace-events “”
">####################### Event notification ##############################
#redis 可以在key 空间中采用发布订阅模式来通知事件的发生
#
#这个功能的文档可以查看 http://redis.io/topics/keyspace-events
#
#
#对于一个实例,如果键空间事件通知是启用状态,当一个客户端执行在一个
#存储在Database 0名为”foo”的key的DEL(删除)操作时,
#有如下两条信息将会通过发布订阅系统产生
#
#
# PUBLISH keyspace@0:foo del
# PUBLISH keyevent@0:del foo
#
#
# 以下是可选的redis事件通知,每个类别的事件可以由一个字符进行描述
#
# K Keyspace events, published with keyspace@prefix.
# E Keyevent events, published with keyevent@prefix.
# g Generic commands (non-type specific) like DEL, EXPIRE, RENAME, …
# $ String commands
# l List commands
# s Set commands
# h Hash commands
# z Sorted set commands
# x Expired events (events generated every time a key expires)
# e Evicted events (events generated when a key is evicted for maxmemory)
# A Alias for g$lshzxe, so that the “AKE” string means all the events.
#
# The “notify-keyspace-events” takes as argument a string that is composed
# by zero or multiple characters. The empty string means that notifications
# are disabled at all.
#
# 例子1: 启用 list 和 generic 事件,
#
# notify-keyspace-events Elg
#
# 例子2 2: 要想订阅通道名为keyevent@0:expired 上expired keys的事件:
#
# notify-keyspace-events Ex
#
#
# 默认不启用所有的通知,因为大部分的用户不需要这些功能,而且这些功能会带来一些开销
#
# 如果你没有指定 K 或者 E,没有事件会被传递
#
notify-keyspace-events “”
- http://redis.io/topics/keyspace-events
- ADVANCED CONFIG
1. redis安装/部署
1.1 基本安装
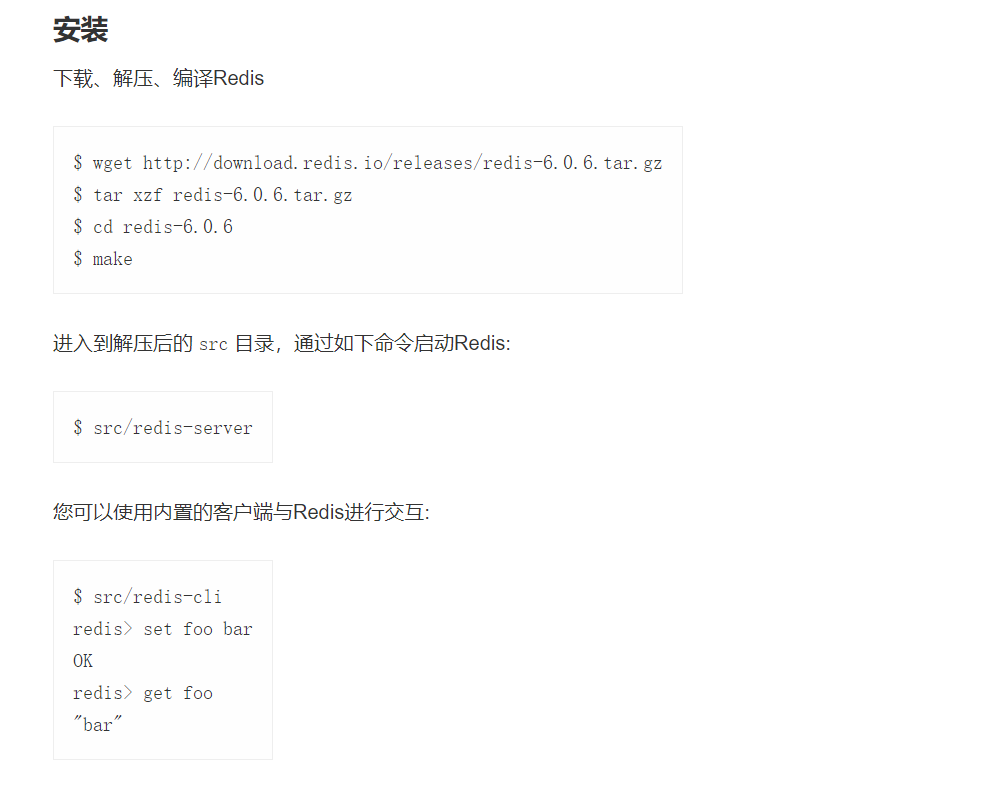
基本安装看官网就行了
1.2 将redis-server 变成服务。
先统一路径:
- redis下载在
{redis_dowland_path}下面 - redis解压在
{redis_source_path}下面 - redis安装在
{redis_install_path}下面
- 配置redis环境变量
在最后一行添加:$ cd {redis_source_path}$ make PREFIX={redis_install_path} install$ vi /etc/profile
export REDIS_HOME=
{redis_install_path}export PATH=$PATH:$REDIS_HOME/bin
保存退出, 使配置文件生效:
source /etc/profile
至此就可以使用service命令开启redis了。
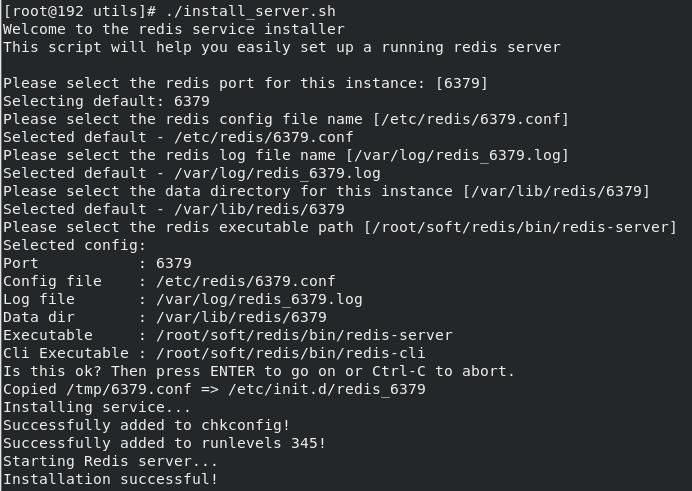
2、执行install_server.sh
$ {redis_source_path}/utils/install_server.sh
Linux安装Redis 6.0.5 ./install_server.sh报错 进行到
./install_server.sh时报错, This systems seems to use systemd. Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry! 解决方案:vi >{redis_source_path/install_server.sh> 注释下面的代码>> 然后重新运行
{redis_source_path/install_server.sh即可。
- 依次按照提示下一步即可。
2. redis 存储类型
1.string
1.2 list
1.3 hash
1.4 set
1.5 zset
1.6 二进制安全
3. redis进阶
3.1 发布/订阅模式
3.2 事务
4. redis高可用
4.1 持久化
复制原理:父子进程间数据可见但修改不可见。
copy on write(写时复制)
fork()函数
save和bqsave的区别:
save是阻塞的。bgsave会开辟后台进程,不会阻塞主进程。
save使用场景是:要关机或者要停止redis等非常明确的停止动作时保存数据。
bgsave使用场景是:无感知地、不影响/不阻塞当前主进程服务的备份时使用bgsave。
弊端:
不支持拉链,永远只有一个dump.rdb- 由于是时点备份,而不是实时备份,所以一旦宕机,
丢失数据相对多。
优势:
- 恢复速度相对快,类似于java中的序列化转对象和json转对象的对比,序列化是二进制直接转对象,而json需要分析语法,分析变量类型等才能转化为对象。
4.1 AOF
Append Only File。 类似于mysql的binlog,实时把数据写到文件中。
优势:
- 丢失数据相对少。
- AOF和rdb是可以同时使用的,但是恢复时只会AOF恢复。4.0版本以后,AOF = rdb+增量。
弊端:
- 因为是 一直增量添加指令, 体量会无限变大。恢复时间会无限变长、且带有溢出危险。
4.0版本以前使用重写命令的方式,
- 同一个key创建和删除抵消。
SET age 1; DEL age; - 合并重复命令:
LPUSH L1 1; LPUSH L1 2; LPUSH L1 3; LPUSH L1 4; 合并为: LPUSH L1 1 2 3 4;
4.0版本开始使用rdb+增量的方式。内含一个RDB的二进制文件, 增量的使用明文指令的方式。
因为AOF是往磁盘写数据,所以会拖慢redis性能,所以redis有3个刷新文件缓冲区设置
appendfsync always 实时刷新 appendfsync everysec 每秒刷新appendfsync no 不刷新,让内核自己判断。有可能会丢失一个缓冲区大小的日志数据。
4.2 主从复制
单机redis的缺陷:
- 单点故障
- 容量有限
- 硬件压力
本机主从模式拓扑图: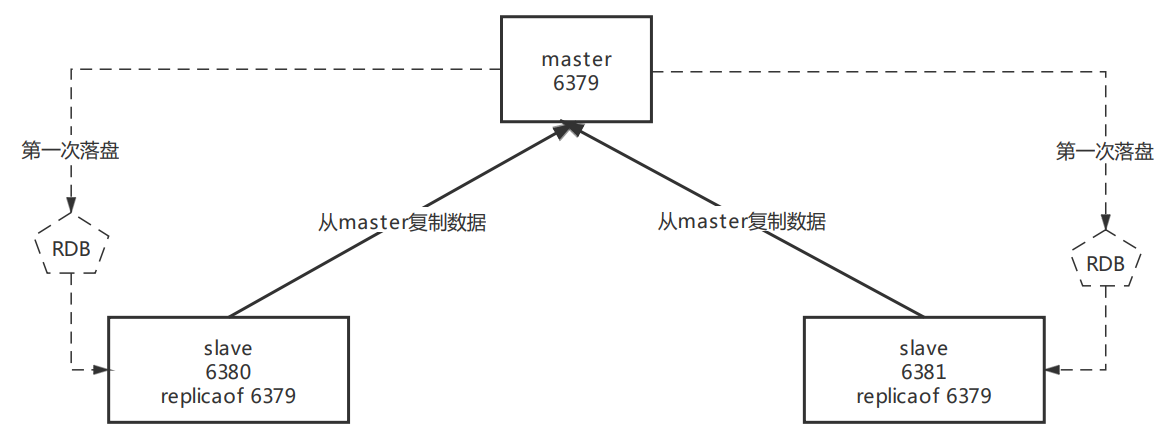
创建主从复制:
- 创建伪集群
使用 {redis_source_path}/utils/install_server.sh 创建3个端口号,分别是 6379、6380、6381。 并且在 /etc/redis/下面找到这3个配置文件
[root@192 ~]# cd /etc/redis/[root@192 redis]# lltotal 252-rw-r--r--. 1 root root 83461 Feb 17 19:12 6379.conf-rw-r--r--. 1 root root 83468 Feb 17 19:12 6380.conf-rw-r--r--. 1 root root 83468 Feb 17 19:13 6381.conf[root@192 redis]#
- 修改配置文件
$ vim /etc/redis/6379.conf
daemonize no : 关闭后台运行, 让所有日志都打印在控制台,便于查看redis运行状况。
logfile /var/log/redis_6379.log:注释掉日志文件
【注意】生产环境不能这样
- 6380.conf 和 6381.conf 配置文件同上。
分别启动 6379、6380、6381端口。我们把6379当做master,把6380、6381当做salve。所以需要进入6380、6381的客户端分别输入
REPLICAOF localhost 6379去追随6379的日志。[root@192 ~]# redis-cli -p 6380127.0.0.1:6380> REPLICAOF 127.0.0.1 6379OK127.0.0.1:6380>
[root@192 ~]# redis-cli -p 6381127.0.0.1:6381> REPLICAOF 127.0.0.1 6379OK127.0.0.1:6381>
查看6379的控制台:
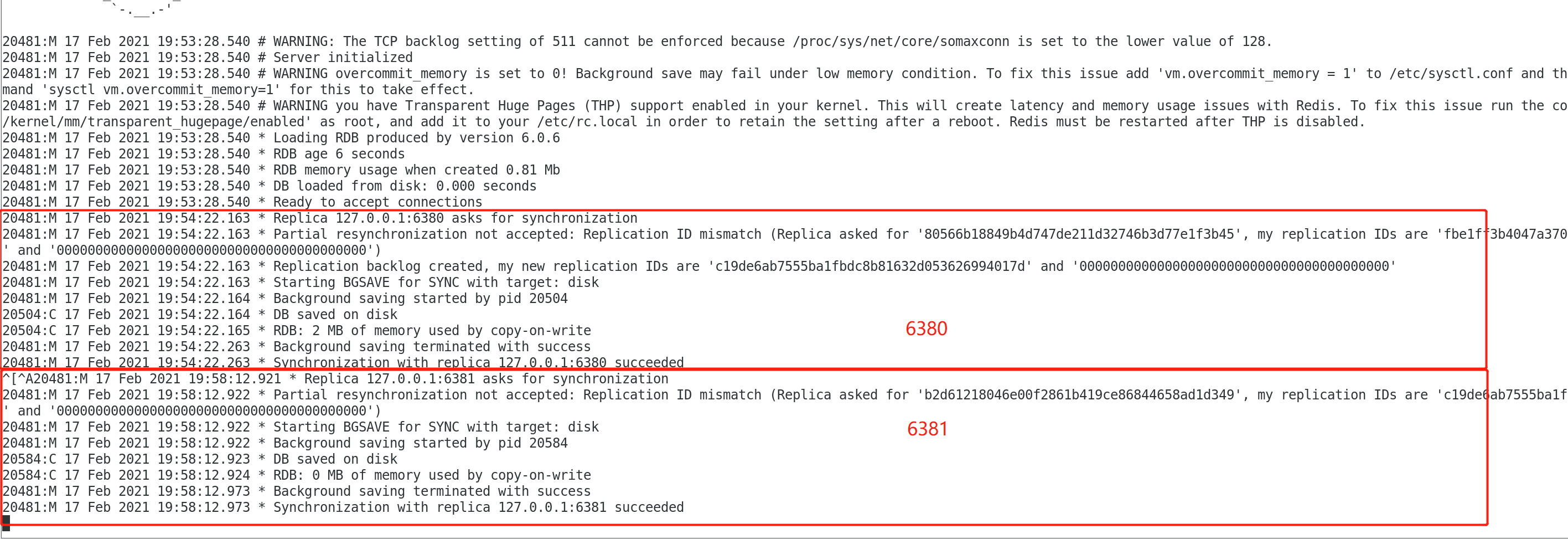
- 验证
在6379上随便设置一个k1:
[root@192 ~]# redis-cli -p 6379127.0.0.1:6379> set k1 wangfanOK127.0.0.1:6379>
在6380上查看k1:
[root@192 ~]# redis-cli -p 6380127.0.0.1:6380> get k1"wangfan"127.0.0.1:6380>
在6381上查看k1:
[root@192 ~]# redis-cli -p 6381127.0.0.1:6381> get k1"wangfan"127.0.0.1:6381>
至此,6380、6381同步复制6379的配置设置成功。
其他理论:
- 默认情况下的redis的salve是禁止写入的。
- 从日志的情况来看,salve初始化时使用的是RDB模式让master把RDB数据落盘到slave上。
- 如果在使用
REPLICAOF之前salve就有数据的话,使用REPLICAOF之后salve数据会被清空。 - 如果salve中途挂掉,则salve再次重启时同步master数据属于增量同步。
【注意】这样的主从复制只是虽然解决了单点故障和硬件压力,但是由于多台同时工作,所以故障率也会相应提高,如果salve或者master挂掉一台的话都需要人手动重启。 那么有没有一种自动化部署,自动化故障转移呢?有的,看下面的“哨兵模式”
主从复制的其他参数:
replica-serve-stale-data yes:
When a replica loses its connection with the master, or when the replication
is still in progress, the replica can act in two different ways:
当salve与master端开链接、或者正在进行复制数据时,salve会表现出2种不同的行为
#
1) if replica-serve-stale-data is set to ‘yes’ (the default) the replica will
still reply to client requests, possibly with out of date data, or the
data set may just be empty if this is the first synchronization.
1) 如果replica-serve-stale-data 设置为 ‘yes’(默认为yes) slave会一直响应客户端的请求,但是可能会丢失一段时间的数据,或者数据正好时空的。
2) if replica-serve-stale-data is set to ‘no’ the replica will reply with
an error “SYNC with master in progress” to all the kind of commands
but to INFO, replicaOF, AUTH, PING, SHUTDOWN, REPLCONF, ROLE, CONFIG,
SUBSCRIBE, UNSUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE, PUBLISH, PUBSUB,
COMMAND, POST, HOST: and LATENCY.
2) 如果replica-serve-stale-data 设置为 ‘no’ 则salve会响应错误给客户端,但是这类命令除外。。。。
replica-serve-stale-data yes
4.3 哨兵模式
- 监控
- 通知
- 故障自动转移
哨兵模式拓扑图: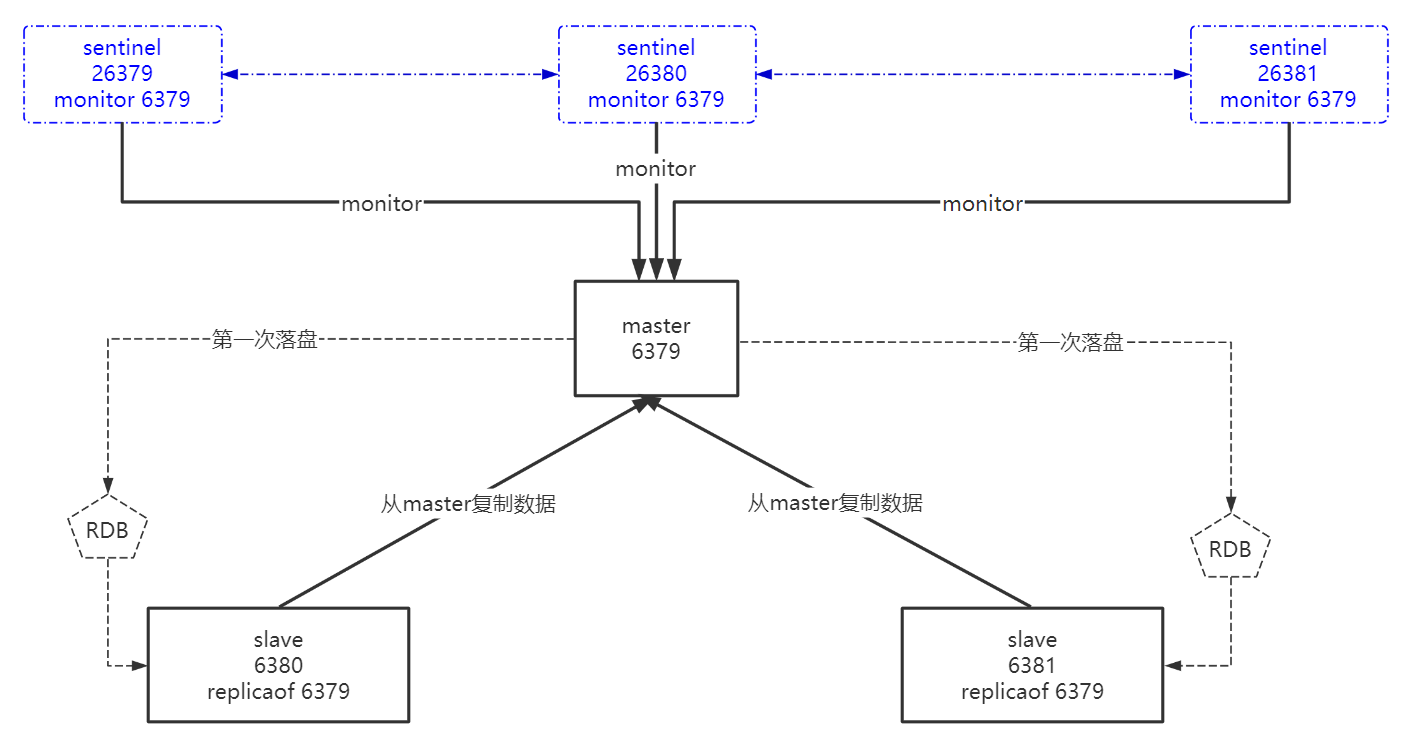
- 在
/etc/redis/下新增26379.conf、26380.conf、26381.conf3个配置文件,并增加如下内容
26379.conf:
port 26379sentinel monitor mymaster 127.0.0.1 6379 2
26380.conf:
port 26380sentinel monitor mymaster 127.0.0.1 6379 2
26381.conf:
port 26381sentinel monitor mymaster 127.0.0.1 6379 2
新增后的目录如下:
[root@192 redis]# lltotal 264-rw-r--r--. 1 root root 54 Feb 17 22:46 26379.conf-rw-r--r--. 1 root root 54 Feb 17 22:48 26380.conf-rw-r--r--. 1 root root 54 Feb 17 22:48 26381.conf-rw-r--r--. 1 root root 83461 Feb 17 19:12 6379.conf-rw-r--r--. 1 root root 83468 Feb 17 19:12 6380.conf-rw-r--r--. 1 root root 83468 Feb 17 19:13 6381.conf[root@192 redis]#
启动哨兵
哨兵模式需要主从复制为基础,所以之前的主从复制还是需要的。
首先启动1个master和2个slave$ redis-server /etc/redis/6379.conf$ redis-server /etc/redis/6380.conf --REPLICAOF 127.0.0.1 6379$ redis-server /etc/redis/6381.conf --REPLICAOF 127.0.0.1 6379
然后启动3个哨兵
$ redis-server /etc/redis/26379.conf --sentinel$ redis-server /etc/redis/26380.conf --sentinel$ redis-server /etc/redis/26381.conf --sentinel
关闭6379服务, 查看26380的控制台:

查看26381的控制台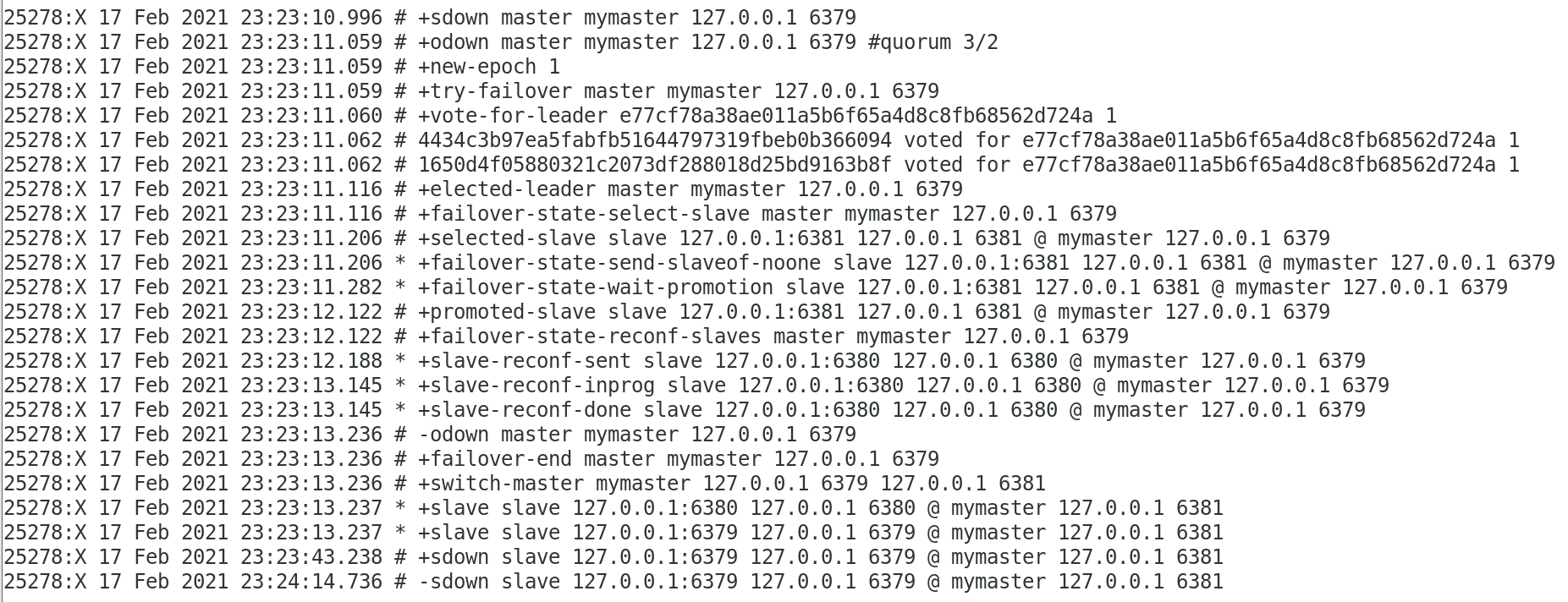
观察26380.conf配置文件: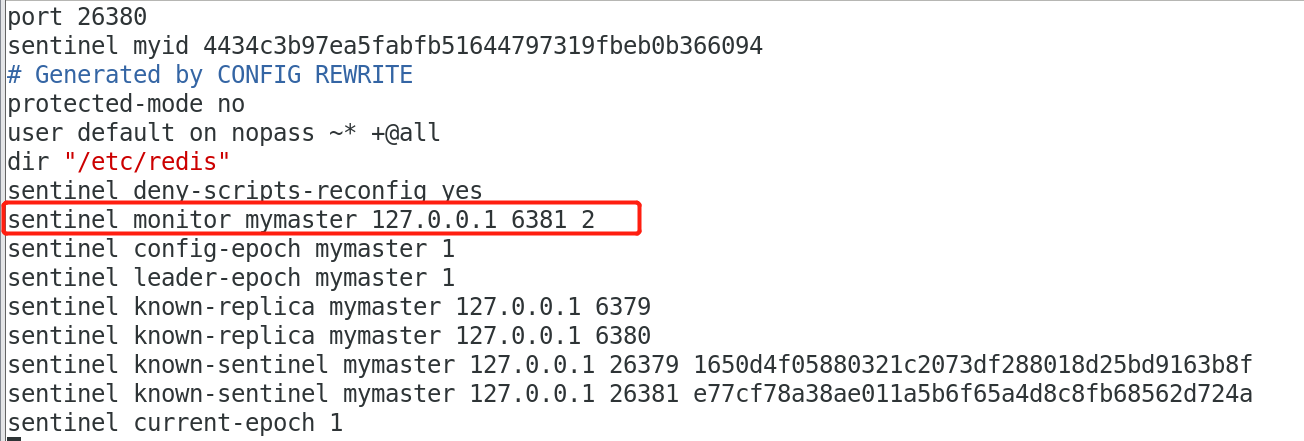
发现哨兵监控已被默认改为6381服务。
观察26381.conf配置文件: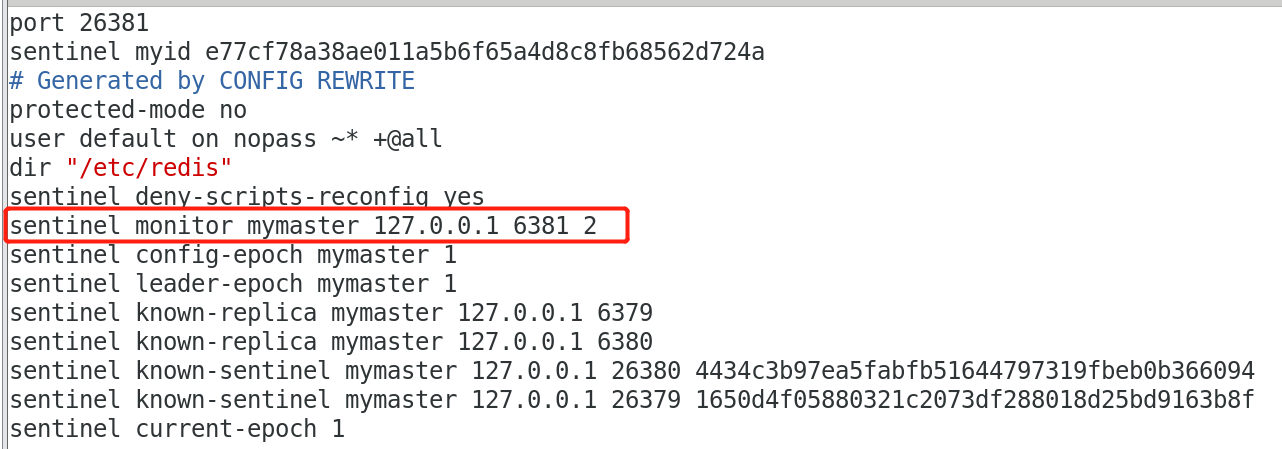
发现哨兵监控已被默认改为6381服务。
5. redis代理
哨兵模式有很多优势、没有单点故障、故障自动转移、主从复制等等。但是哨兵模式并没有解决存储压力,所有的节点的存储的数据是一样的,也就是说,哨兵模式并没有把数据分片(sharding)。
5.1 不同的分区实现方案
分区可以在程序的不同层次实现。
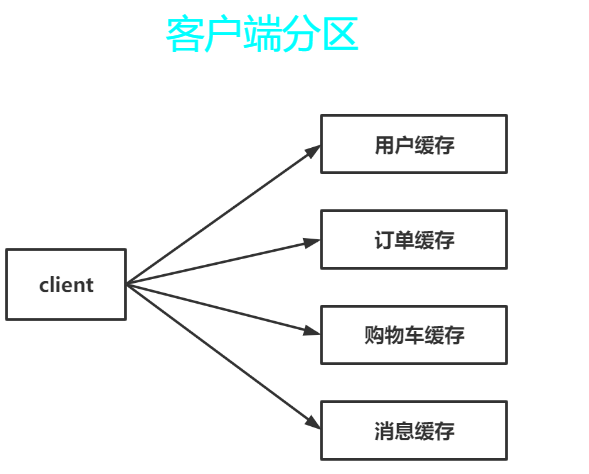
- 客户端分区: 就是在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。比如:规定redis01为用户缓存,redis02为订单缓存等。
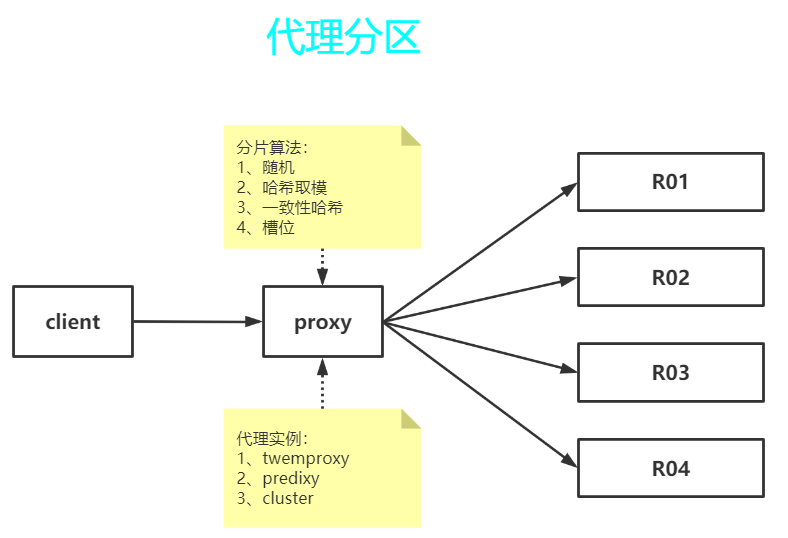
- 代理分区 意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy
- 查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。
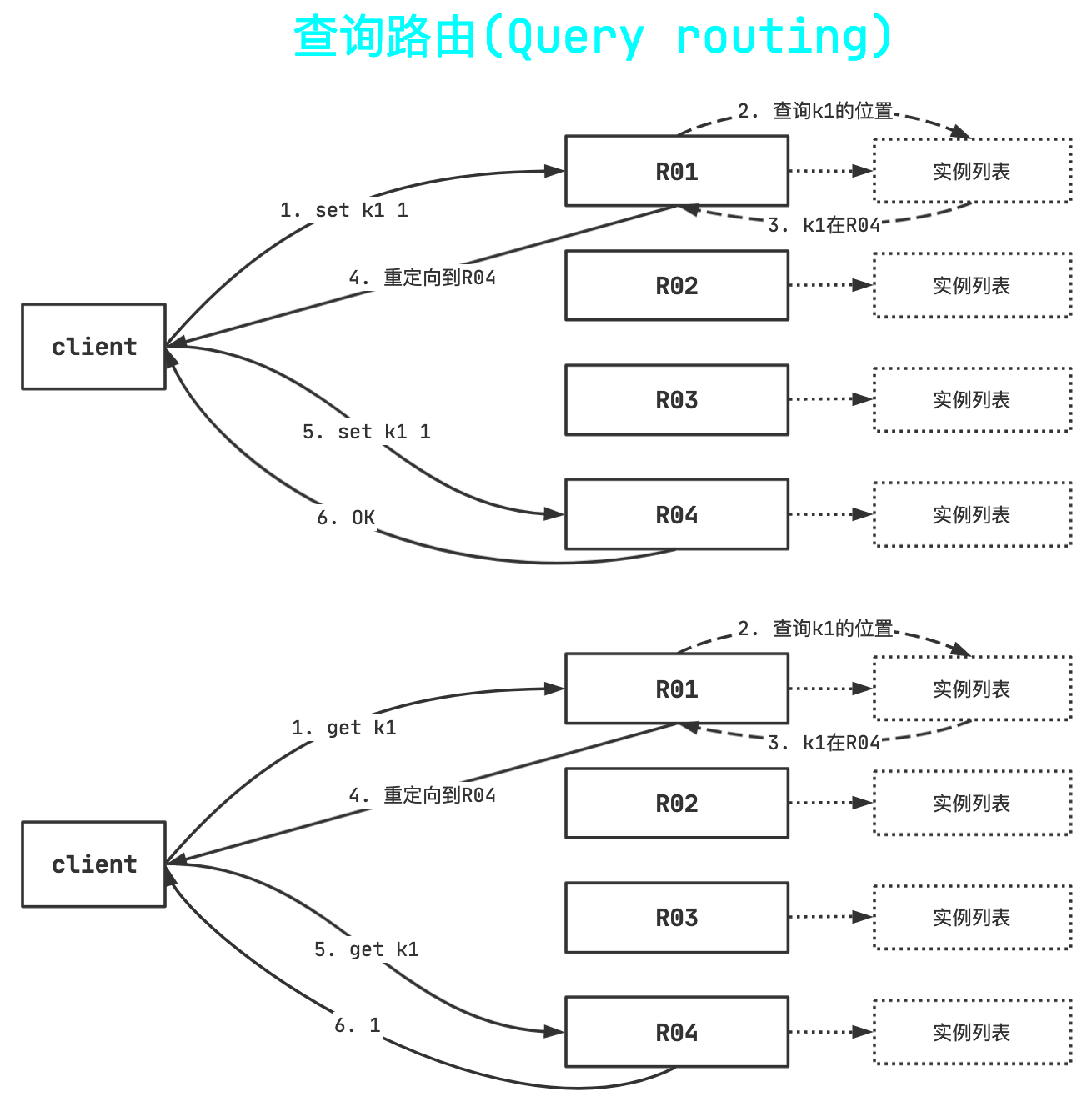
Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
5.2 代理分区时的分片方案:
- 范围分区: 就是将不同范围的对象映射到不同Redis实例。比如说,用户ID从0到10000的都被存储到R0,用户ID从10001到20000被存储到R1,依此类推。
这是一种可行方案并且很多人已经在使用。但是这种方案也有缺点,你需要建一张表存储数据到redis实例的映射关系。这张表需要非常谨慎地维护并且需要为每一类对象建立映射关系,所以redis范围分区通常并不像你想象的那样运行,比另外一种分区方案效率要低很多。
- 散列分区:就是对key进行hash运算后取模。这种分区方式的缺点是模数不能变,如果增加或者减少的话会影响很大部分的数据进行迁移。
- 一致性哈希:一致性哈希的目的就是为了在节点数目发生改变时尽可能少的迁移数据,将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash 后会顺时针找到临接的存储节点存放。而当有节点加入或退 时,仅影响该节点在Hash环上顺时针相邻的后续节点。
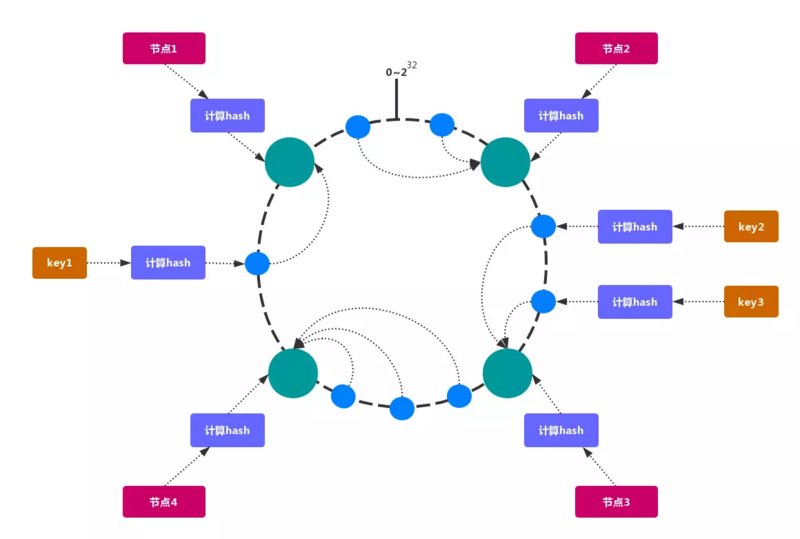
一致性哈希的优点:加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。最大程度减少了增加或者减少redis实例时对数据迁移的成本。
一致性哈希的缺点:数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
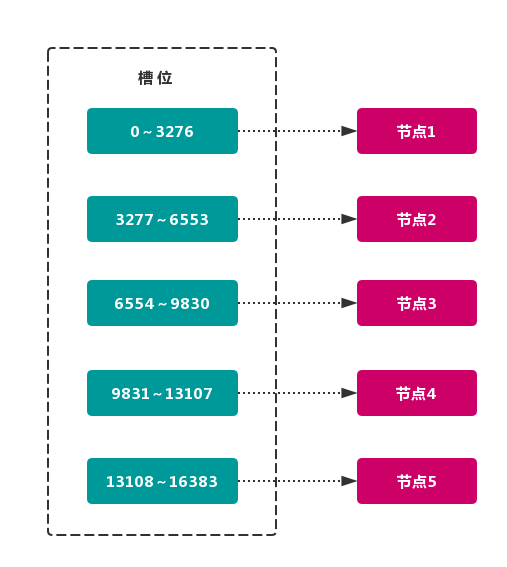
- 虚拟槽分区:本质上还是第一种的普通哈希算法,把全部数据离散到指定数量的哈希槽中,把这些哈希槽按照节点数量进行了分区。这样因为哈希槽的数量的固定的,添加节点也不用把数据迁移到新的哈希槽,只要在节点之间互相迁移就可以了,即保证了数据分布的均匀性,又保证了在添加节点的时候不必迁移过多的数据。Redis的集群模式使用的就是虚拟槽分区,一共有16383个槽位平均分布到节点上
分片的优势:解决存储压力
分片的弊端:1. 聚合操作很难实现。2.食物很难实现。
hashtag:
聚合操作和事务很难实现的原因时我们把数据分片,而且我们不知道数据到底时存储在哪一个实例中,如果我们知道一类数据确定都存储在一个实例中,那么分片下的聚合操作和事务就可以实现。hashtage就是这样一种解决方式。 hastage是把key给规范化,统一的去一个公用的前缀,比如说:用户数据都以{user}来作为前缀,
例如:
{user}1
{user}2
{user}3
{user}4
{user}10000
代理只会把{user}做哈希运算这样取得的结果都是一样,自然分片到的分区也是一样的,这样就能确定此类数据都是存储在一个实例上的,自然也就能实现聚合、事务等操作了。
5.3 twemproxy
github地址: https://github.com/twitter/twemproxy
假设:twemproxy的下载路径为:{twemproxy_download_path}
下载、安装、配置、编译
$ cd {twemproxy_download_path}$ git clone git@github.com:twitter/twemproxy.git$ cd twemproxy$ autoreconf -fvi$ ./configure --enable-debug=full$ make
启动3个redis实例(不能是主从、也不能是哨兵)
$ redis-server --port 6379$ redis-server --port 6380$ redis-server --port 6381
修改twemproxy配置文件
$ cp {twemproxy_download_path}/conf/nutcraker.yml {twemproxy_download_path}/conf/nutcraker.yml.bak$ vim {twemproxy_download_path}/conf/nutcraker.yml
只保留alpha的实例,其他的删除。
修改alpha下面的servers列表:alpha:listen: 127.0.0.1:22121hash: fnv1a_64distribution: ketamaauto_eject_hosts: trueredis: trueserver_retry_timeout: 2000server_failure_limit: 1servers:- 127.0.0.1:6379:1- 127.0.0.1:6380:1- 127.0.0.1:6381:1
启动twemproxy
$ {twemproxy_download_path}/src/nutcraker -c {twemproxy_download_path}/conf/nutcraker.yml
控制台显示成功

验证
使用redis-cli链接到代理
[root@192 ~]# redis-cli -p 22121127.0.0.1:22121> set k1 1OK127.0.0.1:22121> set k2 2OK127.0.0.1:22121> set k3 3OK127.0.0.1:22121> set k4 4OK127.0.0.1:22121> set 1 1OK127.0.0.1:22121> set name hahahaOK127.0.0.1:22121> set {user}1 1OK127.0.0.1:22121> set {user}2 2OK127.0.0.1:22121> set {user}3 3OK127.0.0.1:22121> set {user}4444 4444OK127.0.0.1:22121> keys *Error: Server closed the connection127.0.0.1:22121>
5.4 predixy
github地址:https://github.com/joyieldInc/predixy
假设:predixy的下载路径为:{predixy_download_path}
5.5 cluster
自动创建集群:
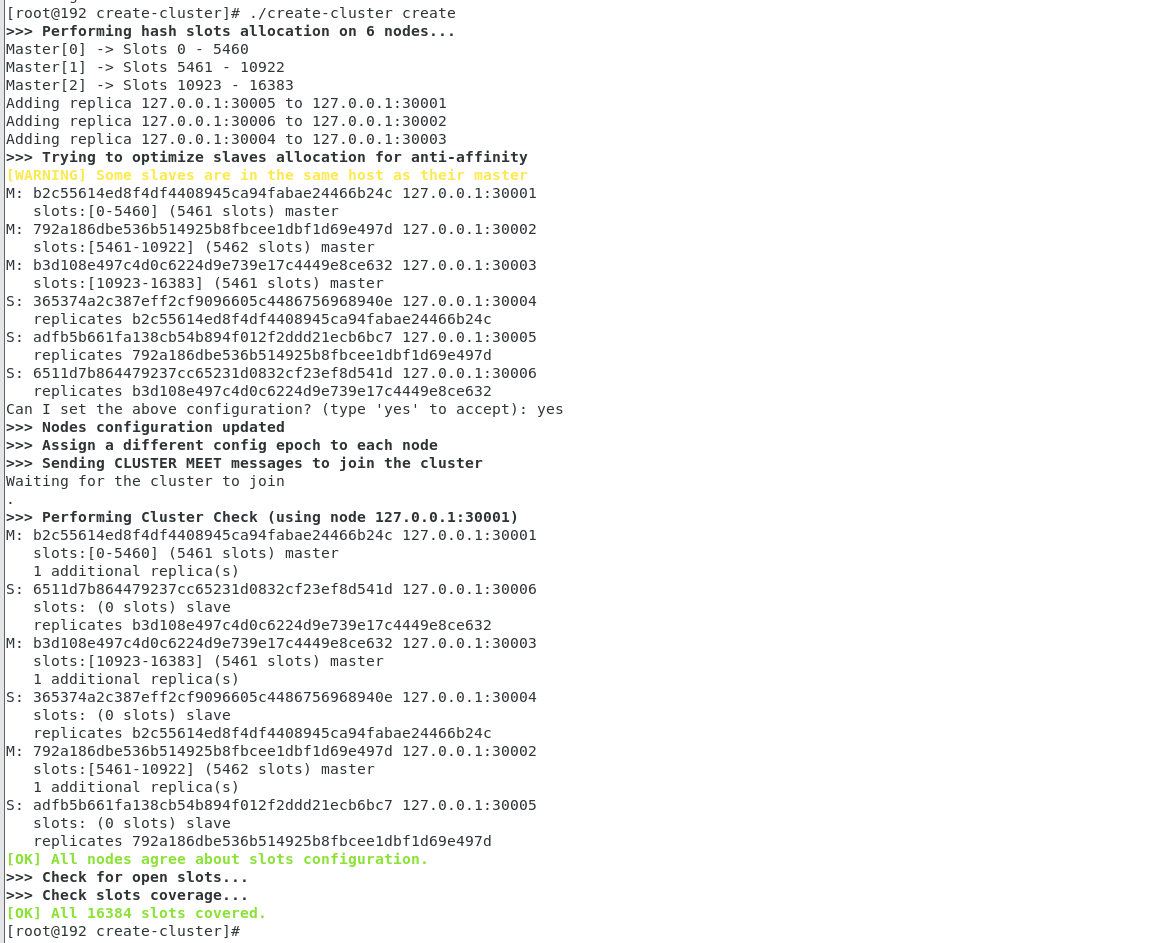
$ cd {redis_source_path}/utils$ ./create-cluster start$ ./create-cluster create$ ./create-cluster start
Starting 30001 Starting 30002 Starting 30003 Starting 30004
Starting 30005
Starting 30006
$ ./create-cluster create
Performing hash slots allocation on 6 nodes…
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:30005 to 127.0.0.1:30001
Adding replica 127.0.0.1:30006 to 127.0.0.1:30002
Adding replica 127.0.0.1:30004 to 127.0.0.1:30003
Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: b2c55614ed8f4df4408945ca94fabae24466b24c 127.0.0.1:30001
slots:[0-5460] (5461 slots) master
M: 792a186dbe536b514925b8fbcee1dbf1d69e497d 127.0.0.1:30002
slots:[5461-10922] (5462 slots) master
M: b3d108e497c4d0c6224d9e739e17c4449e8ce632 127.0.0.1:30003
slots:[10923-16383] (5461 slots) master
S: 365374a2c387eff2cf9096605c4486756968940e 127.0.0.1:30004
replicates b2c55614ed8f4df4408945ca94fabae24466b24c
S: adfb5b661fa138cb54b894f012f2ddd21ecb6bc7 127.0.0.1:30005
replicates 792a186dbe536b514925b8fbcee1dbf1d69e497d
S: 6511d7b864479237cc65231d0832cf23ef8d541d 127.0.0.1:30006
replicates b3d108e497c4d0c6224d9e739e17c4449e8ce632
Can I set the above configuration? (type ‘yes’ to accept): yes
Nodes configuration updated
Assign a different config epoch to each node
Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
Performing Cluster Check (using node 127.0.0.1:30001)
M: b2c55614ed8f4df4408945ca94fabae24466b24c 127.0.0.1:30001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 6511d7b864479237cc65231d0832cf23ef8d541d 127.0.0.1:30006
slots: (0 slots) slave
replicates b3d108e497c4d0c6224d9e739e17c4449e8ce632
M: b3d108e497c4d0c6224d9e739e17c4449e8ce632 127.0.0.1:30003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 365374a2c387eff2cf9096605c4486756968940e 127.0.0.1:30004
slots: (0 slots) slave
replicates b2c55614ed8f4df4408945ca94fabae24466b24c
M: 792a186dbe536b514925b8fbcee1dbf1d69e497d 127.0.0.1:30002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: adfb5b661fa138cb54b894f012f2ddd21ecb6bc7 127.0.0.1:30005
slots: (0 slots) slave
replicates 792a186dbe536b514925b8fbcee1dbf1d69e497d
[OK] All nodes agree about slots configuration.
Check for open slots…
Check slots coverage…
[OK] All 16384 slots covered.
$ redis-cli -c -p 30001127.0.0.1:30001>127.0.0.1:30001> set k1 1-> Redirected to slot [12706] located at 127.0.0.1:30003OK127.0.0.1:30003> set k2 2-> Redirected to slot [449] located at 127.0.0.1:30001OK127.0.0.1:30001> set k3 3OK127.0.0.1:30001> get k2"2"127.0.0.1:30001> get k1-> Redirected to slot [12706] located at 127.0.0.1:30003"1"127.0.0.1:30003> WATCH k1OK127.0.0.1:30003> MULTIOK127.0.0.1:30003> set k6 6-> Redirected to slot [325] located at 127.0.0.1:30001OK127.0.0.1:30001> set k7 7OK127.0.0.1:30001> set k8 8-> Redirected to slot [8331] located at 127.0.0.1:30002OK127.0.0.1:30002> EXEC(error) ERR EXEC without MULTI127.0.0.1:30002> set {kk}k9 9-> Redirected to slot [2589] located at 127.0.0.1:30001OK127.0.0.1:30001> WATCH {kk}k9OK127.0.0.1:30001> MULTIOK127.0.0.1:30001> set {kk}k10 10QUEUED127.0.0.1:30001> set {kk}k11 11QUEUED127.0.0.1:30001> set {kk}K12 12QUEUED127.0.0.1:30001> set {kk}k13 13QUEUED127.0.0.1:30001> EXEC1) OK2) OK3) OK4) OK127.0.0.1:30001>
5. redis一般面试问题
6. redis配置文件全解析
Redis 配置案例
Redis 配置案例
#关于单位,当你需要指定内存的大小时,可以使用如下的单位来指定
#(译者注,为什么会存在1000为单位,我认为是考虑到硬盘的容量单位是以1000来进行计算而非程序中的1024)
#(因此 使用 1000为单位可以进一步地精确估算出所需的实际硬盘容量)
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 10241024 bytes
# 1g => 1000000000 bytes
# 1gb => 10241024*1024 bytes
#
# 单位是大小写不敏感的 所以 1GB 1Gb 1gB 是一样的
INCLUDES
############################ INCLUDES ###################################
#
#如果你拥有一个标准的配置模板,并且希望在该模板之上坐一些个性化的修改,你可以
#使用include 指令来引入其他的配置文件。
#
#注意:”include” 不会被 admin 或者 Redis Sentinel “CONFIG REWRITE” 命令覆盖。
#(译者注:”CONFIG REWRITE” 是redis 2.8 引入的新命令,用来重写配置)
#由于redis以最终的配置作为实际配置,因此我们希望你将include命令放置在配置文件的最前面
#以防配置被覆盖
#如果你打算使用另外的 conf文件来覆盖当前文件的配置,那么最好将include指令放置到该文件的末尾
#
# 即最后生效原则,最后被解析的配置将作为最后的配置
#
# include /path/to/local.conf
# include /path/to/other.conf
GENERAL
########################## GENERAL #####################################
# redis 默认不是以一个守护进程来运行的,使用 yes,可以让redis作为守护进程来运行
# 注意:当redis作为守护进程的时候 /var/run/redis.pid 作为 pid 文件
#
daemonize no
# 当redis以守护进程运行时,将会使用/var/run/redis.pid作为 pid文件的位置,也就是
#上一个指令所说的默认,你可以根据自己的需要修改它
#
pidfile /var/run/redis.pid
# 在指定的端口上进行监听,默认是 6379
# 如果端口设置为0,那么redis就不会在TCP socket上进行监听
# (译者注:不在tcp socket上进行监听,不代表没法连接,只是无法使用网络连接而已)
port 6379
# TCP listen() backlog值
#(译者注:backlog值是指目前最大的连接队列,因为TCP连接是三次握手)
#(没有完成三次握手和尚未被accept的connect都会处于连接队列中,但是backlog的实际值与操作系统相关)
#(并非设置多少就是多少,只能说调整得大一些可以在同一时间应对更多的连接请求)
#
#在一个并发量高的环境中,你需要指定一个比较大的backlog值来避免慢连接(由于网络原因握手速度慢)的情况
#注意,linux内核会默认 使用/proc/sys/net/core/somaxconn 的值来削减 backlog的实际值,
#因此你需要确保提升 somaxconn 和 tcp_max_syn_backlog 这两个值来确保此处的backlog生效
#(译者注:只有 当每一个请求都重新发起一个连接的时候,backlog值的增大才能影响到并发量)
#(在tcp稳定连接的时候,或连接复用(连接池的使用),backlog值对并发没有任何影响)
#
tcp-backlog 511
#
#默认情况下redis会在所有的可用网络接口中进行监听,如果你想让redis在指定的网络接口中
#监听,那么可以使用bind 命令来指定redis的监听接口
#(译者科普:网络的中的服务是通过 ip+进程 来进行区分的,当一个服务器拥有两个ip时 )
#(自然就在网络中拥有两个人身份,如 内网,外网,当你只想让redis在一个网络上监听时,就可以使用如下的配置)
# (127.0.0.1 就是指定只能本机进行网络访问)
# 例如:
#
# bind 192.168.1.100 10.0.0.1
# bind 127.0.0.1
#
#指定unix sock的路径来进行连接监听,默认是不指定,因此redis不会在unix socket上进行监听
#(译者注:这个是用来进行进程间通信的时候指定的)
# unixsocket /tmp/redis.sock
# unixsocketperm 755
# 关闭掉空闲N秒的连接(0则是不处理空闲连接)
timeout 0
# TCP keepalive.
#
#
#如果该值不为0,将使用 SO_KEEPALIVE 这一默认的做法来向客户端连接发送TCP ACKs
#
#这样的好处有以下两个原因
# 1)检测已经死亡的对端(译者注:TCP的关闭会存在无法完成4次握手的情况,如断电,断网,数据丢失等等)
# 2)保持连接在网络环境中的存活
#
#
tcp-keepalive 0
# 指定日志的记录级别的
# 可以是如下的几个值之一
# debug (尽可能多的日志信息,用于开发和测试之中)
# verbose (少但是有用的信息, 没有debug级别那么混乱)
# notice (适量的信息,用于生产环境)
# warning (只有非常重要和关键的信息会被记录)
loglevel notice
# 指定日志文件的位置. 为空时将输出到标准输出设备
# 如果你在demo模式下使用标准输出的日志,日志将会输出到 /dev/null
logfile “”
# 当设置 ‘syslog-enabled’为 yes时, 允许记录日志到系统日志中。
# 以及你可以使用更多的日志参数来满足你的要求
# syslog-enabled no
# 指定在系统日志中的身份
# syslog-ident redis
# 指定系统日志的能力. 必须是 LOCAL0 到 LOCAL7 之间(闭区间).
# syslog-facility local0
#设置数据库的编号. 默认的数据库是DB 0
#使得你可以在每一个连接的基础之上使用 SELECT 来指定另外的数据库,但是这个值必须在 0到 ‘database’-1之间
databases 16
databases 16
SNAPSHOTTING
########################## SNAPSHOTTING ################################
#
# 保存 DB 到硬盘:
#
# save
#
# 将会在 和 两个值同时满足时,将DB数据保存到硬盘中
# 其中 每多少秒,是改变的key的数量
#
# 在以下的例子中,将会存在如下的行为
# 当存在最少一个key 变更时,900秒(15分钟)后保存到硬盘
# 当存在最少10个key变更时,300秒后保存到硬盘
# 当存在最少1000个key变更时,60秒后保存到硬盘
#
# 提示: 你可以禁用如下的所有 save 行
#
# 你可以删除所有的save然后设置成如下这样的情况
#
#
#
# save “”
save 900 1
save 300 10
save 60 10000
#
# 作为默认,redis会在RDB快照开启和最近后台保存失败的时候停止接受写入(最少一个保存点)
#这会使得用户察觉(通常比较困难)到数据不会保持在硬盘上的正确性,否则很难发现
#这些灾难会发生
#
# 如果后台保存程序再次开始工作,reidis会再次自动允许写入
#
#然而如果对redis服务器设置了合理持续的监控,那么你可以关闭掉这个选项。
#这会导致redis将继续进行工作,无论硬盘,权限或者其他的是否有问题
#
#
stop-writes-on-bgsave-error yes
# 是否在dump到 rdb 数据库的时候使用LZF来压缩字符串
# 默认是 yes,因为这是一个优良的做法
#
# 如果你不想耗费你的CPU处理能力,你可以设置为 no,但是这会导致你的数据会很大
rdbcompression yes
# 从RDB的版本5开始,CRC64校验值会写入到文件的末尾
#这会使得格式化过程中,使得文件的完整性更有保障,但是这会在保存和加载的时候损失不少的性能(大概在10%)
#你可以关闭这个功能来获得最高的性能
#
#RDB文件会在校验功能关闭的时候,使用0来作为校验值,这将告诉加载代码来跳过校验步骤
rdbchecksum yes
# DB的文件名称
dbfilename dump.rdb
# 工作目录.
#
# DB将会使用上述 ‘dbfilename’指定的文件名写入到该目录中
#
# 追加的文件也会在该目录中创建
#
# 注意,你应该在这里输入的是一个目录而不是一个文件名
dir ./
#
# 将会在
# 其中
#
# 在以下的例子中,将会存在如下的行为
# 当存在最少一个key 变更时,900秒(15分钟)后保存到硬盘
# 当存在最少10个key变更时,300秒后保存到硬盘
# 当存在最少1000个key变更时,60秒后保存到硬盘
#
# 提示: 你可以禁用如下的所有 save 行
#
# 你可以删除所有的save然后设置成如下这样的情况
#
#
#
# save “”
save 900 1
save 300 10
save 60 10000
#
# 作为默认,redis会在RDB快照开启和最近后台保存失败的时候停止接受写入(最少一个保存点)
#这会使得用户察觉(通常比较困难)到数据不会保持在硬盘上的正确性,否则很难发现
#这些灾难会发生
#
# 如果后台保存程序再次开始工作,reidis会再次自动允许写入
#
#然而如果对redis服务器设置了合理持续的监控,那么你可以关闭掉这个选项。
#这会导致redis将继续进行工作,无论硬盘,权限或者其他的是否有问题
#
#
stop-writes-on-bgsave-error yes
# 是否在dump到 rdb 数据库的时候使用LZF来压缩字符串
# 默认是 yes,因为这是一个优良的做法
#
# 如果你不想耗费你的CPU处理能力,你可以设置为 no,但是这会导致你的数据会很大
rdbcompression yes
# 从RDB的版本5开始,CRC64校验值会写入到文件的末尾
#这会使得格式化过程中,使得文件的完整性更有保障,但是这会在保存和加载的时候损失不少的性能(大概在10%)
#你可以关闭这个功能来获得最高的性能
#
#RDB文件会在校验功能关闭的时候,使用0来作为校验值,这将告诉加载代码来跳过校验步骤
rdbchecksum yes
# DB的文件名称
dbfilename dump.rdb
# 工作目录.
#
# DB将会使用上述 ‘dbfilename’指定的文件名写入到该目录中
#
# 追加的文件也会在该目录中创建
#
# 注意,你应该在这里输入的是一个目录而不是一个文件名
dir ./
REPLICATION
########################### REPLICATION #################################
# 主从复制。使用 slaveof 命令来 指导redis从另一个redis服务的拷贝中来创建一个实例
#
#注意:这个配置是主从结构的从(主从结构的从,怎么那么拗口呢)redis的本地配置
#
#如下例子,这个配置指导 slave (从redis) 通过另一个redis的实例的ip和端口号来获取DB数据
#
#
#
# slaveof
#
# 如果主服务器开启了密码保护(使用下面的”requirepass”配置)
# 这个配置就是告诉从服务在发起向主服务器的异步复制的请求之前使用如下的密码进行认证,
#否则主服务器会拒绝这个请求
#
#
#
# masterauth
#
# 如果从服务器失去了和主服务器之间的连接,或者当复制仍然处于处理状态的时候
# 从服务器做出如下的两个行为
#
# 1)如果 slave-serve-stale-data 被设置为 yes(默认值),从服务器将会持续
# 回复来自客户端的请求,可能会回复已经过期的数据,或者返回空的数据,当从服务器第一次异步请求数据时。
#
# 2)如果 slave-serve-stale-data 被设置为 no ,从服务器就会返回”SYNC with master in progress”
# 这个错误,来应答所有命令除了 INFO 和 SLAVEOF
#
slave-serve-stale-data yes
#
#
# 你可以配置一个从服务器的实例是否接受写请求,
# 从服务器在存储一些短暂的数据的的时候,接收写请求是一件非常正确的事情
# (因为数据在向主服务器同步之后非常容易擦除)但是会因为配置不正确而导致一些问题
#
# 从redis 2.6开始默认从服务器是只读的服务器
#
#
#
#提示:只读的从服务器并不是设计用来公开给不受信任的互联网客户端的,它
#仅仅是一个用来防止对实例进行误操作的保护层。只读从服务器默认用来输出管理命令
#例如 CONFIG, DEBUG 和其他。如果你想限制它的规模,你可以使用’rename-command’来
#提高它的安全性,使得她作为一个影子来执行管理或者危险的命令
#
#
slave-read-only yes
# 从服务器在预设的间隔中发送送一个ping到目标服务器。你可以通过修改repl-ping-slave-period
#的值来修改它,默认是10秒钟
#
#
# repl-ping-slave-period 10
# repl-timeout设置了以下的复制超时值:
#
# 1) 在从服务器中,使用同步IO进行大规模传输.
# 2) 在从服务器中,主服务器的超时(ping,数据)
# 3) 在主服务器中. 从服务器的超时(对pings的响应)
#
#
# 确保这个值大于 指定的repl-ping-slave-period 值,否则当主从之间是低流量时
# 会检测到超时的情况
#
# repl-timeout 60
# 在从服务器同步之后是否关闭TCP_NODELAY?
#
#
# 如果你选择 “yes”,redis将会使用一个很小的TCP包和很小的带宽来向从服务器发送数据。
# 如果使用默认的设置这会增加数据复制到从服务器之间的延迟。如果使用默认配置的linux内核
# 这个延迟会高达到40毫秒
#
#
#如果你选择 “no”,数据复制到从服务器将会减少延迟,但是会使用更多的带宽。
#
#作为默认我们为低延迟进行优化,但是在一个高流量的情况下或者当主服务器和从服务器
#有很多hops的时候,将该值设置为yes会更好
# (译者注:这就是一个网络调优的问题,默认的TCP内核会使用Nagle,即将小的数据包合并成大的数据包(及yes的情况))
# (在等待合并的过程种,肯定会存在等待后续数据的步骤,因此这会导致数据的延迟)
# (yes,就是使用TCP的默认情况开启Nagle算法,no就是关闭Nagle算法)
repl-disable-tcp-nodelay no
#
#
#设置复制的backlog值。(这个backlog和tcp中的backlog不一样)
#
#这个backlog值是一个缓冲区,当从服务器断开连接之后,主服务器将更新的数据放置
#在这个缓冲区中,因为当从服务重新连接上来时候不是所有的数据都需要同步,因此从这个
#缓冲区中取数据就可以同步到和主服务器一样的状态
#
#
#这个值设置得越大,从服务器的掉线时间就可以越长,上线后就可以进行局部更新
#(译者注:当掉线时间过长而无法进行局部更新,那么从服务器就会再一次进行同步所有的数据,耗时和当时的数据量成正比)
#当且仅当第一个从服务器连接到服务器之后这个缓存才会被分配
#
# repl-backlog-size 1mb
#
#
# 当从服务器在长时间内没有连接到主服务器时,backlog的缓存将会被释放。
# 以下的选项就是自 从服务器最后一次断掉和主服务器之间的
# 连接开始N秒后清空backlog的缓存
#
# 设置为0意味着永远不会清空backlog
#
# repl-backlog-ttl 3600
#
#
# 在redis的信息输出中我们使用一个整型值来表示从服务器的优先值
#
#这个优先级的作用是,在主从结构种,当主服务器不能正常工作的时候时候,
#将一个从服务器提升为主服务器,提升的依据就是这个值。
#
# 假设又三个 优先级分别为 25 10 100 的服务器,将优先将数值最少的提升为主服务器
# 即最小值优先
# 如果优先级设置为0,意味着将不会又机会成为主服务器
# 默认优先级是100
slave-priority 100
#
# 下面的值用来设置主服务器停止接受写入事件的情况。
# 如果从服务器的连接小于N
# 从服务器的数据落后 小于等于M秒
#
# N个从服务器必须是在线的状态
#
# lag的单位是秒,它必须 <=指定的值,它从最后一次收到ping包的时间开始计算。
# 通常ping包都是每秒发送一次
#
#
# 这个选项并不担保N个副本都会接受写入,但是会确保在指定的时间没有足够的从服务可用的时候
# 窗口上显示丢失写入
#
#
# 例如要求最少三个从服务器在lag<=10秒
#
# min-slaves-to-write 3
# min-slaves-max-lag 10
#
# 设置任意一个为0都会导致关闭这项特性
#
# 默认min-slaves-to-write 设置为0(关闭这个特性)
# min-slaves-max-lag 设置为10
#
# 如果主服务器开启了密码保护(使用下面的”requirepass”配置)
# 这个配置就是告诉从服务在发起向主服务器的异步复制的请求之前使用如下的密码进行认证,
#否则主服务器会拒绝这个请求
#
#
#
# masterauth
#
# 如果从服务器失去了和主服务器之间的连接,或者当复制仍然处于处理状态的时候
# 从服务器做出如下的两个行为
#
# 1)如果 slave-serve-stale-data 被设置为 yes(默认值),从服务器将会持续
# 回复来自客户端的请求,可能会回复已经过期的数据,或者返回空的数据,当从服务器第一次异步请求数据时。
#
# 2)如果 slave-serve-stale-data 被设置为 no ,从服务器就会返回”SYNC with master in progress”
# 这个错误,来应答所有命令除了 INFO 和 SLAVEOF
#
slave-serve-stale-data yes
#
#
# 你可以配置一个从服务器的实例是否接受写请求,
# 从服务器在存储一些短暂的数据的的时候,接收写请求是一件非常正确的事情
# (因为数据在向主服务器同步之后非常容易擦除)但是会因为配置不正确而导致一些问题
#
# 从redis 2.6开始默认从服务器是只读的服务器
#
#
#
#提示:只读的从服务器并不是设计用来公开给不受信任的互联网客户端的,它
#仅仅是一个用来防止对实例进行误操作的保护层。只读从服务器默认用来输出管理命令
#例如 CONFIG, DEBUG 和其他。如果你想限制它的规模,你可以使用’rename-command’来
#提高它的安全性,使得她作为一个影子来执行管理或者危险的命令
#
#
slave-read-only yes
# 从服务器在预设的间隔中发送送一个ping到目标服务器。你可以通过修改repl-ping-slave-period
#的值来修改它,默认是10秒钟
#
#
# repl-ping-slave-period 10
# repl-timeout设置了以下的复制超时值:
#
# 1) 在从服务器中,使用同步IO进行大规模传输.
# 2) 在从服务器中,主服务器的超时(ping,数据)
# 3) 在主服务器中. 从服务器的超时(对pings的响应)
#
#
# 确保这个值大于 指定的repl-ping-slave-period 值,否则当主从之间是低流量时
# 会检测到超时的情况
#
# repl-timeout 60
# 在从服务器同步之后是否关闭TCP_NODELAY?
#
#
# 如果你选择 “yes”,redis将会使用一个很小的TCP包和很小的带宽来向从服务器发送数据。
# 如果使用默认的设置这会增加数据复制到从服务器之间的延迟。如果使用默认配置的linux内核
# 这个延迟会高达到40毫秒
#
#
#如果你选择 “no”,数据复制到从服务器将会减少延迟,但是会使用更多的带宽。
#
#作为默认我们为低延迟进行优化,但是在一个高流量的情况下或者当主服务器和从服务器
#有很多hops的时候,将该值设置为yes会更好
# (译者注:这就是一个网络调优的问题,默认的TCP内核会使用Nagle,即将小的数据包合并成大的数据包(及yes的情况))
# (在等待合并的过程种,肯定会存在等待后续数据的步骤,因此这会导致数据的延迟)
# (yes,就是使用TCP的默认情况开启Nagle算法,no就是关闭Nagle算法)
repl-disable-tcp-nodelay no
#
#
#设置复制的backlog值。(这个backlog和tcp中的backlog不一样)
#
#这个backlog值是一个缓冲区,当从服务器断开连接之后,主服务器将更新的数据放置
#在这个缓冲区中,因为当从服务重新连接上来时候不是所有的数据都需要同步,因此从这个
#缓冲区中取数据就可以同步到和主服务器一样的状态
#
#
#这个值设置得越大,从服务器的掉线时间就可以越长,上线后就可以进行局部更新
#(译者注:当掉线时间过长而无法进行局部更新,那么从服务器就会再一次进行同步所有的数据,耗时和当时的数据量成正比)
#当且仅当第一个从服务器连接到服务器之后这个缓存才会被分配
#
# repl-backlog-size 1mb
#
#
# 当从服务器在长时间内没有连接到主服务器时,backlog的缓存将会被释放。
# 以下的选项就是自 从服务器最后一次断掉和主服务器之间的
# 连接开始N秒后清空backlog的缓存
#
# 设置为0意味着永远不会清空backlog
#
# repl-backlog-ttl 3600
#
#
# 在redis的信息输出中我们使用一个整型值来表示从服务器的优先值
#
#这个优先级的作用是,在主从结构种,当主服务器不能正常工作的时候时候,
#将一个从服务器提升为主服务器,提升的依据就是这个值。
#
# 假设又三个 优先级分别为 25 10 100 的服务器,将优先将数值最少的提升为主服务器
# 即最小值优先
# 如果优先级设置为0,意味着将不会又机会成为主服务器
# 默认优先级是100
slave-priority 100
#
# 下面的值用来设置主服务器停止接受写入事件的情况。
# 如果从服务器的连接小于N
# 从服务器的数据落后 小于等于M秒
#
# N个从服务器必须是在线的状态
#
# lag的单位是秒,它必须 <=指定的值,它从最后一次收到ping包的时间开始计算。
# 通常ping包都是每秒发送一次
#
#
# 这个选项并不担保N个副本都会接受写入,但是会确保在指定的时间没有足够的从服务可用的时候
# 窗口上显示丢失写入
#
#
# 例如要求最少三个从服务器在lag<=10秒
#
# min-slaves-to-write 3
# min-slaves-max-lag 10
#
# 设置任意一个为0都会导致关闭这项特性
#
# 默认min-slaves-to-write 设置为0(关闭这个特性)
# min-slaves-max-lag 设置为10
SECURITY
############################ SECURITY ###################################
#
# 要求客户端在处理其他指令之前先发起AUTH
#
# 这在你不信任其他的接入主机上的redis-server是比较有用
#
# 这个选项应当注释掉来保证向后的兼容性,毕竟大部分的人都不需要鉴权验证(因为他们都运行自己的sever)
#
#
#注意,由于redis太快,所以每秒钟可以尝试150K次密码,因此你应该设置一个
#非常强壮的密码来防止别人的破解
#
# requirepass foobared
# 命令重命名.
#
#
# 它用来改变共享环境中危险命令的名字,在这个例子中
# CONFIG 命令被重命名为一个难以猜解的名字。
# 这会对内部用户的工具有效,但是对一般的客户端无效。
#
# Example:
#
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
#
#
# 可以使用一个空字符串来抹杀这个命令
#
# rename-command CONFIG “”
#
# 请注意,改变记录在AOF文件中的命令名称或者传输到从服务会导致问题
# AOF file or transmitted to slaves may cause problems.
#
# 这在你不信任其他的接入主机上的redis-server是比较有用
#
# 这个选项应当注释掉来保证向后的兼容性,毕竟大部分的人都不需要鉴权验证(因为他们都运行自己的sever)
#
#
#注意,由于redis太快,所以每秒钟可以尝试150K次密码,因此你应该设置一个
#非常强壮的密码来防止别人的破解
#
# requirepass foobared
# 命令重命名.
#
#
# 它用来改变共享环境中危险命令的名字,在这个例子中
# CONFIG 命令被重命名为一个难以猜解的名字。
# 这会对内部用户的工具有效,但是对一般的客户端无效。
#
# Example:
#
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
#
#
# 可以使用一个空字符串来抹杀这个命令
#
# rename-command CONFIG “”
#
# 请注意,改变记录在AOF文件中的命令名称或者传输到从服务会导致问题
# AOF file or transmitted to slaves may cause problems.
LIMITS
############################# LIMITS ####################################
#
# 设置同一时间的客户端最大连接数,默认的限制是10000个客户端。
#然而如果redis服务不设置这个限制值那么最大的用户数就是最大文件描述符数-32.
#
#
#一旦连接的用户数超出了限制值,redis将会关闭新的连接并且发送 ‘max number of client reached’
#
# maxclients 10000
# 不使用超出指定大小的内存,
#当redis使用到的内存达到限定值的时候,将会根据淘汰策略试图移除一部分key
#
#
# 如果根据相关策略无法移除key,或者策略被设置为 ‘noeviction’,redis将会对
#使用到内存的命令返回错误,比如 SET LPUSH等,并且进入只读模式仅仅响应只读的命令如GET
#
# 这个选项在你将redis当做一个LRU缓存和设置一个内存大小限制的时候十分有用。
#
#
#
# 警告:如果你的从服务器关联到一个有最大内存限制的redis实例上,
#
# 主服务器向从服务器输出的缓存属于被该服务器使用的内存的一部分。
#因此 网络问题和重新同步引发的复制,不会触发淘汰key的循环,
#
#反过来,从服务器的输出缓存将会被触发淘汰的DEL key,直到数据库清空
#
#
#
#简单来说,如果你拥有一个从服务器,我们建议你将这个值
#设置为少于系统可用的最大内存,以便系统可以腾出空间来安放
#从服务器的输出缓存(但是如果策略是noeviction 那就没这个必要)
#
# maxmemory
# 最大内存策略: 当redis使用的内存达到指定的最大值时,你可以使用如下的5种
# 策略来应对这种情况
#
# volatile-lru -> 使用LRU算法依据过期时间来移除key
# allkeys-lru -> 使用LRU算法来移除任何key
# volatile-random -> 根据过期时间设置随即移除key
# allkeys-random -> 随即移除任何一个key
# volatile-ttl -> 移除一个最近过期时间的key
# noeviction -> 所有key用不过期(即不移除任何key),对于任何写操作都返回一个错误信息
#
# 提示: 在以上的所有策略中,当不存在一个key满足以上的淘汰策略时(即无法空出内存时)
# 任何写操作都会返回错误信息
#
# 目前为止具有写入操作的指令是: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
#
# 默认值为:
#
# maxmemory-policy volatile-lru
#
# LRU和最小TTL算法都不是精确的算法,但是是近似的算法,
#因此你可以选择一些样本大小来进行测试,对于一个默认的redis实例
#将会选选择3个key,并且挑选其中之一作为最近最少的Key,你可以使用如下参数修改例子的数量大小
#
#
# maxmemory-samples 3
# 最大内存策略: 当redis使用的内存达到指定的最大值时,你可以使用如下的5种
# 策略来应对这种情况
#
# volatile-lru -> 使用LRU算法依据过期时间来移除key
# allkeys-lru -> 使用LRU算法来移除任何key
# volatile-random -> 根据过期时间设置随即移除key
# allkeys-random -> 随即移除任何一个key
# volatile-ttl -> 移除一个最近过期时间的key
# noeviction -> 所有key用不过期(即不移除任何key),对于任何写操作都返回一个错误信息
#
# 提示: 在以上的所有策略中,当不存在一个key满足以上的淘汰策略时(即无法空出内存时)
# 任何写操作都会返回错误信息
#
# 目前为止具有写入操作的指令是: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
#
# 默认值为:
#
# maxmemory-policy volatile-lru
#
# LRU和最小TTL算法都不是精确的算法,但是是近似的算法,
#因此你可以选择一些样本大小来进行测试,对于一个默认的redis实例
#将会选选择3个key,并且挑选其中之一作为最近最少的Key,你可以使用如下参数修改例子的数量大小
#
#
# maxmemory-samples 3
APPEND ONLY MODE
######################## APPEND ONLY MODE ###############################
# Redis默认使用异步存储数据到硬盘上.
#
# 这个模式非常合适一些应用,但是当redis的进程出现问题
# 或者停电的时候,会丢失一些写入的数据(丢失的多少根据保存点的设置)
#
#
# Append Only 文件(Append Only file),是一个备选的持久化模型,
# 它提供了更好的续航能力,对于一个使用默认数据同步文件策略的实例
#redis可能会因为一个戏剧性的灾难比如停电等丢失一秒钟的数据
#
#或者由于redis进程本身的错误仅仅写入一个数据,但操作系统一直运行
#
#
#
# AOF和RDB可以毫无问题地共存,因此你可以同时开启他们,
#
# 如果你开启了AOF,redis会在启动时加载AOF,因为AOF有更好的鲁棒性
#
# 你可以从 http://redis.io/topics/persistence 获取更多的信息
appendonly no
# append only file 的名称 (默认是: “appendonly.aof”)
appendfilename “appendonly.aof”
# fsync() 调用告诉操作系统立即将数据写入到硬盘中,而不是写入到输出缓冲区
# 等待足够的数据再写入。一些操作系统会立即将数据写入到硬盘中,一些其他的
#操作系统则只是尽可能快地将数据写入硬盘中
#
#
# Redis支持三种不同的模式:
#
# no:不进行强制同步,仅仅让操作系统根据自身的决策写入到硬盘中。这种速度更快
# always:在每一次追加写入操作都采用强制同步,特点是慢,安全。
# everysec:每间隔一秒钟强制同步数据。折中的方案
#
#
# 默认采用 “everysec”作为速度和安全性之间的平衡方案
# 你将根据自己的需求决定采用更快的方案或者更安全的方案。
# 选择no,何时写入数据将由操作系统决定,你可以由此获取最快的速度
# 选择always,数据将立即写入到硬盘中,你可以获得更高的数据安全性
#
# 更多的信息可以从以下地址中获取:
# http://antirez.com/post/redis-persistence-demystified.html
#
# 如果不开启该选项默认使用”everysec”.
# appendfsync always
appendfsync everysec
# appendfsync no
#
#
# 当AOF的强制写入策略设置为 always 或者 everysec,并且一个后台保存进程
#(一个后台保存进程或者 AOF 日志后台重写)会占用硬盘的大量I/O资源,在一些linux
# 的配置中redis会因为 fsync() 调用而长期锁定。特别的是在目前我们没法解决这个问题
# 即使采用另外的线程来运行强制同步也会锁定住我们的 同步 write(2)调用
#
# 为了减轻这个问题,下面的选项将会在GBSAVE 或者BGREWRITEAOF运行时
# 预防主进程调用fsync()
#
# 这意味着当另一个 子进程在保存的时候,Redis的保存策略将处于”appendfsync none”这样的类似状态
# 在实际应用当中,这意味着在最坏的情况下将会失去30秒的日志(使用linux默认的设置)
#
#
# 如果你采用yes,那么将会存在一个潜在的隐患,不然请设置它为 “no”,
# 这是一个为了稳定的安全性选择
#
no-appendfsync-on-rewrite no
# 自动改写append only 文件.
#
# redis会在AOF日志文件增长到指定百分比的时候通过调用BGREWRITEAOF来自动重写日志文件
#
# 他是这样工作的:redis会记住最后一次改写后AOF文件的大小(如果重写自重启以来
#尚未发生,那么AOF文件的大小就是启动以来使用的大小)
#
#
# 这个基准值将会和当前值进行比较,如果当前值比设定的百分比还要大,重写事件就会发生。
#
# 并且你需要指定一个AOF重写的最小值,这用来避免当重写文件的百分比增长符合目标
# 但是整个文件依然很小的时候
#
#
# 将 auto-aof-rewrite-percentage 设置为0则可以关闭掉AOF自动重写的功能
#
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
LUA SCRIPTING
//################################ LUA SCRIPTING ###############################
# 以毫秒为单位限定lua脚本的最大执行时间.
#
#
# 当lua脚本在超出最大允许执行时间之后,redis会记录下这个脚本到日志中,
#并且会向这个请求返回error的错误
#
#
#
# 仅当 SCRIPT KILL 和 SHUTDOWN NOSAVE 命令可用的时候
# 一个运行时间超过最大限定时间的脚本才会继续执行
# SCRIPT KILL用来停止一个没有调用写入命令的脚本
# 当用户不想等待脚本的自然中止但脚本又在进行写操作的时候
# 采用 SHUTDOWN NOSAVE 是解决这个问题的唯一办法,他可以立即停掉整个脚本
#
#
# 设置为0 或者一个负数来取消时间限定.
lua-time-limit 5000
SLOW LOG
############################ SLOW LOG ###################################
#
# slow log(慢日志)用来记录执行时间超过指定值的查询。
# 执行时间不包含 I/O操作,比如和客户端交互,发送应答等等
# 仅仅是执行命令的真实时间,(仅仅是线程因为执行这个命令而锁定且无法处理其他请求的阶段)
#
#
# 你可以使用两个参数来配置 slow log,一个是以微秒为单位的命令执行时间值,
# 另一个是slow log 的长度(即记录的最大数量)
# 当一个新的命令被记录到slow log的时候,最旧的一条记录将会被移除。
#
#
# 下面的值将会被解释为 微秒 为单位,所以 1000000 微秒为 1秒
#
# 将这个值设置为一个负数,将关闭掉slow log ,如果设置为0,则记录所有的命令
#(默认是10毫秒)
slowlog-log-slower-than 10000
# 因为这会消耗内存,因此实际上并不是限制到这个长度.
# 你可以使用 SLOWLOG RESET来回收占用的内存
slowlog-max-len 128
LATENCY MONITOR
########################## LATENCY MONITOR ##############################
#
# redis延迟监控子系统例子与操作系统收集的redis实例相关的数据不同
#
# 通过LATENCY命令,可以为用户打印出相关信息的图形和报告
#
#这个系统只会记录运行时间超出指定时间值的命令,如果设置为0,这个监控将会被关闭
#
#
# 默认的情况下,延迟监控是关闭,因为如果你没有延迟的问题大部分情况下不需要
#,并且收集数据的行为会对性能造成影响,虽然这个影响很小可以在大负荷下工作
#
#延迟监控可以使用如下命令来打开
#
# “CONFIG SET latency-monitor-threshold “.
latency-monitor-threshold 0
latency-monitor-threshold 0
Event notification
####################### Event notification ##############################
#redis 可以在key 空间中采用发布订阅模式来通知事件的发生
#
#这个功能的文档可以查看 http://redis.io/topics/keyspace-events
#
#
#对于一个实例,如果键空间事件通知是启用状态,当一个客户端执行在一个
#存储在Database 0名为”foo”的key的DEL(删除)操作时,
#有如下两条信息将会通过发布订阅系统产生
#
#
# PUBLISH keyspace@0:foo del
# PUBLISH keyevent@0:del foo
#
#
# 以下是可选的redis事件通知,每个类别的事件可以由一个字符进行描述
#
# K Keyspace events, published with keyspace@
# E Keyevent events, published with keyevent@
# g Generic commands (non-type specific) like DEL, EXPIRE, RENAME, …
# $ String commands
# l List commands
# s Set commands
# h Hash commands
# z Sorted set commands
# x Expired events (events generated every time a key expires)
# e Evicted events (events generated when a key is evicted for maxmemory)
# A Alias for g$lshzxe, so that the “AKE” string means all the events.
#
# The “notify-keyspace-events” takes as argument a string that is composed
# by zero or multiple characters. The empty string means that notifications
# are disabled at all.
#
# 例子1: 启用 list 和 generic 事件,
#
# notify-keyspace-events Elg
#
# 例子2 2: 要想订阅通道名为keyevent@0:expired 上expired keys的事件:
#
# notify-keyspace-events Ex
#
#
# 默认不启用所有的通知,因为大部分的用户不需要这些功能,而且这些功能会带来一些开销
#
# 如果你没有指定 K 或者 E,没有事件会被传递
#
notify-keyspace-events “”
ADVANCED CONFIG
######################### ADVANCED CONFIG ###############################
#
#创建空白哈希表时,程序默认使用 REDIS_ENCODING_ZIPLIST 编码,当以下任何一个条件被满
#足时,程序将编码从切换为 REDIS_ENCODING_HT
#哈希表中某个键或某个值的长度大于 server.hash_max_ziplist_value (默认值为 64)。
#压缩列表中的节点数量大于 server.hash_max_ziplist_entries (默认值为 512 )。
#
# ziplist是一个解决空间的紧凑的数据存储结构,但是当数据超过阈值时,将采用原生的数据存储结构
#
#
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
#
# 与hash表类似,
#
list-max-ziplist-entries 512
list-max-ziplist-value 64
#
# 设置特殊编码的唯一情况:
# 当一个set仅仅由一个基数为10最大位数为64位的有符号整形的字符串构成的时候
#
#以下配置设置了set的限制大小,当小于这个值的时候将会使用一个更紧凑的数据结构来保存
#以期减少内存占用
#
set-max-intset-entries 512
#
# 与hash和list类似 zsort也采用如下的配置来选择是否进行特殊编码来节省空间
#
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
#
# HyperLogLog 稀疏表示字节限制
# 这个限制包含了16个字节的头部,当一个HyperLogLog使用sparse representation
# 超过了这个显示,它就会转换到dense representation上
#
#
hll-sparse-max-bytes 3000
#
# active rehashing使用CPU时间的每100毫秒中的1毫秒来进行rehashing工作
# 来rehash redis的主hash表(rehash的时候在代码种引入记时来保证)
#
# lazy rehashing :逐步hash,每一次添加查找删除进行一次rehash的步骤
# 又称惰性hash
#
# 因为hash的再散列会导致整个进程的stop,为了避免长时间的stop,以上的策略都是在分散整个
# rehash的过程(参照《redis设计与实现》的字典部分)
#
activerehashing yes
#
# 客户端输出缓冲区显示可以用来解决由于某些原因导致的强制断线
# 而造成的不能读到足够的数据
# 一个比较常见的原因是发布订阅模式种,客户端不能足够快速地消费发布者生产的信息
#
# 这个限制可以设置为如下的三种类型:
#
# normal -> 正常普通的客户端,包含监控客户端
# slave -> 主从服务器的从客户端
# pubsub -> 订阅了最少一个频道的客户端
#
# 每一个 client-output-buffer-limit 格式如下:
#
# client-output-buffer-limit
#
#
#
# 在两种情况下服务器认为客户端不是意外临时掉线
#
# 1.缓冲区的数据达到硬限制
# 2.缓冲区的数据达到软限制,同时时间超过了指定值
#
# 因为一个客户离线,有可能是临时性的网络故障,或者传输问题
# 也有可能是永久性离线 或者强制性离线,此时服务器将不会保留他的缓存数据
# 以下的设置就是为了判断这一情况的
#
#
#
# 硬限制和软限制都可以通过将其设置为0来关闭掉
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
#
# redis会按照一定的频率来处理诸如 关闭超时连接,清理没有被使用的过期key等等此类后台任务
#
# 并不是所有的任务都以相同的频率来执行的,redis通过一个hz的值来决定处理这些(如上所述的后台任务)任务的频率
#
#
# 提高这个值会使用更多的cpu时间来在redis闲置的时候处理以上的,但是以此同时
# 超时的连接的处理和过期key的清理则会更精确
#
# hz的取值范围在1到500,不建议设置为超过100的值,默认是10
hz 10
#
# 当子进程重写AOF文件的时候,以下选项将会允许等到存在32MB数据的时候才调用强制同步
# 这样可以降低IO上的延迟
#
aof-rewrite-incremental-fsync yes
#
#
#
# 在两种情况下服务器认为客户端不是意外临时掉线
#
# 1.缓冲区的数据达到硬限制
# 2.缓冲区的数据达到软限制,同时时间超过了指定值
#
# 因为一个客户离线,有可能是临时性的网络故障,或者传输问题
# 也有可能是永久性离线 或者强制性离线,此时服务器将不会保留他的缓存数据
# 以下的设置就是为了判断这一情况的
#
#
#
# 硬限制和软限制都可以通过将其设置为0来关闭掉
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
#
# redis会按照一定的频率来处理诸如 关闭超时连接,清理没有被使用的过期key等等此类后台任务
#
# 并不是所有的任务都以相同的频率来执行的,redis通过一个hz的值来决定处理这些(如上所述的后台任务)任务的频率
#
#
# 提高这个值会使用更多的cpu时间来在redis闲置的时候处理以上的,但是以此同时
# 超时的连接的处理和过期key的清理则会更精确
#
# hz的取值范围在1到500,不建议设置为超过100的值,默认是10
hz 10
#
# 当子进程重写AOF文件的时候,以下选项将会允许等到存在32MB数据的时候才调用强制同步
# 这样可以降低IO上的延迟
#
aof-rewrite-incremental-fsync yes

若有收获,就点个赞吧
0 人点赞
