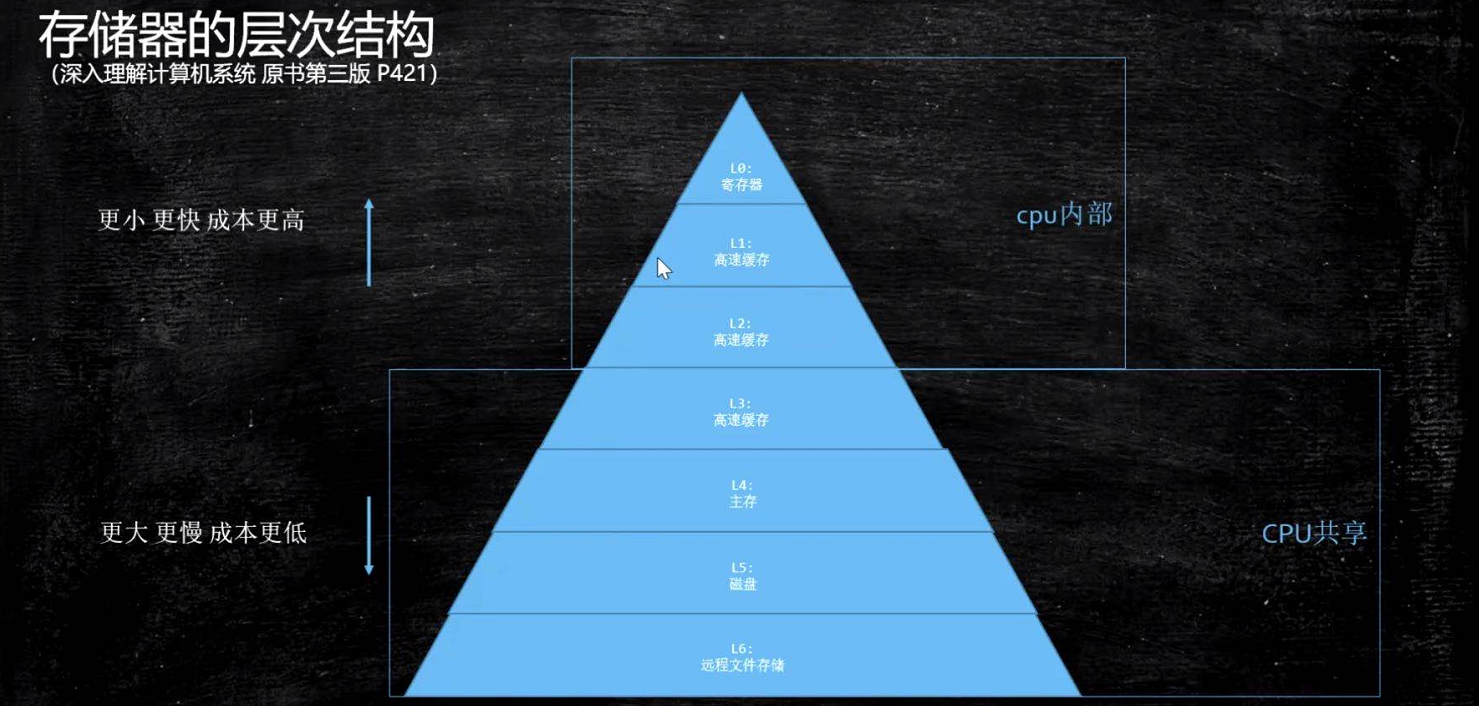
1. 存储器的层次结构
2. 缓存行对其与伪共享
每个CPU都有自己的1级缓存和2级缓存, 所有的CPU共享3级缓存。当一个CPU要读取一个变量时先从1级缓存中找, 找不到则取2级缓存中找,2级缓存找不到则去3级缓存中找, 以此类推直接找打主存,如果主存中找到了则依次存储在3级2级1级中。
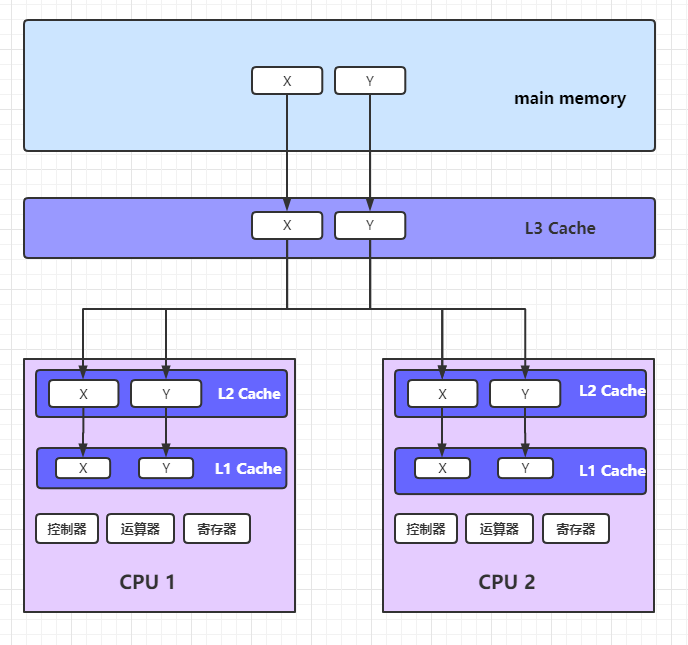
因为每个CPU都有自己的1级缓存和2级缓存, 当2个或多个CPU读取同一块内存时,会把2块一样的内存数据都存储在自己的一级和二级缓存中。
这样的存储方式就会引起缓存数据不一致的问题。 假设一个CPU改动了其中一个变量,那么如果不通知其他CPU此变量已经改动过,其他CPU如果还是按照以前的值就行运算这样计算的结果就会有问题。
那么如何解决这种缓存不一致的问题呢? 答案是MESI缓存一致性协议。
2.1 总线锁。
通过计算机组成原理我们知道, 计算总线(Bus)是计算机各种功能部件之间传送信息的公共通信干线,它是由导线组成的传输线束, 按照计算机所传输的信息种类,计算机的总线可以划分为数据总线、地址总线和控制总线,分别用来传输数据、数据地址和控制信号。
CPU通过控制总线锁,锁定对当前内存的独占,达到缓存一致性的目的。
点击查看【processon】
总线锁虽然解决了缓存一致性的问题,但是由于其机制问题硬锁性能太差。
2.2 MESI缓存一致性协议。
语雀内容
虽然MESI缓存一致性协议再保证性能的同时保证数据一致性,但是由于其机制问题一些有些缓存数据(比如跨越多个缓存行的数据)依然不能保证缓存一致性, 因此现在CPU硬件层面的缓存一致性使用锁总线+MESI配合使用的。
2.3 缓存行
3. java对象的的内存布局
3.1 开启虚拟机配置参数
java -XXL+PrintCommandLineFlags -version

每个参数解释如下:
- -XX:InitialHeapSize=26711737 初始化堆大小
- -XX:MaxHeapSize=4273878016 最大堆大小
- -XX:+PrintCommandLineFlags 打印命令行参数
- -XX:+UseCompressedClassPointers 使用压缩指针,使用之后指针从8字节大小变为4字节大小
- -XX:+UseCompressedOops 使用压缩Oops
- -XX:-UseLargePagesIndividualAllocation
- XX:+UseParallelGC
3.2 普通对象布局
对象头markword: 8字节ClassPointer指针:使用-XX:+UseCompressedClassPointer后为4字节, 禁止使用为8字节。- 实例数据:
- 引用类型使用-XX:+UseCompressedOops为4个字节, 不适用为8个字节
-
3.3 数组对象布局
对象头markword: 8字节同上
- ClassPointer指针:同上
- 数组长度: 4字节。这也是因为为什么数组不能创建比int类型大的元素总数的原因。
- 数组数据。
- 内存对齐。
3.4 markword 详细
| 锁状态 | 25 bit | 31 bit | 1 bit | 1 bit | age 4bit 分代年龄 |
biased_lock 1bit 是否偏向锁 |
lock 2bit 锁标记 |
|---|---|---|---|---|---|---|---|
| 无锁 | 未使用 | hash | 未使用 | 分代年龄 | 0 | 01 | |
| 偏向锁 | 线程ID | Epoch | 分代年龄 | 1 | 01 | ||
| 轻量级锁 | 栈中锁记录的指针(64) | 00 | |||||
| 重量级锁 | monitor的指针(64) | 10 | |||||
| GC | 空 | 11 |
| 锁状态 | 25bit | age 4bit 分代年龄 |
biased_lock 1bit 是否偏向锁 |
lock 2bit 锁标记 |
|
|---|---|---|---|---|---|
| 23bit | 2bit | ||||
| 无锁 | hash | 分代年龄 | 0 | 01 | |
| 偏向锁 | 线程ID | Epoch | 分代年龄 | 1 | 01 |
| 轻量级锁 | 栈中锁记录的指针 | 00 | |||
| 重量级锁 | 指向互斥量(重量级锁)的指针 | 10 | |||
| GC | 空 | 11 |

若有收获,就点个赞吧
0 人点赞
