Transcription May Begin Anywhere**
In “Transcribing DNA into RNA”, we discussed the transcription of DNA into RNA, and in “Translating RNA into Protein”, we examined the translation of RNA into a chain of amino acids for the construction of proteins. We can view these two processes as a single step in which we directly translate a DNA string into a protein string, thus calling for a DNA codon table.
However, three immediate wrinkles of complexity arise when we try to pass directly from DNA to proteins. First, not all DNA will be transcribed into RNA: so-called junk DNA appears to have no practical purpose for cellular function. Second, we can begin translation at any position along a strand of RNA, meaning that any substring of a DNA string can serve as a template for translation, as long as it begins with a start codon, ends with a stop codon, and has no other stop codons in the middle. See Figure 1.
| As a result, the same RNA string can actually be translated in three different ways, depending on how we group triplets of symbols into codons. For example, …AUGCUGAC… can be translated as …AUGCUG…, …UGCUGA…, and …GCUGAC…, which will typically produce wildly different protein strings. | 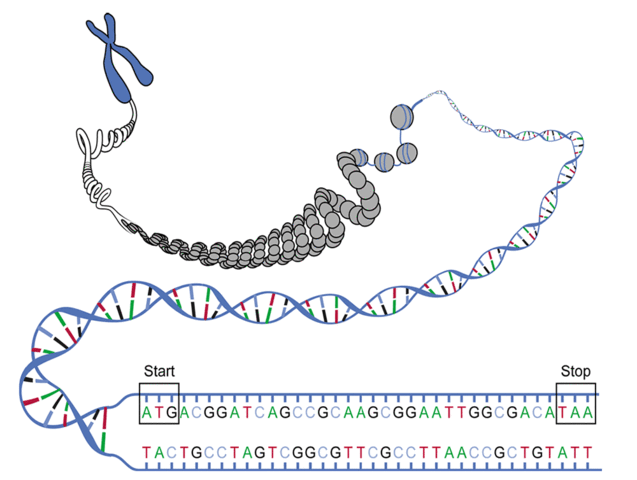 Figure 1. Schematic image of the particular ORF with start and stop codons shown. |
|---|---|
Problem
Either strand of a DNA double helix can serve as the coding strand for RNA transcription. Hence, a given DNA string implies six total reading frames, or ways in which the same region of DNA can be translated into amino acids: three reading frames result from reading the string itself, whereas three more result from reading its reverse complement.
An open reading frame (ORF) is one which starts from the start codon and ends by stop codon, without any other stop codons in between. Thus, a candidate protein string is derived by translating an open reading frame into amino acids until a stop codon is reached.
Given: A DNA string s of length at most 1 kbp in FASTA format.
Return: Every distinct candidate protein string that can be translated from ORFs of s. Strings can be returned in any order.
Sample Dataset
>Rosalind_99AGCCATGTAGCTAACTCAGGTTACATGGGGATGACCCCGCGACTTGGATTAGAGTCTCTTTTGGAATAAGCCTGAATGATCCGAGTAGCATCTCAG
Sample Output
MLLGSFRLIPKETLIQVAGSSPCNLSMMGMTPRLGLESLLEMTPRLGLESLLE
Solution
本题有误区,一般认为开放阅读框就是正反链各三个,但是实际上本题是遇到 AUG 就算,所以远不止 6 个!非常坑。
假设输入序列为 5'->3' 端的 DNA 序列,然后相应的求出反向互补,即互补链也是 5'->3' 方向的序列。因为转录只能是这个方向。![%9CWYBNHF~8GC9N]@4OU5L1.png](/uploads/projects/u1190503@gfsoma/f7767c5d5770d8dedddc3d3a675216d2.png)
- 将两条链翻译为
mRNA,直接替换T->U即可。 - 暴力寻找每条链中
AUG序列,然后找到一个就开始往后翻译。如果遇到终止密码子就加入答案中,否则走完序列的不算!
由于本题需要去重,也没有说,因此用集合操作。
from typing import Listdef readFasta(fileName: str) -> str:seqs = []with open(fileName) as f:seq = []for line in f:line = line.strip() # withespaceif line.startswith('>'): # IDif seq: # last sequence finishedyield ''.join(seq)seq = []elif line: # basesseq.append(line.strip())# last sequenceif seq:yield ''.join(seq)d = {'UUU': 'F', 'CUU': 'L', 'AUU': 'I', 'GUU': 'V','UUC': 'F', 'CUC': 'L', 'AUC': 'I', 'GUC': 'V','UUA': 'L', 'CUA': 'L', 'AUA': 'I', 'GUA': 'V','UUG': 'L', 'CUG': 'L', 'AUG': 'M', 'GUG': 'V','UCU': 'S', 'CCU': 'P', 'ACU': 'T', 'GCU': 'A','UCC': 'S', 'CCC': 'P', 'ACC': 'T', 'GCC': 'A','UCA': 'S', 'CCA': 'P', 'ACA': 'T', 'GCA': 'A','UCG': 'S', 'CCG': 'P', 'ACG': 'T', 'GCG': 'A','UAU': 'Y', 'CAU': 'H', 'AAU': 'N', 'GAU': 'D','UAC': 'Y', 'CAC': 'H', 'AAC': 'N', 'GAC': 'D','UAA': '', 'CAA': 'Q', 'AAA': 'K', 'GAA': 'E','UAG': '', 'CAG': 'Q', 'AAG': 'K', 'GAG': 'E','UGU': 'C', 'CGU': 'R', 'AGU': 'S', 'GGU': 'G','UGC': 'C', 'CGC': 'R', 'AGC': 'S', 'GGC': 'G','UGA': '', 'CGA': 'R', 'AGA': 'R', 'GGA': 'G','UGG': 'W', 'CGG': 'R', 'AGG': 'R', 'GGG': 'G'}def orf(seq: str) -> str:n = len(seq)res = set()def helper(seq: str) -> None:rna = seq.replace("T", 'U')for i in range(0, n - 3 + 1):if rna[i:i+3] == 'AUG':protein = []for j in range(i, n, 3):if j + 3 > n: breakcodon = rna[j:j+3]if not d[codon]:res.add(''.join(protein[:]))breakprotein.append(d[codon])helper(seq)helper(seq[::-1].translate(str.maketrans('ATCG', 'TAGC')))return '\n'.join(res)for seq in readFasta("./DNA.fasta"):print(orf(seq))'''AGCCATGTAGCTAACTCAGGTTACATGGGGATGACCCCGCGACTTGGATTAGAGTCTCTTTTGGAATAAGCCTGAATGATCCGAGTAGCATCTCAGMLLGSFRLIPKETLIQVAGSSPCNLSMMGMTPRLGLESLLEMTPRLGLESLLE'''
正则表达式与变相“笛卡尔乘积”
- 用 re 需要找出所有的开始和结束,但是需要注意的就是,如何解决
3的倍数关系!因为可能找到不是3倍数,肯定不对! - 所有的终止子只能出现一次!因为转录到最近的终止子就停止了,因此不能够再枚举后续的终止子位置了。 ```python from typing import List
def readFasta(fileName: str) -> str: seqs = [] with open(fileName) as f: seq = [] for line in f: line = line.strip() # withespace if line.startswith(‘>’): # ID if seq: # last sequence finished yield ‘’.join(seq) seq = [] elif line: # bases seq.append(line.strip())
# last sequenceif seq:yield ''.join(seq)
d = { ‘UUU’: ‘F’, ‘CUU’: ‘L’, ‘AUU’: ‘I’, ‘GUU’: ‘V’, ‘UUC’: ‘F’, ‘CUC’: ‘L’, ‘AUC’: ‘I’, ‘GUC’: ‘V’, ‘UUA’: ‘L’, ‘CUA’: ‘L’, ‘AUA’: ‘I’, ‘GUA’: ‘V’, ‘UUG’: ‘L’, ‘CUG’: ‘L’, ‘AUG’: ‘M’, ‘GUG’: ‘V’, ‘UCU’: ‘S’, ‘CCU’: ‘P’, ‘ACU’: ‘T’, ‘GCU’: ‘A’, ‘UCC’: ‘S’, ‘CCC’: ‘P’, ‘ACC’: ‘T’, ‘GCC’: ‘A’, ‘UCA’: ‘S’, ‘CCA’: ‘P’, ‘ACA’: ‘T’, ‘GCA’: ‘A’, ‘UCG’: ‘S’, ‘CCG’: ‘P’, ‘ACG’: ‘T’, ‘GCG’: ‘A’, ‘UAU’: ‘Y’, ‘CAU’: ‘H’, ‘AAU’: ‘N’, ‘GAU’: ‘D’, ‘UAC’: ‘Y’, ‘CAC’: ‘H’, ‘AAC’: ‘N’, ‘GAC’: ‘D’, ‘UAA’: ‘’, ‘CAA’: ‘Q’, ‘AAA’: ‘K’, ‘GAA’: ‘E’, ‘UAG’: ‘’, ‘CAG’: ‘Q’, ‘AAG’: ‘K’, ‘GAG’: ‘E’, ‘UGU’: ‘C’, ‘CGU’: ‘R’, ‘AGU’: ‘S’, ‘GGU’: ‘G’, ‘UGC’: ‘C’, ‘CGC’: ‘R’, ‘AGC’: ‘S’, ‘GGC’: ‘G’, ‘UGA’: ‘’, ‘CGA’: ‘R’, ‘AGA’: ‘R’, ‘GGA’: ‘G’, ‘UGG’: ‘W’, ‘CGG’: ‘R’, ‘AGG’: ‘R’, ‘GGG’: ‘G’ }
def orf(seq: str) -> str: n = len(seq) res = set()
def helper(seq: str) -> None:import re, bisectrna = seq.replace("T", 'U')start = [i.start() for i in re.finditer(r'AUG', rna)]end = [i.start() for i in re.finditer(r'UAG|UGA|UAA', rna)]for i in start:# idx = bisect.bisect_right(end, i)for j in end:if j > i and (j - i) % 3 == 0:res.add(''.join(d[rna[k:k+3]] for k in range(i, j, 3)))break # 距离它最近的一个足够helper(seq)helper(seq[::-1].translate(str.maketrans('ATCG', 'TAGC')))return '\n'.join(res)
for seq in readFasta(“./DNA.fasta”): print(orf(seq)) ‘’’ AGCCATGTAGCTAACTCAGGTTACATGGGGATGACCCCGCGACTTGGATTAGAGTCTCTTTTGGAATAAGCCTGAATGATCCGAGTAGCATCTCAG
MLLGSFRLIPKETLIQVAGSSPCNLS M MGMTPRLGLESLLE MTPRLGLESLLE ‘’’ ```

若有收获,就点个赞吧
0 人点赞
