Identifying Unknown DNA Quickly
| A quick method used by early computer software to determine the language of a given piece of text was to analyze the frequency with which each letter appeared in the text. This strategy was used because each language tends to exhibit its own letter frequencies, and as long as the text under consideration is long enough, software will correctly recognize the language quickly and with a very low error rate. See Figure 1 for a table compiling English letter frequencies. You may ask: what in the world does this linguistic problem have to do with biology? Although two members of the same species will have different genomes, they still share the vast percentage of their DNA; notably, 99.9% of the 3.2 billion base pairs in a human genome are common to almost all humans (i.e., excluding people having major genetic defects). For this reason, biologists will speak of the human genome, meaning an average-case genome derived from a collection of individuals. Such an average case genome can be assembled for any species, a challenge that we will soon discuss. The biological analog of identifying unknown text arises when researchers encounter a molecule of DNA from an unknown species. Because of the base pairing relations of the two DNA strands, cytosine and guanine will always appear in equal amounts in a double-stranded DNA molecule. Thus, to analyze the symbol frequencies of DNA for comparison against a database, we compute the molecule’s GC-content, or the percentage of its bases that are either cytosine or guanine. In practice, the GC-content of most eukaryotic genomes hovers around 50%. However, because genomes are so long, we may be able to distinguish species based on very small discrepancies in GC-content; furthermore, most prokaryotes have a GC-content significantly higher than 50%, so that GC-content can be used to quickly differentiate many prokaryotes and eukaryotes by using relatively small DNA samples. |
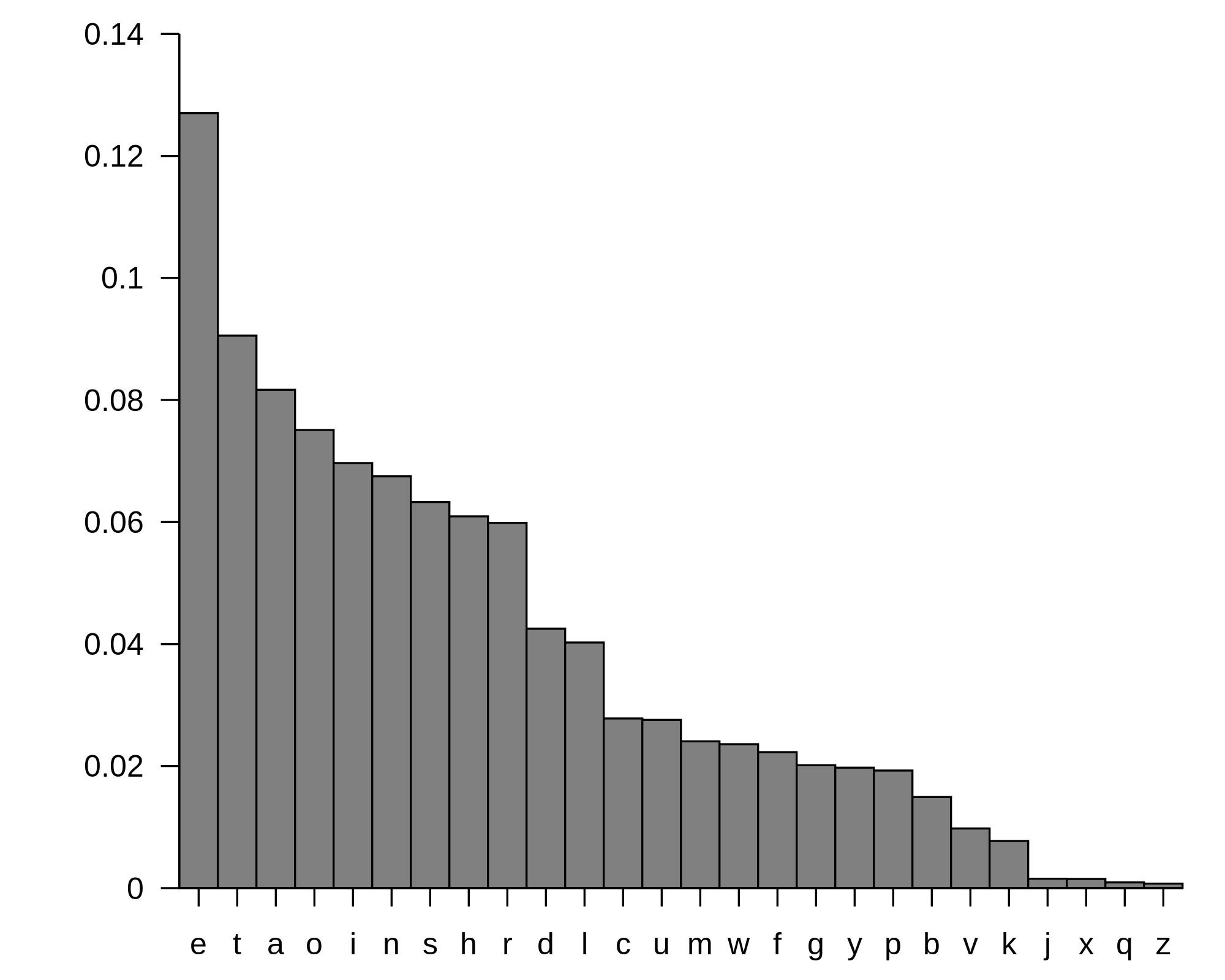 Figure 1. The table above was computed from a large number of English words and shows for any letter the frequency with which it appears in those words. These frequencies can be used to reliably identify a piece of English text and differentiate it from that of another language. Taken from http://en.wikipedia.org/wiki/File:Englishletter_frequency(frequency).svg..svg.) |
|---|---|
Problem
The GC-content of a DNA string is given by the percentage of symbols in the string that are ‘C’ or ‘G’. For example, the GC-content of “AGCTATAG” is 37.5%. Note that the reverse complement of any DNA string has the same GC-content.
DNA strings must be labeled when they are consolidated into a database. A commonly used method of string labeling is called FASTA format. In this format, the string is introduced by a line that begins with ‘>’, followed by some labeling information. Subsequent lines contain the string itself; the first line to begin with ‘>’ indicates the label of the next string.
In Rosalind’s implementation, a string in FASTA format will be labeled by the ID “Rosalind_xxxx”, where “xxxx” denotes a four-digit code between 0000 and 9999.
Given: At most 10 DNA strings in FASTA format (of length at most 1 kbp each).
Return: The ID of the string having the highest GC-content, followed by the GC-content of that string. Rosalind allows for a default error of 0.001 in all decimal answers unless otherwise stated; please see the note on absolute error below.
Sample Dataset
>Rosalind_6404CCTGCGGAAGATCGGCACTAGAATAGCCAGAACCGTTTCTCTGAGGCTTCCGGCCTTCCCTCCCACTAATAATTCTGAGG>Rosalind_5959CCATCGGTAGCGCATCCTTAGTCCAATTAAGTCCCTATCCAGGCGCTCCGCCGAAGGTCTATATCCATTTGTCAGCAGACACGC>Rosalind_0808CCACCCTCGTGGTATGGCTAGGCATTCAGGAACCGGAGAACGCTTCAGACCAGCCCGGACTGGGAACCTGCGGGCAGTAGGTGGAAT
Sample Output
Rosalind_080860.919540
解题思路
关键是如何用 C 处理按行输入问题,非常麻烦。
#include <stdio.h>#include <string.h>#define N 30int main() {float maxContent = 0;char ch = getchar(), seqId[N], maxSeq[N];while (ch != EOF) {// 1. handle the seqIDif ('>' == ch) {ch = getchar();int idx = 0;while ('\n' != ch && ch != EOF) {seqId[idx++] = ch;ch = getchar();}seqId[idx] = '\0';}// 2. handle the base(ch = '\n')int G = 0, C = 0, len = 0;while (ch != EOF && ch != '>') {G += ch == 'G';C += ch == 'C';len += ch != '\n';ch = getchar();}// 3. compare the max valueif (((G + C) * 100.0) / len > maxContent) {strcpy(maxSeq, seqId);maxContent = ((G + C) * 100.0) / len;}}printf("%s\n%f\n", maxSeq, maxContent);return 0;}
测试用例集:
>Rosalind_0605ATGAATGTTTGACTACTGGTGCGCTCGGGACTCACTATGACATGAAAGGTAATACTTCAAAGGTTTCGAATGCTTACGTTTATCACCCAGGCCCAATACCAGAGGAATGACTCCAGGGCGCACGCTACCCAGAAGCGAGTCATGGACATTACTATAACCCAATGCGAGAAAGATTTACTGGTTGAGTTGAAAGGGTATGCCGGATACTCATCTTTGACGACTTTTGCTTGTGCTCTAGAATTCTCGTGTTTGCTGGTAGGAGTGGACCAATTCATCTTTGCCTCGATAAGGAGGTTGCCCACGGTGCCTTCATGCGGGCGCAAGCGTGCCCCCCTCTTTTATAAGCGCGCCTTCAAGTCGGTAGTGATTCCCCGGATTTAATCAGACACGTAACCTCATTTCACTTTGCGGTGATTTTGCTACAATAGCTCAGGTGCAATCAGCACAGTCTTAAGGCCCCAATAGGGAAGCCAGGTCTGGGCCCTTTGAGGCGGAAAGAATAGCCAATGCCAGATCGGTTATCAGGAACATTGTTTGCCGATGACTGTCTAACAGAAGCGGTAGGGGAGATGATTTCCAGGTTCCTCGCGTTATCACGAGTACGAGTTCGGGGAACCTGTCTAGTCAGCAACCCGCAGTCACCAGATTGGGATGCGTGGCTCTGAACAGGACCCGGTGACGGCTGTTGGTGCTTCCCCTATTGGCGAGTGAGCATAGTAAGTCGTATAGGGTGCGTGTACTATTCAGGTAAGAATCGTTAATTTCTCCTATCCCCCGGAACCCTGACTCTAAGCCAAATTCGACGCTAATCGCTAAAGCTATGTTTACACGGGATAGAGGTGCCTGCGAGTCCACTGAAGATCGAACACTAAAAGGGGGTAAGGCCATGTTTATGGCCTAATCGGTATTAAAAAAGTA>Rosalind_2432GCATTAGGAGGTCTAGGCGACTCACGAGGTGGTTCTATACGCCACCTTATGAAAGGCAGTAGCAAGTCCTTCAAGTTCTATATGTGATGATGCAGACACAGCAGTTTAACGGATTAGCCAACGAGCCTGTGGGAGGATGACTGAGGTCTCTCGCTAGTGGGCGTGACCACTTTATTAGGAGTCGTGCTCACTACGGATGAAATGTCCGTCATGATTGGGCAAGACCCACGGATTACAACATATCTTTTTATCCCCGCACGCTACGAGCCCTTGAACCCCTAATCGCCACGCCAATCAATCTAGTGCGGCGAACCAATATGATAGCGAAGTGAACCGTGATCGGAGTCTATGTCGTCTTCTGTTTTTGGGACACGCACGAAAGTTCAACAAATCTTAGTCACTTGAGAATATGTTCGGTTCTATAGCACCCTAAGCCCGAAAGACACAGGAAGATCATGCCCCGTAATCACTGGGTACTATCTAGGTCACAGGCCCCCATAGTACAAGAACTGCTAGGCGACCAGTGGAACACCCCTAAGGTATTGCACCGGGGGCCCCACTTAGCGCTTAAGCGTACATGAACCTGCTCGCGCATACCCATTTGTCAGGGCGCGATAGCAAATACGTCGCTGGCTCGATTTTAGCGCGCTCGTCAACTATACATAGAGAATCTCAGCGAGGATGGGTAGACCTAACGACATCCTAGCCATCACATACCTTACTCCGGGGTCTGTTGTCACCGACCGGCAGAGTATTACAGGACTCAATTACTTAGCATATAGTTTGTGTAGCACACATAAATTCCCCTAACCTGGGCGCCACGGAAAGGTCCTATAGCGAGCATGATTACTTAAATCTTTGGAGGATTTGCTGTGCCGACCTATGGGAGAAGCAGTTTTTACCGGAACATTGATGTAGCTGTTTGTCCCCTACACATCCCATTATATAAAAGTCCCATAAGGTACATATATCCAAAGTCAGATGCGAT>Rosalind_3691ATCGGCAGTTCGTAGGTTATTCATGGTGAACTAAGGGATTTGGGTCAATCTGCTACGACACACTTCGCTAGAGCCTTTGAAGGGAATCTCACCGAGGCACTTGCCACTGTCCACGCACGGGGGTTTATATATCTGGCATGTCCTATTTTGTAGCGGCGGCTGCGTGGGACTCCAGTGCGAGTTCCTTCCCAGTATGATGAAAGCATACGACAAGCTGGGTATGCGAACGGGATGGTTGCGTCGGTATACGATATTACGTGACACGTGTTCGTCAATGCATTAAATCCACGTCTACTGTTAGACGGACCAATAAGTAGCCGGTCATAACGCCCAGAACTTTCAAAATCGTACGGGCAAGGCTTCACGAAGTGTCCCCCGATCTTTGCCCCATCTTAGGACGAGCAATGACATCCCAAGGAGGGTCTCGGCATACCATGACGTTATGGCGCCGATGACTAAAACCCCCTAATATCGACTGCGGAGTCGTCCTGTTTGTGTAGAATTTTATAATTTAGGTTGAAACAGCCTTTTGGCCTTCATTGGAACCGTTTACCAGATATTCAGGCTTCAGCCAGCACTCAACCACGCCCGGACGTACGCCCGGACTCGCAAAGGATTTTTCATAAGGATATTGAATAAAAAGTGGCGAGGGAAATACTTTGCGTGGCTGCCGATGCCGAACGGCCGATATCTCAGCACCGAGATAAACAGGTGAAAGTATATGCAGACGCAATCTCGTACGGAGATCATTGGATGATCCCGTATGCCTAACGTTACATTGAATACAACCGTTCCCGTTCAGGAAGACTGGCCAAACGGTGTTACTCAGTCACTGCCGCTACTCTGTTGGCACTTTAGAAAATGGTTGCCAATCTTCGCAACACTTGATTTCGCCGCTGATTAGCGAAACGCGGGAATTCACTACACTTCTCCGTGCGCTACCAATAAGAGTACAGGCGCCG>Rosalind_5892GCTACTTGCATCACCATGCAGCAACGCTACGTATAGGGCACATCCCACGTACGGAAGATTGCTTGCTTCCATCTCTTGGGCACGGACTGCACGATGCATTGTGCGACCTCAGAGCTCATCTTCCAGATTGTCTTCCGTTAGTGCCGCCCCAGTTTGGGTCCTGAGGCTCTATTGCGTTCCGCAGTTGCCTTACGACATCGAGTATTTTCGTCGCCTAGCGTCGCTGCCTAATCTCTAACTTTGGTTGAACGGCCGACGAGGTGATAGAACAAAGGATTTACTTCTCTACGTATTGCACGATCGCTGCTGGTGCCAAAGGCAATGTAGAATAGTACCCTAACAAACAGAGGTAACACCTAGAGCGTCCGTTTCCCTAATTTCTGTTAATGCCACATTTTTCGGATTTTAGTGCATGAGCTTTCGTAATTTTAGAATTTGAGACCTATTTCAATACATCATTGAGAGCTTGCTCCGTTACTCGATCCCCACCAATGAAGCAAGATTCAAGGGCGGGAAACCCCTCCAAACCCTGGGAAACAGAAACGCTTTACTAACGCTCAACAGCACAAGTCCTAGCTGACGACGACGCGTGTCTTCTTGTTATATCTAAAAACCACGGATTATGTCTAGACTATGACAGCTTTTACGTGGCGACCGAAAGGACGACAGTTAACTTTACGGTCGGGGTAGTCAAACGCGTAACTAGCCGACGCACTGGTCATTAAAGGGCGCCGAAACATATTGCTAATTTGGGTCTTAGTATATCATCACATGCCCTTGTTACCACGTTCCGCTTGCGCACTACACCGGTCCCCGAACACTTAAACACTCCCTCGAGGATATGTAGTACCTGCCCCCATGGAAGGGGTGTGCCGCGTGTAGTGGCTCTTATCCTTTTTTA>Rosalind_2852ATTATGGGATAACCCAAAATGATCGATGTCGATCGAGTAAATAGCCATGTTTAGAGTGAGATCTGCTCATATGTATTTTCAGTCCACGGGTATTTCTACTCCACAGCGTCGGAATCTTCCGGACCTACAGCGCGGCTCGGTGTGCGCACACGGATAATCCGGGTCAAATAACGCCCTCCGCACAACGAGAGGCAACTTAAAGGAGCTATGTAGGTGTATTAATCTACGAAGTCTACCACACTAACACTACCTTAGGCACGTAGACTGCAGTGGGCAGCTGTTGGCCACATAATATAGGTTGGGAATGAACATGGCTGTCTACTATAAGATTCGACTTGGCCGACGTGGGGCTCGTATCGGATCGAGCTTGTCCCCAAAATGCAGTTTATTCCGAGCGTTCTCCGGTGTGGACACTAACTGCCAAAGCCTACCACATAGGTCTGCAGGGAGGCATCTTCTCCTGTACAATTCGATTCGGTAGAAATGAGATGAGTGGAGTCAGCCATCGAGACTGAAGTTCTGTAAAGGGCTGAGTTCAGTTTATTAACCTAGCGACTGTACGTTCTAAGGATTCGTACGAGTATACCTCCTCCCCGTACGGGGGTTCATGTTGCGTGGCGTTAGCCCGTTATGATCAGAAGAAGAGCAAACCTTAGCGGGTATGACGGTCGTGATTGTATCGTGGAAATTTCTATGTGGAGGCTAGTGGATTTGACTGTGAGCAAGCGAACCCCAACGGGGACCGATTGGTCGTACAGCCTAAGTGGTAGTCTGATCAAGTGGCCAAAAGCAGATTTAGACCCGCCGACAGGTAGATGACACTAGTTTTTGTGAAGCCCTACCGTACTGGCCGTCGGTAAGTGGGAGTTTCATCCCACCTC
编译运行:
b12@PC:~/ROSALIND/Computing_GC_Content$ gcc -Wall ./GCcontent.c -o ./GCcontentb12@PC:~/ROSALIND/Computing_GC_Content$ ./GCcontent < ./dataset.faRosalind_369149.376301

若有收获,就点个赞吧
0 人点赞
