The Second Nucleic Acid
| In “Counting DNA Nucleotides”, we described the primary structure of a nucleic acid as a polymer of nucleotide units, and we mentioned that the omnipresent nucleic acid DNA is composed of a varied sequence of four bases. Yet a second nucleic acid exists alongside DNA in the chromatin; this molecule, which possesses a different sugar called ribose, came to be known as ribose nucleic acid, or RNA. RNA differs further from DNA in that it contains a base called uracil in place of thymine; structural differences between DNA and RNA are shown in Figure 1. Biologists initially believed that RNA was only contained in plant cells, whereas DNA was restricted to animal cells. However, this hypothesis dissipated as improved chemical methods discovered both nucleic acids in the cells of all life forms on Earth. The primary structure of DNA and RNA is so similar because the former serves as a blueprint for the creation of a special kind of RNA molecule called messenger RNA, or mRNA. mRNA is created during RNA transcription, during which a strand of DNA is used as a template for constructing a strand of RNA by copying nucleotides one at a time, where uracil is used in place of thymine. In eukaryotes, DNA remains in the nucleus, while RNA can enter the far reaches of the cell to carry out DNA’s instructions. In future problems, we will examine the process and ramifications of RNA transcription in more detail. |
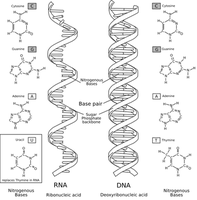 Figure 1. Structural differences between RNA and DNA |
|---|---|
Problem
An RNA string is a string formed from the alphabet containing ‘A’, ‘C’, ‘G’, and ‘U’.
Given a DNA string t corresponding to a coding strand, its transcribed RNA string u is formed by replacing all occurrences of ‘T’ in t with ‘U’ in u.
Given: A DNA string t having length at most 1000 nt.
Return: The transcribed RNA string of t.
Sample Dataset
GATGGAACTTGACTACGTAAATT
Sample Output
GAUGGAACUUGACUACGUAAAUU
解题思路
本题就是让把给定 DNA 中的 T 换成 U 输出即可。
#include <stdio.h>int main() {int A = 0, C = 0, G = 0, T = 0;char base = fgetc(stdin);while (base != EOF) {if ('T' == base) {base = 'U';}putchar(base);base = fgetc(stdin);}return 0;}
测试用例集:
AATGAATCTCGCAATCAATGGAGCTAAGCGTCCACAGACTAGCTTCATTTCCACTTGTGCTCACGATAGGACTAATCTGTATAGAAACCATGAGCCCTCACGTGAACGTTGTTCTTCACATTGATCTTCGAAGCTCTGTTATAAGTTAAGTCGTTACAAAGCGGCACATCCTTCTCTCAGTCAAGTTACTATGATATTACATTCATAAGACAGAAAAACCCTGAGCGGCATTCAGAAAAAATTTACTATATACTAGGCAGTTTGACGGCCTGAAGGAGATCCTTCCGTGACATCACAATGTACATGCGTAACTGAGACCAAACAAGCATTCGGTGTCCGGCCGGCTTCTCCCCGTAAACAAGGTTCCCGGGCCAAGAATAACCACCTATTGTCAACTTACGAATGTGCAAGGGTGCACGTTGAAAAAAGTTTTTCGAGGCCGGGAATTTATAGATTCAGCGTCATCCTTTAAGAACGGCTTGTAACCCATGCCCATCCCAAATCACAGACCGCGCGCGCGAAACACGACCAGCCGCACCGGCCCGTCCACGTTTGGTTCCGAACAGCCCATATTACCGGACTCCTTATCCGTACACTGCCGAAAGTTCTTGTCCTACGTGACTGAAATCCTAACACCTAATAAGCAATTAGAGGACAAGTATTGTACTGTCAACCTGCTCCCCGGATCAGCTACCACGTACCAATAGAATCTAGCGATACTGCGTTCAAGAGCTAGCATGGATTCCACGGCAGGCTACGCGGAAGGCGGCCCCGCATCAAAGGAGTTAAGGTGGTCCGAGGAACGGCTGACTACTTCTACGCGCGTTAAACTATTATTGCTCCCGGCTACGGCCGCGTTCCGTTGCGCTGTAAAGCAGCCAGGGTCCTGCCAAGCCTTCGTCGACAGAGCTTGCCGACTGCGCCGCCCGATGCATTACCAGATAAGAAATAGTACTCAGTCGG
编译运行:
b12@PC:~/ROSALIND/Transcribing_DNA_into_RNA$ gcc -Wall ./T2U.c -o ./T2Ub12@PC:~/ROSALIND/Transcribing_DNA_into_RNA$ ./T2U < ./dataset.txtAAUGAAUCUCGCAAUCAAUGGAGCUAAGCGUCCACAGACUAGCUUCAUUUCCACUUGUGCUCACGAUAGGACUAAUCUGUAUAGAAACCAUGAGCCCUCACGUGAACGUUGUUCUUCACAUUGAUCUUCGAAGCUCUGUUAUAAGUUAAGUCGUUACAAAGCGGCACAUCCUUCUCUCAGUCAAGUUACUAUGAUAUUACAUUCAUAAGACAGAAAAACCCUGAGCGGCAUUCAGAAAAAAUUUACUAUAUACUAGGCAGUUUGACGGCCUGAAGGAGAUCCUUCCGUGACAUCACAAUGUACAUGCGUAACUGAGACCAAACAAGCAUUCGGUGUCCGGCCGGCUUCUCCCCGUAAACAAGGUUCCCGGGCCAAGAAUAACCACCUAUUGUCAACUUACGAAUGUGCAAGGGUGCACGUUGAAAAAAGUUUUUCGAGGCCGGGAAUUUAUAGAUUCAGCGUCAUCCUUUAAGAACGGCUUGUAACCCAUGCCCAUCCCAAAUCACAGACCGCGCGCGCGAAACACGACCAGCCGCACCGGCCCGUCCACGUUUGGUUCCGAACAGCCCAUAUUACCGGACUCCUUAUCCGUACACUGCCGAAAGUUCUUGUCCUACGUGACUGAAAUCCUAACACCUAAUAAGCAAUUAGAGGACAAGUAUUGUACUGUCAACCUGCUCCCCGGAUCAGCUACCACGUACCAAUAGAAUCUAGCGAUACUGCGUUCAAGAGCUAGCAUGGAUUCCACGGCAGGCUACGCGGAAGGCGGCCCCGCAUCAAAGGAGUUAAGGUGGUCCGAGGAACGGCUGACUACUUCUACGCGCGUUAAACUAUUAUUGCUCCCGGCUACGGCCGCGUUCCGUUGCGCUGUAAAGCAGCCAGGGUCCUGCCAAGCCUUCGUCGACAGAGCUUGCCGACUGCGCCGCCCGAUGCAUUACCAGAUAAGAAAUAGUACUCAGUCGG

若有收获,就点个赞吧
0 人点赞

{kind=link}