https://paperswithcode.com/paper/omninet-omnidirectional-representations-from
总观
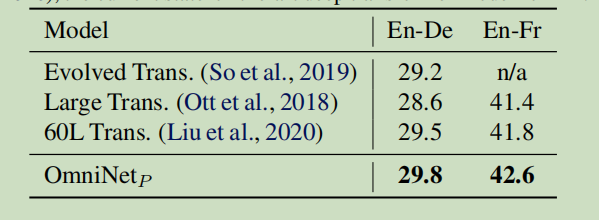
在本文中,我们提出了OmniNet,它使用全局注意力,通过自注意力来连接整个网络中的所有标记(tokens)。为了管理整个接受域(the full receptive field)的计算成本,利用快速、高效的自注意模型对全网络中的元学习进行了参数化(the meta-learner is parameteried by self-attention models)。该方法在众多自然语言和视觉任务上都取得了优异的性能。具体地说,Omninet在WMT EnDe和EnFr上取得了最先进的性能,性能优于深度60层transformers。OmniNet在图像识别任务上也比ViT有了显著的改进。
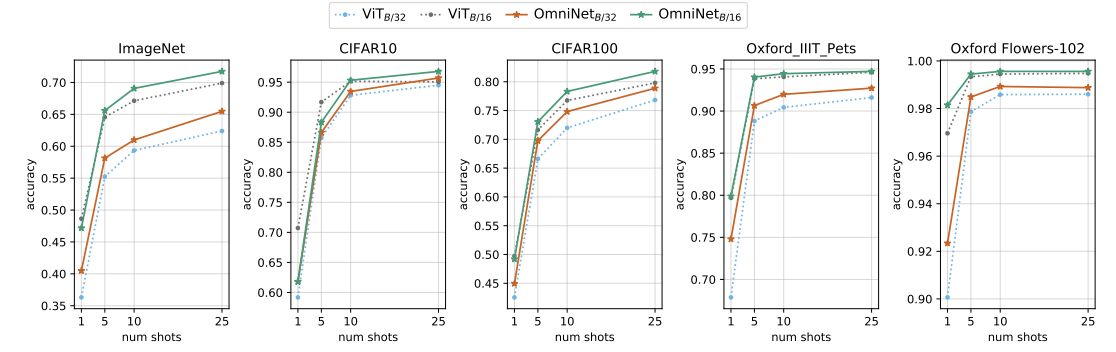
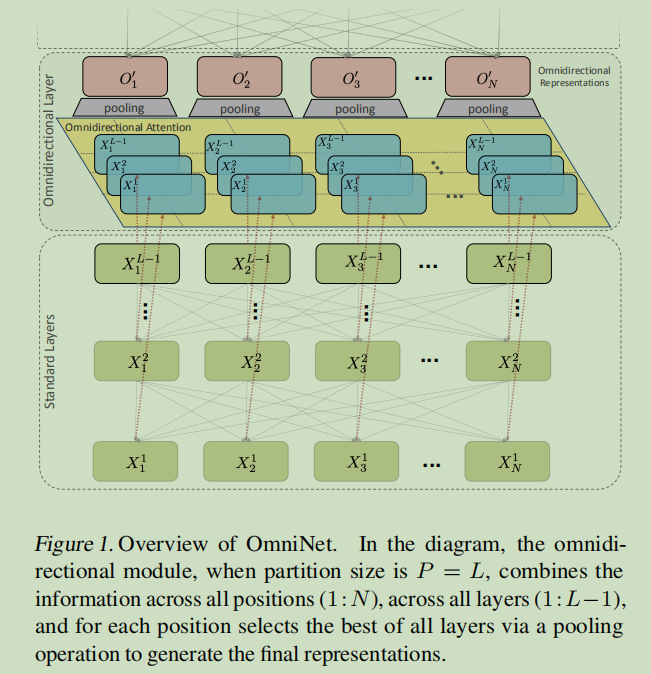
上图:这里对比了Omni模块与标准模块的实现区别,其中虚线框表示一个模块,框内的水平顺序叫做位置,框内的纵向顺序叫做层数。
可见,在Omni的模块内部中,所有层的所有位置都进行了注意力。反之,在标准的模块中,通常只有最后一层进行了注意力。
看看模块内部的注意力机制是如何实现的?
上图:每个神经元是一个d维的向量,其所在位置由N表示,其所在深度(层)由L表示。
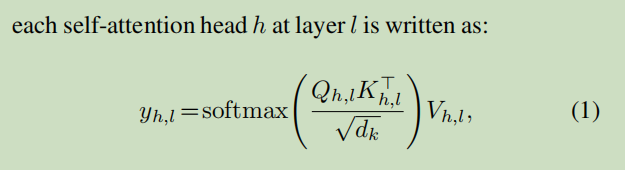
首先:定义两种基本的算法。第一个是Omni模块采用常规的多头注意力算法; 第二个是Omni模块内部的相邻层之间的转化算法,该算法是一个残差结构,但采用了层归一化(简称FFL:Feed Forward Layers) 注:连续的FFL算法构成了后面所谓的xformer算法
第一步,使用FFL算法得到模块内每一层的输出,即进行xformer(X)算法。具体:对于输入X(即上个模块的输出,尺寸为Nxd),使用上述的FFL算法对模型内部的相邻层进行向前传播,并且返回所有层的输出结果(每层的输出尺寸均为Nxd),这些输出结果表现为图中的X1,X2,…XL ,但在实际上,它们按照L维度被合并为LxNxd的张量 。 注:xformer的输入尺寸为Nxd, 输出尺寸为LxNxd,
第二步,对于所有位置进行注意力打分。 对上述xformer(X)的输出进行位置标记,并在各个位置进行注意力打分,其中位置标记即IndexSort部分,注意力打分即Attend部分。 注:Attend(IndexSort(xformer(X)))的输出尺寸为LxNxd。
第三步,得到最终的注意力得分。 对上一个的输出,直接在L维度上进行最大池化。 注:输出尺寸为Nxd
最后一步,得到最终模块输出。 模块内部的最后一个层的输出 + 最终的注意力得分 注:输出尺寸为Nxd,这个模块的输出又作为下一个模块的输入。

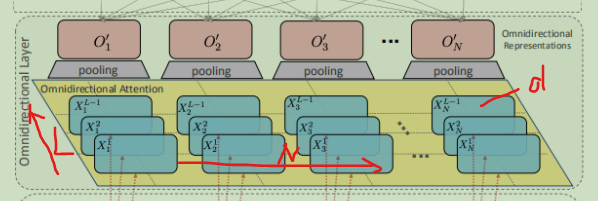
看看模块之间做了什么?

上图:定义了超参数P,表示模块内部的层数。当层下标 mod P = 0时,即模块内部的最后一个层时就进行模块内所有位置的Attend操作,否则就进行模块内部的xformer算法。

若有收获,就点个赞吧
0 人点赞
