


摘要
- 解决问题:计算机对手写数学符号公示的识别。
- 现存问题:现存方法仅在形状上识别数学符号。
- 贡献:作者提出CAC(上下文纠正)的模型,将结果提高了5.34%。 读者注:注意是纠正。

介绍


相关工作
- 手写数学公式的3种认知方案:符号分割、符号认知、结构分析
- 直接使用3种认知过程去解决问题。
- 存在问题1:之前的错误会地影响之后的认知
- 存在问题2: 没有考虑上下文。
- 针对以上问题: 一些学者提出的利用二维随机上下文无关文法、隐马尔可夫模型和公式中的上下文信息解决办法,但都没有什么效果。(这段论述是作者引用的Naik et al. 2017).)
- 直接使用3种认知过程去解决问题。
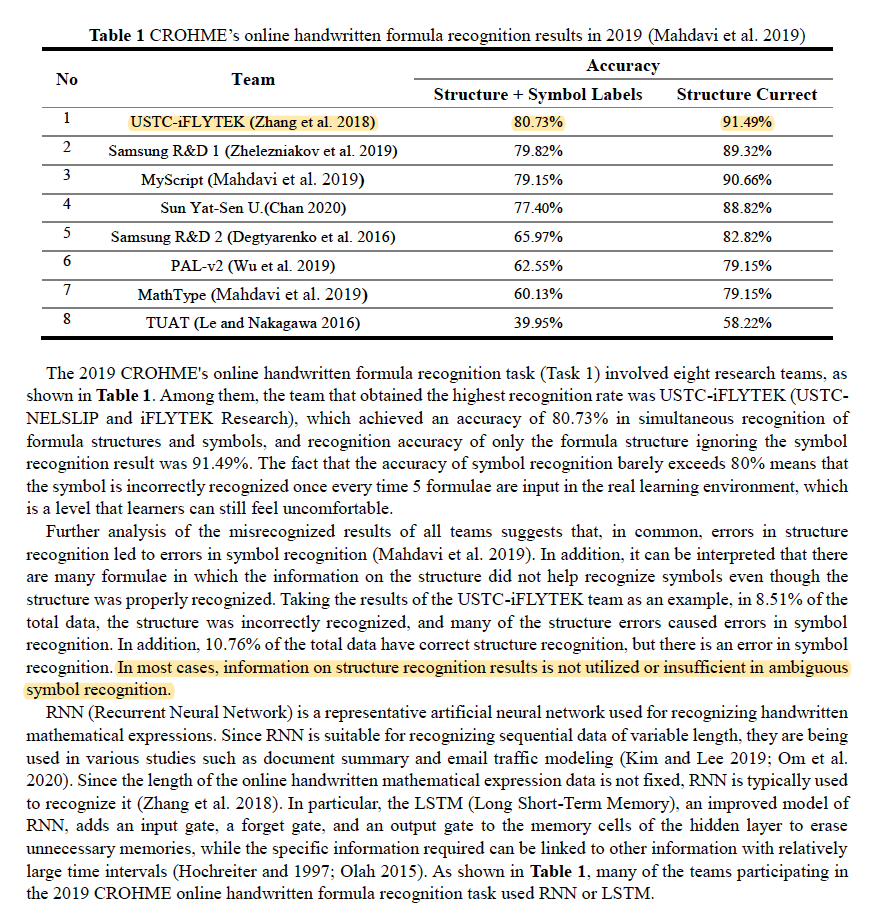
- 关于CROHMS比赛
- 科大讯飞在2019比赛中拿到了第一,但是作者分析出一个关键结论(问题):大情况下,公式中的结构信息被识别的很好,但是这并没有给符号的识别提供什么帮助。
- 作者的实验室数据集:2019 CROHME在线单符号识别任务(任务1a)提供的符号数据集。
读者的疑问 (关于CROHMS比赛部分):
- 可以直接得到上诉关于结构对识别没有帮助的结论吗?论文给出的CROHMS比赛结果只包含“结构+符号”的识别率和“仅结构”的识别率,除非增加“仅符号”的识别率。
- 为何作者的实验数据采用单符号识别的数据集?这于作者提出关键问题的比赛数据集不符合。
- 后文可知,作者所谓的结构居然是指符号出现的位置,即主题、题干、解题、答案。 令人吃惊!难道该比赛所说的structure是指这种结构吗?

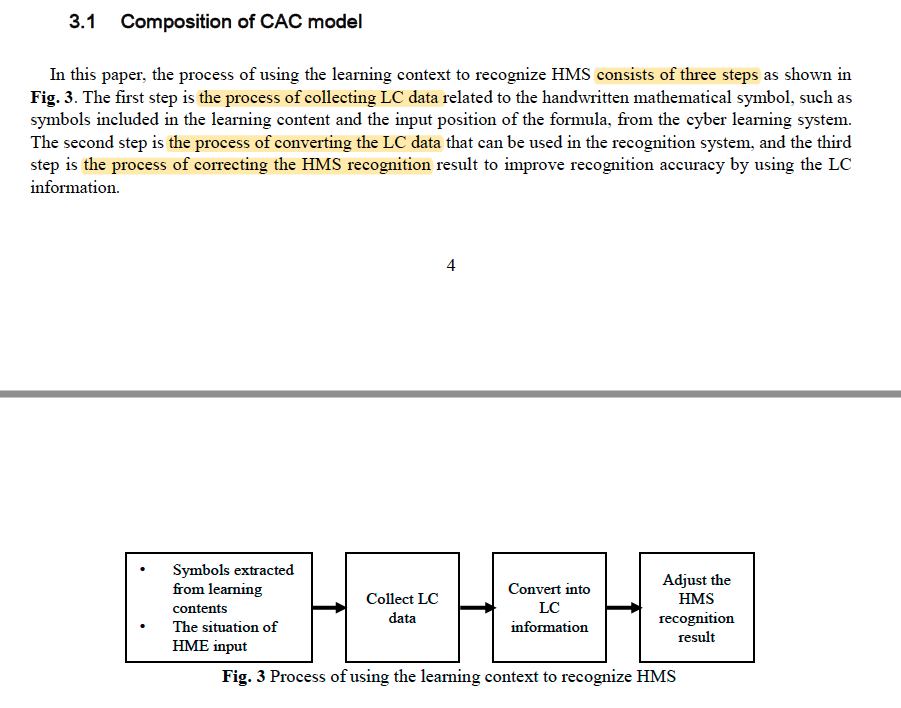

CAC模型总揽
CAC模型认为3步,也对应3个模型。LC: learning Content
- LC数据收集模块
- 生成提取符号矩阵
- 生成符号频率矩阵
- LC信息生成模块
- LC信息识别模块(LSTM模型)
读者注: 论文似乎没有解释所谓LC数据集到底是什么??? 但是论文下文,可以大概知道是中学数学课程中557道题(Yang 2011)中的50个符号,进行频率。 这个频率来对作为对比的数据集进行取一部分来做LC数据集。这个LC数据包含了其在不同出现位置的频率(位置时指下文提出的4个学习部分,即主题、问题、解答、答案)

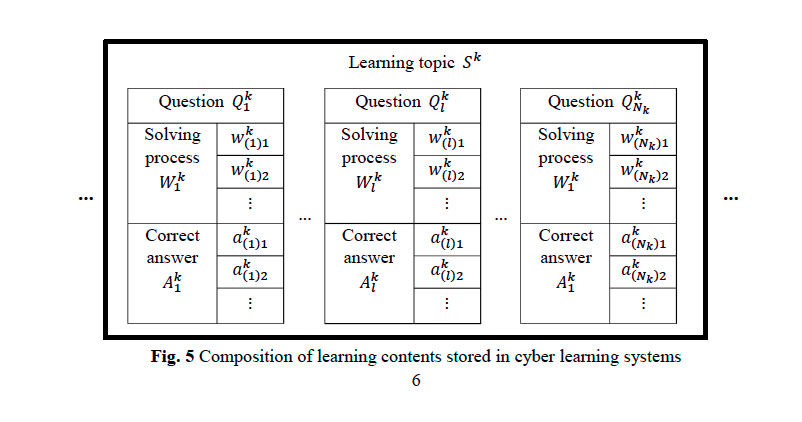

CAC模型之1: LC数据收集模块(1)生成提取符号的矩阵E
存储的学习内容由四个学习部分组成:学习主题、问题、解决过程、正确答案。
读者注::实际上是将公式中的符号按照出现的不同使用场景添加到特定的字典中。
读者疑问1:表格标题中的from learning contents是什么? 文本?
读者疑问2: 分类依据的依据?(后文提到:“学习者在学习过程中输入公式的地方有两个:求解过程和答案。学习者在每个位置主要使用的符号是不同的。此外,即使每个位置使用相同的符号,其含义也可能有不同的解释。”。但是如此的划分依据是否严谨?)

CAC模型之1: LC数据收集模块(2)生成符号频率矩阵Ro
对上一步生成提取符号的矩阵,按4个学习部分分别进行符号的频率统计。比如,𝑅𝑊 , 表示求解过程中的频率,以及𝑅𝐴, 表示正确答案中的频率。

CAC模型之2: LC信息生成模块 (符号期望矩阵R)
- 矩阵R的来源:
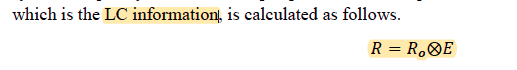
读者注:某学习部分的信息矩阵 = 某学习部分的提取符号矩阵 ⨂ 某学习部分提取符号的频率矩阵。更简单说就是将符号按照不同的使用场景(即4中学习部分)分别进行期望计算,结果由矩阵的形式保存。R为(4,nD)矩阵
- 矩阵R的作用:
进一步将矩阵R和手写识别的结果y0合并为矩阵L, L为(5,nD)的矩阵。
读者注:如何合并作者似乎没提,但是根据论文上下文可知,y0位(1,nD)的向量,R为(4,nD)矩阵, 所以合并方式应该是concat。
读者注: nD是字典的索引,这个字典就是在LC数据收集收集块中的字典。

CAC模型之3: LC信息识别模块((5,nD)的L矩阵 —> (1, nD)的模型输出向量)
作者认为第一个问题是:如何将R矩阵(LC信息生成模块的输出) 应用到当前模块中。关于此,作者有关键分析:
- 存在问题:每个学习部分使用的符号列表和符号频率率也会因学习范围和学习内容的不同而不同,因此这些值也会随着学习情况的变化而变化。(读者注:R矩阵可以看作权重矩阵,但是R矩阵本身是随输入而变化的)
- 解决办法:在CDC模型中,可以用神经网络来获取可变的权重,以此来调整目标任务的识别结果。
- 存在问题:识别结果应与LC信息中的所有子上下文信息相关(all sub-contextual
information),但是识别结果和所有子上下文信息相互影响着。(读者注:鸡生蛋,蛋生鸡问题)
- 解决办法:LSTM 应用于LC信息识别模块。





实验
使用与实际学习情况相似的数据集,根据是否使用LC信息,比较HMS的识别结果
在本文的实验中,使用与实际学习情况相似的数据集,根据是否使用LC信息,比较HMS的识别结果。
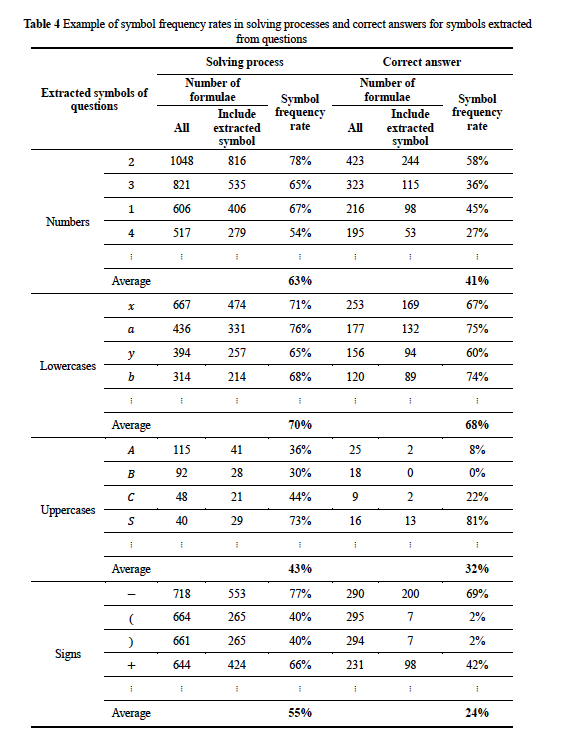
- 表3、表4、表5、表6、表7。 读者注:对符号频率进行调查:
建立并分析了中学数学课程中557道题(Yang 2011)中使用的50个符号和LC数据,这些符号和LC数据以有理数、单项式计算和多项式计算为单位。下面是2个结论和1个假设:
- 解算过程部分和正确答案部分的符号频率率存在差异。
- 求解过程在求解过程的公式中比在答案的公式中使用得更多。
- 本文假设学习者在答案部分输入的公式与正确答案的所有公式相匹配。 因为:由于正确答案通常是唯一的,并且学习者尝试尽可能地写出相同的答案,因此可以预期学习者的答案与正确答案匹配的概率非常高。
读者注:对垃圾结论和不严谨的假设而放置这么多表格,非常不认可。
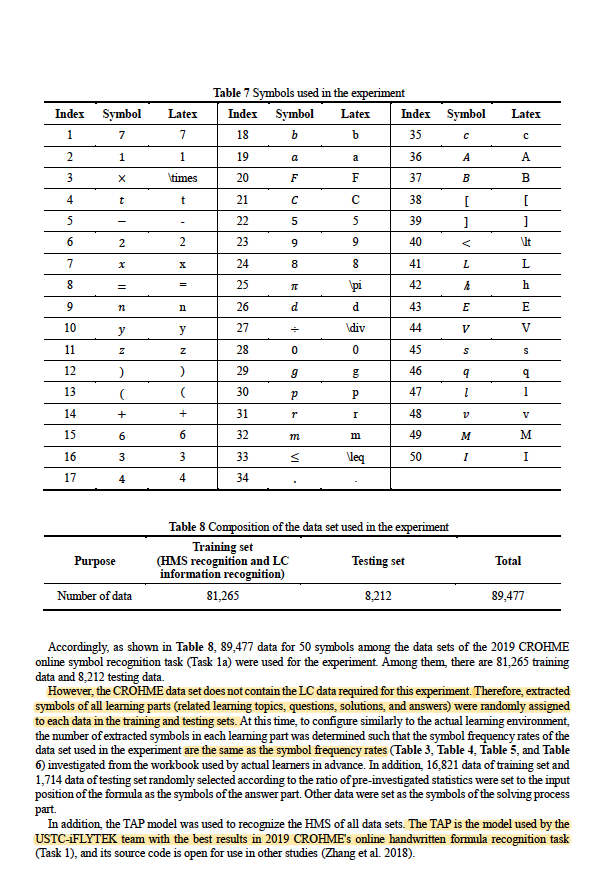
- 表8 :2019年CROHME在线符号识别任务(任务1a)数据集中50个符号的89477个数据。其中,有81265个训练数据和8212个测试数据。 读者注:CROHME数据集的问题以及解决办法
- 存在问题:CROHME数据集不包含本实验所需的LC数据。
- 解决办法:
- 从训练和测试集中随机分配给提取符号到:4个学习部分(主题、题干、解答过程、答案)。并且符号提取频率参考了之前表3至表6的符号频率。
- 按照之前的统计,随机抽取16821个训练集的数据和1714个测试集的数据作为答案部分的符号。
- 解决办法:
- 存在问题:CROHME数据集不包含本实验所需的LC数据。
读者注: 原文写得好乱,见下原文。
TAP模型用于识别所有数据集的HMS。(TAP模型为科大讯飞团队的CROHME2019比赛所使用)
表10、表11: 最终的数据集,以及实验对比。 读者注:证明CAC有纠错作用。
- LC信息识别模块中的神经网络结构
作者认为LSTM能够掌握HMS识别结果(TAP模型)与LC信息中顺序排列的所有子上下文信息之间的关系。

若有收获,就点个赞吧
0 人点赞
