https://paperswithcode.com/paper/enhanced-deep-residual-networks-for-single
总观
本文提出了一种增强的超分辨率算法。通过从传统的ResNet架构中删除不必要的模块,我们在使模型紧凑的同时实现了改进的结果, 见下Residual Block。我们还使用了残余缩放系数来稳定地训练大型模型, 见下残余放缩系数。我们提出的单尺度模型超过了目前的模型,并达到了最先进的性能, EDSR见下。此外,我们还开发了一个多尺度的超分辨率网络来减小模型的大小和训练时间。利用尺度依赖的模块和共享的主网络,我们的多尺度模型可以在一个统一的框架内有效地处理各种尺度的超分辨率。虽然与一套单尺度模型相比,多尺度模型仍然很紧凑,但它表现出了与单尺度SR模型相当的性能, MDSR见下。我们提出的单尺度和多尺度模型在标准基准数据集和DIV2K数据集中都达到了榜首水平。
Residual blocks

上图:作者认为BN会降低灵活度和带来计算负担,所以删去了BN,甚至也删去了外部的Relu层。事实证明表现和性能的确提高了。
Single-scale model

上图:以上是作者的基准模型,使用了32个ResBlock,每个ResBlock256层卷积。
残差放缩系数:增加深度比增加宽度有效,但是深度增加会导致训练不稳定的问题,作者提出残差放缩系数来解决这个问题,即在残差相加之前乘以一个系数,见图中绿色的Mult块。
训练策略
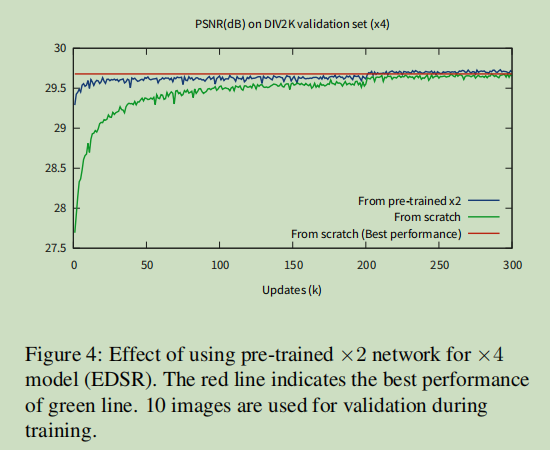
上图:在训练X4时,用X2的参数来预训练X4模型比从头训练要快一些。
Multi-scale model
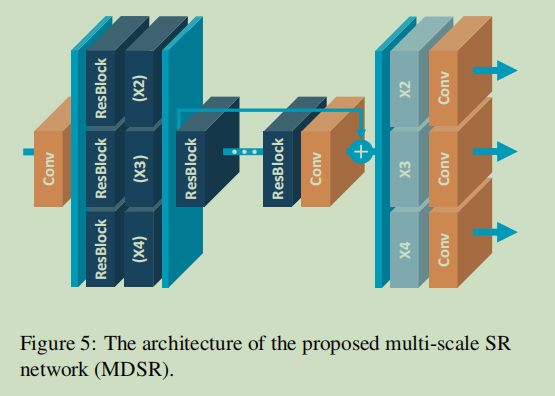
上图:作者构建了多尺度模型,该模型有80个ResBlock,每个Block有64个卷积。
详细(后续代码可见):核心部分是预处理模块和主体模块和上采样模块。预处理部分即写了X4 X3 X2的部分,这部分就是ResBlock模块的堆叠。主体部分也是ResBlock模块的堆叠,但这部分作为整体使用了残差结构。上采样使用了nn.PixelShuffle实现。另外,在mdsr中X4X3X2的不同,带了预处理部分和上采样部分的规模不同而已。
参数和表现对比
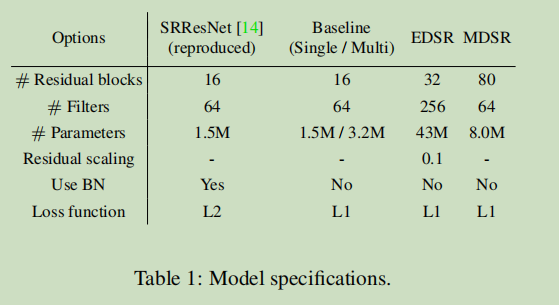
上图:相比SRResNet, 虽然EDSR和MDSR的参数还是很大的, 但是作者想强调的是MDSR的参数比EDSR小很多了。
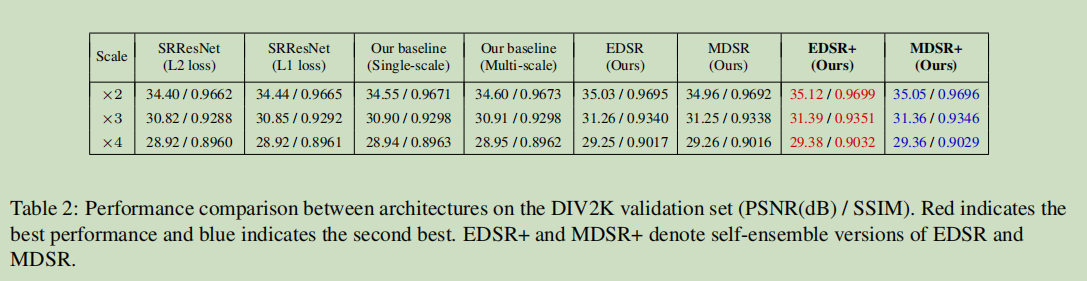
上图:DIV2K 验证集表现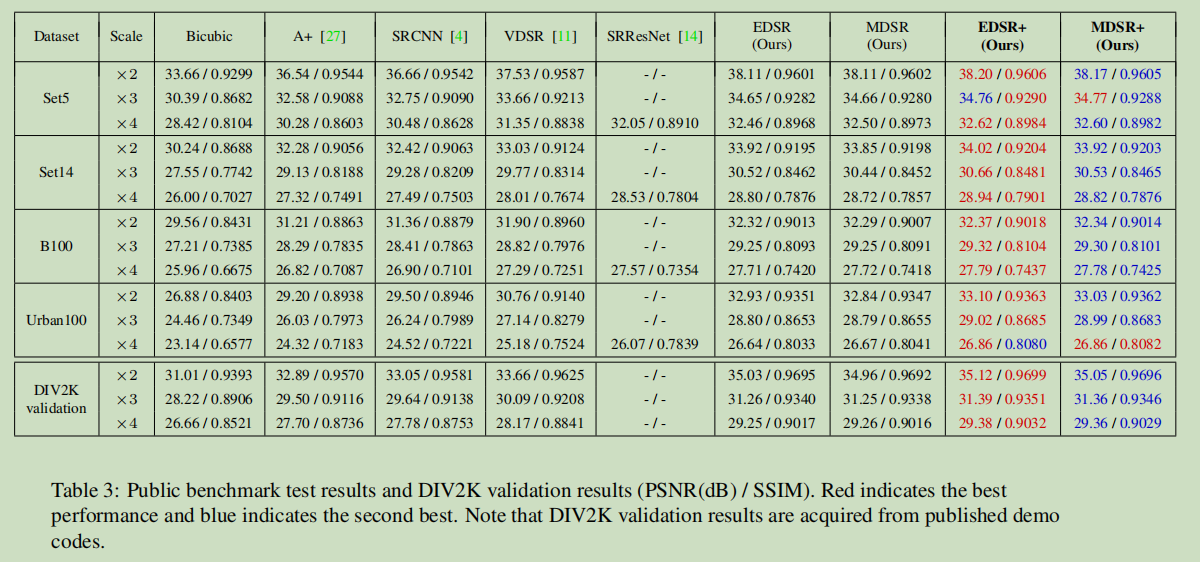
上图:基准验证集表现
训练细节
patchsize = 48X48
horizontal filps
90 rotations
optimizer = adam(0.9,0.999,1e-8)
minibatch size = 16
init_lr = 1e-4
lr_weightdecay = 每2x1e5个minibatch,对半砍lr
loss = L1
- 最大化模型的潜能
使用集成学习,使用翻转旋转等对输入图像进行增广,对这些不同增广图像的得分求均值。
代码
common.py 此次代码常规,仅需关注注释部分。
import mathimport torchimport torch.nn as nnimport torch.nn.functional as Fdef default_conv(in_channels, out_channels, kernel_size, bias=True):return nn.Conv2d(in_channels, out_channels, kernel_size,padding=(kernel_size//2), bias=bias)class MeanShift(nn.Conv2d):def __init__(self, rgb_range,rgb_mean=(0.4488, 0.4371, 0.4040), rgb_std=(1.0, 1.0, 1.0), sign=-1):super(MeanShift, self).__init__(3, 3, kernel_size=1)std = torch.Tensor(rgb_std)self.weight.data = torch.eye(3).view(3, 3, 1, 1) / std.view(3, 1, 1, 1)self.bias.data = sign * rgb_range * torch.Tensor(rgb_mean) / stdfor p in self.parameters():p.requires_grad = Falseclass BasicBlock(nn.Sequential):def __init__(self, conv, in_channels, out_channels, kernel_size, stride=1, bias=False,bn=True, act=nn.ReLU(True)):m = [conv(in_channels, out_channels, kernel_size, bias=bias)]if bn:m.append(nn.BatchNorm2d(out_channels))if act is not None:m.append(act)super(BasicBlock, self).__init__(*m)class ResBlock(nn.Module):def __init__(self, conv, n_feats, kernel_size,bias=True, bn=False, act=nn.ReLU(True), res_scale=1):# NOTE: res_scale=1 残差放缩系数,见下。super(ResBlock, self).__init__()m = []for i in range(2):m.append(conv(n_feats, n_feats, kernel_size, bias=bias))if bn:m.append(nn.BatchNorm2d(n_feats))if i == 0:m.append(act)self.body = nn.Sequential(*m)self.res_scale = res_scaledef forward(self, x):res = self.body(x).mul(self.res_scale) # NOTEres += xreturn resclass Upsampler(nn.Sequential):def __init__(self, conv, scale, n_feats, bn=False, act=False, bias=True):m = []if (scale & (scale - 1)) == 0: # Is scale = 2^n?for _ in range(int(math.log(scale, 2))):m.append(conv(n_feats, 4 * n_feats, 3, bias))m.append(nn.PixelShuffle(2))if bn:m.append(nn.BatchNorm2d(n_feats))if act == 'relu':m.append(nn.ReLU(True))elif act == 'prelu':m.append(nn.PReLU(n_feats))elif scale == 3:m.append(conv(n_feats, 9 * n_feats, 3, bias))m.append(nn.PixelShuffle(3))if bn:m.append(nn.BatchNorm2d(n_feats))if act == 'relu':m.append(nn.ReLU(True))elif act == 'prelu':m.append(nn.PReLU(n_feats))else:raise NotImplementedErrorsuper(Upsampler, self).__init__(*m)
edsr.py
from model import commonimport torch.nn as nnurl = {'r16f64x2': 'https://cv.snu.ac.kr/research/EDSR/models/edsr_baseline_x2-1bc95232.pt','r16f64x3': 'https://cv.snu.ac.kr/research/EDSR/models/edsr_baseline_x3-abf2a44e.pt','r16f64x4': 'https://cv.snu.ac.kr/research/EDSR/models/edsr_baseline_x4-6b446fab.pt','r32f256x2': 'https://cv.snu.ac.kr/research/EDSR/models/edsr_x2-0edfb8a3.pt','r32f256x3': 'https://cv.snu.ac.kr/research/EDSR/models/edsr_x3-ea3ef2c6.pt','r32f256x4': 'https://cv.snu.ac.kr/research/EDSR/models/edsr_x4-4f62e9ef.pt'}def make_model(args, parent=False):return EDSR(args)class EDSR(nn.Module):def __init__(self, args, conv=common.default_conv):super(EDSR, self).__init__()n_resblocks = args.n_resblocksn_feats = args.n_featskernel_size = 3scale = args.scale[0]act = nn.ReLU(True)url_name = 'r{}f{}x{}'.format(n_resblocks, n_feats, scale)if url_name in url:self.url = url[url_name]else:self.url = Noneself.sub_mean = common.MeanShift(args.rgb_range)self.add_mean = common.MeanShift(args.rgb_range, sign=1)# define head modulem_head = [conv(args.n_colors, n_feats, kernel_size)]# define body modulem_body = [common.ResBlock(conv, n_feats, kernel_size, act=act, res_scale=args.res_scale) for _ in range(n_resblocks)]m_body.append(conv(n_feats, n_feats, kernel_size))# define tail modulem_tail = [common.Upsampler(conv, scale, n_feats, act=False),conv(n_feats, args.n_colors, kernel_size)]self.head = nn.Sequential(*m_head)self.body = nn.Sequential(*m_body)self.tail = nn.Sequential(*m_tail)def forward(self, x):x = self.sub_mean(x)x = self.head(x)res = self.body(x)res += xx = self.tail(res)x = self.add_mean(x)return xdef load_state_dict(self, state_dict, strict=True):own_state = self.state_dict()for name, param in state_dict.items():if name in own_state:if isinstance(param, nn.Parameter):param = param.datatry:own_state[name].copy_(param)except Exception:if name.find('tail') == -1:raise RuntimeError('While copying the parameter named {}, ''whose dimensions in the model are {} and ''whose dimensions in the checkpoint are {}.'.format(name, own_state[name].size(), param.size()))elif strict:if name.find('tail') == -1:raise KeyError('unexpected key "{}" in state_dict'.format(name))
mdsr.py
核心代码,为不同scale_factor设置不同规模的预处理模块和上采样模块。注:这里的预处理模块的规模也就是ResBlock的堆叠数量。
from model import commonimport torch.nn as nnurl = {'r16f64': 'https://cv.snu.ac.kr/research/EDSR/models/mdsr_baseline-a00cab12.pt','r80f64': 'https://cv.snu.ac.kr/research/EDSR/models/mdsr-4a78bedf.pt'}def make_model(args, parent=False):return MDSR(args)class MDSR(nn.Module):def __init__(self, args, conv=common.default_conv):super(MDSR, self).__init__()n_resblocks = args.n_resblocksn_feats = args.n_featskernel_size = 3act = nn.ReLU(True)self.scale_idx = 0self.url = url['r{}f{}'.format(n_resblocks, n_feats)]self.sub_mean = common.MeanShift(args.rgb_range)self.add_mean = common.MeanShift(args.rgb_range, sign=1)m_head = [conv(args.n_colors, n_feats, kernel_size)]self.pre_process = nn.ModuleList([nn.Sequential(common.ResBlock(conv, n_feats, 5, act=act),common.ResBlock(conv, n_feats, 5, act=act)) for _ in args.scale])m_body = [common.ResBlock(conv, n_feats, kernel_size, act=act) for _ in range(n_resblocks)]m_body.append(conv(n_feats, n_feats, kernel_size))self.upsample = nn.ModuleList([common.Upsampler(conv, s, n_feats, act=False) for s in args.scale])m_tail = [conv(n_feats, args.n_colors, kernel_size)]self.head = nn.Sequential(*m_head)self.body = nn.Sequential(*m_body)self.tail = nn.Sequential(*m_tail)def forward(self, x):x = self.sub_mean(x)x = self.head(x)x = self.pre_process[self.scale_idx](x) # NOTEres = self.body(x)res += xx = self.upsample[self.scale_idx](res) # NOTEx = self.tail(x)x = self.add_mean(x)return xdef set_scale(self, scale_idx):self.scale_idx = scale_idx

若有收获,就点个赞吧
0 人点赞
