

Generative Adversarial Nets 生成式对抗网络 作者: lan Goodfellow 单位:加拿大蒙特利尔大学 发表会议及时间: NeurIPs(NPS)2014
01.论文摘要
1.提出了一个基于对抗的新生成式模型,它由一个生成器和一个判别器组成
2.生成器的目标是学习到样本的数据分布,从而能生成样本欺骗判别器;判别器的目标是判断输入
样本是生成/真实的概率
3.GAN模型等同于博弈论中的二人零和博弈
4.对于任意的生成器和判别器,都存在一个独特的全局最优解
5.在本文中,生成器和判别器都由多层感知机实现,整个网络可以用反向传播算法来训练
6.通过实验的定性与定量分析显示,GAN具备很大的潜力
02.论文研究背景、成果及意义
生成模型比判别式模型更加难以训练

03-论文泛读
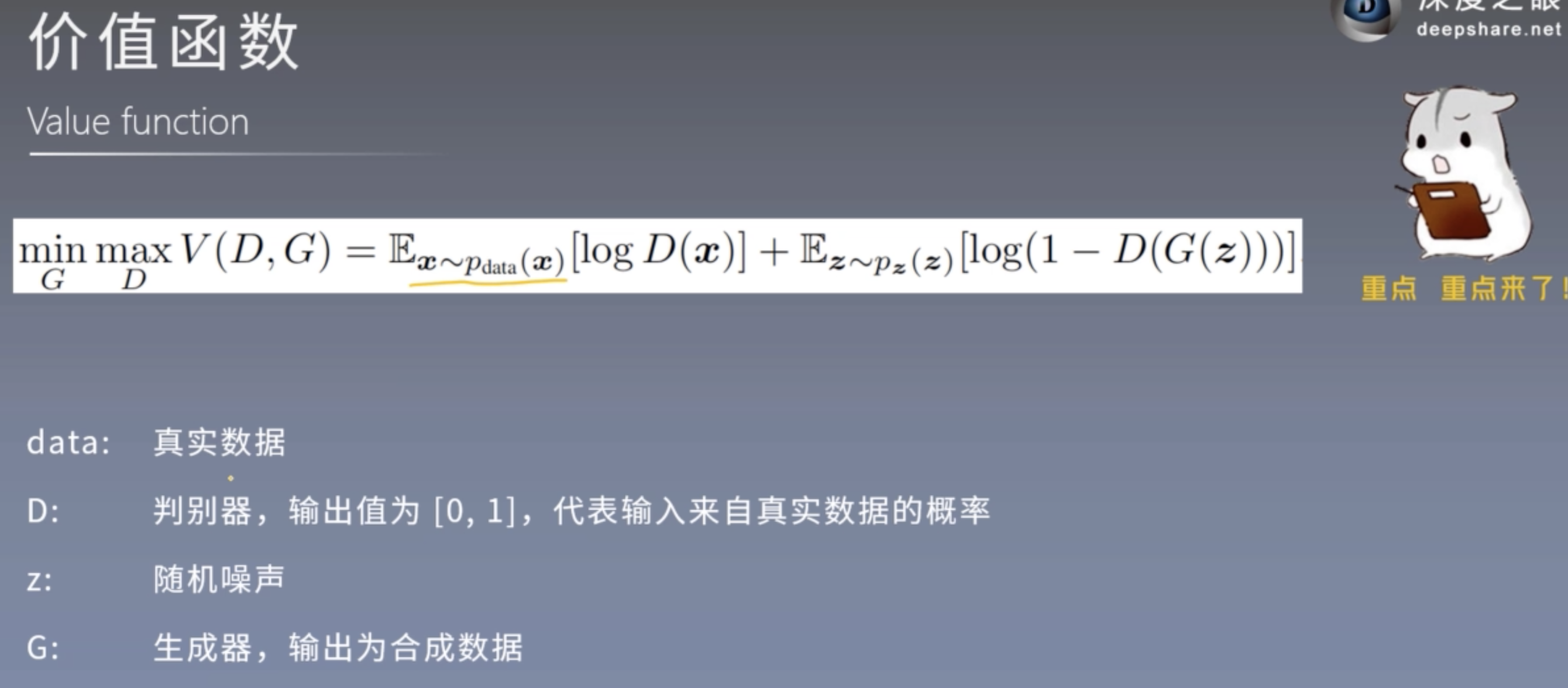
04-价值函数
VAE

VAE也有一个生成器, 但是与之对应的第二个网络是执行近似推理的识别模型。
GAN

Maxout 是全连接网络, 目前已被淘汰. Dropout : 由于使用了Maxout参数很多, 所以为了减轻过拟合而使用Dropout latent space,就是输入噪声的一个特征空间,也可以理解为一种有效的信息表示
价值函数

可见, 鉴别器只是一个二分类网络, 负责鉴别真实数据(标签为1)和伪造数据(标签为0). 而生成器负责欺骗鉴别器
在早期学习中, 判别器强于生成器,所以会导致生成器的成长很慢, 而判别器成长很快. 但是将G的目标改为最大化 log(D(G(z)))函数, 就能解决这个问题…原文:Rather than training G _to minimize log(1 _D(G(z))), we can train G _to maximize log _D(G(z))
05-训练流程&理论证明

左图: gaussian parzen window方法, 用于估计离散数据的概率密度分布. 右图: 每次训练, [为了防止过拟合,] 先训练K次判别器,再训练1次生成器.


解释:
- 当特定(固定)生成器时, 通过最大化价值函数V(G,D)得到判别器的最优解 D(x) , 如下, 是判别器最大化价值函数的推理过程, 最后对alog(y) + blog(1-y)的y求导, 依据费马定理, 很容易得到 a/(a+b)的结论,即 P(x) / (P(x)+P(x)):
- 当判别器最优解时, 带入该最优解到价值函数得到C(G) (注: C(G)不等于V(G,D)), 最小化C(G)得到生成器的最优解 P=P即伪造数据和真实数据同分布), 此时得到价值函数的全局最优解C* = -log(4). , 如下推导过程将KL和JS散度


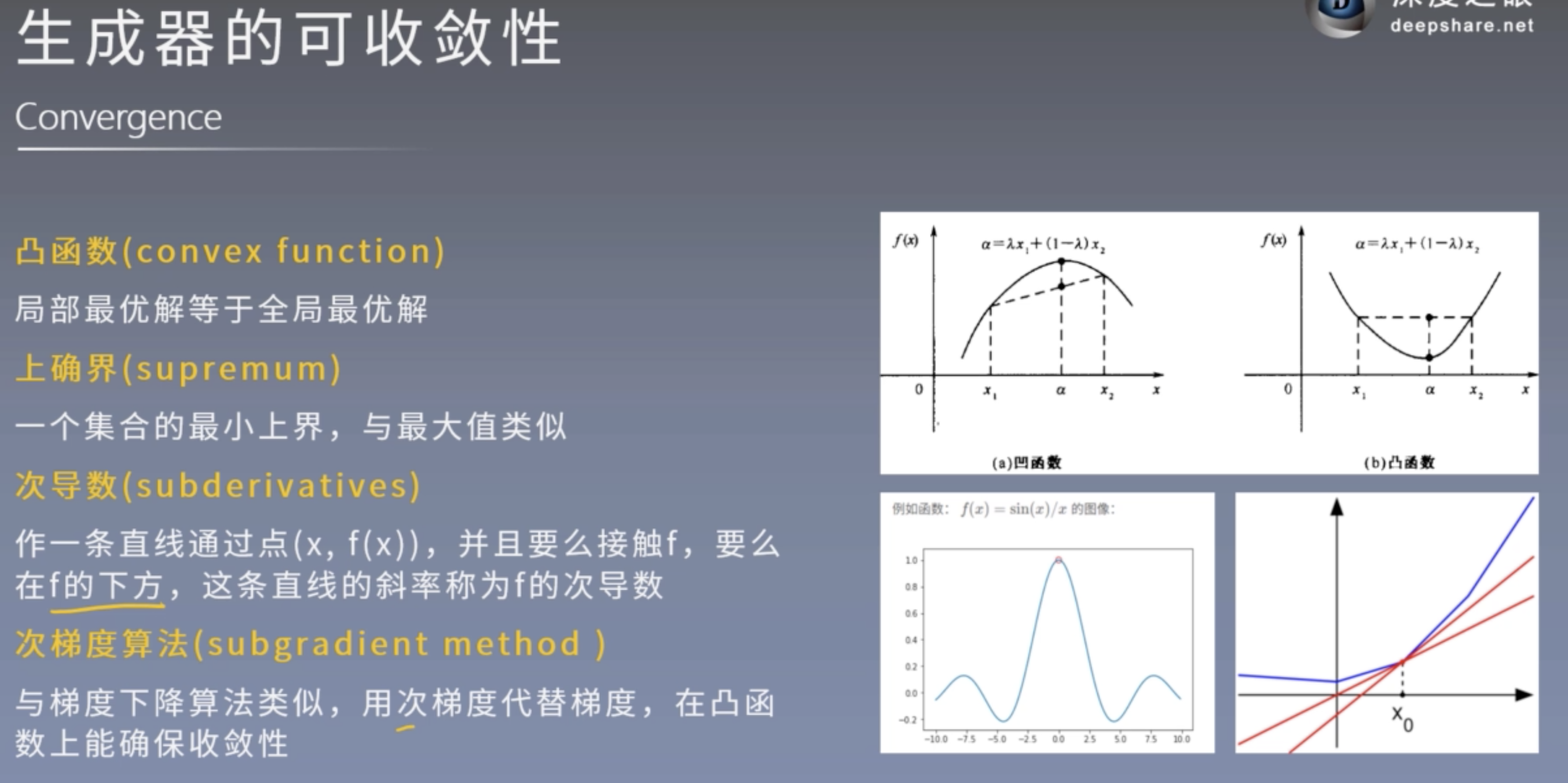
次导数和次梯度是一个集合.
06-理论证明2&实验结果&总结展望

- 要证明什么?
过给定G能得到判别器最优解D(x), 然后用D(x)带入到价值函数中, 即可得到用于改善P的评价函数
证明大致过程?
V(G,D) = U(p,D), 对于p来说是convex函数, 然后通过次梯度下降算法求其最小值.
- 问题?
实际中,该方法用得很少.

右边Parzen窗口
用于离散点来估计概率密度函数. 对每一个样本构造核函数, 如上高斯函数, 然后将这些核函数相加,即得到估计的概率密度函数.
- 高斯Parzen窗口方法的方差较大
lan Goodfellow的<<深度学习>>书中, 给出高斯最大似然函数用样本去估计方差是属于有偏估计.





竞争导致了生物进化的多样性 评价两个分布的相似性是重难点: 当两个分布没有重叠时,KL散度没有意义,而JS散度是常量1, 此时无法衡量两个分布的相似性.
07-代码分析综述
再次阅读GAN论文 配置 PyTorch开发环境 下载GAN代码 https://github.com/eriklindernoren/Pytorch-GAN 下载MNIST数据集 http://yann.lecun.com/exdb/mnist/

08-代码复现
…
09-心得
论文:
视频的讲解给了很大的帮助, 但是真正的理解还是要逐字逐句读论文. 首先, GAN论文有很大的开创性意义, 站在博弈的角度, 生物多样性竞争的角度, 给了我很大启发. 其实它有充分的理论证明. 在论文内容上, 用高斯窗口将真实样本的这些离散点估计出其所在的概率密度空间p , 同样地, 噪声在经过生成器后, 生成器也潜在决定了一个概率密度空间p. 而判别器充当了二分类模型的角色, 它在判别生成器的假样本的同时, 也在找到真实数据所在的概率密度空间p., 让判断器很可惜的是, 生成器的概率密度空间p也正在收敛至p那么有什么力量在推动这种收敛呢? 恰恰是判别器自身, 因为给定的判别器本身就像是生成器的损失函数, 是不断被优化的判别器一步步诱导生成器收敛.
代码复现;
用Pytorch1.6实现, 最大心得就是先写baseline,再进一步改代码.
其实复现代码最难的部分是重写torch.utils.dataset, 另外tran部分代码应该尽可能固定下来.

若有收获,就点个赞吧
0 人点赞
