Conditional generative Adversarial Nets 条件生成式对抗网络 作者: Mehdi mirza, Simon osindero 单位:蒙特利尔大学, Flickr/ Yahoo 发表渠道及时间:AXiv2014.11
0. CGAN学习目标
CGAN的实验设计是重点
1. 论文背景

GAN

多模态学习

图像标记

词向量

根据上下文对词进行文向量化表示, 并使得语义上相似的单词在向量空间内距离也很近.
数据集

留意YFCC 100M
研究成果

研究意义

论文精读
论文结构
模型总览

价值函数

对比原生GAN, 价值函数仅仅是将输入改为条件输入.
单模态任务

多模态任务
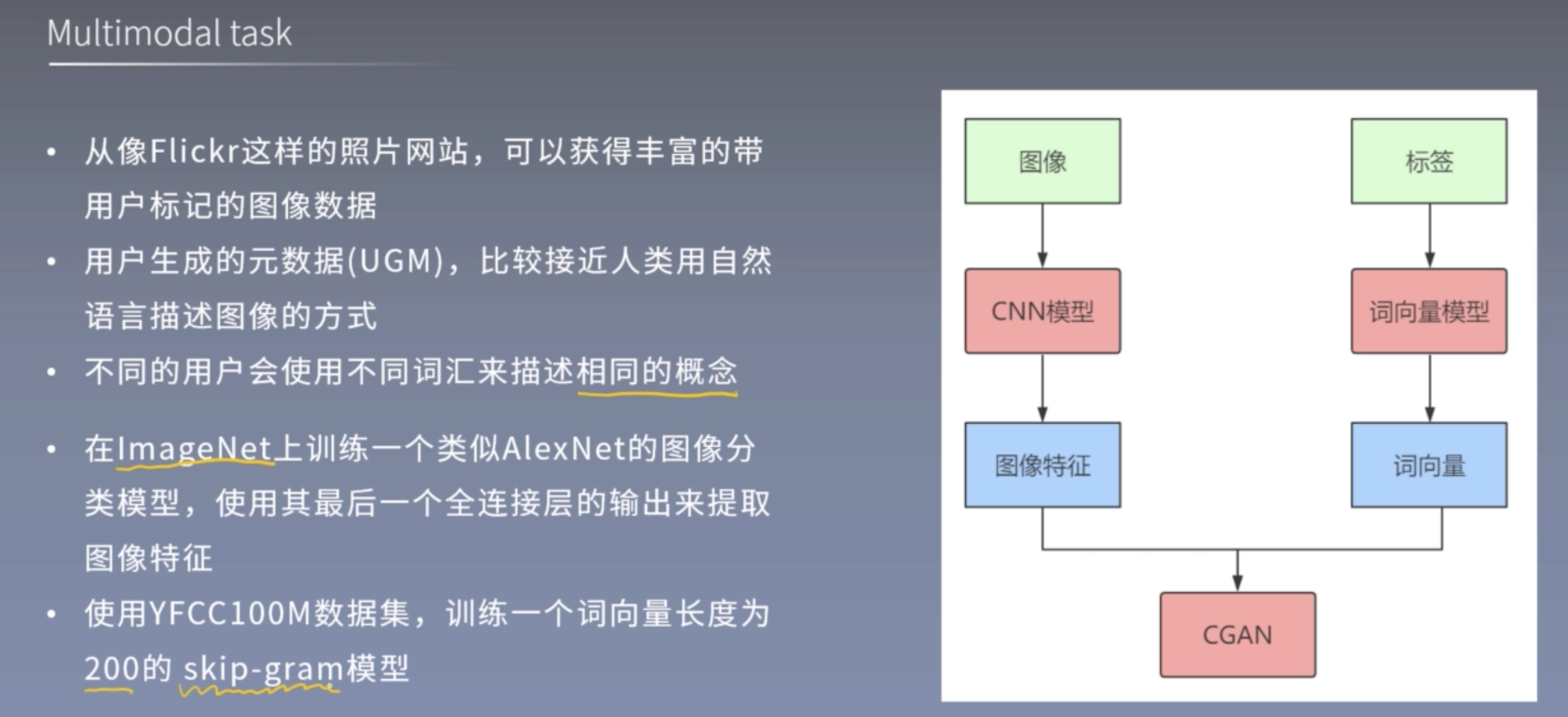
ImageNet和Flickr100M数据集用于CNN模型\训练词向量模型. 这两个模型被训练好之后就不再改变.

CNN模型提取的图像特征作为CGAN输入, 将词向量模型提取的标签特征作为CGAN的输出来训练CGAN ?? 有点模糊, 等下看代码.
总结与展望

同时使用多个标签: 作者将每个标签独立训练, 实际上这些标签是有联系的
论文总结


SOA : state of art
代码复现
手写数字
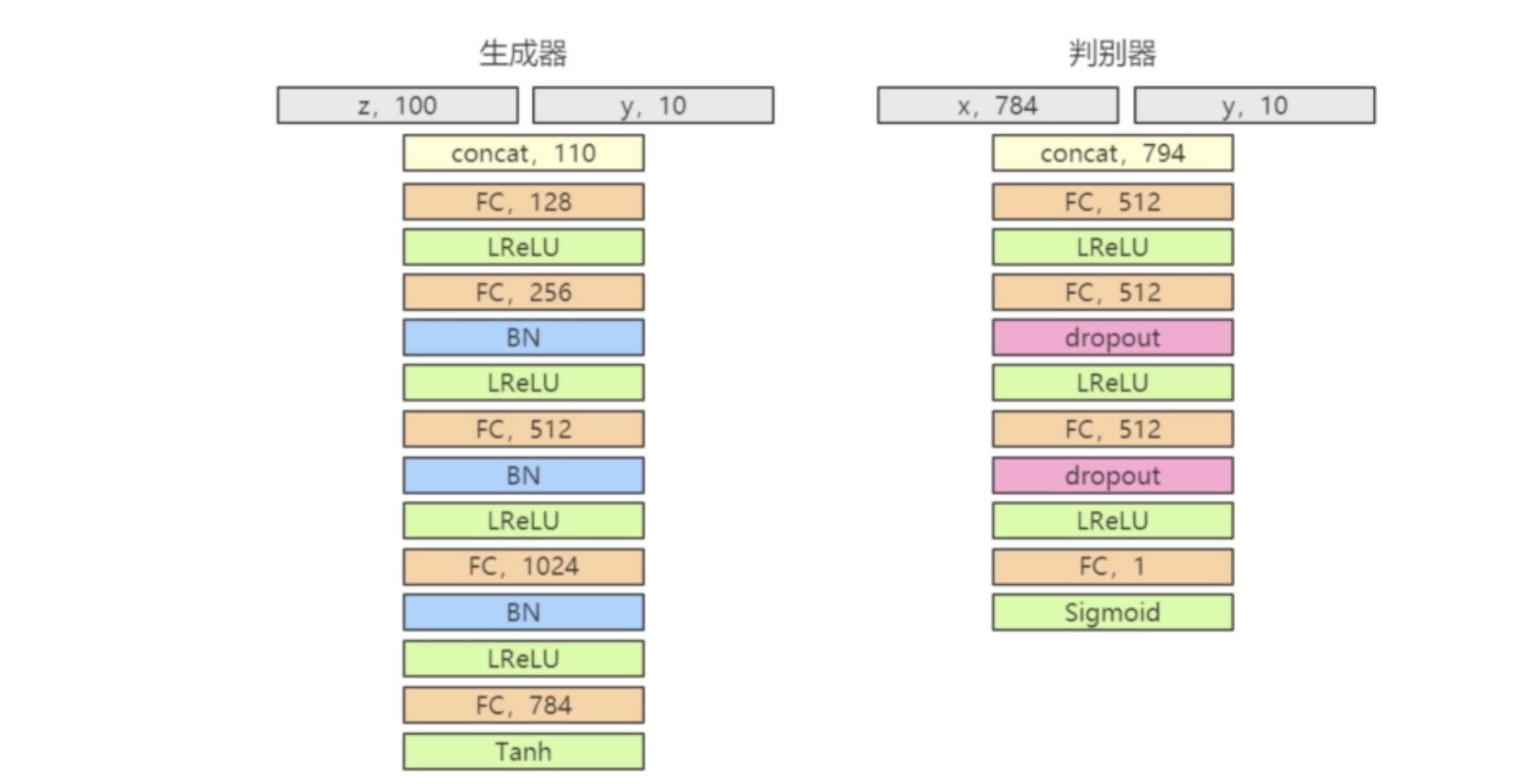
生成器输入: 100维噪声z(
z,100); 10维的条件输入y, 其经过onehot编码的class label(y,10). 生成器输出: 784维的图像输出(FC,784), 像素值域在-1~1之间(Tanh). 判别器输入: 784维的图像x(x,784); 10维的条件输入y(y,10). 判别器输出: 1维概率值(FC,1 Sigmoid)
原文0-Abstract

核心要点: 1.提出了一个基于生成对抗网络的条件生成式模型 2.在原模型基础上,输入额外的数据作为条件 3.在原模型基础上,对生成器和判别器都进行了修改 4.在MNST数据集上,新模型可以生成以数字类别标签为条件的手写数字图像 5.新模型还可以用来做多模态学习,可以生成输入图像相关的描述标签
原文1-Introduce

原生GAN没有条件生成模型, 而CGAN加入了条件模型,并且可以接受多模态的数据.
原文2-Relate Work

有监督训练取得很大成功,但是仍有两个问题. 问题1, 无法处理极大的分类任务. 问题2, 往往是1对1的输入与输出映射, 而我们更需要一对多的输入和输出映射.

CGAN提供了对应的2个解决办法. 办法1, 一种方法是利用其他模态的信息, 例如,过使用自然语言语料库来学习标签的矢量表示. 办法2, 使用条件概率生成模型(CGAN), 来生成条件的预测分布.
原文3-Generative Adversarial Nets

原生GAN的价值函数

CGAN条件概率生成模型, 在原生GAN的两个模型的基础上, 对输入层加入extra information y. y可以是任何信息,包括标签甚至其他模态的数据.

- 原有噪声z与额外信息y进行何种的结合方式, 将给网络的训练增加灵活性.
- CGAN的价值函数.

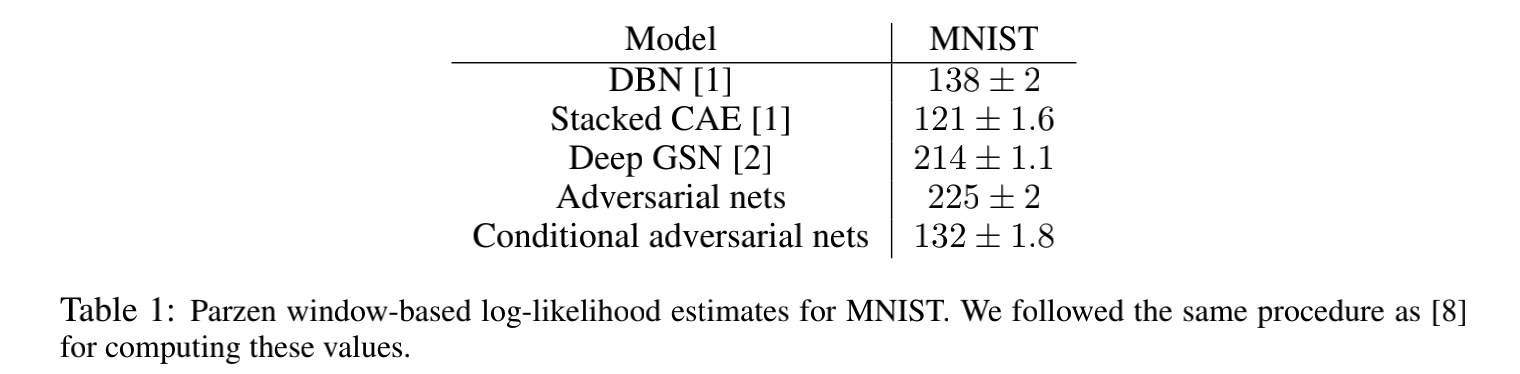
原文4 -Experimental Results


模型的具体参数设置, 直接看代码更方便.

虽然效果其实一般. 但是其做到了条件概率模型和多模态输入.


多模态有更自然表达,就像是同一个概念有不同的表述方式
natural metadata 自然元数据demonstrate 展示\演示

多模态: 使用CNN提取图片特征,使用自然语言模型提取词向量, 利用CGAN将两者结合起来.
omitted``略去
原文5-future work




若有收获,就点个赞吧
0 人点赞
