YOLO的发展历史_20201009180340.pdf
YOLO V3论文算法模型_20201009180329.pdf
1 Data Pre-Processing.ipynb2 Yolo-v3 Network.ipynb3 Train Network.ipynb4 Detect Demo.ipynb
归纳


设计细节
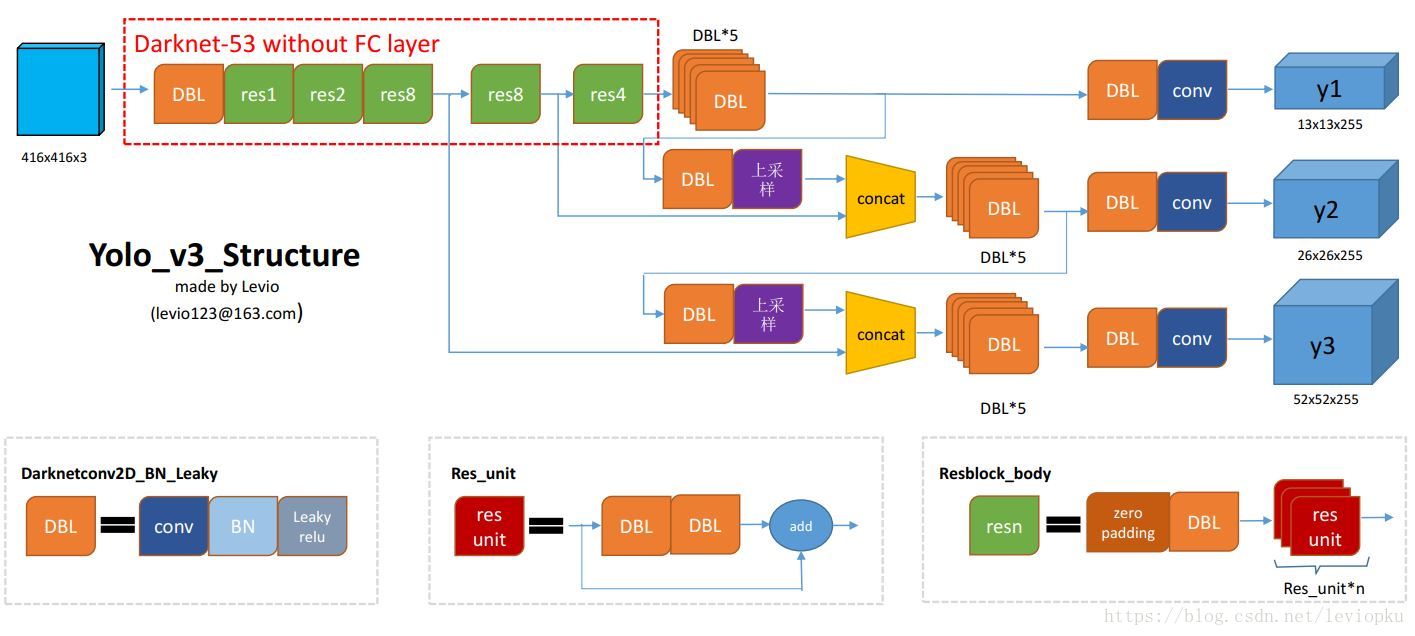
- 基于Darknet-53
yolo-v3基于Darknet-53结构. Darknet-53的精度接近resnet-101, 但是fps更高.
Darknet-53能输出3中尺寸的输出, 以作为特征金字塔结构. 小尺寸更适合检测大物体, 大尺寸更适合检测小物体.
大尺寸更适合检测大物.``
- 先验框与检测框的区别
先验框和检测框, 分别被称为anchor box和bounding box. 注意两者的区别, 前者只是一个尺度即宽高, 而后者指框得绝对位置(中心坐标与宽高), 更广泛地说, 就是模型的输出, 这样的话还包括置信度和类别.
- 先验框
利用k-means聚类在训练集上寻找先验框, 距离公式为 d(box, centroid) = 1 - IoU(box, centroid). 这里作者认为, 标准的k-mean采用欧式距离会导致大框更优势.
另外, 先验框具备特征图金字塔的思想. 如下图, 总体来看, 对每个特征点有9种anchor进行先验. 其中特征图根据尺寸分为3种(具有特征图金字塔的思想), 对每个特征图的每个grad, 又都配置3个不同的先验框. 
- 有了先验框与输出特征图, 就可以解码检测框(逻辑回归)
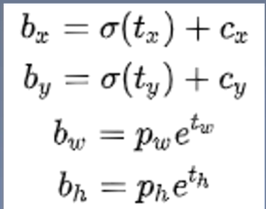
- 置信度和类别解码
置信度和类别解码的代码实现体现在网络输出的维度. out 80维度 = [检测框位置(4维), 检测置信度(1维), 类别解码(80维)]
其中, 类别解码采用sigmoid替代yolo-v2中的softmax. sigmoid和softmax最大的区别在于, sigmoid没有类别之间概率和为1的限制. 作者改用sigmoid取消类别之间的互斥, 使网络更加灵活.
- 训练策略

- 损失函数

以上损失分为三类. 12对xywh进行回归, 34对正负例的置信度进行回归. 5是分类做loss.
回归部分使用了MSE, 也可以使用smooth L1 loss.
yolo v4

 传统是在通道级别的attention, 作者改进, 在像素级别上的attention.
传统是在通道级别的attention, 作者改进, 在像素级别上的attention.
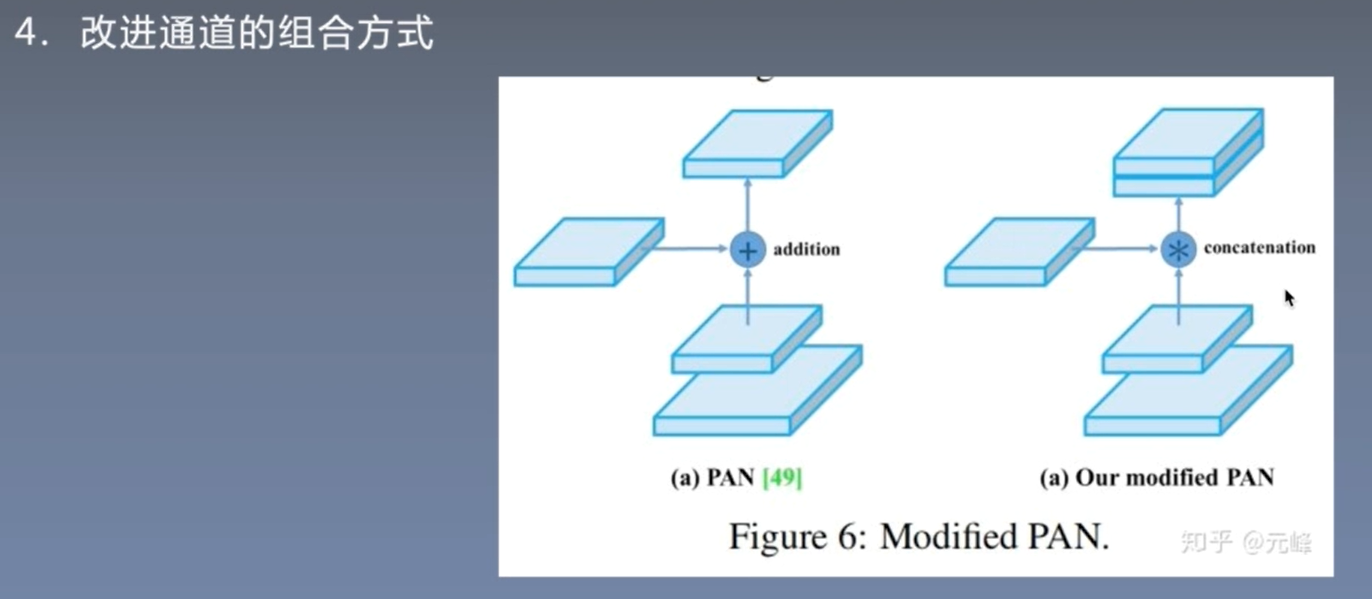

跨batch进行normalizetion.

**

若有收获,就点个赞吧
0 人点赞
