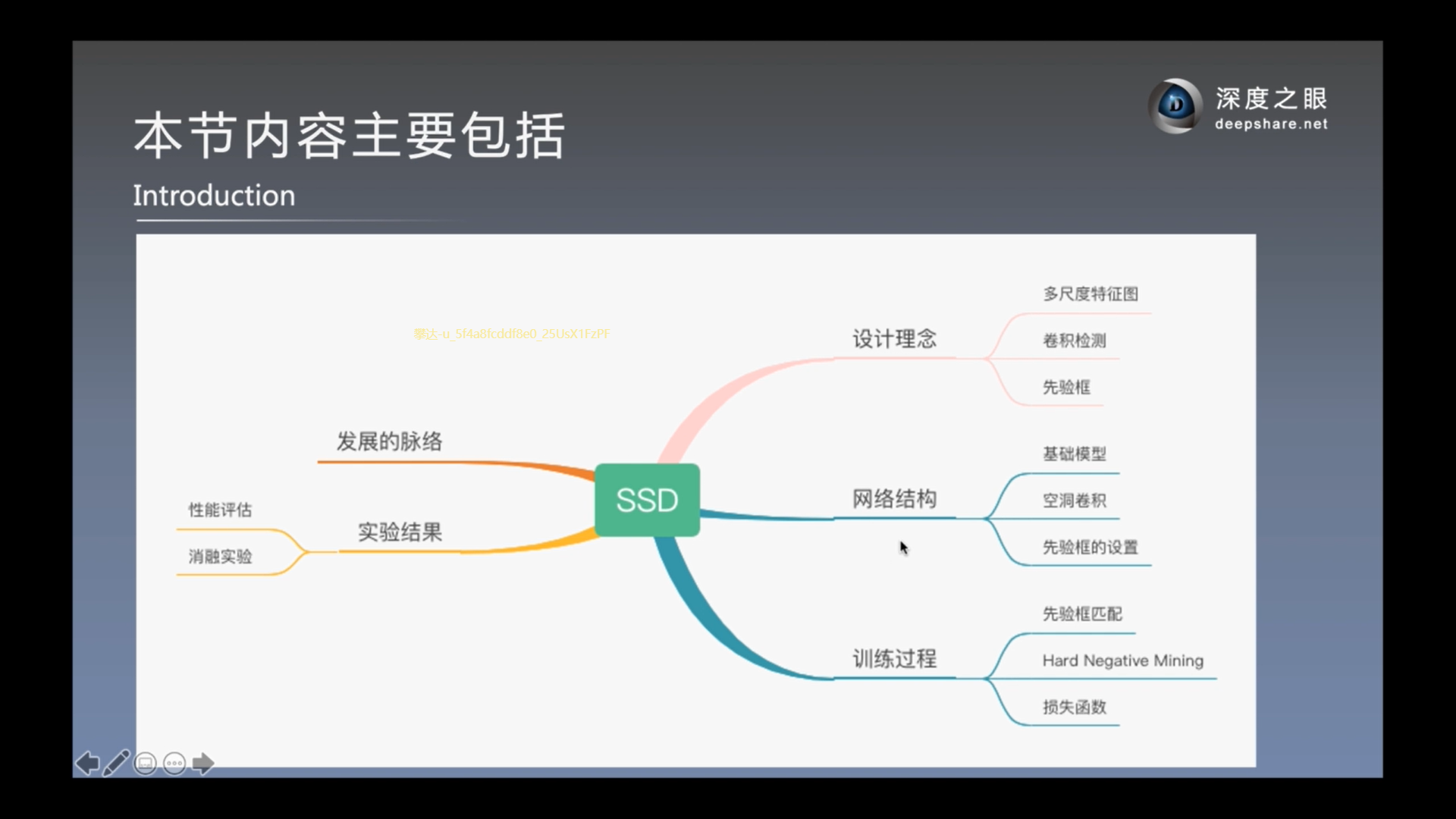
1-发展历史和泛读

学习目标

one stage. 兼顾速度和精度

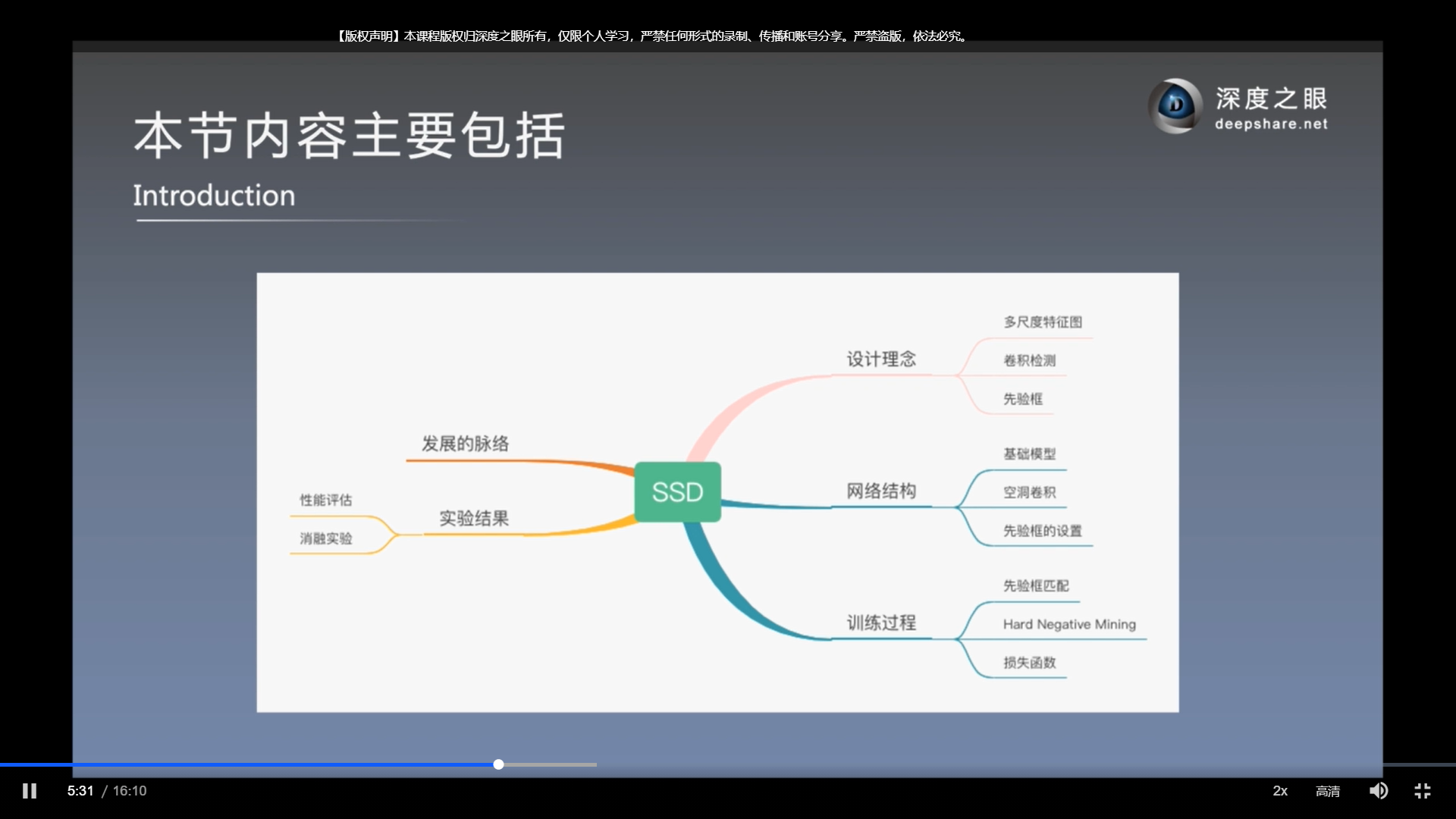
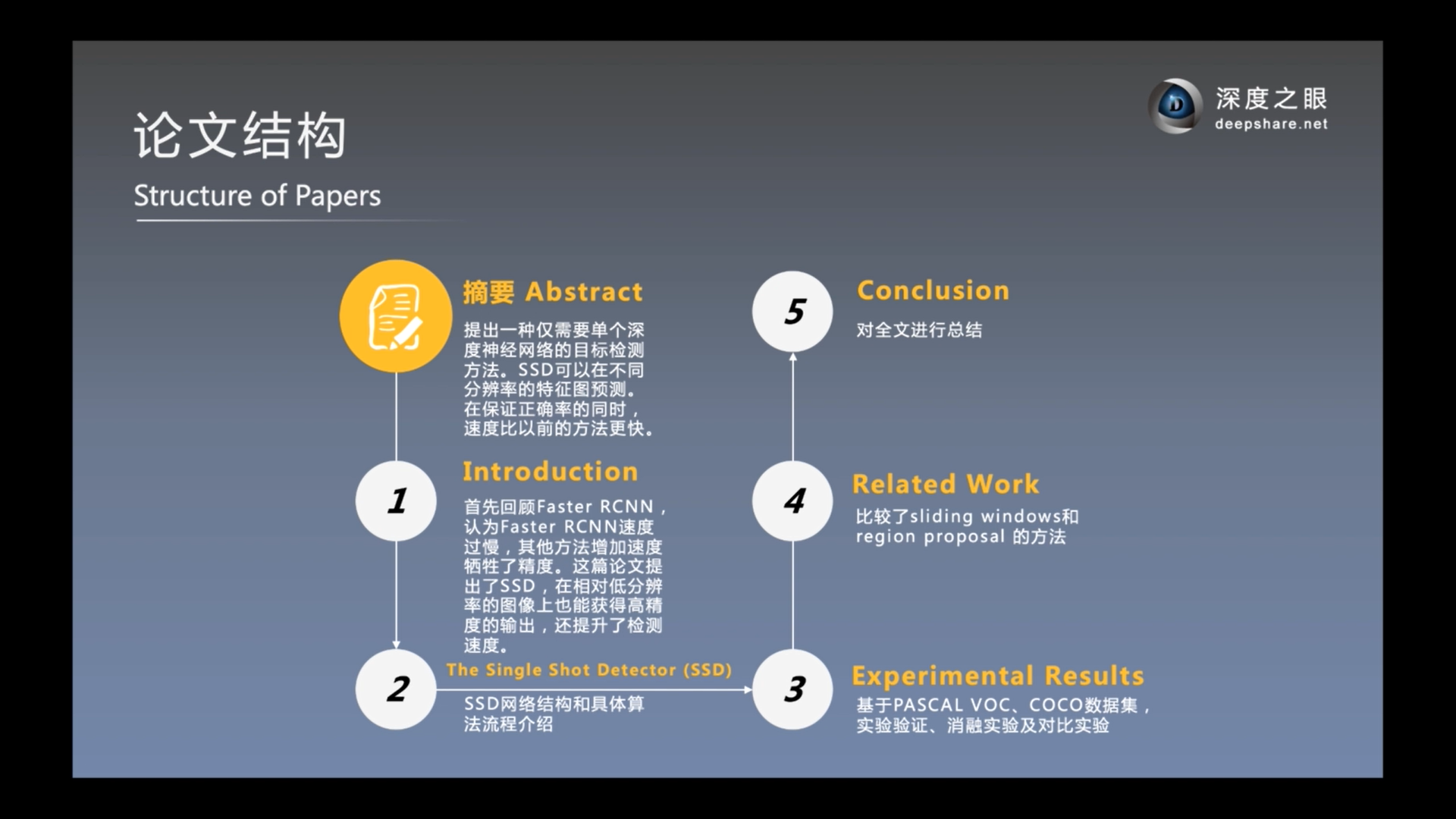
论文结构

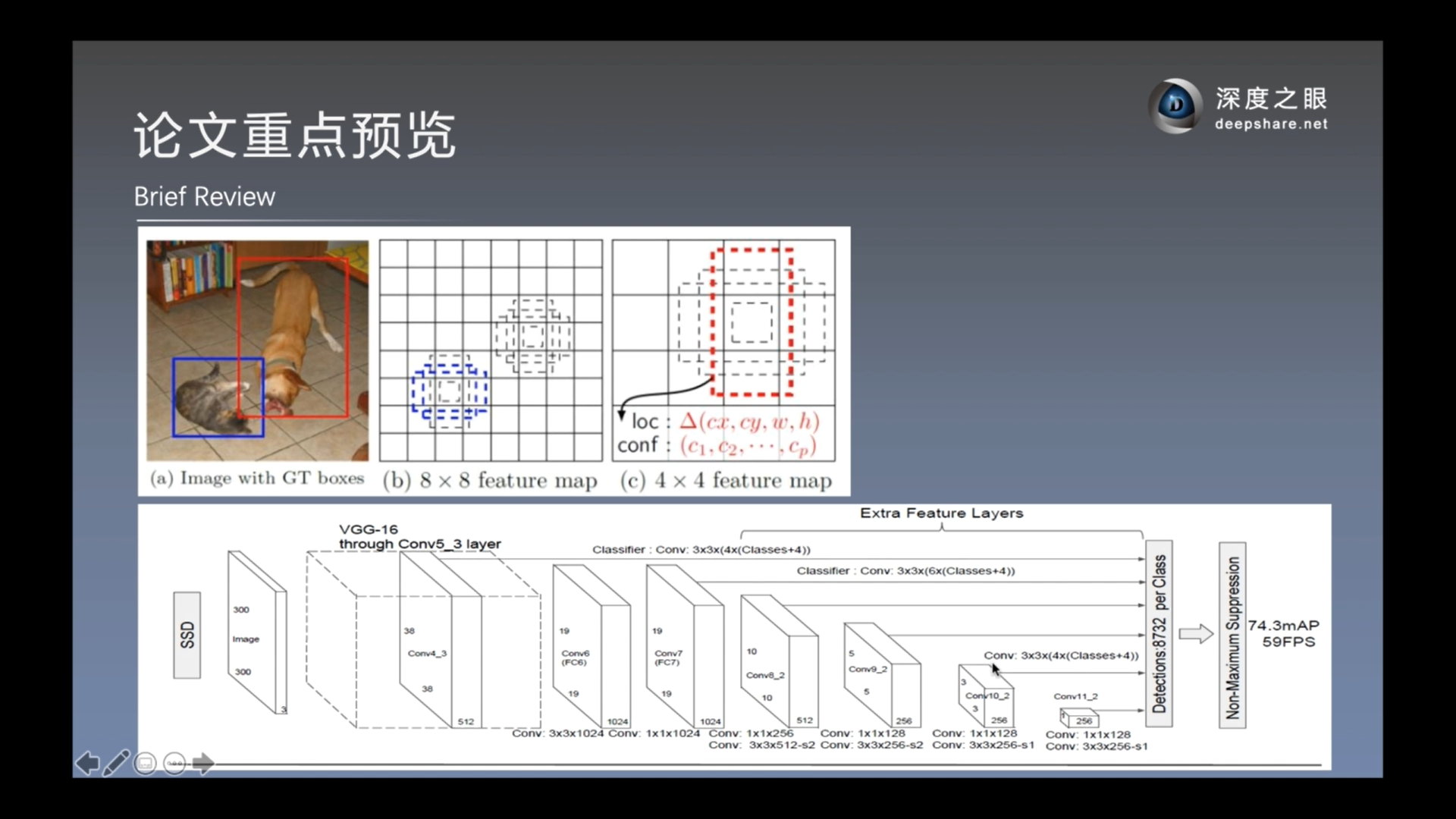
论文重点预览
2-网络结构和具体算法
模型总览




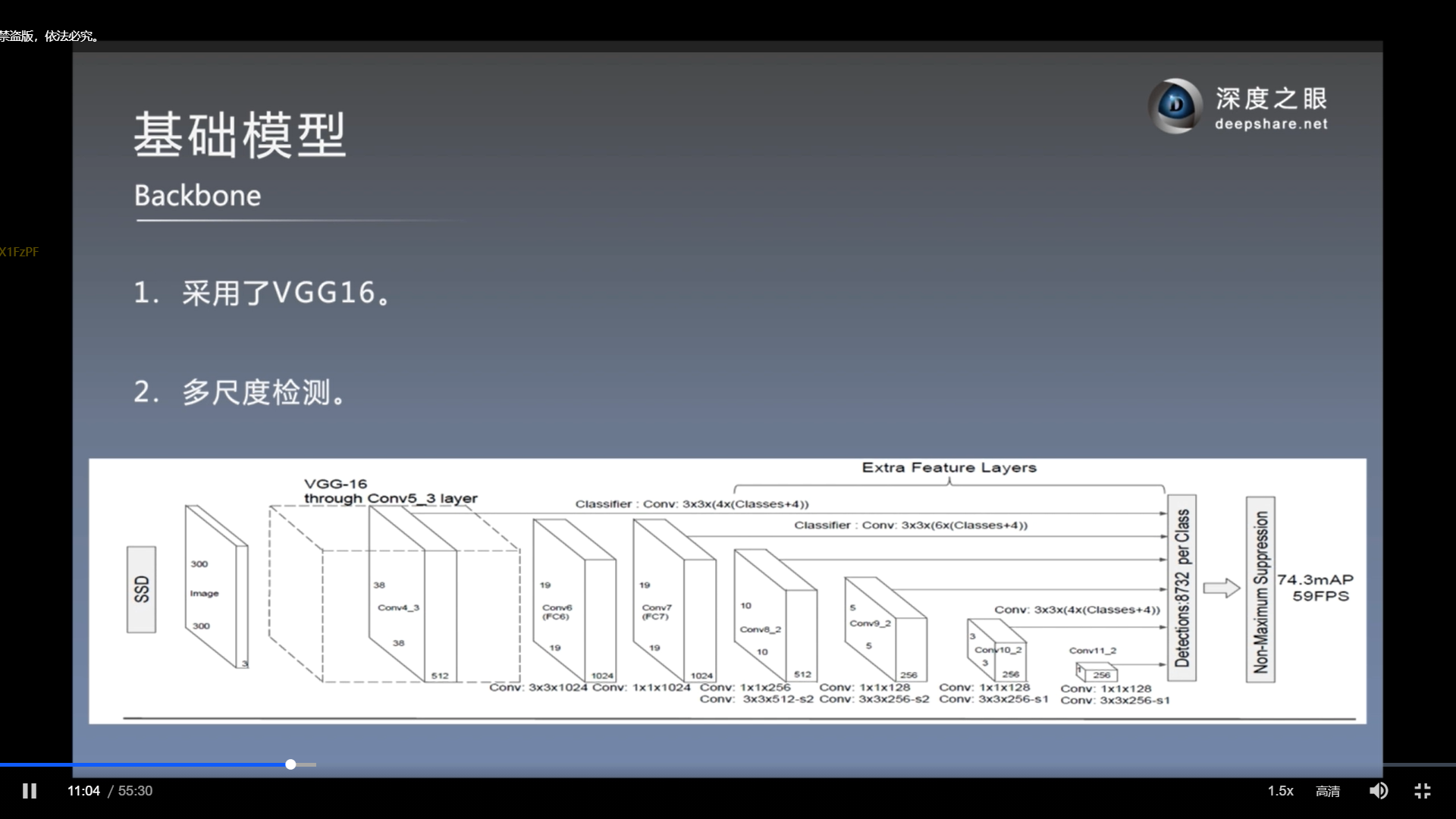
使用VGG16的conv4-3开始作为第一个特征图


空洞卷积. 如上, 将3x3卷积扩大到5x5


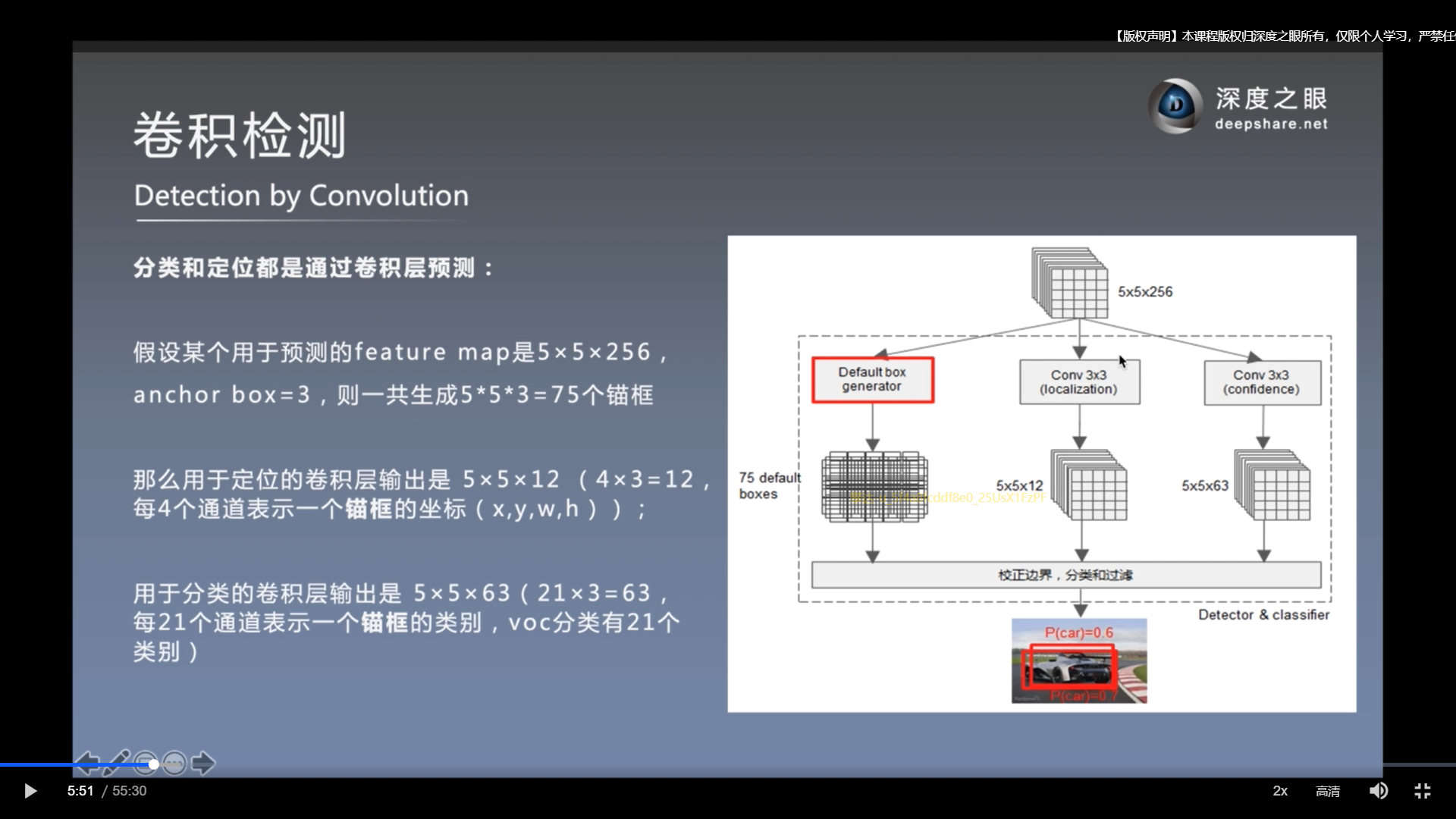
在m*n的特征图上, 每个位置都有K个预测框.
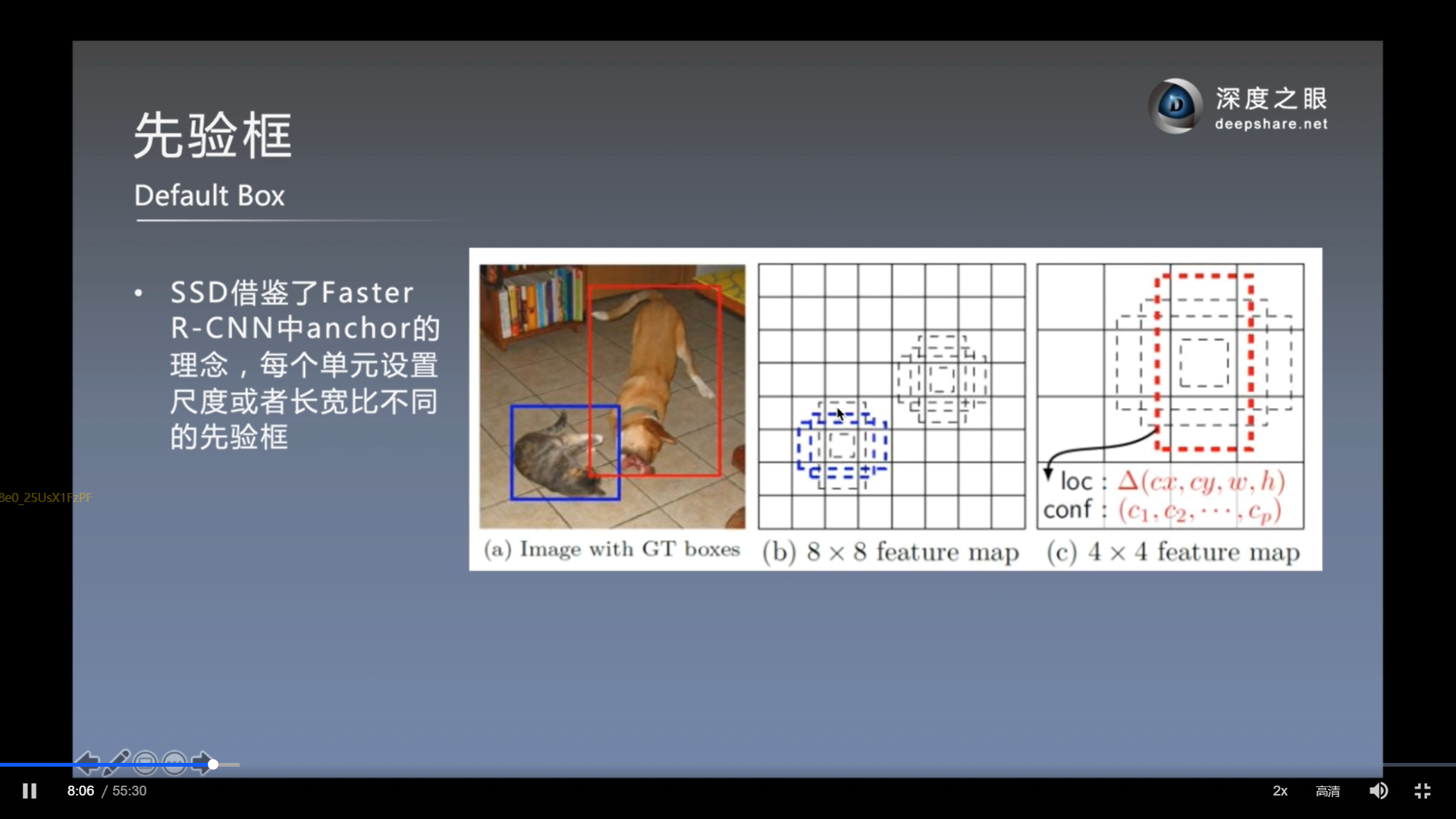
先验框的设置(重点)
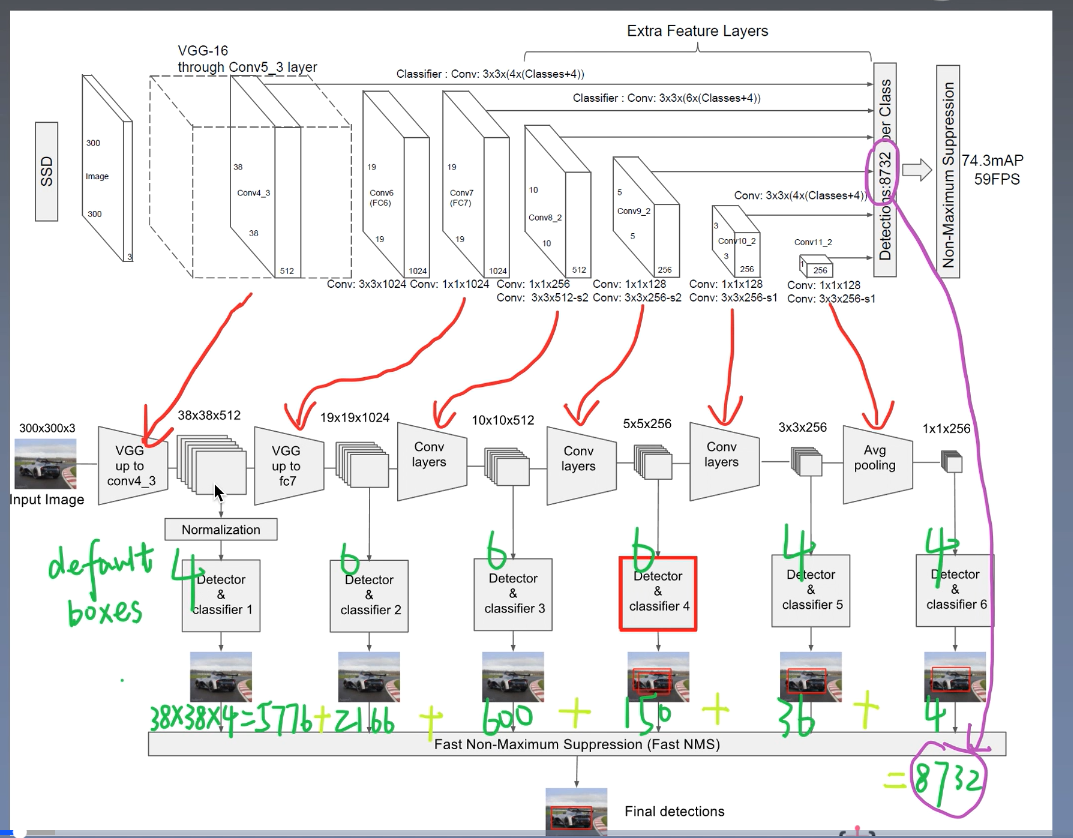
从38x38x512特征图开始, 到1x1x256特征图结束. 总共有6个特征图. 这几个特征图的每个位置分别有不同数量的
先验框.(如上绿色数字). 整个SSD共计有8732个先验框.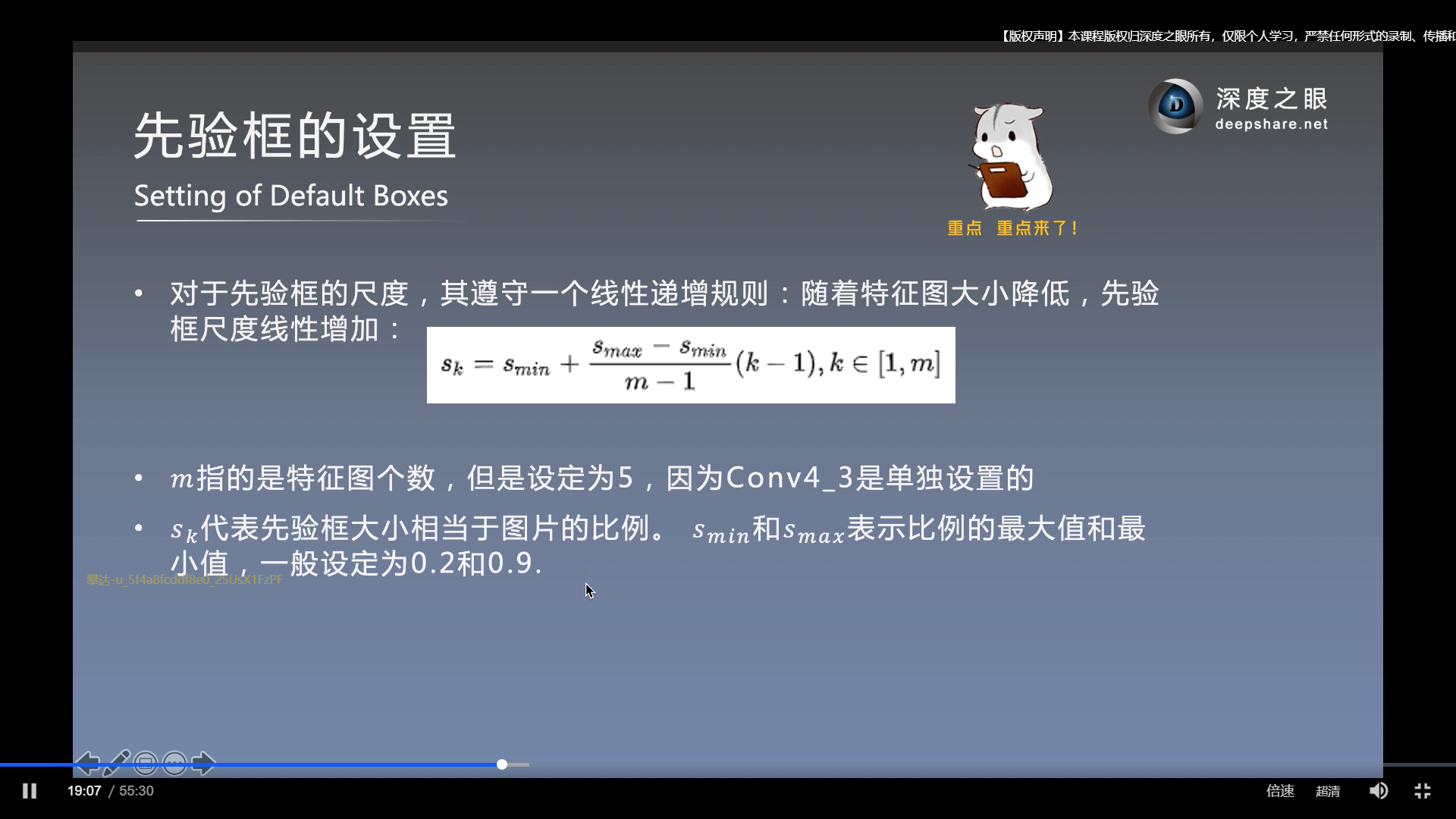
(以上不包含第一个特征图)
Sk中, k指哪一层的先验框的尺度比例. Sk代表先验框大小相对于原图的比例. 它的范围是Smin到Smax.
对应的特征图大小为= 原图大小*Sk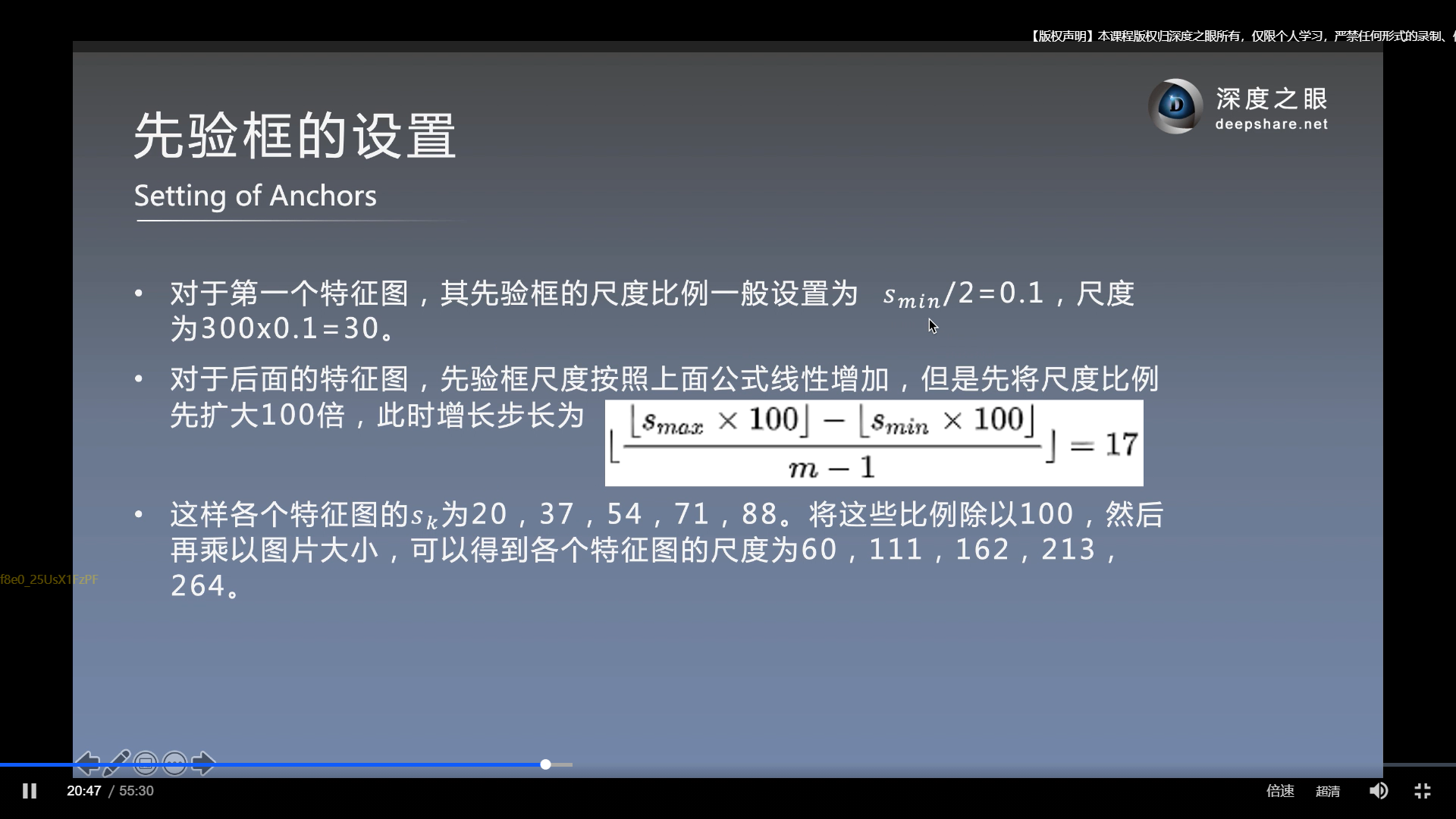
- 第一个特诊图的先验框的Sk设置为Smin/2 = 0.1. 那么可计算出对应的特征图尺寸为 300*0.1= 30.
- 上图中的, 所谓Sk步长增加公式, 只是将Sk放大100倍, 搞一个所谓步长的概念, 之后又除以100倍. 其实也可以不需要这些概念, 无非就是计算对应的特征图大小 = 原图大小*Sk
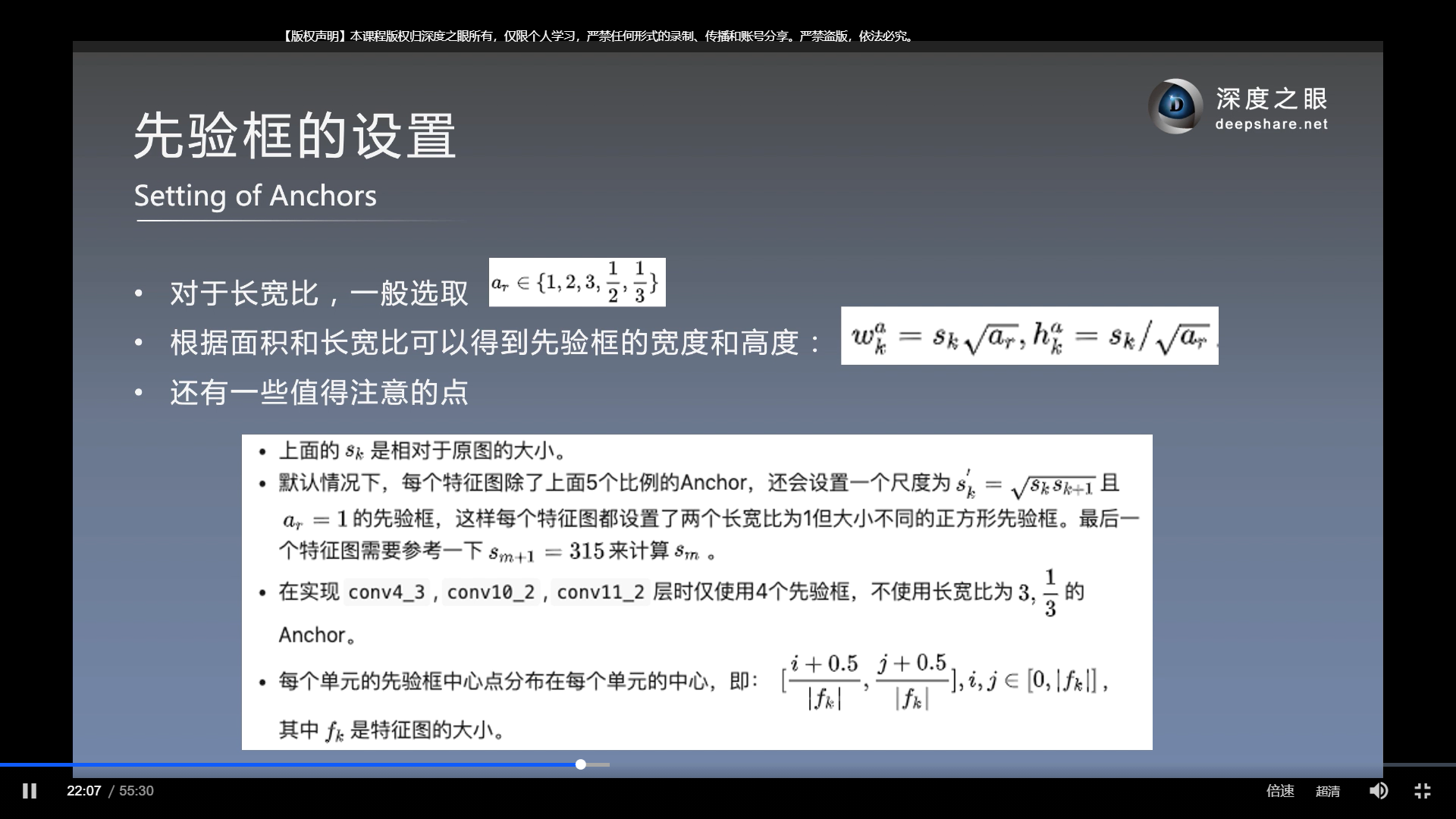
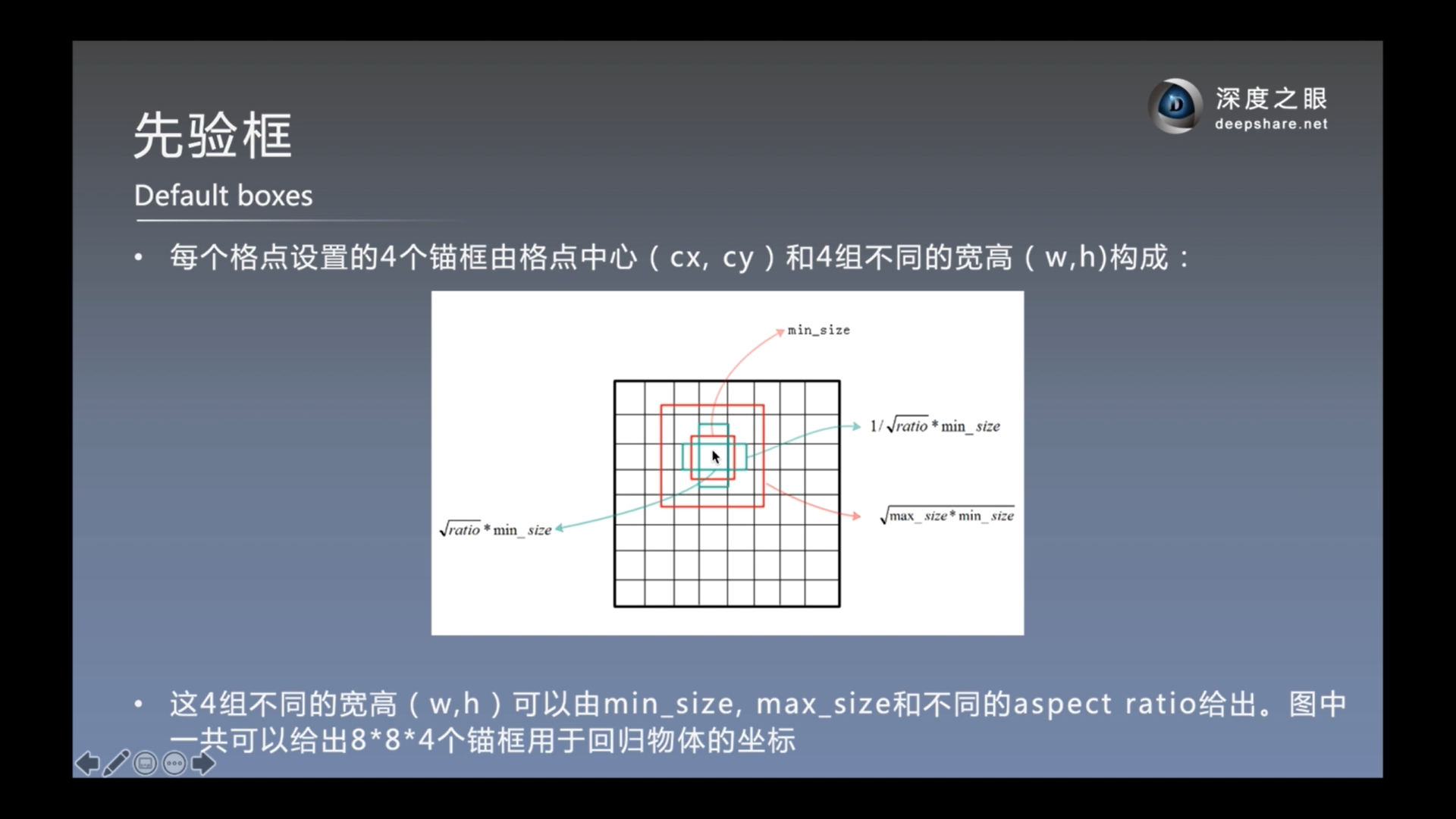
以上, 求先验框的宽度和高度.

注: 上图第一行中的{1/2, 1, 2 }是指选用先验框的长宽比的集合. sqrt(30x60)是指正方形先验框的边长
可以发现, 这些先验框的设置都是超参数, 在不同场景中可能需要不同的设置. 所以在实际中Yolo的超参数更少, 相比而言, yolo更常用.
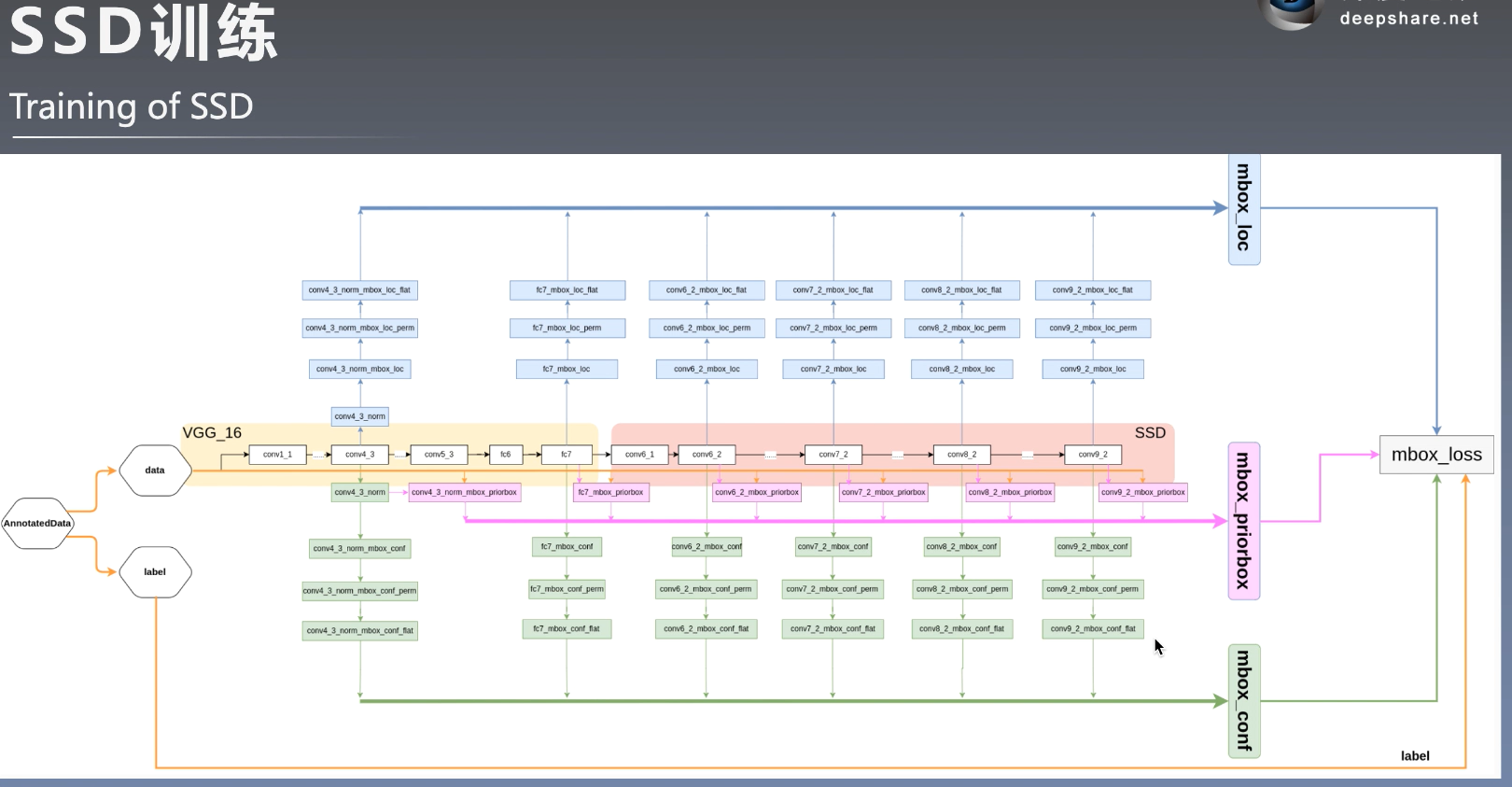
计算损失需要: 先验框的位置, 标签框得位置, 类别置信度.
先验框匹配
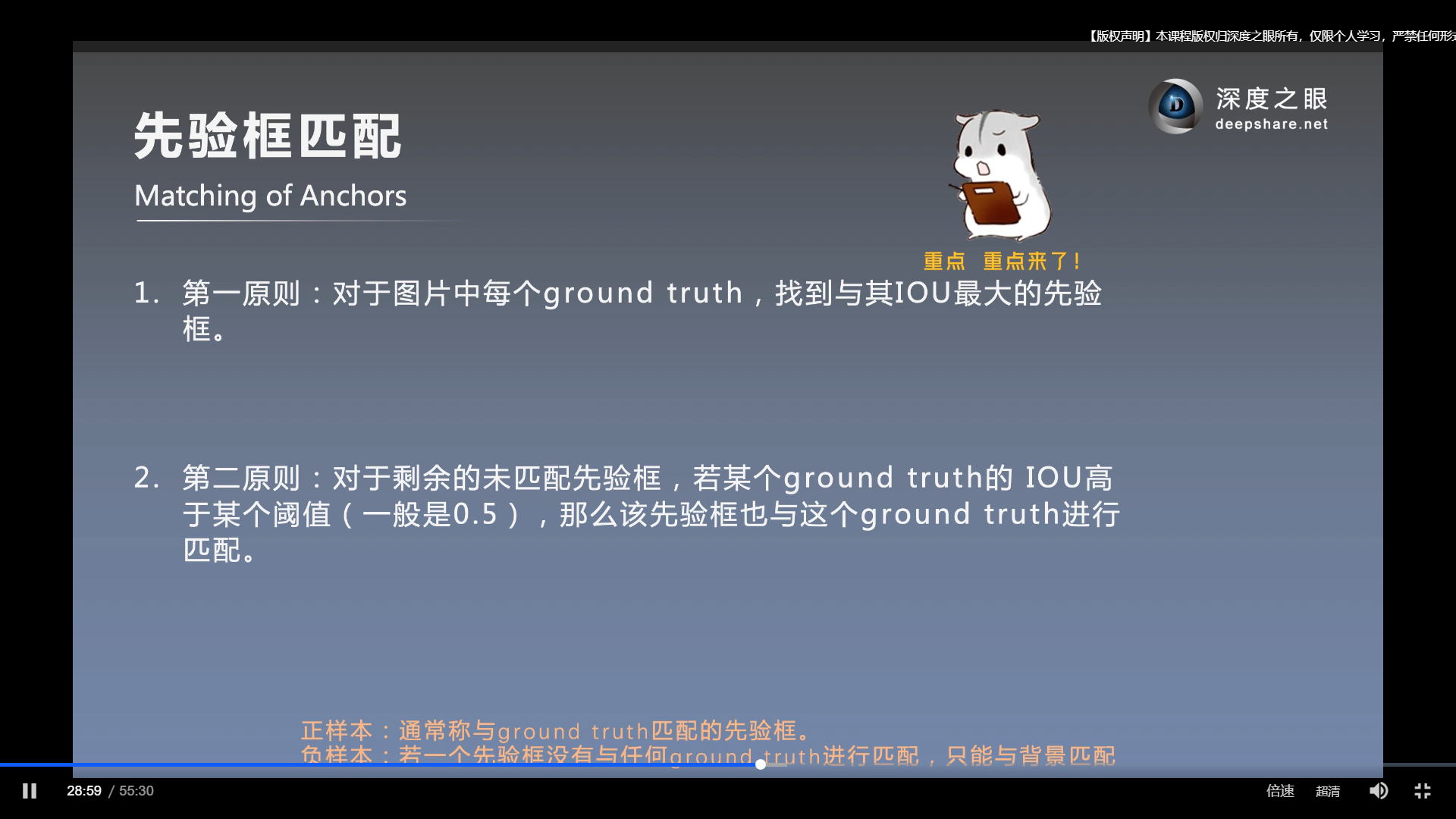
第二个原则, 稍微地平衡了正负样本(尽管仍然是很不平衡的). 即满足IOU达到阈值就算是正样本, 而在第一原则中, 正样本只有最大的IOU, 第一原则中, 正负样本太失衡了.
尽量保证正负样本平衡的原因是为了训练更容易收敛

在此之前, 正负样本仍然是很失衡的. 以上的方法, 对负样本抽样, 这使得正负样本更加平衡了, 使得比例接近为1:3
损失函数
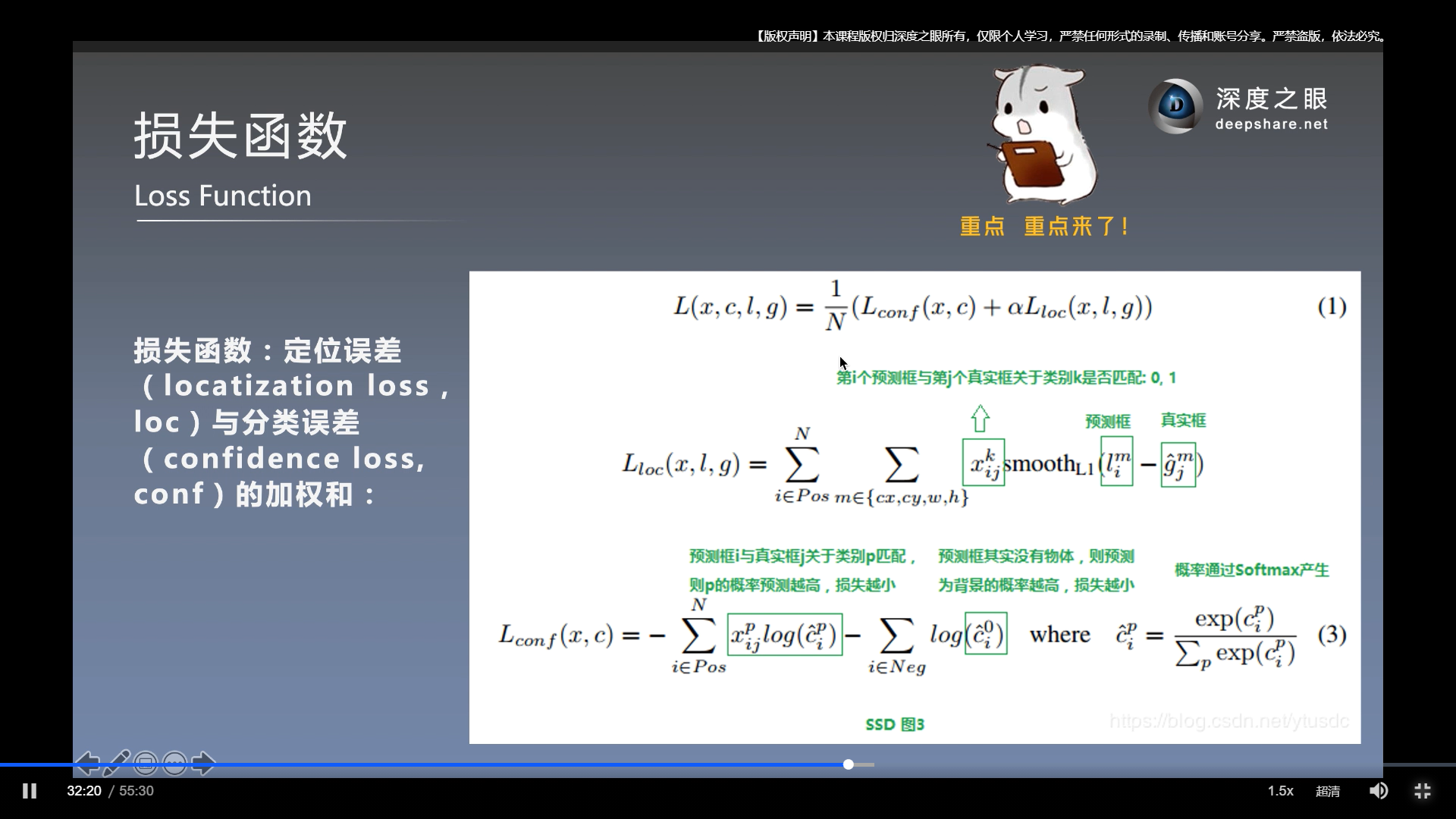
可见:
定位损失 只针对正样本计算. 这是肯定的, 分类正确的前提下, 才能有定位损失.
只针对正样本计算. 这是肯定的, 分类正确的前提下, 才能有定位损失.
置信度损失, 计算了正样本和负样本的置信度损失.

- 上图, 进一步总结了一下损失函数.
x
c 为类别置信度预测值
l和g 分别为先验框和标签框得位置参数.
- 另外, 关于定位误差, 这里是相对位置的误差, 如下:

- 第三部分, 先验框的相对位置和绝对位置的编码. 图中是针对的caffe框架里面….(个人没有搞懂, 直接忽略)
计算流程

数据增广

预测过程(区分训练过程)

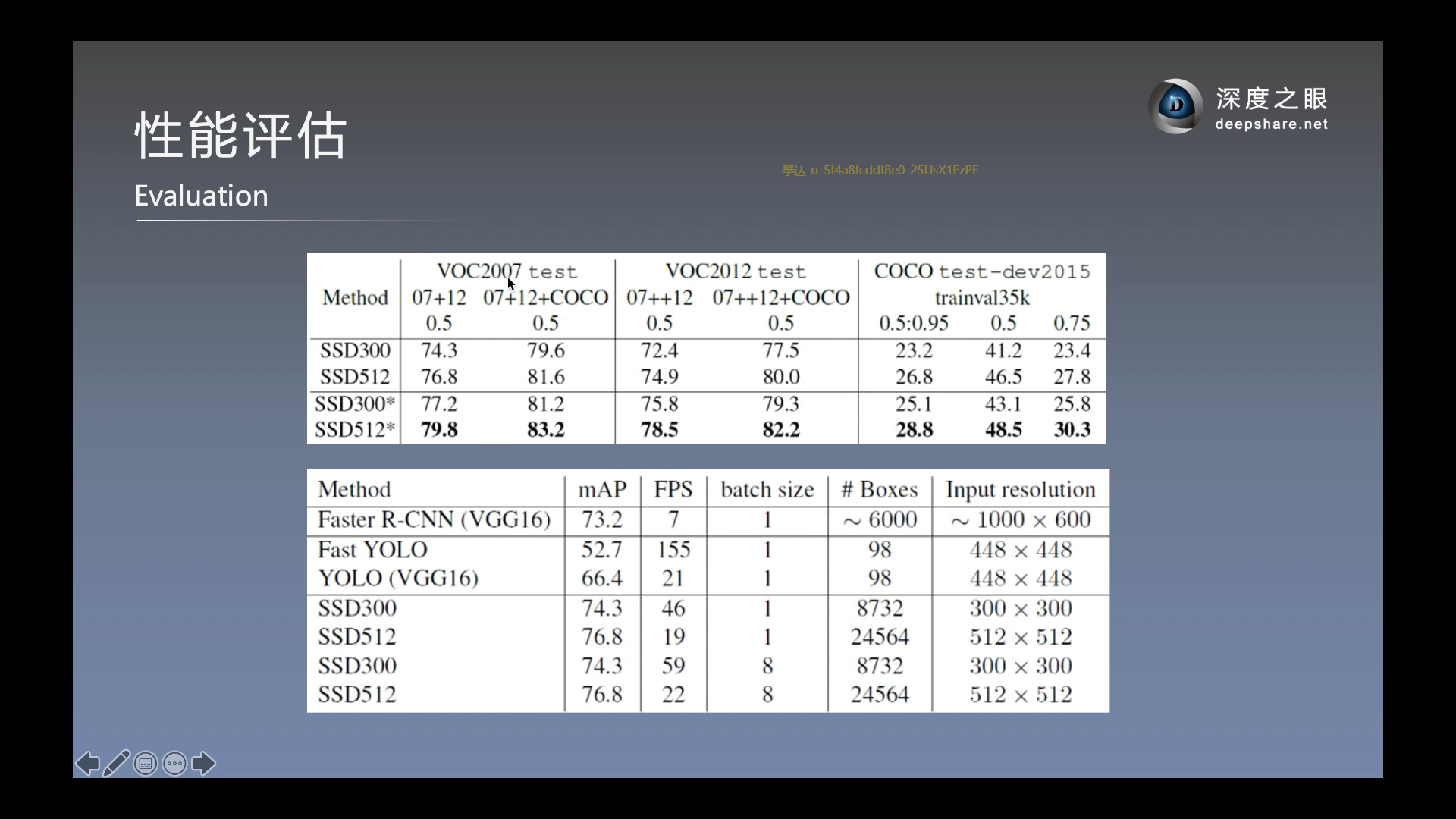

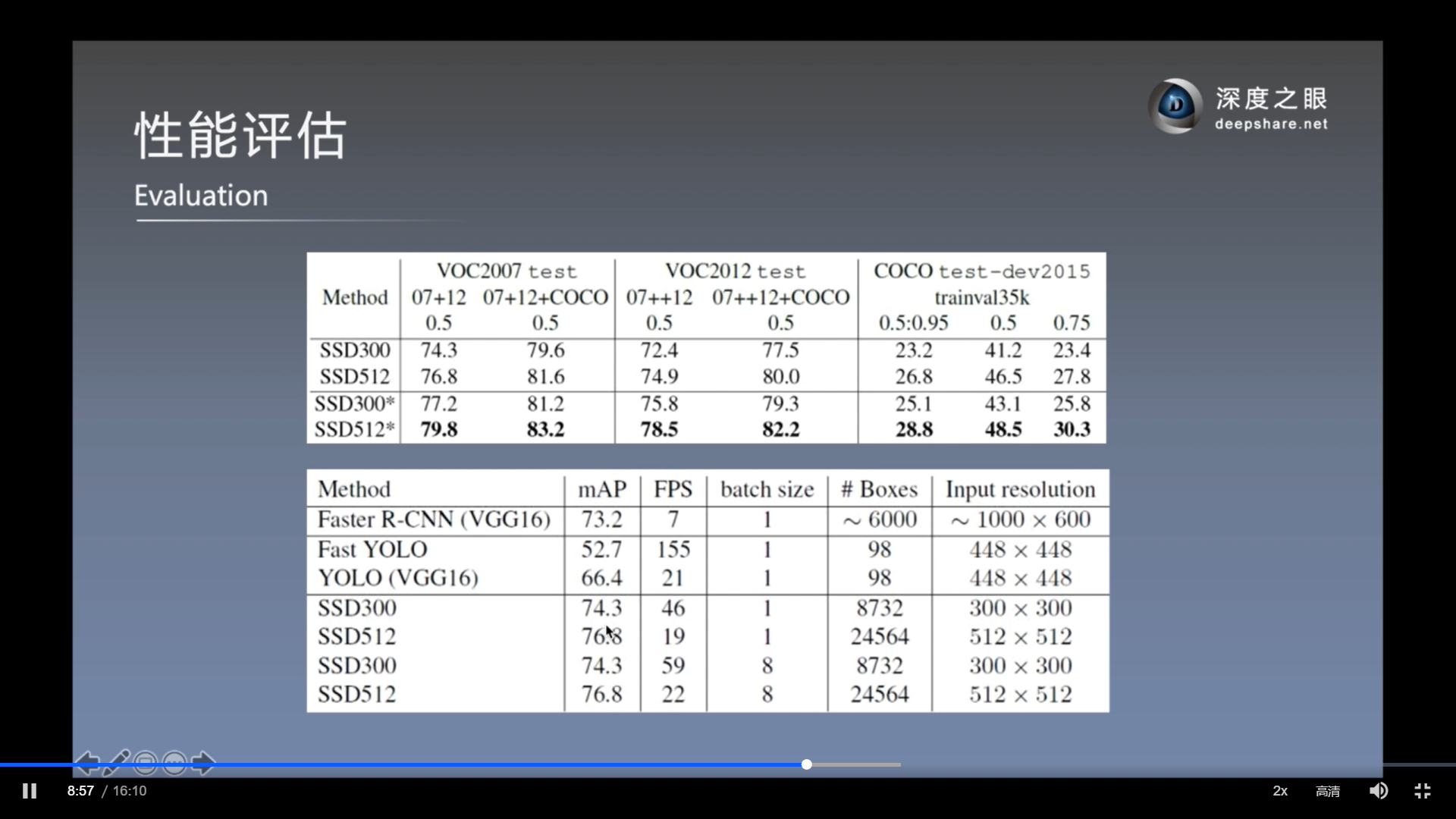
消融实验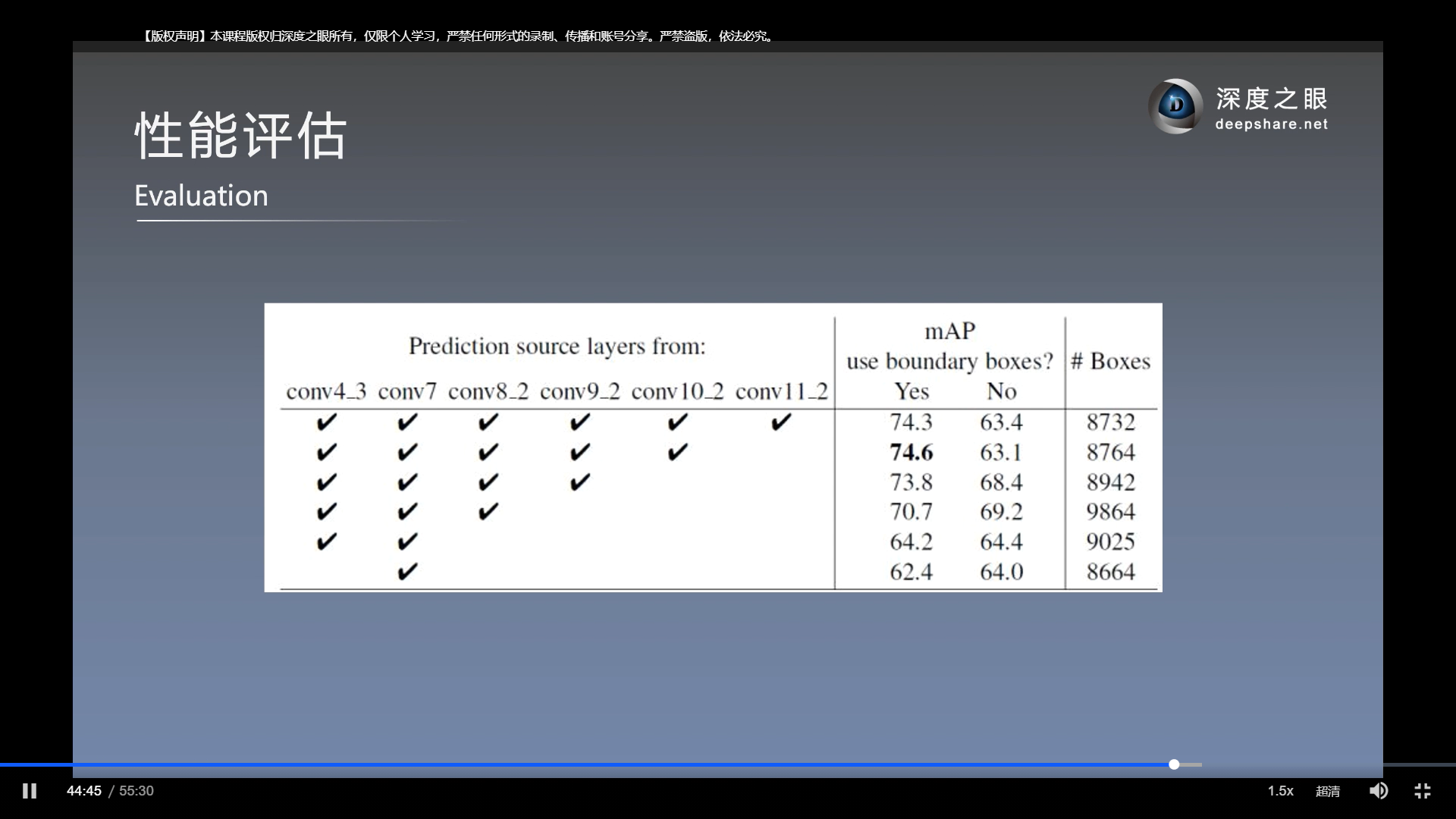
以上的, use boundary boxes 是否使用在边缘上(需要裁剪的)那些先验框, 结果是使用更好.
SSD比较其他模型

(注, 对比Yolo-v1)
相比Faster-rcnn, SSD相当于一个优化了的RPN.
SSD使用了空洞卷积.
- SSD缺点
手动设置先验框
SSD不适合小目标检测. 虽然使用了多尺度特征图, 但是哪怕是最大的特征图也才VGG中的Conv4-3.
论文总结

现在用ResNet-101更深更常见.

3-代码复现

若有收获,就点个赞吧
0 人点赞
