pvt
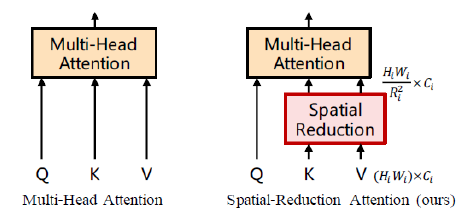

def sr(x, H, W, dim, sr_ratio):""" PVT的改进创新点输入 token.先featureMap化,并卷积操作使得featureMap尺寸减少再token化。上诉操作的好处主要2点:第一点:等价于减少k、v的token数量,即缓解vit显存占用第二点:获得了多种尺寸的featureMap,后续可搭建金字塔结构,以解决下游任务问题。思考1:这里可能导致感受野问题思考2:多头注意力的heads给予了多种语义特征的自相关,但是图片不同语义特征的分布并不均匀。如何将这种不均匀可设置或者可学习化?"""assert dim == x.shape[-1] # token shape# tokens -> featureMapx_rearr2Map = Rearrange('b (h w) dim -> b dim h w', h=H, w=W)x_rearr2Token = Rearrange('b c h w -> b (h w) c') # Map -> tokenssr_conv = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)sr_norm = nn.LayerNorm(dim)# 减小featureMap尺寸,等价于减少k、v的token数量。# 这里可能导致感受野问题sr_x = sr_conv(x_rearr2Map(x))sr_x = sr_norm(x_rearr2Token(sr_x))return sr_x
- 思考1:这里可能导致感受野问题? kv比q多做了conv操作。
思考2:多头和特征聚类的关系?多头注意力的heads给予了多种特征的自相关,但是图片不同特征的分布其实是并不均匀的。
那么如何将这种不均匀可设置或者可学习化呢?
swin-Transformer
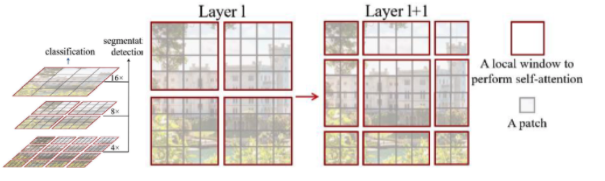
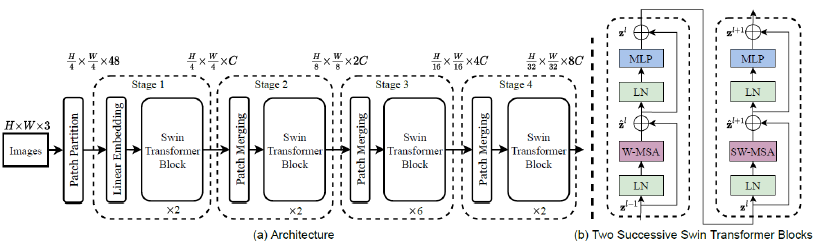
- 一个对cnn中的featureMap的思考:featureMap内部应该需要跨距离的交互。
- swin-T中的WSA可以翻译为窗口多尺度自注意力,SWSA可以翻译为跨窗口之间的多尺度自注意力。论文的结果显示必须要“WSA + SWSA“ 成对使用最好, 单用WSA并不是很理想(差1个多点)。所以 窗口内部的token需要交互,跨窗口的token也需要交互。
更多思考
cv下游任务有应用transfomer有两大难点:显存占用和表示方法。
- 首先关于显存占有问题,attn的自相关矩阵必然是存在的,该矩阵空间复杂度为O(N^2)。
- 局部区域的进行自相关,可以缓解问题。
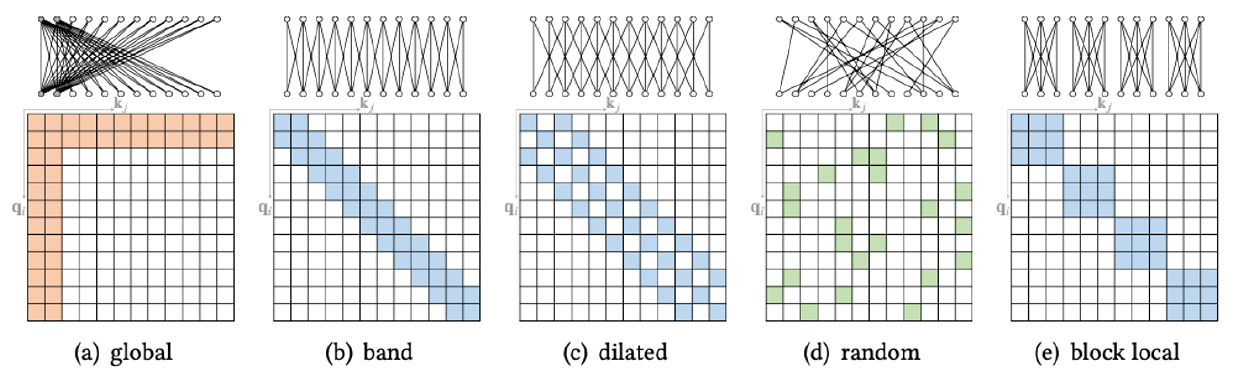
- 比如token共享的方法,也可以缓解问题。
- 可见:patch越大,qk越多,导致显存极速上升。反之patch越小,qk越少,归结到featureMap即导致分辨率不够,所以影响下游任务的性能。
- 表示方法的思考应该从图像数据本身的特点出发,如何人为构建一些设定。
cnn与mlp到底有什么联系和区别?
- cnn可以说是mlp在内存和图像表示方法上的改进。
- 这种在图像表示上的改进,帮助了cnn更好地收敛。这些改进就是所谓cnn的偏置归纳:参数共享、局部区域计算、滑动计算。
一些联想
- cnn的特别机制能否推广到cv-transfomer中呢?
目前transformer源于序列数据,它还没有类似cnn这样的偏置归纳,正因为此,现有的cv-tansformer必须要在ImageNet甚至更大的数据预训练上才能真正超越cnn。
- 其实关于位置编码的个人理解:transformer 需要位置编码,其实算是对于图像特性的人为设定,也是一种偏置归纳。
- transformer可以推广到cnn中吗?
cnn的表达方式,恰好限制了感受野的获取,必须要足够深才能拿到全局感受野。在vit的论文中,作者给出了transfomer优秀的全局”感受野“和之后的全局归纳能力。
- cnn中的金字塔结构,几乎是cnn下游任务的标准结构(如下FPN结构)。pvt和swin-T的工作也正是为了它,两者工作都证明了Vit+FPN > cnn + FPN

其他: 在cnn上辅以attn方案,可能更好。当然这违背了cn-nlp统一框架的目的。
cnn和self-attn有什么联系?
- 对最小计算单位的计算方式上:
- cnn的最小计算单位的由来是(滑动出)“3x3xc的立方体“,计算单位之间的计算方式是加权求和。
- self-attn的最小计算方式是token,它是“1x1xc的立方体”,计算单位之间的计算方式是加权求和。
- token的一种由来是(裁剪出)”p_hp_wc的立方体”,然后进行直接展平。
- token另一种由来是conv2d滑动生成。
- 从加权求和的”操作数“上:假设输入为x。
- cnn是x、filter,其中filter来自人为初始化。
- self-attn是q、k、v , 其中qkv来自x自身。
- 所以,可以在cnn做如下的改变吗?
- 既然pvt中conv2d能用于patch_embed(即token化)和创新的sr过程,那么是否说明con2d与self-attn之间可以混用吗?
- 先用conv2d(inc,3*inc,kernel = 16 ,stride=8) , 再将输出按通道分为q、k、v 以进行self-atten。
- tokens -> Map
x_rearr2Map = Rearrange('b (h w) dim -> b dim h w', h=H, w=W)
- Map -> tokens
x_rearr2Token = Rearrange('b c h w -> b (h w) c')
backbone = - [Conv(Map) -> Attn(Token)] ->

x = torch.randn(1,3,48,48)inc :int= ...outc :int= ...# 尺寸不变的convconv_same = nn.Conv2d(inc,outc,kernel_size=3,stride=1,padding=1)# 尺寸下采样的convconv_donw = nn.Conv2d(inc,outc,kernel_size=3,stride=2,padding=1)# 尺寸上采样的convconv_up = nn.Conv2d(inc, outc, ...)# 用于patch_embed的conv(感受野更大,但是输出尺寸更小,依然保留cnn的滑动窗口和参数共享)patch_conv = nn.Conv2d(inc, outc*3,kernel_size=16,stride=8) # “*3”与q、k、v有关# 计算self-attention的函数def cnn_attn(Map_q,Mao_k,Map_v):#_,C,H,W = x.shapex_rearr2Token = Rearrange('b c h w -> b (h w) c') # token化"""这里是自注意力过程"""x_rearr2Map = Rearrange('b (h w) dim -> b dim h w', h=H, w=W) # Map化return x_rearr2Map# 传播过程x = conv_same(x) + conv_up(cnn_attn(patch_conv(x)))x = conv_donw(x) + conv_up(cnn_attn(patch_conv(x)))...x = conv_donw(x) + conv_up(cnn_attn(patch_conv(x)))
pvt
import torchfrom torch import nn, einsumimport torch.nn.functional as Ffrom functools import partialfrom timm.models.layers import DropPath, to_2tuple, trunc_normal_from timm.models.registry import register_modelfrom timm.models.vision_transformer import _cfgfrom einops import rearrange, repeatfrom einops.layers.torch import Rearrange
def sr(x, H, W, dim, sr_ratio):""" PVT的改进创新点输入 token.先featureMap化,并卷积操作使得featureMap尺寸减少再token化。上诉操作的好处主要2点:第一点:等价于减少k、v的token数量,即缓解vit显存占用第二点:获得了多种尺寸的featureMap,后续可搭建金字塔结构,以解决下游任务问题。思考1:这里可能导致感受野问题思考2:多头注意力的heads给予了多种语义特征的自相关,但是图片不同语义特征的分布并不均匀。如何将这种不均匀可设置或者可学习化?"""assert dim == x.shape[-1] # token shape# tokens -> featureMapx_rearr2Map = Rearrange('b (h w) dim -> b dim h w', h=H, w=W)x_rearr2Token = Rearrange('b c h w -> b (h w) c') # Map -> tokenssr_conv = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)sr_norm = nn.LayerNorm(dim)# 减小featureMap尺寸,等价于减少k、v的token数量。# 这里可能导致感受野问题sr_x = sr_conv(x_rearr2Map(x))sr_x = sr_norm(x_rearr2Token(sr_x))return sr_x
def attentionPvt(x,H,W,dim,num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):B, N, C = x.shape # token shapeassert C == dimassert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."head_dim = dim // num_headsget_q = nn.Linear(dim,dim,bias=qkv_bias)get_kv = nn.Linear(dim,dim*2,bias=qkv_bias)scale = qk_scale or head_dim ** -0.5attn_drop = nn.Dropout(attn_drop)proj = nn.Linear(dim, dim)proj_drop = nn.Dropout(proj_drop)# 创建多头q,k,vmul_q_reaar = Rearrange('b n (heads dim) -> b heads n dim',heads=num_heads)mul_kv_reaar = Rearrange('b n (kv heads dim) -> kv b heads n dim',kv=2,heads=num_heads)q = mul_q_reaar(get_q(x))if sr_ratio > 1:sr_x = sr(x,H,W,dim,sr_ratio)kv = mul_kv_reaar(get_kv(sr_x))k,v = kv[0],kv[1]else:kv = mul_kv_reaar(get_kv(x))k,v = kv[0],kv[1]# attnattn = (q @ k.transpose(-2, -1)) * scaleattn = attn.softmax(dim=-1)attn = attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C) # token-qkvx = proj(x)x = proj_drop(x)return x
def patchEmbed_pvt(x,ph,pw,embed_dim:int):b,c,h,w = x.shapeassert h % ph == 0 and w % pw == 0conv = nn.Conv2d(c,embed_dim , kernel_size=(ph, pw), stride=(ph, pw),)norm = nn.LayerNorm(embed_dim)rearr = Rearrange('b dim h w -> b (h w) dim')x = norm(rearr(conv(x)))H,W = h//ph,w//pw # 下一轮的token转patch所需要。return x,H,Wdef patchEmbed_vit(x,ph,pw,embed_dim:int):_, c, h, w = x.shapeassert h % ph == 0 and w % pw == 0rearr = Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=ph, p2=pw)linear = nn.Linear(c*ph*pw,embed_dim)norm = nn.LayerNorm(embed_dim)x = norm(linear(rearr(x)))return x
b,c,h,w = 2,3,24,24ph, pw = 4, 4num_heads = 2embed_dim = 8pvt_sr_ratio = 2drop_path = 0.1x = torch.randn(b, c, h, w)drop_path = DropPath(drop_path)x_vit = patchEmbed_vit(x, ph, pw, embed_dim)x_pvt,H,W = patchEmbed_pvt(x, ph, pw, embed_dim)y_vit = attentionPvt(x_vit, H=None, W=None, dim=embed_dim,num_heads=num_heads, sr_ratio=1)y_pvt = attentionPvt(x_vit, H=H, W=W, dim=embed_dim,num_heads=num_heads, sr_ratio=pvt_sr_ratio)y_vit = x_vit + drop_path(y_vit) # drop pathy_pvt = x_pvt + drop_path(y_pvt)y_vit.shape,y_pvt.shape

若有收获,就点个赞吧
0 人点赞
