原论文 论文Faster RCNN.pdf 学习文件 目标检测基础知识-6.14_20201019155316.pdf Faster RCNN研究背景-6.14_20201019155316.pdf Faster RCNN论文算法模型-6.14_v3_20201019155324.pdf 相关代码 代码FasterRCNN 2.zip 实验数据 链接:https://pan.baidu.com/s/1PRyzRV9qP3e02M9ueXu5tg 提取码:bb8y 相关博客
泛读
标题, 摘要⭐️(每句话), 结论, 所有标题和图表…如何自测? 1,解决XX问题/任务 2,采用XX方法 3,达到XX效果
答:
- 针对于目标检测任务的二阶段方法中, 首次实现了, 端到端学习的深度检测网络, 实时性与准确率均达到当时最优. 它解决了SPP-net和RCNN的一些缺陷, 包括训练过程慢,需要较大存储空间. 另外, 也没有了SPP-net中尺寸归一化导致物体变形的问题.
- 第一, 采用了新的候选区域提取方法来解决实时性低的问题, 该模块被称为RPN网络. 第二, 使用了预训练模型vgg来作为共享特征, 这大大提升了计算效率.
- 第一, 该网络在单GPU上达到5fps的处理速度. 第二, 在PASCAL VOC2012上达到70.4% mAP
摘要核心:
- 候选区域提取是已有检测方法实时性低的主要瓶颈
- 提出了候选区域网络,通过共享特征,提取候选区域,极大提升了计算效率,可以进行端到端训练
- Fast RCNN和VGG通过迭代优化可以实现特征共享
- Faster RCNN是一个实用系统,在单GPU上达5fps
- 在PASCAL VOC 2012上达70.4% mAP
精读
挑选精华且受用的段落(挑小标题)进行精读….如何自测? 掌握该段落细节(思路/公式推导)
Faster RCNN网络结构
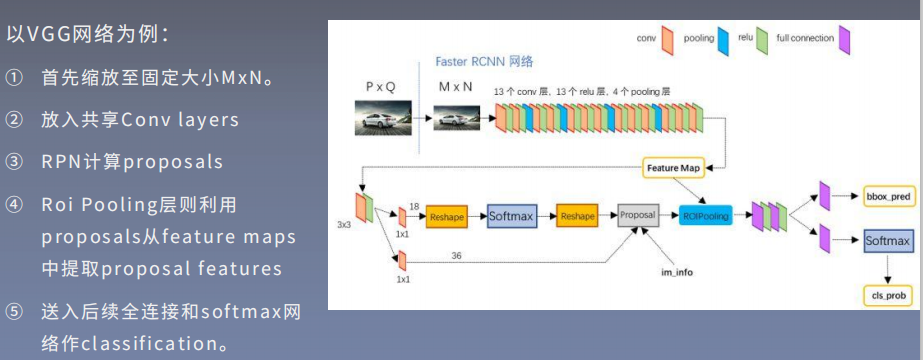
共享特征

如上, VGG网络
RPN中的anchor

以上被称为anchor_base, 它有形状x大小 = 9种. anchor_base的boundingbox和每个像素点的偏移相加即可得到每个像素点对应的anchor. 所以全部boundingbox实际上有HxW*n_anchor个 (n_anchor默认为9)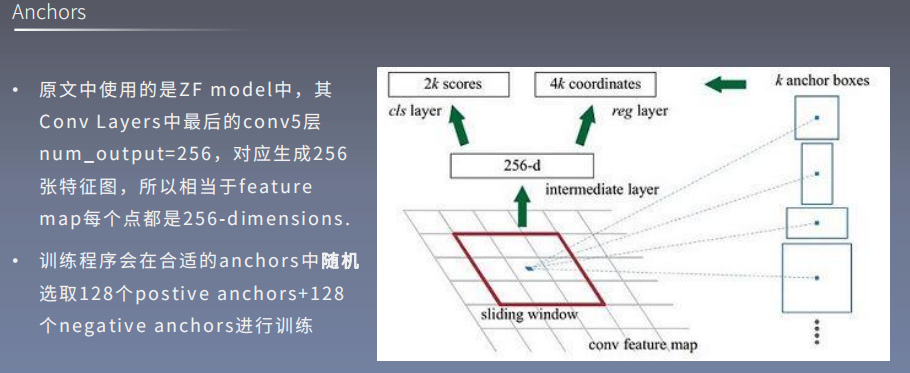
上图, 以具体的特征点对应的特征向量为例, 它是256-d(channels=256), 将其分别进行前后背景分类学习和坐标偏移量回归学习. 前后背景分类学习是指判断当前anchor内是否有检测目标, 分类的方法采用softmax, 所以每个anchor对应两个概率值(得分值), 故该特征向量对应了2k个概率值(每个特征点有K个anchor). 坐标偏移量回归是指学习一些偏移值来作用到anchor框上使得更准确, 由于偏移值包括4个值, 所以该特征向量对应了4k个坐标偏移值
注: 以上的概率值就是=scores , 坐标偏移值=coordinates.
RPN

理解RPN的预测量与真值分别是什么, 是理解RPN原理的关键. 对于物体检测任务来讲, 模型需要预测每个一个物体的类别及其出现的位置.PRN可以预测Anchor来替代直接预测边框.
上一条路径用softmax分类anchors获得postive和negative(前景和背景), 这个由交并比决定.
下一条路径用于学习anchors的boungding box regression的偏移量
以上的输出被称为Roi.
简洁来说: anchor是先验框, 我们对于所有特征点都生成anchors, 这些anchors并不是随机生成的, 他们是确定了位置的, 之后呢, 我们再拿这些anchors与标签框一个一个做IoU, 通过Iou与阈值的比较, 我们可以给这些anchors打上一个叫正或负样本的标签, 这含义是标记某个anchor到底是前景还是背景. 但是, 目前正负样本的均衡性太差, 网络不好收敛, 于是我们在这些样本中挑选出一些正负样本出来. 在这些样本中, 来做softmax分类损失, 它的输出自然是越大越好, 这被称为样本得分. 注意, 这里只是计算了分类损失. 我们还要做坐标偏移的回归呢, 总不能对所有anchors都做回归吧, 当然不是, 我们只需要对分类得分进行排序, 对那些前6000的高分anchor(注:分越高越可能是前景)计算回归就可以了. 你注意到了吗, 根据Iou抛弃一些anchor是不需要学习的, 现在又只对更小一部分anchor进行回归, 这其实也是Fasterrcnn高效的原因吧. 回归之后, 再进行一些其他的操作来过滤anchor, 比如尺寸上限制呀, 以及NMS等, 最终输出Roi. 这个Roi是指如果该特征点有anchor的话, 也最保留iou最大的那个anchor.
注: NMS是指非最大值抑制,. 选择每个anchor对应的最大Iou的标签, 其他bbox抛弃.
注: RPN只分类为前背景, 而不是具体的物体类别
注: 得分排序是指在区分前后景anchors之后挑选一些anchor根据softmax的概率值进行排序. 因为在计算softmax得分之前, 需要考虑数据不均衡问题. 先分好前后景(也就是根据IoU分正负样本)之后, 在其中挑选一些正负样本, 它们之和为256, 其中正样本不超过128个. 在这些挑选出的样本上再做soft损失函数(也就是得分).
Roi pooling


什么是ROI呢?ROI是Region of Interest的简写,指的是在“特征图上的框”; 参考链接: https://zhuanlan.zhihu.com/p/73138740
RoI Pooling的过程就是将一个个大小不同的box矩形框,都映射成大小固定(w * h)的矩形框.
这是由于其后需要接入全连接网路.,分别预测Rol的分类与偏移量.
注: MaskRCNN中进一步提出了RoI Pooling.
最后的输出

总结
创新点, 关键点, 启发点⭐️(“佳句摘抄”)….如何自测? 1. 你是谁 - 提出/采用XX方法,细节是XX. 2. 从哪里来- 解决XX问题/任务, 其启发点/借鉴于XX. 3. 到哪里去 - 论文方法达到了XX效果.
答:
- Fasterrcnn提出了二阶段端到端的目标检测方法, 具体有VGG用于共享特征的提取, 和RPN模块用于先验框得计算, 来个创新实现了该目标检测的高效与准确.
- Fasterrcnn借鉴了rcnn和SPP-net, 它极大地解决了rcnn等效率低,图片尺寸限制,准确度等问题.
- fasterrcnn之后, 有许多基于此的网络, 入hypernet,maskrcnn,r-fcn,cascade rcnn等算法.
论文结构
1, Abstract. 2, introduction. 3, related work⭐️(“吐槽大会”). 4, our work. 5, experiments. 6, discussion. 代码实现5点
- 任务定义…目的/任务
- 数据来源…Dataset type, download
- 运行环境…基础环境, 工具, 第三方包
- 运行结果
- 如何实现…代码整体架构, 每部分实现细节.
答:

若有收获,就点个赞吧
0 人点赞
