使用self-attention替代RNN
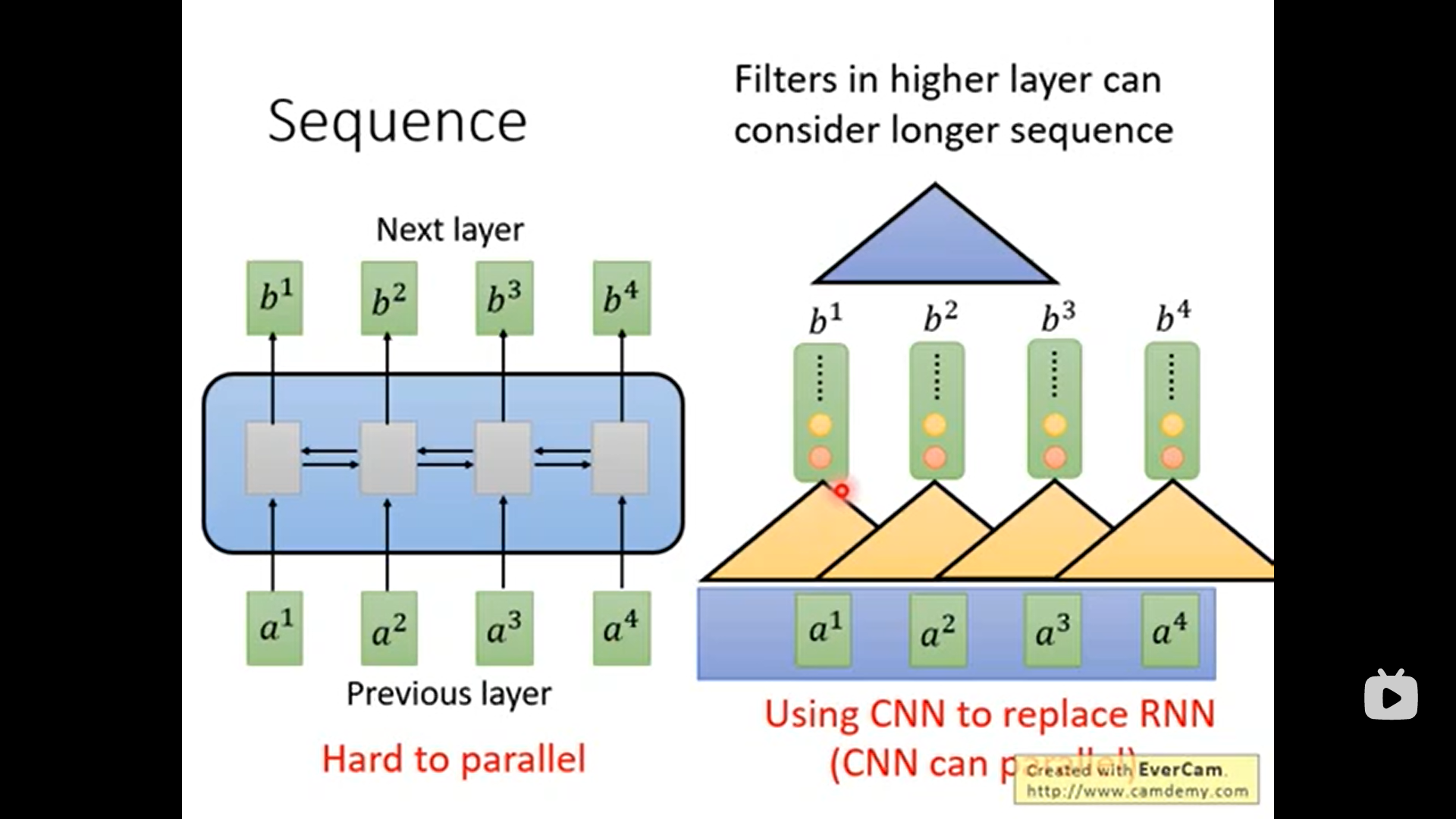
RNN的每个输出都考虑全局的信息, 但它有个很大的缺点, 他它无法并行计算.
于此同时, CNN能并行计算, 但是它相比RNN不够那么考虑全局的信息. 尽管你可以叠加多层CNN来实现, 全局信息的考虑, 使得CNN能到达到与RNN相同输入和输出的效果, 并且还能做并行计算. 但是, 现在有更好地选择-> self-attention
self-attention如何替代RNN
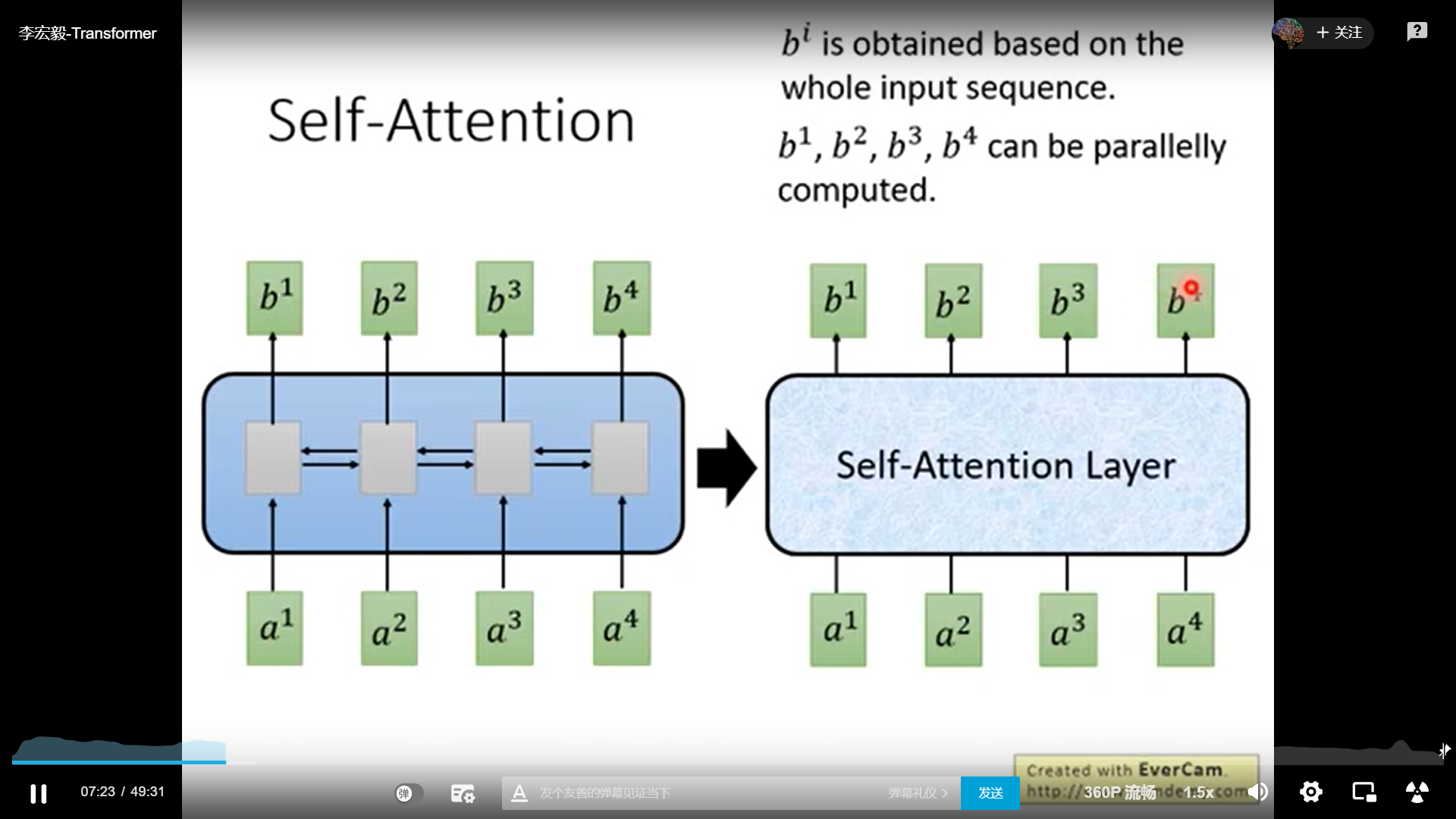
self-attention 用于取代RNN

a : attention

a = q . k / sqrt(d) . 这里的sqrt原论文没有细说, 但直观地讲是 q.k的dim越大那么输出值越大, 所以这里对输出值的大小做一个”平衡”.
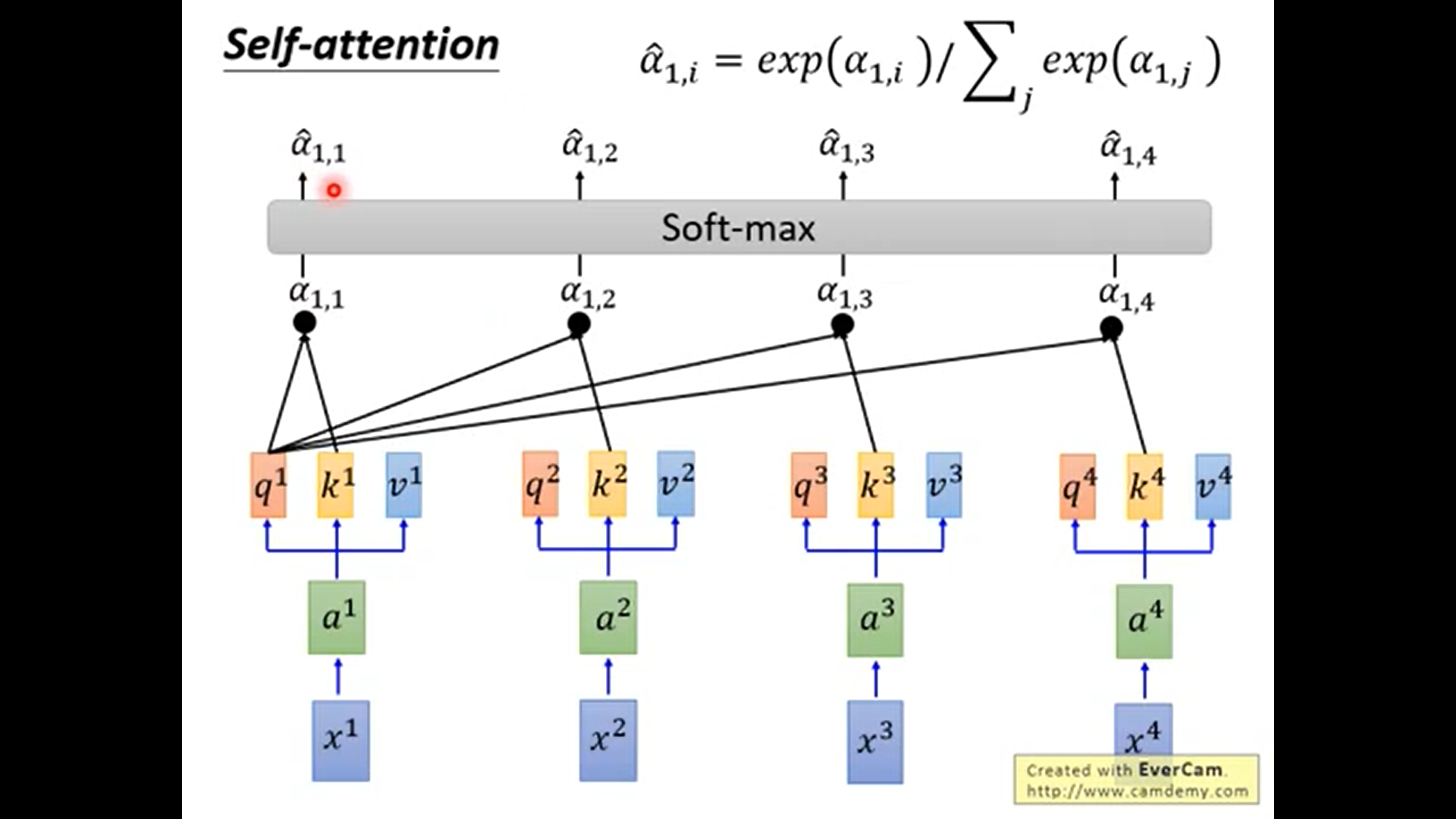
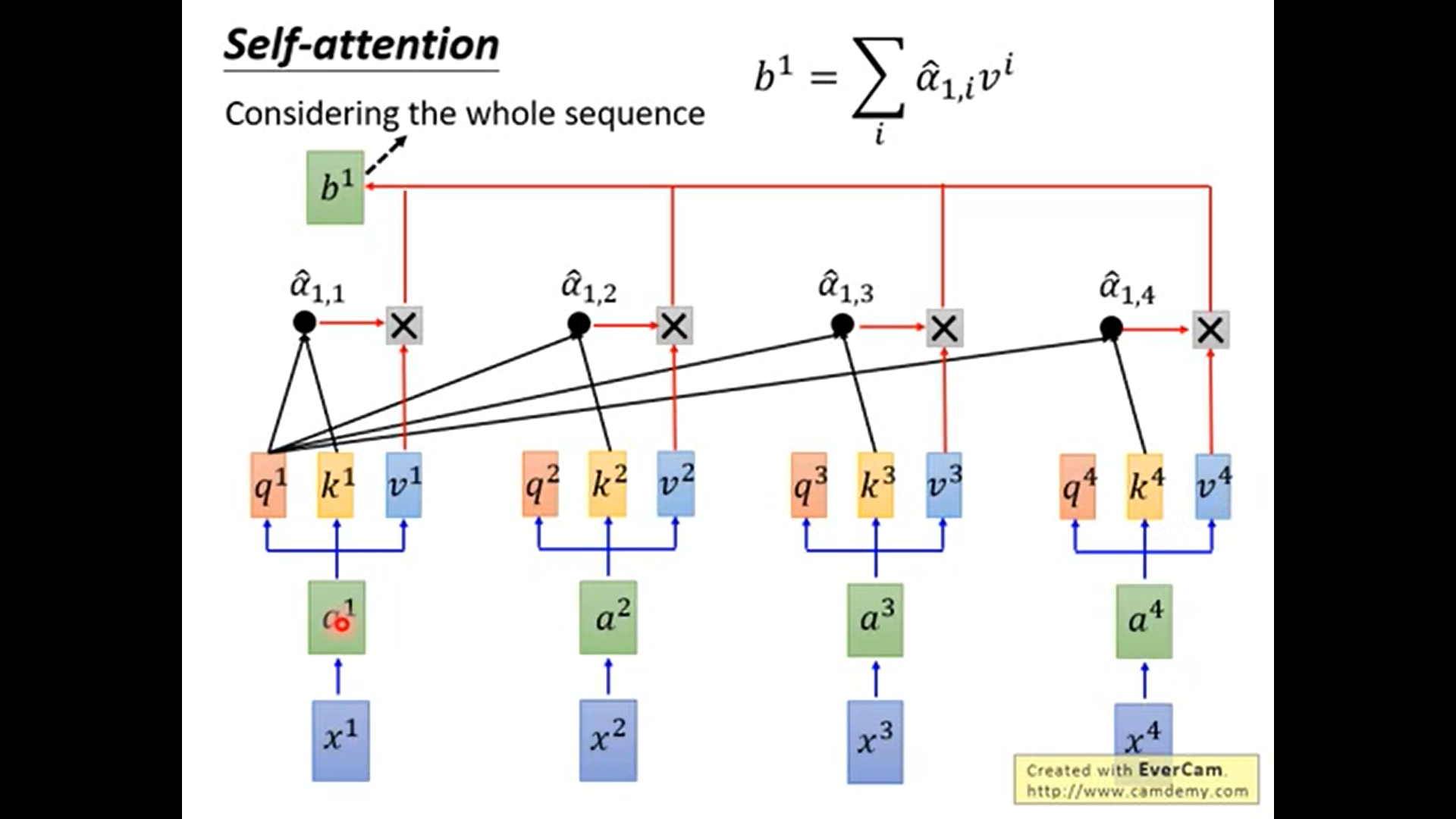
如上, 输出b1考虑了a1~a4的信息. 而且也能只考虑局部信息, 只需要使得a1_hat为0.
…
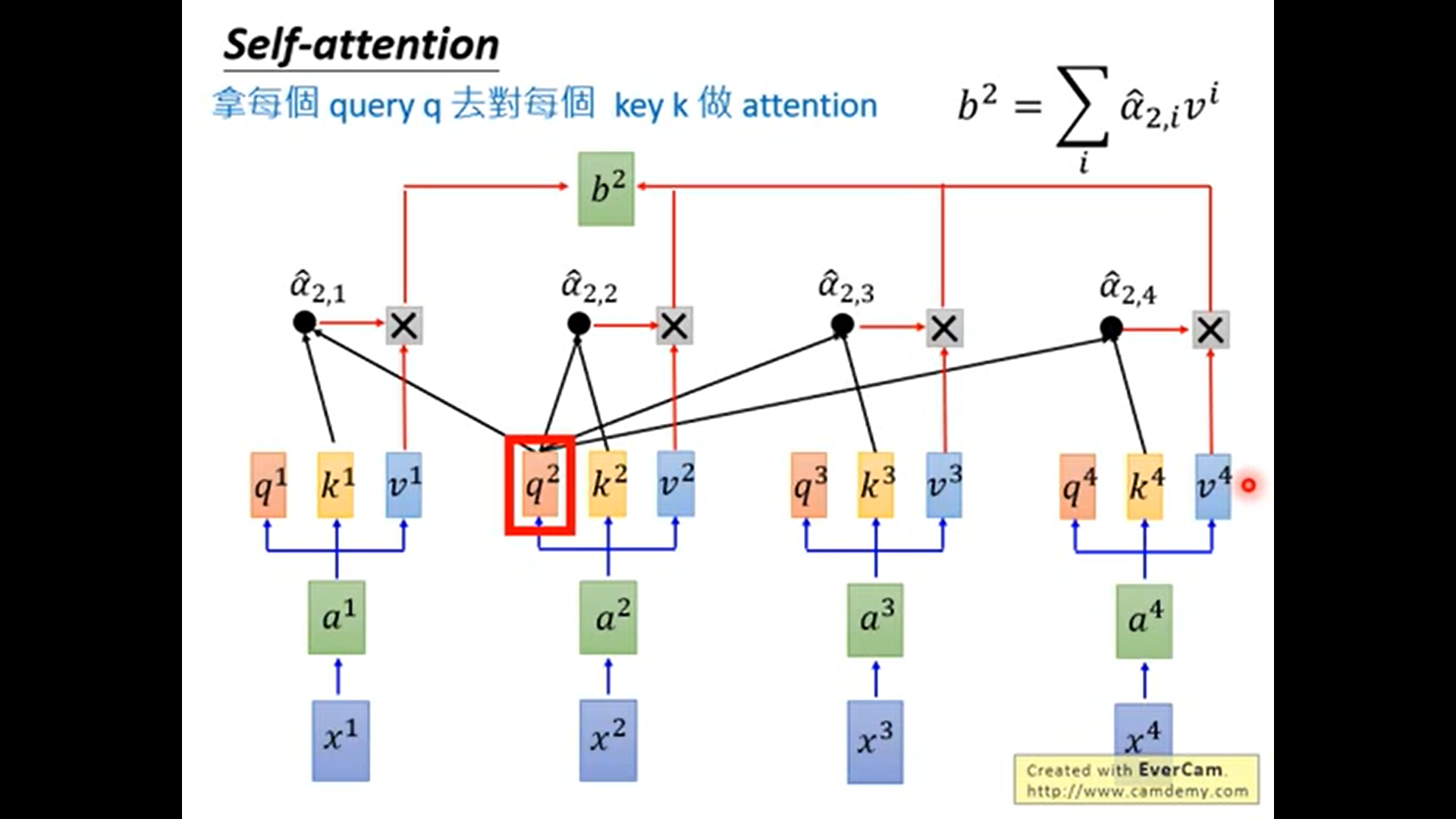
同理, 计算b2~b4
…

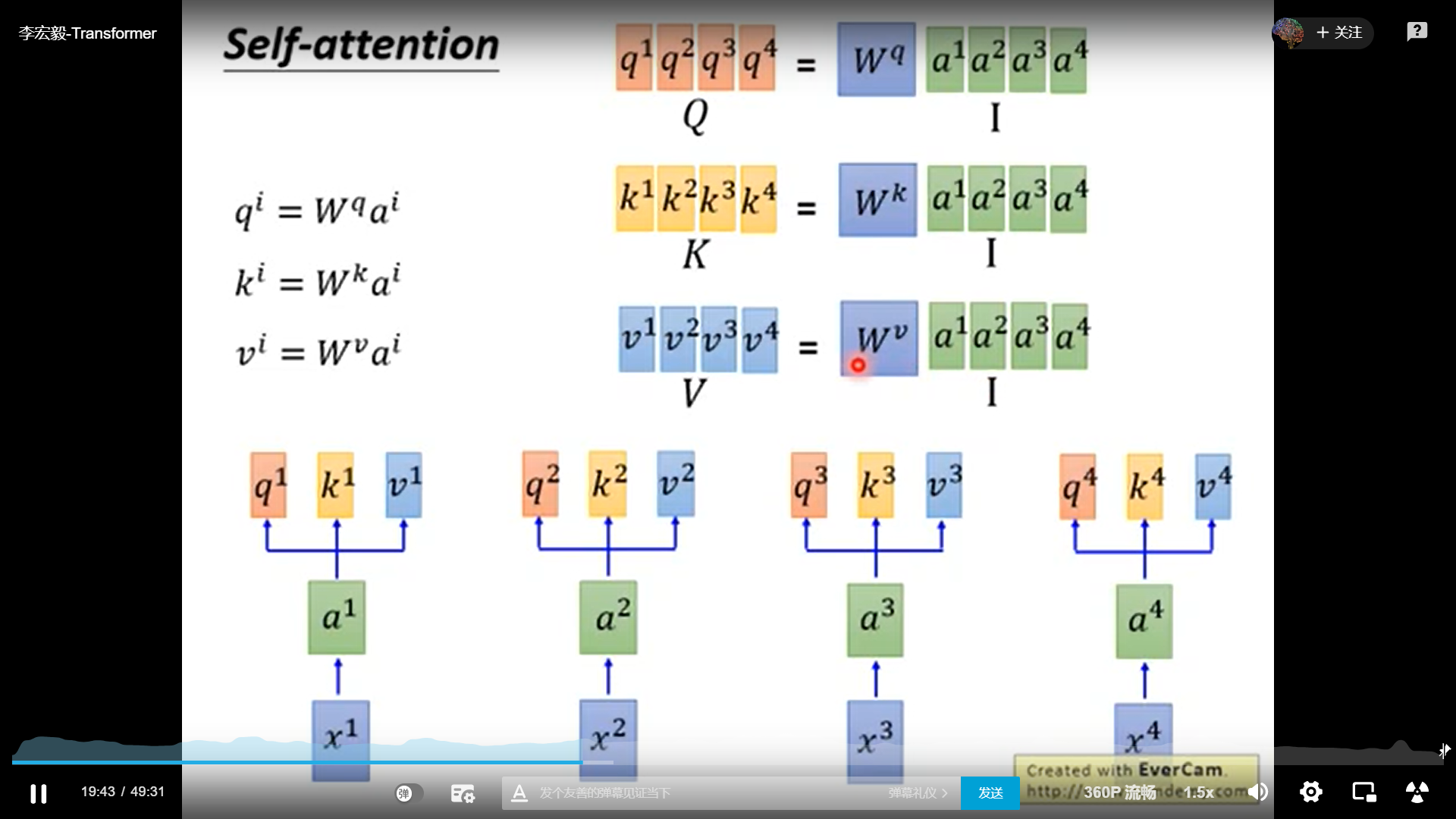
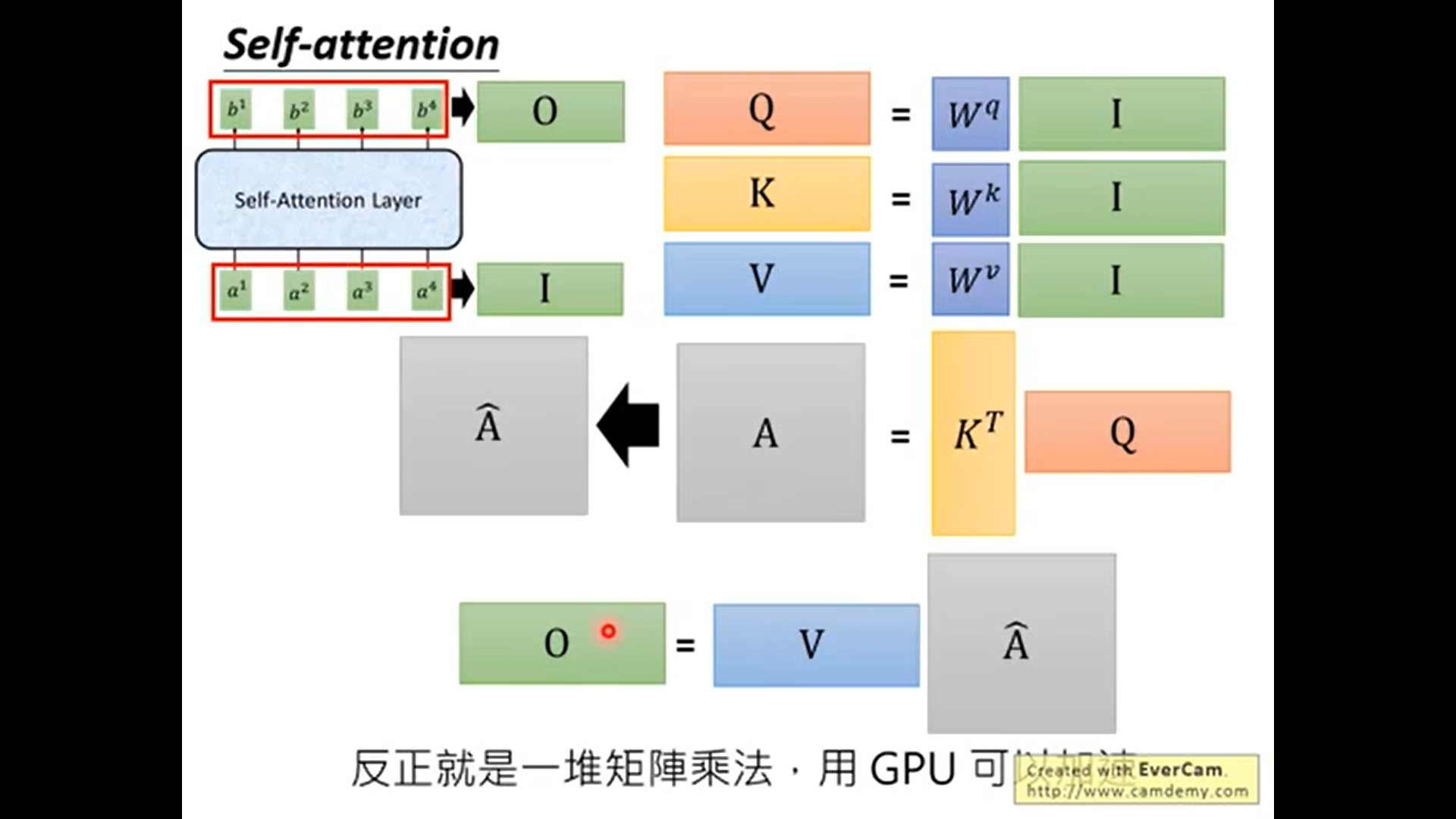
为什么self-attention能并行计算



多头注意力(2头为例)


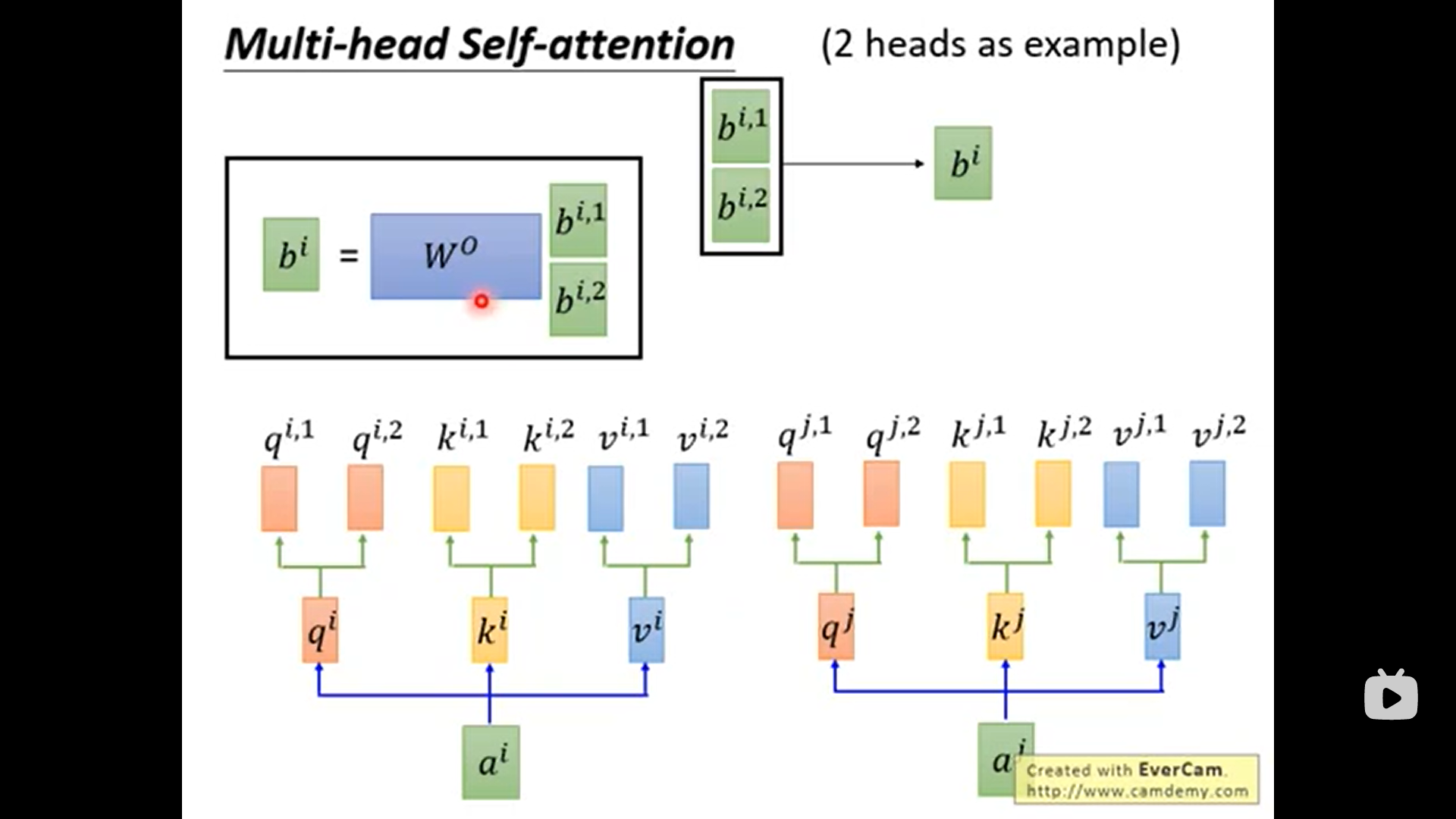
对bi1和bi2 -> bi
对self-attention进行位置编码
之前的self-attention是不考虑位置信息的,而现在, 我们将加上位置编码.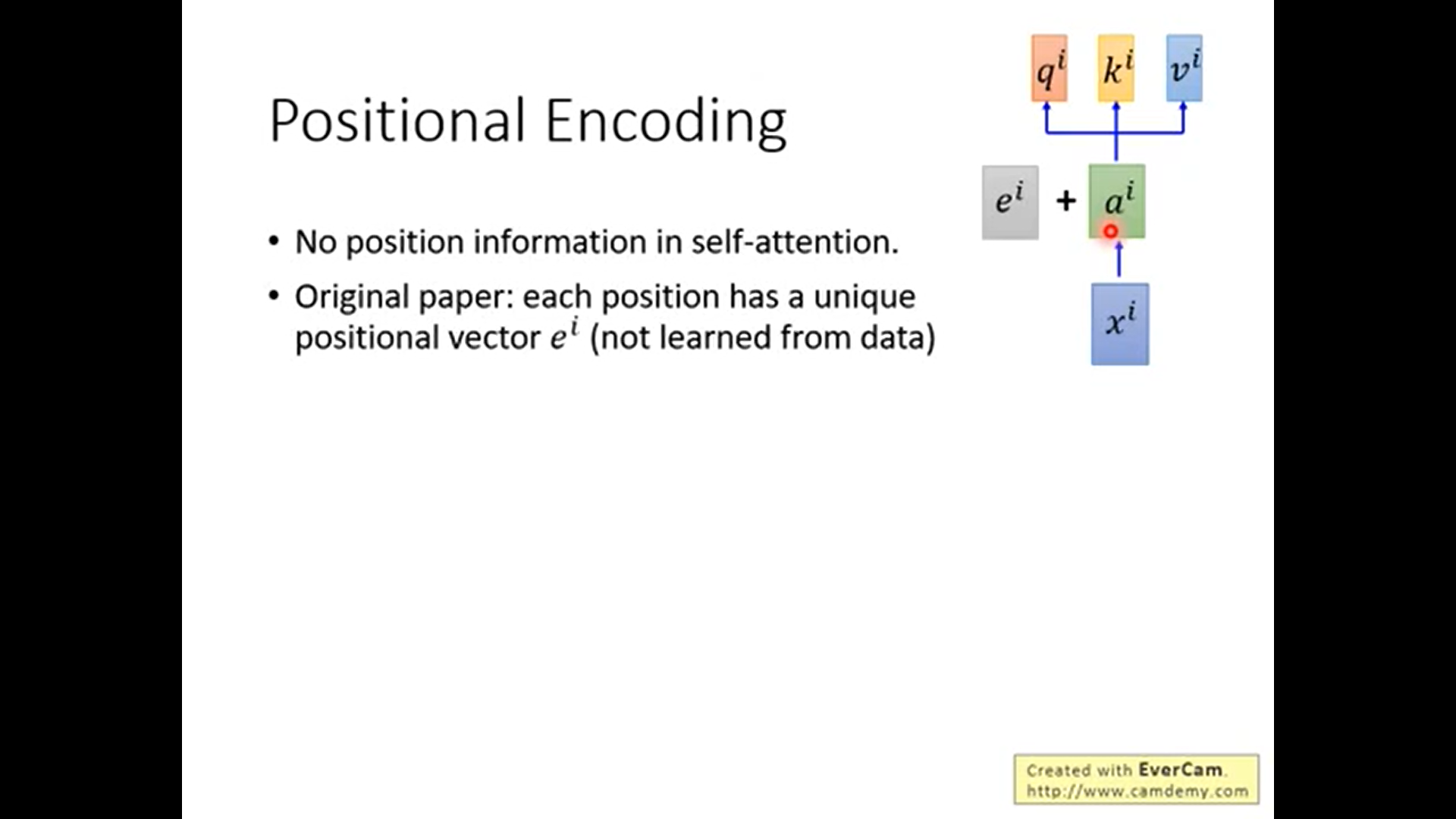
ei就是位置的信息. 它是手动设置的, 它与ai直接相加. 之后的操作与之前相同. 但是为什么不是concat,而是相加呢? 答: 几乎是等价的, 还不如直接相加.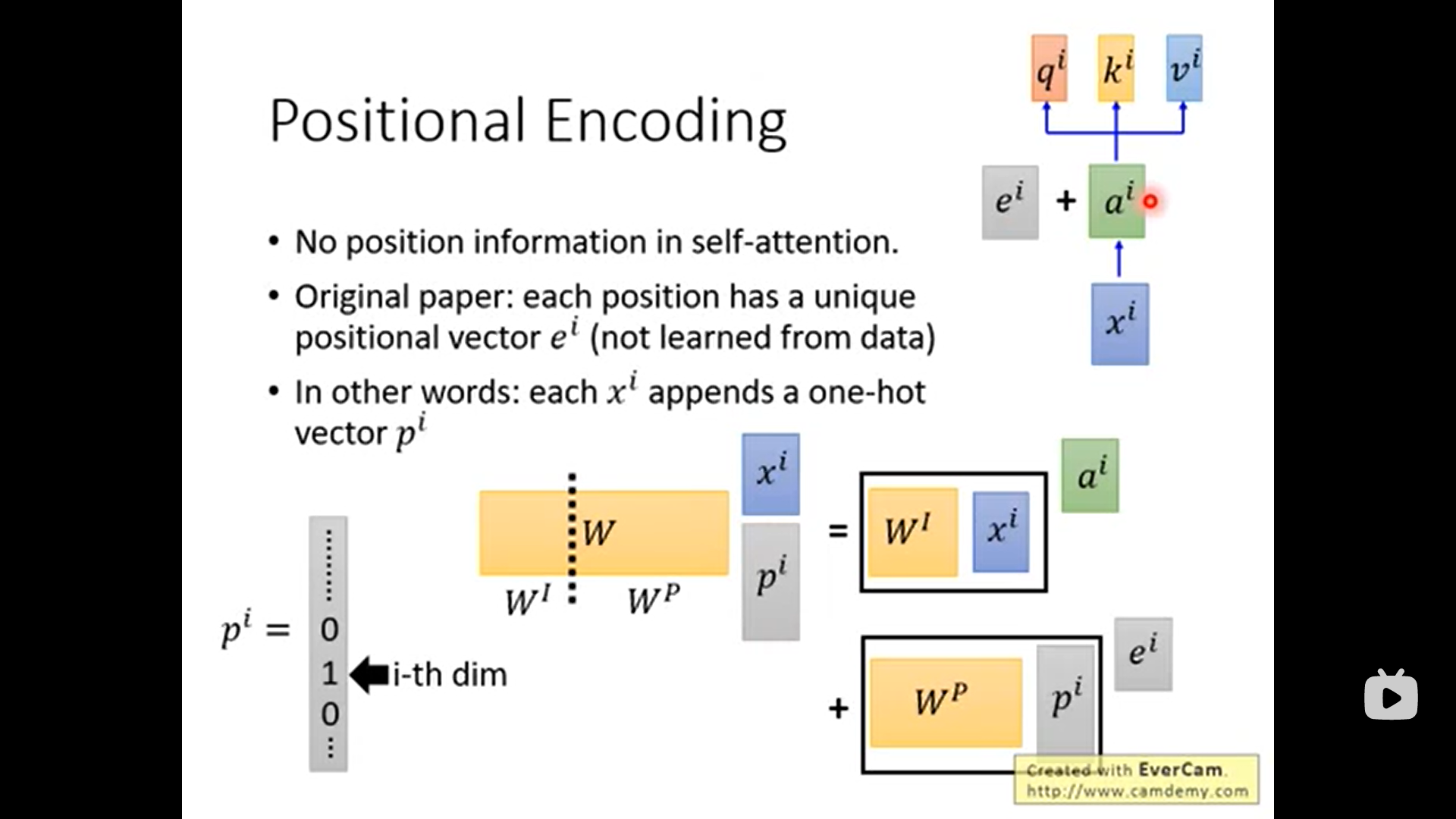
如上解释了为什么ei+ai,而不是concat. 如果我们concat的话, 其中wp和pi都是与位置有关的信息, 可以发现输出的 wp + pi可以被ei直接替代.
这里的wp也是手动的, 它的样子如下: 
self-attention如何在seq2seq中使用.

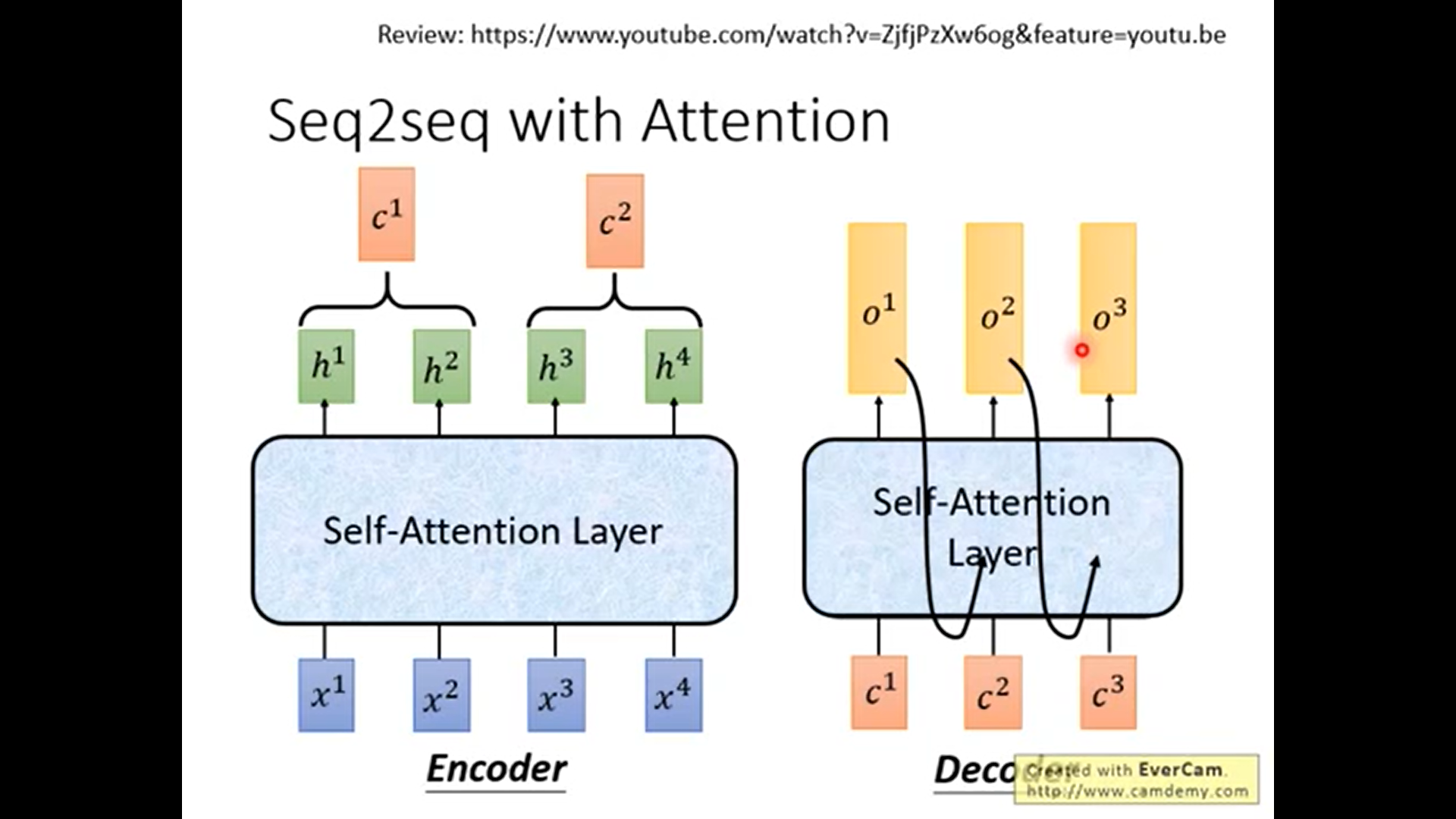
谷歌给出的transformer介绍
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
如上,encode和decodeing阶段, 对语言进行翻译工作.

基于transformer的seq2seq的model. 将中文”机器学习” 翻译为 “machine learning”

解读 encode子模块.
- embeding为向量, 并加上positional encoding
- 输入灰色的块中, 重复这个块多次. (结合上面的gif)
解读 decoding子模块.
- embeding为向量, 并加上positional encoding
- 输入灰色块中, 重复这个块多次.(结合上面的gif)
- Masked Muti-head attention 中的masked是指挑选已经生成的sequence们来做attention
Attention Visuazation
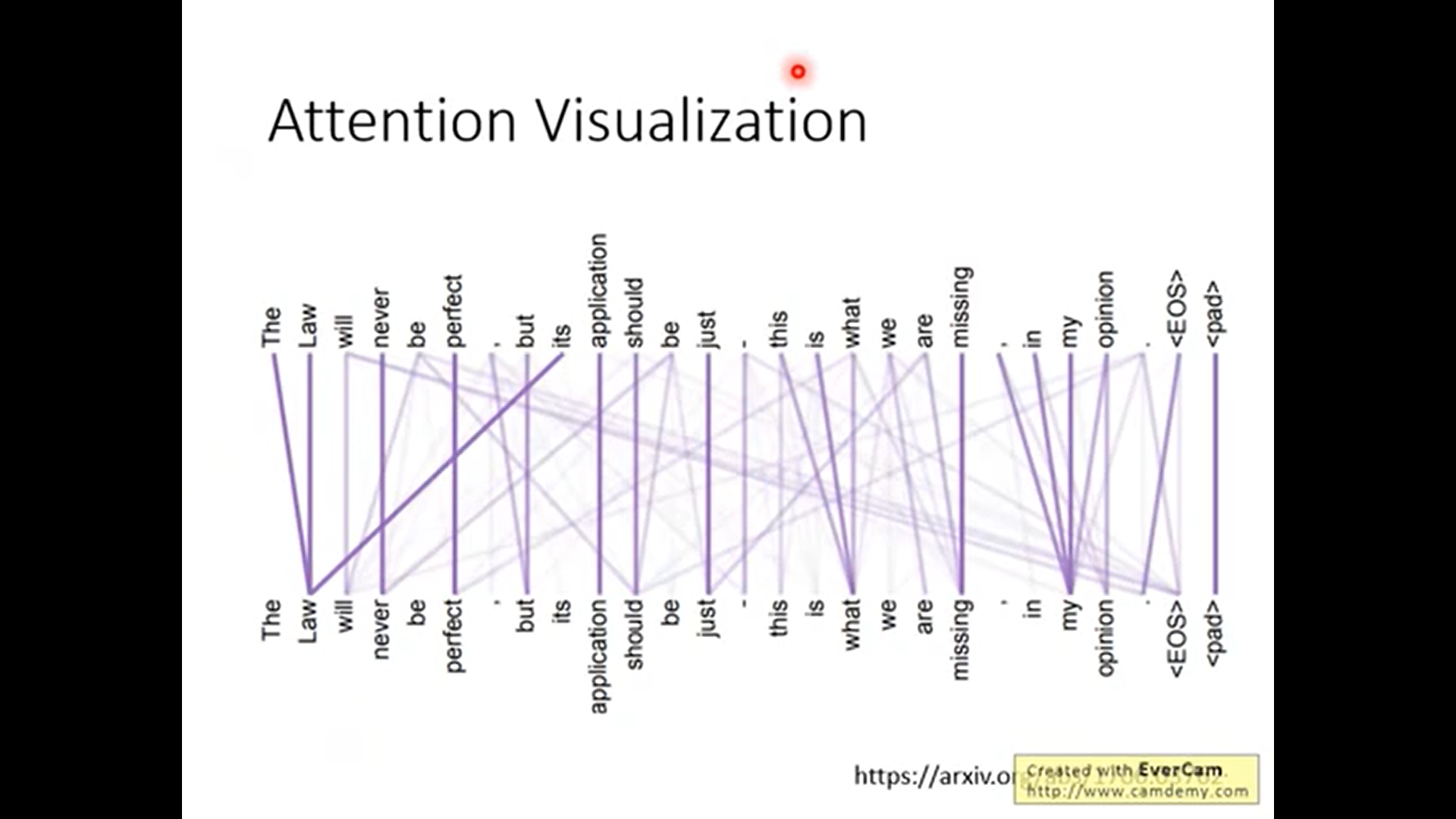
两两之间的attention越强越粗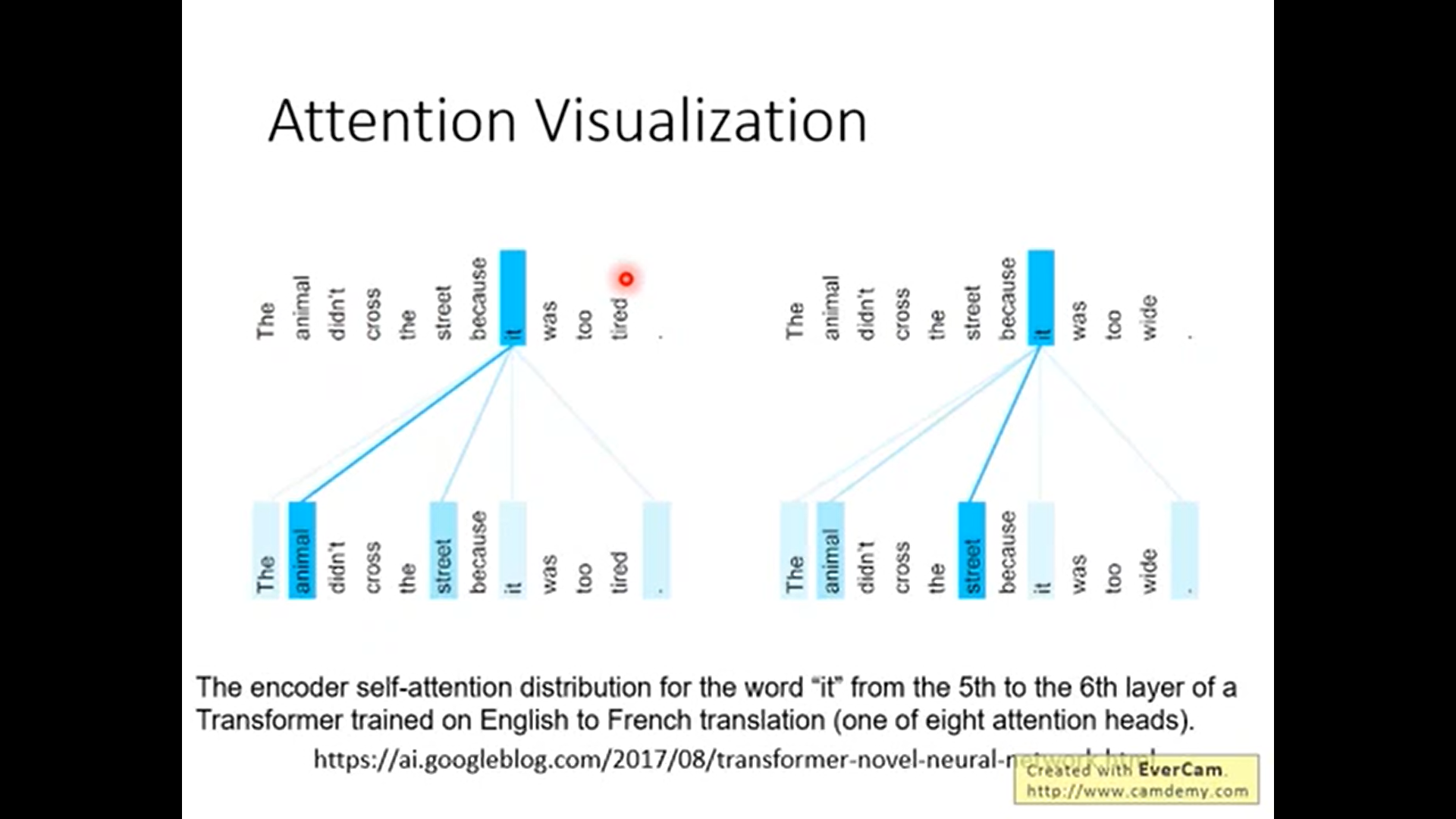
如上. 在不同语境下, attention先后给出了it指代animal和it指代street.
Multi-head Attention Visualization

在多头注意力中, 每一组q和v都做不同的事情. 如上, 绿色和红色是不同组的q和v的注意力结果. 红色的输出是对当前单词的位置的上一个单词进行预测. 绿色的输出就比较复杂了, 是对当前单词的位置之前多个单词进行预测.
transformer能干嘛
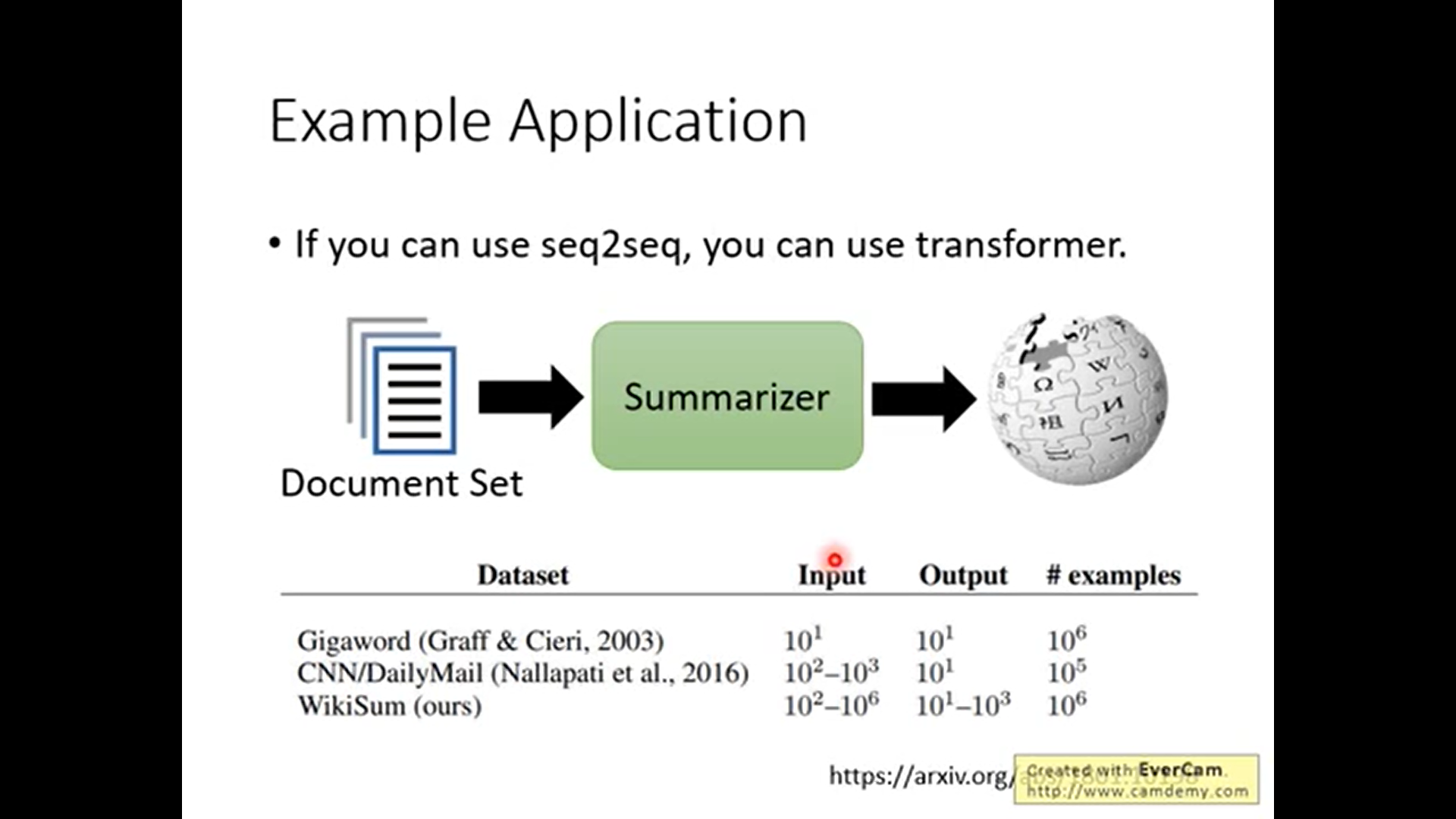
替代seq2seq. (目前transformer已经做了一遍seq2seq这些任务了 ) . 以上是谷歌的一个应用, 对transformer模型输入超级大量的文档, 期望输出类似维基百科的文档.
Universal Transformer
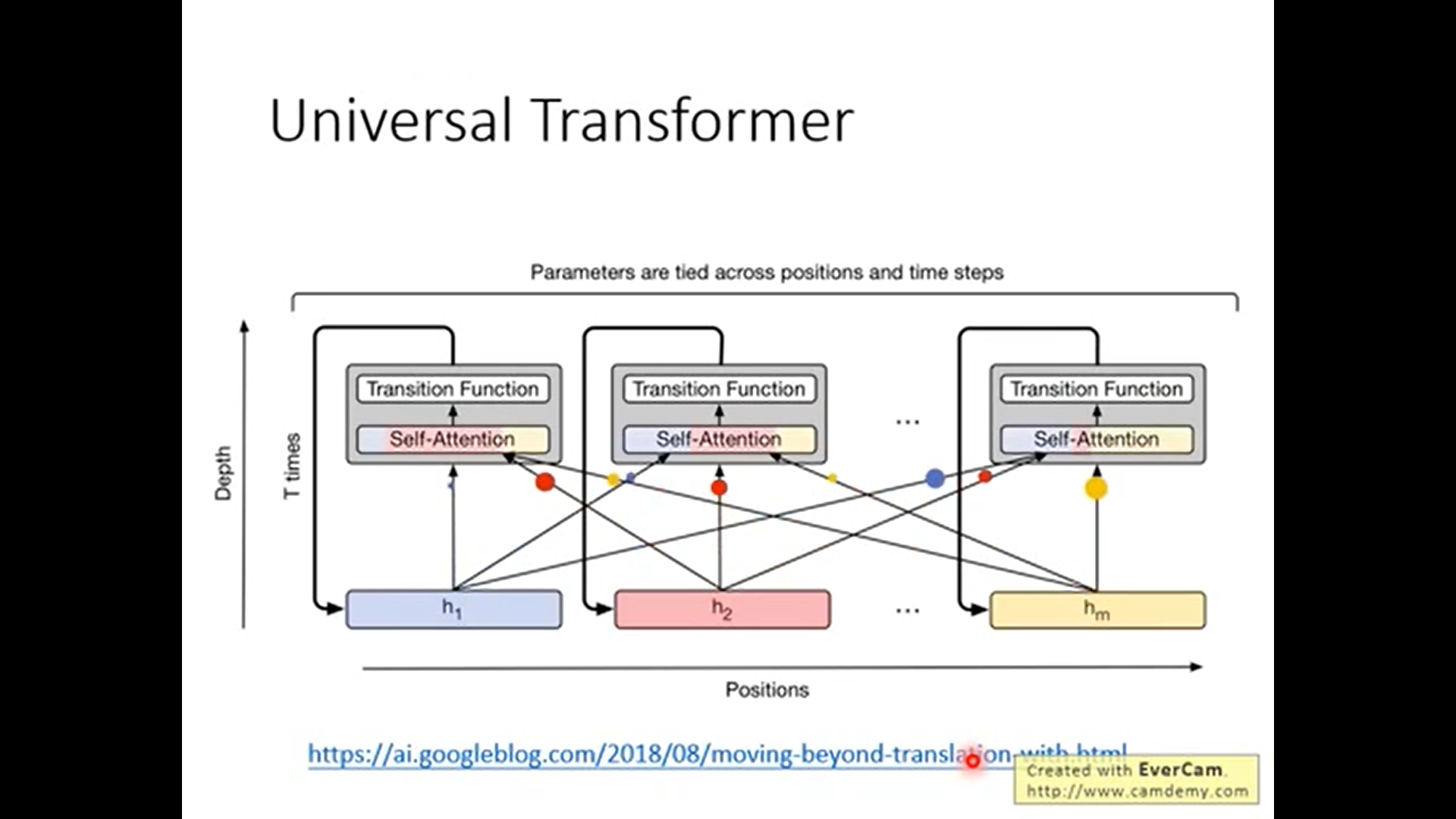
之前的transformer的每一层结构(在模型深度上或说在时间上)是不一样的. universal Transformer通过在深度上使用Rnn使每一层都做相同的transformer结构.
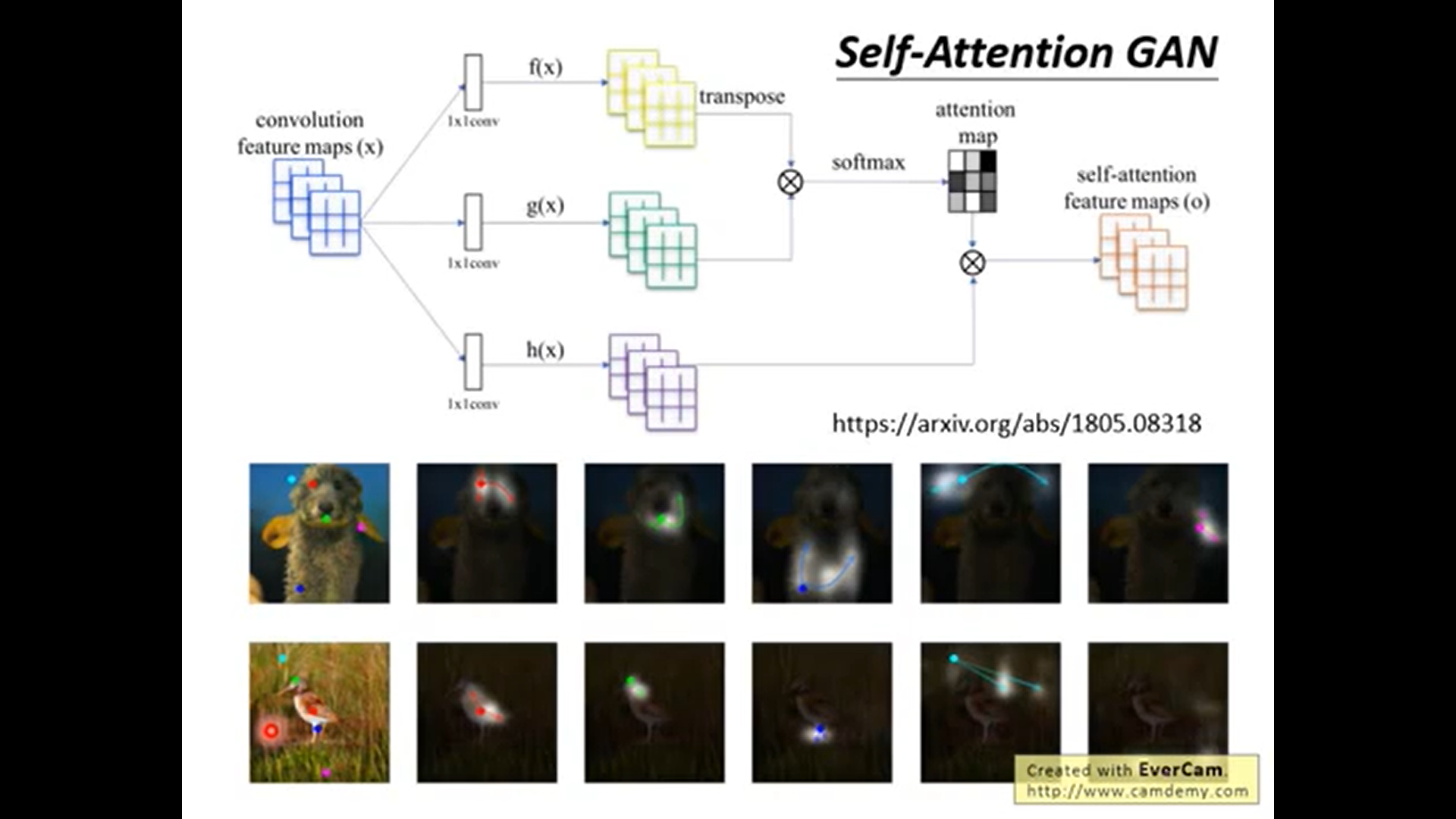
将transformer用在图像上.

若有收获,就点个赞吧
0 人点赞
