https://aistudio.baidu.com/aistudio/education/preview/1389301
传统注意力机制
attention重要概念

计算方式和两种注意力计算
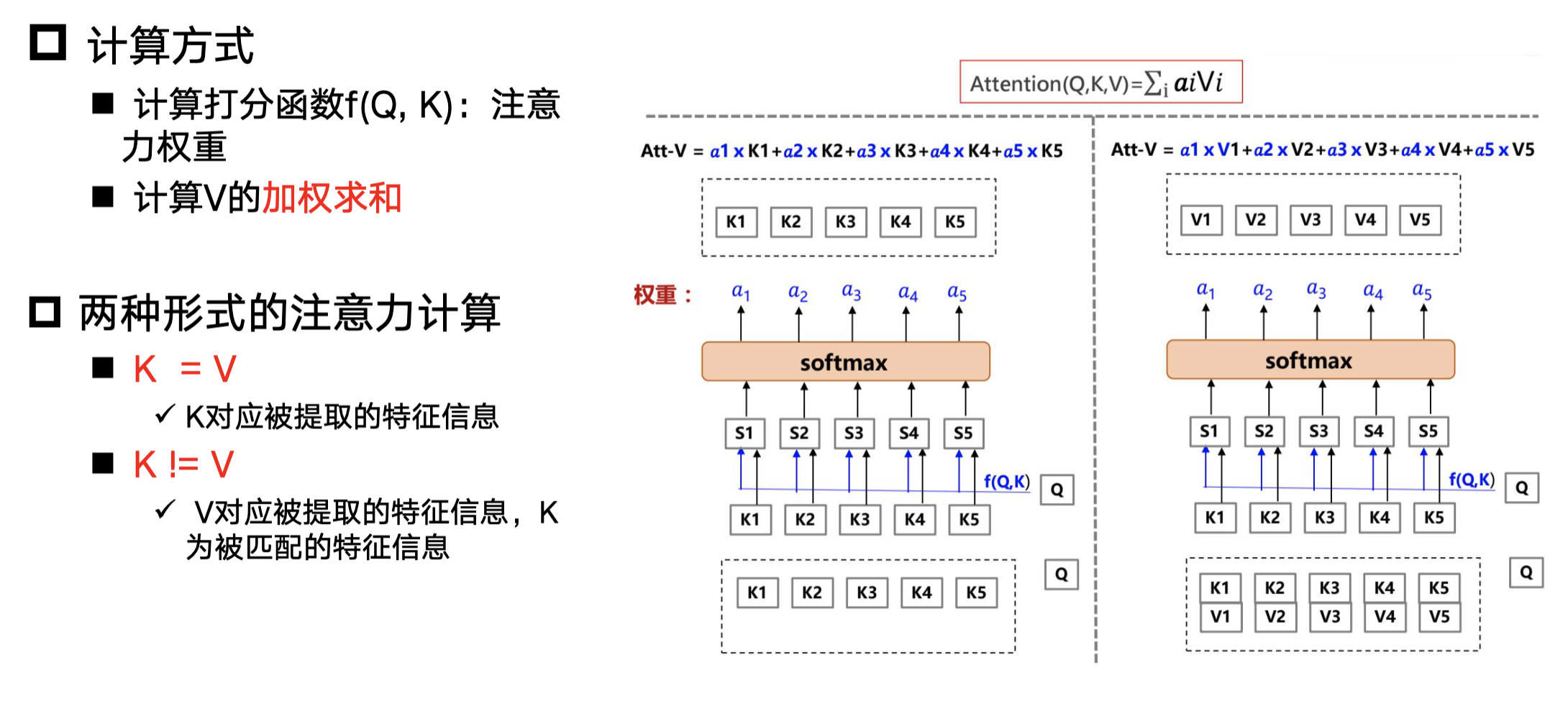
注意力打分函数

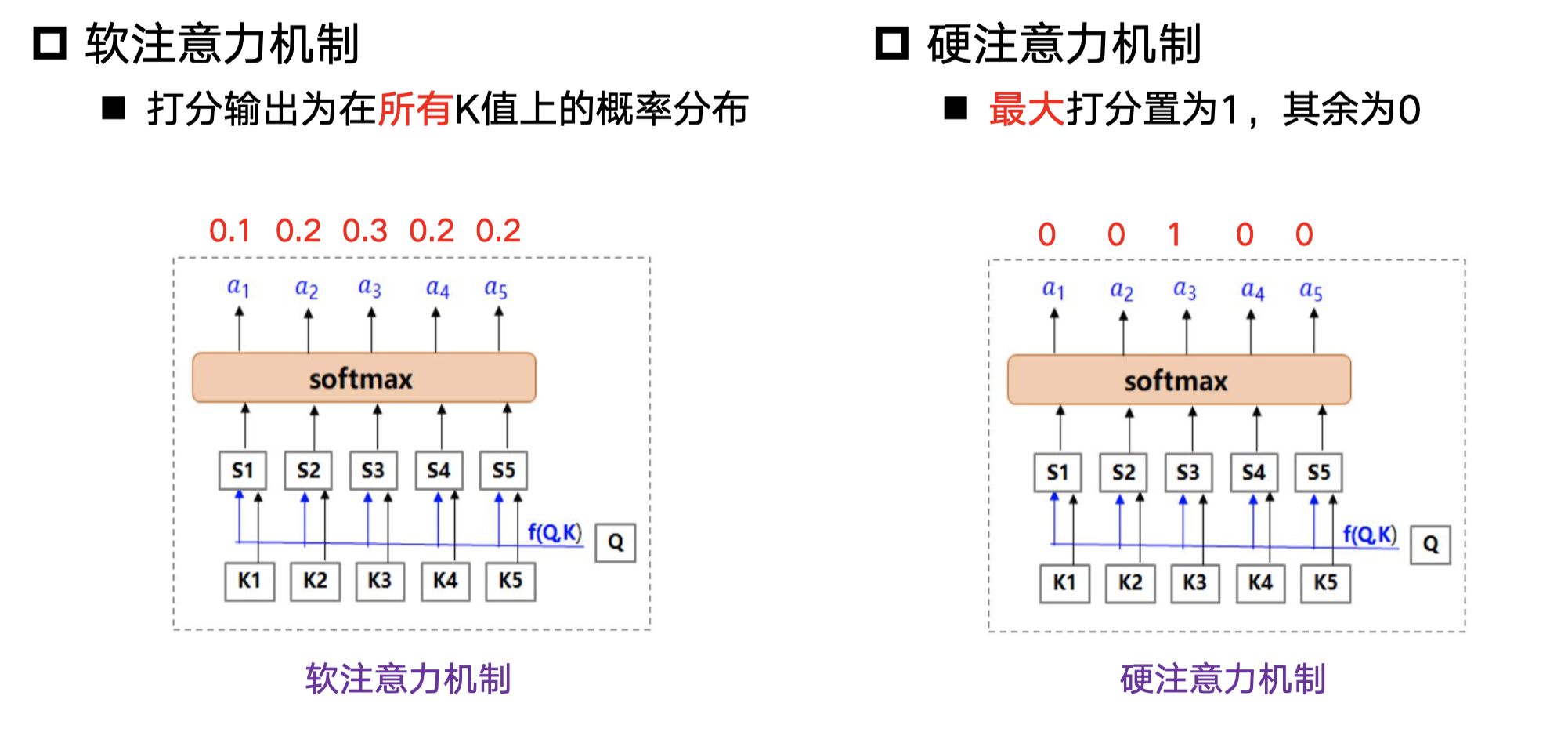
软注意力和硬注意力
局部注意力机制和全局注意力机制

自注意力机制和交叉注意力机制

Transformer注意力机制
Transformer简介和关键点
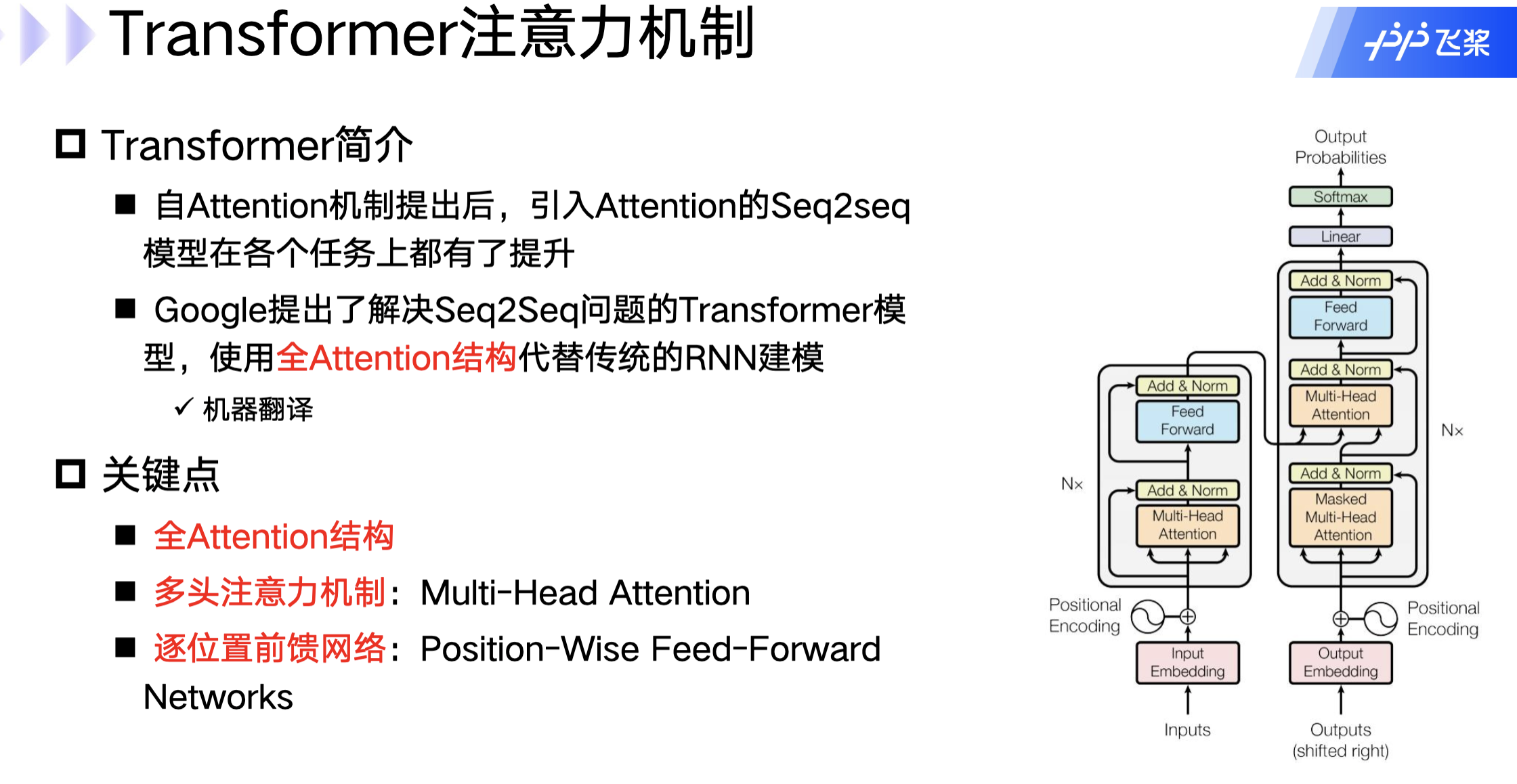
模型结构

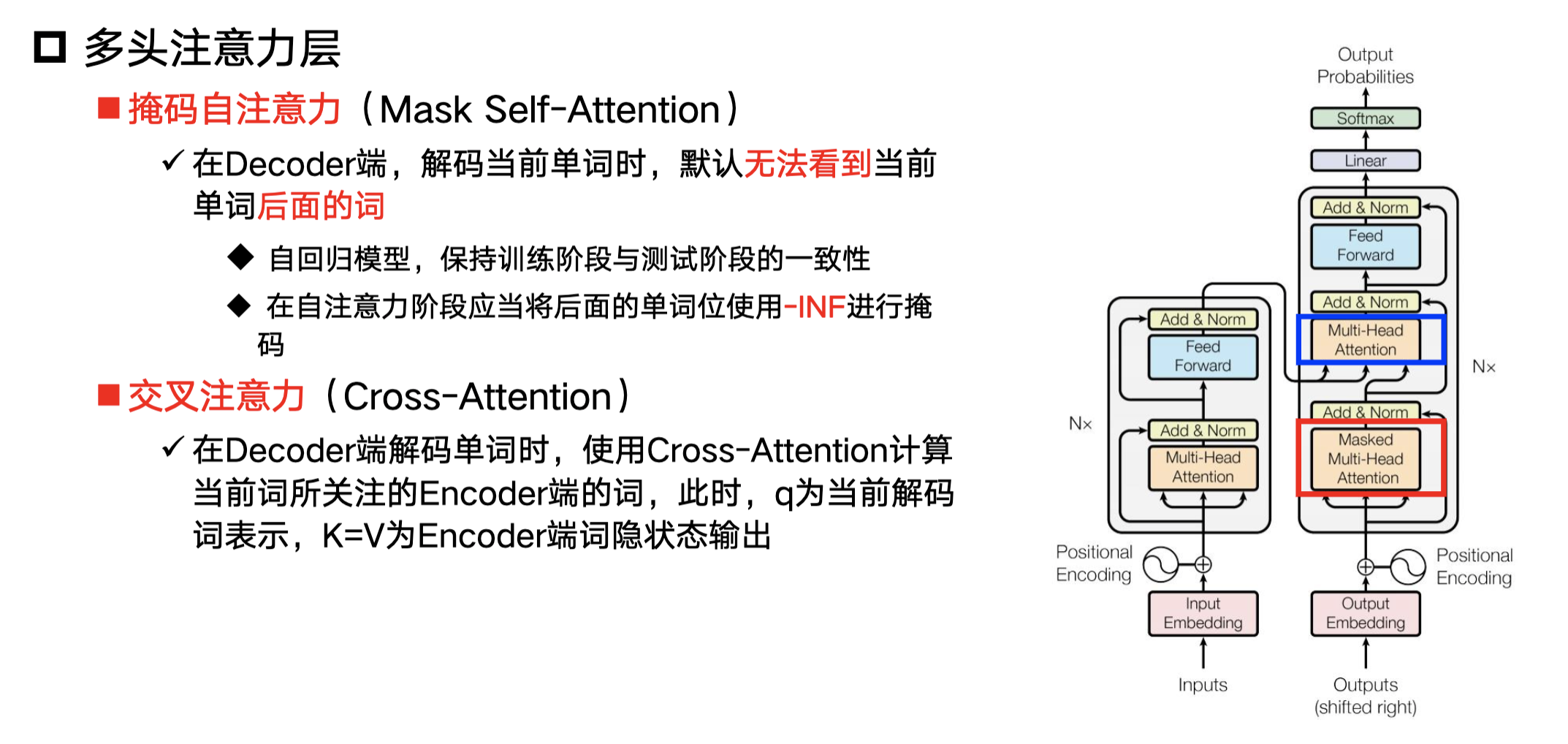
多头注意力层

多头注意力层

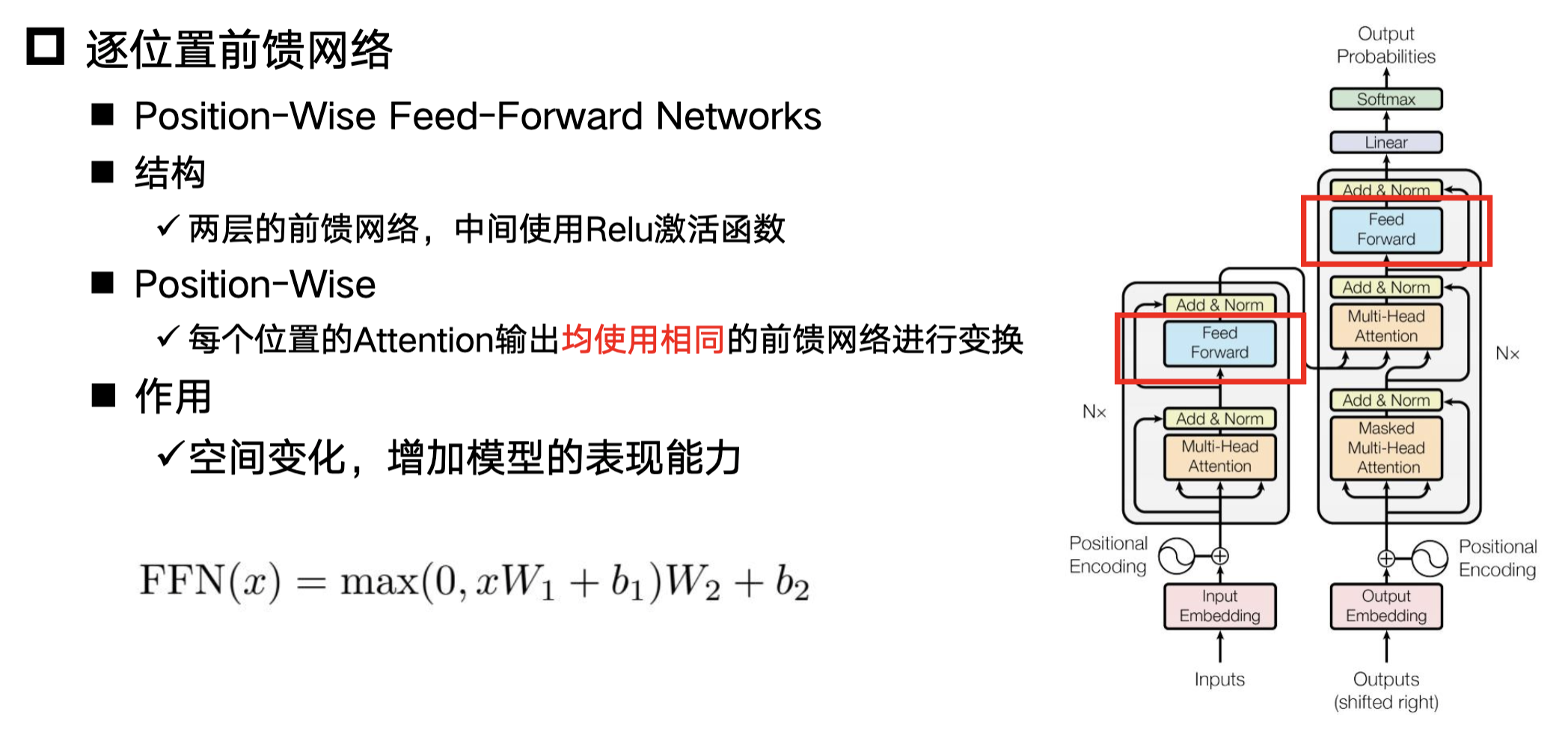
逐位置前馈网络
残差连接

权重矩阵退化:权重矩阵的秩表达了空间中线性无关的向量个数,那么低秩意味着参数空间所表达的空间纬度不高。
层归一化

归一化中的放射变量:对于多个样本的输入,方差和均值是不同的,这里的放射变化是为了综合这些不同的样本。
为什么不是bn: 因为输入为不等长的文本,所以彼此分布可能有很大的不同,尽管在此后用padding进行了填充使它们等长。
输入表示

RNN天然是有序的,而Transformer解除了时序依赖。位置编码因此被引入进来,它将词序信息向量化,是模型中不可或缺的一部分。上图提供了两种位置编码的方式,本质都是用dmodel 维向量来位置编码,上述中i表示第i个样本,pos + k表示相隔 k 个词的位置。

模型效果展示


总结


在数据量不够的情况下,transformer并不一定好。
Transformer在cv中的应用
图像分类: Vit
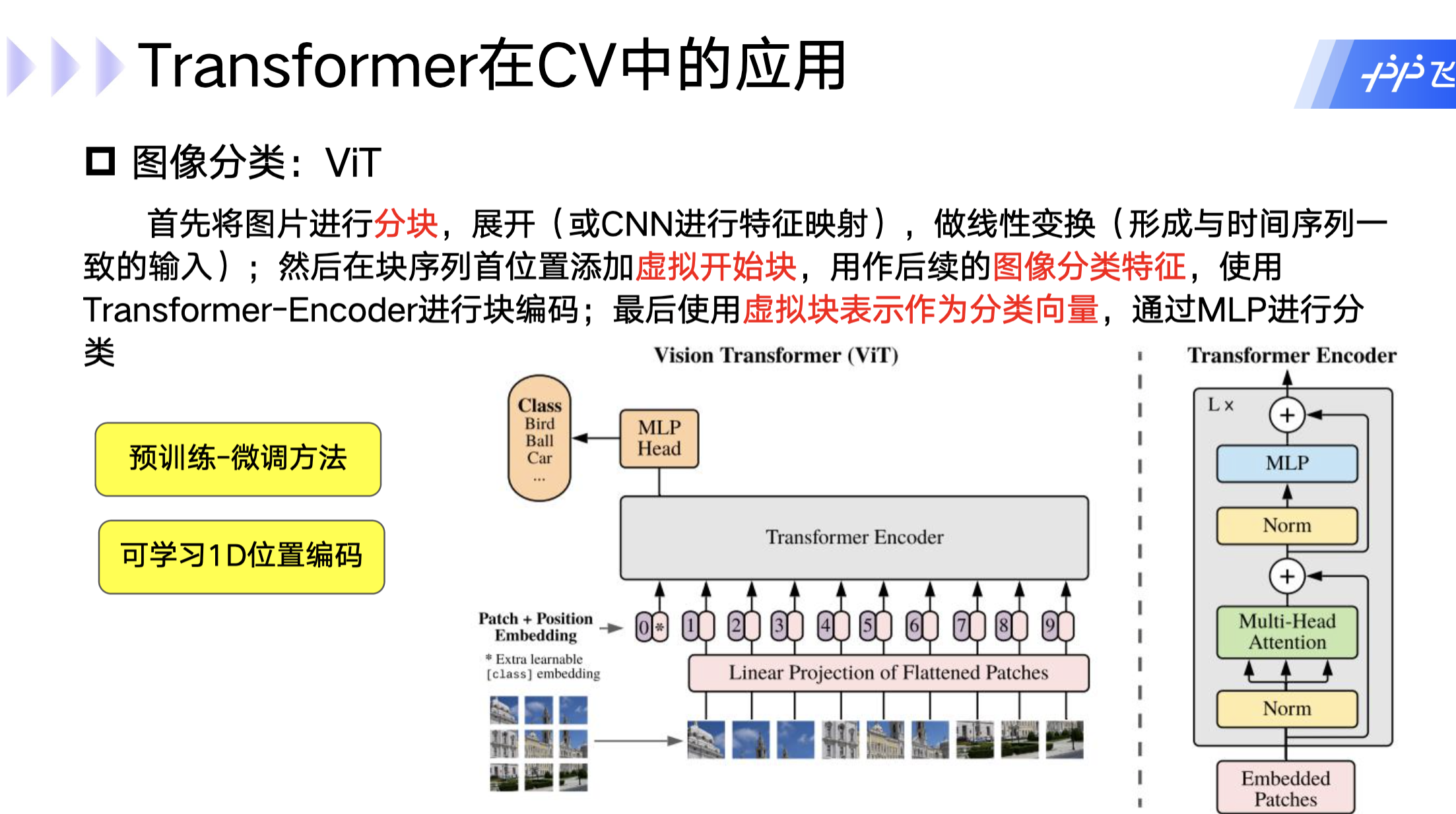
虚拟块:如上图[0#],用它去跟说有编码块进行交互,可认为他具备全局语义信息,在后续分类中使用它输入mlp来生成分类。
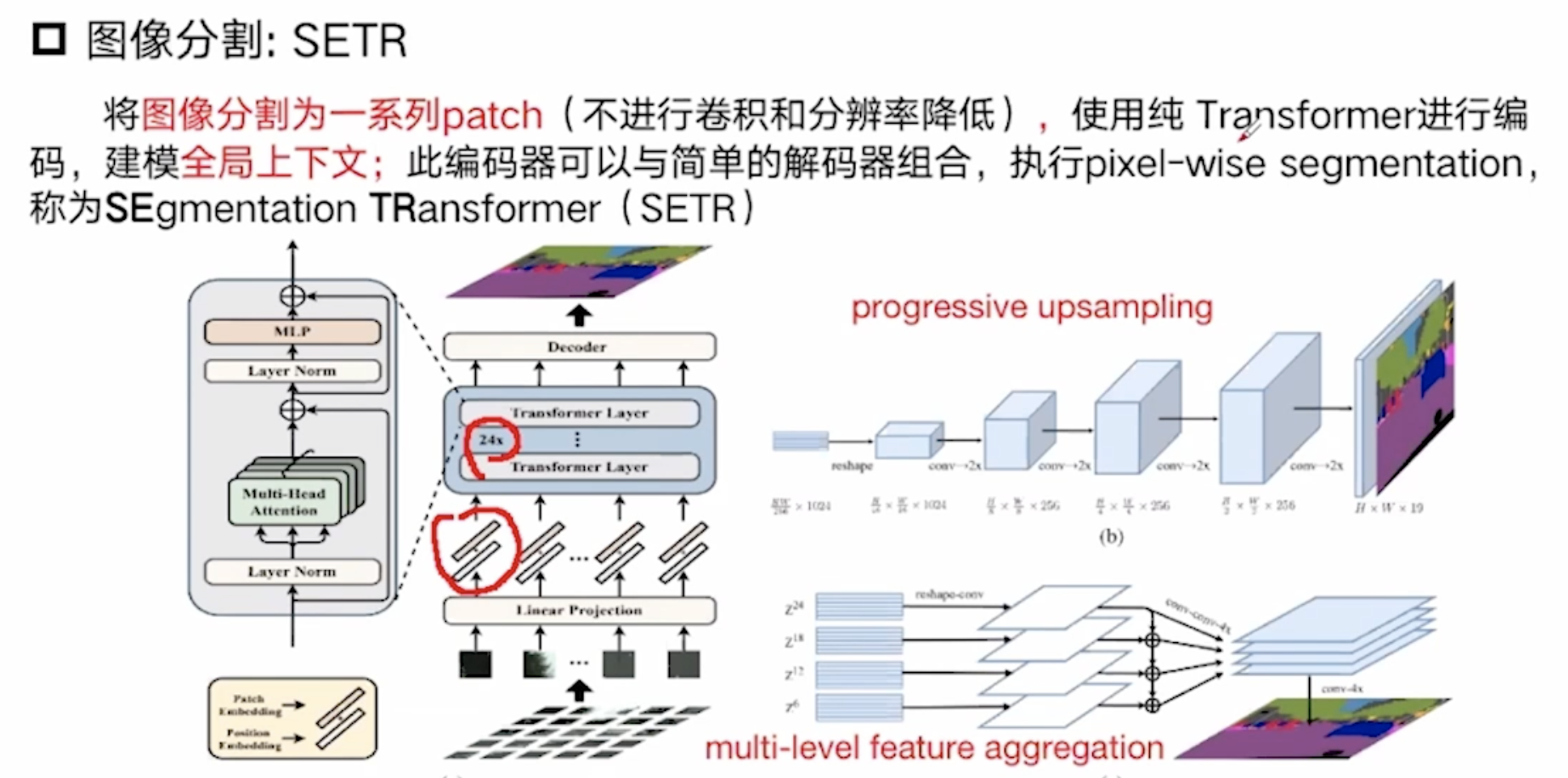
图像分割: SETR
目标检测: DERT


图像预训练模型: IPT
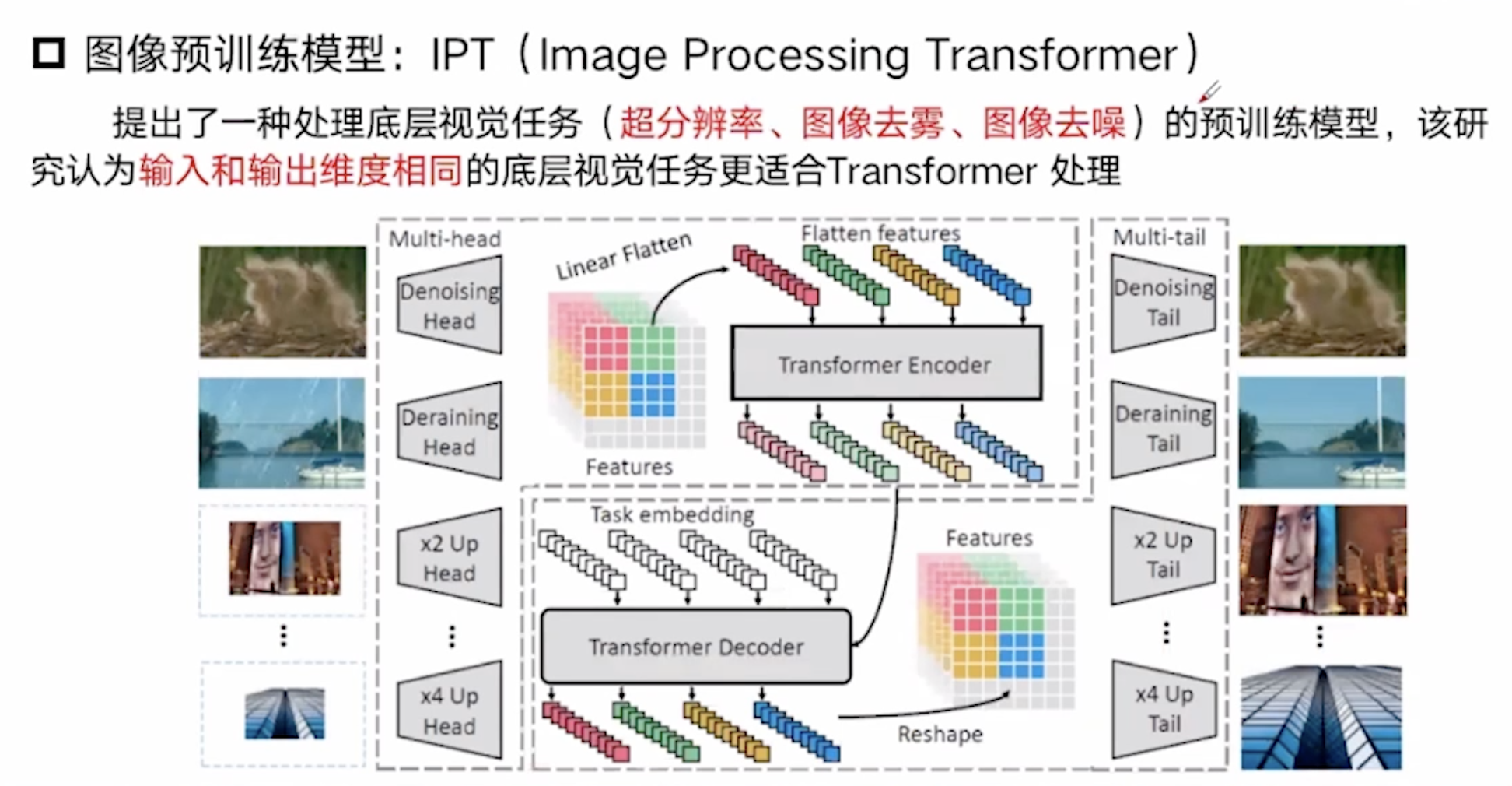
task embedding: 在传统的解码器中,需要特定的词嵌入作为开始标识,所以作为变通,在cv领域使用不同任务的词嵌入来作为开始标识。
其他




若有收获,就点个赞吧
0 人点赞
