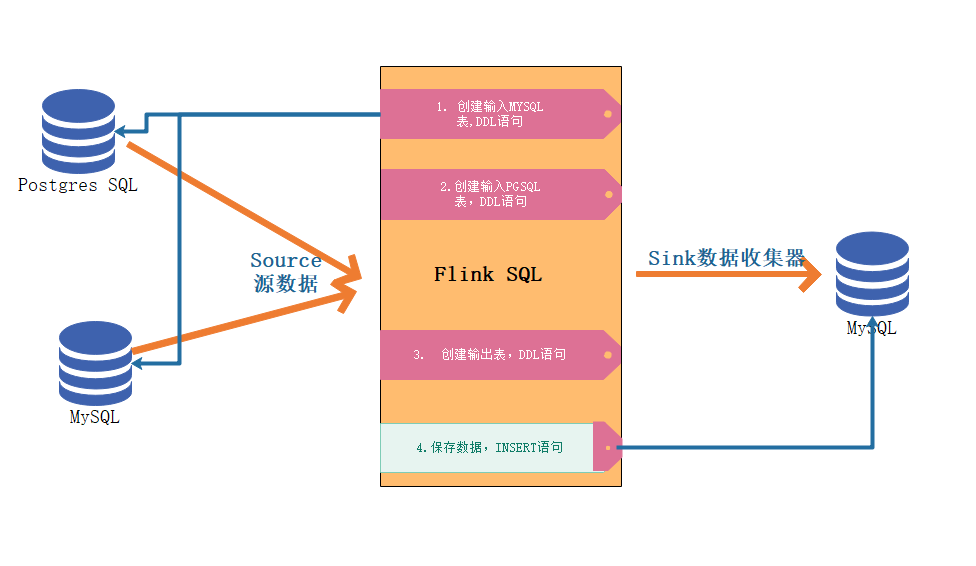
left join pgsql和mysql中的两张表生成新数据后放入mysql中
- flink cdc pgsql
问题注意
Parallelism
- 只能设置为 1 , 要不然数据同步会出问题
env.setParallelism_(_1_)_;SET 'parallelism.default' = '1'; -- optional: Flink's parallelism (1 by default)SET 'pipeline.max-parallelism' = '1'; -- optional: Flink's maximum parallelismsubmit job 时报错,但是任务提交却成功了
```java // sunmit job err tableEnv.executeSql(sourceUserDDL); tableEnv.executeSql(sourceClassesDDL); tableEnv.executeSql(sinkDDL); tableEnv.executeSql(transformDmlSQL);
// submit job success (真他妈神奇) TableResult tableResult = tableEnv.executeSql(sourceUserDDL); TableResult tableResult1 = tableEnv.executeSql(sourceClassesDDL); TableResult tableResult2 = tableEnv.executeSql(sinkDDL); TableResult tableResult3 = tableEnv.executeSql(transformDmlSQL);
<a name="lsOYO"></a># 建表语句```sql# 源数据用户表 <MySQL>CREATE TABLE `user` (`name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,`id` int NOT NULL AUTO_INCREMENT,`class_no` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;# 源数据班级表 <postgres SQL>CREATE TABLE "public"."classes" ("id" int4 NOT NULL DEFAULT nextval('classes_id_seq'::regclass),"class_name" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,"class_no" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,CONSTRAINT "pk_port_forward" PRIMARY KEY ("id"));ALTER TABLE "public"."classes"OWNER TO "postgres";## sink表<mysql>CREATE TABLE `user` (`id` int NOT NULL,`name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,`class_name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
Flink SQL准备
CREATE TABLE mysql_user_binlog (id INT NOT NULL,name STRING,class_no STRING,primary key (id) not enforced) WITH ('connector' = 'mysql-cdc','hostname' = '192.168.31.61','port' = '3306','username' = 'root','password' = 'root','database-name' = 'flink_sql','table-name' = 'user');CREATE TABLE postgres_class_binlog (id INT NOT NULL,class_name STRING,class_no STRING,primary key (id) not enforced) WITH ('connector' = 'postgres-cdc','hostname' = '192.168.31.61','port' = '5432','username' = 'postgres','password' = 'root','database-name' = 'flink','schema-name' = 'public','table-name' = 'classes','decoding.plugin.name' = 'pgoutput');CREATE TABLE user_class_sink (id INT,name STRING,class_name STRING,primary key (id) not enforced) WITH ('connector' = 'jdbc','driver' = 'com.mysql.cj.jdbc.Driver','url' = 'jdbc:mysql://192.168.31.61:3306/flink?serverTimezone=Asia/Shanghai&useSSL=false','username' = 'root','password' = 'root','table-name' = 'user');SET 'pipeline.name' = 'PgSQLAndMySQL2MySQL';SET 'parallelism.default' = '1';SET 'pipeline.max-parallelism' = '1';# sinkinsert into user_class_sink select mu.id, mu.name,pc.class_name from mysql_user_binlog as mu left join postgres_class_binlog as pc on mu.class_no = pc.class_no;
Maven依赖
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-walkthrough-common_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><!-- This dependency is provided, because it should not be packaged into the JAR file. --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><!--flink cdc connector --><dependency><groupId>com.ververica</groupId><!-- add the dependency matching your database --><artifactId>flink-sql-connector-mysql-cdc</artifactId><!-- the dependency is available only for stable releases. --><version>2.1.1</version><scope>provided</scope></dependency><!-- flink cdc pgsql --><dependency><groupId>com.ververica</groupId><artifactId>flink-sql-connector-postgres-cdc</artifactId><version>2.1.1</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency></dependencies>
JAVA代码
package cn.tannn;import cn.tannn.constant.FlinSqlConstant;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.SqlDialect;import org.apache.flink.table.api.TableResult;import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;/*** post*/public class PgSQLAndMySQL2MySQL {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.enableCheckpointing(3000);// 高级选项:// 设置模式为exactly-once (这是默认值)env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1500);// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】env.getCheckpointConfig().setCheckpointTimeout(60000);// 同一时间只允许进行一个检查点env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpointenv.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);env.setParallelism(1);EnvironmentSettings Settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, Settings);tableEnv.getConfig().getConfiguration().setString(FlinSqlConstant.JOB_NAME_KEY,"PgSQLAndMySQL2MySQL");tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);// 数据源表 用户数据String sourceUserDDL = "CREATE TABLE mysql_user_binlog ( " +" id INT NOT NULL, " +" name STRING, " +" class_no STRING, " +" primary key (id) not enforced " +") WITH ( " +" 'connector' = 'mysql-cdc', " +" 'hostname' = '192.168.31.61', " +" 'port' = '3306', " +" 'username' = 'root', " +" 'password' = 'root', " +" 'database-name' = 'flink_sql', " +" 'table-name' = 'user' " +// " , 'scan.startup.mode' = 'latest-offset' " + // 默认全量加增量") ";// 数据源表 班级数据 pgsqlString sourceClassesDDL = "CREATE TABLE postgres_class_binlog ( " +" id INT NOT NULL, " +" class_name STRING, " +" class_no STRING, " +" primary key (id) not enforced " +") WITH ( " +" 'connector' = 'postgres-cdc', " +" 'hostname' = '192.168.31.61', " +" 'port' = '5432', " +" 'username' = 'postgres', " +" 'password' = 'root', " +" 'database-name' = 'flink', " +" 'schema-name' = 'public', " +" 'table-name' = 'classes', " +" 'decoding.plugin.name' = 'pgoutput' " +// " 'debezium.slot.name' = '***' " +// " , 'scan.startup.mode' = 'latest-offset' " + // 默认全量加增量") ";// 输出目标表 聚合用户跟class信息String sinkDDL ="CREATE TABLE user_class_sink ( " +" id INT, " +" name STRING, " +" class_name STRING, " +" primary key (id) not enforced " +") WITH ( " +" 'connector' = 'jdbc', " +" 'driver' = 'com.mysql.cj.jdbc.Driver', " +" 'url' = 'jdbc:mysql://192.168.31.61:3306/flink?serverTimezone=Asia/Shanghai&useSSL=false'," +" 'username' = 'root', " +" 'password' = 'root', " +" 'table-name' = 'user' " +")";// 简单的聚合处理String transformDmlSQL = "insert into user_class_sink select mu.id, mu.name,pc.class_name " +" from mysql_user_binlog as mu left join postgres_class_binlog as pc" +" on mu.class_no = pc.class_no";TableResult tableResult = tableEnv.executeSql(sourceUserDDL);TableResult tableResult1 = tableEnv.executeSql(sourceClassesDDL);TableResult tableResult2 = tableEnv.executeSql(sinkDDL);TableResult tableResult3 = tableEnv.executeSql(transformDmlSQL);}}

若有收获,就点个赞吧
0 人点赞
