注意使用java函数一定要导入相应的类!要不然会报错!对于自定义工具类怎么导入还没有研究
kettle内无论你取出的字段值是为空,还是为null值,若经过JAVA脚本的处理后都会变成NULL 字符串了,java代码中的integer类型无法直接判断,必须用,就算在128字节以内的也判断不了(不会报错) //如果指定的数与参数相等返回0。 //如果指定的数小于参数返回-1。 //如果指定的数大于参数返回1。 Integer1.compareTo(Integer2)
本次测试内容
需要将原来的数据清洗到新的表中!新表中有新的字段需要随机生成数据
流程图
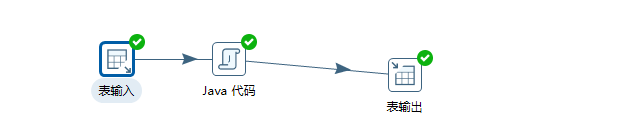
解析
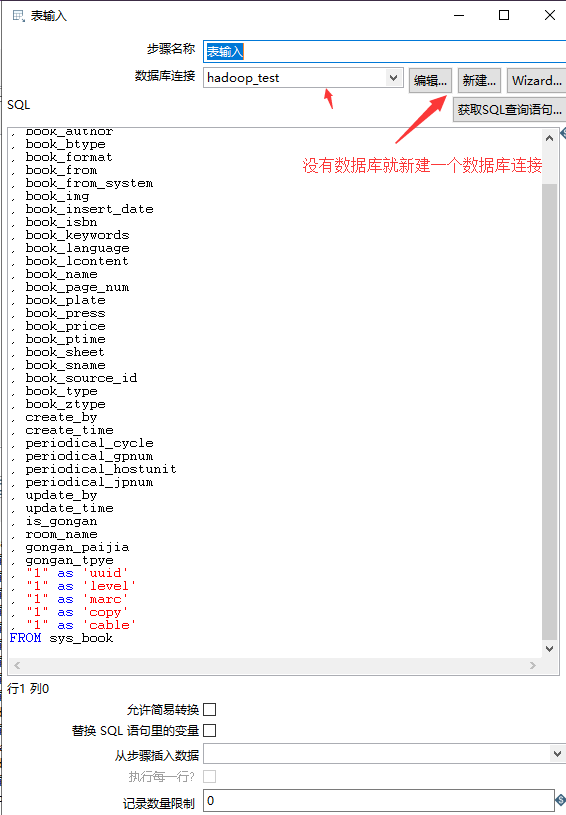
表输入(由于旧数据中没有字段所以 首先现 在sql中虚拟字段)
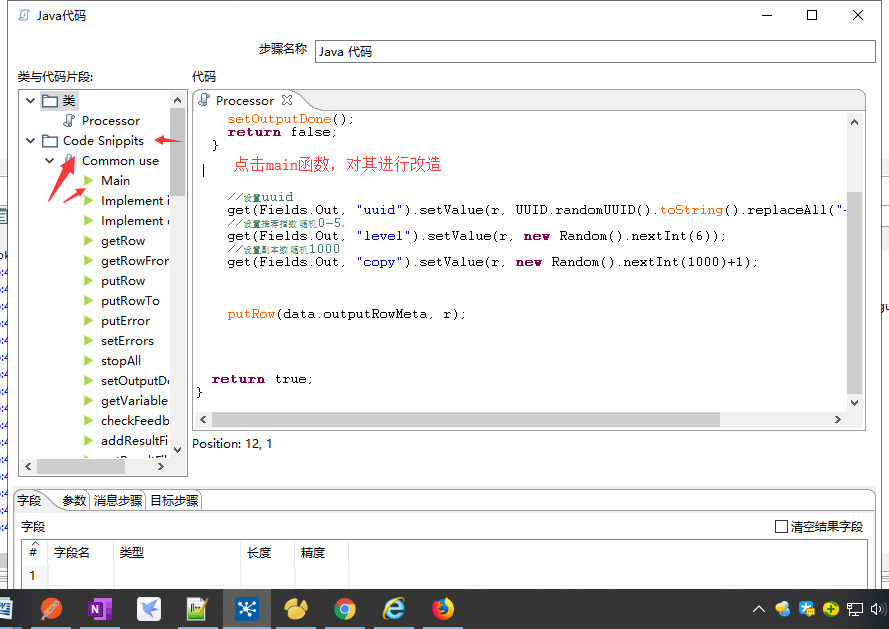
Java 生成随机数据
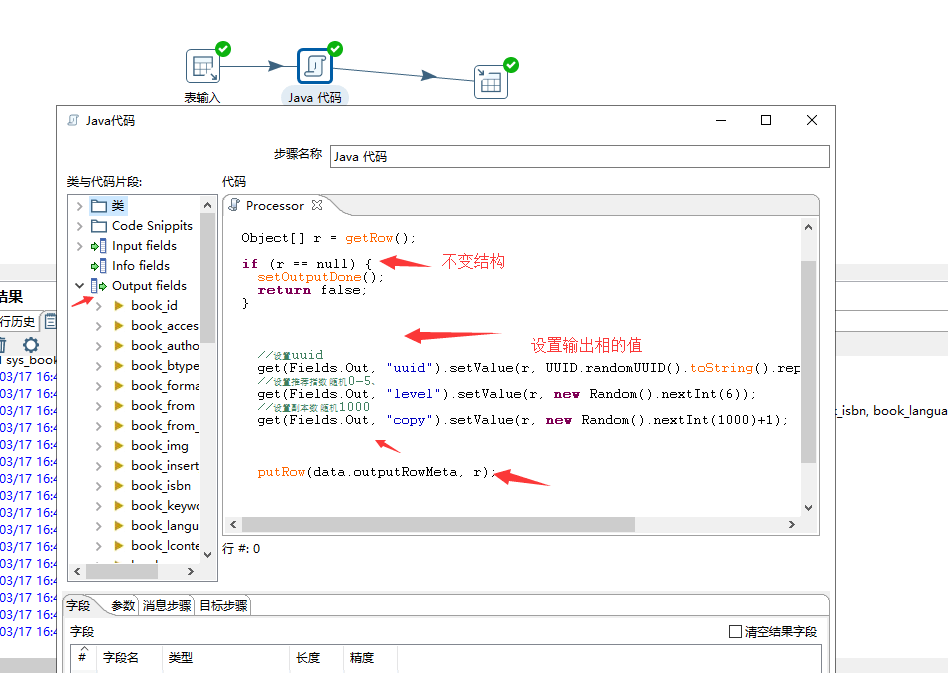
import java.util.*;import java.text.*;import java.util.regex.Pattern;public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {Object[] r = getRow();if (r == null) {setOutputDone();return false;}//如果为空着进行随机添加String book_insert_date = get(Fields.In, "book_insert_date").getString(r);if(book_insert_date==null || book_insert_date==""){String str = "";Date date = new Date();try {str = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(date)+".0";} catch (Exception e) {str="";e.printStackTrace();}get(Fields.Out, "book_insert_date").setValue(r, str);}//设置uuidget(Fields.Out, "uuid").setValue(r, UUID.randomUUID().toString().replaceAll("-", ""));//设置推荐指数 随机0-5、get(Fields.Out, "level").setValue(r, new Random().nextInt(6));//设置副本数 随机1000get(Fields.Out, "copy").setValue(r, new Random().nextInt(1000)+1);//获取中图号 注意sql 判空 这里判断也行String book_ztype = get(Fields.In, "book_ztype").getString(r);String chineseType = book_ztype.substring(0,1);String pattern = "^[a-zA-Z]"; //包含 a-Zif(!Pattern.matches(pattern, chineseType)){ //如果包含a-Z 就强行置为ZchineseType = "Z";}get(Fields.Out, "chineseType").setValue(r,chineseType.toUpperCase());putRow(data.outputRowMeta, r);return true;}
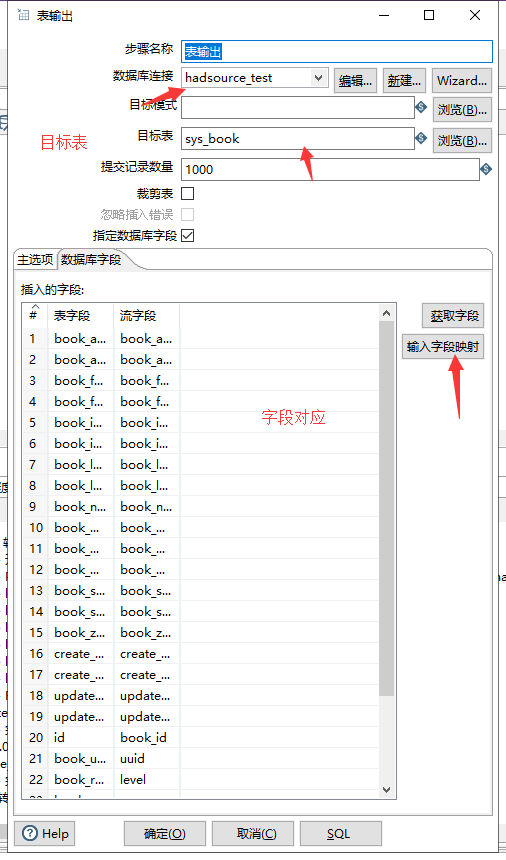
表输出
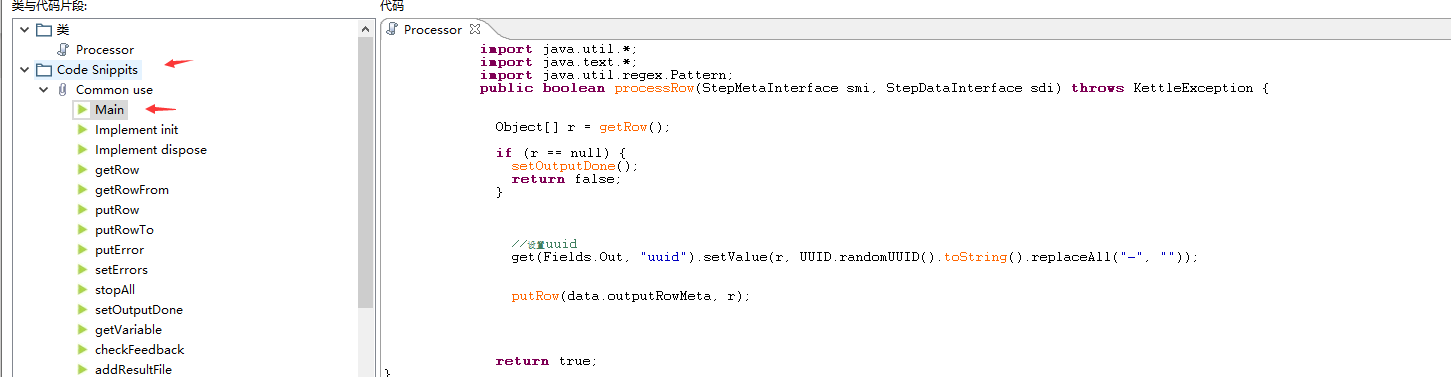
点击mian函数进去java执行主体
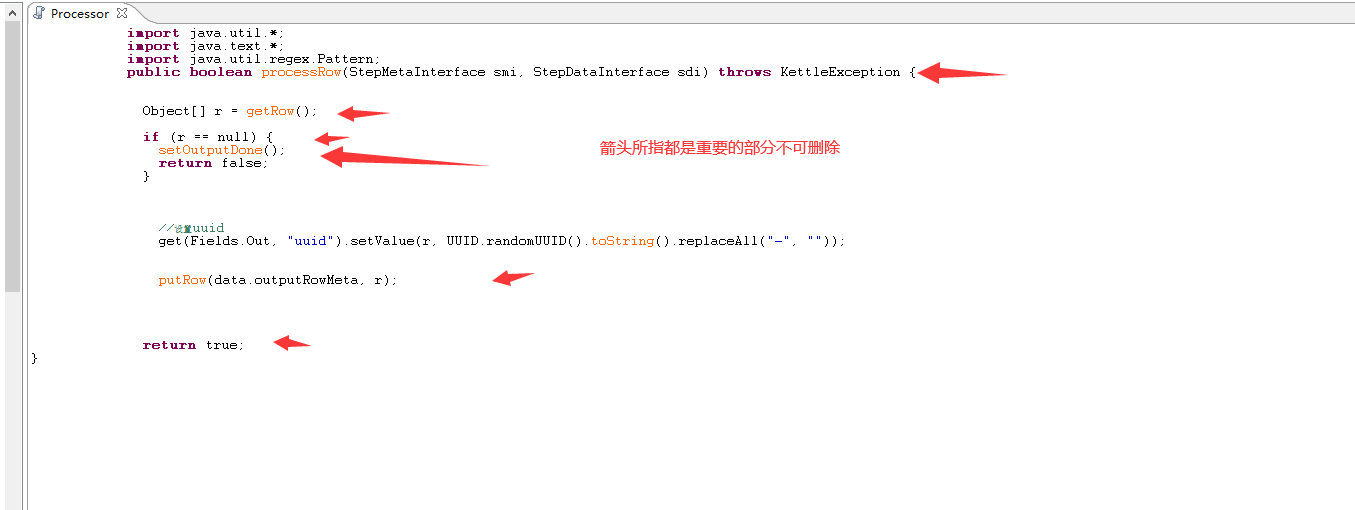
获取输入值对其进行判断等操作
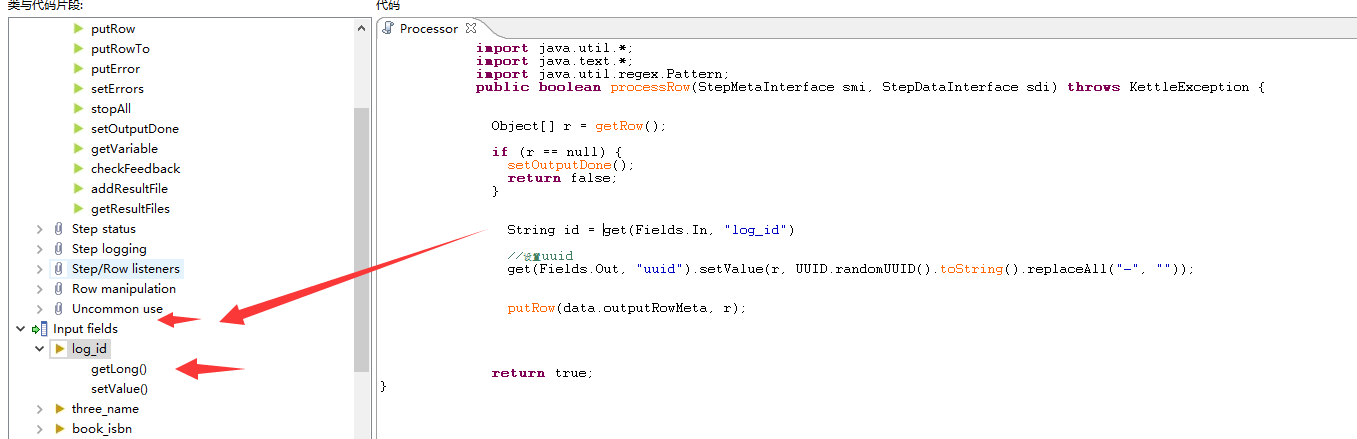
对上面的输入值操作之后输出理想的值

有也可以自定义输出值
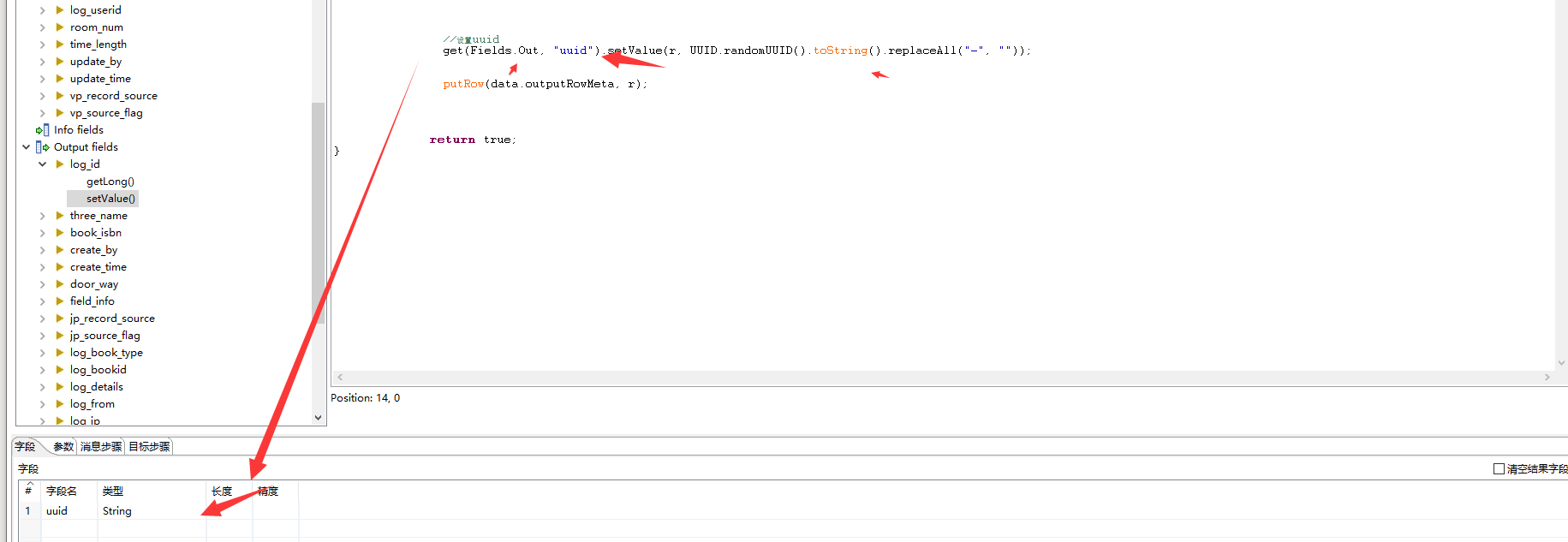
代码参考
<?xml version="1.0" encoding="UTF-8"?><transformation-steps><steps><step><name>Java 代码</name><type>UserDefinedJavaClass</type><description/><distribute>Y</distribute><custom_distribution/><copies>1</copies><partitioning><method>none</method><schema_name/></partitioning><definitions><definition><class_type>TRANSFORM_CLASS</class_type><class_name>Processor</class_name><class_source><![CDATA[import java.util.*;public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {if (first) {first = false;}Object[] r = getRow();if (r == null) {setOutputDone();return false;}// It is always safest to call createOutputRow() to ensure that your output row's Object[] is large// enough to handle any new fields you are creating in this step.r = createOutputRow(r, data.outputRowMeta.size());//设置uuidget(Fields.Out, "uuid").setValue(r, UUID.randomUUID().toString().replaceAll("-", ""));putRow(data.outputRowMeta, r);return true;}]]></class_source></definition></definitions><fields><field><field_name>uuid</field_name><field_type>String</field_type><field_length>-1</field_length><field_precision>-1</field_precision></field></fields><clear_result_fields>N</clear_result_fields><info_steps></info_steps><target_steps></target_steps><usage_parameters></usage_parameters> <cluster_schema/><remotesteps><input></input><output></output></remotesteps><GUI><xloc>400</xloc><yloc>176</yloc><draw>Y</draw></GUI></step><step><name>表输入</name><type>TableInput</type><description/><distribute>Y</distribute><custom_distribution/><copies>1</copies><partitioning><method>none</method><schema_name/></partitioning><connection>mysql5.6_hadoop</connection><sql>SELECTlog_id, three_name, book_isbn, create_by, create_time, door_way, field_info, jp_record_source, jp_source_flag, log_book_type, log_bookid, log_details, log_from, log_ip, log_tableid, log_table_name, log_time, log_type, log_userid, room_num, time_length, update_by, update_time, vp_record_source, vp_source_flagFROM re_logs where log_from="门禁管理系统"</sql><limit>0</limit><lookup/><execute_each_row>N</execute_each_row><variables_active>N</variables_active><lazy_conversion_active>N</lazy_conversion_active><cluster_schema/><remotesteps><input></input><output></output></remotesteps><GUI><xloc>144</xloc><yloc>192</yloc><draw>Y</draw></GUI></step><step><name>表输出</name><type>TableOutput</type><description/><distribute>Y</distribute><custom_distribution/><copies>1</copies><partitioning><method>none</method><schema_name/></partitioning><connection>mysql5.6_hadsource</connection><schema/><table>sys_doorlog</table><commit>1000</commit><truncate>N</truncate><ignore_errors>N</ignore_errors><use_batch>Y</use_batch><specify_fields>Y</specify_fields><partitioning_enabled>N</partitioning_enabled><partitioning_field/><partitioning_daily>N</partitioning_daily><partitioning_monthly>Y</partitioning_monthly><tablename_in_field>N</tablename_in_field><tablename_field/><tablename_in_table>Y</tablename_in_table><return_keys>N</return_keys><return_field/><fields><field><column_name>create_by</column_name><stream_name>create_by</stream_name></field><field><column_name>create_time</column_name><stream_name>create_time</stream_name></field><field><column_name>door_way</column_name><stream_name>door_way</stream_name></field><field><column_name>log_details</column_name><stream_name>log_details</stream_name></field><field><column_name>log_from</column_name><stream_name>log_from</stream_name></field><field><column_name>log_tableid</column_name><stream_name>log_tableid</stream_name></field><field><column_name>log_table_name</column_name><stream_name>log_table_name</stream_name></field><field><column_name>log_time</column_name><stream_name>log_time</stream_name></field><field><column_name>log_type</column_name><stream_name>log_type</stream_name></field><field><column_name>log_userid</column_name><stream_name>log_userid</stream_name></field><field><column_name>update_by</column_name><stream_name>update_by</stream_name></field><field><column_name>update_time</column_name><stream_name>update_time</stream_name></field><field><column_name>uuid</column_name><stream_name>uuid</stream_name></field><field><column_name>id</column_name><stream_name>log_id</stream_name></field><field><column_name>door_aisle_remark</column_name><stream_name>log_ip</stream_name></field></fields><cluster_schema/><remotesteps><input></input><output></output></remotesteps><GUI><xloc>640</xloc><yloc>192</yloc><draw>Y</draw></GUI></step></steps><order><hop><from>Java 代码</from><to>表输出</to><enabled>Y</enabled></hop><hop><from>表输入</from><to>Java 代码</to><enabled>Y</enabled></hop></order><notepads></notepads><step_error_handling></step_error_handling></transformation-steps>
🍔注意
数据结构有变化是需要清除下缓存要不然可能找不到 新的结构字段

若有收获,就点个赞吧
0 人点赞
