在二分类问题中
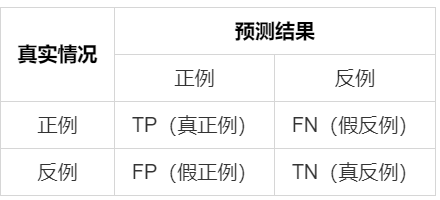
按照模型预测值和真实值可以把测试样本划分为四种情形:真正例(true positive),假正例(false positive),真反例(true negative),假反例(false negative)。可以把结果表示为下图这个矩阵——混淆矩阵(confusion matrix)。
查准率,又称准确率(precision),用于衡量模型避免错误的能力,分母是模型预测的正例数目。
查全率,又称召回率(recall),用于衡量模型避免缺漏的能力,分母是测试样本真正包含的正例数目。
一般来说,这两者是矛盾的,提高其中一者则另一者必然会有所降低。
F1,是查准率和查全率的调和平均,用于综合考虑这两个性能度量。
有时候我们对查准率,查全率的需求是不同的。比方说广告推荐,要尽量避免打扰用户,因此查准率更重要;而逃犯检索,因为漏检的危害很大,所以查全率更重要。这时就需要使用了。
,是查准率和查全率的加权调和平均,用于综合考虑这两个性能度量,并采用不同的权重。
其中 度量了查全率对查准率的相对重要性,等于1时退化为F1,小于1时查准率更重要,大于1时查全率更重要。
书中还介绍了如何对多次训练/测试产生的多个混淆矩阵进行评估,包括宏方法(先分别计算性能度量,再计算均值)和微方法(先对混淆矩阵各元素计算均值,再基于均值计算性能度量)两种途径。
在多个二分类问题中

若有收获,就点个赞吧
0 人点赞
