同样是利用线性模型 %20%3D%20%5Cmathbf%7Bw%7D%5ET%5Cmathbf%7Bx%7D%2Bb#card=math&code=f%28%5Cmathbf%7Bx%7D%29%20%3D%20%5Cmathbf%7Bw%7D%5ET%5Cmathbf%7Bx%7D%2Bb&id=hULeN)
来预测,回归问题希望预测值和真实值 尽可能相近,而不是像分类任务那样,旨在令不同类的预测值可以被划分开。
传统的回归模型计算损失时直接取真实值和预测值的差,支持向量回归(Support Vector Regression,简称SVR)则不然。SVR假设我们能容忍最多有 的偏差,只有当真实值和预测值之间相差超出了
时才计算损失。
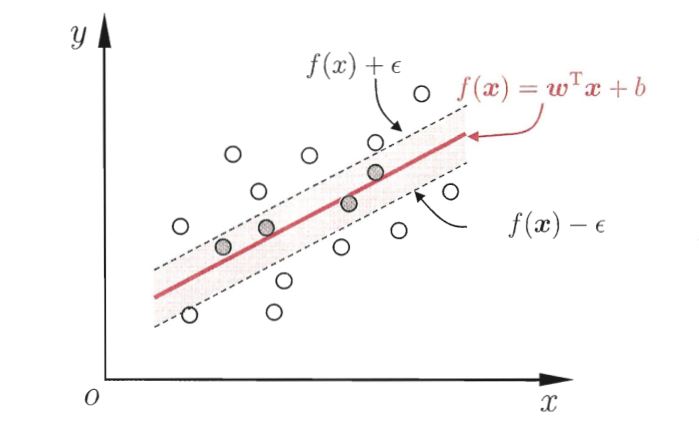
如图所示,以SVR拟合出的直线为中心,两边各构建出一个宽度为 的地带,落在这个宽度为
的间隔带内的点都被认为是预测正确的。
因此,问题可以形式化为目标函数:
%20-%20yi)%20%5Cqquad%20(18)%0A#card=math&code=%5Cmin%7B%5Cmathbf%7Bw%7D%2Cb%7D%20%5Cfrac%7B1%7D%7B2%7D%20%5CVert%20%5Cmathbf%7Bw%7D%20%5CVert%5E2%20%2B%20C%20%5Csum%7Bi%3D1%7D%5Em%20%5Cell%7B%5Cepsilon%7D%28f%28%5Cmathbf%7Bx%7D_i%29%20-%20y_i%29%20%5Cqquad%20%2818%29%0A&id=YiRY3)
其中 为正则化常数,
称为
不敏感损失(
insensitive loss)函数。定义如下:
引入松弛变量 和
,分别表示间隔带两侧的松弛程度,它们可以设定为不同的值。此时,目标函数式(18)可以重写为:
%20%5Cqquad%20(19)%5C%5C%0As.t.%5C%20f(%5Cmathbf%7Bx%7Di)%20-%20y_i%20%5Cleq%20%5Cepsilon%20%2B%20%5Cxi_i%2C%5C%5C%0A%5Cqquad%20%5Cquad%20y_i%20-%20f(%5Cmathbf%7Bx%7D_i)%20%5Cleq%20%5Cepsilon%20%2B%20%5Cxi_i%5C%5C%0A%5Cqquad%20%5Cqquad%20%5Cqquad%20%5Cxi_i%20%5Cgeq%200%2C%20%5Chat%7B%5Cxi%7D_i%20%5Cgeq%200%2C%20i%3D1%2C2%2C…%2Cm.%0A#card=math&code=%5Cmin%7B%5Cmathbf%7Bw%7D%2Cb%7D%20%5Cfrac%7B1%7D%7B2%7D%20%5CVert%20%5Cmathbf%7Bw%7D%20%5CVert%5E2%20%2B%20C%20%5Csum_%7Bi%3D1%7D%5Em%20%28%5Cxi_i%20%2B%20%5Chat%7B%5Cxi%7D_i%29%20%5Cqquad%20%2819%29%5C%5C%0As.t.%5C%20f%28%5Cmathbf%7Bx%7D_i%29%20-%20y_i%20%5Cleq%20%5Cepsilon%20%2B%20%5Cxi_i%2C%5C%5C%0A%5Cqquad%20%5Cquad%20y_i%20-%20f%28%5Cmathbf%7Bx%7D_i%29%20%5Cleq%20%5Cepsilon%20%2B%20%5Cxi_i%5C%5C%0A%5Cqquad%20%5Cqquad%20%5Cqquad%20%5Cxi_i%20%5Cgeq%200%2C%20%5Chat%7B%5Cxi%7D_i%20%5Cgeq%200%2C%20i%3D1%2C2%2C…%2Cm.%0A&id=uuZON)
注意这里有四组 个约束条件,所以对应地有四组拉格朗日乘子。
接下来就是用拉格朗日乘子法获得问题对应的拉格朗日函数,然后求偏导再代回拉格朗日函数,得到对偶问题。然后使用SMO算法求解拉格朗日乘子,最后得到模型。
特别地,SVR中同样有支持向量的概念,解具有稀疏性,所以训练好模型后不需保留所有训练样本。此外,SVR同样可以通过引入核函数来获得拟合非线性分布数据的能力。

若有收获,就点个赞吧
0 人点赞
