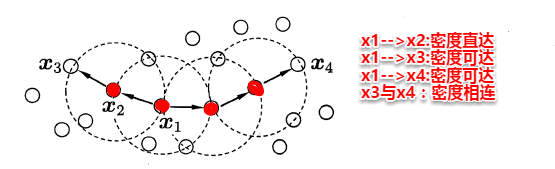
密度聚类则是基于密度的聚类,它从样本分布的角度来考察样本之间的可连接性,并基于可连接性(密度可达)不断拓展疆域(类簇)。其中最著名的便是DBSCAN算法,首先定义以下概念: 简单来理解DBSCAN便是:找出一个核心对象所有密度可达的样本集合形成簇。首先从数据集中任选一个核心对象A,找出所有A密度可达的样本集合,将这些样本形成一个密度相连的类簇,直到所有的核心对象都遍历完。DBSCAN算法的流程如下图所示: