朴素贝叶斯分类器基于属性条件独立性假设,每个属性仅依赖于类别,如上图。但这个假设往往很难成立的,有时候属性之间会存在依赖关系,这时我们就需要对属性条件独立性假设适度地进行放松,适当考虑一部分属性间的相互依赖信息,这就是半朴素贝叶斯分类器(semi-naive Bayes classifier)的基本思想。
独依赖估计(One-Dependent Estimator,简称ODE)是半朴素贝叶斯分类器最常用的一种策略,它假设的是每个属性在类别之外最多仅依赖于一个其他属性。也即:
%20%5Cpropto%20P(c)%20%5Cprod%7Bi%3D1%7D%5E%7Bd%7D%20P(x_i%5C%20%7C%5C%20c%2C%7Bpa%7D_i)%0A#card=math&code=P%28c%5C%20%7C%5C%20%5Cmathbf%7Bx%7D%29%20%5Cpropto%20P%28c%29%20%5Cprod%7Bi%3D1%7D%5E%7Bd%7D%20P%28x_i%5C%20%7C%5C%20c%2C%7Bpa%7D_i%29%0A&id=JlWbB)
其中 是属性
依赖的另一属性,称为
的父属性。若已知父属性,就可以按式(5)来计算了。现在问题转化为如何确定每个属性的父属性?
这里介绍两种产生独依赖分类器的方法:
SPODE
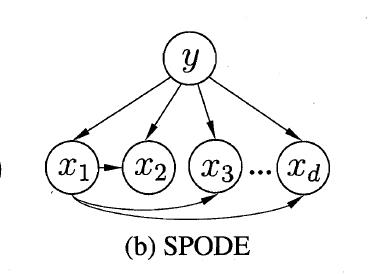
在SPODE(Super-Parent ODE)中,所有属性都依赖于一个共同的属性,称为超父(super-parent),比方说上图中的 。可以通过交叉验证等模型选择方法来确定最合适的超父属性。
TAN
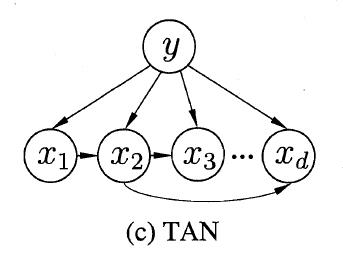
TAN(Tree augmented naive Bayes)则是一种基于最大带权生成树(maximum weighted spanning tree)的方法,包含以下四个步骤:
- 计算任意两个属性间的条件互信息(conditional mutual information):
%20%3D%20%5Csum%7Bx_i%2Cx_j%3B%20c%5Cin%20%5Cmathcal%7BY%7D%7D%20%20P(x_i%2Cx_j%5C%20%7C%5C%20c)%20%5Clog%20%5Cfrac%7B%20P(x_i%2Cx_j%5C%20%7C%5C%20c)%7D%7B%20P(x_i%5C%20%7C%5C%20c)%20P(x_j%5C%20%7C%5C%20c)%7D%0A#card=math&code=I%28x_i%2Cx_j%5C%20%7C%5C%20y%29%20%3D%20%5Csum%7Bx_i%2Cx_j%3B%20c%5Cin%20%5Cmathcal%7BY%7D%7D%20%20P%28x_i%2Cx_j%5C%20%7C%5C%20c%29%20%5Clog%20%5Cfrac%7B%20P%28x_i%2Cx_j%5C%20%7C%5C%20c%29%7D%7B%20P%28x_i%5C%20%7C%5C%20c%29%20P%28x_j%5C%20%7C%5C%20c%29%7D%0A&id=m0MgX)
- 以属性为节点构建完全图,每条边的权重为对应的条件户信息。
- 构建此完全图的最大带权生成树。选一个节点作为根节点,把边转换为有向边。
- 加入类别节点
,并增加从
到每个属性的有向边。
AODE
特别地,有一种更为强大的独依赖分类器——AODE(Average One-Dependent Estimator),它基于集成学习机制。无须通过模型选择来确定超父属性,而是尝试将每个属性都作为超父属性来构建模型,然后把有足够训练数据支撑的SPODE模型集成起来导出最终结果。
类似于朴素贝叶斯分类器,AODE无需进行模型选择,既可以通过预计算来节省预测时间,又可以采取懒惰学习,需要预测时再进行计数,并且可以容易地实现增量学习。
高阶依赖
ODE假设每个属性最多依赖类别以外的另一属性,但如果我们继续放宽条件,允许属性最多依赖类别以外的 k 个其他属性,也即考虑属性间的高阶依赖,那就得到了 kDE。
是不是考虑了高阶依赖就一定能带来性能提升呢?并不是这样的。随着 k 的增加,要准确估计条件概率 #card=math&code=P%28x_i%5C%20%7C%5C%20c%2C%5Cmathbf%7Bpa%7D_i%29&id=CGUhK) 所需的训练样本会呈指数上升。如果训练样本不够,很容易陷入高阶联合概率的泥沼;但如果训练样本非常充足,那就有可能带来泛化性能的提升。

若有收获,就点个赞吧
0 人点赞
