感知机
感知机(Perceptron)仅由两层神经元组成,如下图:
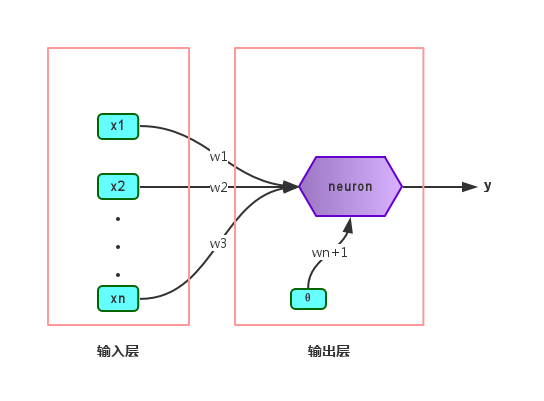
两层是指输入层和输出层,但只有输出层是M-P神经元,也即只有一层功能神经元(functional neuron)。输入层只负责把每一个样本的各个属性传递给输出层(输入层的神经元数量等于样本的属性数目),不进行函数处理。其实说白了这个模型跟逻辑回归是一样的,不过按我的理解就是感知机的输出层可以有多个神经元,产生多个输出。而且线性模型中偏置项是和属性一起加权求和的,但神经网络中则是求属性加权和和预测的差。
有时候阈值 可以看作一个输入固定为
的哑结点(dummy node),连接权为
。这样就可以把权重和阈值的学习统一为权重的学习了。更新权重的方式如下:
%20x_i%0A#card=math&code=%5CDelta%20%20w_i%3D%20%5Ceta%20%28y%20-%20%5Chat%7By%7D%29%20x_i%0A&id=gXpPh)
其中, 称为学习率(learning rate),取值范围是 (0,1)。感知机是逐个数据点输入来更新的。设定初始的权重后,逐个点输入,如果没有预测错就继续检验下一个点;如果预测错了就更新权重,然后重新开始逐个点检验,直到所有点都预测正确了就停止更新(所以这其实是一种最小化经验误差的方法)。
已经证明了,若两类模式是线性可分(linearly separable)的,即存在一个线性超平面能将它们分开。比如二维平面上可以用一条直线完全分隔开两个类别的点。由于感知机只有一层功能神经元,所以学习能力极其有限,只能处理线性可分问题。对于这类问题,感知机的学习过程必然收敛(converge)而求出适当的权向量;对于线性不可分问题,感知机的学习过程会发生振荡(fluctuation),难以稳定下来。
多层网络
使用多层的功能神经元可以解决线性不可分问题,比方说两层(功能神经元)的感知机就可以解决异或问题(在二维平面中需要使用两条直线才能分隔开)。在输入层和输出层之间的层称为隐层或者隐含层(hidden layer),隐含层的神经元也是功能神经元。
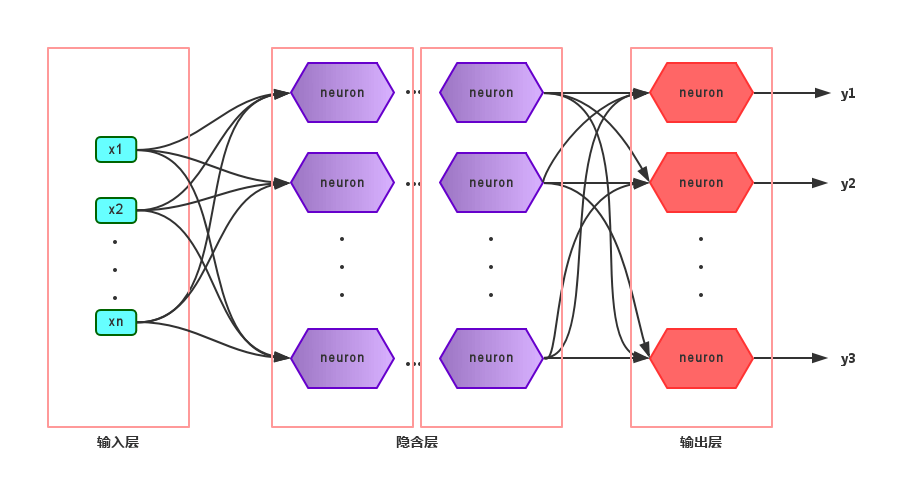
上图展示的最为常见的多层神经网络——多层前馈神经网络(multi-layer feedforward neural networks),它有以下特点:
- 每层神经元与下一层神经元全互连
- 神经元之间不存在同层连接
- 神经元之间不存在跨层连接
因为说两层网络时容易有歧义(只包含输入层输出层?还是包含两层功能神经元?),所以一般称包含一个隐含层的神经网络为单隐层网络。只要包含隐层,就可以称为多层网络。神经网络的学习其实就是调整各神经元之间的连接权(connection weight)以及各神经元的阈值,也即是说,神经网络学到的东西都蕴含在连接权和阈值中了。

若有收获,就点个赞吧
0 人点赞
