决策树(decision tree)是一种模仿人类决策的学习方法。
一棵决策树可以分成三个部分:叶节点,非叶节点,分支。叶节点对应决策结果,也即分类任务中的类别标记;非叶节点(包括根节点)对应一个判定问题(某属性=?);分支对应父节点判定问题的不同答案(可能的属性值),可能连向一个非叶节点的子节点,也可能连向叶节点。
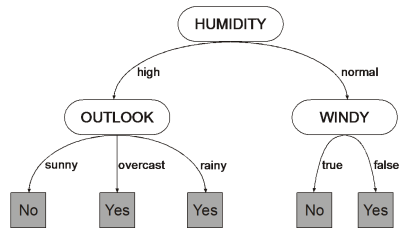
决策就是从根节点开始走到叶节点的过程。每经过一个节点的判定,数据集就按照答案(属性值)划分为若干子集,在子节点做判定时只需要考虑对应的数据子集就可以了。
决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。
决策树生成是一个递归过程:
生成算法:
- 传入训练集和属性集
- 生成一个新节点
- 若此时数据集中所有样本都属于同一类,则把新节点设置为该类的叶节点,然后返回
。
- 若此时属性集为空,或者数据集中所有样本在属性集余下的所有属性上取值都相同,无法进一步划分,则把新节点设置为叶节点,类标记为数据集中样本数最多的类,然后返回
从属性集中选择一个最优划分属性
- 为该属性的每个属性值生成一个分支,并按属性值划分出子数据集
- 若分支对应的子数据集为空,无法进一步划分,则直接把子节点设置为叶节点,类标记为父节点数据集中样本数最多的类,然后返回
- 将子数据集和去掉了划分属性的子属性集作为算法的传入参数,继续生成该分支的子决策树。
稍微注意以下,3处返回中的第2处和第3处设置叶节点的类标记原理有所不同。第2处将类标记设置为当前节点对应为数据集中样本数最多的类,这是利用当前节点的后验分布;第3处将类标记设置为为父节点数据集中样本数最多的类,这是把父节点的样本分布作为当前节点的先验分布。

若有收获,就点个赞吧
0 人点赞
