1.Logstash架构介绍
1.1 为什么需要Logstash
对于部分生产上的日志无法像 Nginx 那样,可以直接将输出的日志转为 Json 格式,但是可以借助 Logstash 来将我们的 “非结构化数据”,转为 “结构化数据”;
1.2 什么是Logstash
Logstash 是开源的数据处理管道,能够同时从多个源采集数据,转换数据,然后输出数据。 官网传送门
1.3 Logstash架构介绍
Logstash的基础架构类似于pipeline流水线,如下图所示:
Input: #数据采集(常用插件:stdin、file、kafka、beat、http、)Filter:#数据解析/转换(常用插件:grok、date、geoip、mutate、useragent)Output:#数据输出 (常用插件:Elasticsearch、)
2.Logstash Input插件
input插件用于指定输入源,一个pipeline可以有多个input插件,我们主要围绕下面几个input插件进行介绍;stdin
- file
- beat
-
2.1 stdin插件
从标准输入读取数据,从标准输出中输出内容;
[root@oldxu-logstash-node1-172 ~]# cat /etc/logstash/conf.d/stdin_logstash.confinput {stdin {type => "stdin" #自定义事件类型,可用于后续判断tags => "stdin_type" #自定义事件tag,可用于后续判断}}output {stdout {codec => "rubydebug"}}
执行测试
# echo "oldxu" | /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/stdin_logstash.conf
返回结果
{ "@version" => "1", "message" => "oldxu", "@timestamp" => 2019-12-30T02:39:03.270Z, "tags" => [ [0] "stdin_type" ], "type" => "stdin", "host" => "oldxu-logstash-node1-172.16.1.151.novalocal" }2.2 file插件
从
file文件中读取数据,然后输入至标准输入;[root@oldxu-logstash-node1-172 ~]# cat /etc/logstash/conf.d/file_logstash.conf input { file { path => "/var/log/oldxu.log" type => syslog exclude => "*.gz" #不想监听的文件规则,基于glob匹配语法 start_position => "beginning" #第一次丛头开始读取文件 beginning or end stat_interval => "3" #定时检查文件是否更新,默认1s } } output { stdout { codec => rubydebug } }执行测试
# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/file_logstash.conf由于内容过多,摘选部分返回结果
{ "@timestamp" => 2019-12-30T03:09:33.127Z, "type" => "syslog", "message" => "Nov 24 14:52:44 oldxu-logstash-node1-172 filebeat: 2019-11-24T14:52:44.645+0800#011INFO#011[monitoring]#011log/log.go:145#011Non-zero metrics in the last 30s#011{\"monitoring\": {\"metrics\": {\"beat\":{\"cpu\":{\"system\":{\"ticks\":6810,\"time\":{\"ms\":3}},\"total\":{\"ticks\":16300,\"time\":{\"ms\":6},\"value\":16300},\"user\":{\"ticks\":9490,\"time\":{\"ms\":3}}},\"handles\":{\"limit\":{\"hard\":4096,\"soft\":1024},\"open\":7},\"info\":{\"ephemeral_id\":\"017e513e-6264-461f-9397-35f44fd61c7b\",\"uptime\":{\"ms\":60510082}},\"memstats\":{\"gc_next\":7229904,\"memory_alloc\":4269800,\"memory_total\":657143752},\"runtime\":{\"goroutines\":27}},\"filebeat\":{\"events\":{\"added\":1,\"done\":1},\"harvester\":{\"open_files\":1,\"running\":1}},\"libbeat\":{\"config\":{\"module\":{\"running\":0}},\"pipeline\":{\"clients\":1,\"events\":{\"active\":0,\"filtered\":1,\"total\":1}}},\"registrar\":{\"states\":{\"current\":1,\"update\":1},\"writes\":{\"success\":1,\"total\":1}},\"system\":{\"load\":{\"1\":0,\"15\":0.05,\"5\":0.01,\"norm\":{\"1\":0,\"15\":0.05,\"5\":0.01}}}}}}", "host" => "oldxu-logstash-node1-172.16.1.151.novalocal", "path" => "/var/log/oldxu.log", "@version" => "1" }2.3 beats插件
从filebeat文件中读取数据,然后输入至标准输入;
[root@oldxu-logstash-node1-172 ~]# cat /etc/logstash/conf.d/beats_logstash.conf input { beats { port => 5044 } } output { stdout { codec => rubydebug } }2.3 kafka插件
从kafka文件中读取数据,然后输入至标准输入;
input { kafka { zk_connect => "kafka1:2181,kafka2:2181,kafka3:2181" group_id => "logstash" topic_id => "apache_logs" consumer_threads => 16 } }3.Logstash Filter插件
数据从源传输到存储的过程中,
Logstash的filter过滤器能够解析各个事件,识别已命名的字段结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值;利用
Grok从非结构化数据中派生出结构- 利用
geoip从IP地址分析出地理坐标 - 利用
useragent从 请求中分析操作系统、设备类型 -
3.1 Grok插件
1.grok是如何出现?
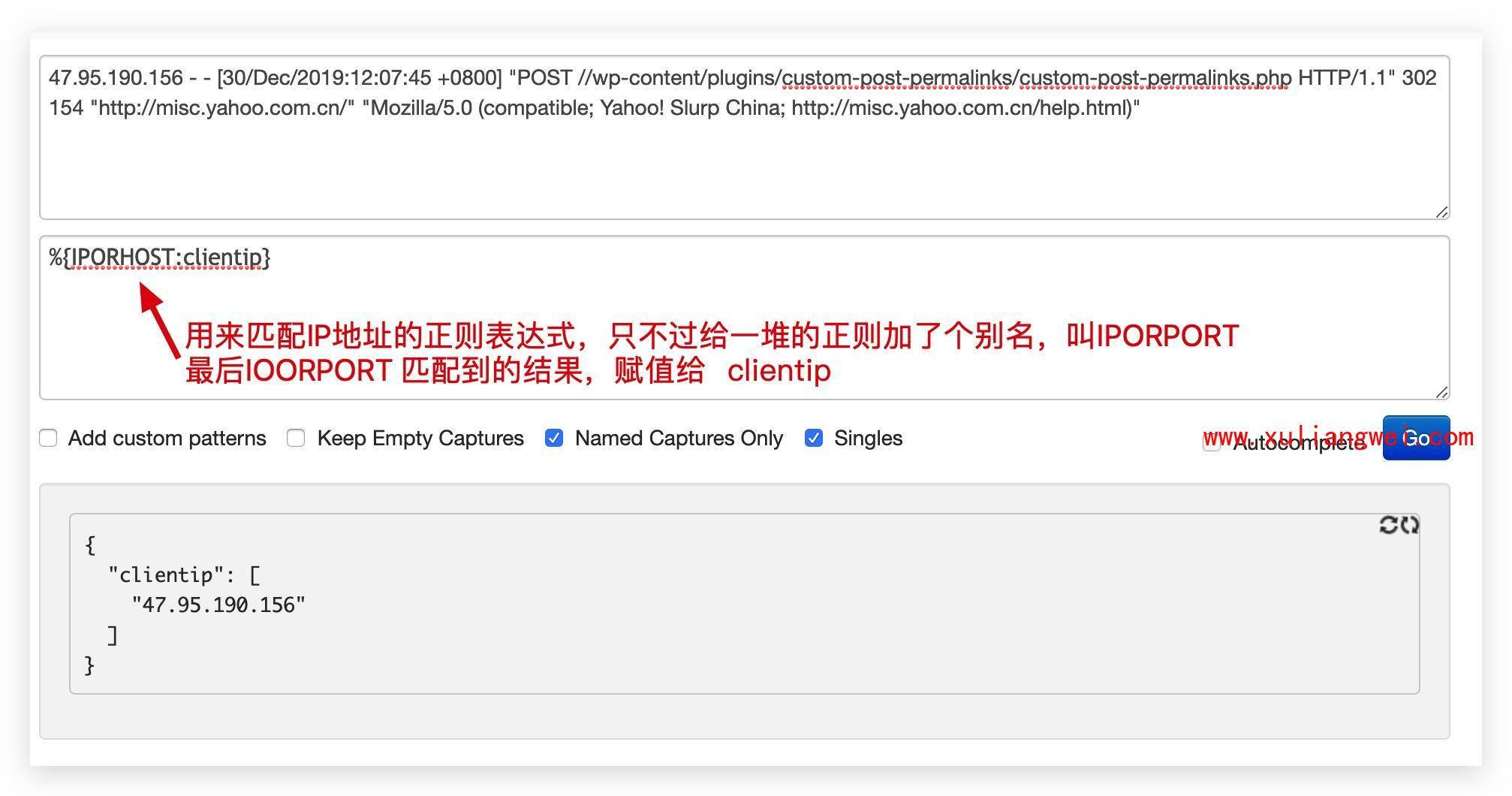
# 我们希望将如下非结构化的数据解析成json结构化数据格式 120.27.74.166 - - [30/Dec/2019:11:59:18 +0800] "GET / HTTP/1.1" 302 154 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) Chrome/79.0.3945.88 Safari/537.36" # 需要使用非常复杂的正则表达式 \[([^]]+)]\s\[(\w+)]\s([^:]+:\s\w+\s\w+\s[^:]+:\S+\s[^:]+: \S+\s\S+).*\[([^]]+)]\s\[(\w+)]\s([^:]+:\s\w+\s\w+\s[^:]+: \S+\s[^:]+:\S+\s\S+).*\[([^]]+)]\s\[(\w+)]\s([^:]+:\s\w+ \s\w+\s[^:]+:\S+\s[^:]+:\S+\s\S+).*2.grok如何解决该问题呢? grok其实是带有名字的正则表达式集合。 grok 内置了很多pattern可以直接使用。
grok语法生成器%{IPORHOST:clientip} %{NGUSER:ident} %{NGUSER:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response} (?:%{NUMBER:bytes}|-) (?:"(?:%{URI:referrer}|-)"|%{QS:referrer}) %{QS:agent} %{QS:xforwardedfor} %{IPORHOST:host} %{BASE10NUM:request_duration}3.1.1 grok示例
grok示例:使用 grok pattern 将 Nginx 日志格式化为 json 格式;
[root@oldxu-logstash-node1-172 ~]# cat /etc/logstash/conf.d/grok_logstash.conf input { http { port =>7474 } } filter { #将nginx日志格式化为json格式 grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } } output { stdout { codec => rubydebug } }
3.1.2 grok结果
{
"timestamp" => "30/Dec/2019:11:55:59 +0800",
"ident" => "-",
"headers" => {
"request_path" => "/",
"content_length" => "178",
"http_host" => "172.16.1.151:7474",
"http_accept" => "*/*",
"http_version" => "HTTP/1.1",
"http_user_agent" => "insomnia/7.0.6",
"request_method" => "POST"
},
"request" => "/feed",
"@timestamp" => 2019-12-30T06:49:35.468Z,
"response" => "302",
"httpversion" => "1.1",
"bytes" => "154",
"verb" => "GET",
"@version" => "1",
"referrer" => "\"-\"",
"message" => "47.95.190.158 - - [30/Dec/2019:11:55:59 +0800] \"GET /feed HTTP/1.1\" 302 154 \"-\" \"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Thunderbird/60.9.1 Lightning/6.2.9.1\"",
"auth" => "-",
"agent" => "\"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Thunderbird/60.9.1 Lightning/6.2.9.1\"",
"host" => "172.16.1.1",
"clientip" => "47.95.190.158"
}
3.2 geoip插件 ✨
geoip 插件:根据 ip 地址提供的对应地域信息,比如经纬度、城市名等、方便进行地理数据分析;
3.2.1 geoip示例
geoip示例:通过 geoip 提取 Nginx 日志中 clientip 字段,并获取地域信息;
[root@oldxu-logstash-node1-172 ~]# cat /etc/logstash/conf.d/geoip_logstash.conf
input {
http {
port =>7474
}
}
filter {
...
#提取clientip字段,获取地域信息
geoip {
source => "clientip"
}
...
}
output {
stdout {
codec => rubydebug
}
}
3.2.2 geoip结果
对服务器发送
POST请求,提供一个公网ip地址;{ "timestamp" => "30/Dec/2019:11:55:59 +0800", "ident" => "-", "headers" => { "request_path" => "/", "content_length" => "178", "http_host" => "172.16.1.151:7474", "http_accept" => "*/*", "http_version" => "HTTP/1.1", "http_user_agent" => "insomnia/7.0.6", "request_method" => "POST" }, "request" => "/feed", "@timestamp" => 2019-12-30T06:50:36.929Z, "response" => "302", "httpversion" => "1.1", "bytes" => "154", "verb" => "GET", "@version" => "1", "referrer" => "\"-\"", "message" => "47.95.190.158 - - [30/Dec/2019:11:55:59 +0800] \"GET /feed HTTP/1.1\" 302 154 \"-\" \"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Thunderbird/60.9.1 Lightning/6.2.9.1\"", "auth" => "-", "agent" => "\"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Thunderbird/60.9.1 Lightning/6.2.9.1\"", "geoip" => { #重点看这块 "country_code3" => "CN", "ip" => "47.95.190.158", "country_name" => "China", "country_code2" => "CN", "timezone" => "Asia/Shanghai", "latitude" => 30.294, "continent_code" => "AS", "region_code" => "ZJ", "city_name" => "Hangzhou", "region_name" => "Zhejiang", "longitude" => 120.1619, "location" => { "lat" => 30.294, "lon" => 120.1619 } }, "host" => "172.16.1.1", "clientip" => "47.95.190.158" }3.2.3 fields字段
由于输出内容太多,可以通过
fileds选项选择自己需要的信息;[root@oldxu-logstash-node1-172 ~]# cat /etc/logstash/conf.d/geoip_logstash.conf input { http { port =>7474 } } filter { ... # 提取clientip字段,获取地域信息 geoip { source => "clientip" fields => ["country_name","country_code2","timezone","longitude","latitude","continent_code"] # 仅提取需要获取的指标 } ... } output { stdout { codec => rubydebug } }3.3 Date插件
date插件:将日期字符串解析为日志类型。然后替换@timestamp字段或指定的其他字段。timezone时间
date示例,将 nginx 请求中的 timestamp 日志进行解析;
[root@oldxu-logstash-node1-172 ~]# cat /etc/logstash/conf.d/date_logstash.conf input { http { port =>7474 } } filter { ... #解析date日期 30/Dec/2019:11:40:44 +0800 date { match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ] target => "nginx_date" timezone => "Asia/Shanghai" } } output { stdout { codec => rubydebug } }3.3.2 date结果
{ "timestamp" => "30/Dec/2019:11:40:44 +0800", #解析前的格式 "ident" => "-", "headers" => { "request_path" => "/", "content_length" => "194", "http_host" => "172.16.1.151:7474", "http_accept" => "*/*", "http_version" => "HTTP/1.1", "http_user_agent" => "insomnia/7.0.6", "request_method" => "POST" }, "request" => "/", "@timestamp" => 2019-12-30T07:56:57.993Z, "response" => "302", "httpversion" => "1.1", "bytes" => "154", "verb" => "GET", "@version" => "1", "referrer" => "\"-\"", "nginx_date" => 2019-12-30T03:40:44.000Z, #解析后的格式 "message" => "123.156.198.183 - - [30/Dec/2019:11:40:44 +0800] \"GET / HTTP/1.1\" 302 154 \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36\"", "auth" => "-", "agent" => "\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36\"", "geoip" => { "country_name" => "China", "country_code2" => "CN", "timezone" => "Asia/Shanghai", "longitude" => 119.6442, "latitude" => 29.1068, "continent_code" => "AS" }, "host" => "172.16.1.1", "clientip" => "123.156.198.183" }3.4 useragent插件
useragent插件:根据请求中的user-agent字段,解析出浏览器设备、操作系统等信息;3.4.1 useragent示例
[root@oldxu-logstash-node1-172 ~]# cat /etc/logstash/conf.d/useragent_logstash.conf input { http { port =>7474 } } filter { ... #提取agent字段,进行解析 useragent { source => "agent" #指定丛哪个字段获取数据解析 target => "useragent" #转换后的新字段 } } output { stdout { codec => rubydebug } }3.4.2 useragent结果
{ "timestamp" => "30/Dec/2019:11:40:44 +0800", "ident" => "-", "headers" => { "request_path" => "/", "content_length" => "194", "http_host" => "172.16.1.151:7474", "http_accept" => "*/*", "http_version" => "HTTP/1.1", "http_user_agent" => "insomnia/7.0.6", "request_method" => "POST" }, "request" => "/", "@timestamp" => 2019-12-30T08:02:45.996Z, "response" => "302", "httpversion" => "1.1", "bytes" => "154", "verb" => "GET", "@version" => "1", "referrer" => "\"-\"", "nginx_date" => 2019-12-30T03:40:44.000Z, "message" => "123.156.198.183 - - [30/Dec/2019:11:40:44 +0800] \"GET / HTTP/1.1\" 302 154 \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36\"", "auth" => "-", "agent" => "\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36\"", "geoip" => { "country_name" => "China", "country_code2" => "CN", "timezone" => "Asia/Shanghai", "longitude" => 119.6442, "latitude" => 29.1068, "continent_code" => "AS" }, "host" => "172.16.1.1", "clientip" => "123.156.198.183", "useragent" => { #新字段 "major" => "71", "minor" => "0", "os_name" => "Windows", "device" => "Other", "name" => "Chrome", "build" => "", "os" => "Windows", "patch" => "3578" } }3.5 mutate 插件
mutate主要是对字段进行、类型转换、删除、替换、更新等操作;mutate删除无用字段,比如:headers、message、agent[root@oldxu-logstash-node1-172 conf.d]# cat mutate_logstash.conf input { http { port =>7474 } } filter { ... #mutate 删除操作 mutate { remove_field => ["headers", "message", "agent"] } ... } output { stdout { codec => rubydebug } }结果返回,整个数据返回的结果清爽了很多
{ "timestamp" => "30/Dec/2019:11:40:44 +0800", "ident" => "-", "request" => "/", "@timestamp" => 2019-12-30T09:05:02.051Z, "response" => "302", "httpversion" => "1.1", "bytes" => "154", "verb" => "GET", "@version" => "1", "referrer" => "\"-\"", "nginx_date" => 2019-12-30T03:40:44.000Z, "useragent" => { "major" => "71", "minor" => "0", "os_name" => "Windows", "device" => "Other", "name" => "Chrome", "build" => "", "os" => "Windows", "patch" => "3578" }, "auth" => "-", "geoip" => { "country_name" => "China", "country_code2" => "CN", "timezone" => "Asia/Shanghai", "longitude" => 119.6442, "latitude" => 29.1068, "continent_code" => "AS" }, "host" => "172.16.1.1", "clientip" => "123.156.198.183" }3.5.2 split
mutate中的split字符切割, 指定 | 为字段分隔符。测试数据:5607|提交订单|2020-08-31[root@oldxu-logstash-node1-172 conf.d]# cat mutate_logstash.conf input { http { port =>7474 } } filter { mutate { #字段分隔符 split => { "message" => "|" } } } output { stdout { codec => rubydebug } }结果返回
{ "host" => "172.16.1.1", "message" => [ [0] "5607", [1] "提交订单", [2] "2020-08-31" ], "@timestamp" => 2019-12-30T09:29:24.170Z, "@version" => "1", "headers" => { "request_path" => "/", "content_length" => "21", "http_host" => "172.16.1.151:7474", "http_accept" => "*/*", "http_version" => "HTTP/1.1", "http_user_agent" => "insomnia/7.0.6", "request_method" => "POST" } }3.5.3 add_field
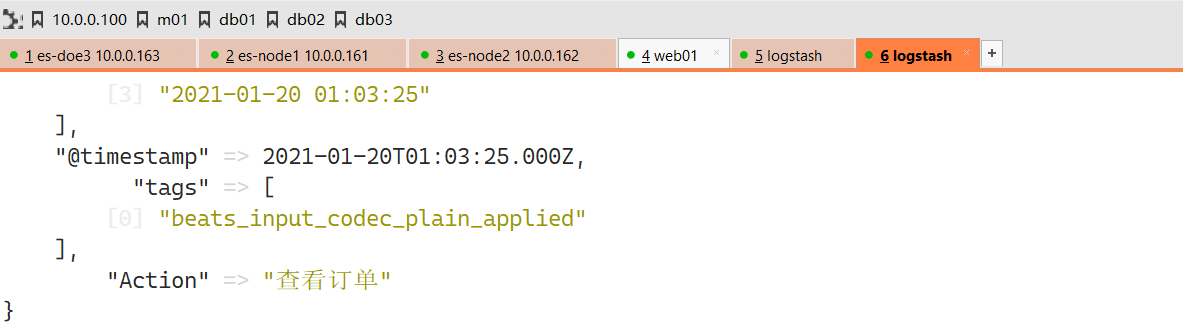
mutate中add_field,可以将分割后的数据创建出新的字段名称。便于以后的统计和分析;[root@oldxu-logstash-node1-172 conf.d]# cat mutate_3_logstash.conf input { http { port =>7474 } } filter { mutate { #字段分隔符 split => { "message" => "|" } #将分割后的字段添加到指定的字段名称 add_field => { "UserID" => "%{[message][0]}" "Action" => "%{[message][1]}" "Date" => "%{[message][2]}" } } } output { stdout { codec => rubydebug } }3.5.4 convert
mutate中的convert类型转换。 支持转换integer、float、string等类型;[root@oldxu-logstash-node1-172 conf.d]# cat mutate_4_logstash.conf input { http { port =>7474 } } filter { mutate { #字段分隔符 split => { "message" => "|" } #将分割后的字段添加到指定的字段名称 add_field => { "UserID" => "%{[message][0]}" "Action" => "%{[message][1]}" "Date" => "%{[message][2]}" } #对新添加字段进行格式转换 convert => { "UserID" => "integer" "Action" => "string" "Date" => "string" } #移除无用的字段 remove_field => ["headers", "message"] } } output { stdout { codec => rubydebug } }最终返回结果如下
{ "host" => "172.16.1.1", "@version" => "1", "UserID" => "5608", "@timestamp" => 2019-12-30T10:16:40.709Z, "Action" => "提交订单", "Date" => "2019-12-10" }4.Logstash Output插件
负责将Logstash Event输出,常见的插件如下:
stdout
- file
-
4.1 stdout插件
stdout插件将数据输出到屏幕终端,便于调试;output { stdout { codec => rubydebug } }4.2 file插件
输出到文件,实现将分散在多地的文件统一到一处:
比如将所有
web机器的web日志收集到一个文件中,从而方便查阅信息;output { file { path => "/var/log/web.log" } }4.3 elastic插件
输出到
elasticsearch,是最常用的输出插件;output { elasticsearch { hosts => ["172.16.1.162:9200","172.16.1.163:9200"] #一般写data地址 index => "nginx-%{+YYYY.MM.dd}" #索引名称 template_overwrite => true #覆盖索引模板 } }
09 Logstash分析App业务日志
1.APP日志概述
应用APP日志,主要是用来记录用户的操作
[INFO] 2019-12-28 04:53:36 [cn.oldxu.dashboard.Main] - DAU|8329|领取优惠券|2019-12-28 03:18:31
[INFO] 2019-12-28 04:53:40 [cn.oldxu.dashboard.Main] - DAU|131|评论商品|2019-12-28 03:06:27
APP在生产是真实的系统,目前仅仅是为了学习日志收集、分析、展示,所以就模拟一些用户数据。
2.APP日志架构
实现思路:
1.首先通过Filebeat读取日志文件中的内容,并且将内容发送给Logstash。
2.Logstash接收到内容后,将数据转换为结构化数据。然后输出给Elasticsearch
3.Kibana添加Elasticsearch索引,读取数据,然后在Kibana中进行分析,最后进行展示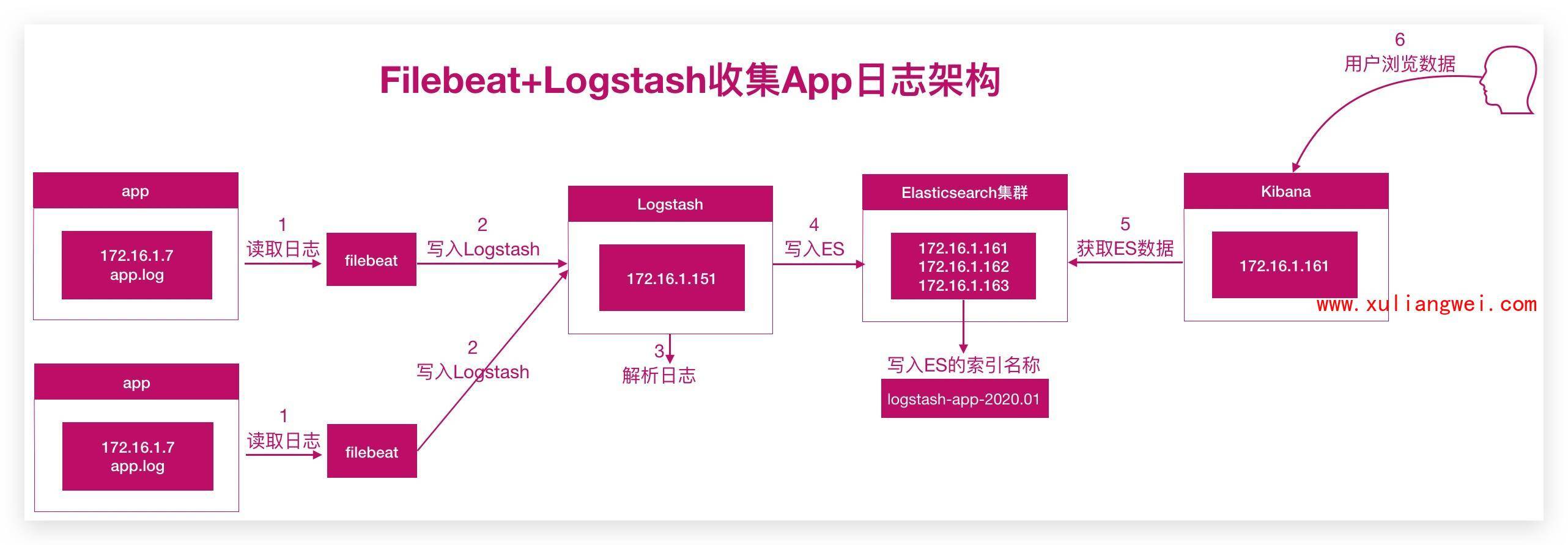
3.App日志实践
1.启动app程序产生日志 app程序传送门 、 app日志传送门
[root@web01 ~]# java -jar app-dashboard-1.0-SNAPSHOT.jar
_2.filebeat配置如下
[root@web01 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/app.log
output.logstash:
hosts: ["172.16.1.151:5044"]
重启filebeat
_3.logstash配置如下
[root@logstash-node1 conf.d]# cat app_filter_logstash.conf
input {
beats {
port => 5044
}
}
filter {
mutate {
split => { "message" => "|" }
add_field => {
"UserID" => "%{[message][1]}"
"Action" => "%{[message][2]}"
"Date" => "%{[message][3]}"
"[@metadata][target_index]" => "app-logstash-%{+YYYY.MM.dd}"
}
convert => {
"UserID" => "integer"
"Action" => "string"
"Date" => "string"
}
remove_field => ["message","headers"]
}
date {
#2020-08-28 01:05:02
match => ["Date", "yyyy-MM-dd HH:mm:ss"]
target => "@timestamp"
timezone => "UTC"
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
index => "%{[@metadata][target_index]}"
}
}
前台查看:/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/app_logstash.conf -r
测试完毕后
#调优配置
#后台启动
4.APP日志分析
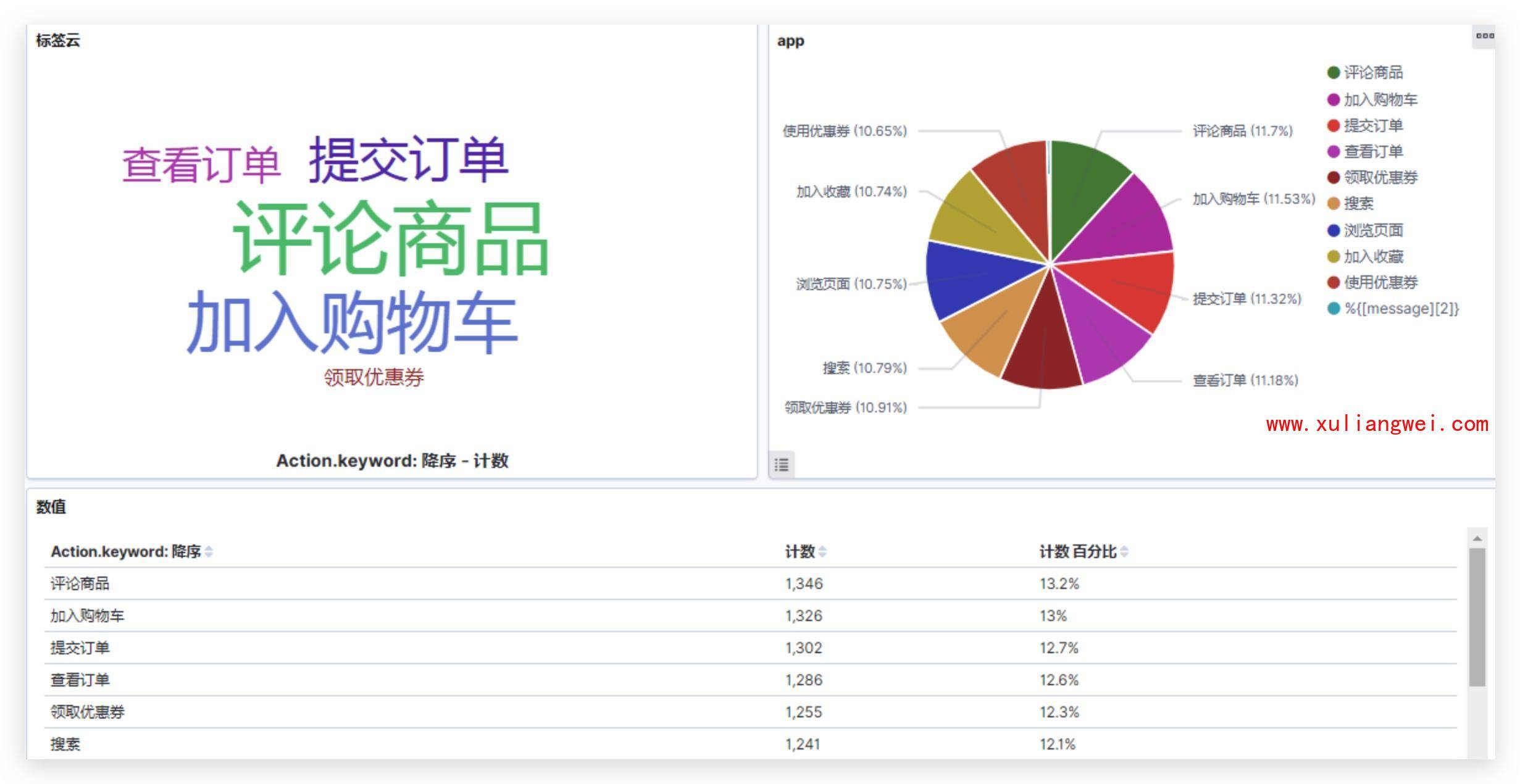
10 Logstash分析Nginx日志
1.Nginx日志收集概述
使用前面所学习到的所有内容,对文件access-logstash-2015-11-22.log 进行日志分析。日志下载地址
123.150.183.45 - - [22/Nov/2015:12:01:01 +0800] "GET /online/ppjonline/images/bgSLBCurrentLocation.png?v=1.8 HTTP/1.1" 200 764 "http://www.papaonline.com.cn/online/ppjonline/order/orderNow.jsp" "Mozilla/5.0 (Linux; U; Android 4.3; zh-CN; SCH-N719 Build/JSS15J) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 UCBrowser/9.9.5.489 U3/0.8.0 Mobile Safari/533.1"
- 1.将Nginx普通日志转换为json
- 2.将Nginx日志的时间格式进行格式化输出
- 3.将Nginx日志的来源IP进行地域分析
- 4.将Nginx日志的user-agent字段进行分析
- 5.将Nginx日志的bytes修改为整数
- 6.移除没有用的字段,message、headers
2.Nginx日志分析架构
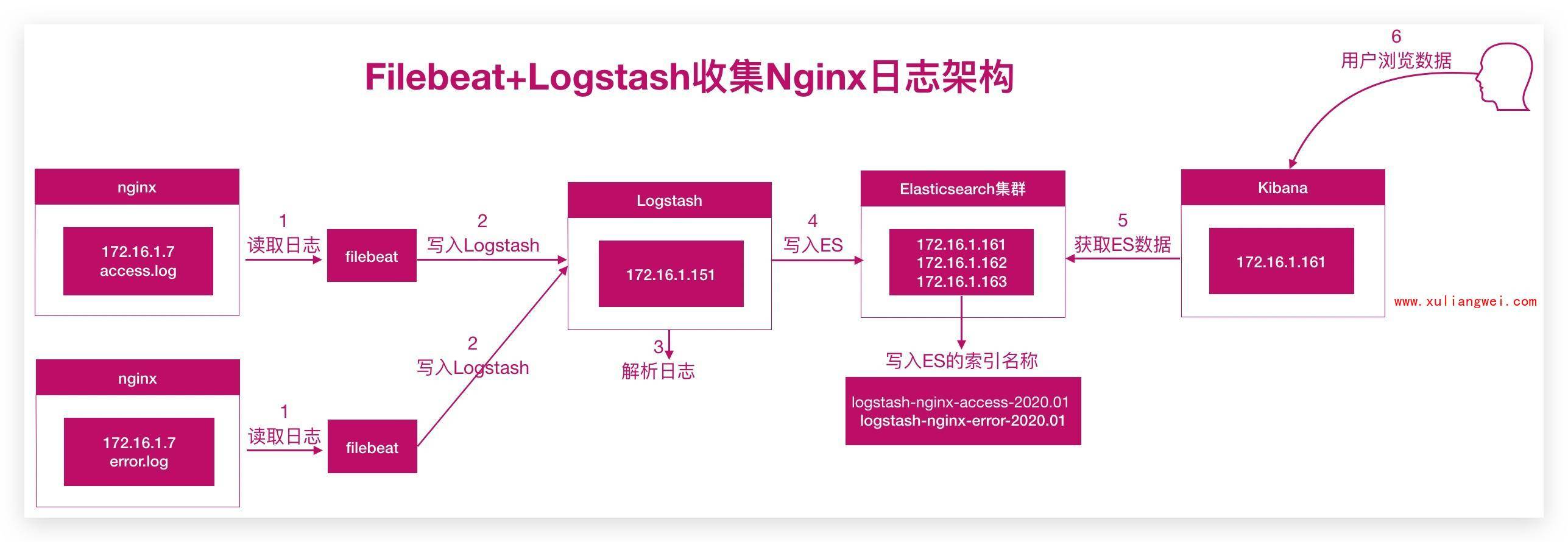
3.Nginx日志分析实践
1.filebeat配置如下: ``` [root@oldxu-web01-172 ~]# cat /etc/filebeat/filebeat.yml filebeat.inputs: - type: log
enabled: true
paths:
- /var/log/nginx/access.log tags: [“access”]
- type: log
enabled: true
paths:
- /var/log/nginx/error.log
tags: [“error”]
output.logstash:
hosts: [“172.16.1.151:5044”]
loadbalance: true 多个Logstash的时候开启负载
worker: 2 #工作线程数 * number of hosts
[root@oldxu-logstash-node1-172 conf.d]# cat /etc/logstash/conf.d/filebeat_logstash_codec.conf input { beats { port => 5044 } } filter { if “nginx-access” in [tags][0] { grok {_2.logtash配置如下:_
} date {match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:useragent}" }
} geoip {match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] target => "@timestamp" timezone => "Asia/Shanghai" #timezone => "UTC"
} useragent {source => "clientip"
} mutate {source => "useragent" target => "useragent"
} } else if “nginx-error” in [tags][0] {convert => [ "bytes", "integer" ] remove_field => [ "message", "agent" , "input","ecs" ] add_field => { "target_index" => "logstash-nginx-access-%{+YYYY.MM.dd}" }
} } output { elasticsearch { hosts => [“172.16.1.161:9200”,”172.16.1.162:9200”,”172.16.1.163:9200”] index => “%{[targetindex]}” } } ``` _3.Kibana部分效果展示图mutate { add_field => { "target_index" => "logstash-nginx-error-%{+YYYY.MM.dd}" } }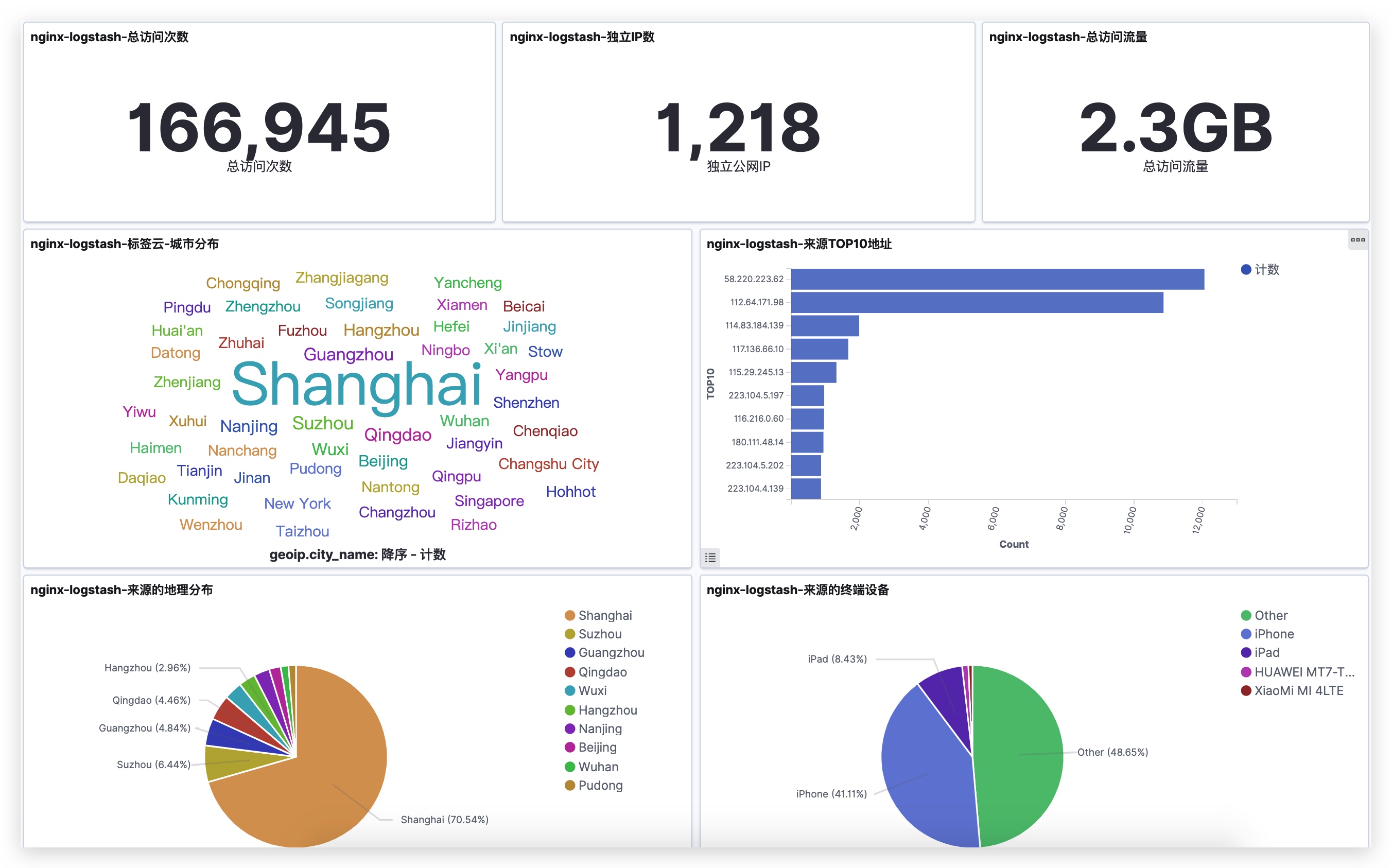
- /var/log/nginx/error.log
tags: [“error”]
output.logstash:
hosts: [“172.16.1.151:5044”]
11 Logstash分析MySQL日志✨
1.MySQL慢日志收集介绍
1.什么是Mysql慢查询日志?
当SQL语句执行时间超过所设定的阈值时,便会记录到指定的日志文件中,所记录内容称之为慢查询日志。
2.为什么要收集Mysql慢查询日志?
数据库在运行期间,可能会存在SQL语句查询过慢,那我们如何快速定位、分析哪些SQL语句需要优化处理,又是哪些SQL语句给业务系统造成影响呢?
当我们进行统一的收集分析,SQL语句执行的时间,以及执行的SQL语句,一目了然。
3.如何收集Mysql慢查询日志?
1.安装MySQL
2.开启MySQL慢查询日志记录
3.使用filebeat收集本地慢查询日志路径
2.MySQL慢查询日志收集
安装MySQL,并开启慢日志
[root@db01 ~]# vim /etc/my.cnf [mysqld] ... slow_query_log=ON slow_query_log_file=/var/log/mariadb/slow.log long_query_time=3 ... #重启mariadb [root@db01 ~]# systemctl restart mariadb #模拟慢日志 MariaDB [(none)]> select sleep(1) user,host from mysql.user;_
配置filebeat收集mysql日志 ```less [root@db01~]# cat /etc/filebeat/filebeat.yml filebeat.inputs:
- type: log enabled: true paths:
[root@db01 ~]# systemctl restart filebeat.service
<a name="nLvEV"></a>
## 3.Logstash处理分析日志
_由原来的 mysql+filebeat --> elasticsearch <--kibana 替换为如下方式_<br />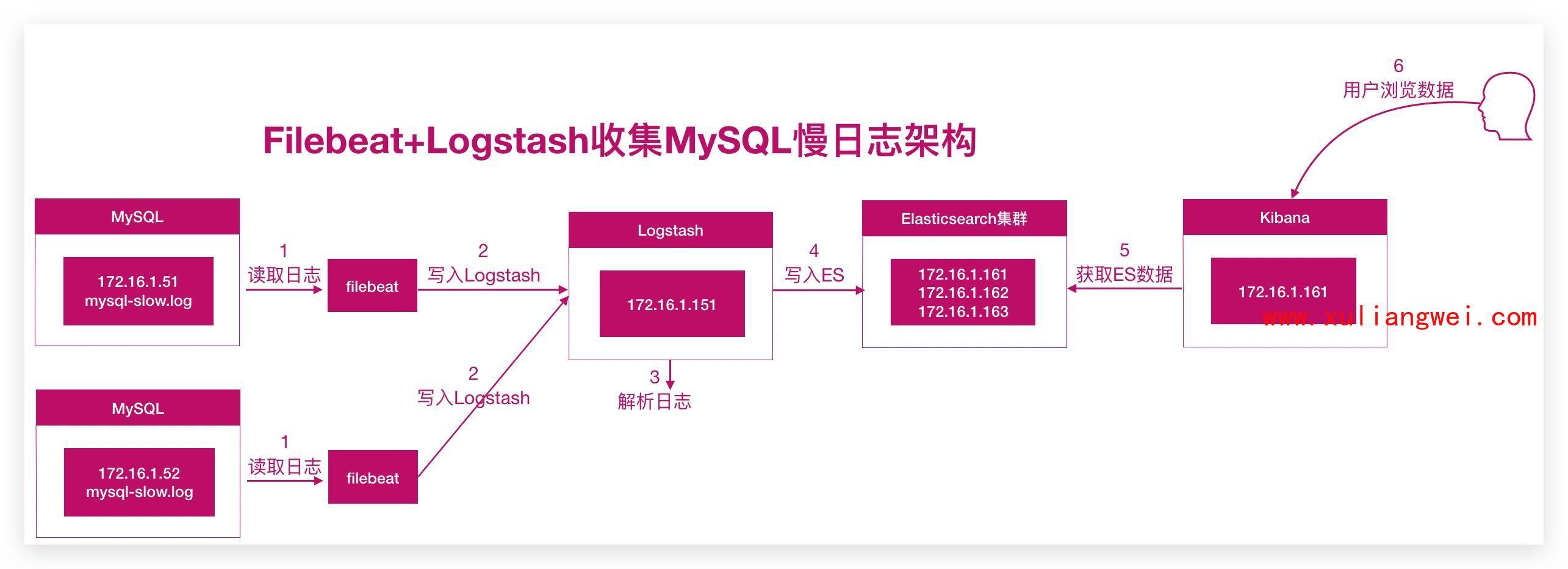<br />_
<a name="JQ2Jf"></a>
#### _1.filebeat配置,将原来写入elasticsearch修改为写入logstash_
```less
[root@db01 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/mariadb/slow.log
exclude_lines: ['^\# Time'] #排除匹配的行
multiline.pattern: '^\# User'
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ["10.0.0.151:5044"]
[root@db01 /etc/filebeat]# systemctl restart filebeat.service
- 客户端调试:
##1. filebeat 采集器如何调试: [root@db01 ~]# cat /etc/filebeat/filebeat.yml .... output.console: pertty: true enabled: true[root@db01 ~]# filebeat -e -c /etc/filebeat/filebeat.yml #没配置logstash时 指定文件,输出到屏幕的方式调试
2.logstash配置以及日志处理思路。grok案例
1.使用grok插件将mysql慢日志格式化为json格式
2.将timestamp时间转换为本地时间
3.检查json格式是否成功,成功后可以将没用的字段删除
4.最后将输出到屏幕的内容,输出至Elasticsearch集群。
input {
beats {
port => 5044
}
}
filter {
#将filebeat多行产生的\n替换为空
mutate {
gsub => ["message","\n"," "]
}
grok {
match => { "message" => "(?m)^# User@Host: %{USER:User}\[%{USER-2:User}\] @ (?:(?<Clienthost>\S*) )?\[(?:%{IP:Client_IP})?\] # Thread_id: %{NUMBER:Thread_id:integer}\s+ Schema: (?:(?<DBname>\S*) )\s+QC_hit: (?:(?<QC_hit>\S*) )# Query_time: %{NUMBER:Query_Time}\s+ Lock_time: %{NUMBER:Lock_Time}\s+ Rows_sent: %{NUMBER:Rows_Sent:integer}\s+Rows_examined: %{NUMBER:Rows_Examined:integer} SET timestamp=%{NUMBER:timestamp}; \s*(?<Query>(?<Action>\w+)\s+.*)" }
}
date {
match => ["timestamp","UNIX", "YYYY-MM-dd HH:mm:ss"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
#移除message等字段
remove_field => ["message","input","timestamp"]
#对Query_time Lock_time 格式转换为浮点数
convert => ["Lock_Time","float"]
convert => ["Query_Time","float"]
#添加索引名称
add_field => { "[@metadata][target_index]" => "mysql-logstash-%{+YYYY.MM.dd}" }
}
}
output {
elasticsearch {
hosts => ["10.0.0.161:9200","10.0.0.162:9200","10.0.0.163:9200"]
index => "%{[@metadata][target_index]}"
template_overwrite => true
}
}
kibana添加索引
_5.最后kibana展示效果如下: 会发现所有的字段都进行了拆分。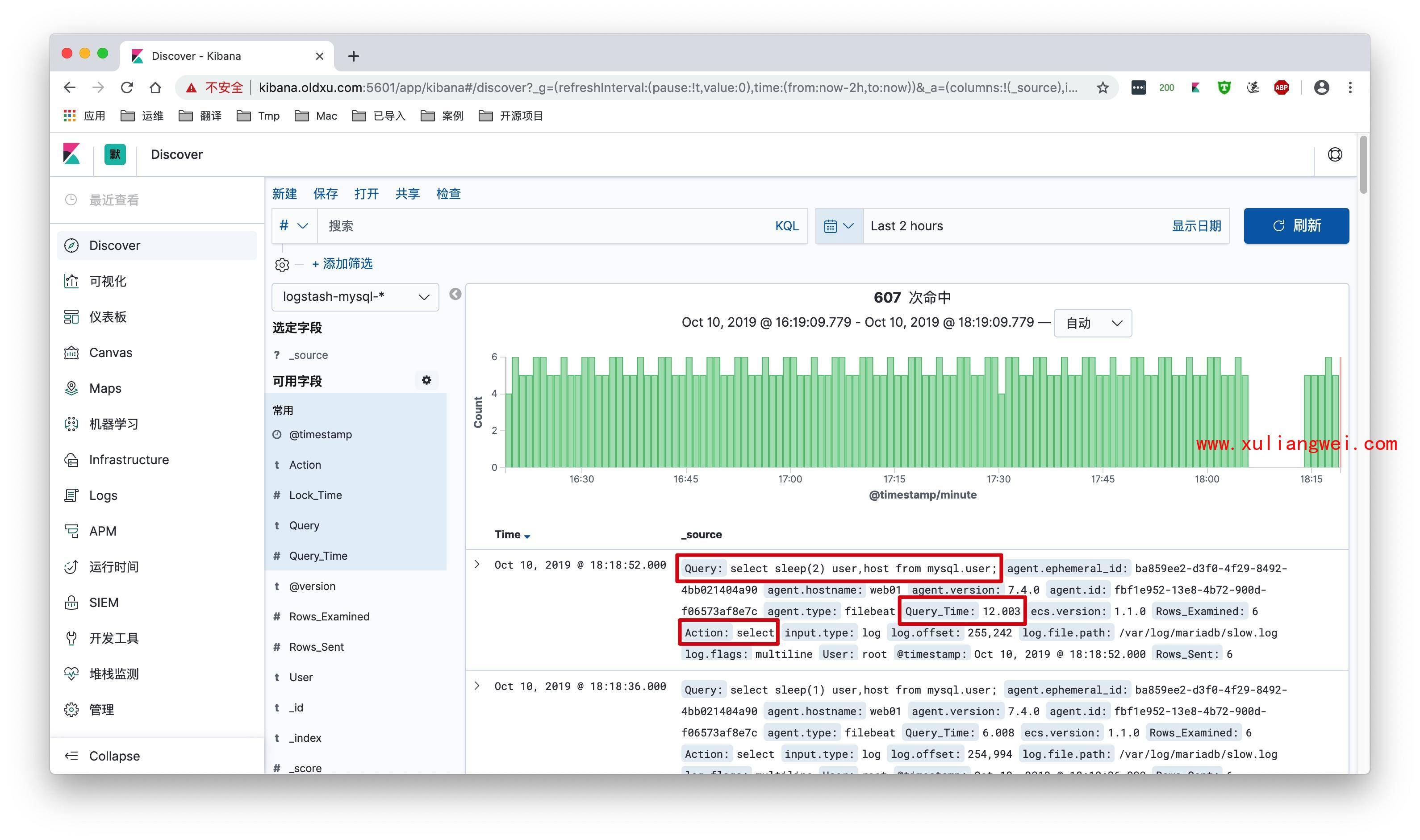
3.导入MySQL-Slow日志,并通过Kibana分析与展示**
1.导入slow-2020-01.log日志(约4w条),然后追加至指定的文件中。日志下载
#基于之前已有的架构进行日志导入,filebeat-->logstash-->elasticsearch
[root@web01 ~]# cat slow-2020-01.log >> /var/log/mariadb/slow.log
_2.当ES数据写入完成后,使用kibana对该日志进行分析与展示。
- 索引的字段类型改为Bytes,可视化才能人人类可读显示大小

若有收获,就点个赞吧
0 人点赞
