资料: index.html
一: Kibana分析站点业务日志
1.kibana数据展示概述
1.Kibana是用来数据展示、数据分析、数据探索的web UI工具。
2.kibana线上部署的推荐架构,专门部署一个coordinating only ES Node,和Kibana在同一台机器上。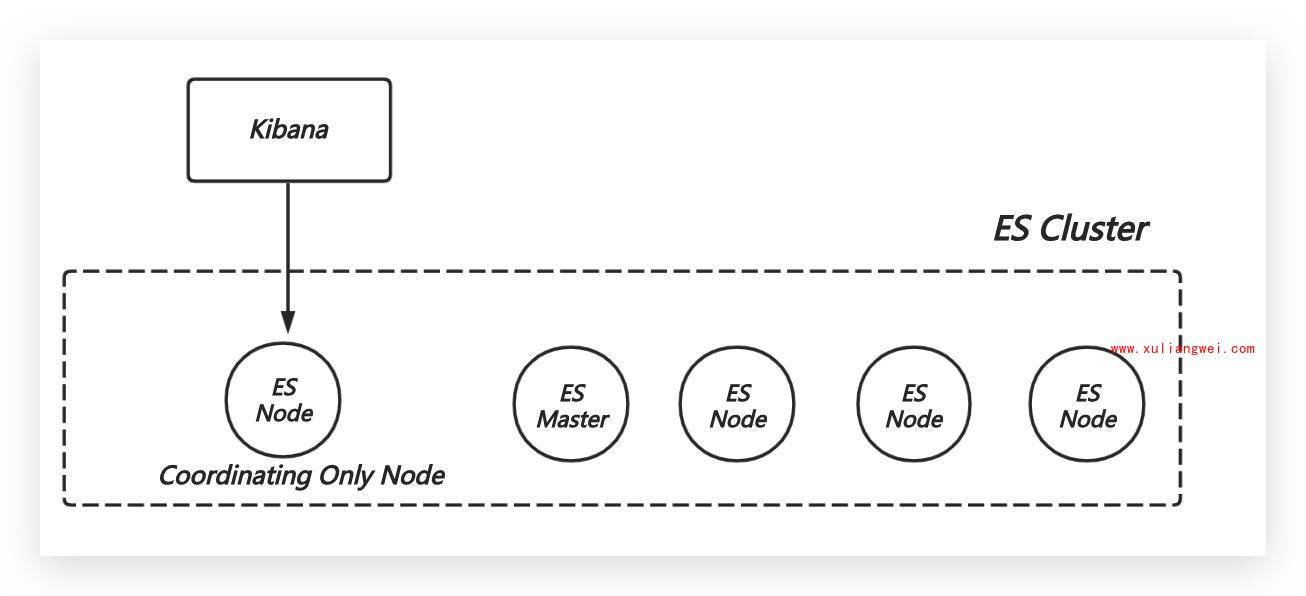
2.Kibana出图基本应用
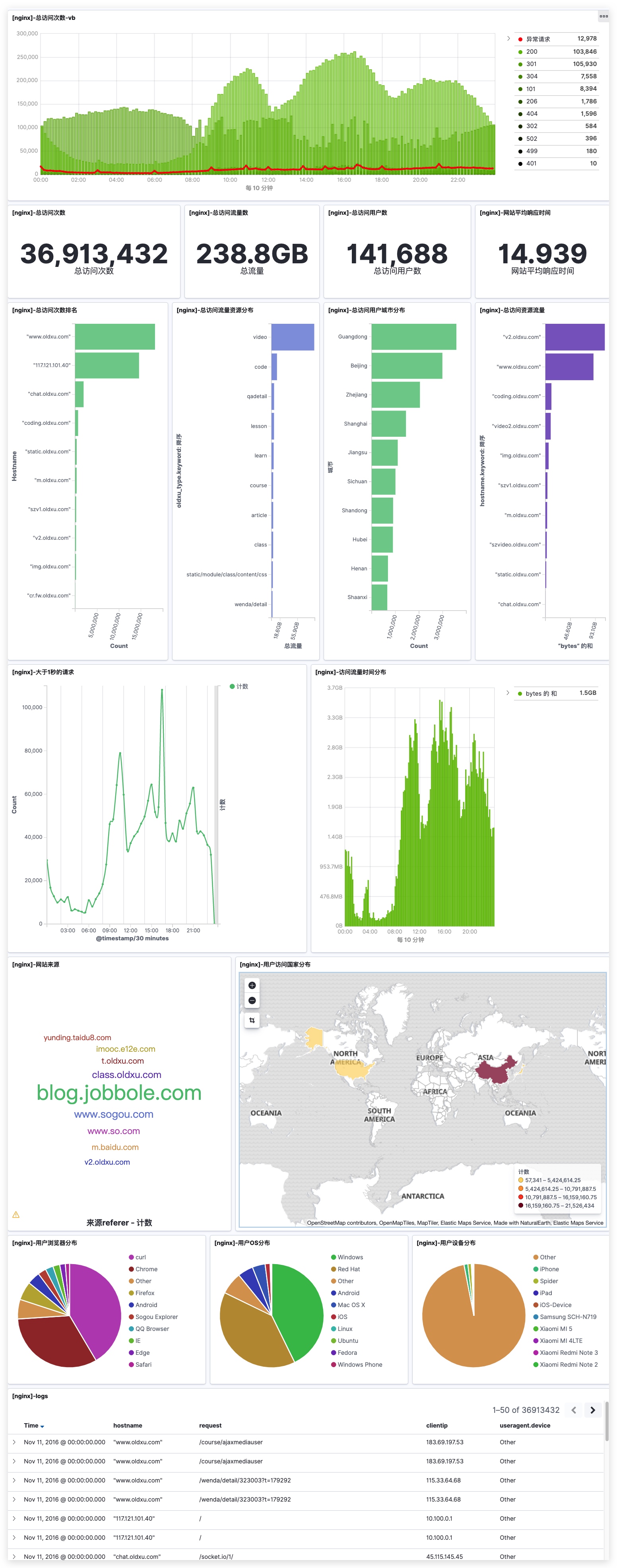
使用kibana对如下网站日志进行如下展示。
- 统计网站总PV、独立IP个数(指标)
- 统计访问IP Top10(水平条形图)
- 统计来源的refrer
- 统计前10的资源(饼图或标签云)
- 统计访问状态码(饼图或时序图)
- 统计客户端设备(饼图)
- 统计大于1s请求
- 统计网站的总流量(指标图)
-
3.Kibana展示业务日志
1.需要分析的日志如下,日志传送门
#www.oldxu.com 为请求的域名 api3为请求的资源 uid=为用户id124.161.176.119 - - [10/Nov/2016:00:01:52 +0800] "POST /api3/appover HTTP/1.1" 200 103 "www.oldxu.com" "-" code=B157963E-5BDA-4090-A021-A3D46D2E6BA2&secrect=f0fbb455c7aebc69c5cc39d68c7859fe&time=9441×tamp=1478707307012&token=12d0f0cfa1efb81e42c321f027bbe752&uid=4384521 "oldxu/5.0.2 (iPhone; iOS 10.1.1; Scale/2.00)" "-" 10.100.136.65:80 200 0.011 0.011
_2.两个维度分析 Nginx 访问分析
- 访问人数?流量?
- 访问来源分布、访问站点分布、访问页面排名
- 请求响应时间分布
- 请求响应码分布
- 访问地图分布
- 网站业务数据分析
- 访问量最大的是视频还是文章
- 最受欢迎视频、文章有哪些
- 最努力的用户是谁
- 兴趣最广泛的用户数是
- 用户哪个时间段最活跃
_3.日志架构如下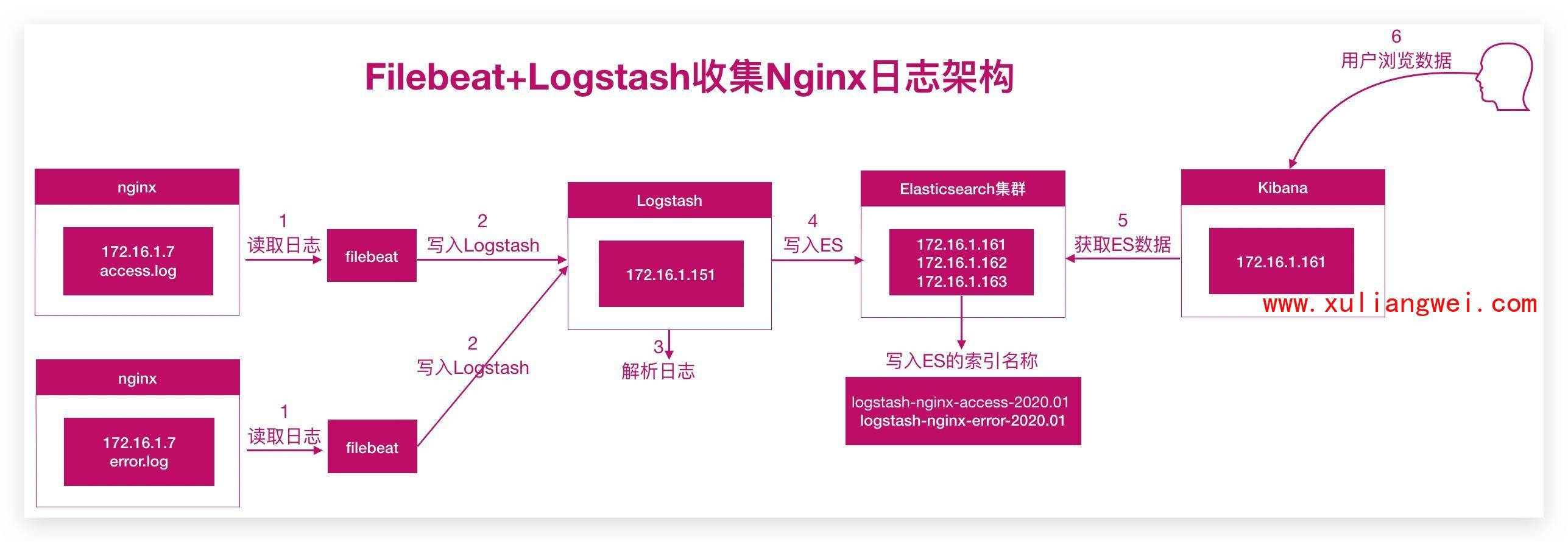
_4.配置filebeat
[root@oldxu-web01-172 ~]# cat /etc/filebeat/filebeat.ymlfilebeat.inputs:- type: logenabled: truepaths:- /var/log/nginx/access.logtags: ["access"]- type: logenabled: truepaths:- /var/log/nginx/error.logtags: ["error"]output.logstash:hosts: ["172.16.1.151:5044"]#loadbalance: true#worker: 2 #number of hosts * workers
_5.配置logstash
[root@oldxu-logstash-node1-172 ~]# cat /etc/logstash/conf.d/filebeat_logstash_codec.conf
input {
beats {
port => 5044
}
}
filter {
if "access" in [tags][0] {
grok {
match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:hostname} (?:%{QS:referrer}|-) (?:%{NOTSPACE:post_args}|-) %{QS:useragent} (?:%{QS:x_forward_for}|-) (?:%{URIHOST:upstream_host}|-) (?:%{NUMBER:upstream_response_code}|-) (?:%{NUMBER:upstream_response_time}|-) (?:%{NUMBER:response_time}|-)" }
}
useragent {
source => "useragent"
target => "useragent"
}
geoip {
source => "clientip"
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
convert => ["bytes","integer"]
convert => ["response_time", "float"]
convert => ["upstream_response_time", "float"]
remove_field => ["message","agent","tags"]
add_field => { "target_index" => "logstash-nginx-access-%{+YYYY.MM}" }
}
#提取referrer具体的域名/^"http/
if [referrer] =~ /^"http/ {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}' }
}
}
#提取用户请求资源类型以及资源ID编号
if "oldxu.com" in [referrer_host] {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:oldxu_type}/%{NOTSPACE:oldxu_res_id})?"' }
}
}
}
else if "error" in [tags][0] {
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
add_field => { "target_index" => "logstash-nginx-error-%{+YYYY.MM}" }
}
}
}
output {
elasticsearch {
hosts => ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
index => "%{[target_index]}"
template_overwrite => true
}
}
4.Kibana安全访问控制
默认情况下,kibana可以直接通过浏览器打开进行操作,这样的话任何人都可以通过该方式打开,极其的不安全。我们可以通过如下两种方式来解决。
方式1:nginx+kibana,非常简单实现方式。
方式2:kibana roles,比较推荐方式。
实践1:nginx+kibana实现基础访问控制。
_
yum install nginx -y
vim /etc/nginx/conf.d/kibana.oldxu.com.conf
server {
listen 80;
server_name kibana.oldxu.com;
location / {
proxy_pass http://127.0.0.1:5601$request_uri;
include proxy_params;
}
}
实践2:从 Elastic Stack6.8和7.1开始,在默认分发包中免费提供多项安全功能,例如 TLS 加密通信、基于角色的访问控制 RBAC 等等。
_1)在 Elastic 主节点配置 TLS
[root@es-node1-172 ~]# /usr/share/elasticsearch/bin/elasticsearch-certutil \
cert -out /etc/elasticsearch/elastic-certificates.p12 -pass ""
[root@es-node1-172 ~]# chmod 660 /etc/elasticsearch/elastic-certificates.p12
_2)编辑 Elastic 配置文件,添加如下内容,所有节点都需要添加。
[root@es-node1-172 ~]# vim /etc/elasticsearch/elasticsearch.yml
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
_3)拷贝 TLS 证书至集群的所有 node 节点。
scp -rp /etc/elasticsearch/elastic-certificates.p12 root@172.16.1.162:/etc/elasticsearch/
scp -rp /etc/elasticsearch/elastic-certificates.p12 root@172.16.1.163:/etc/elasticsearch/
_4)重新所有 Elastic 集群节点。
systemctl restart elasticsearch
_5)一旦主节点开始运行,便可以为集群设置密码了。auto 会为不同的内部堆栈生成随机密码。或者修改为 interactive 参数手动定义密码。
[root@es-node1-172 ~]# /usr/share/elasticsearch/bin/elasticsearch-setup-passwords auto
#请记录这些密码,我们很快就会再次用到这些密码。
_6)在kibana中实现安全性,我们需要为 Kibana 用户添加密码。我们可以从之前 setup-passwords 命令的输出内容中找到密码。
[root@es-node1-172 ~]# vim /etc/kibana/kibana.yml
elasticsearch.username: "kibana"
elasticsearch.password: "JtE2EyyZD9muQCXOXd5q" #setup-passwords获取的 Kibana 密码
[root@es-node1-172 ~]# systemctl restart kibana
_7)在kibana中实现 RBAC,我们通过浏览器并打开http://localhost:5601 我们将会使用 elastic 超级用户进行登录,密码来自 setup-passwords 命令。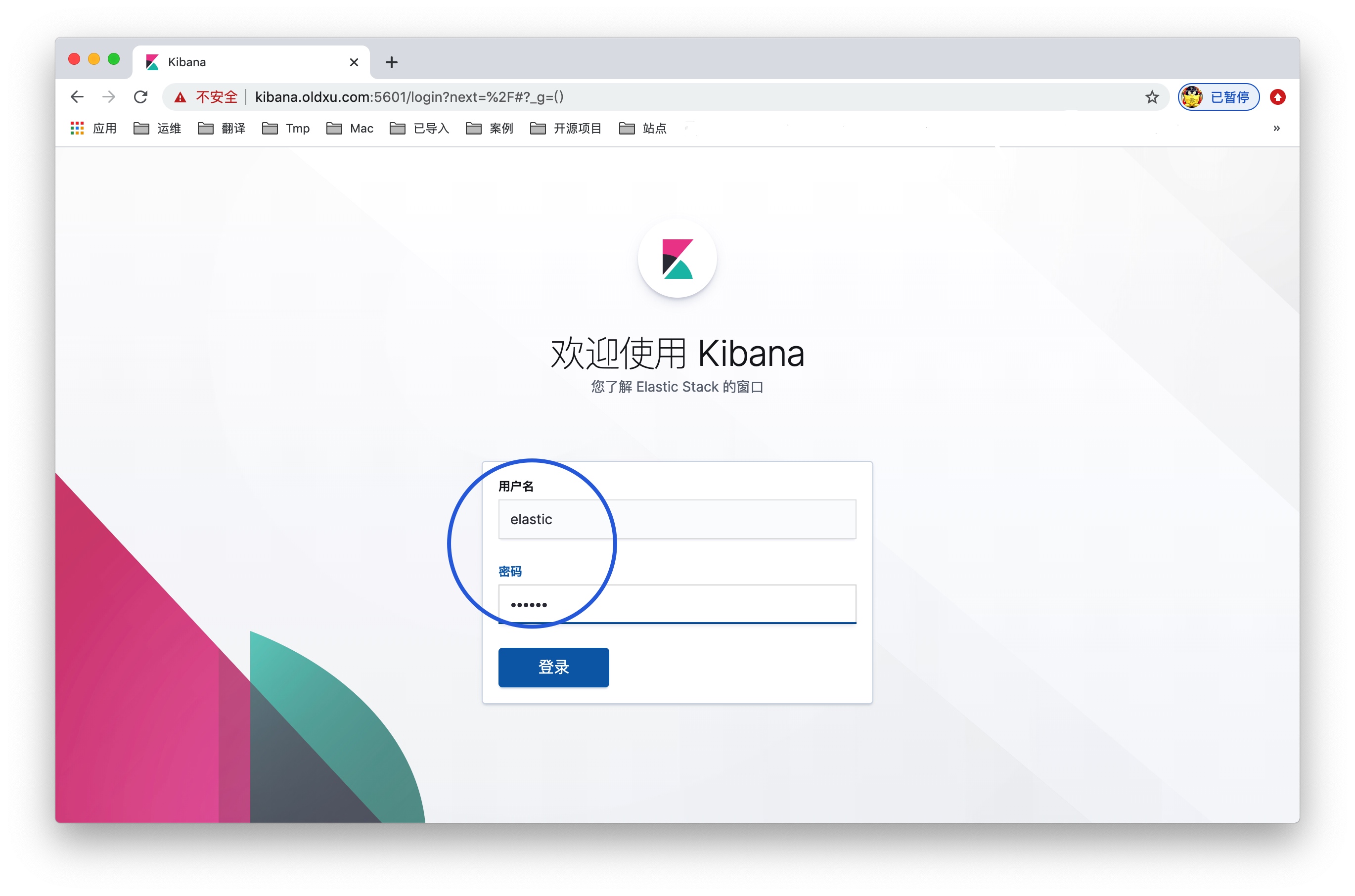
kibana roles权限配置参考Url
二: 引入Redis消息队列解耦
1.ELK引入Redis介绍
1.EFLK架构面临问题一:耦合度太高。
举个例子:
比如目前系统日志输出很频繁,十分钟大约5G,那么一个小时就是50G。而应用服务器的存储空间一般默认40Gb,所以通常会对应用服务器日志按小时轮转。如果我们的Logstash故障了1小时,那么Filebeat就无法向Logstash发送日志,但我们的应用服务器每小时会对日志进行切割,那么也就意味着我们会丢失1小时的日志数据。
解决办法:使用队列,只要你的filebeat能够收集日志,队列能够存储足够长时间的数据,那后面logstash或Elasticsearch故障了,也不用担心,修复后,日志依然能正常写入,也不会造成数据丢失,这样就完成了解耦。
2.此前架构面临问题二:性能瓶颈。
举个例子:使用filebeat或logstash直接写入ES,那么日志频繁的被写入ES的情况下,可能会造成ES出现超时、丢失等情况。因为ES需要处理数据,性能会变缓。
解决办法:使用消息队列,filebeat或Logstash直接写入消息队列中就可以了,因为队列可以起到一个缓冲作用,最后我们的logstash根本自己的能力进行数据消费和处理,然后写入ES,这样能有效缓解ES写入性能的瓶颈。
3.redis队列实现是最简单的方式,但会带来两个问题。
1.filebeat不支持写入redis集群。
2.redis是需要内存支持,大量的数据写入redis需要足够大的内存,成本较高。
2.ELK对接Redis架构
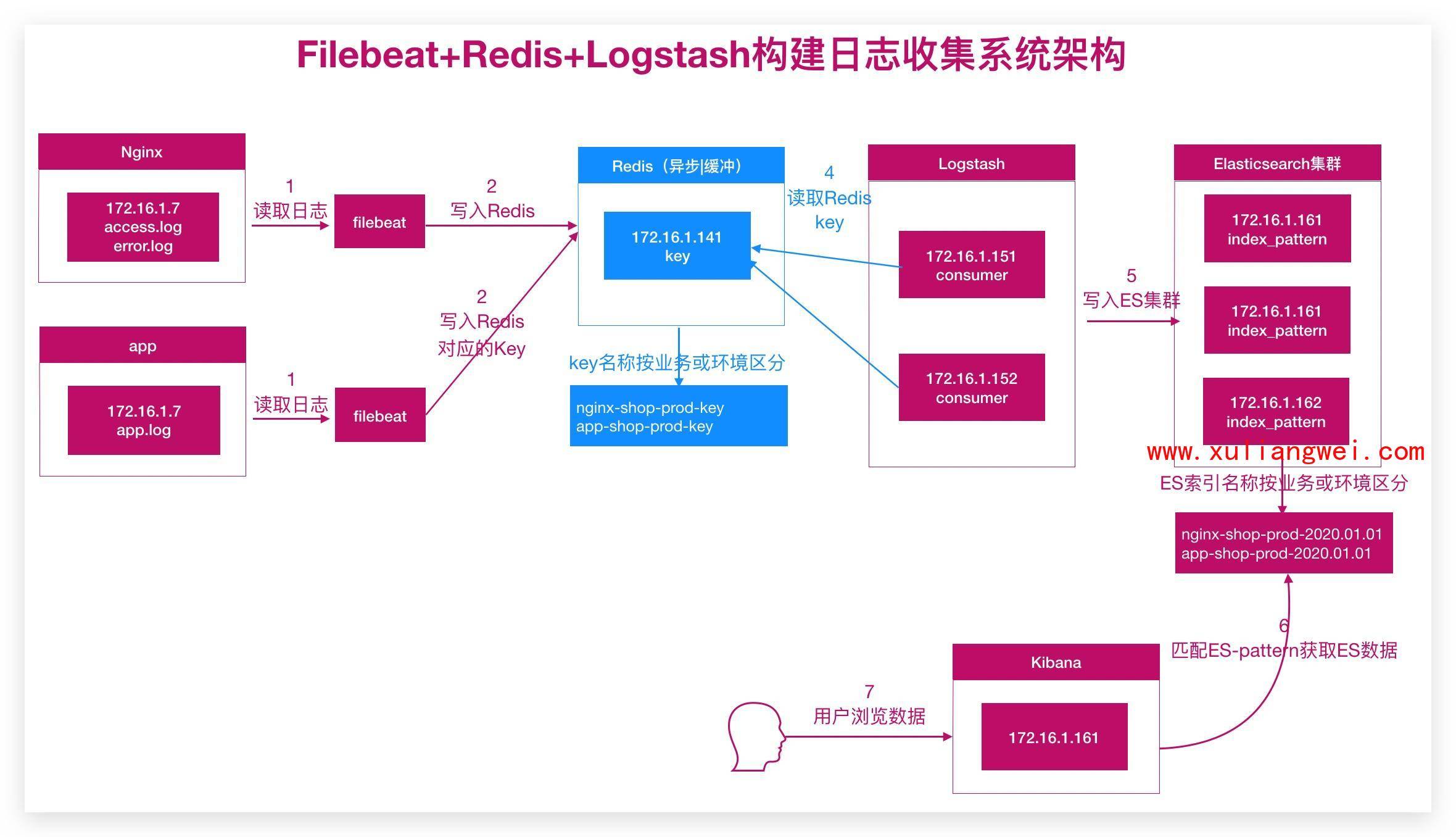
3.ELK对接Redis实践
_1.安装redis
[root@web02 ~]# yum install redis -y
_2.配置redis
[root@web02 ~]# grep "^[a-Z]" /etc/redis.conf
bind 127.0.0.1 172.16.1.141
requirepass 123456
....
_3.启动redis
[root@web02 ~]# systemctl restart redis
[root@web02 ~]# systemctl enable redis
_4.修改filebeat输出数据至Redis
[root@web01 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
tags: ["access"]
- type: log
enabled: true
paths:
- /var/log/nginx/error.log
tags: ["error"]
output.redis:
hosts: ["10.0.0.141:6379"] #redis地址
password: 123456 #redis密码
timeout: 5 #连接超时时间
db: 0 #写入db0库中
keys: #存储的key名称
- key: "nginx_access"
when.contains:
tags: "access"
- key: "nginx_error"
when.contains:
tags: "error"
_5.修改logstash从Redis中读取数据
[root@logstash-node1 ~]# cat /etc/logstash/conf.d/input_redis_nginx_1w_output_es.conf
input {
redis {
host => ["10.0.0.141"]
port => "6379"
password => "123456"
data_type => "list"
key => "nginx_access"
db => "0"
}
redis {
host => ["10.0.0.8"]
port => "6379"
password => "123456"
data_type => "list"
key => "nginx_error"
db => "0"
}
}
filter {
if "access" in [tags][0] {
grok {
match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:hostname} (?:%{QS:referrer}|-) (?:%{NOTSPACE:post_args}|-) %{QS:useragent} (?:%{QS:x_forward_for}|-) (?:%{URIHOST:upstream_host}|-) (?:%{NUMBER:upstream_response_code}|-) (?:%{NUMBER:upstream_response_time}|-) (?:%{NUMBER:response_time}|-)" }
}
useragent {
source => "useragent"
target => "useragent"
}
geoip {
source => "clientip"
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
convert => ["bytes","integer"]
convert => ["response_time", "float"]
remove_field => ["message","agent","tags"]
add_field => { "target_index" => "logstash-redis-nginx-access-%{+YYYY.MM.dd}" }
}
#提取referrer具体的域名/^"http/
if [referrer] =~ /http/ {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}' }
}
}
#提取用户请求资源类型以及资源ID编号
if "oldxu.com" in [referrer_host] {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:oldxu_type}/%{NOTSPACE:oldxu_res_id})?"' }
}
}
}
else if "error" in [tags][0] {
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
add_field => { "target_index" => "logstash-redis-nginx-error-%{+YYYY.MM.dd}" }
}
}
}
output {
elasticsearch {
hosts => ["10.0.0.161:9200","10.0.0.162:9200","10.0.0.163:9200"]
index => "%{[target_index]}"
template_overwrite => true
}
stdout {
codec => rubydebug
}
}
6.登录kibana添加索引
三: 引入Kafka消息队列解耦
1.消息队列基本介绍
1.什么是消息队列?
消息 Message:比如两个设备进行数据的传输,所传输的数据,都可以称为消息,可以是文本、音频
队列 Queue:是一种”先进先出“的数据结构。类似排队买票、羽毛球筒。
消息队列MQ:是用来保存消息的一个容器。消息队列需要两个功能接口供外部调用,一个是生产、一个是消费。主要是进行数据存储和读取。把数据放到消息队列叫做生产者,从队列里取数据叫做消费者。
2.MQ主要分为两类: 点对点、发布/订阅
_
| 共同点 |
|---|
消息的生产者 (Producer)生产消息发送到队列中,然后消息的消费者(Consumer)从队列中读取并消费消息。
| 不同点 |
|---|
点对点:消息队列 (Queue)、发送者 (Sender)、接收者 (Receiver)
一个生产者生产的消息只能有一个消费者,消息一旦被消费,消息就不在消息队列中了,比如:钉钉的澡堂模式、打电话等。都是消息发送到消息队列后只能被一个接收者接收,当接收完毕消息则销毁。
发布/订阅:消息队列(Queue)、发布者(Publisher)、订阅者(Subscriber)、主题(Topic)
每个消息可以有多个消费者,彼此互不影响,比如:我使用公众号发布一篇文章,关注我的人都能看到,即发布到消息队列的消息能被多个接收者(订阅者)接收。
2.消息队列使用场景
消息队列最主要有三个场景总结为6个字。解耦、异步、削峰
1.解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。如下图: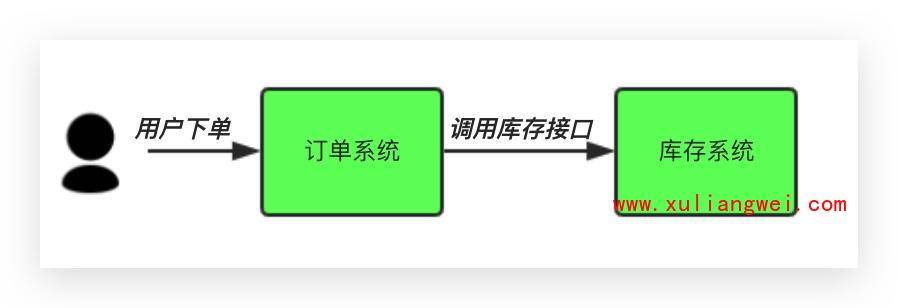
传统模式的缺点:
1)假如库存系统无法访问,则订单减库存将失败,从而导致订单失败;
2)订单系统与库存系统耦合;
中间件模式: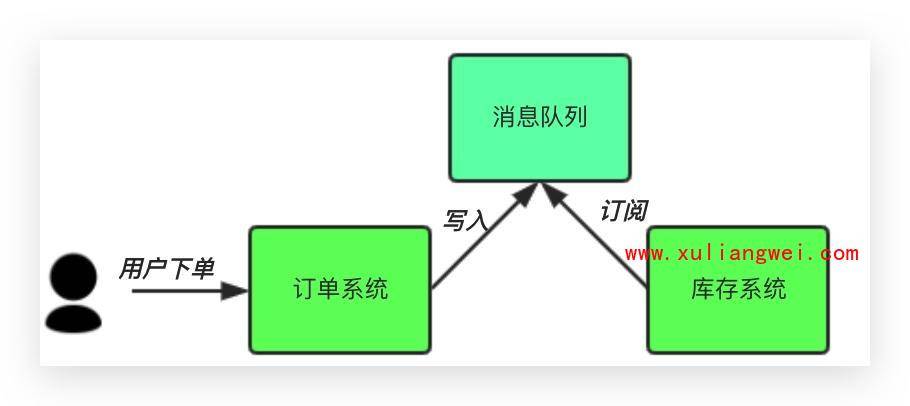
订单系统:用户下单后,订单系统完将消息写入消息队列,返回用户订单下单成功。
库存系统:订阅下单的消息,获取下单信息,库存系统根据下单信息,进行库存操作。
假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
2.异步 (同步完成的事情分开执行)
场景说明:用户注册后,需要发注册邮件和注册短信。将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端。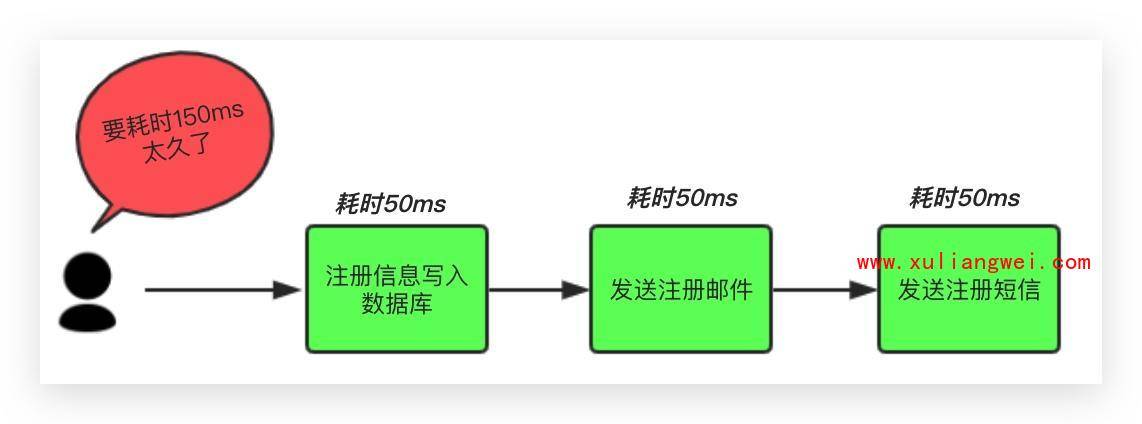
传统模式的缺点:系统的性能(并发量,吞吐量,响应时间)会有瓶颈。
中间件模式: 将不是必须的业务逻辑,异步处理。改造后的架构如下: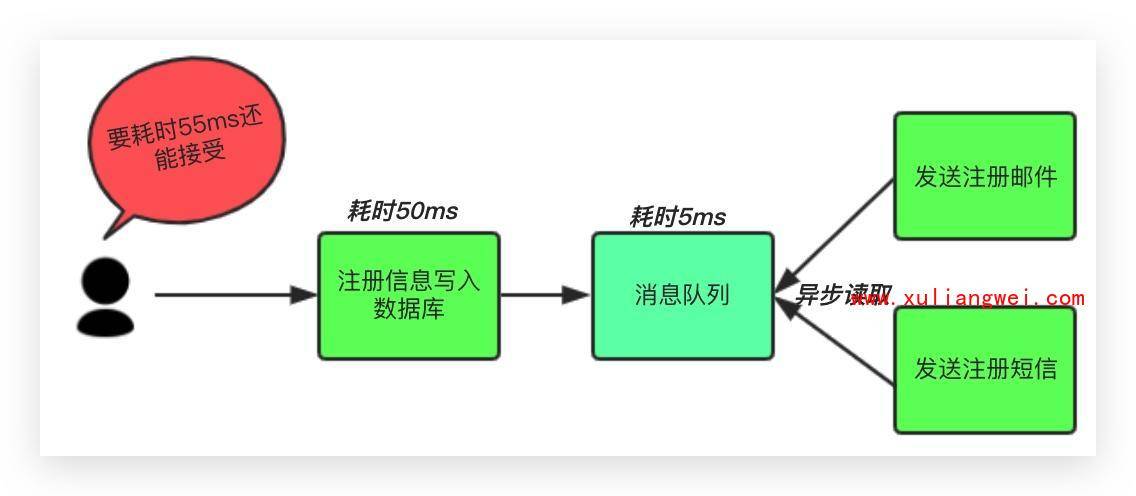
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50ms或55ms。
3.削峰
场景说明:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。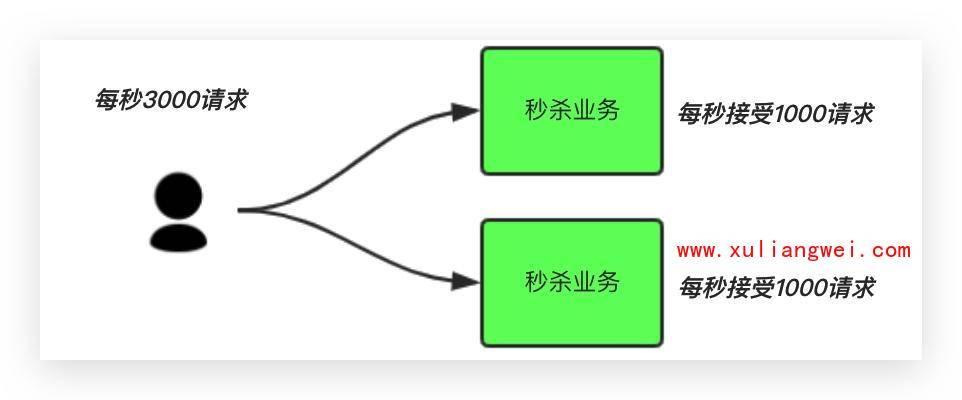
中间件模式:
1.用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量限制,则直接抛弃用户请求或跳转到错误页面。
2.秒杀业务可以根据自身能处理的能力获取消息队列数据,然后做后续处理。这样即使有8000个请求也不会造成秒杀业务奔溃。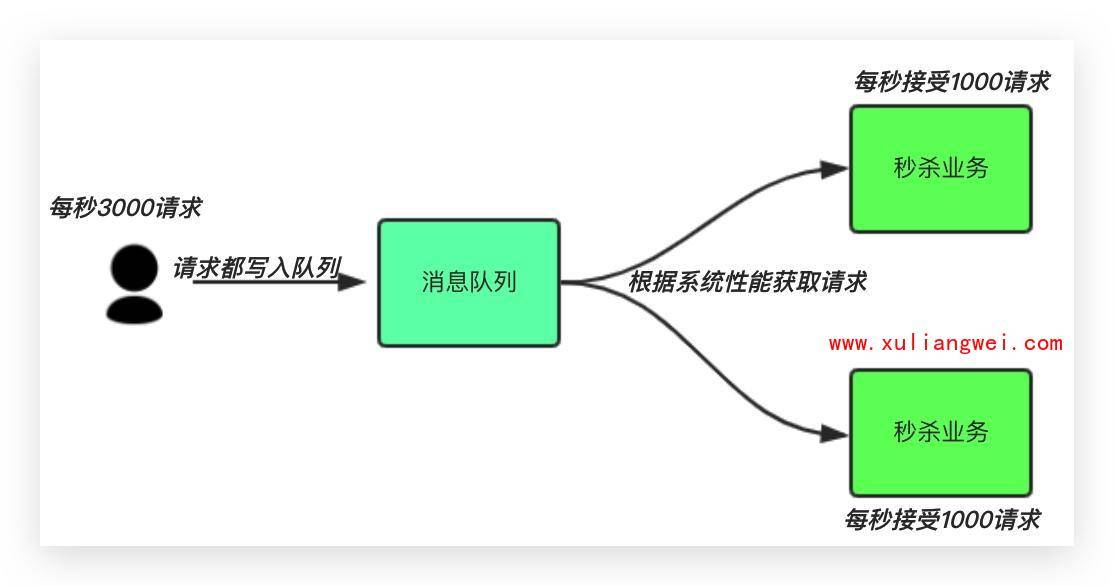
消息队列使用场景
消息队列使用的四种场景介绍
3.Kafka基本概述
1.什么是kafka
kafka是一个实时数据处理系统。实时数据处理系统就是数据一旦产生,就要能快速进行处理的系统。对于实时数据处理系统,最常见的就是消息队列。kafka 也是一个MQ消息队列。
2.kafka的特点
高吞吐量:可以满足每秒百万级别消息的生产和消费。零拷贝技术、磁盘顺序IO存储
持久性:有一套完善的消息存储机制,确保数据的高效安全的持久化。
分布式:基于分布式的扩展和容错机制,当某一台发生故障失效时,可以实现故障自动转移。
3.kafka基本架构(1-2T 级别) ✨ ✨ ✨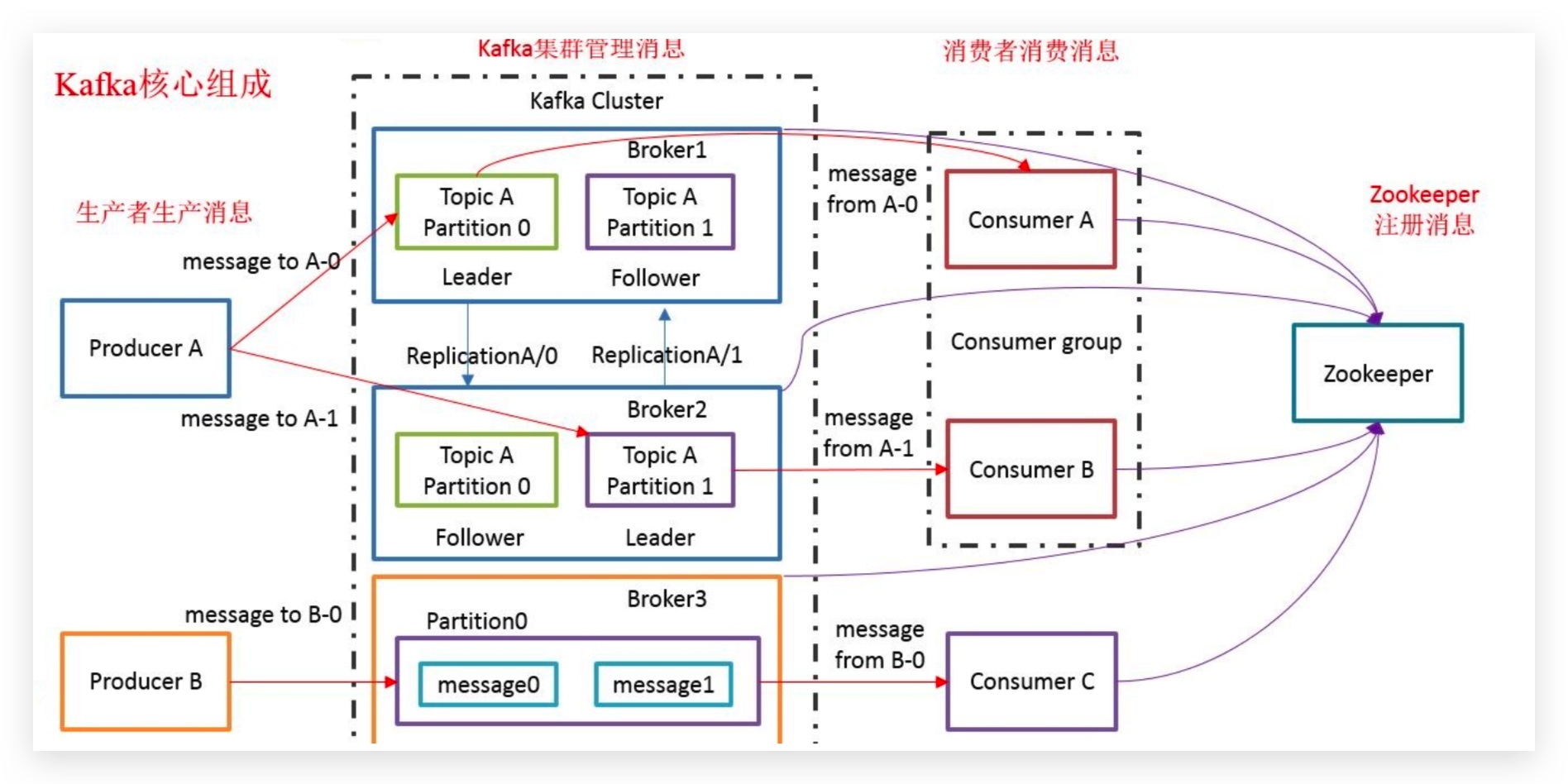
Broker:kafka集群中包含多个kafka服务节点,每一个kafka服务节点就称为一个broker
Topic: 主题,Kafka将消息分门别类, 每一类的消息称之为(Topic).(Kafka消息数据是存储在硬盘上的)
Partition: 分区,每个Topic包含一个或多个Partition,在创建Topic时指定包含的Partition数量(目的是为了进行分布式存储)
Replication: 副本,每个分区可以有多个副本,分布在不同的Broker上,会选出一个副本作为Leader,所有的读写请求都会通过Leader完成,但Follower只负责备份数据,所有Follower会自动的从Leader中复制数据,当Leader宕机后,会从Follower中选出一个新的Leader继续提供服务,实现故障自动转移。
Message: 消息,是通信的基本单位,每个消息都属于一个Partition
Producer: 消息的生产者,向 Kafka的一个topic发布消息
Consumer: 消息的消费者,订阅 topic并读取其发布的消息
Consumer Group: 每个Consumer属于一个特定的Consumer Group,多个Consumer可以属于同一个 Consumer Group中
Zookeeper: 主要用来存储Kafka的元数据信息,比如:有多少集群节点、主题名称、主要用来协调kafka的正常运行。但发送给Topic本身的消息数据并不存储在ZK中,而存在kafka的磁盘文件中。
4.Kafka基本使用
1.安装zookeeper
[root@oldxu-kafka-node1 ~]# yum install java maven -y
[root@oldxu-kafka-node1 ~]# cd /opt/
[root@oldxu-kafka-node1 opt]# tar xf apache-zookeeper-3.5.6-bin.tar.gz
[root@oldxu-kafka-node1 opt]# cd apache-zookeeper-3.5.6-bin/conf/
[root@oldxu-kafka-node1 conf]# cp zoo_sample.cfg zoo.cfg
[root@oldxu-kafka-node1 conf]# ../bin/zkServer.sh start
2.安装kafka
[root@oldxu-kafka-node1 ~]# cd /opt/
[root@oldxu-kafka-node1 opt]# tar xf kafka_2.12-2.3.0.tgz
[root@oldxu-kafka-node1 opt]# cd kafka_2.12-2.3.0/bin
[root@oldxu-kafka-node1 bin]# ./kafka-server-start.sh ../config/server.properties
3.使用kafka创建 topic
[root@oldxu-kafka-node1 bin]# ./kafka-topics.sh \
--create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 3 \
--topic oldxu
4.查看topic详情
[root@oldxu-kafka-node1 bin]# ./kafka-topics.sh \
--describe \
--zookeeper localhost:2181 \
--topic oldxu
5.producer模拟生产者,产生数据。
[root@oldxu-kafka-node1 bin]# ./kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic oldxu
6.consumer模拟消费者,模拟消费。
[root@oldxu-kafka-node1 bin]# ./kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic oldxu \
--from-beginning
7.删除topic
[root@oldxu-kafka-node1 bin]# ./kafka-topics.sh \
--delete \
--zookeeper localhost:2181 \
--topic oldxu
5.Kafka集群搭建🚩
1.安装zookeeper集群——————————————>**
1.安装java
[root@oldxu-kafka-node1 ~]# yum install -y java maven
2.配置zookeeper
[root@oldxu-kafka-node1 ~]# tar xf /opt/apache-zookeeper-3.5.6-bin.tar.gz
[root@oldxu-kafka-node1 ~]# cat /opt/apache-zookeeper-3.5.6-bin/conf/zoo.cfg
# 服务器之间或客户端与服务器之间维持心跳的时间间隔 tickTime以毫秒为单位。
tickTime=2000
# 集群中的follower服务器(F)与leader服务器(L)之间的初始连接心跳数 10* tickTime
initLimit=10
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数 5 * tickTime
syncLimit=5
# 数据保存目录
dataDir=../data
# 日志保存目录
dataLogDir=../logs
# 客户端连接端口
clientPort=2181
# 客户端最大连接数。# 根据自己实际情况设置,默认为60个
maxClientCnxns=60
# 三个接点配置,格式为: server.服务编号=服务地址、LF通信端口、选举端口
server.1=172.16.1.141:2888:3888
server.2=172.16.1.142:2888:3888
server.3=172.16.1.143:2888:3888
3.创建数据存储目录
[root@oldxu-kafka-node1 config]# mkdir ../data
4.将配置好的zookeeper拷贝至另外两个节点
# scp -rp /opt/apache-zookeeper-3.5.6-bin root@172.16.1.142:/opt
# scp -rp apache-zookeeper-3.5.6-bin root@172.16.1.143:/opt
5.在三个节点上/opt/apache-zookeeper-3.5.6-bin/data/myid写入节点标记
#node1的操作
echo "1" > /opt/apache-zookeeper-3.5.6-bin/data/myid
#node2的操作
echo "2" > /opt/apache-zookeeper-3.5.6-bin/data/myid
#node3的操作
echo "3" > /opt/apache-zookeeper-3.5.6-bin/data/myid
6.启动zookeeper集群
[root@oldxu-kafka-node1 ~]# cd /opt/apache-zookeeper-3.5.6-bin/bin/
[root@oldxu-kafka-node1 ~]# ./zkServer.sh start
7.检查集群状态(每个节点都需要进行操作)
[root@oldxu-kafka-node1 ~]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.5.6-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
2.安装kafka集群——————————————>**
1.解压kafka压缩包
[root@oldxu-kafka-node1 ~]# tar xf kafka_2.12-2.3.0.tgz
2.配置kafka
[root@oldxu-kafka-node1 ~]# cat /opt/kafka_2.12-2.3.0/conf/server.properties
############################# Server Basics #############################
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=1
############################# Socket Server Settings #############################
# kafka监听端口,默认9092
listeners=PLAINTEXT://172.16.1.141:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics #############################
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log Flush Policy #############################
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=172.16.1.141:2181,172.16.1.142:2181,172.16.1.143:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000
3.创建数据存储的目录
[root@es-node1 config]# mkdir ../data
[root@es-node1 config]# scp -rp /opt/kafka_2.12-2.3.0 root@172.16.1.142:/opt
[root@es-node1 config]# scp -rp /opt/kafka_2.12-2.3.0 root@172.16.1.143:/opt
4.修改142和143的 server.properties 文件中的 broker.id
#node1
broker.id=1
listeners=PLAINTEXT://172.16.1.141:9092
#node2
broker.id=2
listeners=PLAINTEXT://172.16.1.142:9092
#node3
broker.id=3
listeners=PLAINTEXT://172.16.1.143:9092
5.启动kafka集群
[root@es-node2 bin]# export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
[root@es-node2 bin]# ./kafka-server-start.sh ../config/server.properties #启动测试
[root@es-node2 bin]# ./kafka-server-start.sh -daemon ../config/server.properties #放入后台
6.kafka集群验证
#使用kafka创建一个topic
[root@oldxu-kafka-node1 bin]# ./kafka-topics.sh \
--create \
--zookeeper 172.16.1.141:2181,172.16.1.142:2181,172.16.1.143:2181 \
--partitions 1 \
--replication-factor 3 \
--topic oldxu
#消息发布者测试
[root@oldxu-kafka-node1 bin]# ./kafka-console-producer.sh \
--broker-list 172.16.1.141:9092,172.16.1.142:9092,172.16.1.143:9092 \
--topic oldxu
#消息订阅者测试
[root@oldxu-kafka-node1 bin]# ./kafka-console-consumer.sh \
--bootstrap-server 172.16.1.141:9092,172.16.1.142:9092,172.16.1.143:9092 \
--topic oldxu \
--from-beginning
6.Kafka容错机制
容错机制,简单就是实现故障转义,比如Leader节点故障,follwer会提升为Leader提供数据的读和写。
1.创建一个topic,指定partition分区1,副本数为3。
[root@oldxu-kafka-node1-172 ~]# ./kafka-topics.sh --create \
--zookeeper 172.16.1.141:2181,172.16.1.142:2181,172.16.1.143:2181 \
--replication-factor 3 \
--partitions 1 \
--topic my-topic
2.查看该topic的详情
[root@oldxu-kafka-node1-172 ~]#./kafka-topics.sh --describe \
--zookeeper 172.16.1.141:2181,172.16.1.142:2181,172.16.1.143:2181 \
--topic my-topic
Topic:my-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
#Topic: 主题名称
#PartitionCount: 分区数量
#ReplicationFactor: 分区副本数
#Leader: 分区Leader是brokerID为2的Kafka
#Replicas: 区副本存储再brokerID (2,3,1)
#Isr: 分区可用的副本brokerID (2,3,1)
3.模拟生产者发送消息,消费者消费消息。
#生产者product
[root@oldxu-kafka-node1-172 bin]# ./kafka-console-producer.sh \
--broker-list 172.16.1.141:9092,172.16.1.142:9092,172.16.1.143:9092 \
--topic my-topic
#消费者consumer
[root@oldxu-kafka-node1-172 bin]# ./kafka-console-consumer.sh \
--bootstrap-server 172.16.1.141:9092,172.16.1.142:9092,172.16.1.143:9092 \
--topic my-topic \
--from-beginning
5.模拟Broker为3的节点故障,检查是否会影响生产者和消费者的使用
#kill掉节点3的kafka,然后再次查看topic详情
[root@oldxu-kafka-node1-172 bin]# ./kafka-topics.sh \
--describe \
--bootstrap-server 172.16.1.141:9092,172.16.1.142:9092,172.16.1.143:9092 \
--topic my-topic
Topic:my-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,1
#会发现分区可用的副本从原来的(3,2,1)变为了(2,1),也就意味着并不会影响kafka的使用
6.最后停止该partition为Leader的Kafka节点
[root@oldxu-kafka-node3-172 bin]# ./kafka-topics.sh \
--describe \
--bootstrap-server 172.16.1.141:9092,172.16.1.142:9092,172.16.1.143:9092 \
--topic my-topic
Topic:my-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-topic Partition: 0 Leader: 1 Replicas: 2,3,1 Isr: 1
会发现kafka将原来为Replicas的Broker1节点,提升为Leaders,实现了故障自动转移,重启Kafka的Consumer后发现生产与消费一切正常。
7.ELK对接Kafka
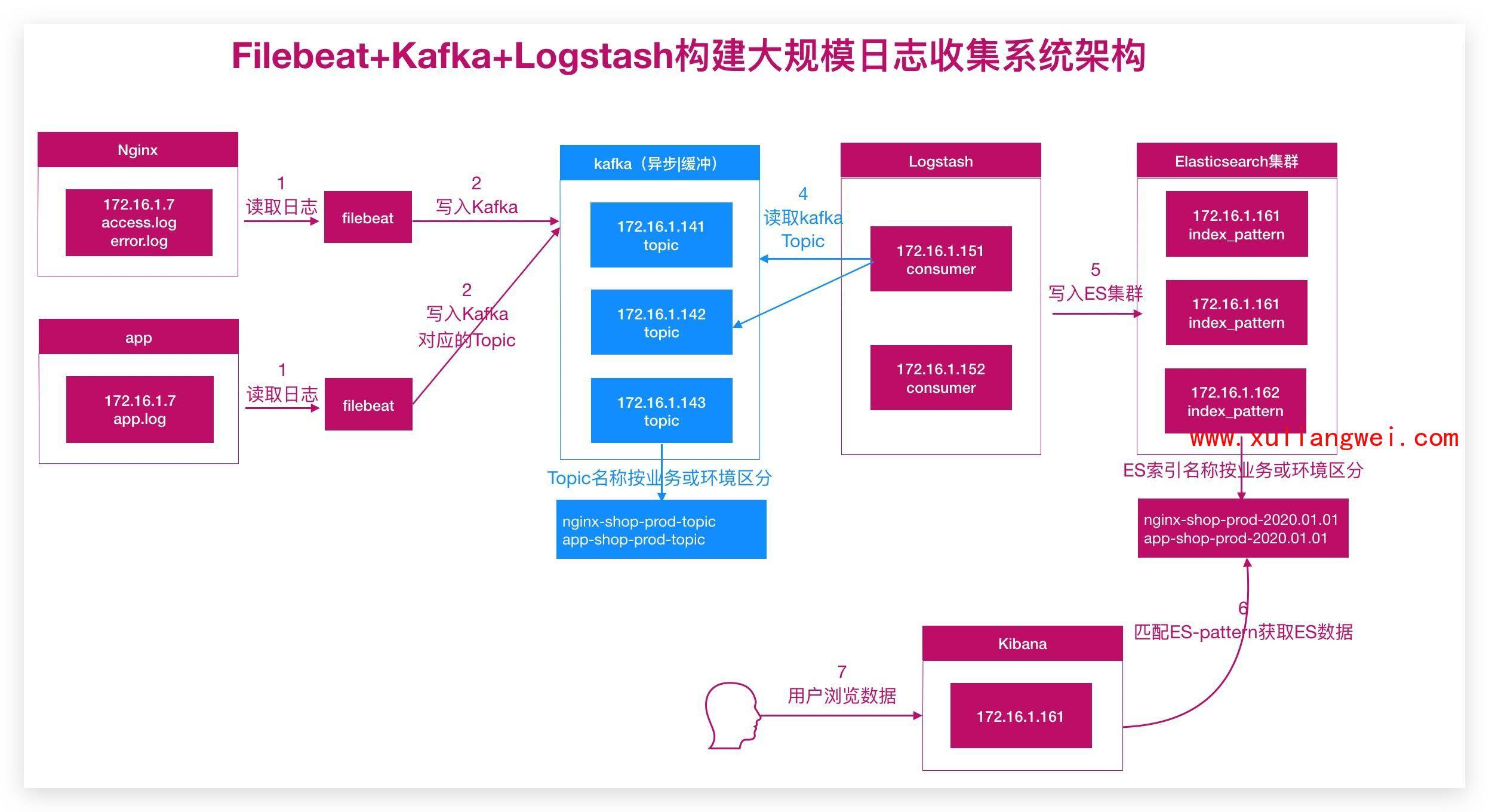
1.filebeat配置
[root@oldxu-web02-172 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
tags: ["access"]
- type: log
enabled: true
paths:
- /var/log/nginx/error.log
tags: ["error"]
output.kafka:
hosts: ["172.16.1.141:9092","172.16.1.142:9092","172.16.1.143:9092"]
topic: nginx_kafka_prod
2.logstash配置
[root@oldxu-logstash-node1-172 conf.d]# cat nginx_kafka_logstash_filter_es.conf
input {
kafka {
bootstrap_servers => "172.16.1.141:9092,172.16.1.142:9092,172.16.1.143:9092"
topics => ["nginx_kafka_prod"]
group_id => "logstash" #消费者组名称
client_id => "node1" #消费者组实例名称
consumer_threads => "3" #理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡,线程多于分区意味着某些线程将处于空闲状态
#topics_pattern => "app_prod*" #通过正则表达式匹配要订阅的主题
codec => "json"
}
}
filter {
if "access" in [tags][0] {
grok {
match => {
"message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:hostname} (?:%{QS:referrer}|-) (?:%{NOTSPACE:post_args}|-) %{QS:useragent} (?:%{QS:x_forward_for}|-) (?:%{URIHOST:upstream_host}|-) (?:%{NUMBER:upstream_response_code}|-) (?:%{NUMBER:upstream_response_time}|-) (?:%{NUMBER:response_time}|-)"
}
}
useragent {
source => "useragent"
target => "useragent"
}
geoip {
source => "clientip"
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
convert => ["bytes","integer"]
convert => ["response_time", "float"]
remove_field => ["message","agent","tags"]
add_field => {
"target_index" => "kafka-nginx-access-%{+YYYY.MM.dd}"
}
}
#提取referrer具体的域名/^"http/
if [referrer] =~ /http/ {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}' }
}
}
#提取用户请求资源类型以及资源ID编号
if "oldxu.com" in [referrer_host] {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:oldxu_type}/%{NOTSPACE:oldxu_res_id})?"' } }
}
} else if "error" in [tags][0] {
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
add_field => { "target_index" => "kafka-nginx-error-%{+YYYY.MM.dd}" }
}
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
index => "%{[target_index]}"
template_overwrite => true
}
}

若有收获,就点个赞吧
0 人点赞
