一,特殊字符
范围:Linux中的所有命令
| 符号 | 作用 |
|---|---|
| * | 匹配任意(0个或多个)字符,包括空字符串常用 |
| ? | 只匹配任意一个字符,有且只有一个,几乎不用 |
| [abcd] | 匹配其中任意一个字符 |
| [a-z] | 匹配其中任意一个字符 [1-9] |
| [!abcd] | 匹配其中的单个字符 取反 正则: [^abcd] |
| ~ | 用户家目录 |
| . | 代表当前目录 |
| 单引号(’’) | 所见即所得,被’’的内容不会发生变化 |
| 双引号(””) | 会解析变量或命令,在输出,和不加引号相同”” 表示一个整体 |
| 反引号(``) | 引用命令,可以解析命令,相当于$() |
| > | 标准输出 |
| 2> | 标准错误输出 |
| ; | 表示一个命令的结束 |
| # | 注释 |
| $ | 1.字符串前加$ ,代表字符串变量内容 2. 普通用户提示符 |
| \ | 逃脱符 |
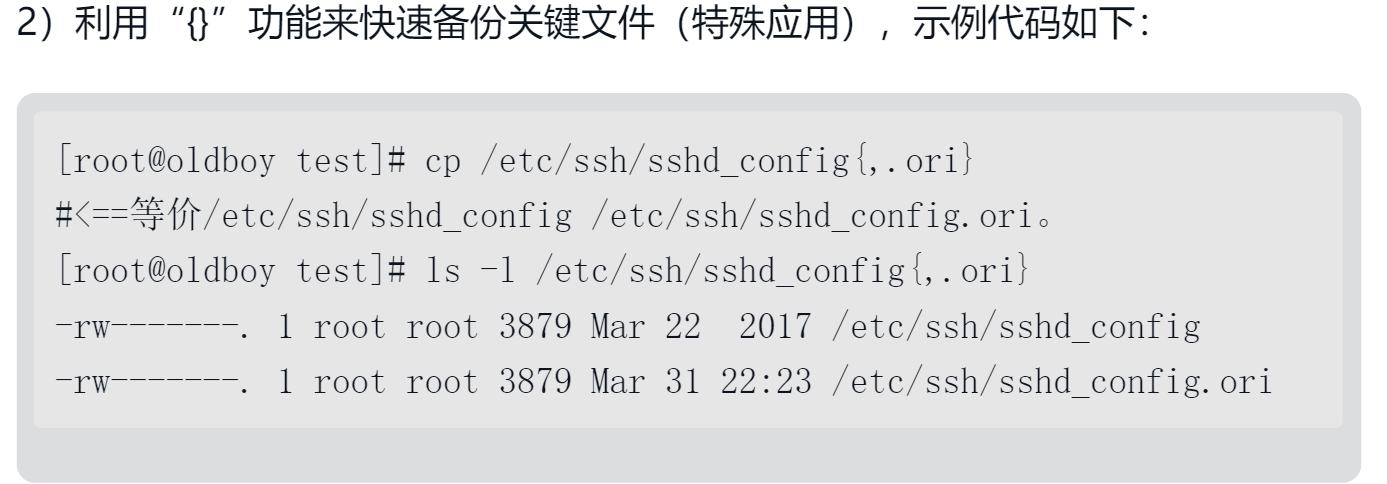
| {} | 1.生成序列 2.变量中表示分割作用 |
2. 对比 ‘’ “” {}

[root@oldboy ~]# echo 'oldboy $HOMEwhoami$(pwd) {1..5} '
oldboy $HOME whoami $(pwd) {1..5}
[root@oldboy ~]# [root@oldboy ~]# echo "oldboy $HOMEwhoami$(pwd) {1..5} "
oldboy /root root /root {1..5}
[root@oldboy ~]# echo oldboy $HOMEwhoami$(pwd) {1..5}
oldboy /root root /root 1 2 3 4 5
ps:
tr和xargs功能不能只通过标准输出
tr ‘a-z’ ‘1-9’ <b.txt
tr补充
[root@oldboy ~]# cat oldboy.txt aabbcc [root@oldboy ~]# tr ‘abc’ ‘123’ < oldboy.txt 112233
标准输出结合标准错误输出, 3种方法:
echo 11 1>>1.txt 2>>1.txt #会看 ech 11 >>1.txt 2>&1 #会看 ech 11 &>>1.txt #自己用
tar 推荐用相对目录形式打包
tar czf /存放路径/名称.tar.gz /root/data #源文件绝对路径,不推荐~ 系统默认一处压缩包中的 ‘/‘ (P参数可取消) tar czf /存放路径/名称.tar.gz ./date #源文件相对路径推荐~
ll -rt 可以在很多的文件中查看到最近修改的文件
3. 示例:
二,基础正则表达式
作用:处理大量字符串,处理文件内容的
范围:grep , sad ,awk | python go c | 开源软件nginx
| ^ | 以..开头的行 |
|---|---|
| $ | 以..结尾的行 |
| . | 任意一个字符 |
| * | 前一个字符出现0次或0次以上 |
| .* | 表示所有字符 贪婪性 |
| [abc] | 表示一个整体,匹配a或b或c |
| [^abc] | 表示一个整体,匹配除了a,除了b,除了c,除了abc 都匹配 |
| ^.* | 任意开头 |
| .*$ | 任意结尾 |

正则练习:
[root@web01 ~]# mkdir ~/test -p
[root@web01 ~]# cat >~/test/oldboy.txt<
> I teach linux.
>
> I like badminton ball ,billiard ball and chinese chess!
> our site is http://www.oldboyedu.com
> my qq num is 49000448.
>
> not 4900000448.
> my god ,i am not oldbey,but OLDBOY!
> EOF
^ : 以..开头的
[root@web01 test]# grep -i ^i ./oldboy.txt
I am oldboy teacher! I teach linux.
$ : 以..结尾的
[root@web01 test]# grep -i “m$” ./oldboy.txt
our site is http://www.oldboyedu.com
练习:过滤ls -l 结果是目录的
[root@web01 ~]# ll | grep ^d
drwxr-xr-x 2 root root 24 Sep 28 09:10 test [root@web01 ~]# ll -p | grep /$ drwxr-xr-x 2 root root 24 Sep 28 09:10 test/
* 匹配前一个字符0次或多次
(连续出现的,可以匹配空)
[root@web01 test]# grep “0*” oldboy.txt I am oldboy teacher! I teach linux.
I like badminton ball ,billiard ball and chinese chess!
our site is http://www.oldboyedu.com
my qq num is 49000448.
not 4900000448.
\ 转译字符 (不能匹配空行)
[root@web01 test]# grep “.“ oldboy.txt
I teach linux.
our site is http://www.oldboyedu.com
my qq num is 49000448.
not 4900000448.
^$ 匹配空行
[root@web01 test]# grep “^$” oldboy.txt
. 点号表示匹配任意一个且只有一个字符
.* 匹配所有
[root@web01 test]# grep “.*” oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
our site is http://www.oldboyedu.com
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
^. 以任意一个字符开头
[root@web01 test]# grep “^.” oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
our site is http://www.oldboyedu.com
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
^.* 匹配以多个字符开头
.*$ 匹配以多个字符结尾
[abc] 匹配括号内任意字符
[^abc] 匹配括号内任意字符取反不能用!
显示配置文件内容
显示/etc/ssh/sshd_config 内容排除空行和井号开头的行。
1.每个正则题目 尽量多种方法完成
2.只要遇到新的写法,分析,理解,吸收
[root@oldboy ~/test]# egrep -v ‘^$|^#’ oldboy.txt
[root@oldboy ~/test]# sed -r ‘/^$|^#/d’ oldboy.txt
(sed 取反)sed -nr ‘/^$|^#/!p’ /etc/ssh/sshd_config[root@oldboy ~/test]# awk ‘!/^$|^#/‘ oldboy.txt
[root@oldboy ~/test]# sed -nr ‘/^$|^#/!p’ oldboy.txt
扩展正则:
正则扩展:
应用范围: grep -E | egrep | awk | sed grep -w 严格匹配
| ERE 121 | 说明 |
|---|---|
| | | 或者 |
| + | 前一个字符连续出现(重复)1次或1次以上, +一般与[]搭配 |
| () | 表示一个整体,sed一般用于后向引用 |
| [: /]+ | 匹配括号内的 :或 / 一次到多次 |
{n,m} 前一个字符连续出现至少n次最多m次 {n} 前一个字符连续出现n次 {n,} 前一个字符连续出现至少n次 {,m} 前一个字符连续出现最多m次 |
|
[root@oldboy ~/test]# egrep '0{3,4}'oldboy.txtmy qq num is 49000448.not 4900000448.[root@oldboy ~/test]# egrep -o '0{3,4}'oldboy.txt0000000[root@oldboy ~/test]#[root@oldboy ~/test]# egrep '0{3}'oldboy.txtmy qq num is 49000448.not 4900000448.[root@oldboy ~/test]# egrep -o '0{3}'oldboy.txt6.3.3 取出网卡ip地址的n种方法000000

若有收获,就点个赞吧
0 人点赞
