- 3.1 Spark逻辑处理流程概览
- 3.2 Spark逻辑处理流程生成方法
- 3.3 常用transformation()数据操作
- 3.3.1 map()和mapValues()操作
- 3.3.2 filter()和filterByRange()操作
- 3.3.3 flatMap()和flatMapValues()操作
- 3.3.4 sample()和sampleByKey()操作
- 3.3.5 mapPartitions()和mapPartitionsWithIndex()操作
- 3.3.6 partitionBy()操作
- 3.3.7 groupByKey()操作
- 3.3.8 reduceByKey()操作
- 3.3.9 aggregateByKey()操作
- 3.3.10 combineByKey()操作
- 3.3.11 foldByKey()操作
- 3.3.12 cogroup()/groupWith()操作
- 3.3.13 join()操作
- 3.3.14 cartesian()操作
- 3.3.15 sortByKey()操作
- 3.3.16 coalesce()操作
- 3.3.17 repartition()操作
- 3.3.18 repartitionAndSortWithinPartitions()操作
- 3.3.19 intersection()操作
- 3.3.20 distinct()操作
- 3.3.21 union()操作
- 3.3.22 zip()操作
- 3.3.23 zipPartitions()操作
- 3.3.24 zipWithIndex()和zipWithUniqueId()操作
- 3.3.25 subtractByKey()操作
- 3.3.26 subtract()操作
- 3.3.27 sortBy(func)操作
- 3.3.28 glom()操作
- 3.4 常用action()数据操作
- 3.4.1 count()/countByKey()/countByValue()操作
- 3.4.2 collect()和collectAsMap()操作
- 3.4.3 foreach()和foreachPartition()操作
- 3.4.4 fold()/reduce()/aggregate()操作
- 3.4.5 treeAggregate ()和treeReduce()操作
- 3.4.6 reduceByKeyLocality()操作
- 3.4.7 take()/f irst()/takeOrdered()/top()操作
- 3.4.8 max()和min()操作
- 3.4.9 isEmpty()操作
- 3.4.10 lookup()操作
- 3.4.11 saveAsTextFile()/saveAsObjectFile()/saveAsHadoopFile()/saveAsSequenceFile()操作
- 3.5 对比MapReduce,Spark的优缺点
3.1 Spark逻辑处理流程概览
Spark在运行应用前,首先需要将应用程序转化为逻辑处理流程(Logical plan)。如图3.1所示。图3.1表示了从数据源开始经过了哪些处理步骤得到最终结果,还有中间数据及其依赖关系。
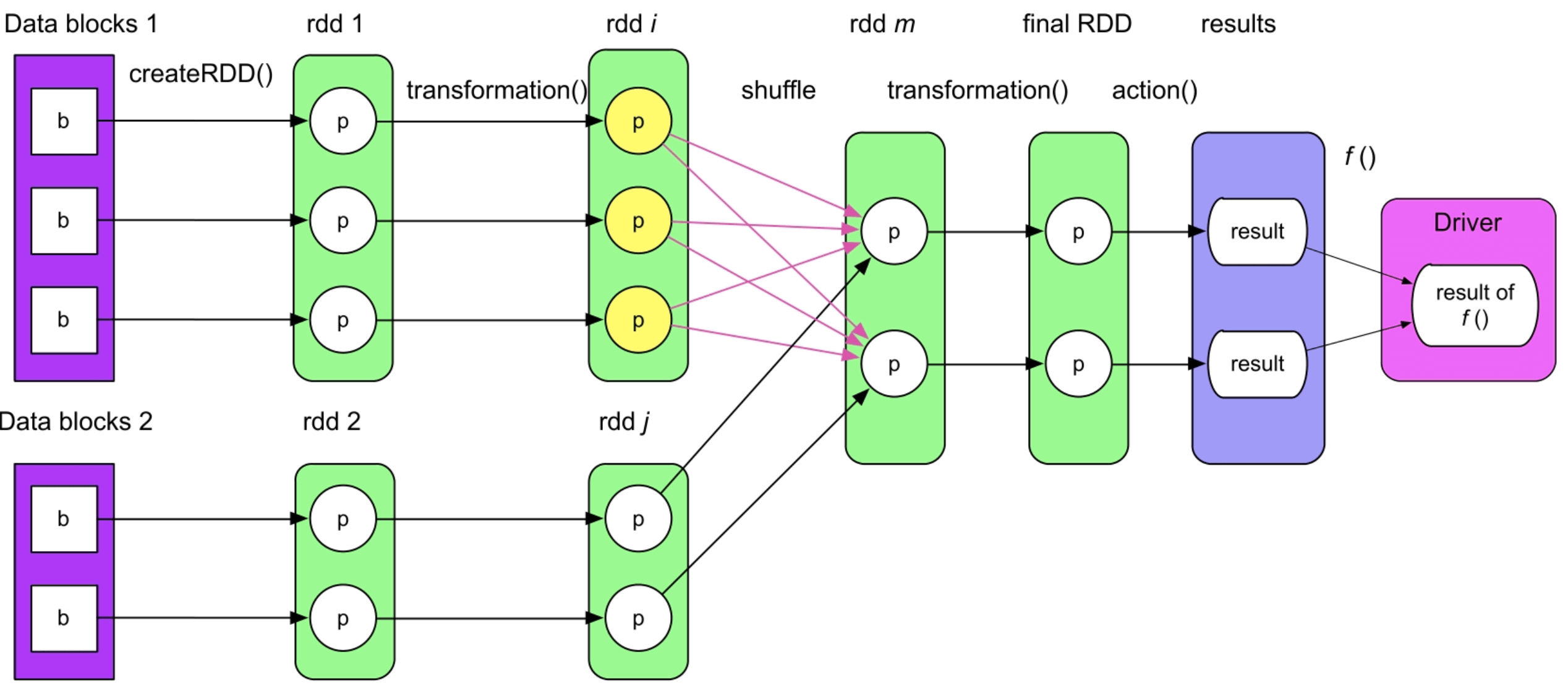
图3.1 一个典型的Spark逻辑处理流程
_
这个典型的逻辑处理流程主要包含四部分。
(1)数据源(Data blocks):数据源表示的是原始数据,数据可以存放在本地文件系统和分布式文件系统中,如HDFS、分布式Key-Value数据库(HBase)等。在IntelliJ IDEA中运行单机测试时,数据源可以是内存数据结构,如list(1,2,3,4,5);对于流式处理来说,数据源还可以是网络流等。
(2)数据模型:确定了数据源后,我们需要对数据进行操作处理。首要问题是如何对输入/输出、中间数据进行抽象表示,使得程序能够识别处理。
在使用普通的面向对象程序(C++/Java程序)处理数据时,我们将数据抽象为对象(object),如doubleObject=new Double(2.0)、listObject=new ArrayList()。然后,我们可以在对象上定义数据操作,如doubleObject.longValue()可以将数据转化为long类型,listObject.add(i,Value)可以在list的第i个位置插入一个元素Value。
Hadoop MapReduce框架将输入/输出、中间数据抽象为
record,这种数据表示方式的优点是简单易操作,缺点是过于细粒度。没有对这些<;K,V>;record进行更高层的抽象,导致只能使用map(K,V)这样的固定形式去处理数据,而无法使用类似面向对象程序的灵活数据处理方式。
Spark认知到了这个缺点,将输入/输出、中间数据抽象表示为统一的数据模型(数据结构),命名为RDD(Resilient Distributed Datasets)。每个输入/输出、中间数据可以是一个具体的实例化的RDD,如第2章介绍的ParallelCollectionRDD等。RDD中可以包含各种类型的数据,可以是普通的Int、Double,也可以是<;K,V>;record等。RDD与普通数据结构(如ArrayList)的主要区别有以下两点。
RDD只是一个逻辑概念,在内存中并不会真正地为某个RDD分配存储空间(除非该RDD需要被缓存)。RDD中的数据只会在计算中产生,而且在计算完成后就会消失,而ArrayList等数据结构常驻内存。
RDD可以包含多个数据分区,不同数据分区可以由不同的任务(task)在不同节点进行处理。
(3)数据操作:定义了数据模型后,我们可以对RDD 进行各种数据操作,Spark将这些数据操作分为两种:transformation()操作和action()操作。
两者的区别是action()操作一般是对数据结果进行后处理(post-processing),产生输出结果,而且会触发Spark提交job真正执行数据处理任务。transformation这个词隐含了一个意思是单向操作,也就是rdd1使用transformation()后,会生成新的rdd2,而不能对rdd1本身进行修改。
在Spark中,因为数据操作一般是单向操作,通过流水线执行,还需要进行错误容忍等,所以RDD被设计成一个不可变类型,可以类比成一个不能修改其中元素的ArrayList。
(4)计算结果处理:由于RDD实际上是分布在不同机器上的,所以大数据应用的结果计算分为两种方式:一种方式是直接将计算结果存放到分布式文件系统中,如rdd.save(“hdfs://file_location”),这种方式一般不需要在Driver端进行集中计算;另一种方式是需要在Driver端进行集中计算,如统计RDD中元素数目,需要先使用多个task统计每个RDD中分区(partition)的元素数目,然后将它们汇集到Driver端进行加和计算。
3.2 Spark逻辑处理流程生成方法
Spark框架需要解决以下3个问题:
- 根据应用程序如何产生RDD,产生什么样的RDD?
- 如何建立RDD之间的数据依赖关系?
- 如何计算RDD中的数据?
3.2.1 根据应用程序如何产生RDD,产生什么样的RDD
一种简单解决方法是对程序中的每一个数据进行操作,也就是用transformation()方法返回(创建)一个新的RDD。
一些复杂的transformation(),如join()、distinct()等,需要对中间数据进行一系列子操作,那么一个transformation()会创建多个RDD。例如,rdd3=rdd1.join(rdd2)需要先将rdd1和rdd2中的元素聚合在一起,然后使用笛卡儿积操作生成关联后的结果,在这个过程中会生成多个RDD。Spark依据这些子操作的顺序,将生成的多个RDD串联在一起,而且只返回给用户最后生成的RDD。这就是Spark实际创建出的RDD个数比我们想象的多一些的原因。
RDD的类型有多种,如ParallelCollectionRDD、MapPartitionsRDD、ShuffledRDD等。
为什么会有这么多不同类型的RDD,应该产生哪些RDD?虽然我们用RDD来对输入/输出、中间数据进行统一抽象,但这些数据本身可能具有不同的类型,而且是由不同的计算逻辑得到的,可能具有不同的依赖关系。因此,我们需要多种类型的RDD来表示这些不同的数据类型、不同的计算逻辑,以及不同的数据依赖。
Spark实际产生的RDD类型和个数与transformation()的计算逻辑有关,官网上也给出了典型的transformation()操作及其创建的RDD。
3.2.2 如何建立RDD之间的数据依赖关系
数据依赖关系包括两方面:
- 一方面是RDD之间的依赖关系,如一些transformation()会对多个RDD进行操作,则需要建立这些RDD之间的关系。
- 另一方面是RDD本身具有分区特性,需要建立RDD自身分区之间的关联关系。
具体地,我们需要解决以下3个问题。
(1)如何建立RDD之间的数据依赖关系?例如,生成的RDD是依赖于一个parent RDD,还是多个parent RDD?
这个问题可以很自然地解决,对于一元操作,如rdd2=rdd1.transformation()可以确定rdd2只依赖rdd1,所以关联关系是“rdd1=>rdd2”。对于二元操作,如rdd3=rdd1.join(rdd2),可以确定rdd3同时依赖rdd1和rdd2,关联关系是“(rdd1,rdd2)=>rdd3”。二元以上的操作可以类比二元操作。
(2)新生成的RDD应该包含多少个分区?
在Spark中,新生成的RDD的分区个数由用户和parent RDD共同决定,对于一些transformation(),如join()操作,我们可以指定其生成的分区的个数,如果个数不指定,则一般取其parent RDD的分区个数最大值。还有一些操作,如map(),其生成的RDD的分区个数与数据源的分区个数相同。
(3)新生成的RDD与其parent RDD中的分区间是什么依赖关系?是依赖parent RDD中的一个分区还是多个分区呢?
分区之间的依赖关系既与transformation() 的语义有关,也与RDD的分区个数有关。例如,在执行rdd2=rdd1.map()时,map()对rdd1的每个分区中的每个元素进行计算,可以得到新的元素,类似一一映射,所以并不需要改变分区个数,即rdd2的每个分区唯一依赖rdd1中对应的一个分区。而对于groupByKey()之类的聚合操作,在计算时需要对parent RDD中各个分区的元素进行计算,需要改变分区之间的依赖关系,使得RDD中的每个分区依赖其parent RDD中的多个分区。
理论上,分区之间的数据依赖关系可以灵活自定义,如一一映射、多对一映射、多对多映射或者任意映射等。但实际上,常见数据操作的数据依赖关系具有一定的规律,Spark通过总结这些数据操作的数据依赖关系,将其分为两大类,具体如下所述。
窄依赖(NarrowDependency)
**
窄依赖的官方解释是:“Base class for dependencies where each partition of the child RDD depends on a small number of partitions of the parent RDD.Narrow dependencies allow for pipelined execution。”
中文意思:“如果新生成的child RDD中每个分区都依赖parent RDD中的一部分分区,那么这个分区依赖关系被称为NarrowDependency。”
RDD及其分区之间的数据依赖关系类型如图3.2所示。窄依赖可以进一步细分为4种依赖。
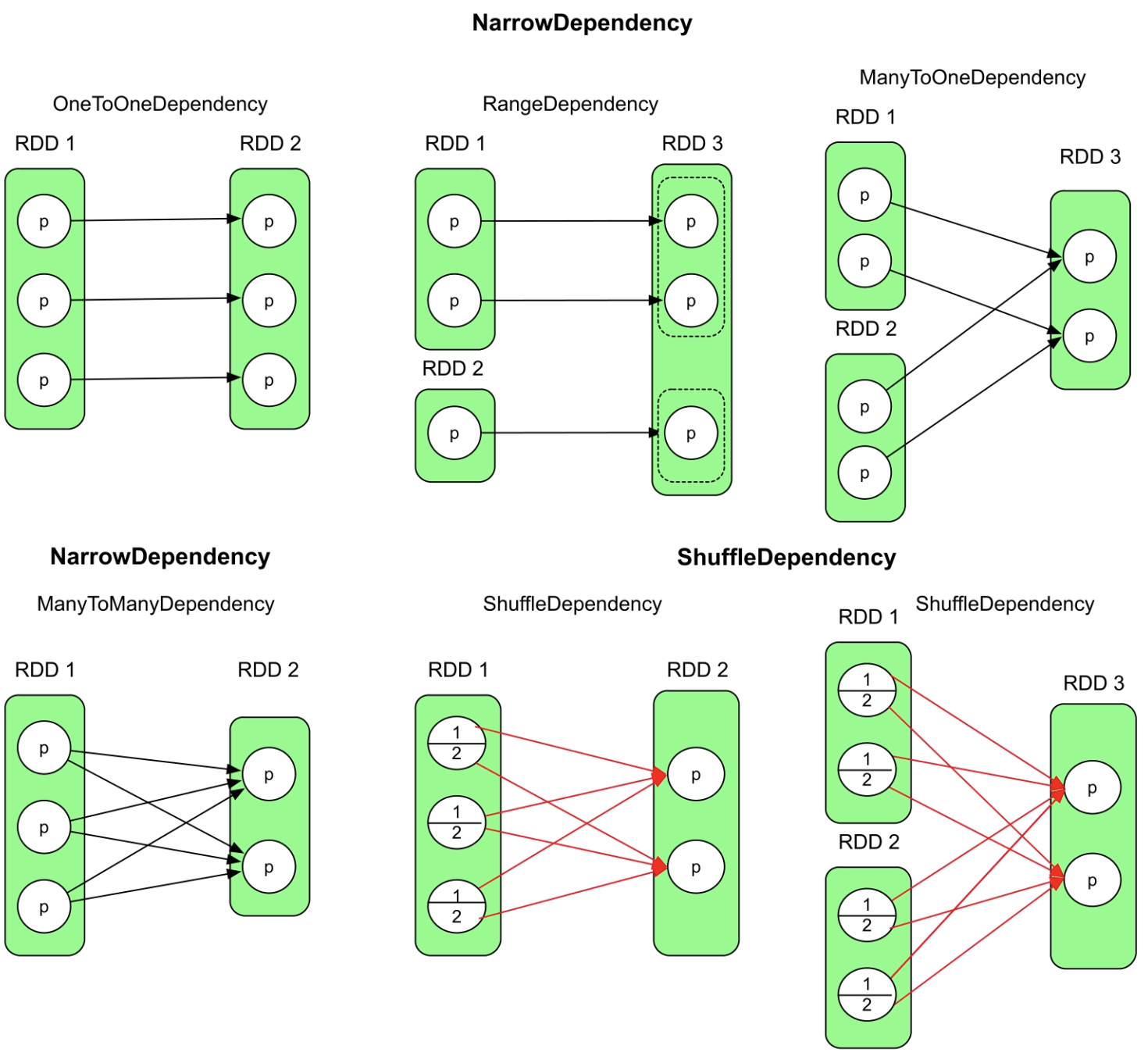
图3.2 RDD及其分区之间的数据依赖关系类型
_
对一依赖(OneToOneDependency):一对一依赖表示child RDD和parent RDD中的分区个数相同,并存在一一映射关系。典型的transformation()包括map()、fliter()等。
区域依赖(RangeDependency):表示child RDD和parent RDD的分区经过区域化后存在一一映射关系。典型的transformation()包括union()等。
多对一依赖(ManyToOneDependency):表示child RDD中的一个分区同时依赖多个parent RDD中的分区。典型的transformation()包括具有特殊性质的cogroup()、join()等,这个特殊性质将在3.3节中详细介绍。
多对多依赖(ManyToManyDependency):表示child RDD中的一个分区依赖parent RDD中的多个分区,同时parent RDD中的一个分区被child RDD中的多个分区依赖。典型的transformation()是cartesian()。
宽依赖(ShuffleDependency)
**
宽依赖的官方解释是:“Represents a dependency on the output of a shuffle stage。”
这个解释是从实现角度来讲的,如果从数据流角度解释,宽依赖表示新生成的child RDD中的分区依赖parent RDD中的每个分区的一部分。
窄依赖、宽依赖的区别是child RDD的各个分区是否完全依赖parent RDD的一个或者多个分区。如果parent RDD的一个或者多个分区中的数据需要全部流入child RDD的某一个或者多个分区,则是窄依赖。如果parent RDD分区中的数据需要一部分流入child RDD的某一个分区,另外一部分流入child RDD的另外分区,则是宽依赖。
对数据依赖(Dependency)进行分类有什么用处”?这样做首先可以明确RDD分区之间的数据依赖关系;其次,对数据依赖进行分类有利于生成物理执行计划。NarrowDependency在执行时可以在同一个阶段进行流水线(pipeline)操作,不需要进行Shuffle,而ShuffleDependency需要进行Shufle;最后,对数据依赖进行分类有利于代码实现。
我们还需要解决的一个问题是如何对RDD内部的数据进行分区?常用的数据分区方法(Partitioner)包括3种:水平划分、Hash划分(HashPartitioner)和Range划分(RangePartitioner)。
水平划分:按照record的索引进行划分。
例如,我们经常使用的sparkContext.parallelize(list(1,2,3,4,5,6,7,8,9),3),就是按照元素的下标划分,(1,2,3)为一组,(4,5,6)为一组,(7,8,9)为一组。这种划分方式经常用于输入数据的划分,如使用Spark处理大数据时,我们先将输入数据上传到HDFS上,HDFS自动对数据进行水平划分,也就是按照128MB为单位将输入数据划分为很多个小数据块(block),之后每个Spark task可以只处理一个数据块。
Hash划分(HashPartitioner):使用record的Hash值来对数据进行划分,该划分方法的好处是只需要知道分区个数,就能将数据确定性地划分到某个分区。在水平划分中,由于每个RDD中的元素数目和排列顺序不固定,同一个元素在不同RDD中可能被划分到不同分区。而使用HashPartitioner,可以根据元素的Hash值,确定性地得出该元素的分区。该划分方法经常被用于数据Shuffle阶段。
Range划分(RangePartitioner):该划分方法一般适用于排序任务,核心思想是按照元素的大小关系将其划分到不同分区,每个分区表示一个数据区域。
例如,我们想对一个数组进行排序,数组里每个数字是[0,100]中的随机数,Range划分首先将上下界[0,100]划分为若干份(如10份),然后将数组中的每个数字分发到相应的分区,如将18分发到(10,20]的分区,最后对每个分区进行排序,这个排序过程可以并行执行,排序完成后是全局有序的结果。Range划分经常采用抽样方法来估算数据区域边界。
3.2.3 如何计算RDD中的数据
在确定了数据依赖关系后,相当于我们知道了child RDD中每个分区的输入数据是什么,那么只需要使用transformation(func)处理这些输入数据,将生成的数据推送到child RDD中对应的分区即可。
Spark中的大多数transformation()类似数学中的映射函数,具有固定的计算方式(控制流),如map(func)操作需要每读入一个record,就进行处理,然后输出一个record。reduceByKey(func)操作中的func对中间结果和下一个record进行聚合计算并输出结果。
Spark中mapPartitions()的计算逻辑更接近Hadoop MapReduce中的map()和cleanup()函数。在Hadoop MapReduce中,map()函数对每个到来的
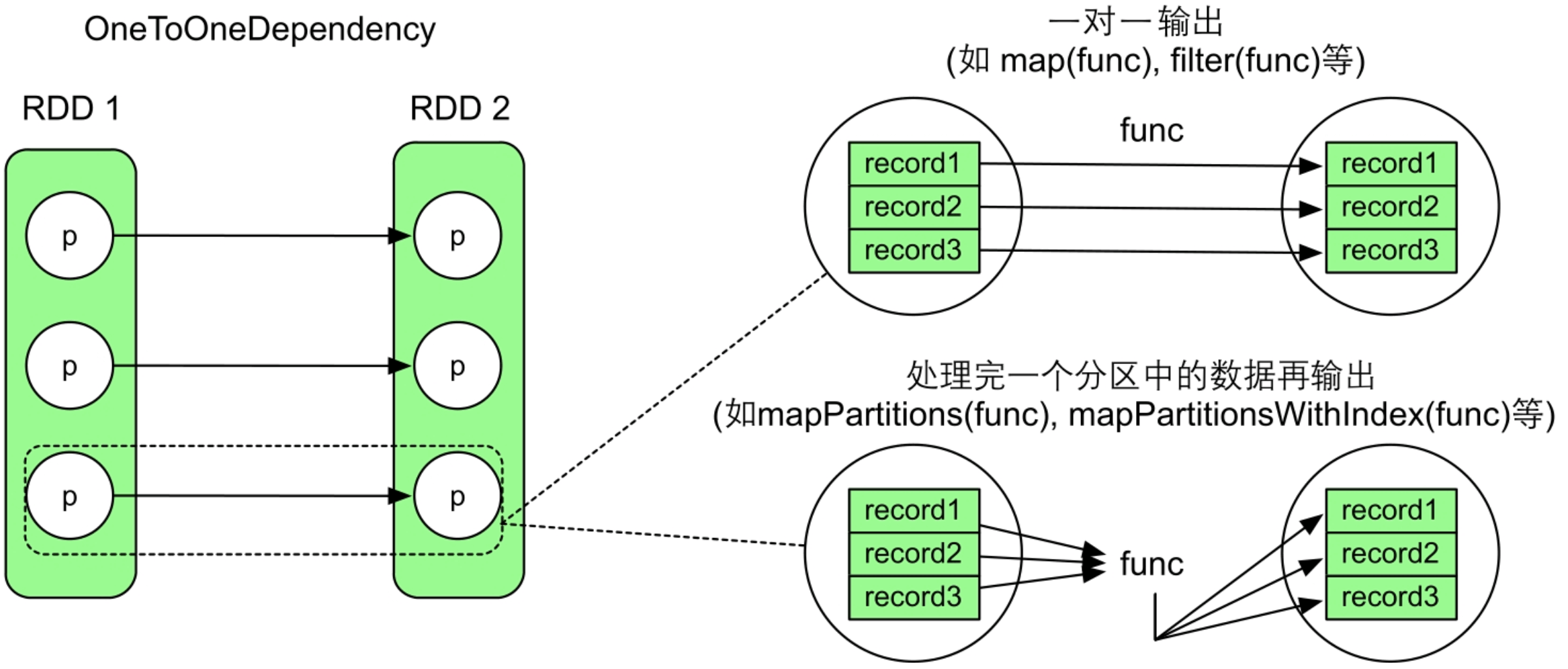
图3.3 RDD中数据的计算过程示例
3.3 常用transformation()数据操作
3.3.1 map()和mapValues()操作
**
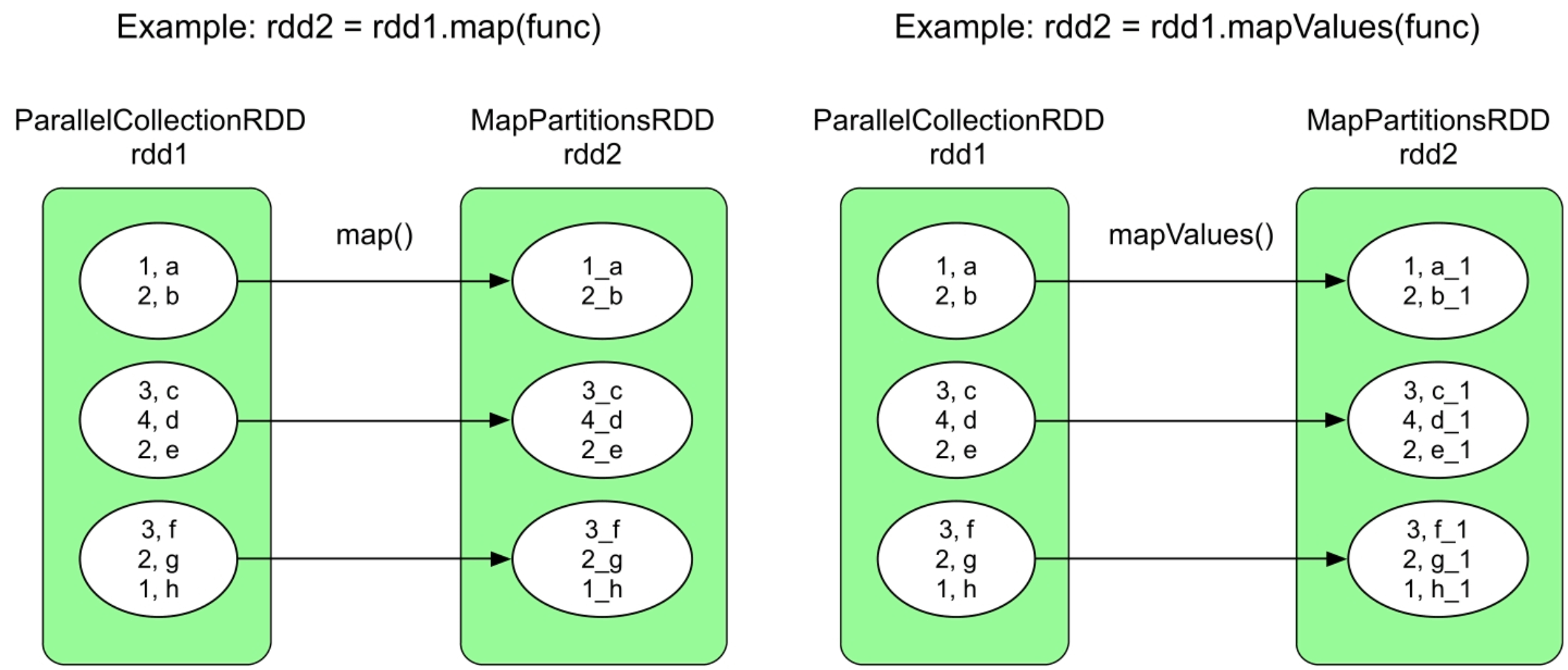
图3.4 map()和mapValues()操作的逻辑处理流程示例
_
map()和mapValues()操作都会生成一个MapPartitionsRDD,这两个操作生成的数据依赖关系都是OneToOneDependency。
3.3.2 filter()和filterByRange()操作

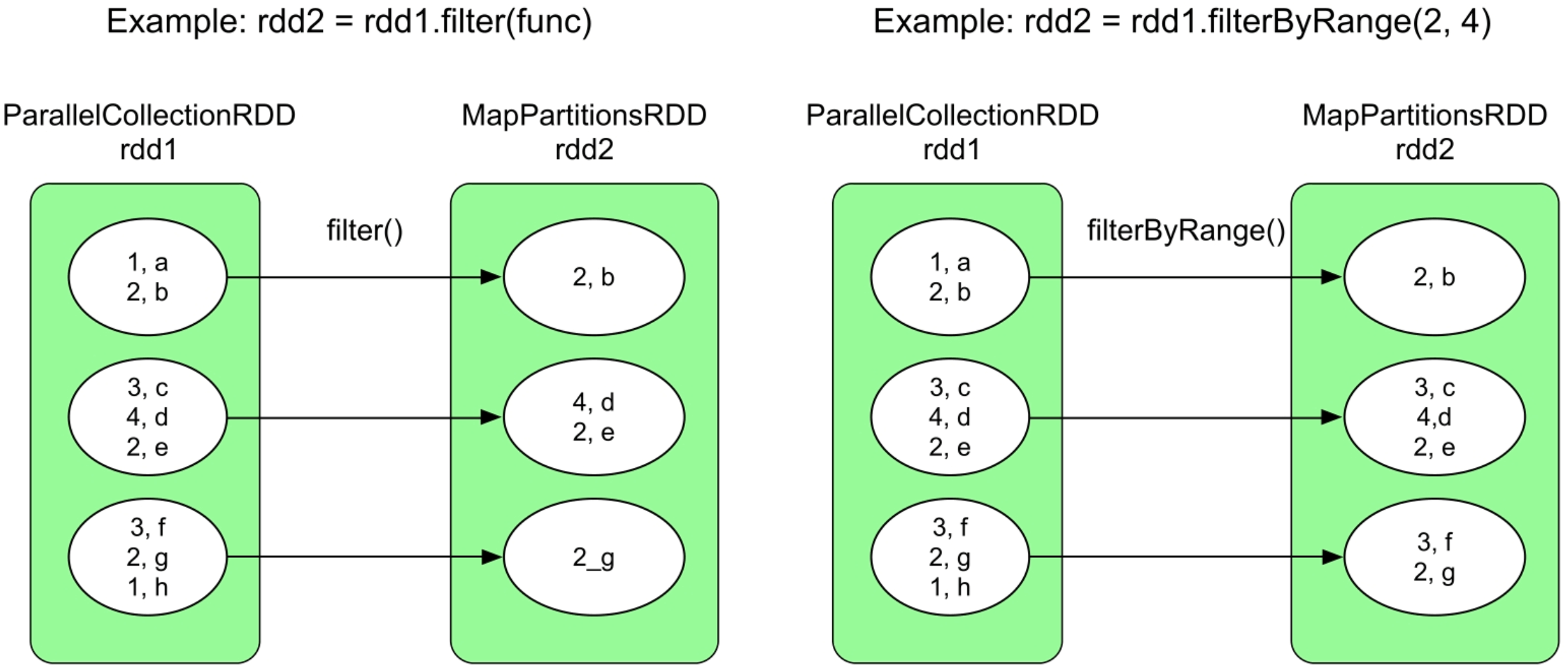
图3.5 filter()和filterByRange()操作的逻辑处理流程示例
filter()和filterByRange()操作都会生成一个MapPartitionsRDD,这两个操作生成的数据依赖关系都是OneToOneDependency。
3.3.3 flatMap()和flatMapValues()操作
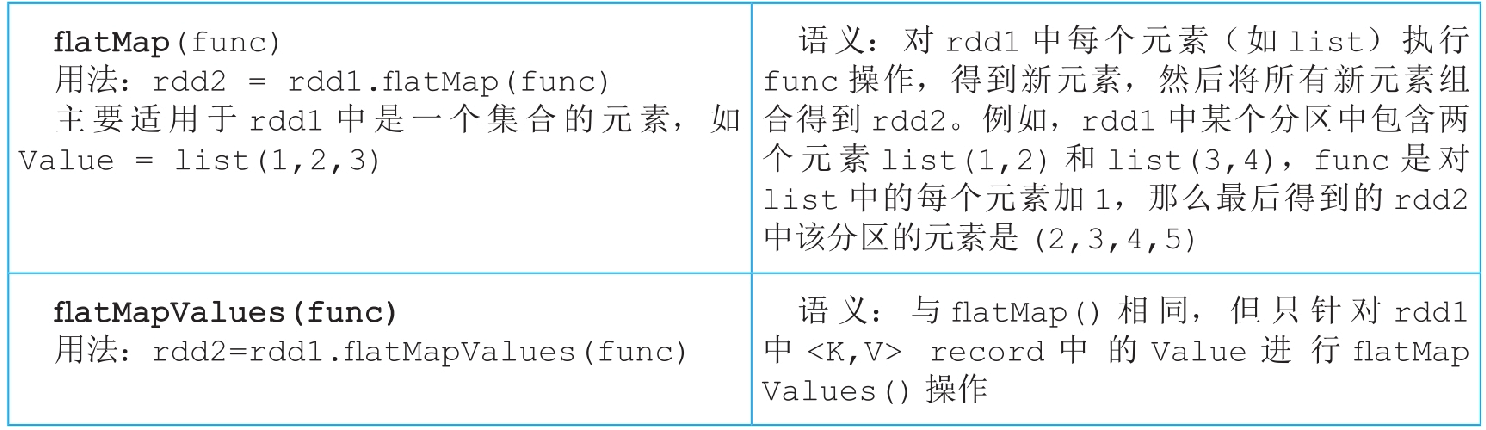
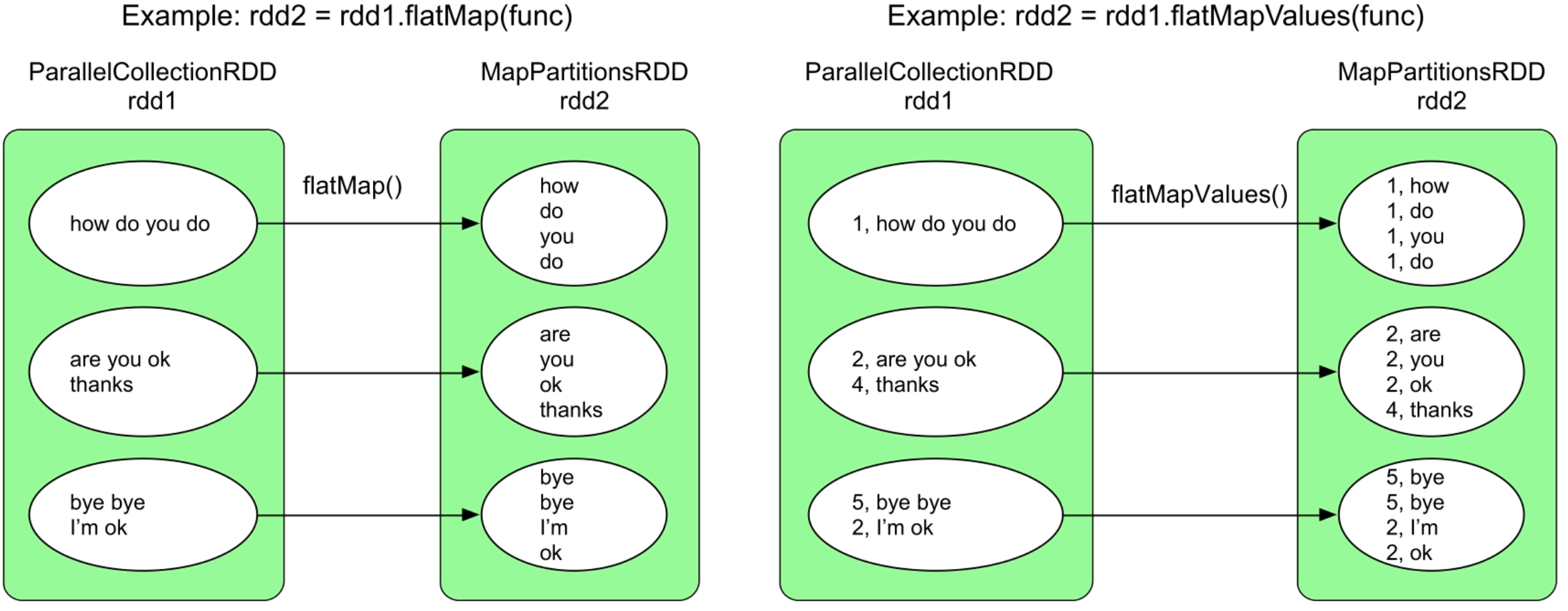
图3.6 flatMap()和flatMapValues()操作的逻辑处理流程示例
_
flatMap()和flatMapValues()操作都会生成一个MapPartitionsRDD,这两个操作生成的数据依赖关系都是OneToOneDependency。
3.3.4 sample()和sampleByKey()操作

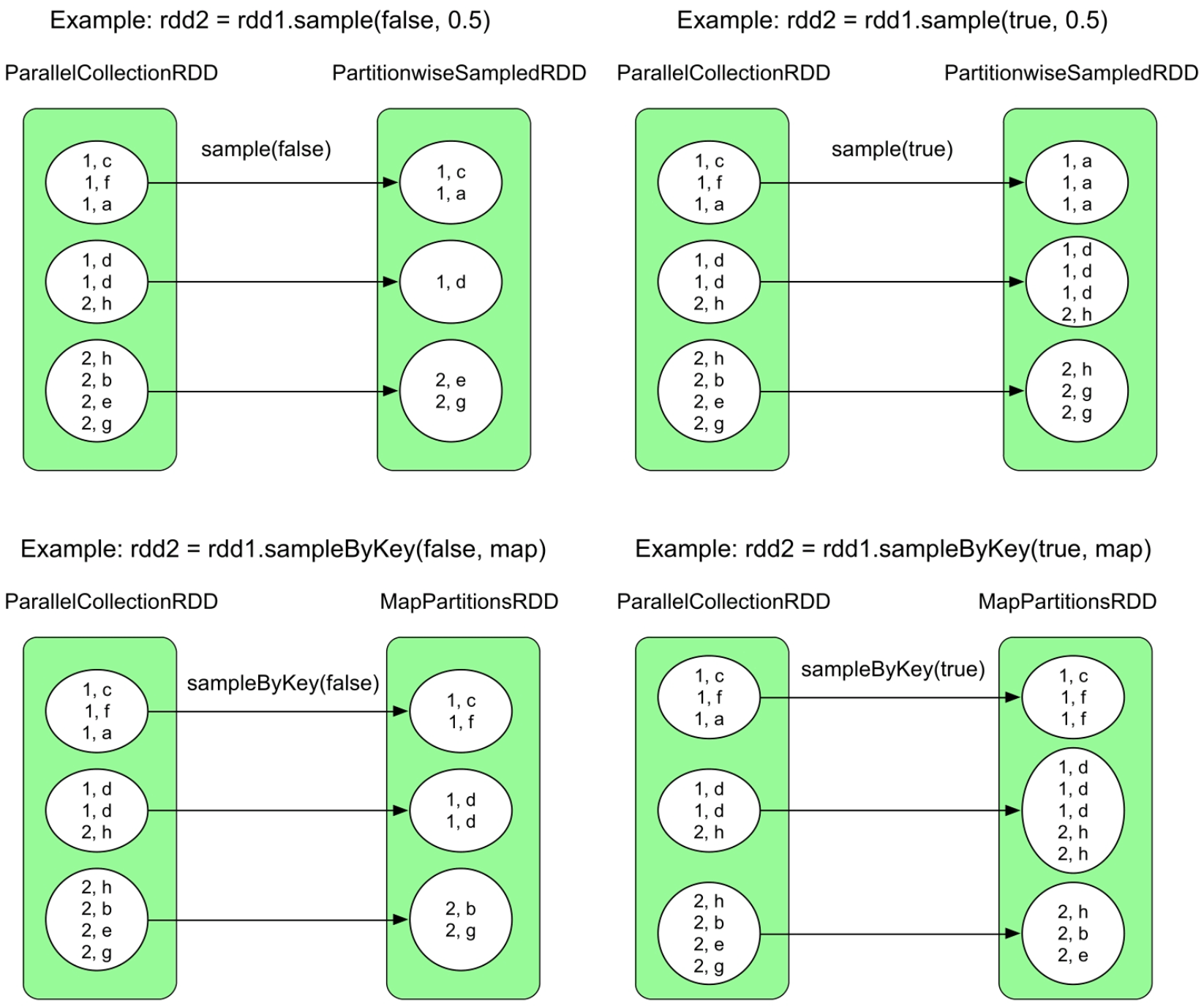
图3.7 sample()和sampleByKey()操作的逻辑处理流程示例
_
sample()操作生成一个PartitionwiseSampledRDD,而sampleByKey()操作生成一个MapPartitionsRDD,这两个操作生成的数据依赖关系都是OneToOneDependency。sample(false)与sample(true)的区别是,前者使用伯努利抽样模型抽样,也就是每个record有fraction×100%的概率被选中,如图3.7所示的第一个图中,每个分区中有1~2个record被选中;后者使用泊松分布抽样,也就是生成泊松分布,然后按照泊松分布采样,抽样得到的record个数可能大于rdd1中的record个数。
sampleByKey()与sample()的区别是,sampleByKey()可以为每个Key设定被抽取的概率。
sample()和sampleByKey()操作都会生成一个MapPartitionsRDD,这两个操作生成的数据依赖关系都是OneToOneDependency。
3.3.5 mapPartitions()和mapPartitionsWithIndex()操作

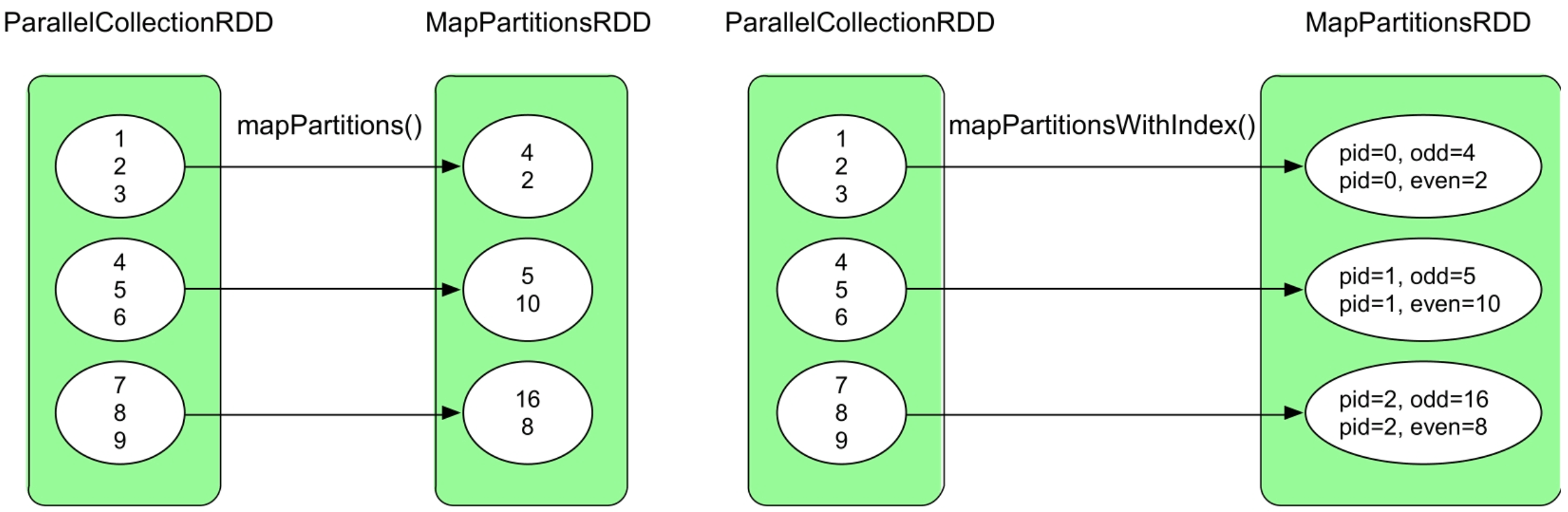
图3.8 mapPartitions()和mapPartitionsWithIndex()操作的逻辑处理流程示例
mapPartitions()和mapPartitionsWithIndex()操作更像是过程式编程,给定了一组数据后,可以使用数据结构持有中间处理结果,也可以输出任意大小、任意类型的一组数据。这两个操作还可以用来实现数据库操作。
3.3.6 partitionBy()操作

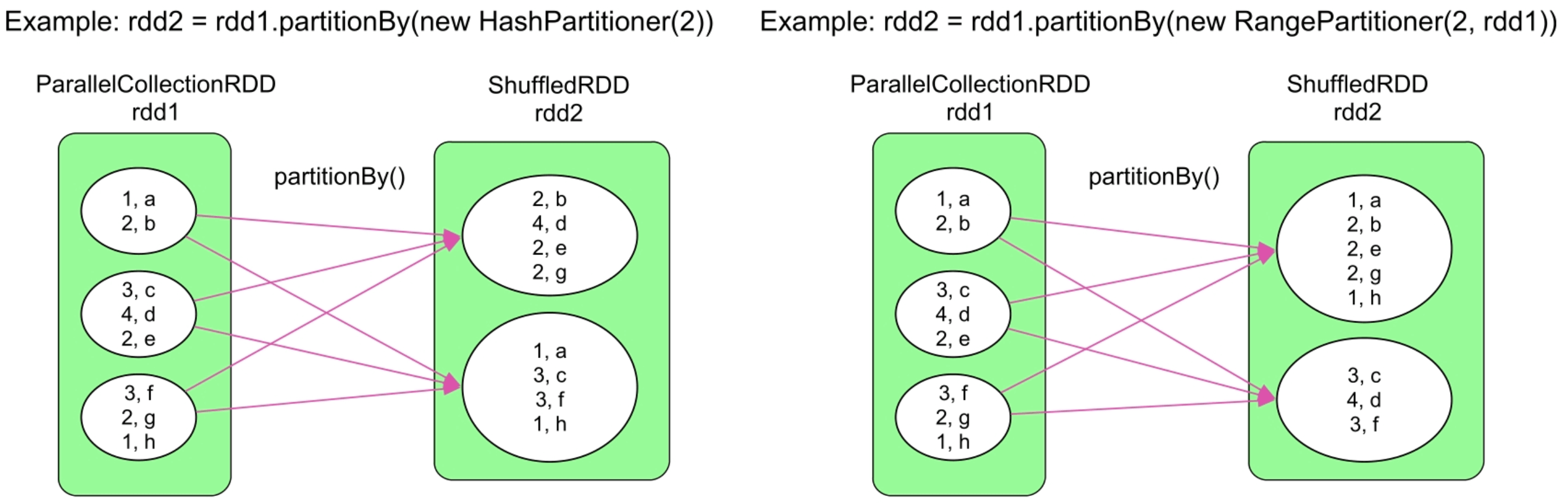
图3.9 partitionBy()的逻辑处理流程示例
3.3.7 groupByKey()操作

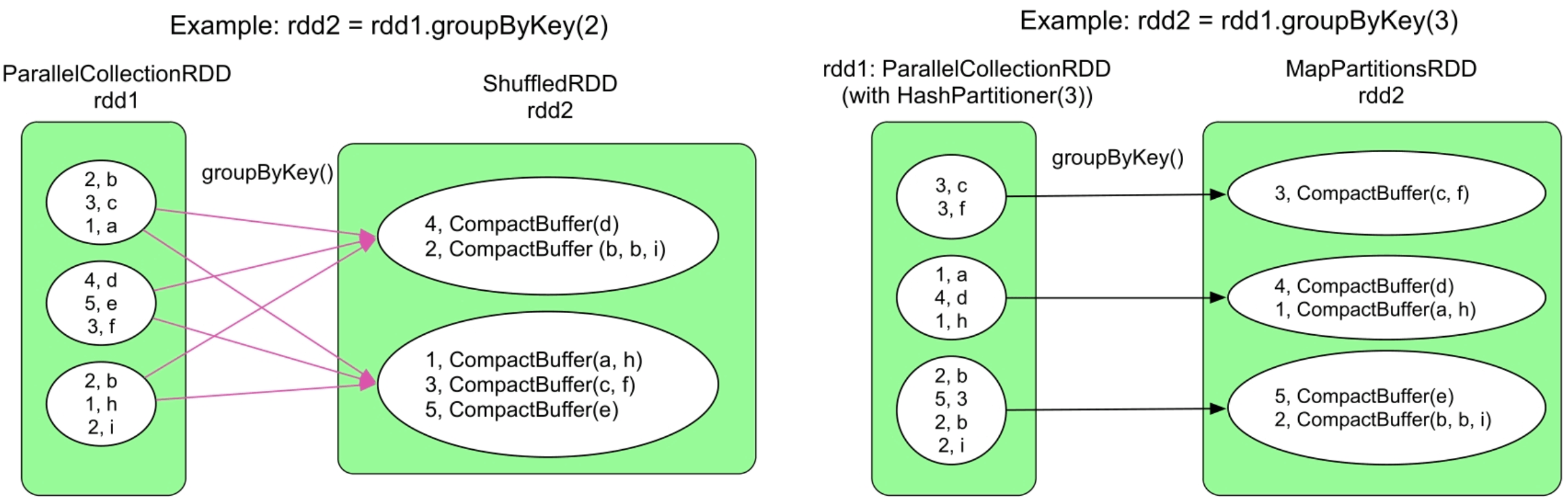
图3.10 groupByKey()操作的逻辑处理流程示例
groupByKey()在不同情况下会生成不同类型的RDD和数据依赖关系。在通常情况下,rdd1.partitioner与rdd2.partitioner不同,因此会产生ShuffleDependency。
与前面介绍的只包含NarrowDependency的transformation()不同,groupByKey()引入了ShuffleDependency,可以对child RDD的数据进行重新分区组合,因此,groupByKey()输出的parent RDD的分区个数更加灵活,分区个数(numPartitions)可以由用户指定,如果用户没有指定就默认为parent RDD中的分区个数。
注意:groupByKey()的缺点是在Shuffle时会产生大量的中间数据、占用内存大(具体在下一章中介绍),因此在多数情况下会选用下面要介绍的reduceByKey()进行操作。
3.3.8 reduceByKey()操作

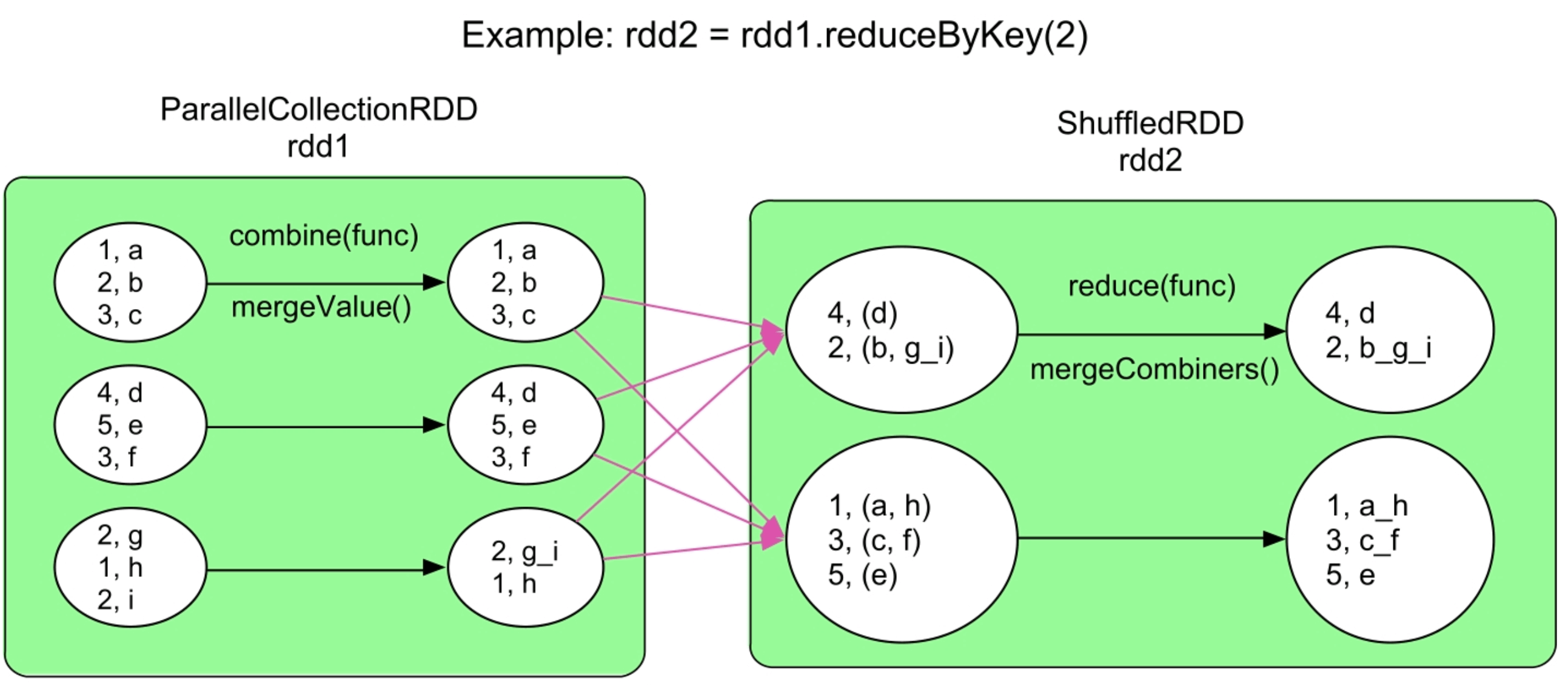
图3.11 reduceByKey()操作的逻辑处理流程示例
_
与groupByKey()只在ShuffleDependency后按Key对数据进行聚合不同,reduceByKey()实际包括两步聚合。第1步,在ShuffleDependency之前对RDD中每个分区中的数据进行一个本地化的combine()聚合操作(也称为mini-reduce或者map端combine())。首先对ParallelCollectionsRDD中的每个分区进行combine()操作,将具有相同Key的Value聚合在一起,并利用func进行reduce()聚合操作,这一步由Spark自动完成,并不形成新的RDD。第2步,reduceByKey()生成新的ShuffledRDD,将来自rdd1中不同分区且具有相同Key的数据聚合在一起,同样利用func进行reduce()聚合操作。在reduceByKey()中,combine()和reduce()的计算逻辑一样,采用同一个func。需要注意的是,func需要满足交换律和结合律,因为Shuffle并不保证数据到达顺序。另外,因为ShuffleDependency需要对Key进行Hash划分,所以,Key不能是特别复杂的类型,如Array。
在性能上,相比groupByKey()、reduceByKey()可以在Shuffle之前使用func对数据进行聚合,减少了数据传输量和内存用量,效率比groupByKey()的效率高。
3.3.9 aggregateByKey()操作

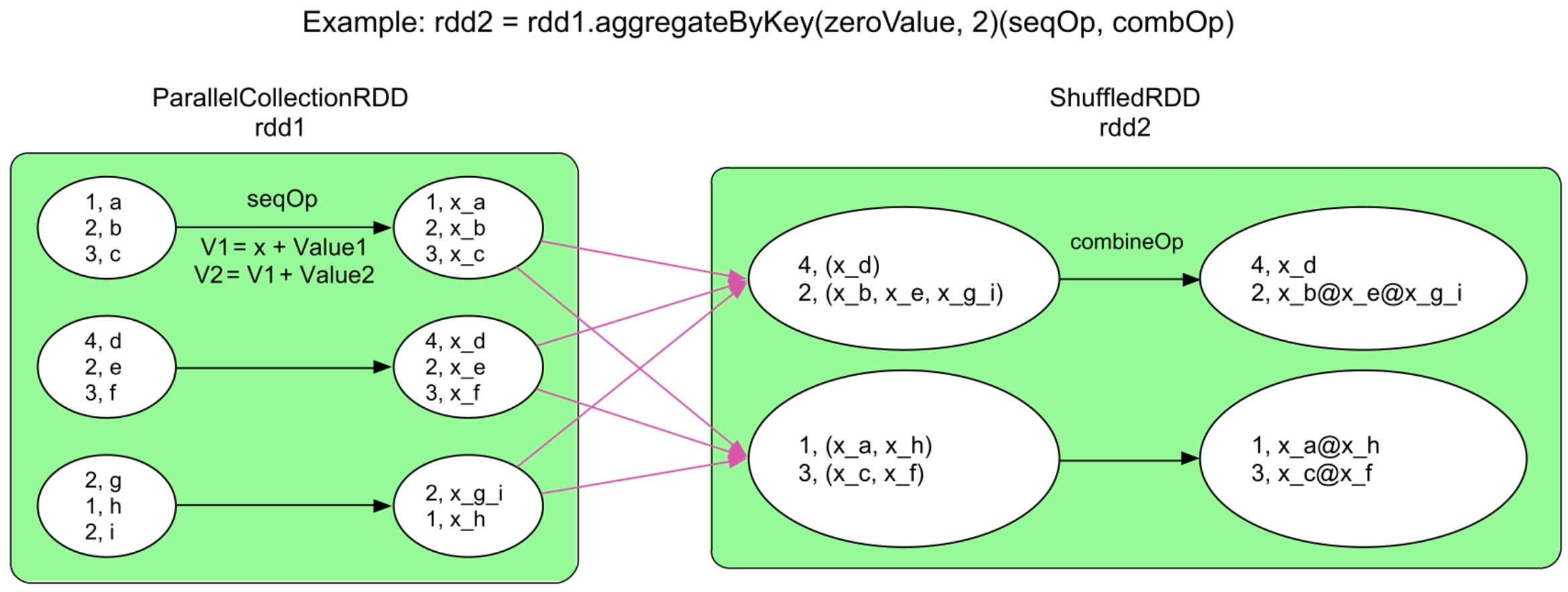
图3.12 aggregateByKey()操作的逻辑处理流程示例
为什么已经有了reduceByKey(),还要定义aggregate-ByKey()呢?因为reduceByKey()的灵活性较低,前面介绍过reduceByKey()中的combine()计算逻辑与reduce()一样,都采用func,这样会限制某些需要不一样处理的应用,如在combine()中想使用一个sum()函数,而在reduce()中想使用max()函数,那么reduceByKey()就不满足要求了。所以,aggregateByKey()将combine()和reduce()两个函数的计算逻辑分开,combine()使用seqOp将同一个分区中的
aggregateByKey()与reduceByKey()还有一处不同,对比一下两者的定义可以发现,在reduceByKey()中,func要求参与聚合的record和输出结果是同一个类型(类型Value),而在aggregateByKey()中,zeroValue和record可以是不同类型,但seqOp的输出结果与zeroValue是同一类型的,这在一定程度上提高了灵活性。
另外,reduceByKey()可以看作特殊版的aggregateByKey()。在后面章节中我们会看到,当seqOp处理的中间数据量很大,出现Shuffle spill的时候,Spark会在map端执行combOp(),将磁盘上经过seqOp处理的
3.3.10 combineByKey()操作

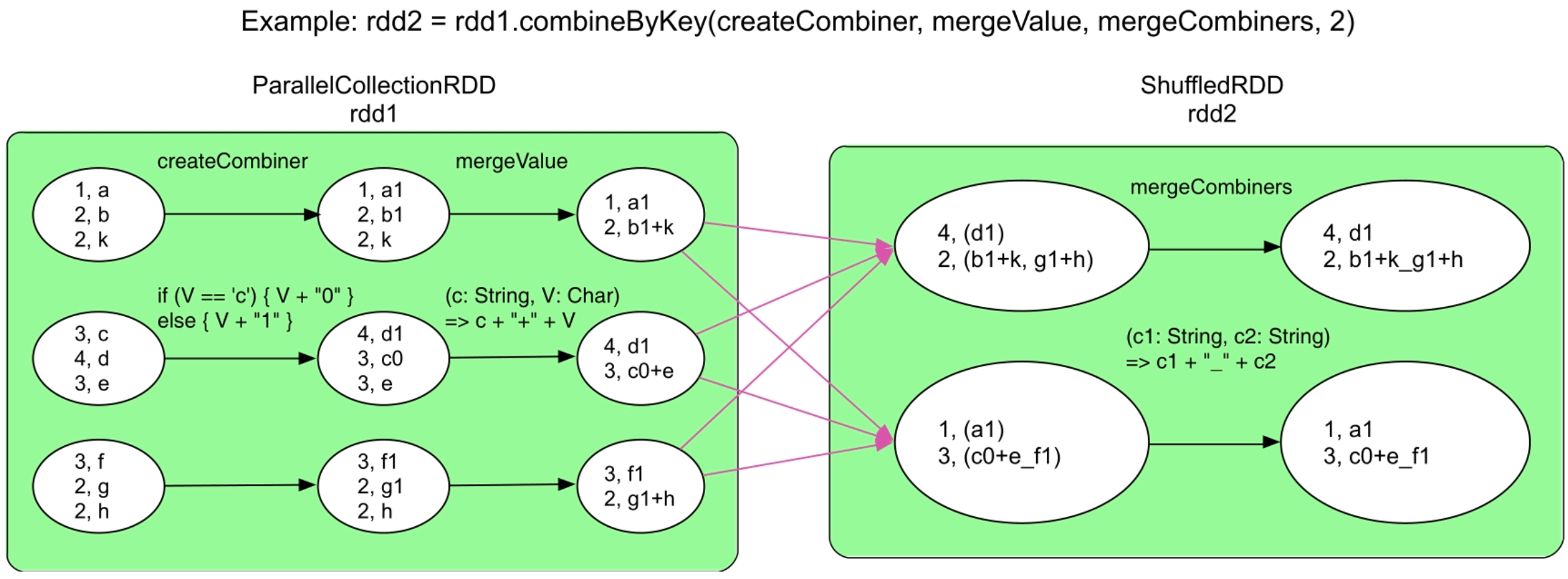
图3.13 combineByKey()的逻辑处理流程示例
_
为什么已经有aggregateByKey()了,还定义combine-ByKey()?两者又有什么区别?实际上,两者没有大的区别,aggregateByKey()是基于combineByKey()实现的,如aggregateByKey()中的zeroValue对应combineByKey()中的createCombiner,seqOp对应mergeValue,combOp对应mergeCombiners。唯一的区别是combineByKey()的createCombiner是一个初始化函数,而aggregateByKey()包含的zeroValue是一个初始化的值,显然createCombiner函数的功能比一个固定的zeroValue值更强大。
3.3.11 foldByKey()操作

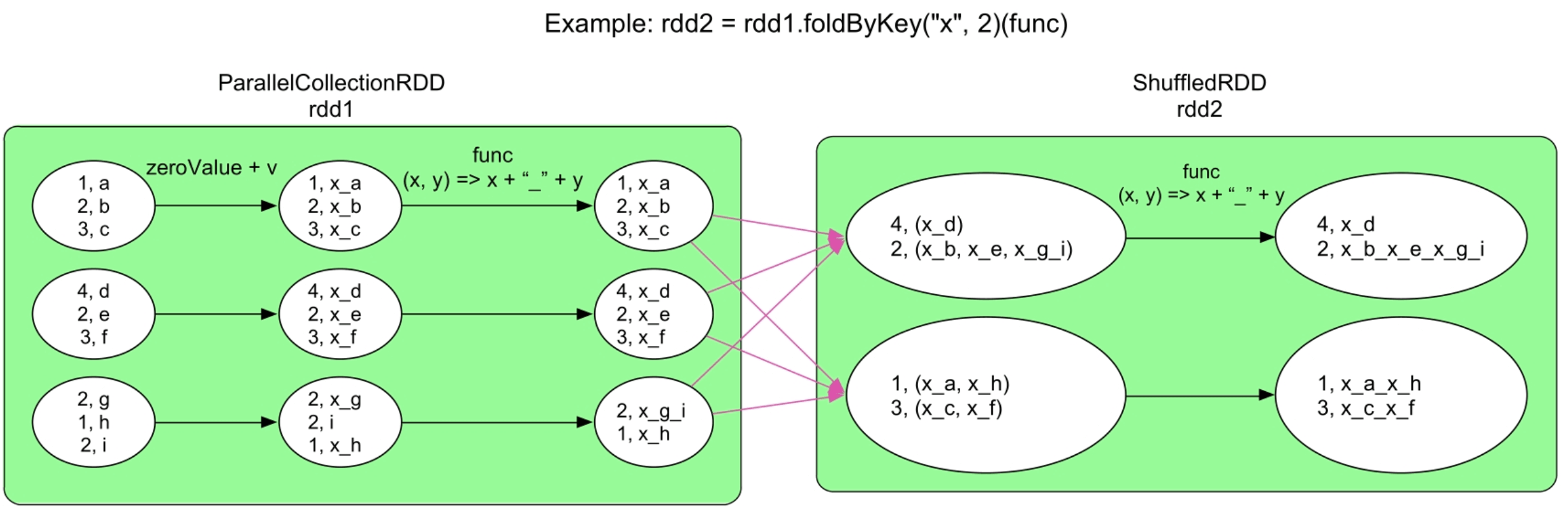
图3.14 foldByKey()的逻辑处理流程示例
foldByKey()也是基于aggregateByKey()实现的,功能介于reduceByKey()和aggregateByKey()之间。相比reduceByKey(),foldByKey()多了初始值zero Value;相比aggregateByKey(),foldByKey()要求seqOp=combOp=func。
3.3.12 cogroup()/groupWith()操作

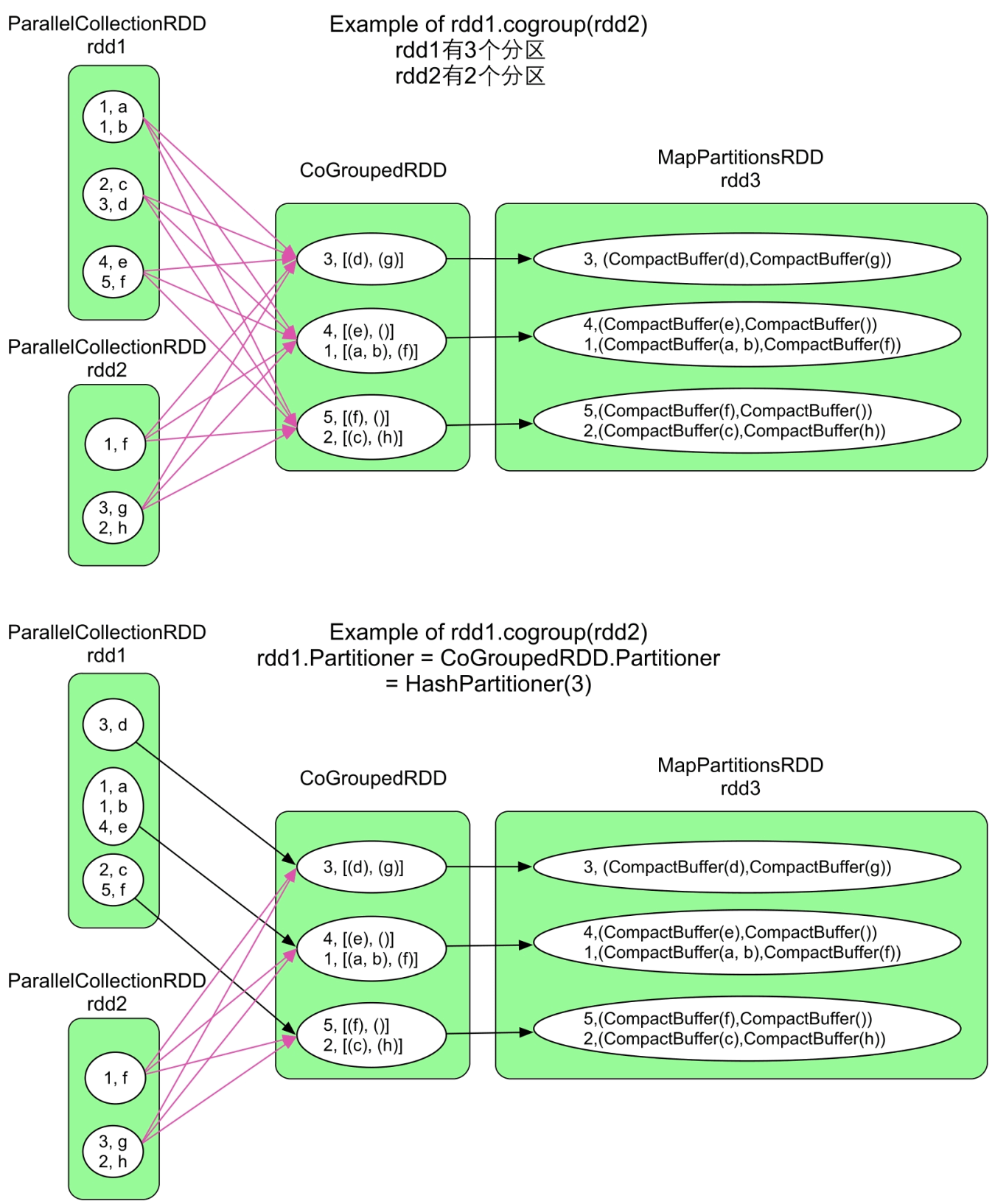
图3.15 cogroup()操作的逻辑处理流程示例
_
cogroup()与groupByKey()的不同在于cogroup()可以将多个RDD聚合为一个RDD。因此,其生成的RDD与多个parent RDD存在依赖关系。一般来说,聚合关系需要ShuffleDependency,但也存在特殊情况。例如,在groupByKey()操作中,如果child RDD和parent RDD使用的partitioner相同且分区个数也相同,那么没有必要使用ShuffleDependency,使用OneToOneDewpendency即可。更为特殊的是,由于cogroup()可以聚合多个RDD,因此可能对一部分RDD采用ShuffleDependency,而对另一部分RDD采用OneToOneDependency。
Spark在决定RDD之间的数据依赖时除了考虑transformation()的计算逻辑,还考虑child RDD和parent RDD的分区信息,当分区个数和partitioner都一致时,说明parent RDD中的数据可以直接流入child RDD,不需要ShuffleDependency,这样可以避免数据传输,提高执行效率。
cogroup()最多支持4个RDD同时进行cogroup(),如rdd5=rdd1.cogroup (rdd2,rdd3,rdd4)。cogroup()实际生成了两个RDD:CoGroupedRDD将数据聚合在一起,MapPartitionsRDD将数据类型转变为CompactBuffer(类似于Java 的ArrayList)。当cogroup()聚合的RDD包含很多数据时,Shuffle这些中间数据会增加网络传输,而且需要很大内存来存储聚合后的数据,效率较低。
3.3.13 join()操作

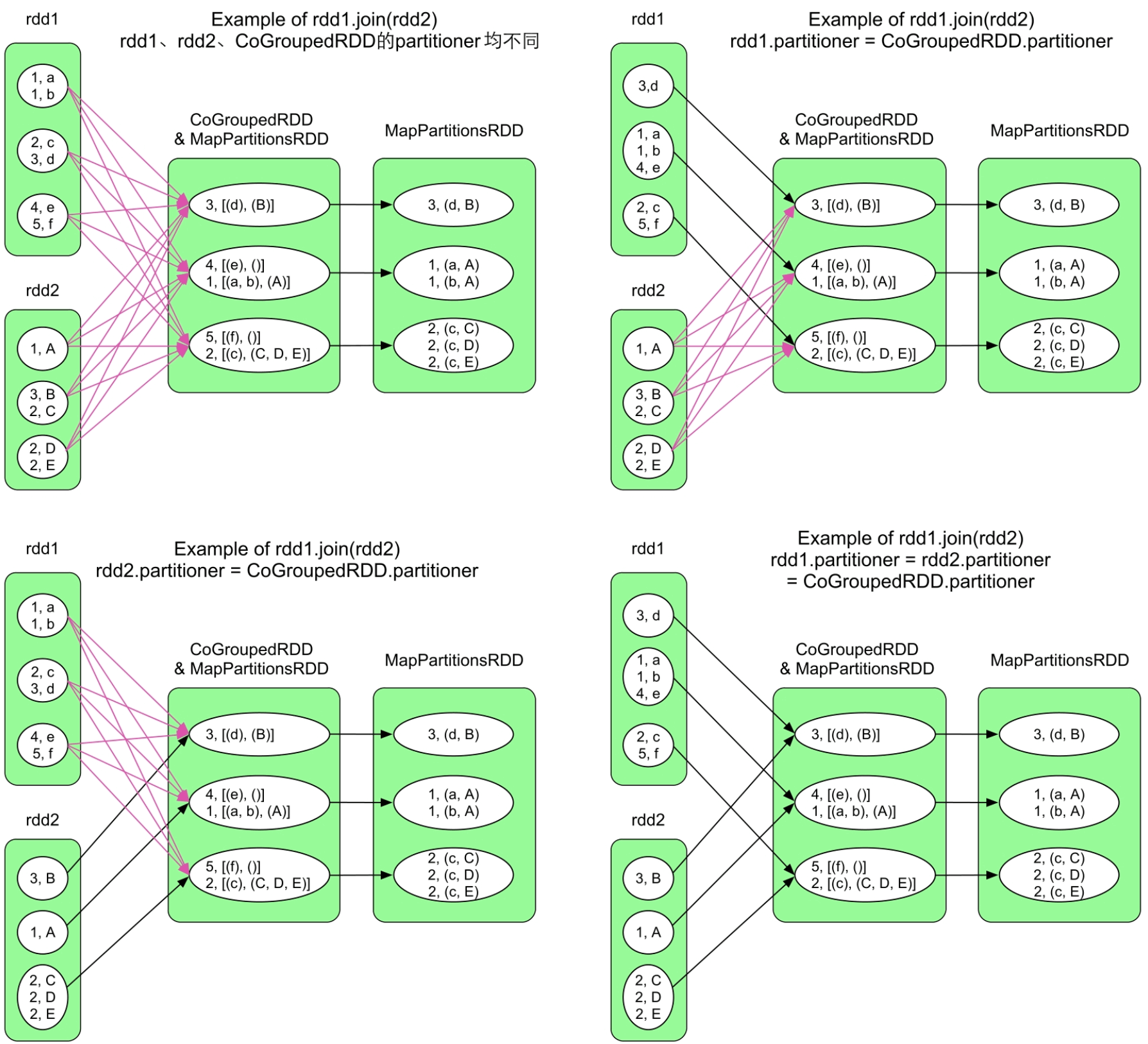
图3.16 join()操作的不同逻辑处理流程示例
join()操作实际上建立在cogroup()之上,首先利用CoGroupedRDD将具有相同Key的Value聚合在一起,形成
3.3.14 cartesian()操作

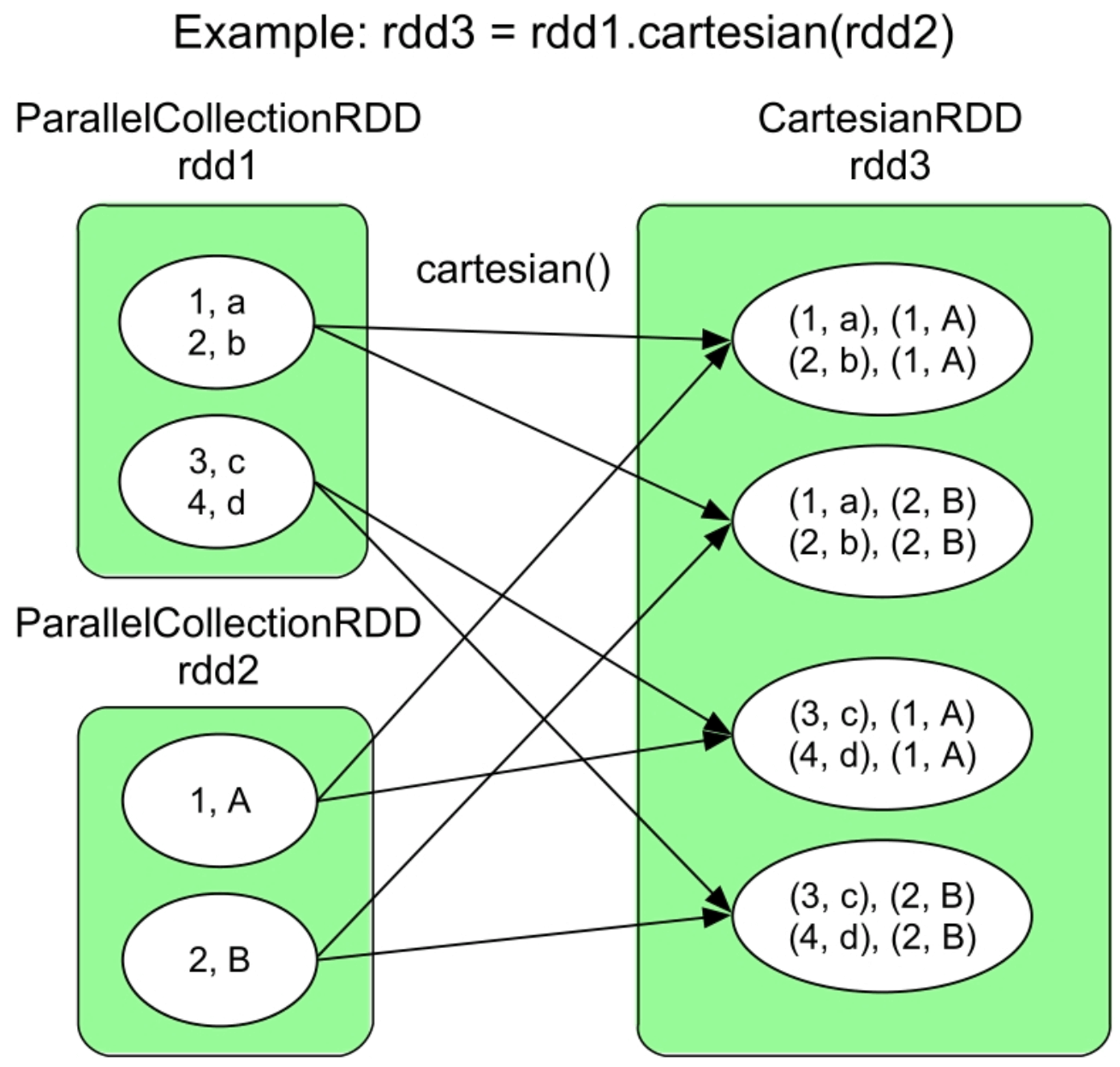
图3.17 cartesian()操作的逻辑处理流程示例
_
假设rdd1中的分区个数为m,rdd2的分区个数为n,cartesian()操作会生成m×n个分区。rdd1和rdd2中的分区两两组合,组合后形成CartesianRDD中的一个分区,该分区中的数据是rdd1和rdd2相应的两个分区中数据的笛卡儿积。
cartesian()操作形成的数据依赖关系虽然比较复杂,但归属于多对多的NarrowDependency,并不是ShuffleDependency。
3.3.15 sortByKey()操作

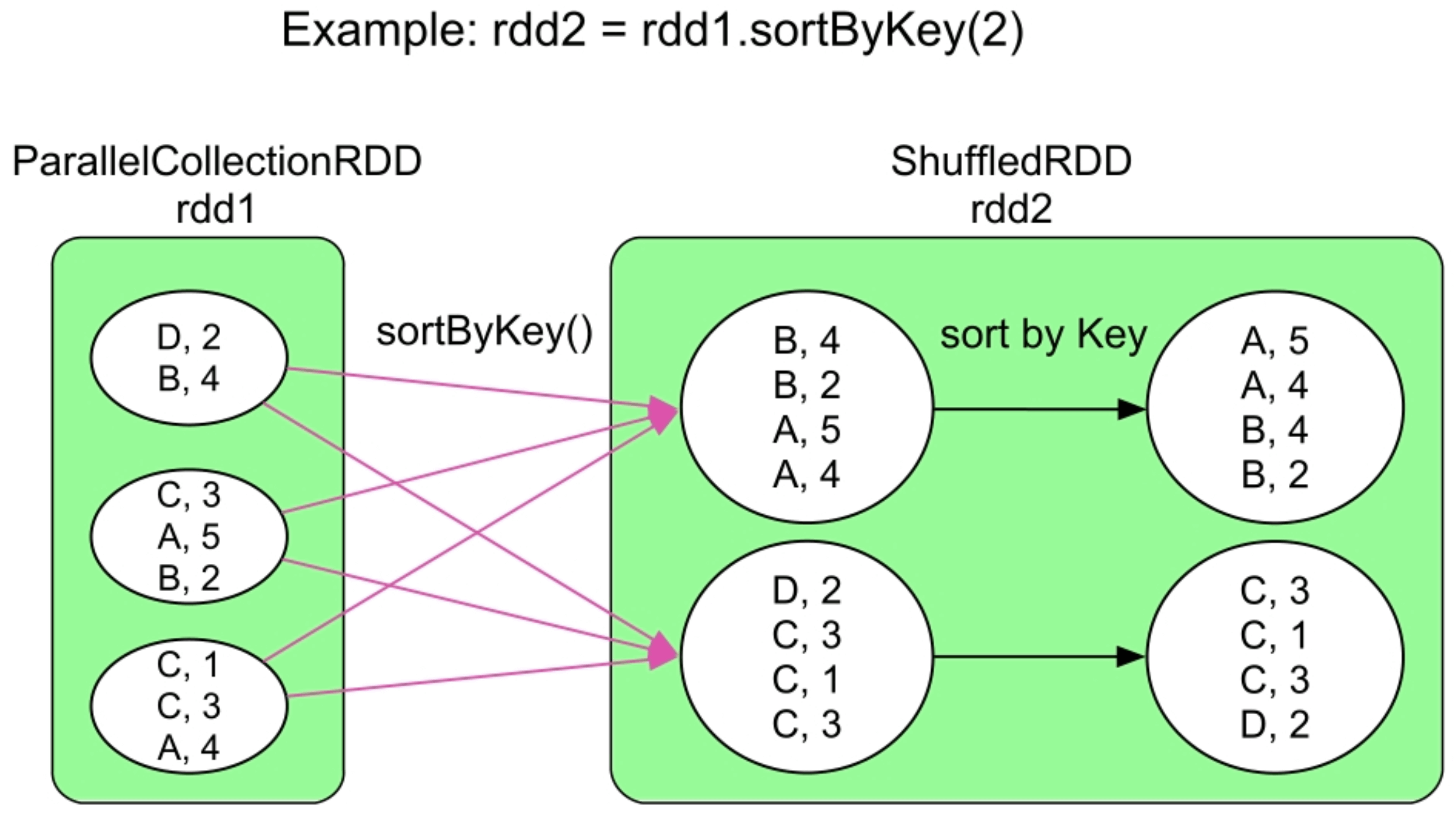
图3.18 sortByKey()操作的逻辑处理流程示例
_
与reduceByKey()等操作使用Hash划分来分发数据不同,sortByKey()为了保证生成的RDD中的数据是全局有序(按照Key排序)的,采用Range划分来分发数据。Range划分可以保证在生成的RDD中,partition 1中的所有record的Key小于(或大于)partition 2中所有的record的Key。
sortByKey()的缺点是record的Key是有序的,但Value是无序的,那么如何使得Value也是有序的?在Hadoop MapReduce中,我们可以使用SecondarySort的方法,也就是通过将Value放到Key中,如
3.3.16 coalesce()操作

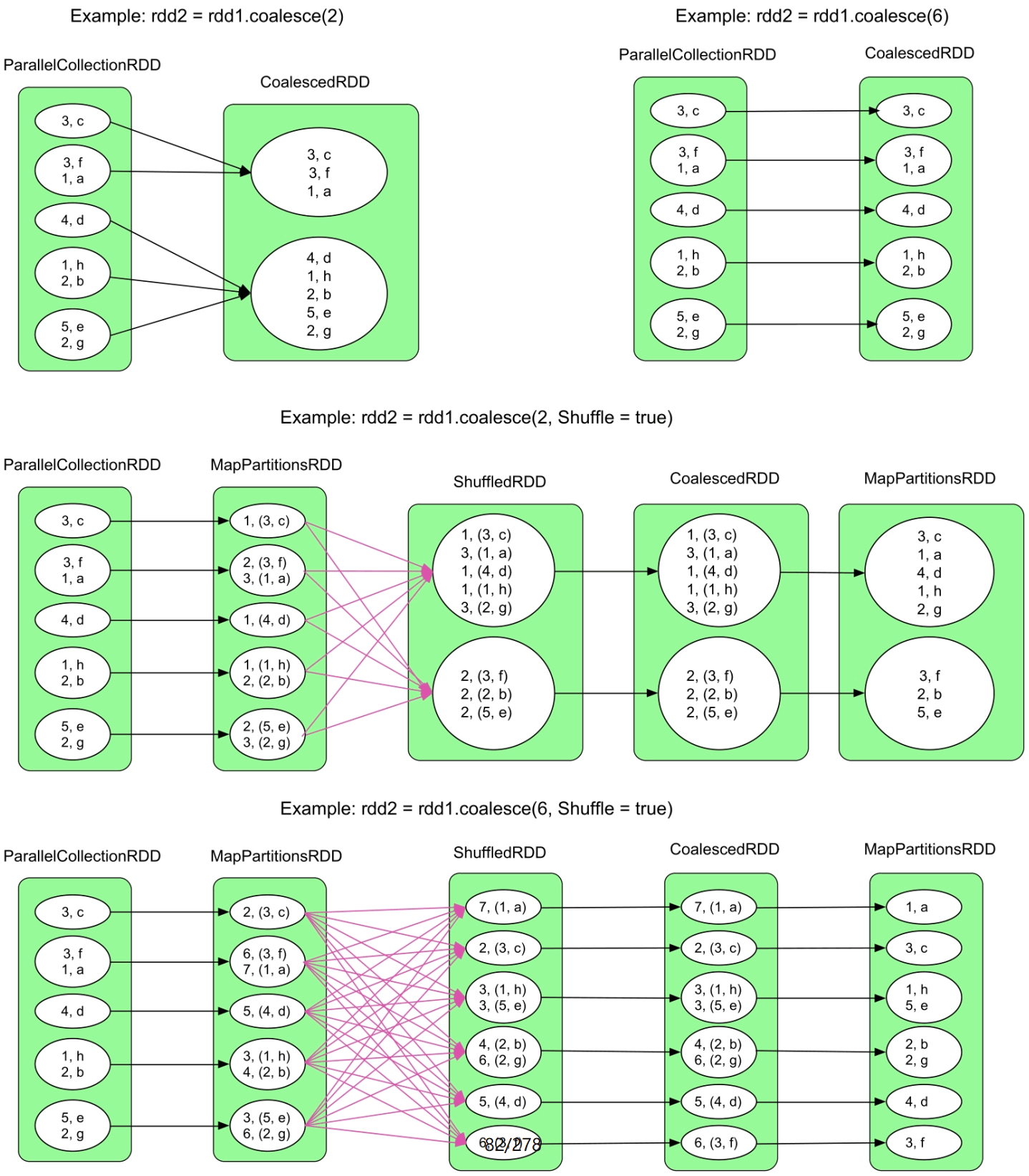
图3.19 coalesce()操作的不同逻辑处理流程示例
_
如图3.19中的第2个图所示,当使用coalesce(6)将rdd1的分区个数增加为6时,会发现生成的rdd2的分区个数并没有增加,还是5。这是因为coalesce()默认使用NarrowDependency,不能将一个分区拆分为多份。
使用Shuffle=true后,Spark可以随机将数据打乱,从而使得生成的RDD中每个分区中的数据比较均衡。具体采用的方法是为rdd1中的每个record添加一个特殊的Key,如第3个图中的MapPartitionsRDD,Key是Int类型,并从[0,numPartitions)中随机生成,如<3,f> => <2,(3,f)>;中,2是随机生成的Key,接下来的record的Key递增1,如<1,a> => <3,(1,a)>。这样,Spark可以根据Key的Hash值将rdd1中的数据分发到rdd2的不同的分区中,然后去掉Key即可(见最后的MapPartitionsRDD)。
使用Shuffle来增加分区个数:如图3.19中的第4个图所示,通过使用ShuffleDepedency,可以对分区进行拆分和重新组合,解决分区不能增加的问题。
3.3.17 repartition()操作

3.3.18 repartitionAndSortWithinPartitions()操作

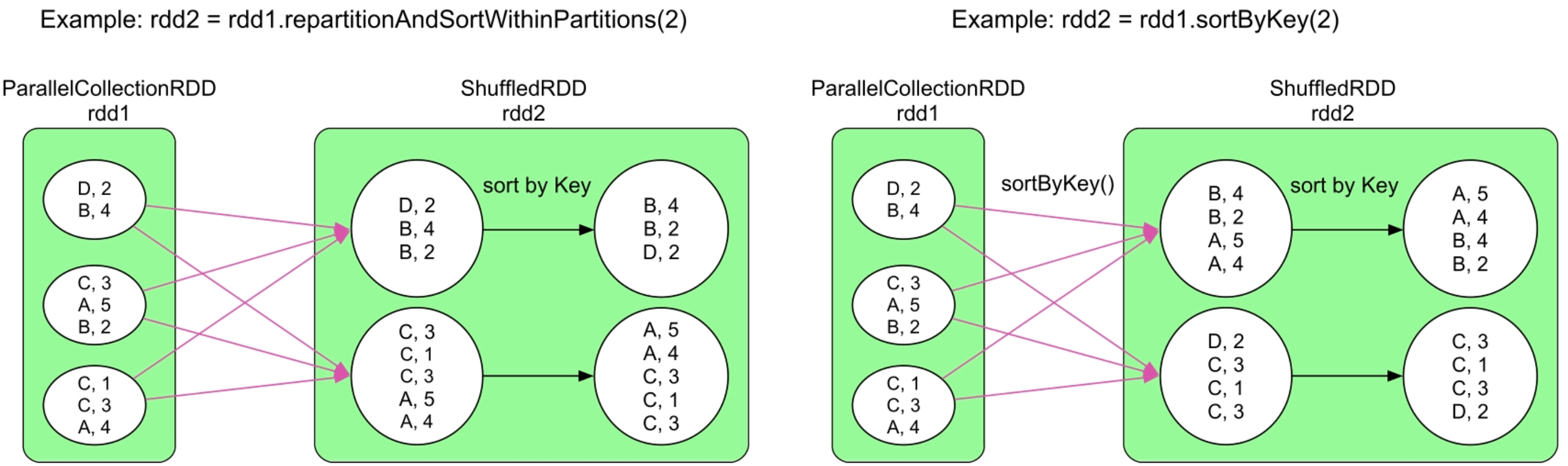
图3.20 repartitionAndSortWithinPartitions()操作与sortByKey()的逻辑处理流程对比
_
repartitionAndSortWithinPartitions()操作首先使用用户定义的partitioner将数据分发到不同分区,然后对每个分区中的数据按照Key进行排序。与repartition()操作相比,repartitionAndSortWithinPartitions()操作多了分区数据排序功能。
与sortByKey()操作相比,repartitionAndSortWithinPart itions()中的partitioner可定义,不一定是sortByKey()默认的RangePartitioner。因此,repa rtitionAndSortWithinPartitions()操作得到的结果不能保证Key是全局有序的。
3.3.19 intersection()操作

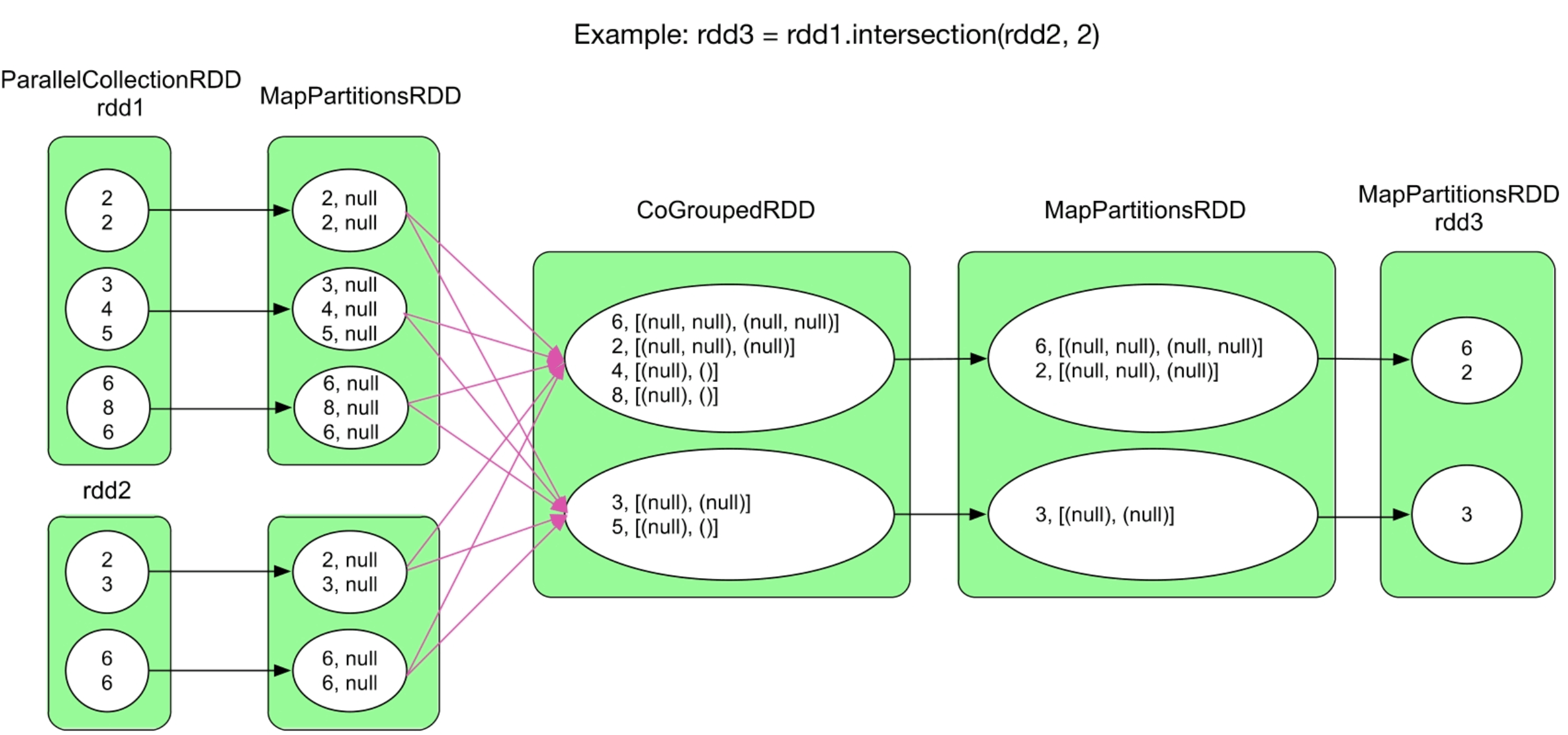
图3.21 intersection()的逻辑处理流程示例
_
intersection()的核心思想是先利用cogroup()将rdd1和rdd2的相同record聚合在一起,然后过滤出在rdd1和rdd2中都存在的record。具体方法是先将rdd1中的record转化为
3.3.20 distinct()操作

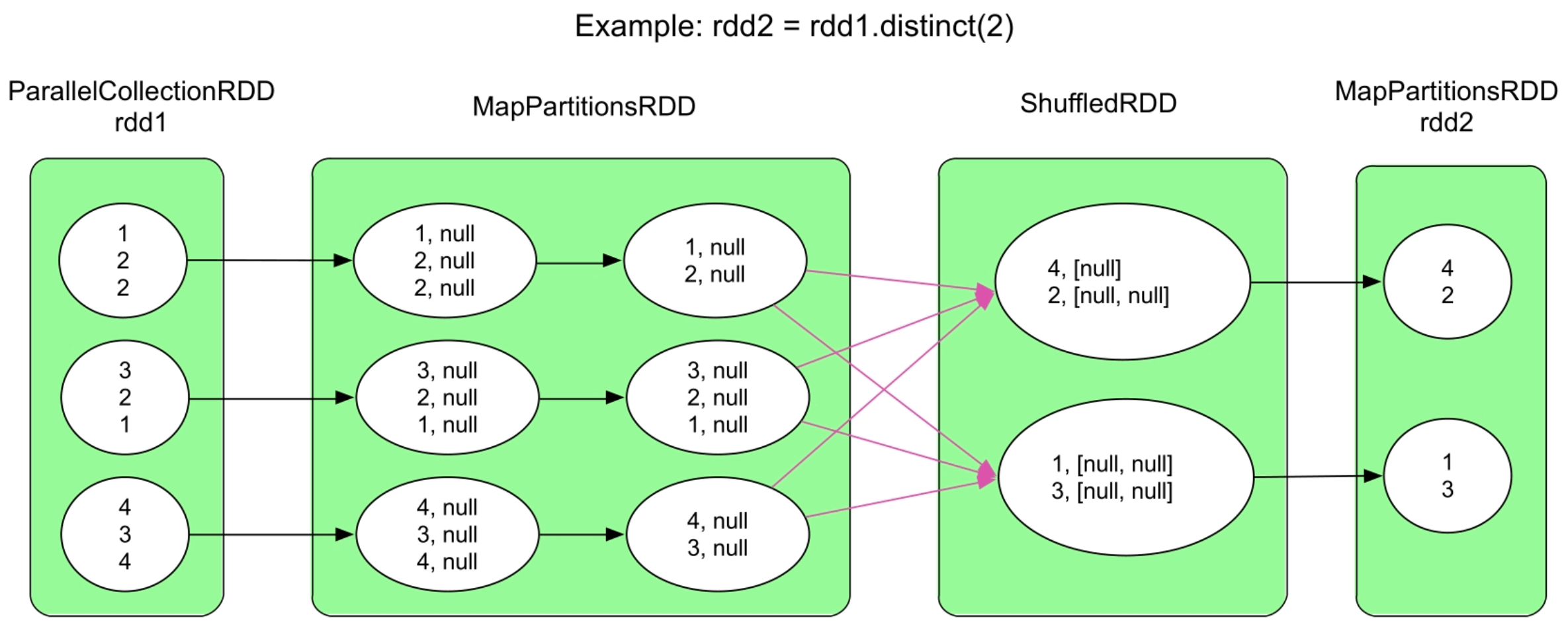
图3.22 distinct()的逻辑处理流程示例
_
与intersection()操作类似,distinct()操作先将数据转化为
3.3.21 union()操作

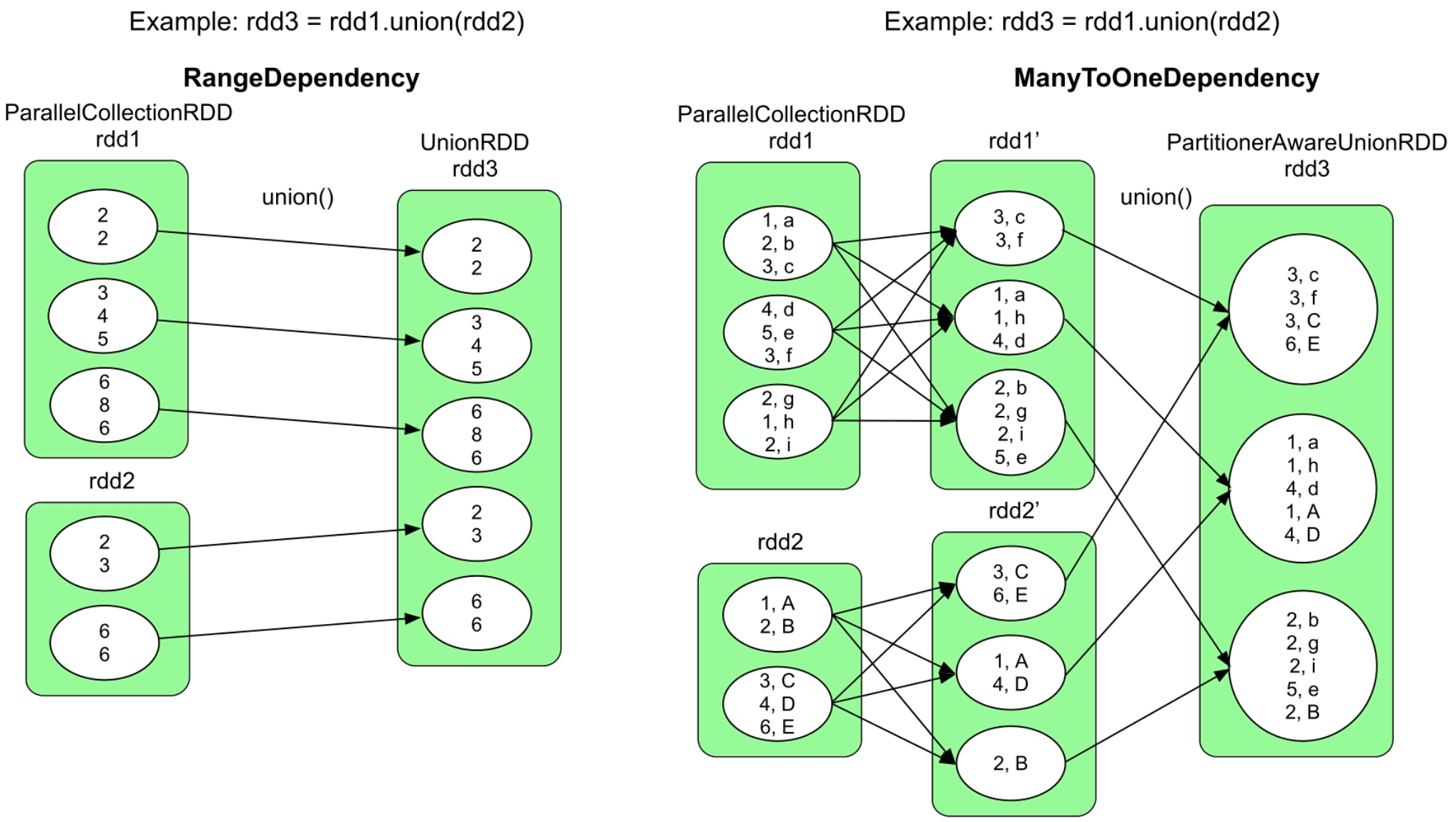
图3.23 union()的逻辑处理流程示例
_
union()将rdd1和rdd2中的record组合在一起,形成新的rdd3,形成的数据依赖关系是RangeDependency。union()形成的逻辑执行流程有以下两种。
第一种:如图3.23中的左图和示例代码1所示,rdd1和rdd2是两个非空的RDD,而且两者的partitioner 不一致,且合并后的rdd3为UnionRDD,其分区个数是rdd1和rdd2的分区个数之和,rdd3的每个分区也一一对应rdd1或rdd2中相应的分区。
第二种:如图3.23中的右图和示例代码2所示,rdd1和rdd2是两个非空的RDD,且两者都使用Hash划分,得到rdd1′和rdd2′。因此,rdd1′和rdd2′的partitioner是一致的,都是Hash划分且分区个数相同。rdd1′和rdd2′合并后的rdd3为PartitionerAwareUnionRDD,其分区个数与rdd1和rdd2的分区个数相同,且rdd3中的每个分区的数据是rdd1′和rdd2′对应分区合并后的结果。
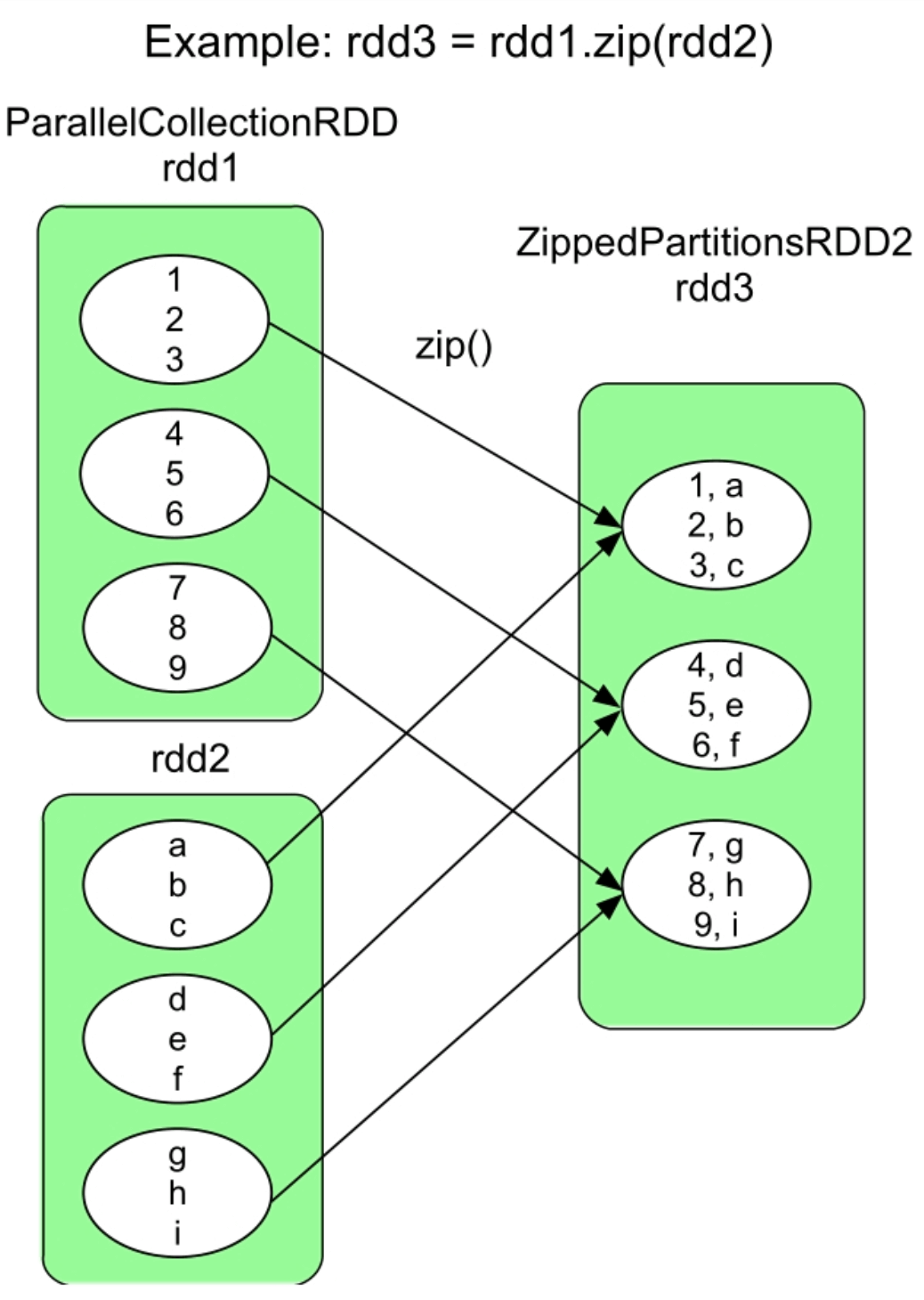
3.3.22 zip()操作

3.3.23 zipPartitions()操作

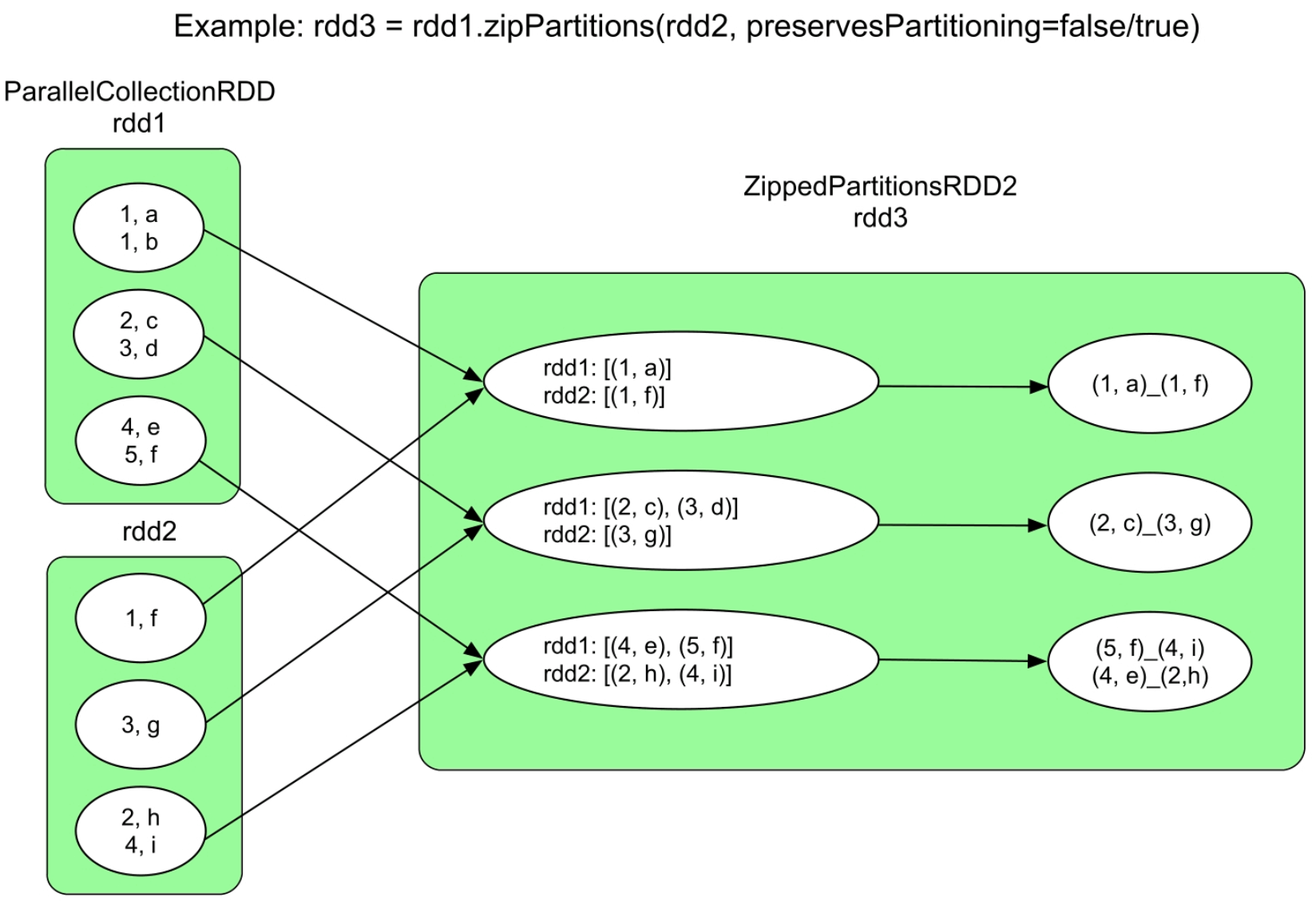
图3.25 zipPartitions()的逻辑处理流程示例
3.3.24 zipWithIndex()和zipWithUniqueId()操作

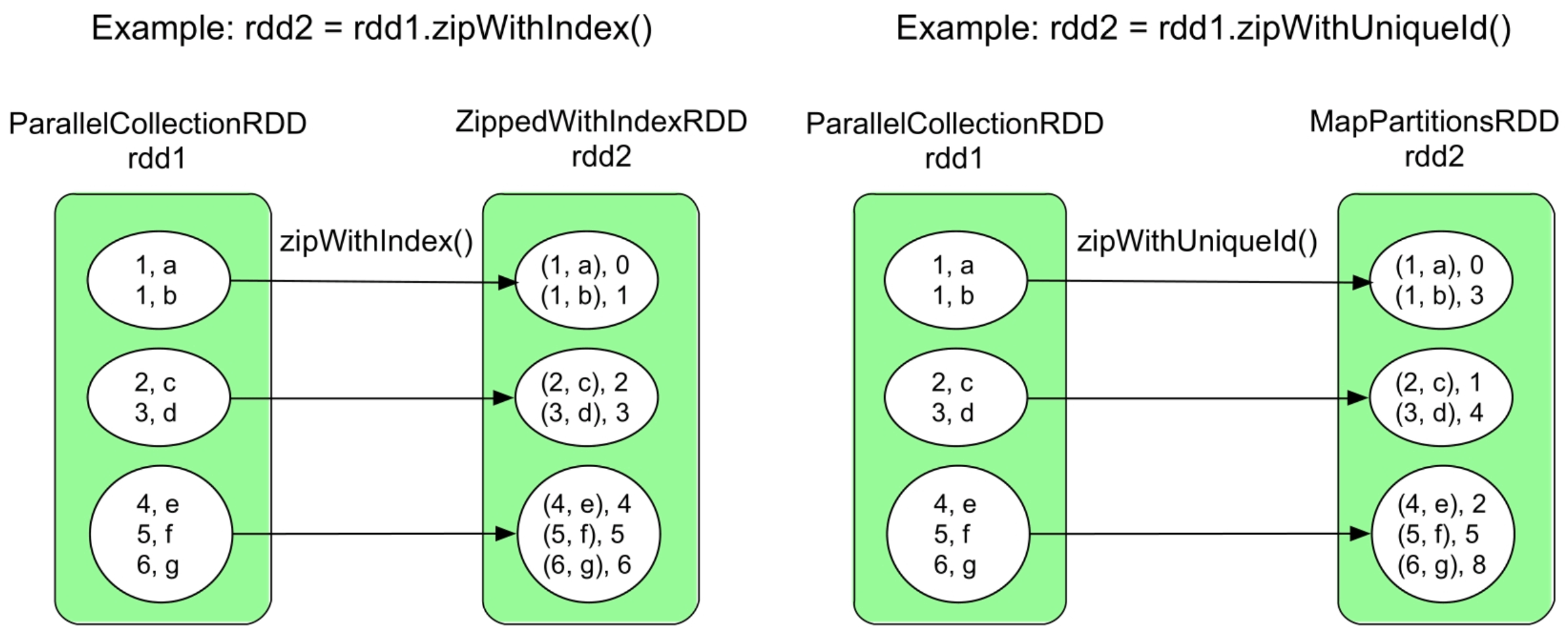
图3.26 zipWithIndex()和zipWithUniqueId()的逻辑处理流程示例
3.3.25 subtractByKey()操作

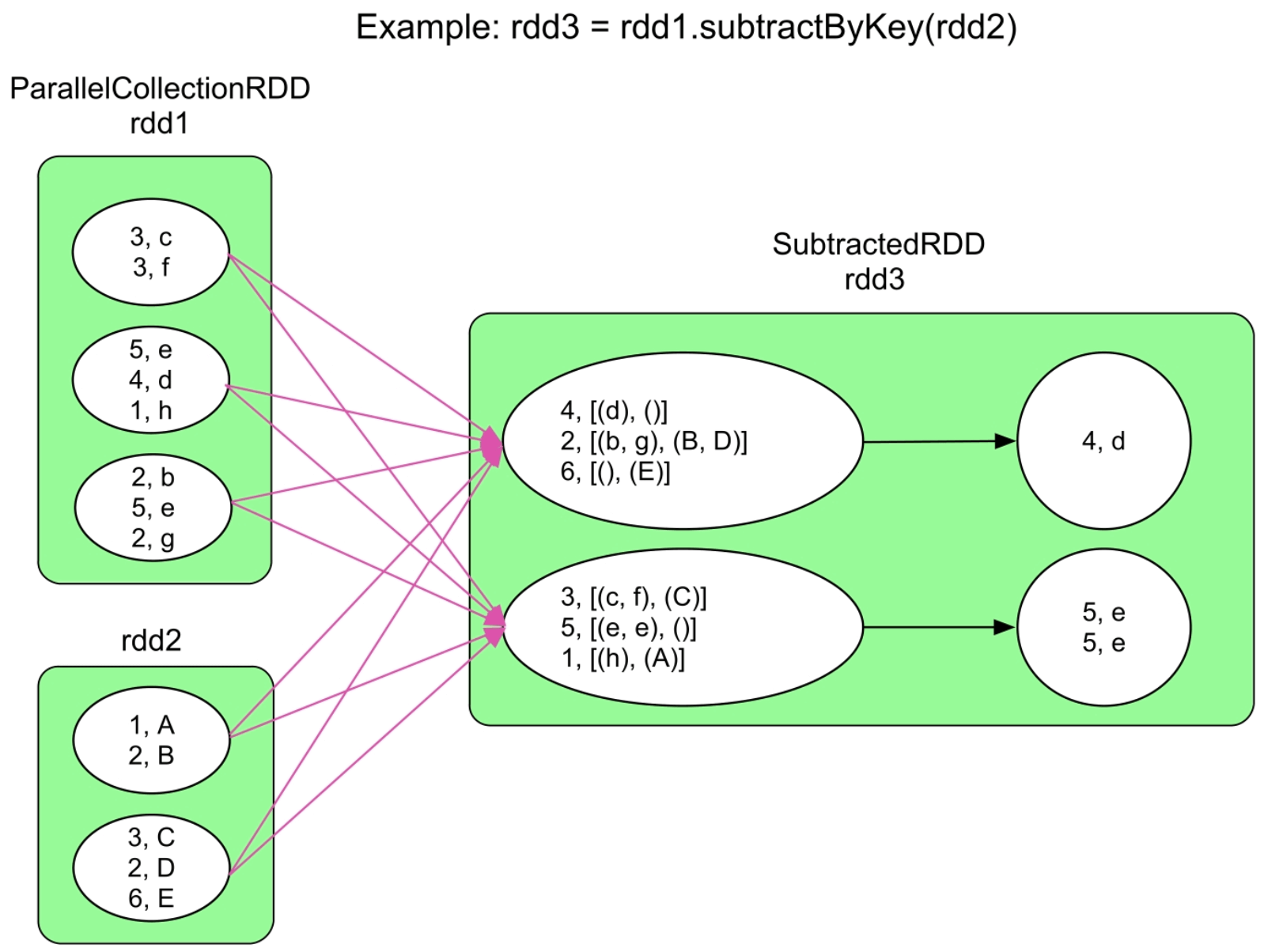
图3.27 subtractByKey()的逻辑处理流程示例
SubtractedRDD结构和数据依赖模式都类似于CoGroupedRDD,可以形成OneToOneDependency或者ShuffleDependency,但实现比CoGroupedRDD更高效。
3.3.26 subtract()操作

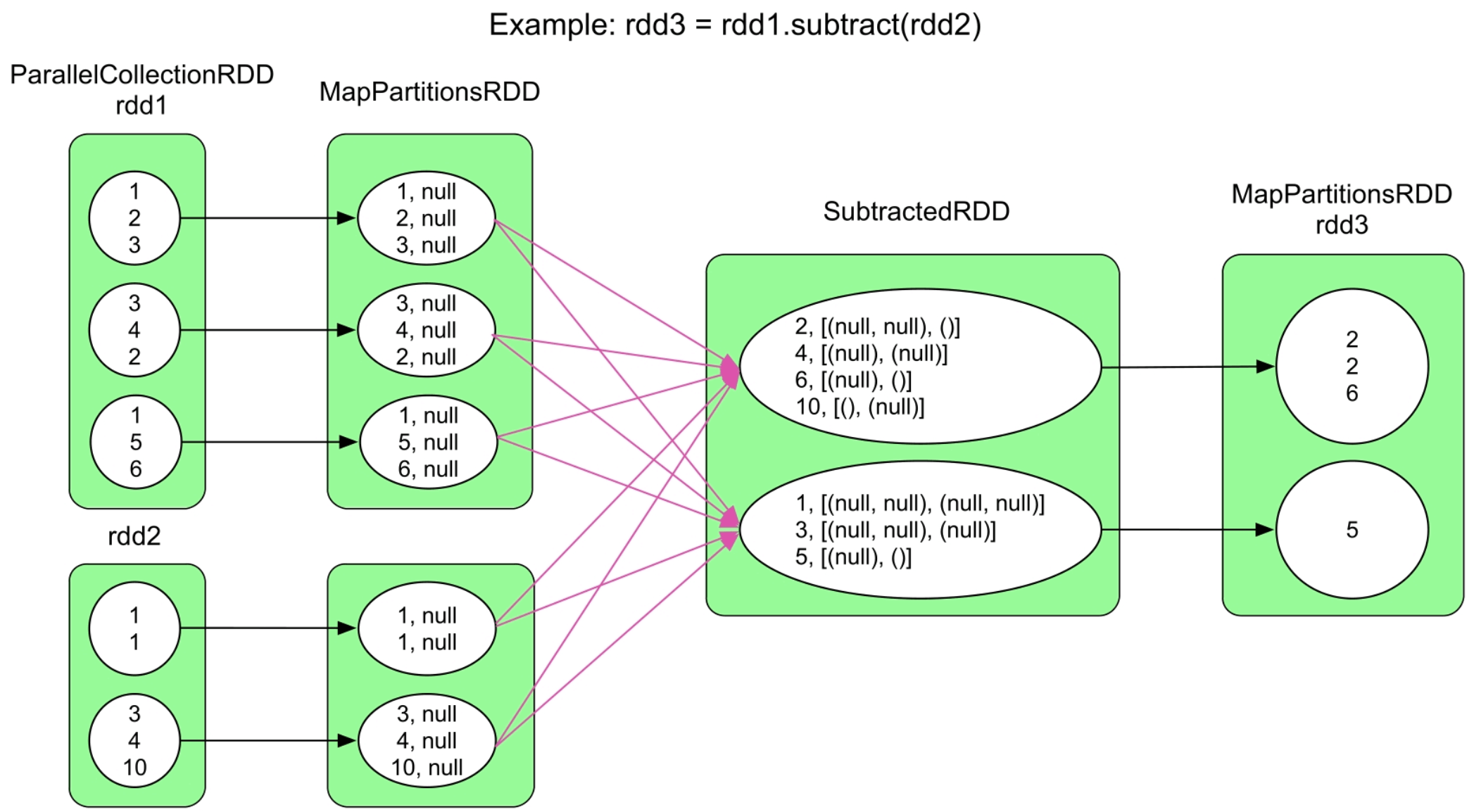
图3.28 subtract()的逻辑处理流程示例
subtract()的语义与subtractByKey()类似,不同点是subtract()适用面更广,可以针对非
3.3.27 sortBy(func)操作

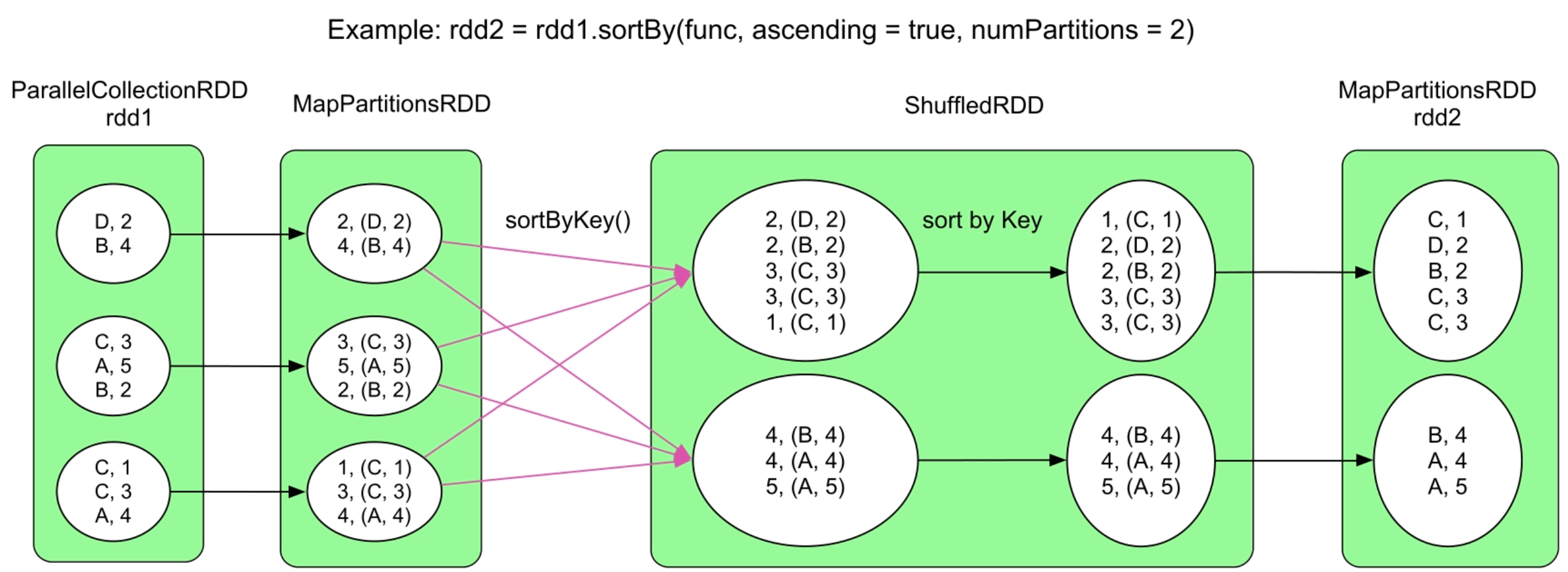
图3.29 sortBy()的逻辑处理流程示例
_
sortBy(func)与sortByKey()的语义类似,不同点是sortByKey()要求RDD是
3.3.28 glom()操作
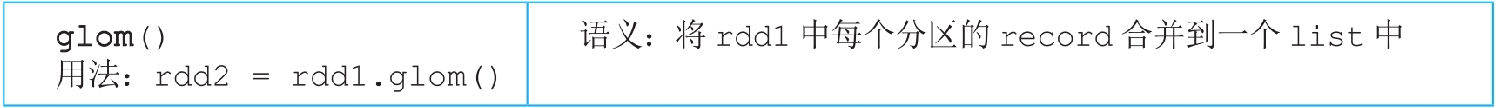
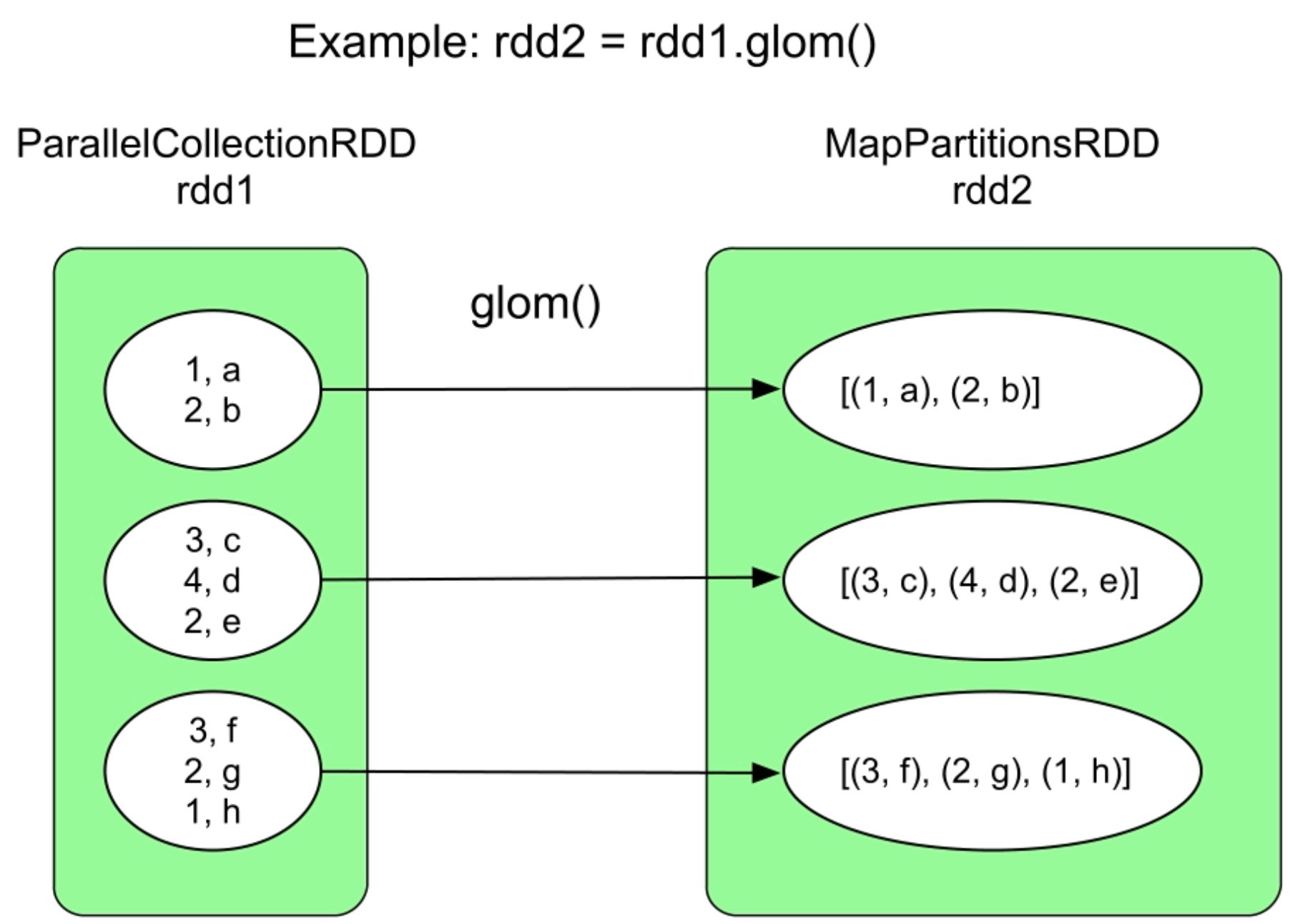
图3.30 glom()的逻辑处理流程示例
3.4 常用action()数据操作
我们如何判断一个操作是action()还是transformation()?答案是看返回值,transformation()操作一般返回RDD类型,而action()操作一般返回数值、数据结构(如Map)或者不返回任何值(如写磁盘)。
3.4.1 count()/countByKey()/countByValue()操作
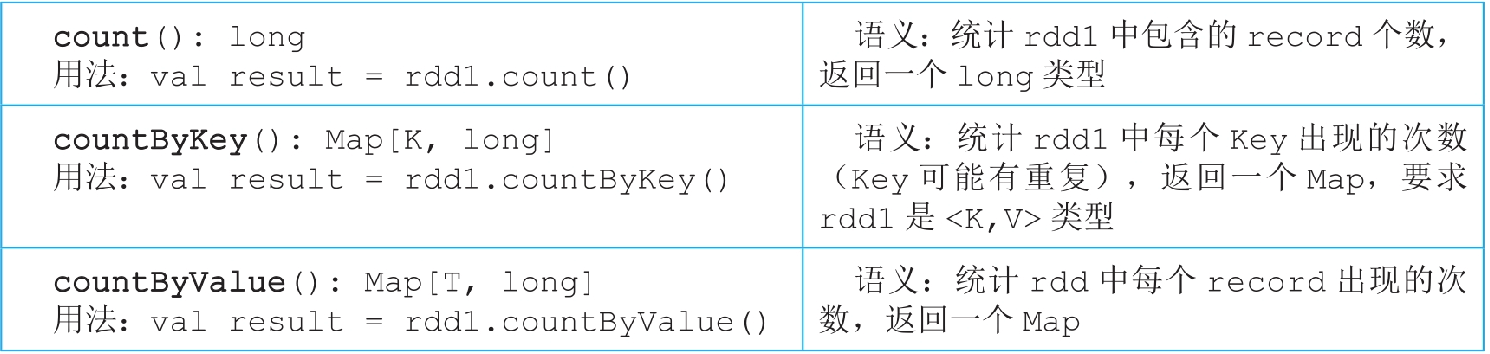
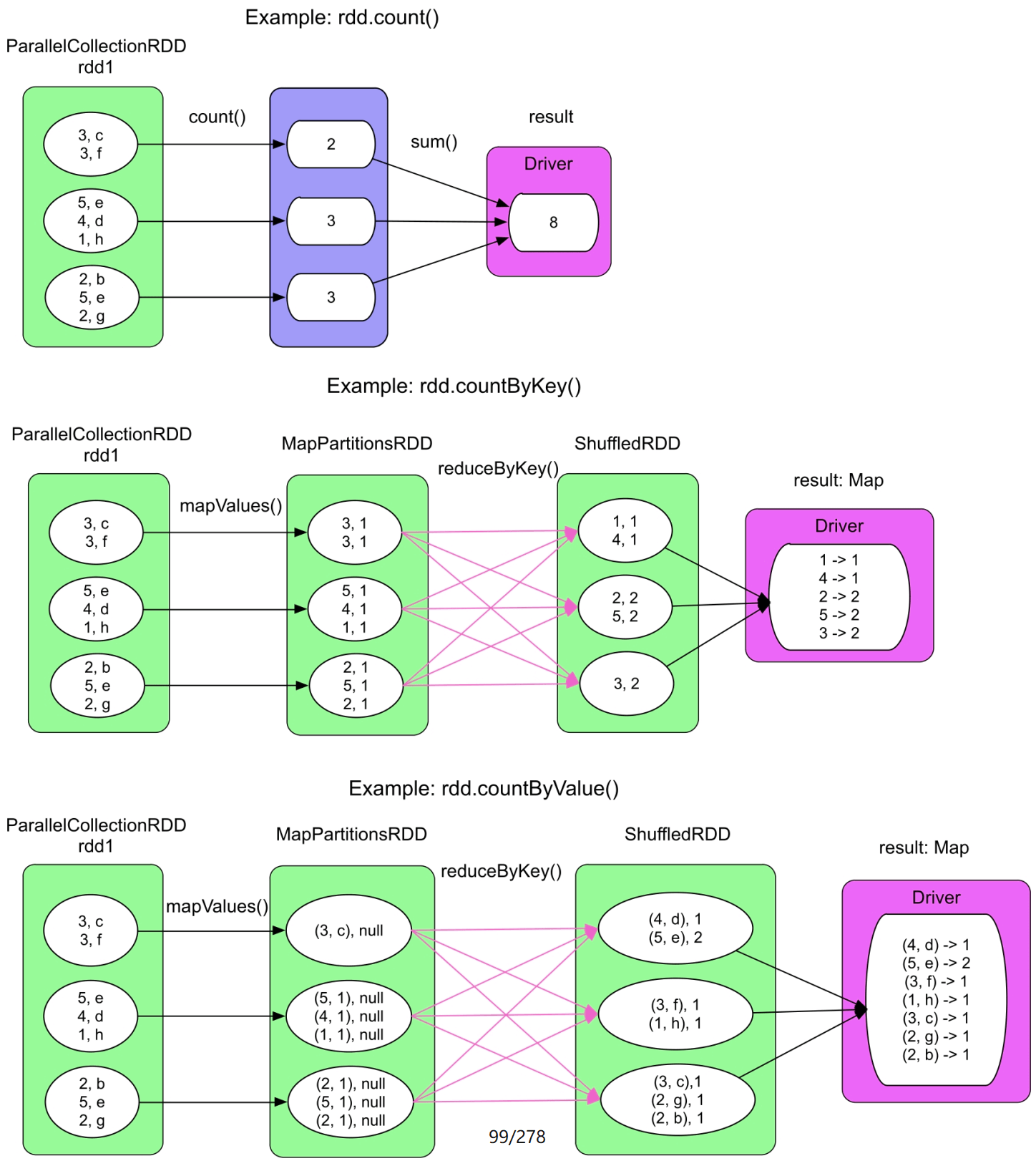
图3.31 count()/countByKey()/countByValue()的逻辑处理流程示例
countByKey()和countByValue()需要在Driver端存放一个Map,当数据量比较大时,这个Map会超过Driver的内存大小,所以,在数据量较大时,建议先使用reduceByKey()对数据进行统计,然后将结果写入分布式文件系统(如HDFS等)。
3.4.2 collect()和collectAsMap()操作

collect()将record直接汇总到Driver端,而collectAsMap()将
3.4.3 foreach()和foreachPartition()操作

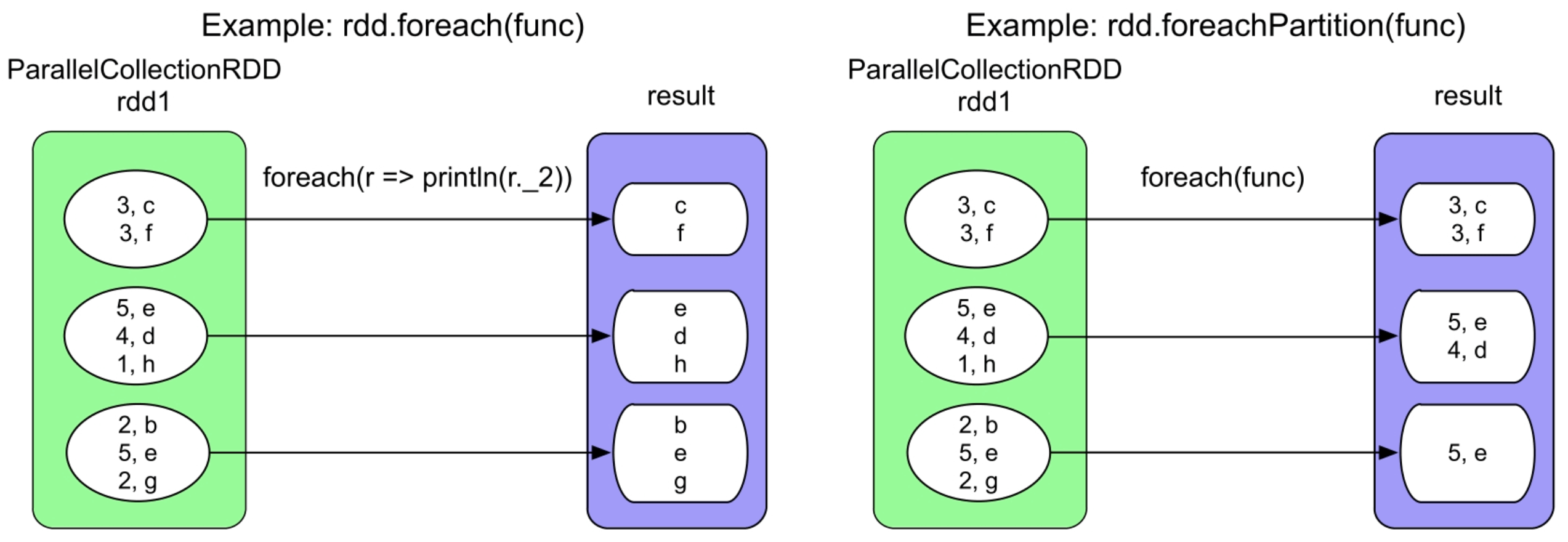
图3.32 foreach()和foreachPartition()的逻辑处理流程示例
3.4.4 fold()/reduce()/aggregate()操作

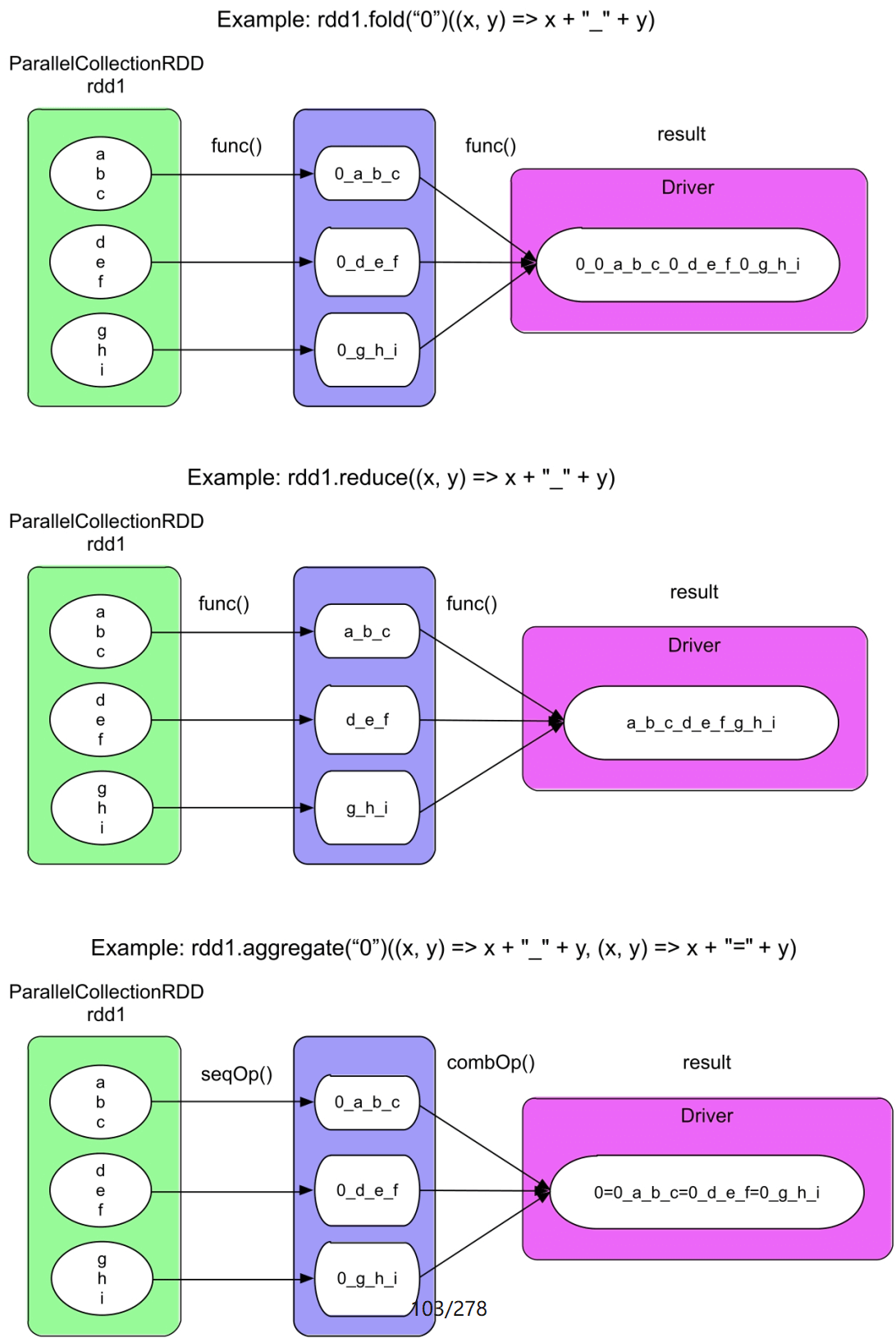
图3.33 fold()、reduce()和aggregate()的逻辑处理流程示例
fold(func)中的func的语义与foldByKey (func)中的func相同,区别是foldByKey()生成一个新的RDD,而fold()直接计算出结果,并不生成新的RDD。fold()首先在rdd1的每个分区中计算局部结果,如0_a_b_c,然后在Driver端将局部结果聚合成最终结果。需要注意的是,每次聚合时初始值zeroValue都会参与计算,而foldByKey()在聚合来自不同分区的record时并不使用初始值。如图3.33的第2个图所示,reduce(func)的语义与去掉初始值的fold(func)相同。reduce(func)可以看作是aggregate(seqOp,combOp)中seqOp=combOp=func的场景。
如图3.33的第3个图所示,aggregate(seqOp,combOp)中的seqOp和combOp的语义与aggregateByKey(seqOp,combOp)中的seqOp和combOp的语义相同,区别是aggregateByKey()生成一个新的RDD,而aggregate()直接计算出结果。aggregate()使用seqOp在每个分区中计算局部结果,然后使用combOp在Driver端将局部结果聚合成最终结果。需要注意的是,在aggregate()中,seqOp和combOp聚合时初始值zeroValue都会参与计算,而在aggregateByKey()中,初始值只参与seqOp的计算。
为什么已经有reduceByKey()、aggregateByKey()等操作,还要定义aggregate()、reduce()等操作呢?答案是,有时候我们需要全局聚合。虽然reduceByKey()、aggregateByKey()等操作可以对每个分区中的record,以及跨分区且具有相同Key的record进行聚合,但这些聚合都是在部分数据上(如<;K,func(list(V))>;使用func聚合函数)进行的,并不是针对所有record进行全局聚合的,即func(
3.4.5 treeAggregate ()和treeReduce()操作
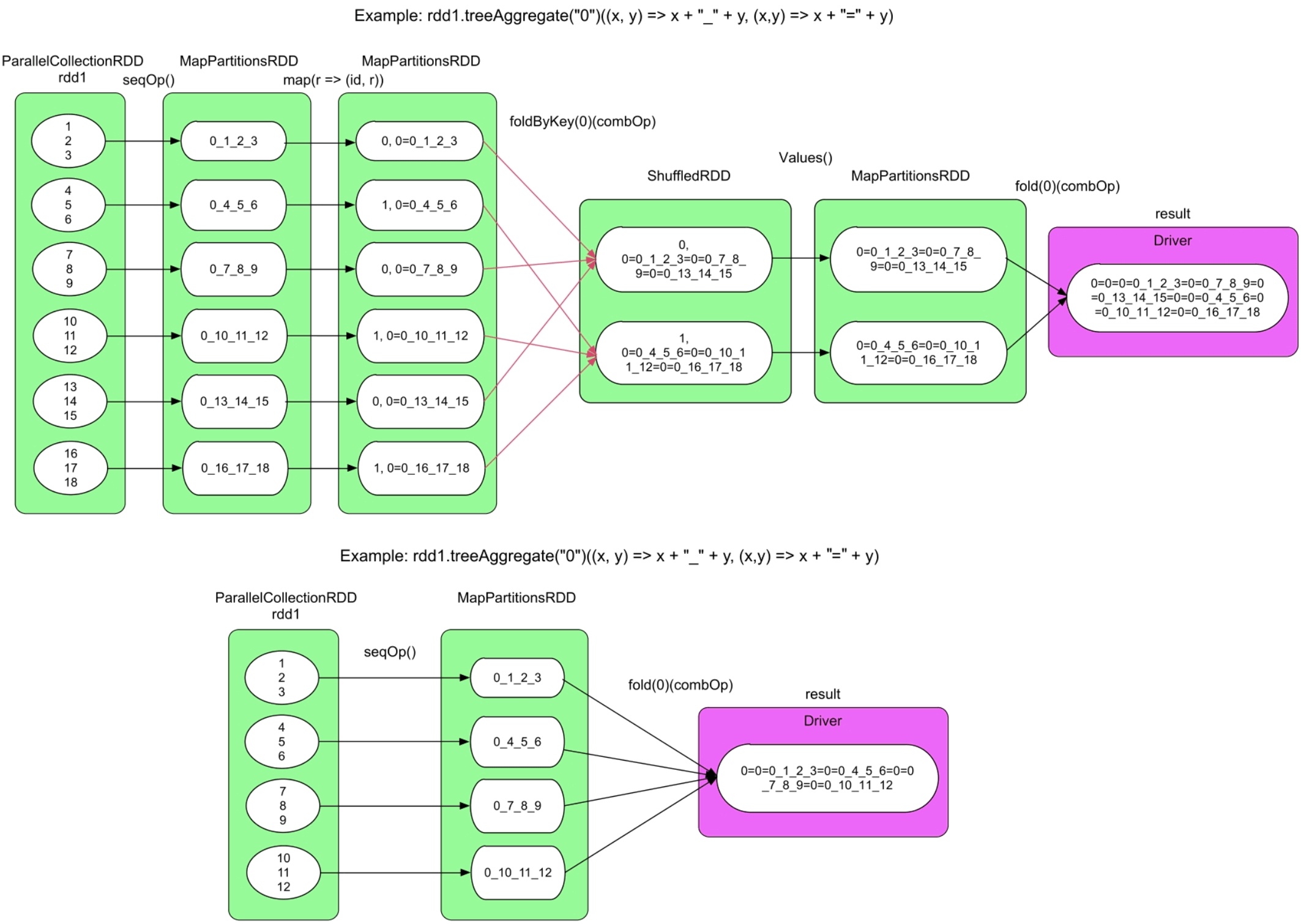
图3.34 treeAggregate()的逻辑处理流程示例
_
treeAggregate(seqOp,combOp)的语义与aggregate (seqOp,combOp)的语义相同,区别是treeAggregate()使用树形聚合方法来优化全局聚合阶段,从而减轻了Driver端聚合的压力(数据传输量和内存用量)。树形聚合方法类似归并排序中的层次归并。那么如何实现这个树形聚合过程呢?如果树形聚合全部放在Driver端进行,则没有意义,因为没有减少数据传输量。换个角度思考,在树形聚合时,非根节点实际上是局部聚合,只有根节点是全局聚合,那么我们可以利用之前的聚合操作(如reduceByKey()、aggregateByKey())来实现非根节点的局部聚合,而将最后的根节点聚合放在Driver端进行,只是我们需要为每个非根节点分配合理的数据。基于这个思想,Spark采用foldByKey()来实现非根节点的聚合,并使用fold()来实现根节点的聚合。
如果输入数据中的分区个数本来就很少,如图3.34的下图中只有4个分区,那么即使调用了treeAggregate(),也会退化为类似aggregate()的方式进行处理。此时treeAggregate()与aggregate()的区别是,treeAggregate()中的zeroValue会被多次使用(由于调用了fold()函数)。
treeReduce()实际上是调用treeAggregate()实现的,唯一区别是没有初始值zeroValue,因此其逻辑处理流程图是简化版的treeAggregate()。
3.4.6 reduceByKeyLocality()操作

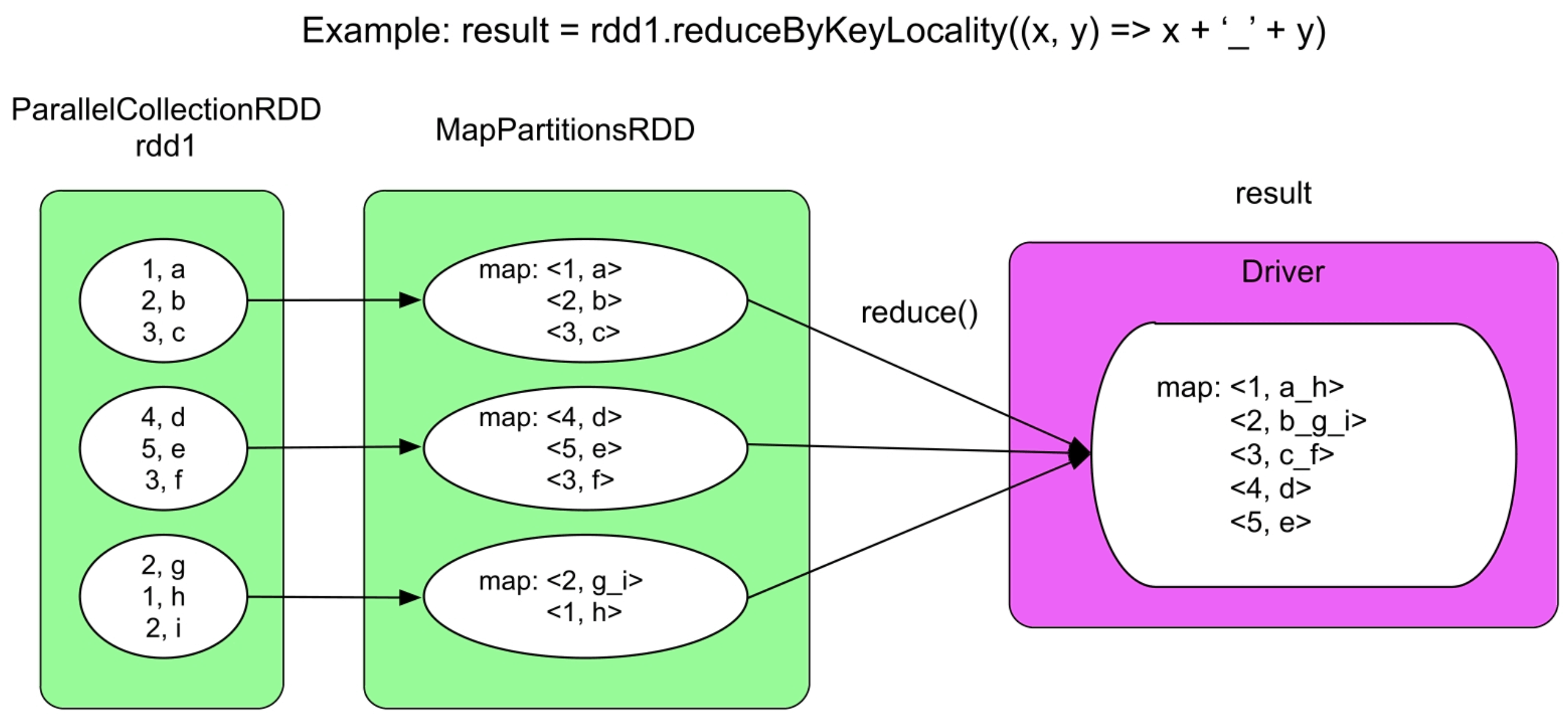
图3.36 reduceByKeyLocality()的逻辑处理流程示例
_
3.4.7 take()/f irst()/takeOrdered()/top()操作
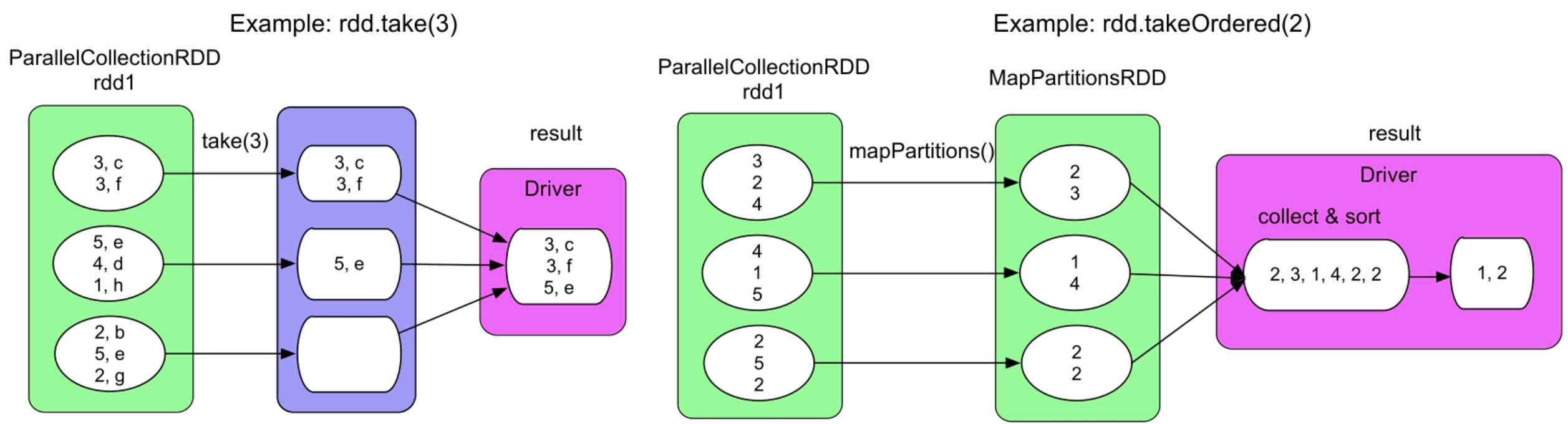
图3.37 take()和takeOrdered()的逻辑处理流程示例
take(num)操作首先取出rdd1中第一个分区的前num个record,如果num大于partition1中record的总数,则take()继续从后面的分区中取出record。为了提高效率,Spark在第一个分区中取record的时候会估计还需要对多少个后续的分区进行操作。
first()操作流程等价于take(1),takeOrdered(num)的目的是从rdd1中找到最小的num个record,因此要求rdd1中的record可比较。takeOrdered()操作首先使用map在每个分区中寻找最小的num个record,因为全局最小的n个元素一定是每个分区中最小的n个元素的子集。然后将这些record收集到Driver端,进行排序,然后取出前num个record。top(num)的执行逻辑与takeOrdered(num)相同,只是取出最大的num个record。可以看到,这4个操作都需要将数据收集到Driver端,因此不适合num较大的情况。
3.4.8 max()和min()操作

3.4.9 isEmpty()操作

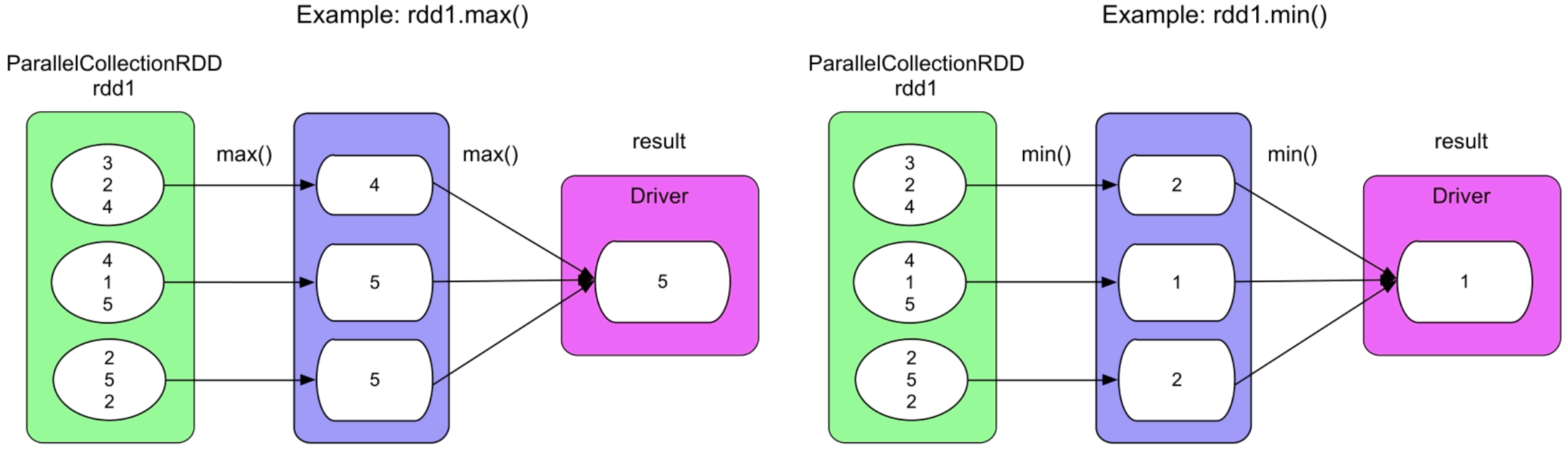
图3.38 max()和min()的逻辑处理流程示例
_
isEmpty()操作主要用来判断rdd中是否包含record。如果对rdd执行一些数据操作(如过滤、求交集等)后,rdd为空的话,那么执行其他操作的结果肯定也为空,因此,提前判断rdd是否为空,可以避免提交冗余的job。
3.4.10 lookup()操作

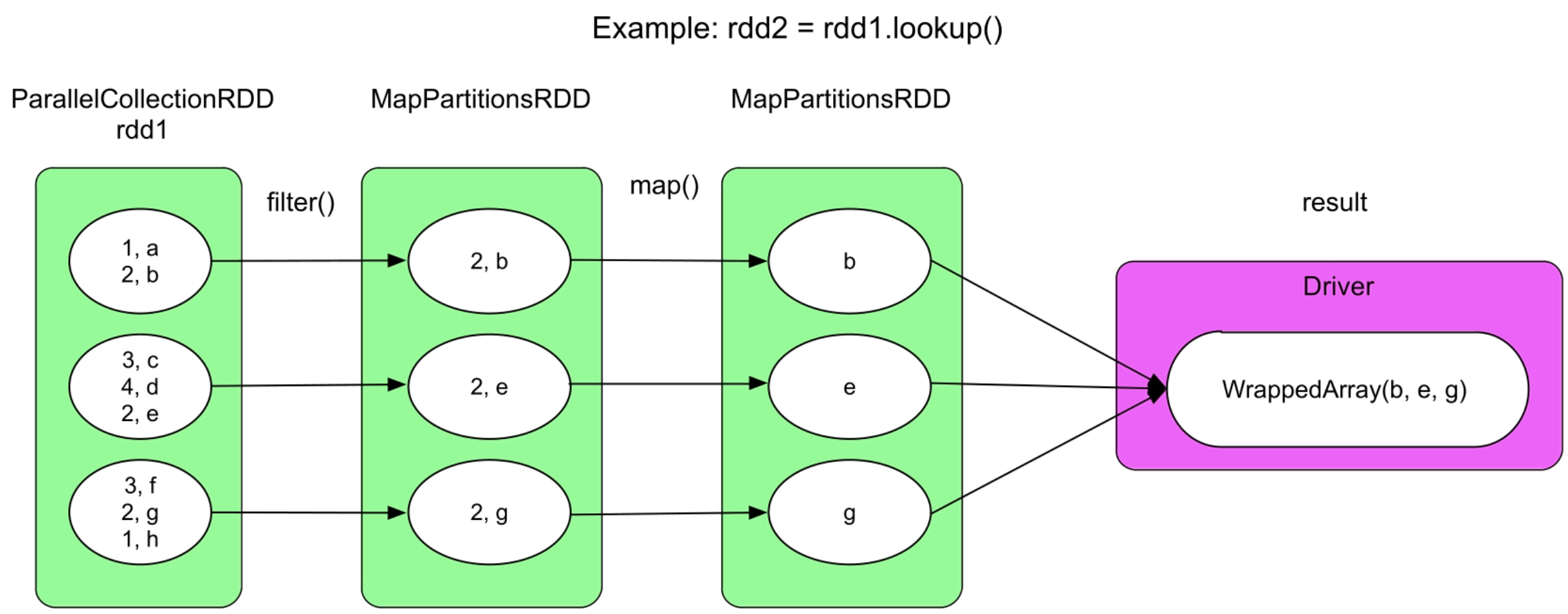
图3.39 lookup()的逻辑处理流程示例
_
lookup()首先过滤出给定Key的record,然后使用map()得到相应的Value,最后使用collect()将这些Value收集到Driver端形成list(也就是图3.39中的WrappedArray)。
3.4.11 saveAsTextFile()/saveAsObjectFile()/saveAsHadoopFile()/saveAsSequenceFile()操作

saveAsTextFile()针对String类型的record,将record转化为
3.5 对比MapReduce,Spark的优缺点
从编程模型角度来说,Spark的编程模型更具有通用性和易用性。
通用性
基于函数式编程思想,MapReduce将数据类型抽象为
Spark转变了思路,在两方面进行了优化改进:一方面借鉴了DryadLINQ/FlumeJava的思想,将输入/输出、中间数据抽象表达为一个数据结构RDD,相当于在Java中定义了class,然后可以根据不同类型的中间数据,生成不同的RDD(相当于Java中生成不同类型的object)。这样,数据结构就变得灵活了,不再拘泥于MapReduce中的<;K,V>;格式,而且中间数据变得可定义、可表示、可操作、可连接。另一方面通过可定义的数据依赖关系来灵活连接中间数据。
在MapReduce中,数据依赖关系只有ShuffleDependency,Spark对这些数据依赖关系进行了分类,并总结出ShuffleDependency、NarrowDependency(包含多种子依赖关系)。Spark使用DAG图来组合数据处理操作,比固定的map—Shuffle—reduce处理流程表达能力更强。
易用性
基于灵活的数据结构和依赖关系,Spark原生实现了很多常见的数据操作,
虽然Spark比MapReduce更加通用、易用,但还不能达到普通语言(如Java)的灵活性,具体存在两个缺点:
- Spark中的操作都是单向操作,单向的意思是中间数据不可修改。在普通Java程序中,在数据结构中存放的数据是可以直接被修改的,而Spark只能生成新的数据作为修改后的结果。
- Spark中的操作是粗粒度的。粗粒度操作是指RDD上的操作是面向分区的,也就是每个分区上的数据操作是相同的。
3.6 扩展阅读
使用DataSet、DataFrame进行的数据操作可以有效地利用Spark SQL引擎中的一些优化技术,如使用查询优化器来优化逻辑处理流程,使用Encoder避免序列化和反序列化等。

若有收获,就点个赞吧
0 人点赞
