8.1 错误容忍机制的意义及挑战
具体地,对于Spark等大数据处理框架,错误容忍需要考虑以下两方面的问题:
- 作业(job)执行失败问题
- 数据丢失问题
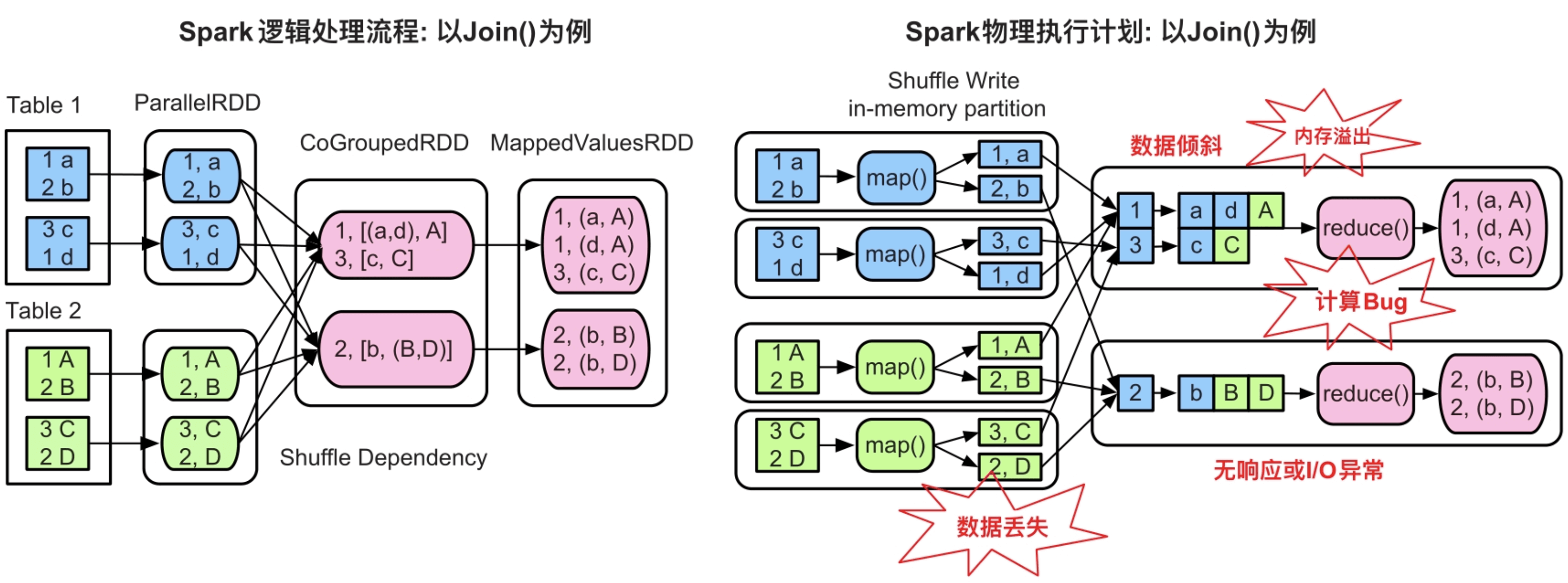
图8.1 Spark应用在运行时出现的错误(如task长时间无响应、内存溢出、I/O异常、数据丢失等)
_
8.2 错误容忍机制的设计思想
既然不能做到对每种错误都进行诊断和修复,那么Spark优先解决一类较为简单的错误:由于执行环境改变而引发的应用执行失败,如由于节点宕机、内存竞争、I/O异常导致的任务执行失败。这类执行任务失败的共同特点是可以通过重新计算来尝试修复的。例如,节点突然宕机后,可以通过重新将计算任务调度到其他节点上,并继续执行。再例如,内存竞争会导致当前没有足够资源执行计算任务,这时可以将计算任务提交到另外一台内存充足的机器上去执行。当然,如果其他节点也是内存不足,那么重新执行也会继续导致出错。
对于数据丢失问题,实际上在数据库中已经有了一些方案,如写日志、数据持久化、复制备份等。Spark采用的是数据检查点持久化方案,即checkpoint机制。
总的来说,Spark错误容忍机制的核心方法有以下两种:
- 通过重新执行计算任务来容忍错误。当job抛出异常不能继续执行时,重新启动计算任务,再次执行。
- 通过采用checkpoint机制,对一些重要的输入/输出、中间数据进行持久化。这可以在一定程度上解决数据丢失问题,而且能够提高任务重新计算时的效率。
8.3 重新计算机制
8.3.1 重新计算是否能够得到与之前一样的结果
要保证一致性,需要task的输入数据和计算逻辑满足以下3个特性。
(1)重新计算时,task输入数据与之前是一致的。
对于map task,其输入数据一般来自分布式文件系统或者上一个job的输出。由于分布式文件系统上的数据是静态可靠的,所以task再次执行时仍然能够读取到相同的数据。同样,如果已经对上一个job的输出进行了持久化,那么task再次执行时仍然可以获得相同的数据。
对于reduce task,其输入数据通过Shuffle获取,由于在Shuffle Write时一般使用确定性的partition()函数来对数据进行划分,所以每个reduce task获取的数据也是确定性的,如reduce task 0只获取Hash(Key)为0的record即可。然而,由于计算延迟和网络延迟,在Shuffle Read过程中不能保证接收到的record的顺序性,因此,reduce task再次运行时的输入数据与之前的数据是部分一致的,即接收到的数据集合与上次task一样,只是里面的record顺序可能不一样。这时,需要task满足下面两个特性才能得到一致的结果。
(2)task的计算逻辑需要满足确定性(deterministic)。
假设task在计算时调用了一个随机函数,这个结果就是不确定的了,会导致task重新执行时得到不一致的结果。
(3)task的计算逻辑需要满足幂等性(idempotent)。
幂等性是指对同样数据进行多次运算,结果都是一致的。
只有func()满足交换律和结合律,结果才是一致的,否则,将会出现不一致的结果。例如,在图8.2中,func()将list(V)中的Value按照下画线连接,如果record的顺序不同,则会得到不同的聚合结果,即使按照Key进行排序后,结果也是不同的。
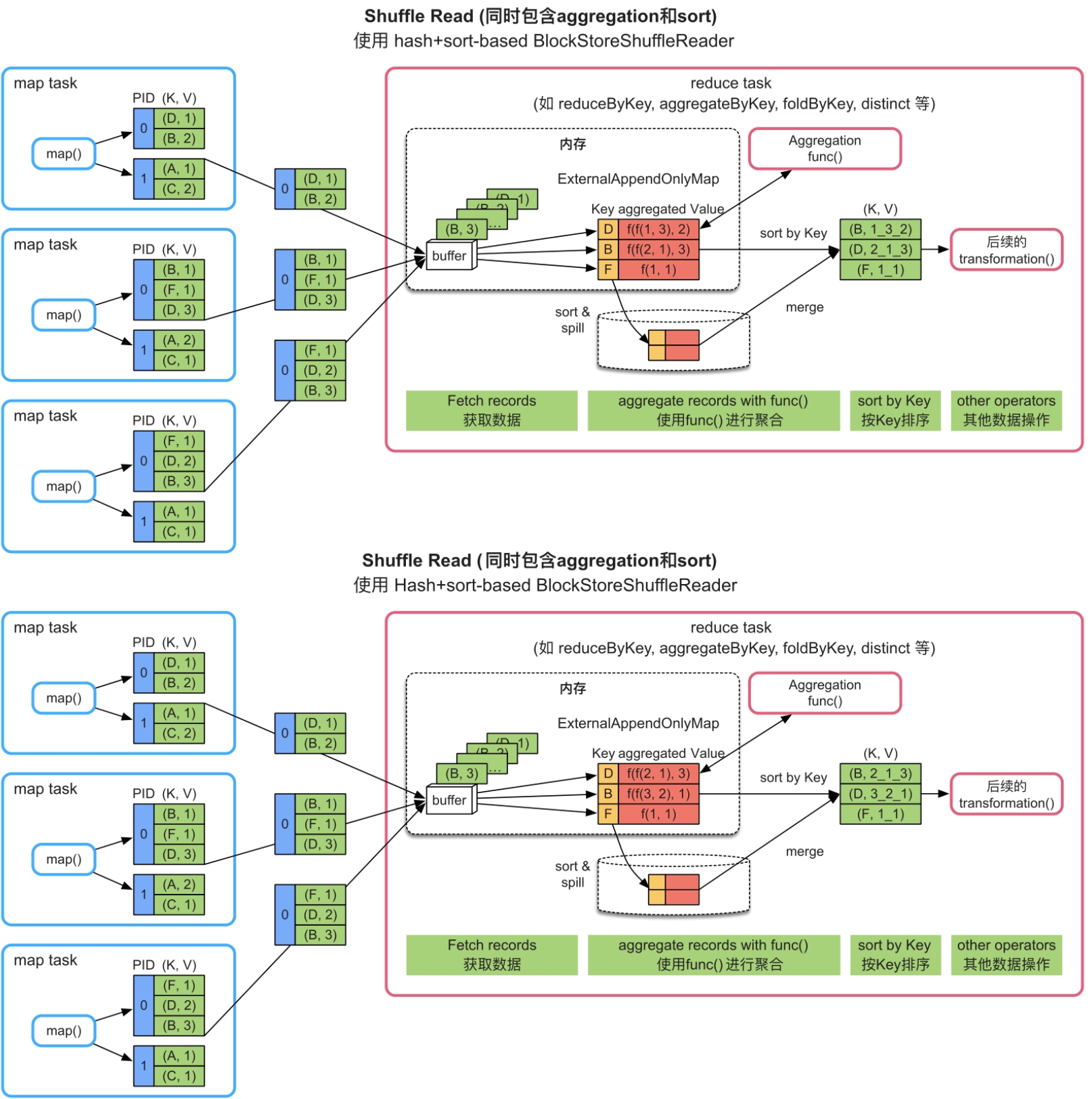
图8.2 Spark中reduce task在不同的Shuffle顺序下得到的不同计算结果(注意:红色部分与绿色部分的数字顺序有差别)
_
总的来说,重新计算机制有效的前提条件:task重新执行时能够读取与上次一致的数据,并且计算逻辑具有确定性和幂等性。
8.3.2 从哪里开始重新计算
(1)重新执行失效的task时,是否还需要执行其上游stage中的task?
如图8.3所示,stage 0和stage 1中的task的输入数据来自分布式文件系统上的固定数据。这些task在重新计算时,直接读取分布式文件系统上的数据计算即可。而下游stage 2中的task的输入数据是通过Shuffle Read读取上游stage输出数据的。
如果stage 2中的某个task执行失败,重新运行时需要再次读取stage 0和stage 1的输出结果,那么如何能够再次读到同样的数据而且避免对上游的task重新计算呢?Spark采用了“延时删除策略”,即将上游stage的Shuffle Write的结果写入本地磁盘,只有在当前job完成后,才删除Shuffle Write写入磁盘的数据。这样,即使stage 2中某个task执行失败,但由于上游的stage 0和stage 1的输出数据还在磁盘上,也可以再次通过Shuffle Read读取得到同样的数据,避免再次执行上游stage中的task。所以,Spark根据ShuffleDependency切分出的stage既保证了task的独立性,也方便了错误容忍的重新计算。
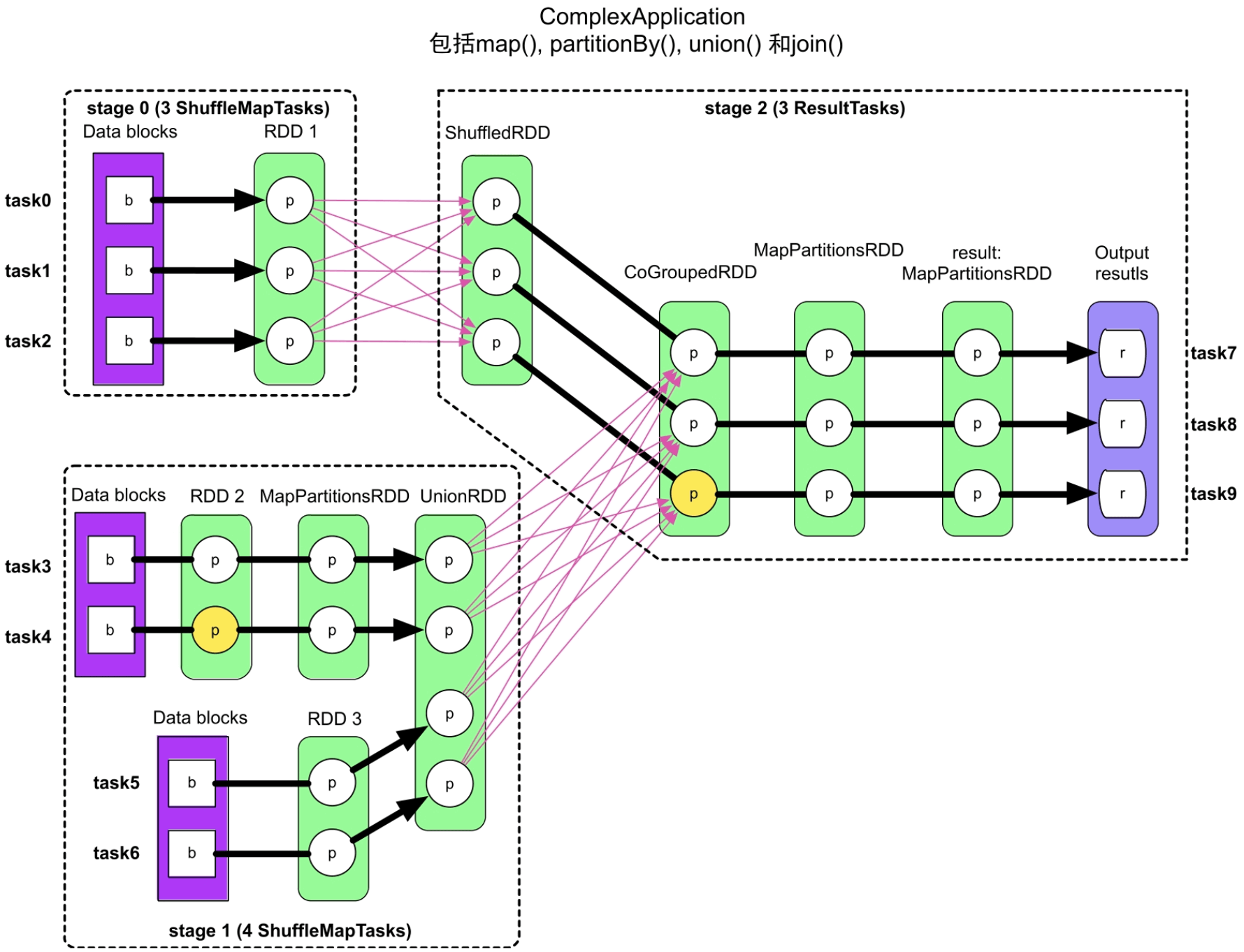
图8.3 一个复杂的Spark应用的物理执行计划(黄色圆圈代表已被缓存的partition)
_
(2)一个task一般会连续计算多个RDD,那么每个RDD都需要重新被计算吗?
这个问题的答案取决应用是否存在缓存数据。对于没有缓存数据的情况,每个RDD都需要重新被计算。对于有缓存的情况,如在图8.3中,在stage 1中的task4,RDD2中相应的分区数据已经被缓存,那么直接从RDD2开始计算即可。
(3)缓存数据如果丢失也需要重新计算,那么从哪里开始计算呢?
如图8.3所示,如果RDD2的第2个分区的缓存数据丢失,那么需要再次启动task4,读取Data blocks数据,计算该分区数据。如果CoGroupedRDD的第3个分区的缓存数据丢失,那么再次启动task9,通过Shuffle Read数据计算ShuffledRDD=>CoGroupedRDD对应的分区数据。
上述3个问题的解决方案都不难,然而统一实现起来就会很复杂,需要考虑各种情况和问题:如task是否需要Shuffle Read?stage中的计算步骤是什么?计算路径上的数据是否包含缓存数据?缓存数据是如何计算出来的?等等。
为了使用更通用的方法解决上述问题,Spark采用了一种称为lineage的数据溯源方法。这个方法的核心思想是在每个RDD中记录其上游数据是什么,以及当前RDD是如何通过上游数据(parent RDD)计算得到的。
这样在错误发生时,可以根据lineage追根溯源,找到计算当前RDD所需的数据和操作,所以lineage更通俗的意思就是计算链(computation chain)。如果计算链上存在缓存数据,那么从缓存数据处截断计算链,即可得到简化后的操作。不管当前RDD本身是缓存数据还是非缓存数据,都可以通过lineage回溯方法找到计算该缓存数据所需的操作和数据。
lineage的实现细节:图8.4展示了图8.3中的result:MapPartitionsRDD持有的lineage,其中prev变量和rdd变量清晰地记录了result与parent RDD的关联关系。从图8.4中可知,result:MapPartitionsRDD的上游是MapPartitionsRDD,再上游是CoGroupedRDD,而CoGroupedRDD的上游包含ShuffledRDD和UnionRDD两个RDD,还可以进一步看到UnionRDD的parent RDD。图8.5展示了result:MapPartitionsRDD的计算函数f (),也就是result是如何被计算得到的。这两组信息构成了计算链,解决了数据和计算追根溯源的问题。
图8.4 计算过程中RDD持有的lineage
图8.5 计算过程中RDD持有的计算函数f ()
总的来说,lineage就是数据依赖关系。这个数据依赖关系不仅用来划分stage,在“正向”计算时得到输出结果,也可以在错误发生时,用来回溯需要重新计算的数据,达到错误容忍的目的。
8.3.3 重新计算机制小结
Spark采用了最朴素的重新计算机制来解决由于软硬件环境改变引发的错误问题,但是重新计算机制要求task的计算逻辑满足确定性、幂等性。虽然Shuffle Read的数据不能保证顺序性,但一般应用并不要求结果有序(或者只要求Key有序),因此,当前的重新计算机制是可行的。
重新计算需要面对各种各样的情况,Spark采用了lineage来统一对RDD的数据和计算依赖关系进行建模,使用回溯方法解决从哪里重新计算,以及计算什么的问题。
8.4 checkpoint机制的设计与实现
重新计算存在一个缺点是,如果某个数据(RDD)的计算链过长,那么重新计算该数据的代价非常高。
为了提高重新计算机制的效率,也为了更好地解决数据丢失问题,Spark采用了检查点(checkpoint)机制。该机制的核心思想是将计算过程中某些重要数据进行持久化,这样在再次执行时可以从检查点执行,从而减少重新计算的开销。虽然checkpoint机制的思想很简单,但与Spark重新计算机制结合使用时,还面临多个问题,下面具体介绍这些问题。
8.4.1 哪些数据需要使用checkpoint机制
那么从直观上来说,应该对计算耗时较高的数据进行持久化。具体地,我们通过分析单个job和多个job的情况来总结哪些数据需要使用checkpoint机制。
(1)单个job的情况
以图8.3为例,假设没有数据缓存(黄色的partition变为白色),我们来分析该job的每个stage中哪些数据需要使用checkpoint机制。在stage 0中RDD1的计算代价较低,task直接读取分布式文件系统上的数据块,进一步计算就得到RDD1,因此不需要对RDD1进行checkpoint。相比RDD1,stage 1中的UnionRDD的计算代价中等,需要运行更多的task、经过更多的计算步骤才能得到,如果UnionRDD的数据量不大的话,则可以考虑对其进行checkpoint。
在stage 2中,对RDD1进行Shuffle Read直接得到ShuffledRDD,ShuffledRDD的计算代价较低,而CoGroupedRDD需要对ShuffleRDD和上一阶段的UnionRDD聚合得到,依赖数据较多,计算较为复杂耗时。所以,建议对CoGroupedRDD进行checkpoint,这样当task7、task8或task9执行出错再次运行时,可以从CoGroupedRDD直接开始计算,不需要进行Shuffle Read。
这里可能有一个观点:CoGroupedRDD不需要进行checkpoint,因为RDD1和UnionRDD的结果已经Shuffle Write到本地磁盘了,重新执行task7、task8或task9时只需要进行Shuffle Read+计算即可,代价并不高。该观点忽略的一个问题是本地磁盘并不可靠,一旦节点宕机,RDD1或者UnionRDD通过Shuffle Write写入磁盘的数据(只有一份)就丢失了,重新计算时需要重新执行task0~task6,计算代价会很高,因此,对于数据依赖较多、经过复杂计算才能得到的RDD,可以使用checkpoint对其进行持久化。
这里再补充一点:对于图8.3中的应用来说,CoGroupedRDD由Spark生成,对用户不可见,因此用户如果想要Checkpoint CoGroupedRDD的话,则可以考虑对其可见的parent RDD和child RDD进行checkpoint。
(2)多个job的情况
相比单个job,多个job的情况需要考虑job之间传递的数据是否需要checkpoint。在应用中存在多个job,尤其是在多个job串联执行的情况下,每执行完一个job后,Spark会将该job中上游stage的Shuffle Write数据清空,以减少占用的磁盘空间。
一个迭代型应用每轮迭代都可能执行一个job,每执行完一个job都会将该job中的Shuffle Write数据清空,只留下被缓存的数据,如cached RDD1、cached RDD2和cached RDD3。当然,由于缓存替换机制,旧的缓存数据(如cached RDD1)也可能被清除。当不断被清除的缓存数据和清除的Shuffle Write数据会导致下游task重新计算时,则要从更加上游的地方开始,从而增加了计算量。
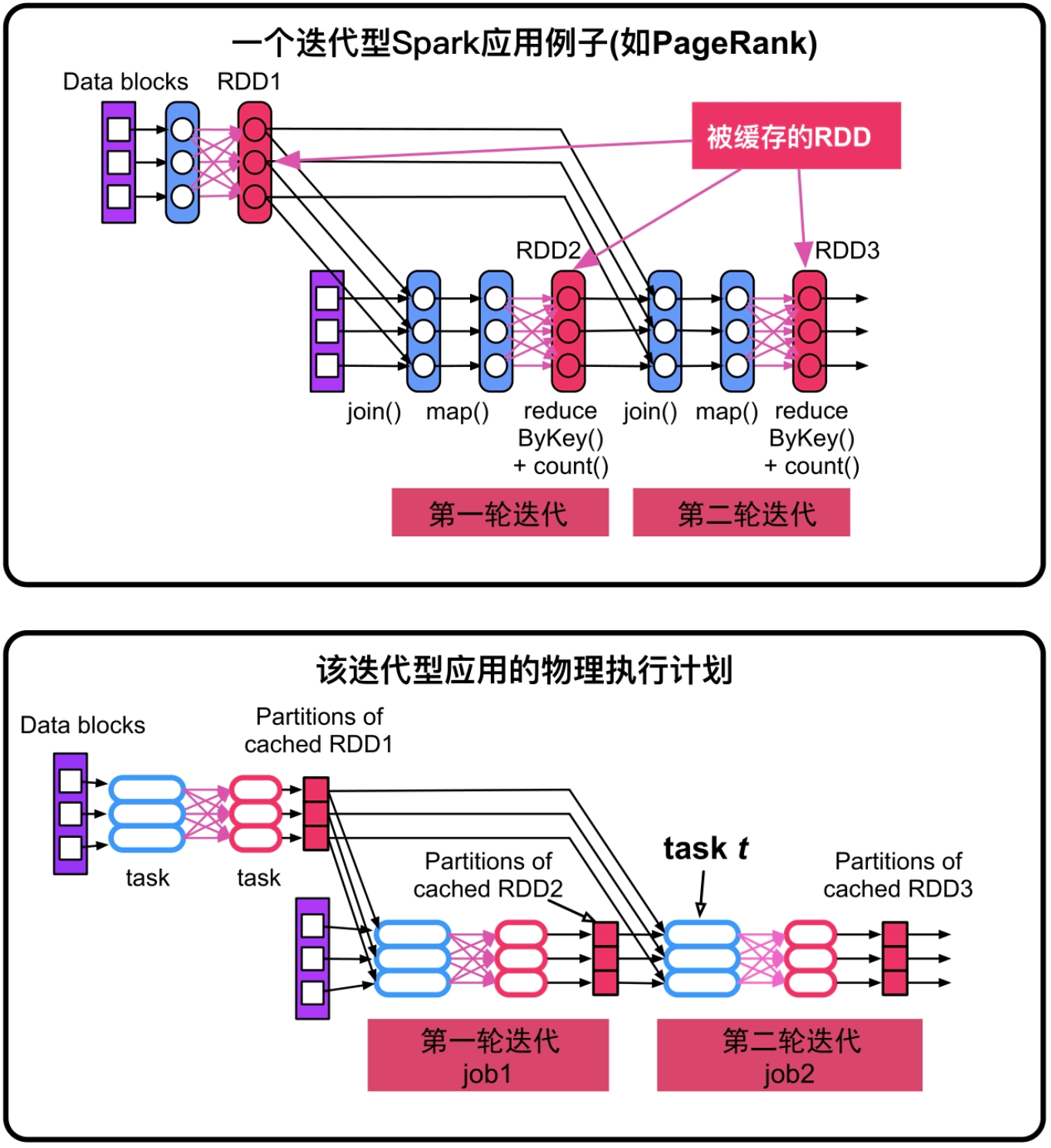
图8.6 迭代型应用的逻辑处理流程和物理执行计划
_
所以,对于串联执行的job,尤其是迭代型job,需要每隔几个job(或者每迭代m轮)就对一些中间数据进行checkpoint,这样在出错时,可以从最近的checkpoint数据恢复执行。
在图8.6中,cached RDD1在每轮迭代中都被使用,所以除了对其进行缓存,也最好对其进行checkpoint,这样不仅可以提高读取效率,也可以避免因为缓存替换或者宕机引起的每轮迭代RDD1都需要重新计算的问题。
总的来说,需要被checkpoint的RDD满足的特征是,RDD的数据依赖关系比较复杂且重新计算代价较高,如关联的数据过多、计算链过长、被多次重复使用等。
8.4.2 checkpoint数据的写入及接口
checkpoint的目的是对重要数据进行持久化,在节点宕机时也能够恢复,因此需要可靠地存储。另外,checkpoint的数据量可能很大,因此需要大的存储空间。所以,一般采用分布式文件系统,如HDFS来存储。当然,如果内存空间足够大,且想加速存储与读取过程,则也可以选择基于内存的分布式文件系统Alluxio。
在Spark中,提供了sparkConext.setCheckpointDir(directory)接口来设置checkpoint的存储路径。同时,提供rdd.checkpoint()来实现checkpoint。
示例1:一个简单的checkpoint应用,对中间数据进行checkpoint。

如图8.7所示,第1个job计算count()结果,并将pairs:MapPartitionsRDD所有的partition checkpoint到HDFS中。第2个job首先从checkpoint文件中读取pairs:RDD,然后进行groupByKey()和foreach()计算。Spark在checkpoint时对RDD数据进行了序列化。
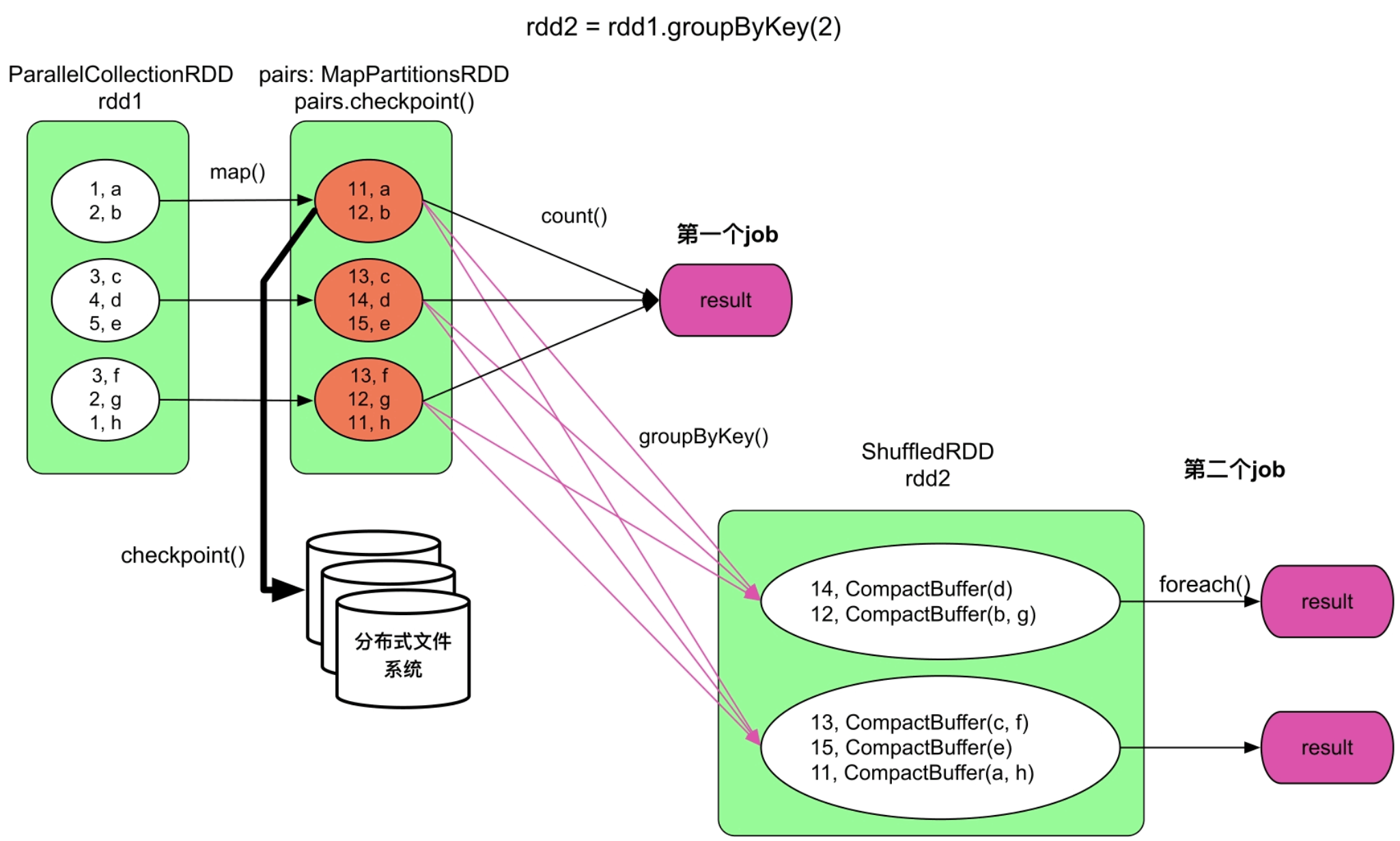
图8.7 示例的逻辑处理流程
图8.8 示例1应用在checkpoint目录存放的序列化后的RDD数据
根据图8.7的物理执行计划,我们认为只会产生两个job。然而,查看该应用实际生成的job信息,则会发现实际生成了3个job,如图8.9所示。那么为什么会多一个job 1呢?我们接下来通过研究checkpoint的时机及计算顺序来回答这个问题。
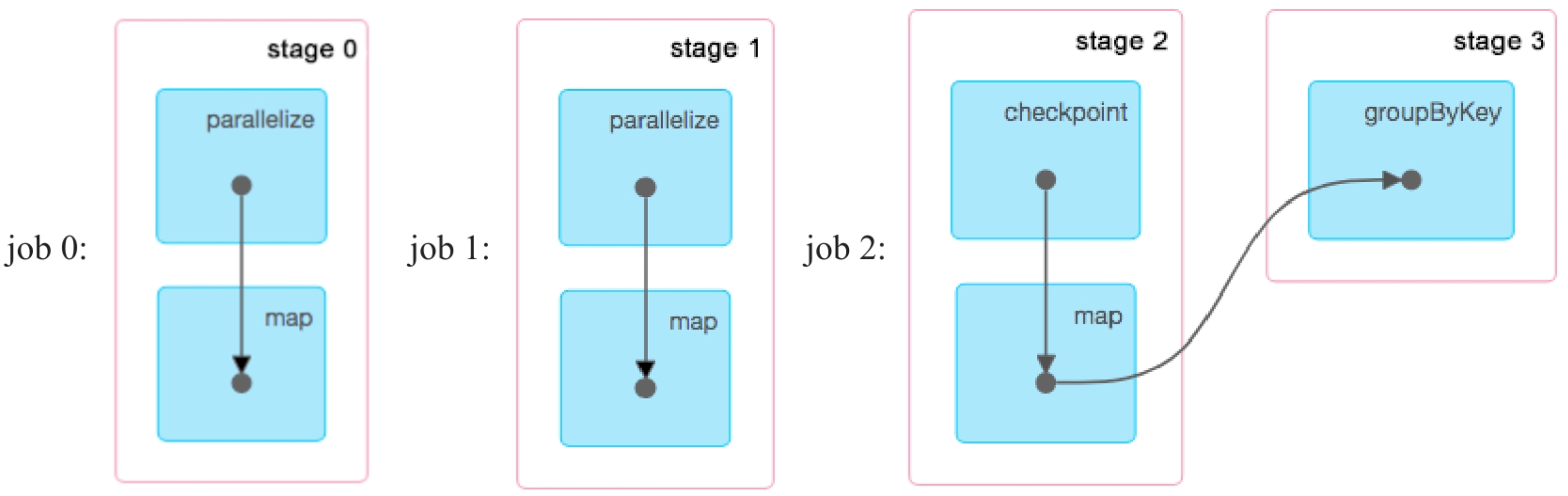
图8.9 示例1应用生成的3个jobs(job 2中的map()操作是用来读取checkpoint数据的)
_
8.4.3 checkpoint时机及计算顺序
checkpoint将数据持久化到分布式文件系统(如HDFS)时需要写入磁盘,而且一般需要复制3份进行跨节点存储,且写入时延高。同时,后续操作需要从HDFS中读取数据,读取代价也很高。如果需要checkpoint的RDD包含的数据量很大,则将会严重影响job的执行时间,造成很高的磁盘I/O代价。
其实Spark也没有好的解决方案,权宜之计是一种比较简单粗暴的方法:用户设置rdd.checkpoint()后只标记某个RDD需要持久化,计算过程也像正常一样计算,等到当前job计算结束时再重新启动该job计算一遍,对其中需要checkpoint的RDD进行持久化。也就是说,当前job结束后会另外启动专门的job 去完成checkpoint,需要checkpoint的RDD会被计算两次。
如图8.7所示,用户设置pairs.checkpoint()后,Spark将pairs:RDD标记为需要被checkpoint,然后正常执行第1个job。执行完以后,重新执行该job,计算rdd1=>pairs,每计算出pairs中的一个record,就将其持久化写入HDFS。当所有record写入完成后,job结束,不需要执行后续的count()操作。这就是为什么实际执行时会多了一个job1。第3个job读取存储在HDFS上的pairs数据中,并正常执行groupByKey()操作。
显然,checkpoint启动额外job来进行持久化会增加计算开销。为了解决这个问题,Spark推荐用户将需要被checkpoint的数据先进行缓存,这样额外启动的任务只需要将缓存数据进行checkpoint即可,不需要再重新计算RDD,可以在一定程度上提高效率。
8.4.4 checkpoint数据的读取
checkpoint数据存储在分布式文件系统(HDFS)上,读取方式与从分布式文件系统读取输入数据没什么太大区别,都是启动task来读取的,并且每个task读取一个分区。只有以下2个不同点:
- checkpoint数据格式为序列化的RDD,因此需要进行反序列化重新恢复RDD中的record。
- checkpoint时存放了RDD的分区信息,如使用了什么partitioner。这样,重新读取后不仅恢复了RDD数据,也可以恢复其分区方法信息,便于决定后续操作的数据依赖关系。例如,决定之后的join()操作应该采用的数据依赖关系是OneToOneDependency还是ShuffleDependency。
8.4.5 checkpoint数据写入和读取的实现细节
在实现中,RDD需要经过[Initialized→CheckpointingInProgress→Checkpointed]这3个阶段才能真正被checkpoint。
(1)Initialized
当应用程序使用rdd.checkpoint()设定某个RDD需要被checkpoint时,Spark为该RDD添加一个checkpointData属性,用来管理该RDD相关的checkpoint信息。
如图8.10所示,当程序执行到pairs.checkpoint()时,对paris.checkpointData对象初始化,该对象保存了pairs的checkpoint的路径及Initialized状态。

图8.10 初始化pairs:RDD的checkpoint状态为Initialized
(2)CheckpointingInProgress
当前job结束后,会调用该job最后一个RDD(finalRDD)的doCheckpoint()方法。该方法根据finalRDD的computing chain回溯扫描,遇到需要被checkpoint的RDD就将其标记为CheckpointingInProgress。
在图8.11中,将pairs.checkpointData的cpState标记为CheckpointingInProgress。之后,Spark会调用runjob()再次提交一个job完成checkpoint。

图8.11 将pairs:RDD的checkpoint状态设置为CheckpointingInProgress
(3)Checkpointed
再次提交的job对RDD完成checkpoint后,Spark会建立一个newRDD,类型为ReliableCheckpointRDD,用来表示被checkpoint到磁盘上的RDD。
如图8.12所示,newRDD实际就是Checkpoined pairs:RDD,保留了pairs:RDD的分区信息。但与pairs:RDD不同的是,newRDD将lineage截断(dependencies_=null),不再保留pairs依赖的数据和计算,原因是pairs:RDD已被持久化到可靠的分布式文件系统,不需要再保留pairs:RDD是如何计算得到的。注意,newRDD的分区类型为CheckpoinedRDDPartition,表示该分区已经被持久化。
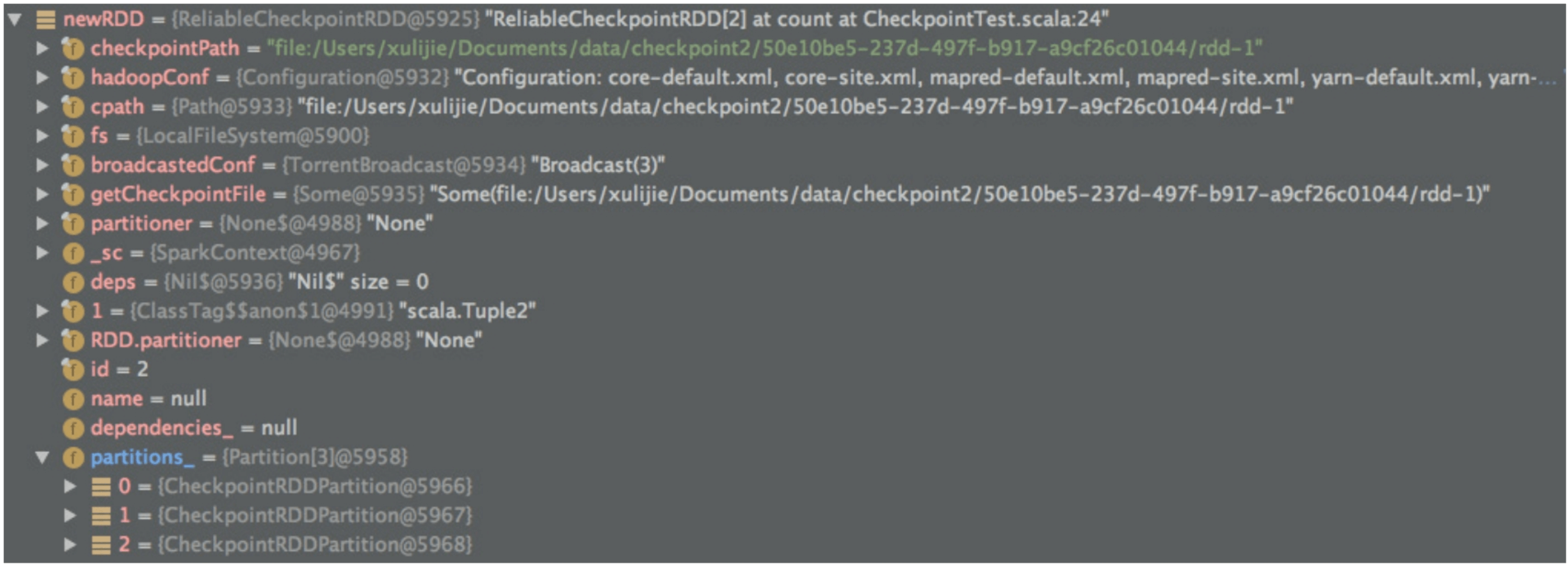
图8.12 checkpoint过程中生成的newRDD,表示Checkpointed RDD
_
生成newRDD后,Spark需要将pairs和newRDD进行关联。当后续job需要读取pairs时,可以去读取newRDD。
如图8.13所示,Spark将newRDD赋值给pairs.checkPointRDD.cpRDD。同时,将pairs的数据依赖关系也清空(本来使用OneToOneDependency 依赖inputRDD),因为访问pairs即访问newRDD,而newRDD不需要依赖任何RDD。这个步骤完成后,将pairs.checkPointRDD.cpState的状态设置为Checkpointed。至此,checkpoint的写入过程结束。
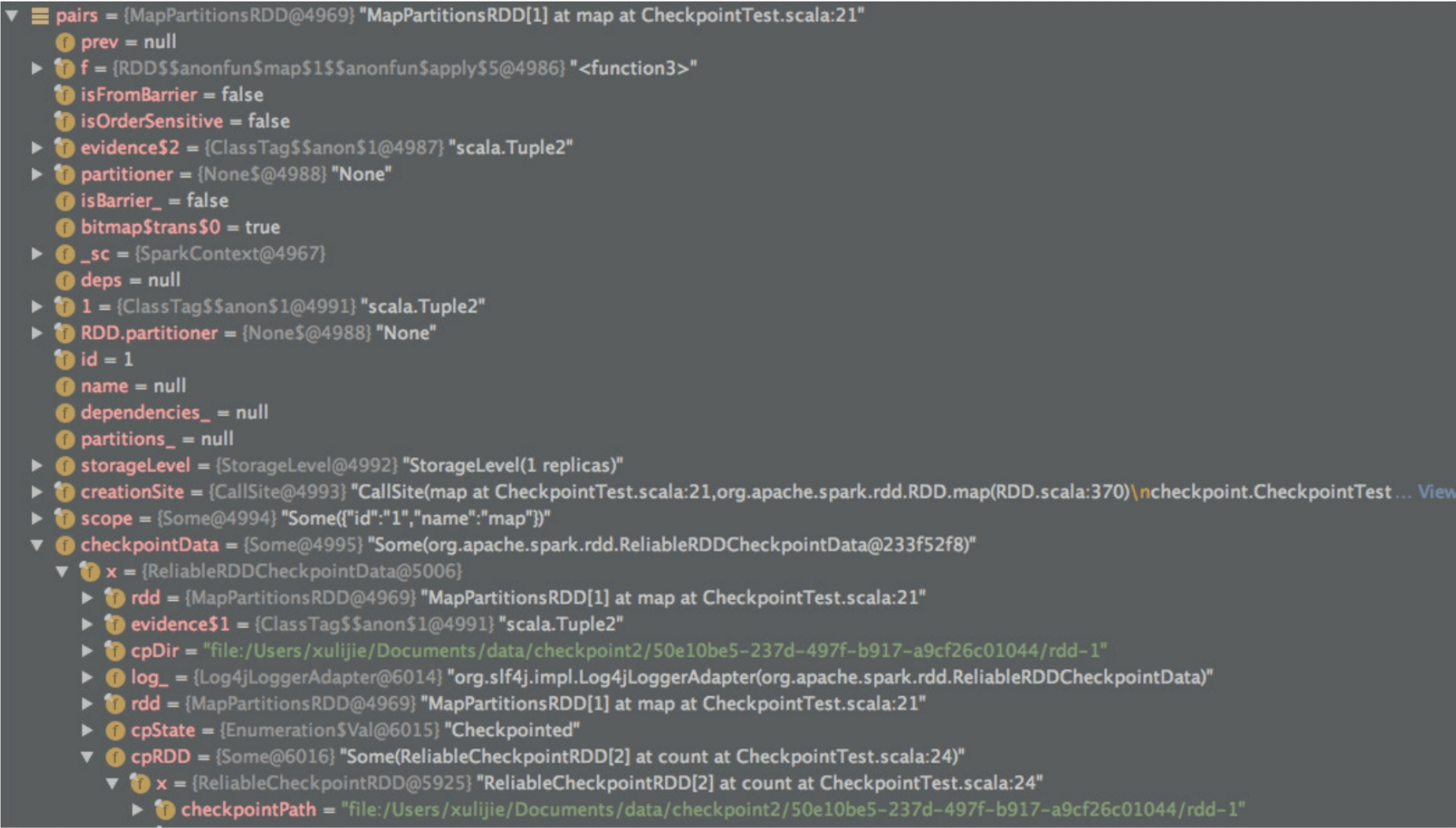
图8.13 将newRDD作为pairs的一个属性,读取pairs即读取newRDD
下面我们通过val result=pairs.groupByKey()的计算链来看一下Checkpointed RDD的读取过程。如下所示,job读取pairs:MapPartitionsRDD时,会读取newRDD:ReliableCheckpointRDD。
总的来说,checkpoint的写入过程不仅对RDD进行持久化,而且会切断该RDD的lineage,将该RDD与持久化到磁盘上的Checkpointed RDD进行关联。这样,读取该RDD时,即读取Checkpointed RDD。
8.4.6 checkpoint语句位置的影响
(1)checkpoint多个RDD
在foreach()语句之前添加result.checkpoint()语句,那么会checkpoint paris和result这两个RDD吗?会发现在checkpoint文件夹下确实生成了rdd-1和rdd-3两个RDD文件,分别代表Checpointed pairs和result。另外,rdd-3还包含了一个分区信息文件_partitioner,里面标注了result使用的划分方法为Hash划分。这样,读取rdd-3时既可以还原result RDD的数据也可以还原其分区信息,就像是在运行过程中动态计算出来的。
checkpoint两个RDD对计算流程有什么影响?根据前面checkpoint的设计原理分析,我们猜想对result:RDD进行checkpoint会多增加一个job。如图8.15所示,实际执行时确实比示例程序Example1(见图8.9)多了一个job 3。job 3计算得到result:RDD,并对其进行checkpoint。然而,我们发现job 3中的stage 4被忽略了,stage 4被忽略的原因与当前Spark实现细节有关。job 2完成后没有删除stage 2和Shuffle Write到本地磁盘上的数据,而是等到job 3(重新执行job 2的逻辑来进行checkpoint)完成后再删除,这样job 3可以直接读取stage 2的输出数据进行groupByKey()计算,不需要运行stage 4。而对于一般的job来说,job完成后需要删除其上游stage和Shuffle Write到磁盘上的数据。
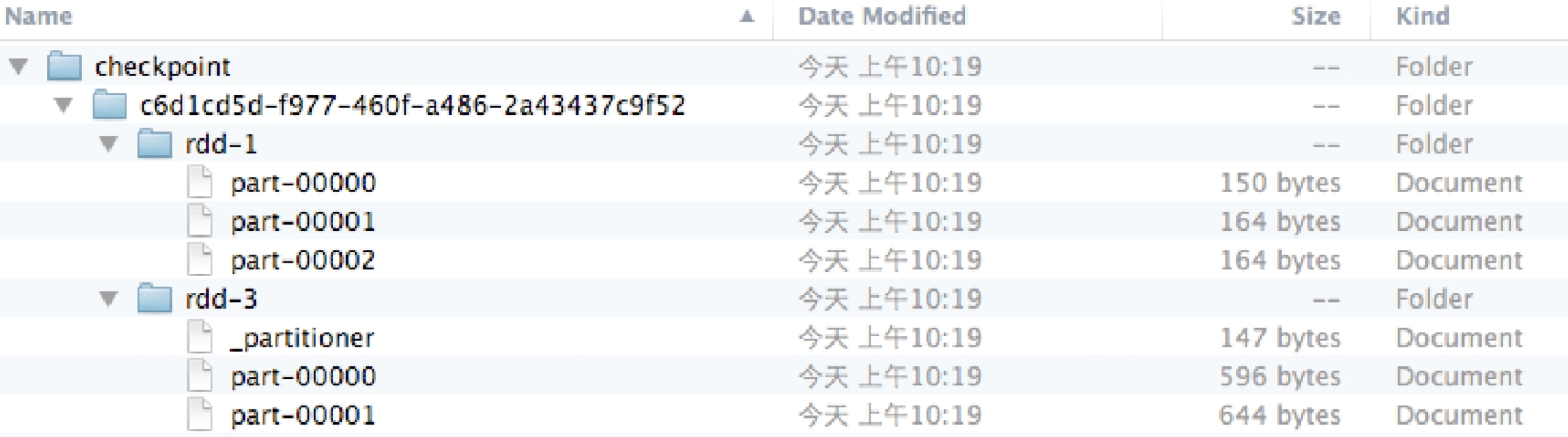
图8.14 checkpoint两个RDD后的写入文件信息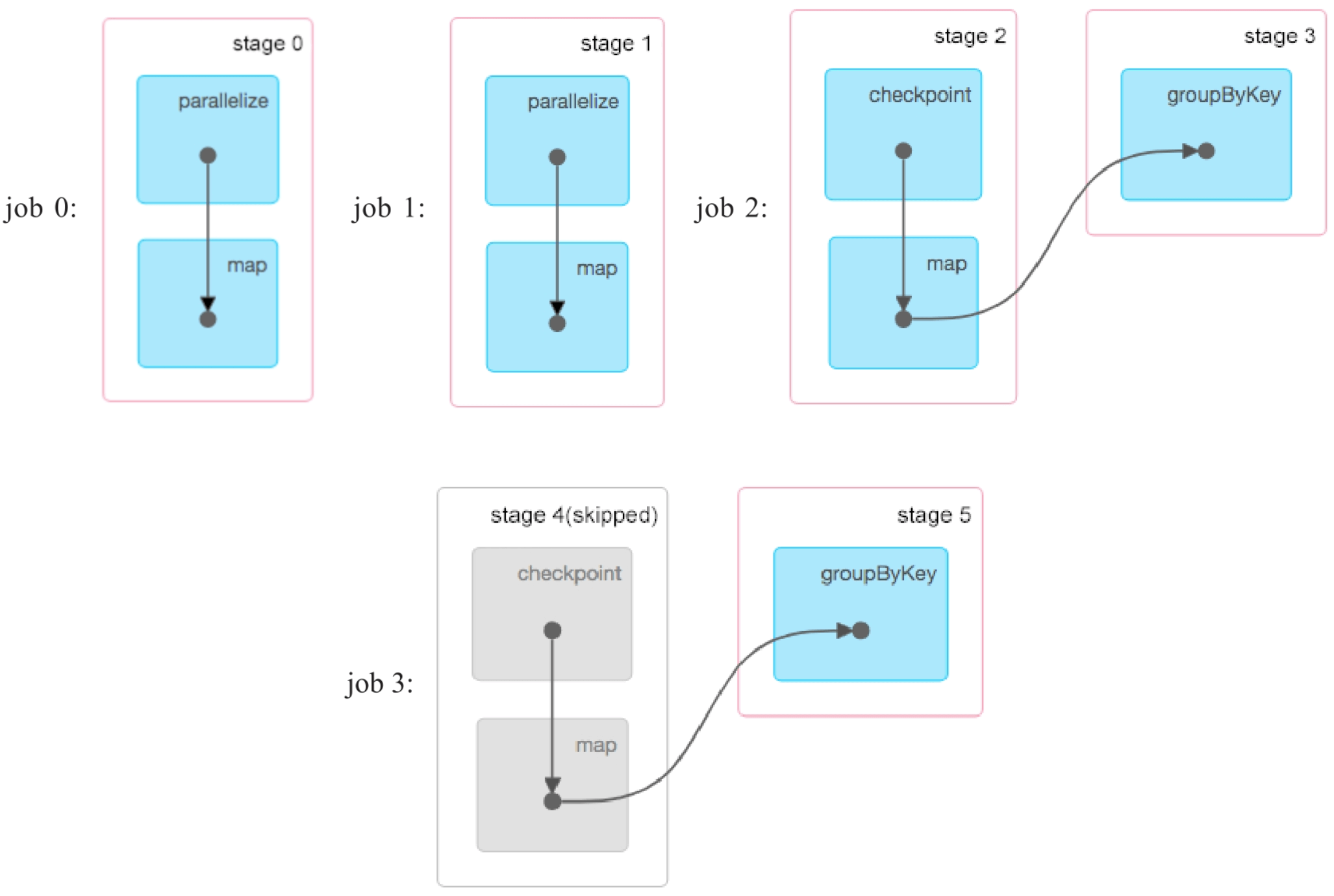
图8.15 checkpoint两个RDD后生成的4个job,其中job 1和job 3用于checkpoint
(2)checkpoint语句放置在action()语句之后
示例2:将checkpoint语句放在count()语句之后。
如果把checkpoint语句都放在action()语句之后,还会进行checkpoint操作吗?如下面的Example2示例程序所示,我们将checkpoint放在count()和foreach()之后,再次运行发现:pairs和result两个RDD都没有被checkpoint。
生成的job如图8.16所示,没有用于被checkpoint的job。没有对result RDD进行checkpoint的原因可能是,checkpoint语句只是标识某个RDD需要进行checkpoint,需要在运行action job的过程中完成标识,然后再启动真正的job进行实际的checkpoint。当action job已经运行完成,就不会将对应RDD进行标识,自然也就不会checkpoint。然而,这个思路并不能解释pairs:RDD为什么没有被checkpoint?虽然我们将checkpoint语句放在count()之后,但是其在foreach()之前,所以理应对pairs进行checkpoint。还有,当我们去掉pairs.count()语句后,pairs是可以被checkpoint的,如图8.17所示,因此,Example2中pairs:RDD没有被checkpoint的原因是系统Bug。
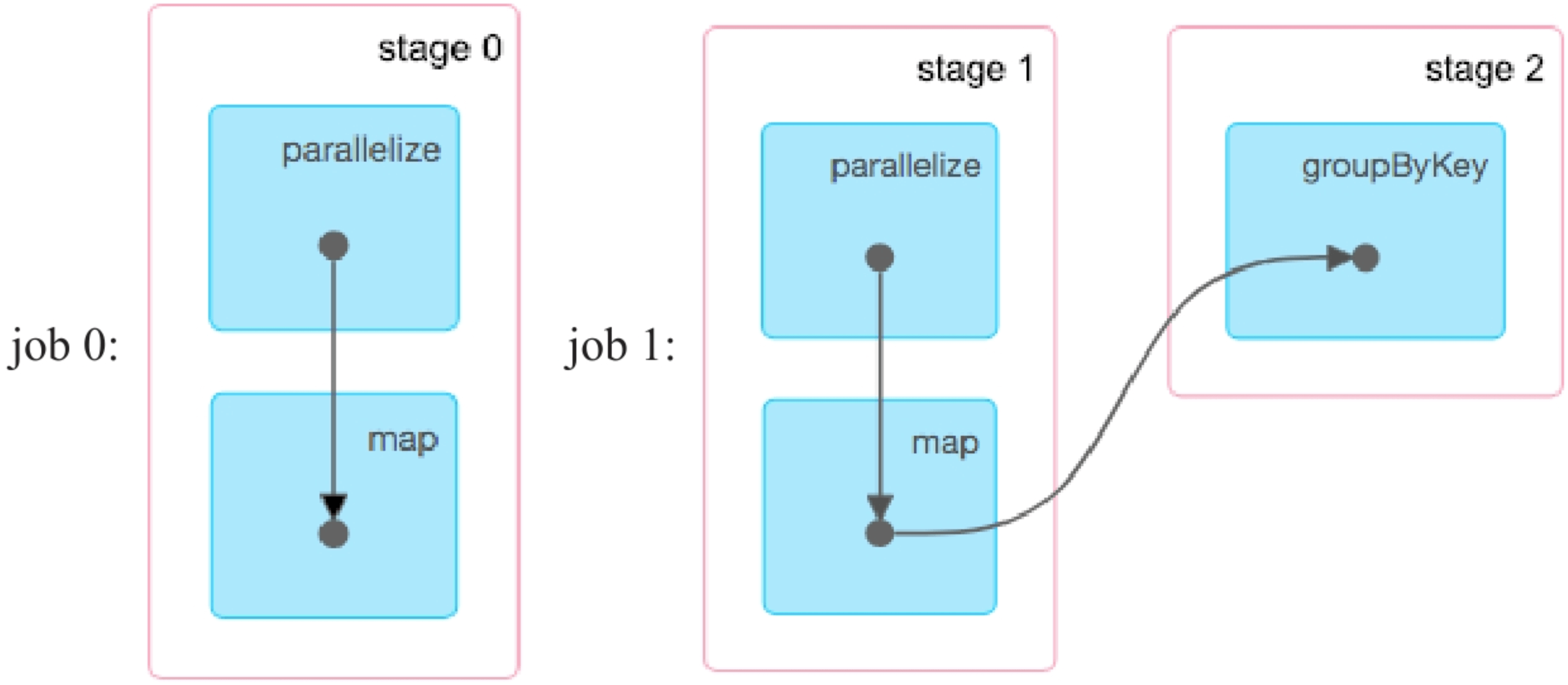
图8.16 checkpoint语句放到action之后生成的job,没有生成用于checkpoint的job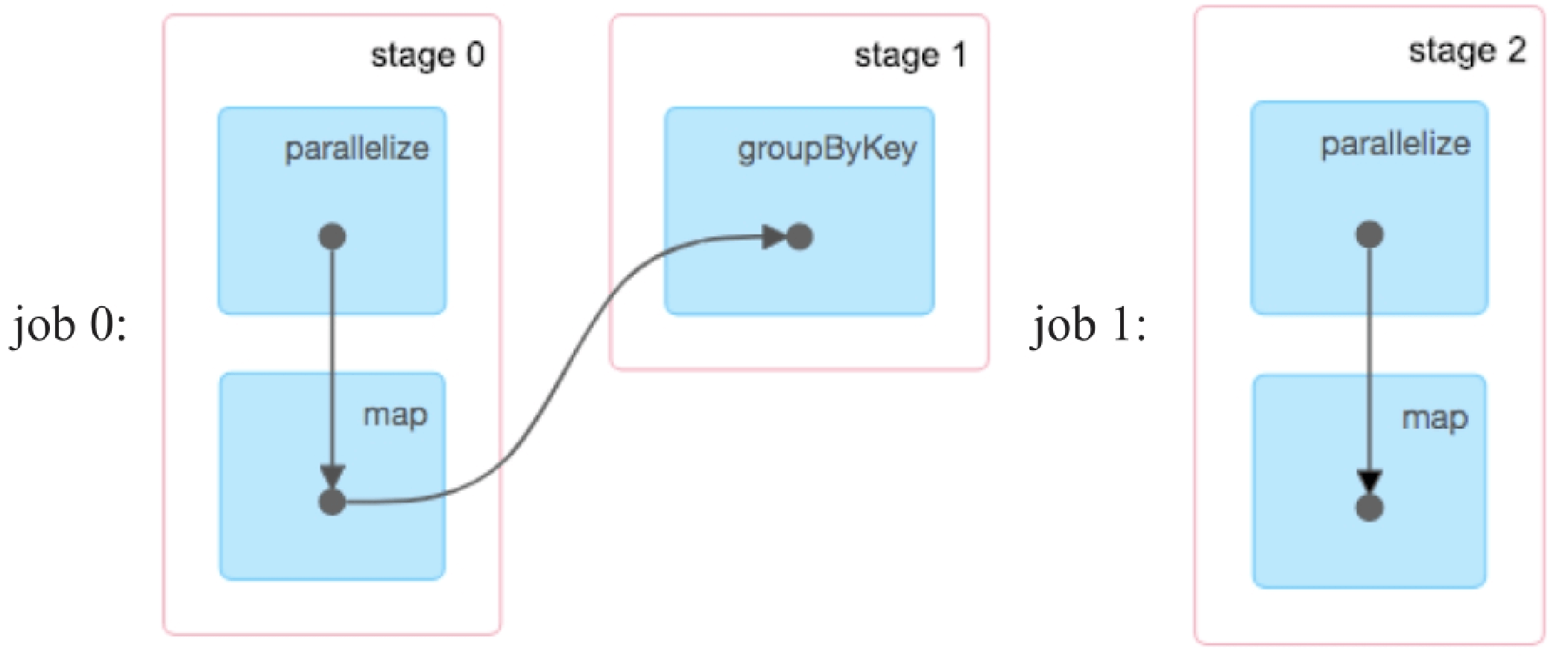
图8.17 去掉pairs.count()语句后生成的job,生成了用于checkpoint pairs的job 1_
(3)在一个job中对多个RDD进行checkpoint
示例3:在一个job中对pairs和result两个RDD进行checkpoint。


直观上理解,pairs和result都应该被checkpoint,然而运行后发现只有result:rdd-2被checkpoint了,如图8.18所示。通过查看执行job,如图8.19所示,发现只有针对result:RDD的checkpoint job。这个原因是,目前checkpoint的实现机制是从后往前扫描的,先碰到result:RDD,对其进行checkpoint,同时将其上游依赖关系(lineage)设置为空,表示重新运行时从这里读取数据即可,不需要再回溯到parent RDD。这个机制导致pairs在从后往前的checkpoint搜索过程中不能被访问到,因此没有被checkpoint。Spark系统开发人员意识到了这个问题,也在源码中将这个问题列为下一步(TODO)工作,拟采用的解决方法是从前往后扫描,先对parent RDD进行checkpoint,然后再对child RDD进行checkpoint(checkpoint parents first because our lineage will be truncated after we checkpoint ourselves)。

图8.18 在同一个job中对两个RDD都进行checkpoint时,只有result被持久化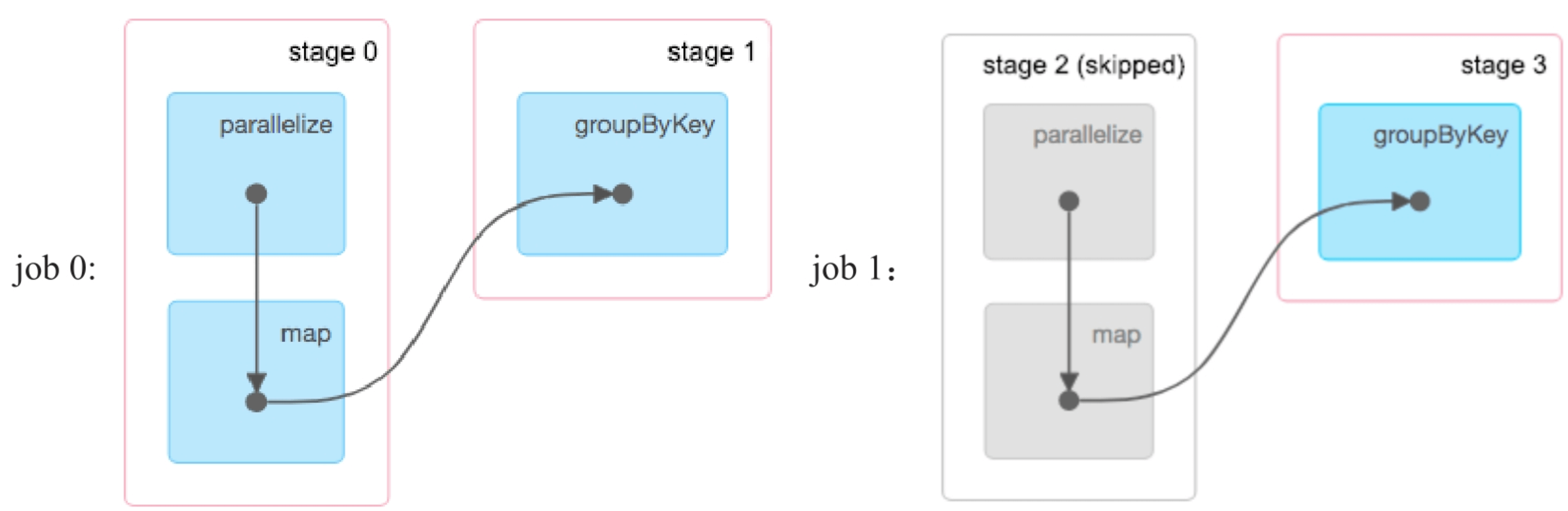
图8.19 在同一个job中对两个RDD都进行checkpoint时,只有result被持久化_
8.4.7 cache+checkpoint
前面介绍过,Spark建议用户在checkpoint RDD的同时对其进行缓存,那么在这种情况下生成的job与只进行缓存有什么异同呢?缓存和checkpoint的顺序是怎样的呢?
示例4:对pairs:RDD既进行缓存也进行checkpoint。


如图8.20所示,示例4应用生成3个job,第1个由count()生成的job在运行时对pairs:RDD进行缓存,然后启动第2个job读取cached pairs:RDD,并对pairs进行checkpoint。最后启动第3个job,其中stage 2读取pairs缓存数据并进行Shuffle Write,stage 3进行groupByKey()操作,输出结果。也就是说,应用先对pairs进行缓存,然后再checkpoint,读取时读取缓存数据而非checkpoint数据。
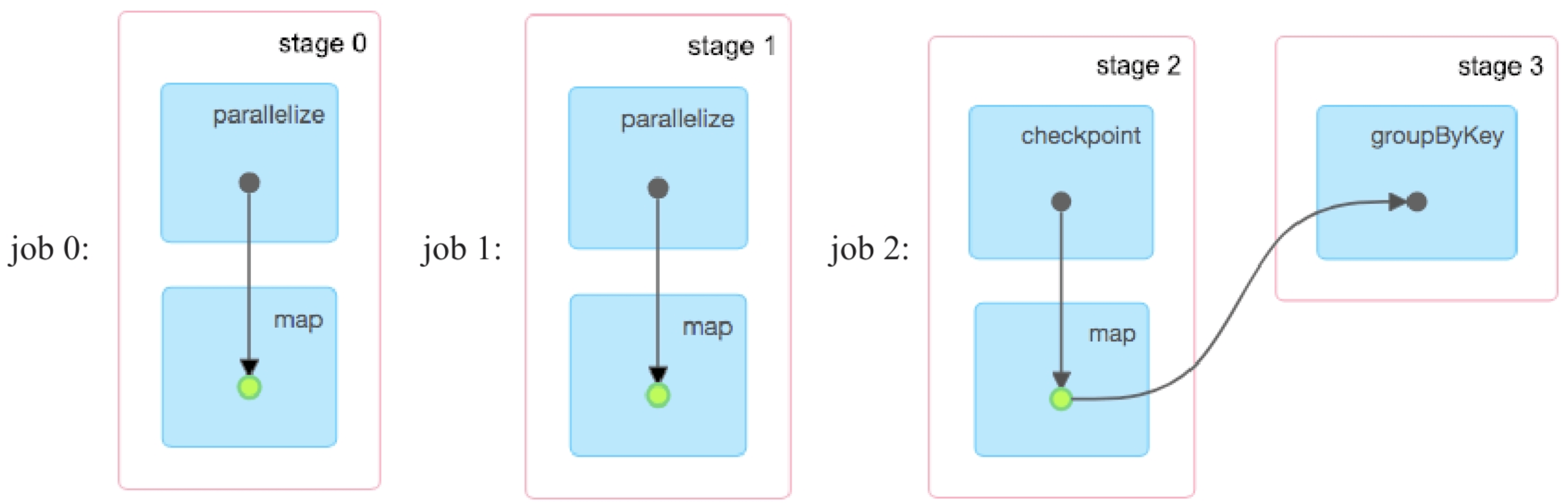
图8.20 同时对pairs:RDD进行缓存和checkpoint生成的3个job
_
result RDD的lineage如下所示,该lineage进一步说明读取pairs:MapPartitionsRDD时优先读取缓存数据(CachedPartitions)。CachedPartitions之下的ReliableCheckpointRDD表示MapPartitionsRDD依赖ReliableCheckpointRDD,但MapPartitionsRDD已经被缓存,不必从ReliableCheckpointRDD中读取数据。

示例5:对两个RDD既进行缓存又进行checkpoint。

如果去掉checkpoint语句,示例5应用会生成3个job,逻辑处理流程如图8.21所示,实际生成的job如图8.22所示。从图8.22中可以看到job 2的lineage非常长,包括了整个应用的所有RDD及操作。因为reducedRDD和groupedRDD已经被缓存,job 2可以直接读取,所以stage 4和stage 6被忽略。总的来说,缓存语句并不能切断lineage,RDD还是保存了其上游依赖的数据和操作。保留lineage的原因是缓存数据并不可靠,一旦丢失,还需要根据lineage进行重新计算。
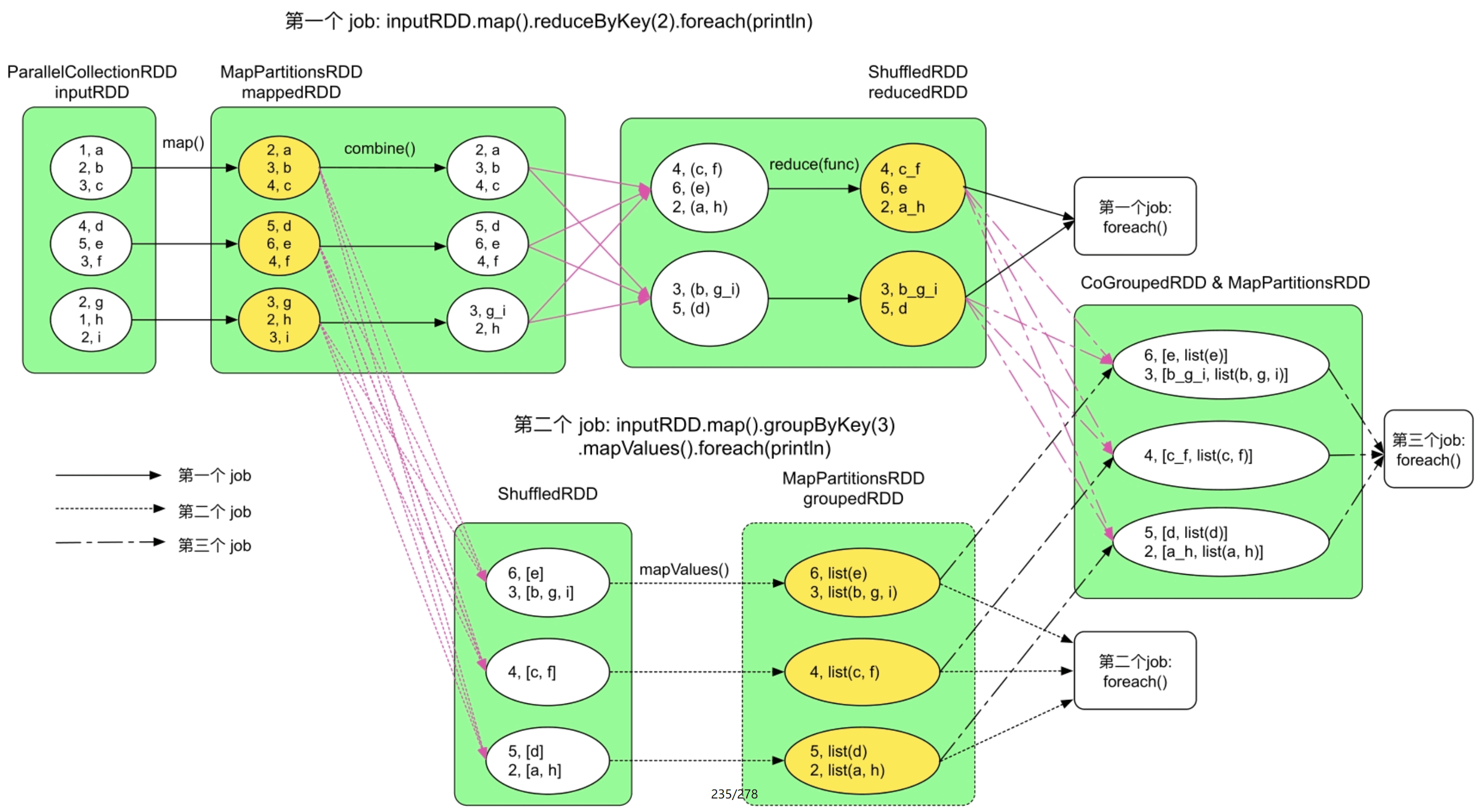
图8.21 只包含cahce()的逻辑处理流程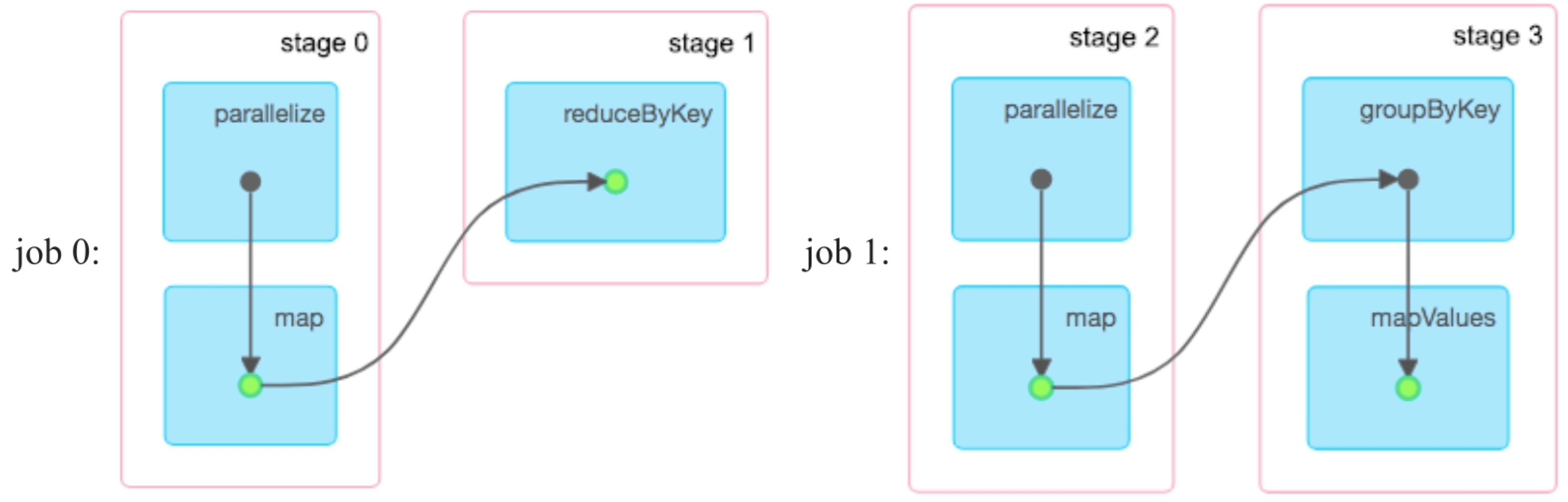
图8.22 只包含cache()而不包含checkpoint语句时生成的3个job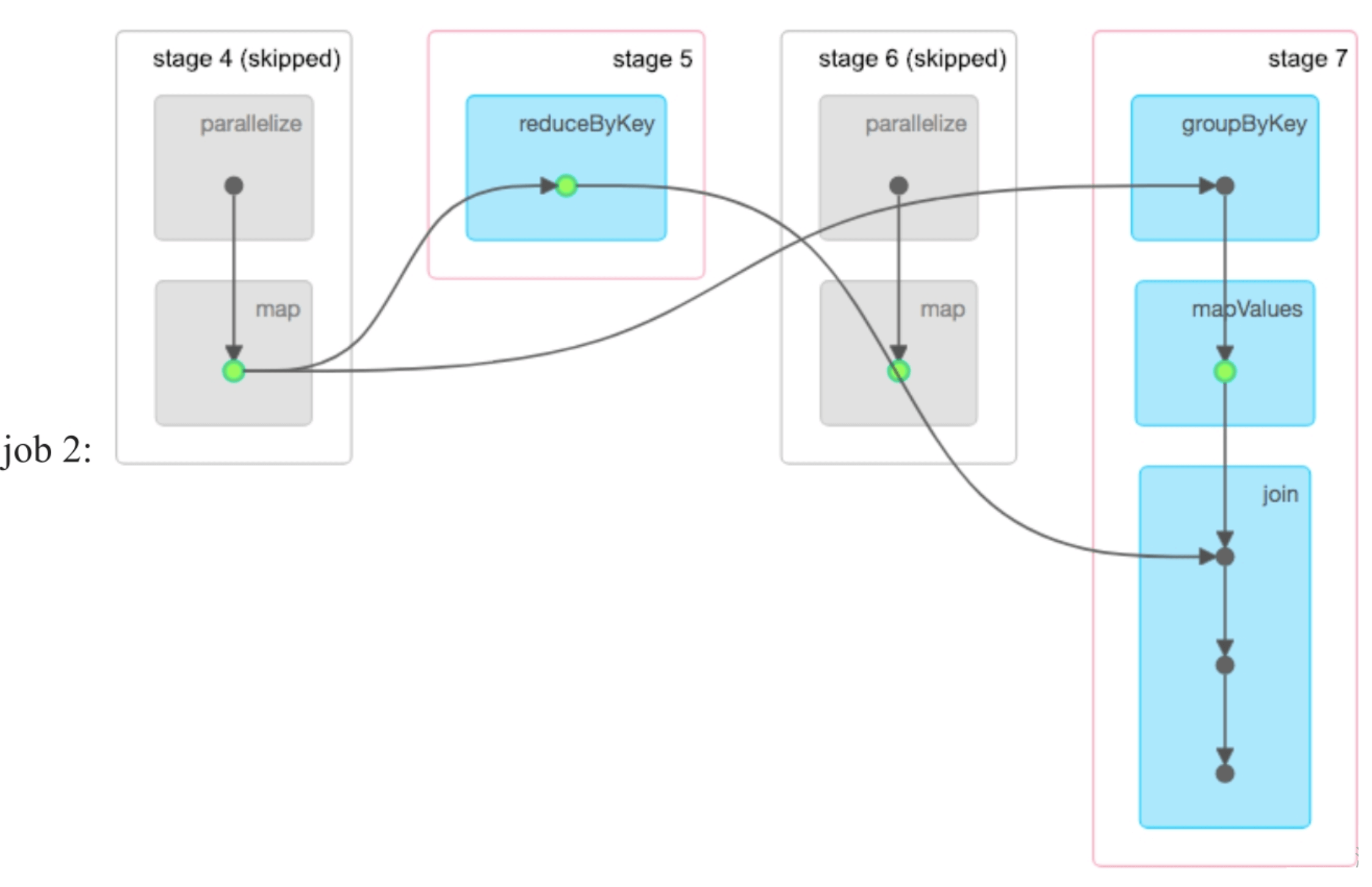
图8.22 只包含cache()而不包含checkpoint语句时生成的3个job(续)
_
添加checkpoint语句,重新运行会生成5个job。如图8.23所示,job 0正常计算,并对mappedRDD和reducedRDD进行缓存,如绿色圆圈所示。由于reducedRDD被设置为需要被checkpoint,需要启动job 1对reducedRDD进行checkpoint。此时,stage 2被忽略,原因是当前Spark实现checkpoint的方式问题,与图8.15中的例子一样。之后,启动job 2读取被缓存的mappedRDD,正常计算得到groupedRDD,并对其进行缓存。由于groupedRDD也需要被checkpoint,因此启动job 3对groupedRDD进行checkpoint,stage 6被忽略的原因和stage 2一样。最后,启动job 4,读取被缓存的reducedRDD和groupedRDD进行join()操作,得到最后的结果。
对比job 4和图8.22中的job 2可以发现:checkpoint切断了lineage,使得job 4不需要再保存整个应用的数据依赖图。checkpoint可以这样做的原因是RDD被持久化到了可靠的分布式文件系统上,该RDD不需要通过再次计算得到,也就没有必要保存其lineage了。这一点对于迭代型应用很重要,迭代型应用的lineage会很长,及时进行checkpoint可以减少job复杂程度,降低再次运行时的计算开销。如果单纯是为了降低job lineage的复杂程度而不是为了持久化,Spark还提供了localCheckpoint()方法,功能上等价于“数据缓存”加上“checkpoint切断lineage”的功能。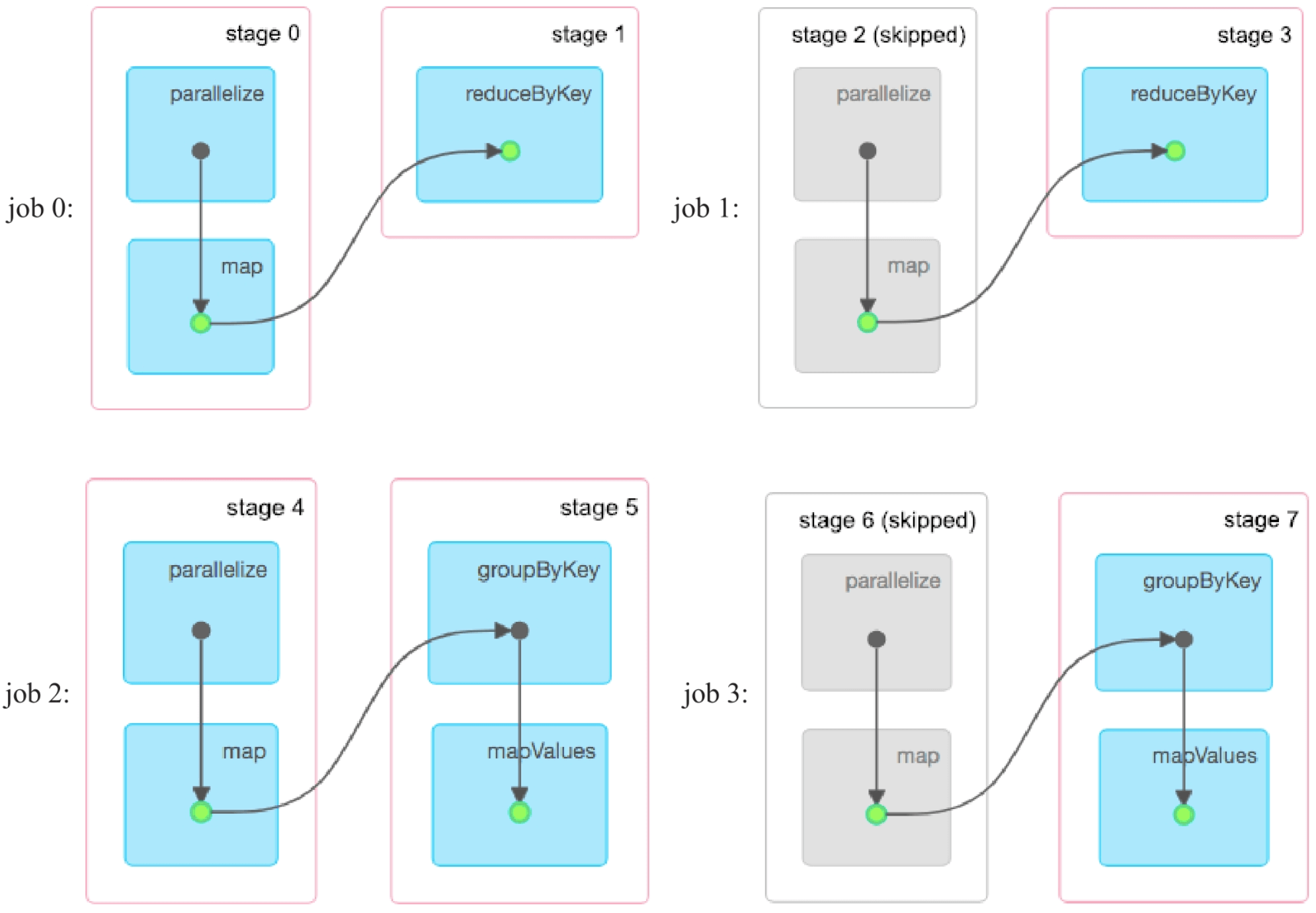
图8.23 示例5应用同时存在缓存数据和checkpoint时生成的job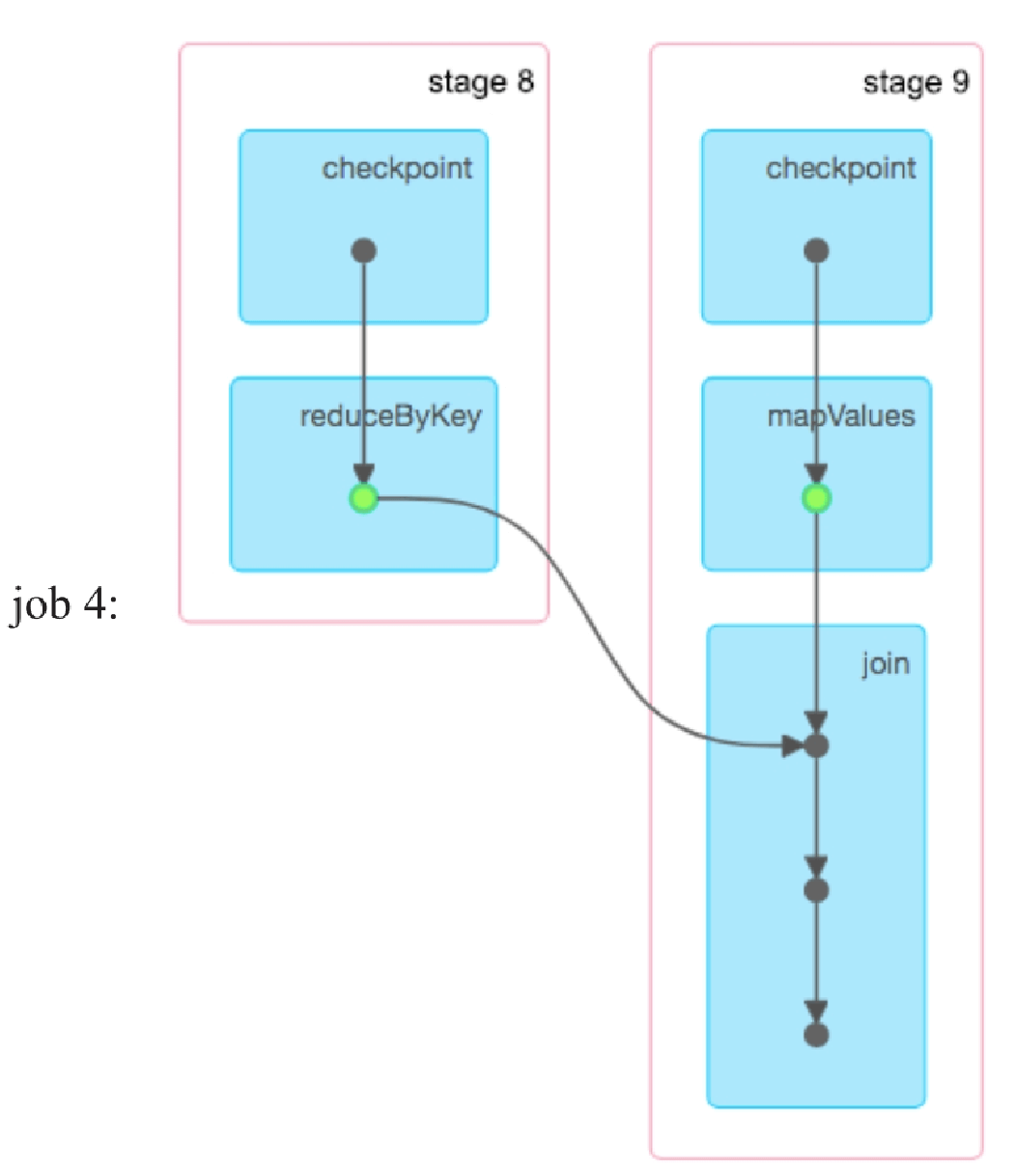
图8.23 示例5应用同时存在缓存数据和checkpoint时生成的job(续)
_
总的来说,本节的两个例子说明对某个RDD进行缓存和checkpoint时,先对其进行缓存,然后再次启动job对其进行checkpoint。
8.5 checkpoint与数据缓存的区别
数据缓存和checkpoint的用法、存储与读取过程确实很相似,但也有不少区别,下面总结说明一下:
- 目的不同。数据缓存的目的是加速计算,即加速后续运行的job。而checkpoint的目的是在job运行失败后能够快速恢复,也就是说加速当前需要重新运行的job。
- 存储性质和位置不同。数据缓存是为了读写速度快,因此主要使用内存,偶尔使用磁盘作为存储空间。而checkpoint是为了能够可靠读写,因此主要使用分布式文件系统作为存储空间。
- 写入速度和规则不同。数据缓存速度较快,对job的执行时间影响较小,因此可以在job运行时进行缓存。而checkpoint写入速度慢,为了减少对当前job的时延影响,会额外启动专门的job进行持久化。
- 对lineage的影响不同。对某个RDD进行缓存后,对该RDD的lineage没有影响,这样如果缓存后的RDD丢失还可以重新计算得到。而对某个RDD进行checkpoint以后,会切断该RDD的lineage,因为该RDD已经被可靠存储,所以不需要再保留该RDD是如何计算得到的。
- 应用场景不同。数据缓存适用于会被多次读取、占用空间不是非常大的RDD,而checkpoint适用于数据依赖关系比较复杂、重新计算代价较高的RDD,如关联的数据过多、计算链过长、被多次重复使用等。
8.6 小结
Spark应用在执行过程中可能面临的作业执行失败、数据丢失等可靠性问题。为了解决这些问题,Spark采用了简单但能够自动化的错误容忍机制——重新计算机制,该机制主要针对节点宕机、磁盘损坏等由于执行环境改变引发的作业执行失败问题。虽然重新计算机制思想简单,但是要求task具有确定性、幂等性,而且在设计和实现时需要考虑从哪里开始重新计算、对哪些RDD进行重新计算等计算粒度问题。为了解决数据和操作追根溯源的问题,Spark采用了lineage机制,也就是为每个RDD保存其数据依赖关系和关联操作,这样可以为每个RDD构建计算链,便于重新计算。
为了更好地解决数据丢失问题,也为了加速重新计算机制,Spark采用了checkpoint机制,将计算过程中重要的数据持久化到可靠存储,如分布式文件系统。这样,当失败的作业重新执行时,会从Checkpointed RDD开始读取,避免重新计算该RDD。然而,checkpoint机制与重新计算机制结合时,还需要确定checkpoint的时机及计算顺序。Spark采用启动额外job执行checkpoint的方式解决了该问题,但该方式会增加应用的job数量。checkpoint还有一个优点是可以截断计算链,减少job的复杂性。

若有收获,就点个赞吧
0 人点赞
