1.1 概述
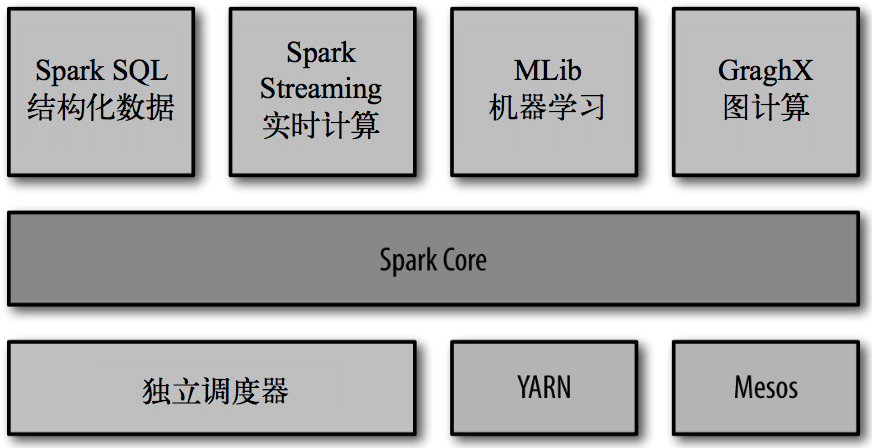
Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称 RDD)的 API 定义。
Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度器,叫作独立调度器。
1.2 特点
Spark实现了高效的 DAG 执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。主要用于数据科学任务、数据处理应用。
1.3 集群安装
1.3.1 集群角色
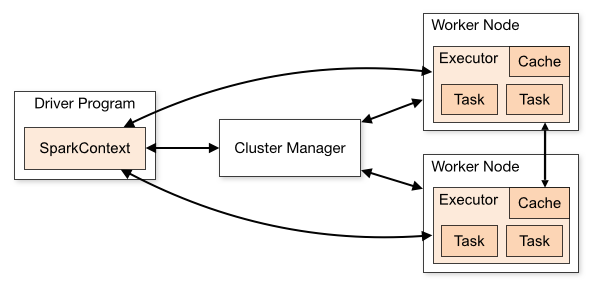
从物理部署层面上来看,Spark 主要分为两种类型的节点,Master 节点和 Worker 节点,Master 节点主要运行集群管理器的中心化部分,所承载的作用是分配 Application 到 Worker 节点,维护 Worker 节点、Driver、Application 的状态。Worker 节点负责具体的业务运行。从 Spark 程序运行的层面来看,Spark 主要分为驱动器节点和执行器节点。
1.3.2 修改配置文件
步骤:
- 修改 slave 文件,将 work 的 hostname 输入。
- 修改 spark-env.sh 文件。
- 将配置好的 Spark 文件拷贝到其他节点上。
1.3.3 配置Job History Server【Standalone】
步骤:
- 修改 spark-default.conf。
- 修改 spark-env.sh。
- 在 HDFS上创建好你所指定的 eventLog 日志目录。
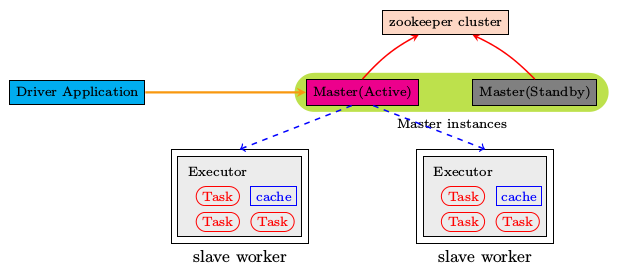
1.3.4 配置Spark HA【Standalone】
步骤:
- 借助 zookeeper,并且启动至少两个 Master 节点来实现高可靠。
- 安装配置 Zookeeper 集群,并启动 Zookeeper 集群。
- 修改 spark-env.sh。
- 将配置文件同步到所有节点。
1.3.5 配置Spark【Yarn】
步骤:
- 修改 Hadoop 配置下的 yarn-site.xml。
- 修改 Spark-env.sh。
HADOOP_CONF_DIR=/home/bigdata/hadoop/hadoop-2.7.3/etc/hadoopYARN_CONF_DIR=/home/bigdata/hadoop/hadoop-2.7.3/etc/hadoop
1.4 执行 Spark 程序
1.4.1 执行第一个spark程序(standalone)
[root]# /home/bigdata/hadoop/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://master01:7077 \--executor-memory 1G \--total-executor-cores 2 \/home/bigdata/hadoop/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \100
参数说明:
- —master spark://master01:7077 指定Master的地址。
- —executor-memory 1G 指定每个executor可用内存为1G。
- —total-executor-cores 2 指定每个executor使用的cup核数为2个。
1.4.2 执行第一个spark程序(yarn)
[root]# /home/bigdata/hadoop/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode client \/home/bigdata/hadoop/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \100
1.4.3 Spark 应用提交
一旦打包好,就可以使用bin/spark-submit脚本启动应用了. 这个脚本负责设置spark使用的classpath和依赖,支持不同类型的集群管理器和发布模式。
[root]# ./bin/spark-submit \--class <main-class>--master <master-url> \--deploy-mode <deploy-mode> \--conf <key>=<value> \... # other options<application-jar> \[application-arguments]
一些常用选项:
- —class: 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)。
- —master: 集群的master URL (如 spark://23.195.26.187:7077)。
- —deploy-mode: 是否发布你的驱动到worker节点(cluster) 或者作为一个本地客户端 (client) (default: client)*。
- —conf: 任意的Spark配置属性, 格式key=value. 如果值包含空格,可以加引 号“key=value”. 缺省的Spark配置。
- application-jar: 打包好的应用jar,包含依赖。
- -arguments: 传给main()方法的参数。
- Master URL可以是以下格式:
- local
- local[K]
- local[*]
- spark://HOST:PORT
- mesos://HOST:PORT
- yarn-client
- yarn-cluster
1.4.4 Spark-Shell
启动spark-shell:
[root]# /home/bigdata/hadoop/spark-2.1.1-bin-hadoop2.7/bin/spark-shell \--master spark://master01:7077 \--executor-memory 2g \--total-executor-cores 2
如果启动 spark shell 时没有指定 master 地址,则 spark 的 local 模式,该模式仅在本机启动一个进程,没有与集群建立联系。
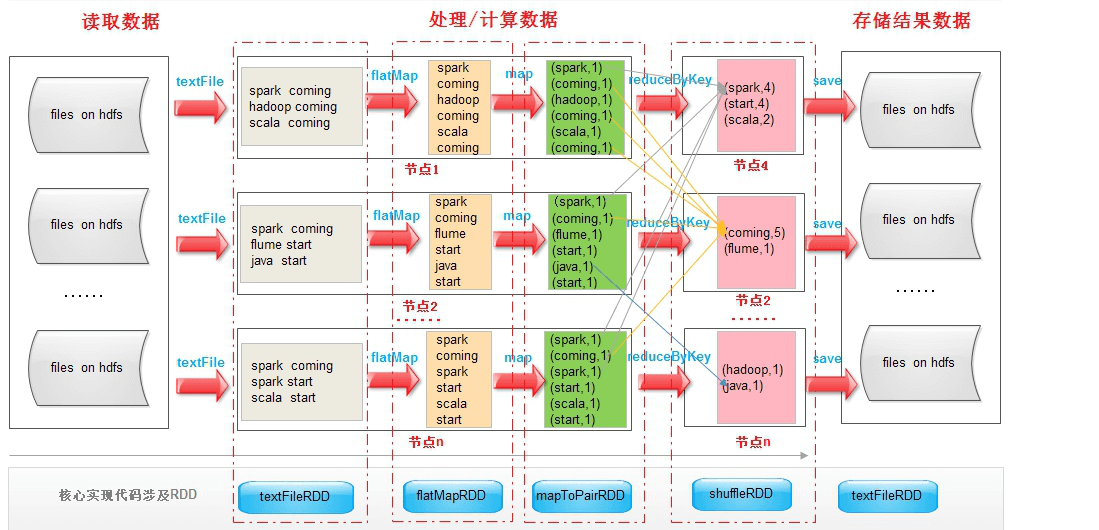
编写 WordCount 程序:
scala>sc.textFile("hdfs://master01:9000/RELEASE").flatMap(.map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://master01:9000/out")
1.4.5 IDEA
(1) 创建一个项目。
(2) 选择Maven项目,然后点击 next。
(3) 填写maven的GAV,然后点击 next。
(4) 填写项目名称,然后点击 finish。
(5) 创建好 maven 项目后,点击 Enable Auto-Import。
(6) 配置 Maven 的 pom.xml。
(7) 将 src/main/scala 设置成源代码目录。
(8) 添加 IDEA Scala(执行此操作后,pom 文件中不用添加 scala 依赖,应为已经以 lib 库的方式加入)。
(9) 新建一个 Scala class,类型为 Object。
(10) 编写 spark 程序。
(11 使用 Maven 打包:首先修改 pom.xml 中的 main class。
(12) 点击 idea 右侧的 Maven Project 选项,点击 Lifecycle,选择 clean 和 package,然后点击 Run Maven Build。
(13) 选择编译成功的 jar 包,并将该 jar 上传到 Spark 集群中的某个节点上。
(14) 使用 spark-submit 命令提交 Spark 应用(注意参数的顺序)。
[root]# /home/bigdata/hadoop/spark-2.1.1-bin-hadoop2.7/bin/spark-submit\--class com.test.spark.WordCount\--master spark://master01:7077\--executor-memory 1G \--total-executor-cores 2 \wordcount-jar-with-dependencies.jar\hdfs://master01:9000/RELEASE\hdfs://master01:9000/out
(15) 查看程序执行结果。
[root]# hdfs dfs -cat hdfs://master01:9000/out/part-*
(16) 在IDEA中配置Run Configuration,添加 HADOOP_HOME 变量。
package com.test.sparkimport org.apache.spark.{SparkConf, SparkContext}import org.slf4j.LoggerFactoryobject WordCount {val logger = LoggerFactory.getLogger(WordCount.getClass)def main(args: Array[String]) {//创建SparkConf()并设置App名称val conf = new SparkConf().setAppName("WC")//创建SparkContext,该对象是提交spark App的入口val sc = new SparkContext(conf)//使用sc创建RDD并执行相应的transformation和actionsc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_,v1).sortBy(_._2, false).saveAsTextFile(args(1))//停止sc,结束该任务logger.info("complete!")sc.stop()}}
1.4.6 Spark 核心概念
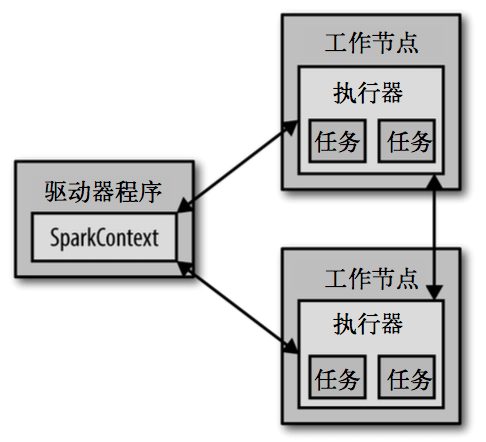
每个 Spark 应用都由一个驱动器程序(driver program)来发起集群上的各种并行操作。驱动器程序包含应用的 main 函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作。
驱动器程序通过一个 SparkContext 对象来访问 Spark。这个对象代表对计算集群的一个连接。shell 启动时已经自动创建了一个 SparkContext 对象,是一个叫作 sc 的变量。驱动器程序一般要管理多个执行器(executor)节点。

若有收获,就点个赞吧
0 人点赞
