2.1 Spark安装部署
Spark官网上提供了多个版本,包括Standalone、Mesos、YARN和Kubernetes版本。这几个版本的主要区别在于:Standalone版本的资源管理和任务调度器由Spark系统本身负责,其他版本的资源管理和任务调度器依赖于第三方框架,如YARN可以同时管理Spark任务和Hadoop MapReduce任务。
2.2 Spark系统架构
Spark也采用Master-Worker结构,Master节点负责管理应用和任务,Worker节点负责执行任务。
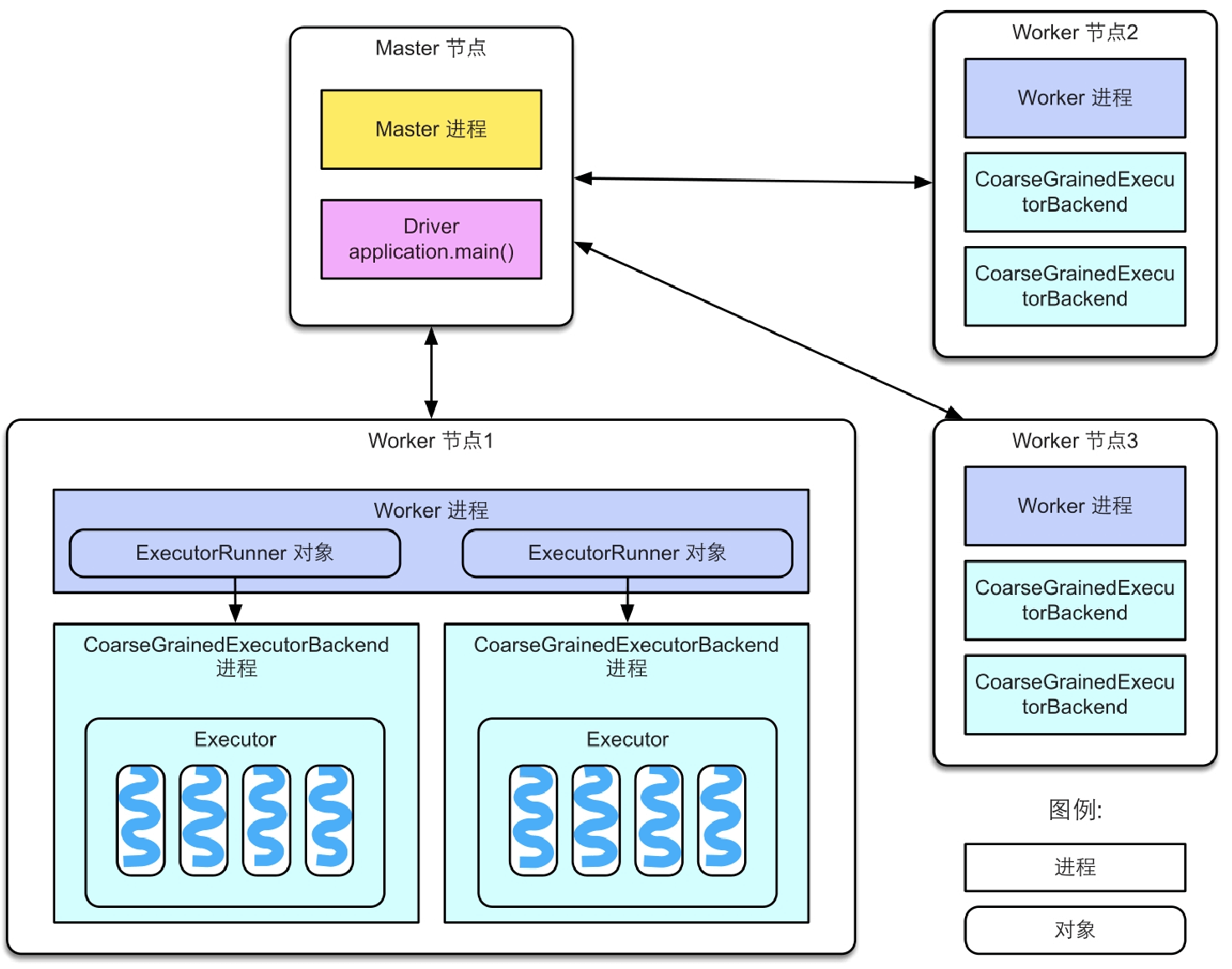
图2.1 Spark部署的系统架构图
Master节点和Worker节点的职责如下所述。
Master:Master节点上常驻Master进程。该进程负责管理全部的Worker节点,如将Spark任务分配给Worker节点,收集Worker节点上任务的运行信息,监控Worker节点的存活状态等。
Worker:Worker节点上常驻Worker进程。该进程除了与Master节点通信,还负责管理Spark任务的执行,如启动Executor来执行具体的Spark任务,监控任务运行状态等。
启动Spark集群时(使用Spark部署包中start-all.sh脚本),Master节点上会启动Master进程,每个Worker节点上会启动Worker进程。启动Spark集群后,接下来可以提交Spark应用到集群中执行。Master节点接收到应用后首先会通知Worker节点启动Executor,然后分配Spark计算任务(task)到Executor上执行,Executor接收到task后,为每个task启动1个线程来执行。
图中几个概念需要解释如下所述。
Spark application:即Spark应用,指的是1个可运行的Spark程序,如WordCount.scala,该程序包含main()函数,其数据处理流程一般先从数据源读取数据,再处理数据,最后输出结果。同时,应用程序也包含了一些配置参数,如需要占用的CPU个数,Executor内存大小等。用户可以使用Spark本身提供的数据操作来实现程序,也可以通过其他框架(如Spark SQL)来实现应用,Spark SQL框架可以将SQL语句转化成Spark程序执行。
Spark Driver:也就是Spark驱动程序,指实际在运行Spark应用中main()函数的进程,官方解释是“The process running the main() function of the application and creating the SparkContext”,如运行SparkPi应用main()函数而产生的进程被称为SparkPi Driver。
运行在Master节点上的Spark应用进程(通常由SparkSubmit脚本产生)就是Spark Driver,Driver独立于Master进程。如果是YARN集群,那么Driver也可能被调度到Worker节点上运行。
Executor:也称为Spark执行器,是Spark计算资源的一个单位。Spark先以Executor为单位占用集群资源,然后可以将具体的计算任务分配给Executor执行。由于Spark是由Scala语言编写的,Executor在物理上是一个JVM进程,可以运行多个线程(计算任务)。
task以线程方式运行在Executor进程中,执行具体的计算任务,如map算子、reduce算子等。由于Executor可以配置多个CPU,而1个task一般使用1个CPU,因此当Executor具有多个CPU时,可以运行多个task。
一个直观例子来理解Master、Worker、Driver、Executor、task的关系。
一个农场主(Master)有多片草场(Worker),农场主要把草场租给3个牧民来放马、牛、羊。假设现在有3个项目(application)需要农场主来运作:第1个牧民需要一片牧场来放100匹马,第2个牧民需要一片牧场来放50头牛,第3个牧民需要一片牧场来放80只羊。每个牧民可以看作是一个Driver,而马、牛、羊可以看作是task。为了保持资源合理利用、避免冲突,在放牧前,农场主需要根据项目需求为每个牧民划定可利用的草场范围,而且尽量让每个牧民在每个草场都有一小片可放牧的区域(Executor)。在放牧时,每个牧民(Driver)只负责管理自己的动物(task),而农场主(Master)负责监控草场(Worker)、牧民(Driver)等状况。
在图2.1中还有一些实现细节:
- 每个Worker进程上存在一个或者多个ExecutorRunner对象。每个ExecutorRunner对象管理一个Executor。Executor持有一个线程池,每个线程执行一个task。
- Worker进程通过持有ExecutorRunner对象来控制CoarseGrainedExecutorBackend进程的启停。
- 每个Spark应用启动一个Driver和多个Executor,每个Executor里面运行的task都属于同一个Spark应用。
2.3 Spark应用例子
2.3.1 用户代码基本逻辑
我们一般不需要在编写应用时指定map task的个数,因为map task的个数可以通过“输入数据大小/每个分片大小”来确定。reduce task的个数一般在使用算子时通过设置partition number来间接设置。
GroupByTest.scala:
import org.apache.spark.sql.SparkSessionimport java.util.Random/*** Usage: GroupByTest [numMappers] [numKVPairs] [KeySize] [numReducers]*/object GroupByTest {def main(args: Array[String]) {val spark = SparkSession.builder.appName("GroupBy Test").master("local").getOrCreate()val numMappers = 3val numKVPairs = 4val valSize = 1000val numReducers = 2val input = 0 until numMappersval pairs1 = spark.sparkContext.parallelize(input, numMappers).flatMap { p =>val ranGen = new Randomval arr1 = new Array[(Int, Array[Byte])](numKVPairs)for (i <- 0 until numKVPairs) {val byteArr = new Array[Byte](valSize)ranGen.nextBytes(byteArr)arr1(i) = (ranGen.nextInt(numKVPairs), byteArr)}arr1}.cache()// Enforce that everything has been calculated and in cacheprintln(pairs1.count())println(pairs1.toDebugString)val result = pairs1.groupByKey(numReducers)println(result.count())println(result.toDebugString)System.in.read()spark.stop()}}
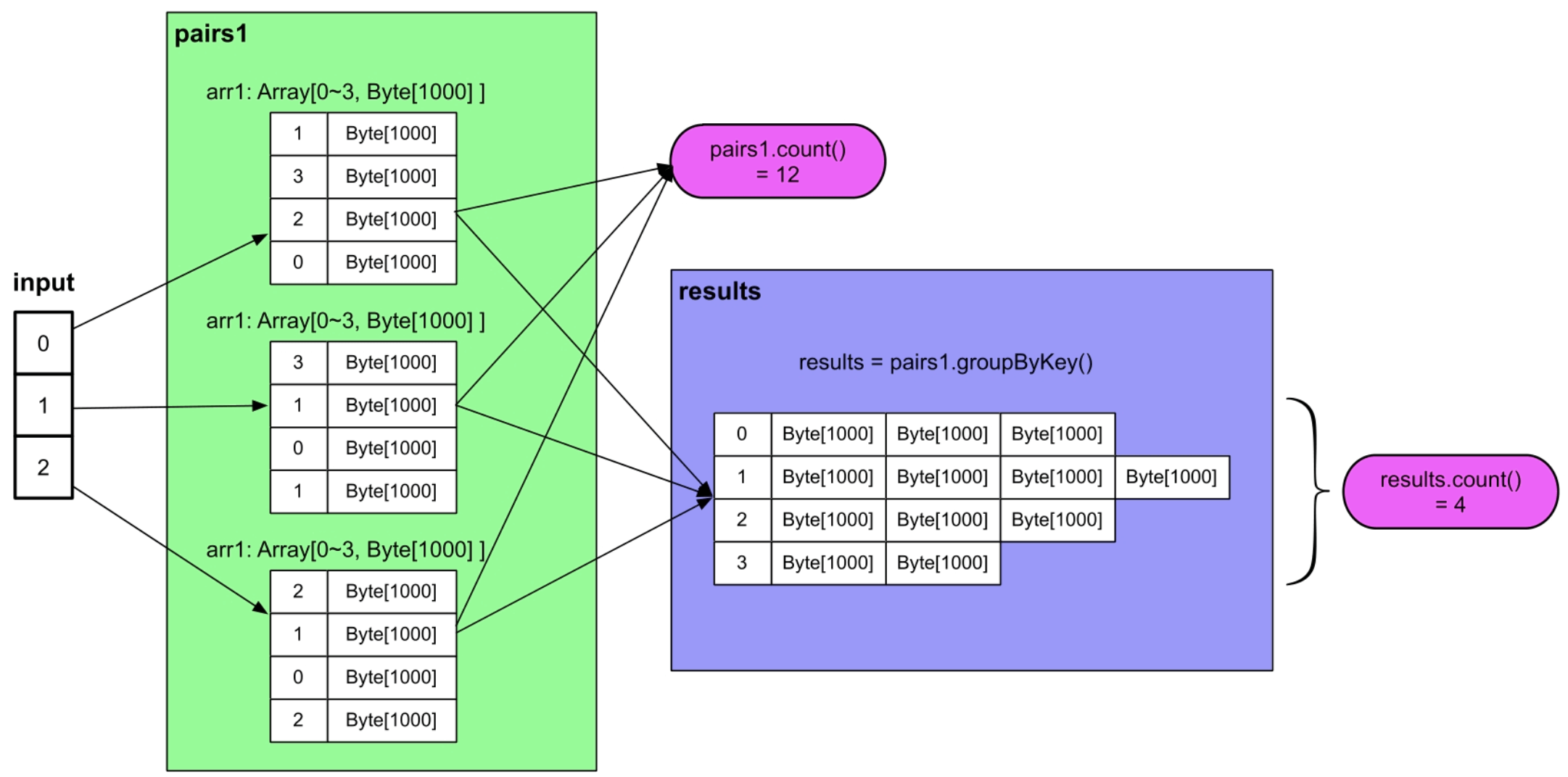
图2.2 GroupByTest应用的计算逻辑图
代码的具体执行流程:
- 初始化SparkSession,这一步主要是初始化Spark的一些环境变量,得到Spark的一些上下文信息sparkContext,使得后面的一些操作函数(如flatMap()等)能够被编译器识别和使用,这一步同时创建GroupByTest Driver,并初始化Driver所需要的各种对象。
- 设置参数。
- 使用sparkContext.parallelize(0 until numMappers,numMappers)。
- 接下来执行一个action()操作pairs1.count()。
- 执行完pair1.count()后,在已经被缓存的pairs1上执行groupByKey()操作。
- 最后执行results.count()。
在Spark程序中,首先要声明SparkSession的环境变量才能够使用Spark提供的数据操作,然后使用Spark操作来定义数据处理流程,如flatMap(func).groupByKey()。至于这些步骤和操作如何在系统中并行执行,用户并不需要关心。在Spark中,唯一需要注意声明的数据处理流程在使用action()操作时,Spark才真正执行处理流程,如果整个程序没有action()操作,那么Spark并不会执行数据处理流程。
2.3.2 逻辑处理流程
Spark的实际执行流程比用户想象的要复杂,需要先建立DAG型的逻辑处理流程(Logical plan),然后根据逻辑处理流程生成物理执行计划(Physical plan),物理执行计划中包含具体的计算任务(task),最后Spark将task分配到多台机器上执行。
使用toDebugString()方法来打印出pairs1和results的产生过程,进而分析GroupByTest的整个逻辑处理流程。
我们先分析GroupByTest产生的job个数。由于GroupByTest进行了两次action()操作:pairs1.count()和results.count(),所以会生成两个Spark作业(job),如图2.3所示。

图2.3 GroupByTest应用生成的两个job
pairs1.toDebugString()的执行结果:

第一行的“(3) MapPartitionsRDD[1]”表示的是pairs1,即pairs1的类型是MapPartitions-RDD,编号为[1],共有3个分区(partition),这是因为pairs1中包含了3个数组。由于设置了pairs1.cache,所以pairs1中的3个分区在计算时会被缓存,其类型是CachedPartitions。那么pairs1是怎么生成的呢?我们看到描述“MapPartitionsRDD[1] at flatMap at GroupByTest.scala:41”,即pairs1是由flatMap()函数生成的,对照程序代码,可以发现确实是input.parallelize().flatMap()生成的。接着出现了“ParallelCollectionRDD[0]”,根据描述是由input.parallelize()函数生成的,编号为[0],因此,我们可以得到结论:input.parallelize()得到一个ParallelCollectionRDD,然后经过flatMap()得到pairs1:MapPartitionsRDD。
results.toDebugString()的执行结果:

同样,第1行的“(2) ShuffledRDD[2]”表示的是results,即results的类型是ShuffledRDD,由groupByKey()产生,共有两个分区(partition),这是因为在groupByKey()中,设置了partition number=numReducers=2。接着出现了“MapPartitionsRDD [1]”,这个就是之前生成的pairs1。接下来的ParallelCollectionRDD由input.parallelize()生成。
上述过程画成逻辑处理流程图,如图2.4所示:
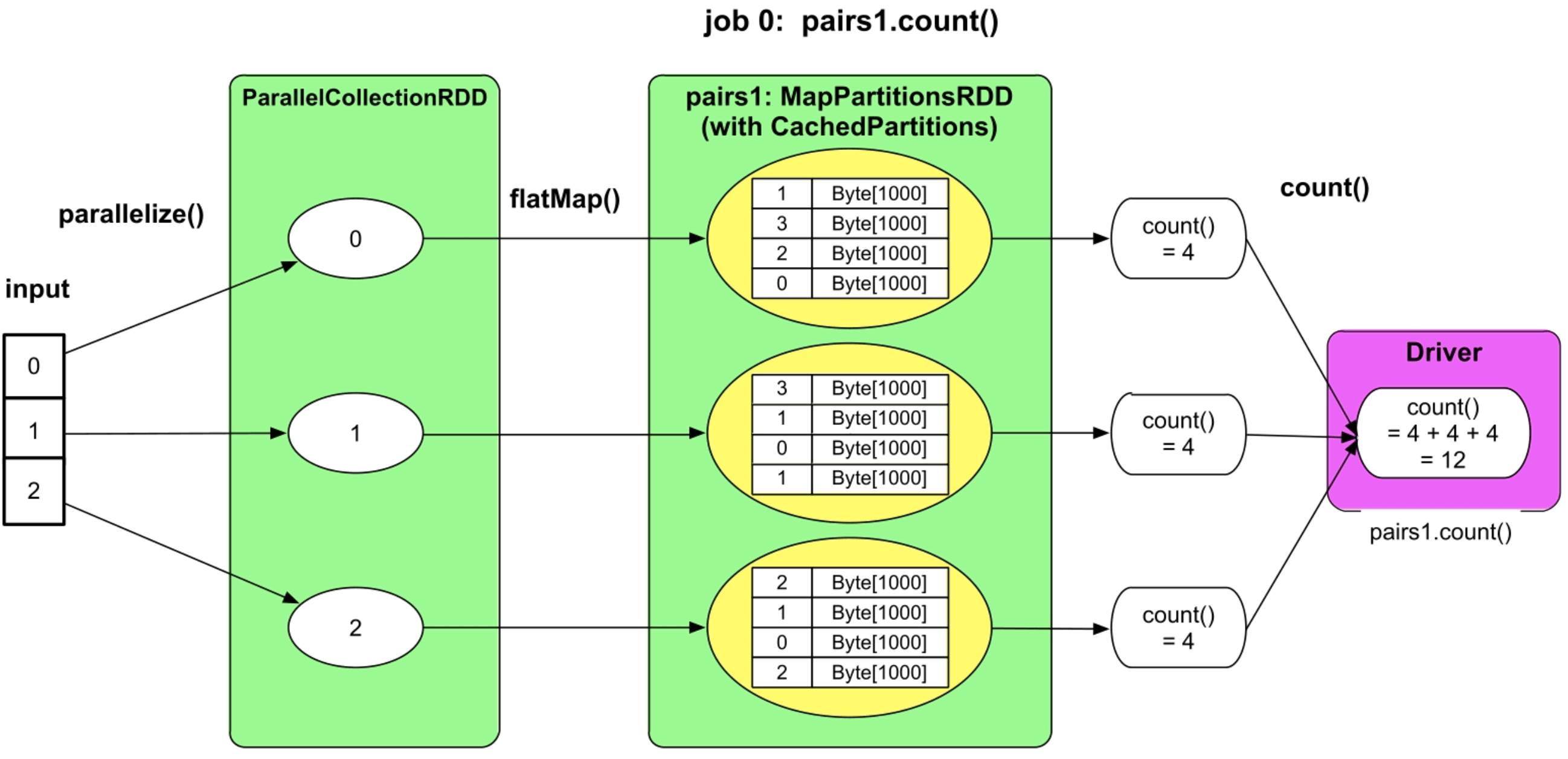
图2.4 GroupByTest的逻辑处理流程图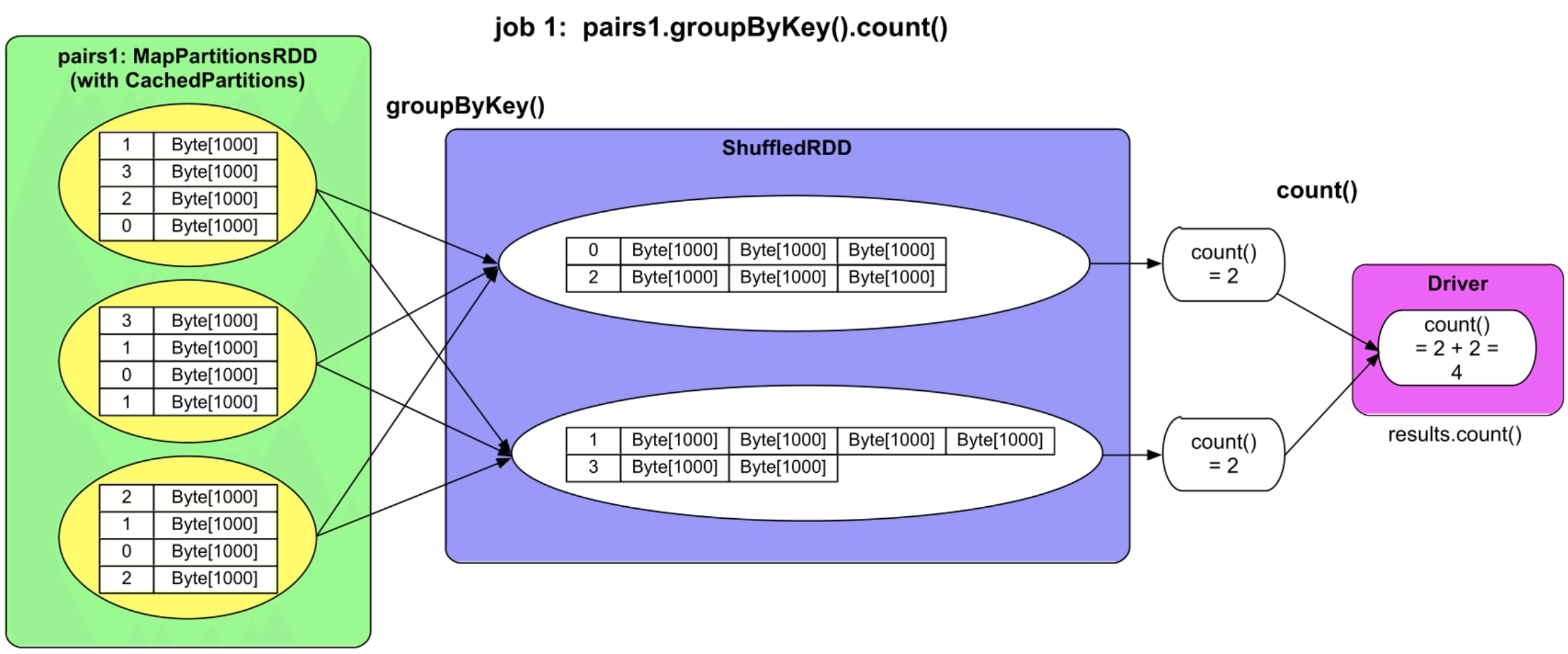
图2.4 GroupByTest的逻辑处理流程图(续)_
Spark在执行到action()操作时,会根据程序中的数据操作,自动生成这样的数据流程图。
第1个job,即pairs1.count()的执行流程如下所述。
(1)input是输入一个[0,1,2]的普通Scala数组。
(2)执行input.parallelize() 操作产生一个ParrallelCollectionRDD,共3个分区,每个分区包含一个整数p。这一步的重要性在于将input转化成Spark系统可以操作的数据类型ParrallelCollectionRDD。也就是说,input数组仅仅是一个普通的Scala变量,并不是Spark可以并行操作的数据类型。在对input进行划分后生成了ParrallelCollectionRDD,这个RDD是Spark可以识别和并行操作的类型。可以看到input没有分区概念,而ParrallelCollectionRDD可以有多个分区,分区的意义在于可以使不同的task并行处理这些分区。RDD(Resilient Distributed Datasets)的含义是“并行数据集的抽象表示”,实际上是Spark对数据处理流程中形成的中间数据的一个抽象表示或者叫抽象类(abstract class),这个类就像一个“分布式数组”,包含相同类型的元素,但元素可以分布在不同机器上。
(3)在ParrallelCollectionRDD上执行flatMap()操作,生成MapPartitionsRDD,该RDD同样包含3个分区,每个分区包含一个通过flatMap()代码生成的arr1数组。
(4)执行paris1.count()操作,先在MapPartitionsRDD的每个分区上进行count(),得到部分结果,然后将结果汇总到Driver端,在Driver端进行加和,得到最终结果。执行paris1.count()操作,先在MapPartitionsRDD的每个分区上进行count(),得到部分结果,然后将结果汇总到Driver端,在Driver端进行加和,得到最终结果。
(5)由于MapPartitionsRDD被声明要缓存到内存中,因此这里将里面的分区都换成了黄色表示。缓存的意思是将某些可以重用的输入数据或中间计算结果存放到内存中,以减少后续计算时间。由于MapPartitionsRDD被声明要缓存到内存中,因此这里将里面的分区都换成了黄色表示。缓存的意思是将某些可以重用的输入数据或中间计算结果存放到内存中,以减少后续计算时间。
第2个job,即results.count()的执行流程如下所述。
(1)在已经被缓存的MapPartitionsRDD上执行groupByKey()操作,产生了另外一个名为ShuffledRDD的中间数据,也就是results,产生这个RDD的原因会在后面章节中讨论。这里我们将ShuffledRDD换了一种颜色表示,是因为ShuffledRDD与MapPartitionsRDD具有不同的分区个数,这样MapPartitionsRDD与ShuffledRDD之间的分区关系就不是一对一的,而是多对多的了。
(2)ShuffledRDD中的数据是MapPartitionsRDD中数据聚合的结果,而且在不同的分区中具有不同Key的数据。
(3)执行results.count(),首先在ShuffledRDD中每个分区上进行count()的运算,然后将结果汇总到Driver端进行加和,得到最终结果。
_
这个逻辑处理流程图只是表示输入/输出、中间数据,以及它们之间的依赖关系,并不涉及具体的计算任务。当然,我们可以简单地将每一个数据操作,如map()、flatMap()、groupByKey()、count(),都作为一个计算任务,但是执行效率太低、内存消耗大,而且可靠性低。
2.3.3 物理执行计划
Spark采用的方法是根据数据依赖关系,来将逻辑处理流程(Logical plan)转化为物理执行计划(Physical plan),包括执行阶段(stage)和执行任务(task)。具体包括以下3个步骤。
(1)首先确定应用会产生哪些作业(job)。
在GroupByTest中,有两个count()的action()操作,因此会产生两个job。
(2)其次根据逻辑处理流程中的数据依赖关系,将每个job的处理流程拆分为执行阶段(stage)。
如图2.4所示,在GroupByTest中,job 0中的两个RDD虽然是独立的,但这两个RDD之间的数据依赖是一对一的关系。因此,如图2.5所示,可以将这两个RDD放在一起处理,形成一个stage,编号为stage 0。在job 1中,MapPartitionsRDD与ShuffledRDD之间是多对多的关系,Spark将这两个RDD分别处理,形成两个执行阶段stage 0和stage 1。
(3)最后,对于每一个stage,根据RDD的分区个数确定执行的task个数和种类。
对于GroupByTest应用来说,job 0中的RDD包含3个分区,因此形成3个计算任务(task)。如图2.5所示,首先,每个task从input中读取数据,进行flatMap()操作,生成一个arr1数组,然后,对该数组进行count()操作得到结果4,完成计算。最后,Driver将每个task的执行结果收集起来,加和计算得到结果12。对于job 1,其中stage 0只包含MapPartitionsRDD,共3个分区,因此生成3个task。每个task从内存中读取已经被缓存的数据,根据这些数据Key的Hash值将数据写到磁盘中的不同文件中,这一步是为了将数据分配到下一个阶段的不同task中。接下来的stage 1只包含ShuffledRDD,共两个分区,也就是生成两两个task,每个task从上一阶段输出的数据中根据Key的Hash值得到属于自己的数据。图2.5中,stage 1中的第1个task只获取并处理Key为0和2的数据,第2个task只获取并处理Key为1和3的数据。从stage 0到stage 1的数据分区和获取的过程称为Shuffle机制,也就是数据经过了混洗、重新分配,并且从一个阶段传递到了下一个阶段。stage 1中的task将相同Key的record聚合在一起,统计Key的个数作为count()的结果,完成计算。Driver再将所有task的结果进行加和输出,完成计算。
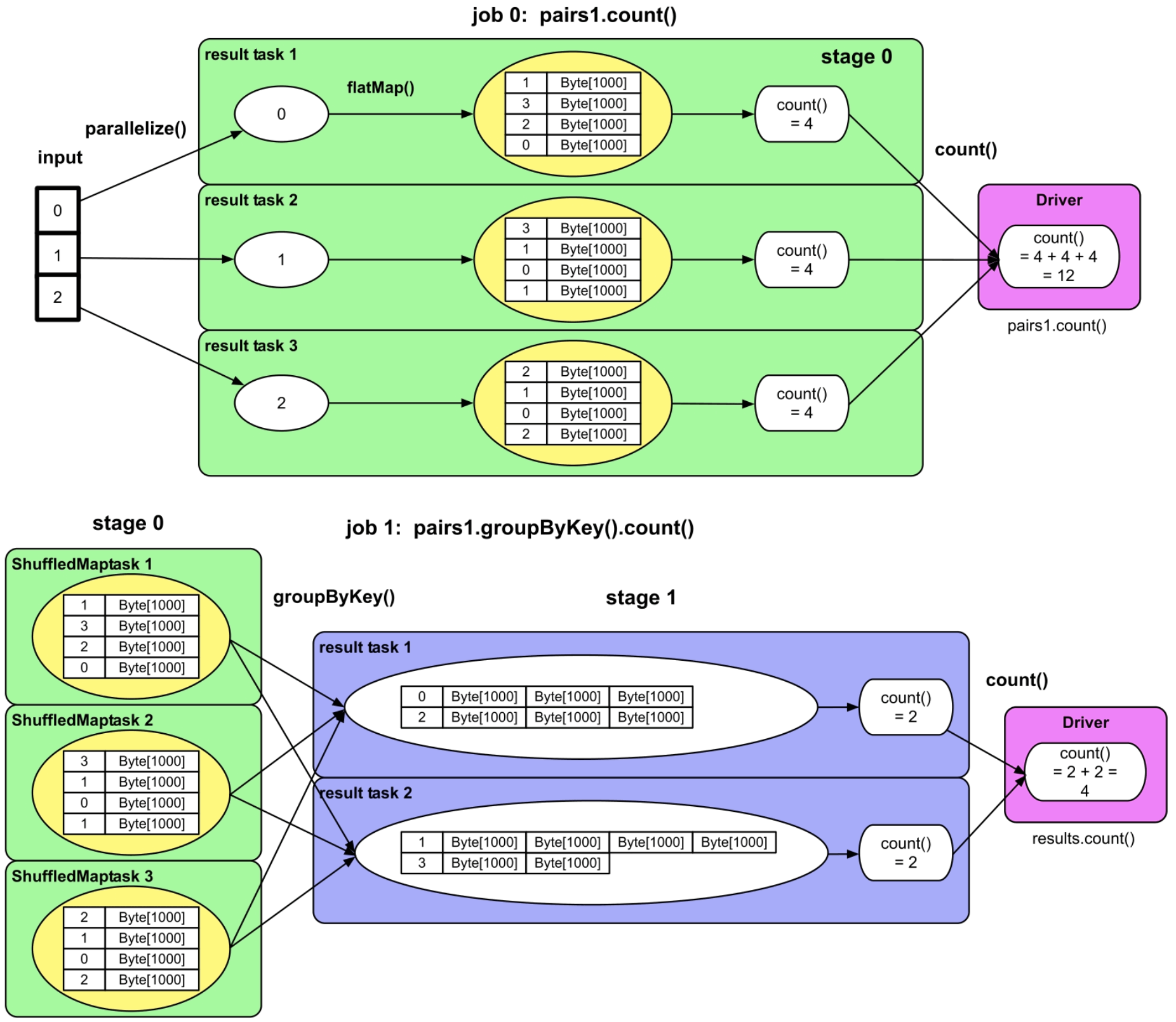
图2.5 GroupByTest的物理执行计划
_
生成执行任务task后,我们可以将task调度到Executor上执行,在同一个stage中的task可以并行执行。
为什么要拆分为执行阶段?在2.3.2节中我们讨论过,如果将每个操作都当作一个任务,那么效率太低,而且错误容忍比较困难。将job划分为执行阶段stage后,第1个好处是stage中生成的task不会太大,也不会太小,而且是同构的,便于并行执行。第2个好处是可以将多个操作放在一个task里处理,使得操作可以进行串行、流水线式的处理,这样可以提高数据处理效率。第3个好处是stage可以方便错误容忍,如一个stage失效,我们可以重新运行这个stage,而不需要运行整个job。在后续章节中,我们将会看到,如果stage划分不当,则会带来性能和可靠性的问题。
2.3.4 可视化执行过程
如何快速获得一个Spark应用的逻辑处理流程和物理执行计划呢?答案是根据Spark提供的执行界面,即job UI来进行分析。
对于GroupByTest应用,我们通过分析用户代码可以知道有两个action()操作,会形成两个job。我们也可以通过Spark的job UI(应用运行输出提示Spark UI地址)看到生成的job。接下来我们来观察这两个job生成的stage。
分析job 0及其包含的stage,单击job UI中的“count at GroupByTest.scala:52”进入Details for job 0界面。如图2.6所示,可以看到job 0包含一个stage,该stage执行了两个操作parallelize()和flatMap()。
为了进一步分析该stage中的数据关联关系和生成的task,我们可以单击图2.6中的“count at GroupByTest.scala:52”进入Details for stage 0界面。如图2.7所示,发现stage 0中包含两个RDD,parallelize()操作生成了ParallelCollectonRDD,flatMap()操作生成了MapRartitionsRDD,并对该RDD进行缓存。cached说明该RDD已经被缓存到内存中。这里没有显示这些RDD有几个分区,但是我们看到该stage有3个task,可以断定分区个数为3。task中还还有一些属性,如Attempt、Locality Level、GC Time等
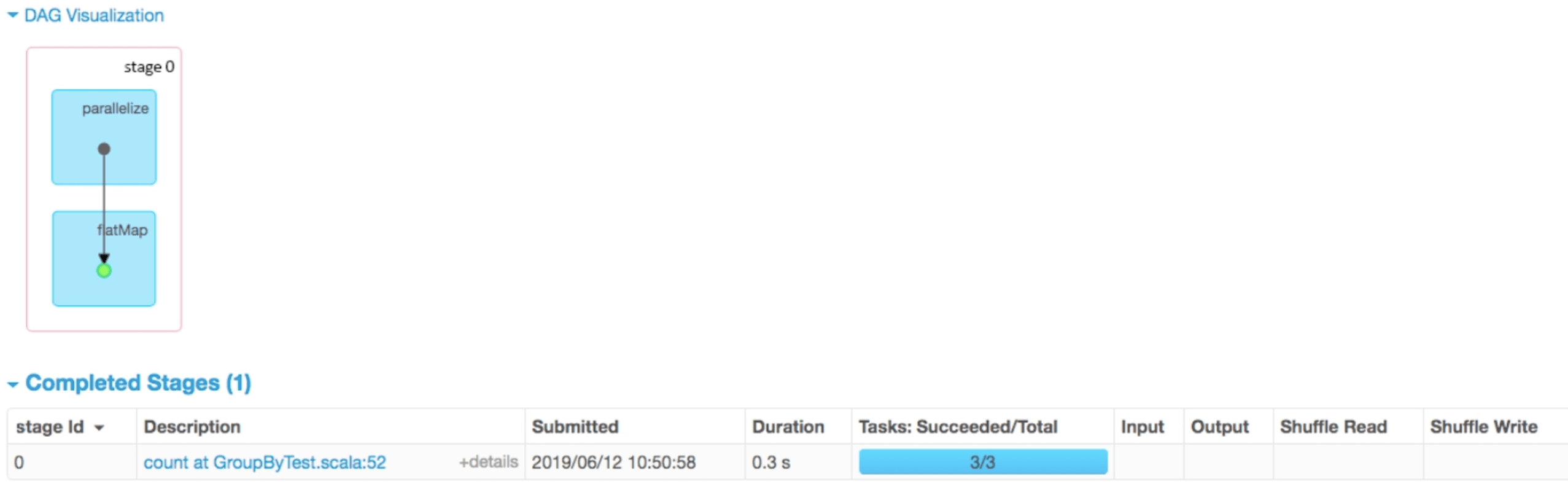
图2.6 GroupByTest中job 0包含的stage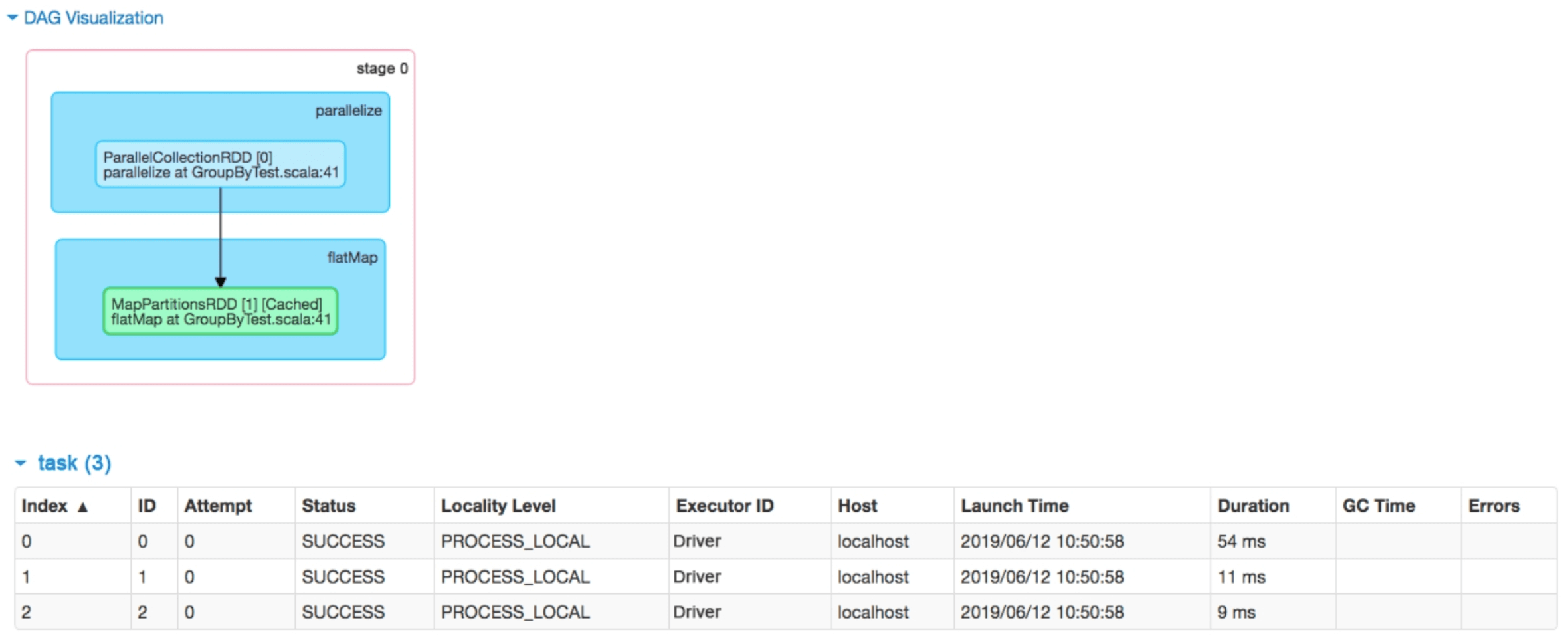
图2.7 job 0中stage 0的逻辑处理流程和生成的task_
分析job 1及其包含的stage,单击Spark job页面(见图2.3)中的“count at GroupByTest.scala:56”进入Details for job 1界面。如图2.8所示,可以看到job 1包含两个stage,其中stage 1执行了两个操作parallelize()和flatMap(),stage 2执行了一个操作groupByKey()。
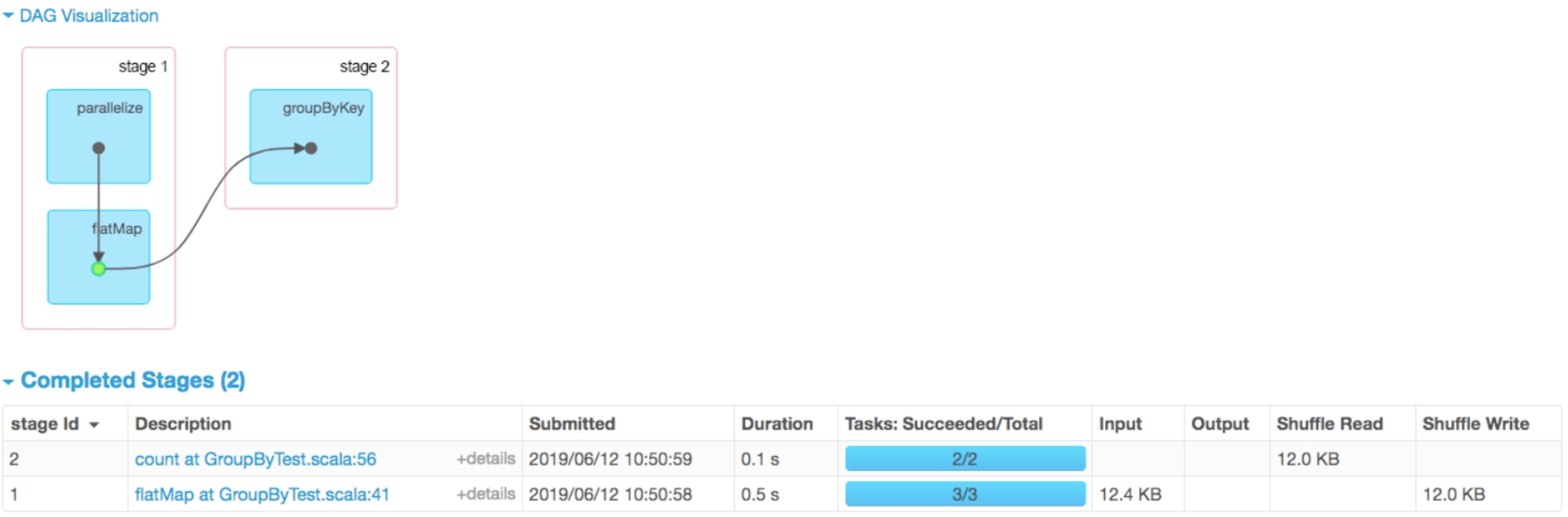
图2.8 job 1中stage 1包含的两个stage
_
对于stage 1生成的task,发现相比stage 0和stage 1中的3个task多了Input Size/Records、Write Time和Shuffle Write Size/Records 3个属性。这是因为stage 1中的task是从缓存(MapPartitionsRDD)中读取数据进行处理的,所以有Input Size属性,而stage0中的task是根据数字p自动生成其他数据的,没有真正的读取动作,所以没有Input Size。同样,stage 0中的task的结果直接通过网络返回给Driver端,没有磁盘写入和Shuffle动作,也就没有Write Time和Shuffle Write Size等属性。前面介绍过,stage 1中的task需要进行Shuffle,把具有不同Hash值的数据Key写入不同的磁盘文件中,因而有Write Time和Shuffle Write Size。
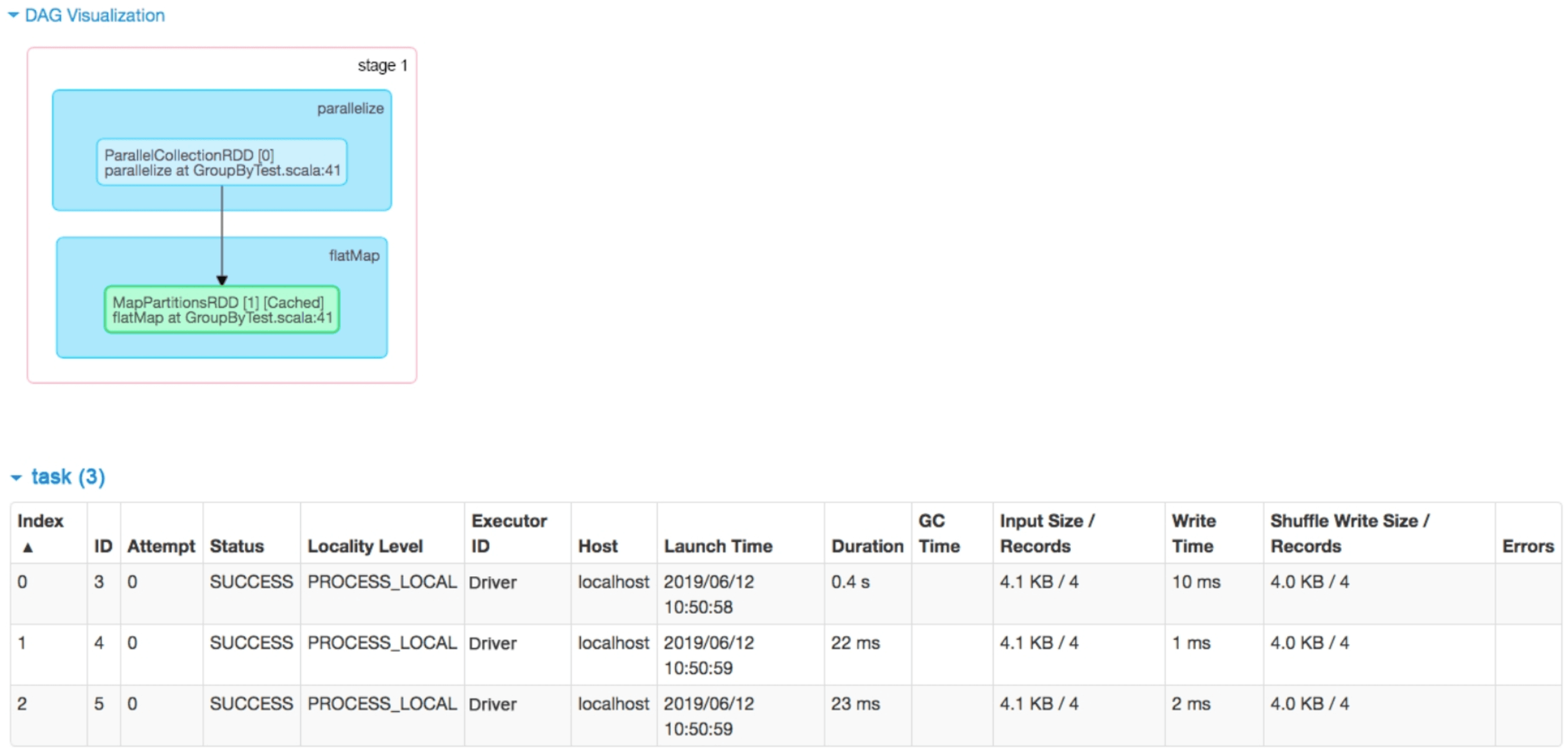
图2.9 job 1中stage 1的逻辑处理流程和生成的task_
对于stage 2,单击图2.8中的“count at GroupByTest.scala:56”进入Details for stage 2界面,得到图2.10。与我们在2.3.2节中给出的逻辑处理流程一致,在进行groupByKey()操作后生成了ShuffledRDD。stage 2包含两个task,每个task包含一个Shuffle Read Size的属性,表示从stage 1的输出结果中Shuffle Read的数据。每个task获取了6个record,与我们画出的物理执行计划一致。
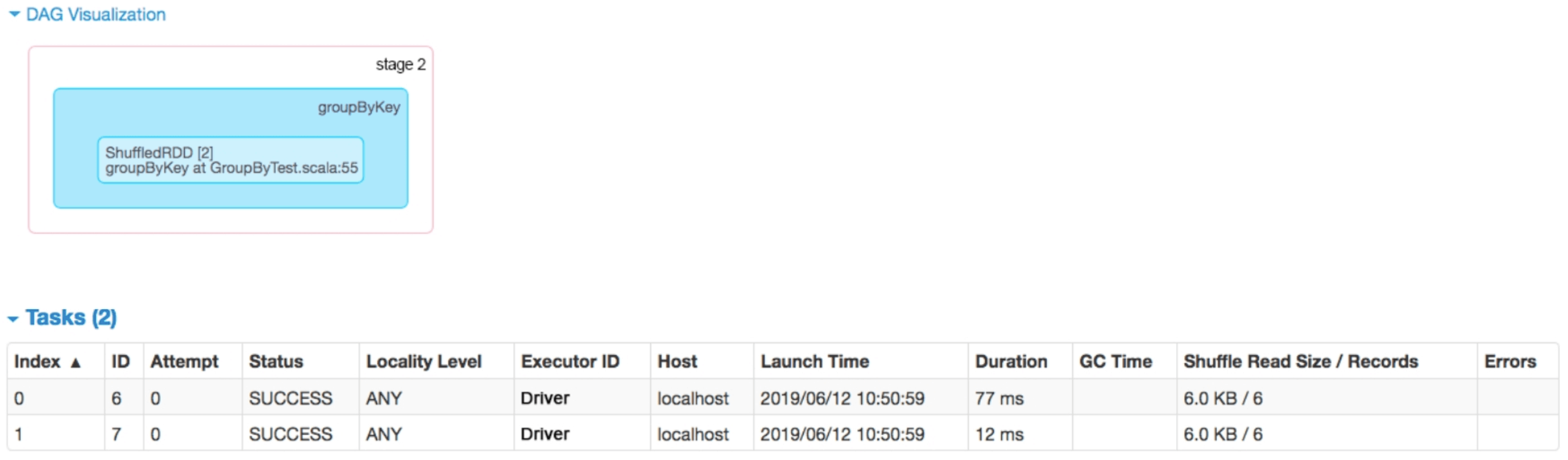
图2.10 job 1中stage 2的逻辑处理流程和生成的task
我们在手工画出的图中加入了每个RDD应该会产生的数据,而在实际运行时Spark并不关心这些数据具体是什么,也不会存储每个RDD中的数据,所以也就无法图示出RDD中的数据。
2.4 Spark编程模型
Google发表了MapReduce论文,将大数据的编程模型抽象为map和reduce阶段,核心是map()和reduce()函数,通过组合这两个函数可以完成一大部分的数据处理任务(主要是可以被分治处理的粗粒度任务)。对于用户来说,给定一个数据处理任务,需要解决的问题就是如何设计这两个函数来实现任务。
为了实现join(),用户需要设计两种map()函数,一个处理第1张表,另一个处理第2张表,还需要精心设计reduce()函数,使得能够分辨来自不同表的数据,进行最后的join()。
为了解决这个问题,研究人员的想法是,提供更高层的操作函数来屏蔽Map—reduce的实现细节。那么如何设计这些高层函数呢?
Java是怎么方便编程的?Java语言通过提供常用的数据结构,如Array、HashMap等来方便用户组织数据,并在数据结构上提供常用函数来方便进行数据操作。根据这个思想,Google在MapReduce编程模型之上设计了FlumeJava,提供了典型数据结构来表示输入/输出和中间数据。在这些数据结构上提供常见的数据操作,如parallelDo()、groupByKey()、join()等。
微软的研究人员也提出了类似的高层语言DryadLINQ,提供多种数据结构和操作。
Spark借鉴了上述这两种编程模型,并提出了RDD的数据结构,以及相应的数据操作。

若有收获,就点个赞吧
0 人点赞
