Spark 计算速度远胜于 Hadoop 的原因之一就在于中间结果是缓存在内存而不是直接写入到 disk,本文尝试分析 Spark 中存储子系统的构成,并以数据写入和数据读取为例,讲述清楚存储子系统中各部件的交互关系。
6.11.1 存储子系统概览
Storage 模块主要分为两层:
- 通信层:storage 模块采用的是 master-slave 结构来实现通信层,master 和 slave 之间传输控制信息、状态信息,这些都是通过通信层来实现的。
- 存储层:storage 模块需要把数据存储到 disk 或是 memory 上面,有可能还需 replicate(复制) 到远端,这都是由存储层来实现和提供相应接口。
而其他模块若要和 storage 模块进行交互,storage 模块提供了统一的操作类 BlockManager,外部类与 storage 模块打交道都需要通过调用 BlockManager 相应接口来实现。
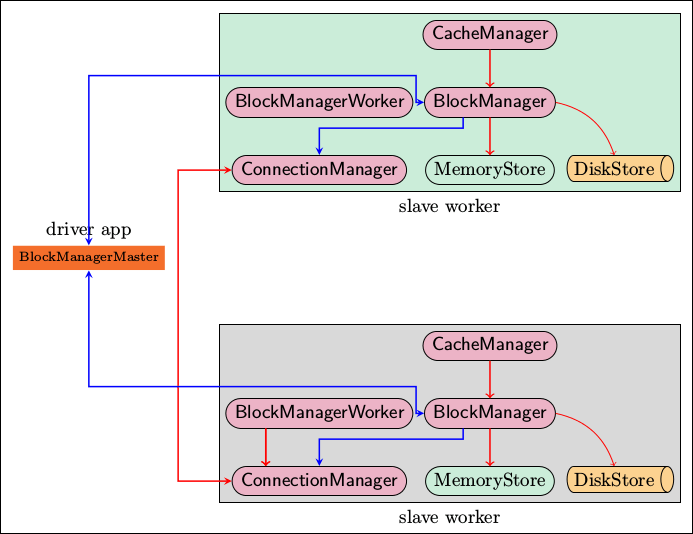
上图是 Spark 存储子系统中几个主要模块的关系示意图,现简要说明如下:
- CacheManager:RDD 在进行计算的时候,通过 CacheManager 来获取数据,并通过 CacheManager 来存储计算结果。
- BlockManager:CacheManager 在进行数据读取和存取的时候主要是依赖 BlockManager 接口来操作,BlockManager 决定数据是从内存(MemoryStore) 还是从磁盘(DiskStore) 中获取。
- MemoryStore:负责将数据保存在内存或从内存读取。
- DiskStore:负责将数据写入磁盘或从磁盘读入。
- BlockManagerWorker:数据写入本地的 MemoryStore 或 DiskStore 是一个同步操作,为了容错还需要将数据复制到别的计算结点,以防止数据丢失的时候还能够恢复,数据复制的操作是异步完成,由 BlockManagerWorker 来处理这一部分事情。
- ConnectionManager:负责与其它计算结点建立连接,并负责数据的发送和接收。
- BlockManagerMaster:注意该模块只运行在 Driver Application 所在的 Executor,功能是负责记录下所有 BlockIds 存储在哪个 SlaveWorker 上,比如 RDD Task 运行在机器 A,所需要的 BlockId 为 3,但在机器 A 上没有 BlockId 为 3 的数值,这个时候 Slave worker 需要通过 BlockManager 向 BlockManagerMaster 询问数据存储的位置,然后再通过 ConnectionManager 去获取。
6.11.2 启动过程分析
上述的各个模块由 SparkEnv 来创建,创建过程在 SparkEnv.create 中完成,代码如下:
val blockManagerMaster = new BlockManagerMaster(registerOrLookup("BlockManagerMaster",new BlockManagerMasterActor(isLocal, conf)), conf)val blockManager = new BlockManager(executorId, actorSystem, blockManagerMaster, serializer, conf)val connectionManager = blockManager.connectionManagerval broadcastManager = new BroadcastManager(isDriver, conf)val cacheManager = new CacheManager(blockManager)
下面这段代码容易让人疑惑,看起来像是在所有的 cluster node 上都创建了 BlockManagerMasterActor,其实不然,仔细看 registerOrLookup 函数的实现。如果当前节点是 driver 则创建这个 actor,否则建立到 driver 的连接。代码如下:
def registerOrLookup(name: String, newActor: => Actor): ActorRef = {if (isDriver) {logInfo("Registering " + name)actorSystem.actorOf(Props(newActor), name = name)} else {val driverHost: String = conf.get("spark.driver.host", "localhost")val driverPort: Int = conf.getInt("spark.driver.port", 7077)Utils.checkHost(driverHost, "Expected hostname")val url = s"akka.tcp://spark@$driverHost:$driverPort/user/$name"val timeout = AkkaUtils.lookupTimeout(conf)logInfo(s"Connecting to $name: $url")Await.result(actorSystem.actorSelection(url).resolveOne(timeout), timeout)}}
初始化过程中一个主要的动作就是 BlockManager 需要向 BlockManagerMaster 发起注册。
6.11.3 通信层
**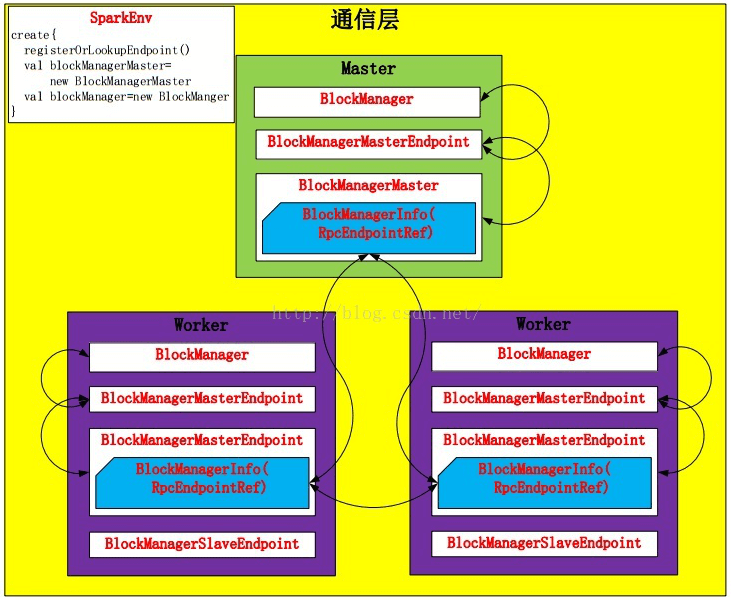
BlockManager 包装了 BlockManagerMaster,发送信息包装成 BlockManagerInfo。Spark 在 Driver 和 Worker 端都创建各自的 BlockManager,并通过 BlockManagerMaster 进行通信,通过 BlockManager 对 Storage 模块进行操作。
BlockManager 对象在 SparkEnv.create 函数中进行创建,代码如下:
def registerOrLookupEndpoint(name: String, endpointCreator: => RpcEndpoint): RpcEndpointRef = {if (isDriver) {logInfo("Registering " + name)rpcEnv.setupEndpoint(name, endpointCreator)} else {RpcUtils.makeDriverRef(name, conf, rpcEnv)}}......val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(BlockManagerMaster.DRIVER_ENDPOINT_NAME,new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),conf, isDriver)val blockManager = new BlockManager(executorId, rpcEnv, blockManagerMaster,serializer, conf, mapOutputTracker, shuffleManager, blockTransferService, securityManager,numUsableCores)
并且在创建之前对当前节点是否是 Driver 进行了判断。如果是,则创建这个 Endpoint;否则,创建 Driver 的连接。
在创建 BlockManager 之后,BlockManager 会调用 initialize 方法初始化自己。并且初始化的时候,会调用 BlockManagerMaster 向 Driver 注册自己,同时,在注册时也启动了 Slave Endpoint。另外,向本地 shuffle 服务器注册 Executor 配置,如果存在的话。代码如下:
def initialize(appId: String): Unit = {......master.registerBlockManager(blockManagerId, maxMemory, slaveEndpoint)if (externalShuffleServiceEnabled && !blockManagerId.isDriver) {registerWithExternalShuffleServer()}}
而 BlockManagerMaster 将注册请求包装成 RegisterBlockManager 注册到 Driver。Driver 的 BlockManagerMasterEndpoint 会调用 register 方法,通过对消息 BlockManagerInfo 检查,向 Driver 注册,代码如下:
private def register(id: BlockManagerId, maxMemSize: Long, slaveEndpoint: RpcEndpointRef) {val time = System.currentTimeMillis()if (!blockManagerInfo.contains(id)) {blockManagerIdByExecutor.get(id.executorId) match {case Some(oldId) =>logError("Got two different block manager registrations on same executor - "+ s" will replace old one $oldId with new one $id")removeExecutor(id.executorId)case None =>}logInfo("Registering block manager %s with %s RAM, %s".format(id.hostPort, Utils.bytesToString(maxMemSize), id))blockManagerIdByExecutor(id.executorId) = idblockManagerInfo(id) = new BlockManagerInfo(id, System.currentTimeMillis(), maxMemSize, slaveEndpoint)}listenerBus.post(SparkListenerBlockManagerAdded(time, id, maxMemSize))}
不难发现 BlockManagerInfo 对象被保存到 Map 映射中。在通信层中 BlockManagerMaster 控制着消息的流向,这里采用了模式匹配,所有的消息模式都在 BlockManagerMessage 中。
6.11.4 存储层
Spark Storage 的最小存储单位是 block,所有的操作都是以 block 为单位进行的。 在 BlockManager 被创建的时候 MemoryStore 和 DiskStore 对象就被创建出来了。代码如下:
val diskBlockManager = new DiskBlockManager(this, conf)private[spark] val memoryStore = new MemoryStore(this, maxMemory)private[spark] val diskStore = new DiskStore(this, diskBlockManager)
6.11.4.1 Disk Store
由于当前的 Spark 版本对 Disk Store 进行了更细粒度的分工,把对文件的操作提取出来放到了 DiskBlockManager 中,DiskStore 仅仅负责数据的存储和读取。
DiskStore 会配置多个文件目录,Spark 会在不同的文件目录下创建文件夹,其中文件夹的命名方式是:spark-UUID(随机 UUID 码)。Disk Store 在存储的时候创建文件夹。并且根据【高内聚,低耦合】原则,这种服务型的工具代码就放到了 Utils 中(调用路径:DiskStore.putBytes —> DiskBlockManager.createLocalDirs —> Utils.createDirectory),代码如下:
def createDirectory(root: String, namePrefix: String = "spark"): File = {var attempts = 0val maxAttempts = MAX_DIR_CREATION_ATTEMPTSvar dir: File = nullwhile (dir == null) {attempts += 1if (attempts > maxAttempts) {throw new IOException("Failed to create a temp directory (under " + root + ") after " +maxAttempts + " attempts!")}try {dir = new File(root, namePrefix + "-" + UUID.randomUUID.toString)if (dir.exists() || !dir.mkdirs()) {dir = null}} catch { case e: SecurityException => dir = null; }}dir.getCanonicalFile}
在 DiskBlockManager 里,每个 block 都被存储为一个 file,通过计算 blockId 的 hash 值,将 block 映射到文件中。
def getFile(filename: String): File = {val hash = Utils.nonNegativeHash(filename)val dirId = hash % localDirs.lengthval subDirId = (hash / localDirs.length) % subDirsPerLocalDirval subDir = subDirs(dirId).synchronized {val old = subDirs(dirId)(subDirId)if (old != null) {old} else {val newDir = new File(localDirs(dirId), "%02x".format(subDirId))if (!newDir.exists() && !newDir.mkdir()) {throw new IOException(s"Failed to create local dir in $newDir.")}subDirs(dirId)(subDirId) = newDirnewDir}}new File(subDir, filename)}def getFile(blockId: BlockId): File = getFile(blockId.name)
通过 hash 值的取模运算,求出 dirId 和 subDirId。然后,在从 subDirs 中找到 subDir,如果 subDir 不存在,则创建一个新 subDir。最后,以 subDir 为路径,blockId 的 name 属性为文件名,新建该文件。 文件创建完之后,那么 Spark 就会在 DiskStore 中向文件写与之映射的 block,代码如下:
override def putBytes(blockId: BlockId, _bytes: ByteBuffer, level: StorageLevel): PutResult = {val bytes = _bytes.duplicate()logDebug(s"Attempting to put block $blockId")val startTime = System.currentTimeMillisval file = diskManager.getFile(blockId)val channel = new FileOutputStream(file).getChannelUtils.tryWithSafeFinally {while (bytes.remaining > 0) {channel.write(bytes)}} {channel.close()}val finishTime = System.currentTimeMillislogDebug("Block %s stored as %s file on disk in %d ms".format(file.getName, Utils.bytesToString(bytes.limit), finishTime - startTime))PutResult(bytes.limit(), Right(bytes.duplicate()))}
读取过程就简单了,DiskStore 根据 blockId 读取与之映射的 file 内容,当然,这中间需要从 DiskBlockManager 中得到文件信息。代码如下:
private def getBytes(file: File, offset: Long, length: Long): Option[ByteBuffer] = {val channel = new RandomAccessFile(file, "r").getChannelUtils.tryWithSafeFinally {if (length < minMemoryMapBytes) {val buf = ByteBuffer.allocate(length.toInt)channel.position(offset)while (buf.remaining() != 0) {if (channel.read(buf) == -1) {throw new IOException("Reached EOF before filling buffer\n" +s"offset=$offset\nfile=${file.getAbsolutePath}\nbuf.remaining=${buf.remaining}")}}buf.flip()Some(buf)} else {Some(channel.map(MapMode.READ_ONLY, offset, length))}} {channel.close()}}override def getBytes(blockId: BlockId): Option[ByteBuffer] = {val file = diskManager.getFile(blockId.name)getBytes(file, 0, file.length)}
6.11.4.2 Memory Store
相对 Disk Store,Memory Store 就显得容易很多。Memory Store 用一个 LinkedHashMap 来管理,其中 Key 是 blockId,Value 是 MemoryEntry 样例类,MemoryEntry 存储着数据信息。代码如下:
private case class MemoryEntry(value: Any, size: Long, deserialized: Boolean)private val entries = new LinkedHashMap[BlockId, MemoryEntry](32, 0.75f, true)
在 MemoryStore 中存储 block 的前提是当前内存有足够的空间存放。通过对 tryToPut 函数的调用对内存空间进行判断。代码如下:
def putBytes(blockId: BlockId, size: Long, _bytes: () => ByteBuffer): PutResult = {lazy val bytes = _bytes().duplicate().rewind().asInstanceOf[ByteBuffer]val putAttempt = tryToPut(blockId, () => bytes, size, deserialized = false)val data =if (putAttempt.success) {assert(bytes.limit == size)Right(bytes.duplicate())} else {null}PutResult(size, data, putAttempt.droppedBlocks)}
在 tryToPut 函数中,通过调用 enoughFreeSpace 函数判断内存空间。如果内存空间足够,那么就把 block 放到 LinkedHashMap 中;如果内存不足,那么就告诉 BlockManager 内存不足,如果允许 DiskStore,那么就把该 block 放到 disk 上。代码如下:
private def tryToPut(blockId: BlockId, value: () => Any, size: Long, deserialized: Boolean): ResultWithDroppedBlocks = {var putSuccess = falseval droppedBlocks = new ArrayBuffer[(BlockId, BlockStatus)]accountingLock.synchronized {val freeSpaceResult = ensureFreeSpace(blockId, size)val enoughFreeSpace = freeSpaceResult.successdroppedBlocks ++= freeSpaceResult.droppedBlocksif (enoughFreeSpace) {val entry = new MemoryEntry(value(), size, deserialized)entries.synchronized {entries.put(blockId, entry)currentMemory += size}val valuesOrBytes = if (deserialized) "values" else "bytes"logInfo("Block %s stored as %s in memory (estimated size %s, free %s)".format(blockId, valuesOrBytes, Utils.bytesToString(size), Utils.bytesToString(freeMemory)))putSuccess = true} else {lazy val data = if (deserialized) {Left(value().asInstanceOf[Array[Any]])} else {Right(value().asInstanceOf[ByteBuffer].duplicate())}val droppedBlockStatus = blockManager.dropFromMemory(blockId, () => data)droppedBlockStatus.foreach { status => droppedBlocks += ((blockId, status)) }}releasePendingUnrollMemoryForThisTask()}ResultWithDroppedBlocks(putSuccess, droppedBlocks)}
MemoryStore 读取 block 也很简单,只需要从 LinkedHashMap 中取出 blockId 的 Value 即可。代码如下:
override def getValues(blockId: BlockId): Option[Iterator[Any]] = {val entry = entries.synchronized {entries.get(blockId)}if (entry == null) {None} else if (entry.deserialized) {Some(entry.value.asInstanceOf[Array[Any]].iterator)} else {val buffer = entry.value.asInstanceOf[ByteBuffer].duplicate()Some(blockManager.dataDeserialize(blockId, buffer))}}
6.11.5 数据写入过程分析
**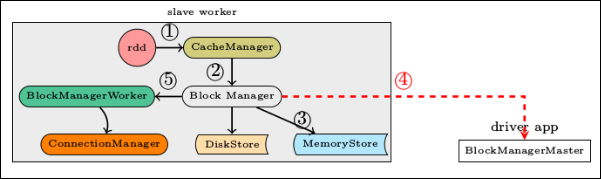
数据写入的简要流程:
RDD.iterator()是与 storage 子系统交互的入口。CacheManager.getOrCompute调用 BlockManager 的 put 接口来写入数据。- 数据优先写入到 MemoryStore 即内存,如果 MemoryStore 中的数据已满则将最近使用次数不频繁的数据写入到磁盘。
- 通知 BlockManagerMaster 有新的数据写入,在 BlockManagerMaster 中保存元数据。
- 将写入的数据与其它 slave worker 进行同步,一般来说在本机写入的数据,都会另先一台机器来进行数据的备份,即 replicanumber=1。
其实,我们在 put 和 get block 的时候并没有那么复杂,前面的细节 BlockManager 都包装好了,我们只需要调用 BlockManager 中的 put 和 get 函数即可。
代码如下:
def putBytes(blockId: BlockId,bytes: ByteBuffer,level: StorageLevel,tellMaster: Boolean = true,effectiveStorageLevel: Option[StorageLevel] = None): Seq[(BlockId, BlockStatus)] = {require(bytes != null, "Bytes is null")doPut(blockId, ByteBufferValues(bytes), level, tellMaster, effectiveStorageLevel)}private def doPut(blockId: BlockId,data: BlockValues,level: StorageLevel,tellMaster: Boolean = true,effectiveStorageLevel: Option[StorageLevel] = None): Seq[(BlockId, BlockStatus)] = {require(blockId != null, "BlockId is null")require(level != null && level.isValid, "StorageLevel is null or invalid")effectiveStorageLevel.foreach {level => require(level != null && level.isValid, "Effective StorageLevel is null or invalid")}val updatedBlocks = new ArrayBuffer[(BlockId, BlockStatus)]val putBlockInfo = {val tinfo = new BlockInfo(level, tellMaster)val oldBlockOpt = blockInfo.putIfAbsent(blockId, tinfo)if (oldBlockOpt.isDefined) {if (oldBlockOpt.get.waitForReady()) {logWarning(s"Block $blockId already exists on this machine; not re-adding it")return updatedBlocks}oldBlockOpt.get} else {tinfo}}val startTimeMs = System.currentTimeMillisvar valuesAfterPut: Iterator[Any] = nullvar bytesAfterPut: ByteBuffer = nullvar size = 0Lval putLevel = effectiveStorageLevel.getOrElse(level)val replicationFuture = data match {case b: ByteBufferValues if putLevel.replication > 1 =>val bufferView = b.buffer.duplicate()Future {replicate(blockId, bufferView, putLevel)}(futureExecutionContext)case _ => null}putBlockInfo.synchronized {logTrace("Put for block %s took %s to get into synchronized block".format(blockId, Utils.getUsedTimeMs(startTimeMs)))var marked = falsetry {val (returnValues, blockStore: BlockStore) = {if (putLevel.useMemory) {(true, memoryStore)} else if (putLevel.useOffHeap) {(false, externalBlockStore)} else if (putLevel.useDisk) {(putLevel.replication > 1, diskStore)} else {assert(putLevel == StorageLevel.NONE)throw new BlockException(blockId, s"Attempted to put block $blockId without specifying storage level!")}}val result = data match {case IteratorValues(iterator) => blockStore.putIterator(blockId, iterator, putLevel, returnValues)case ArrayValues(array) => blockStore.putArray(blockId, array, putLevel, returnValues)case ByteBufferValues(bytes) =>bytes.rewind()blockStore.putBytes(blockId, bytes, putLevel)}size = result.sizeresult.data match {case Left (newIterator) if putLevel.useMemory => valuesAfterPut = newIteratorcase Right (newBytes) => bytesAfterPut = newBytescase _ =>}if (putLevel.useMemory) {result.droppedBlocks.foreach { updatedBlocks += _ }}val putBlockStatus = getCurrentBlockStatus(blockId, putBlockInfo)if (putBlockStatus.storageLevel != StorageLevel.NONE) {marked = trueputBlockInfo.markReady(size)if (tellMaster) {reportBlockStatus(blockId, putBlockInfo, putBlockStatus)}updatedBlocks += ((blockId, putBlockStatus))}} finally {if (!marked) {blockInfo.remove(blockId)putBlockInfo.markFailure()logWarning(s"Putting block $blockId failed")}}}logDebug("Put block %s locally took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))if (putLevel.replication > 1) {data match {case ByteBufferValues(bytes) =>if (replicationFuture != null) {Await.ready(replicationFuture, Duration.Inf)}case _ =>val remoteStartTime = System.currentTimeMillisif (bytesAfterPut == null) {if (valuesAfterPut == null) {throw new SparkException("Underlying put returned neither an Iterator nor bytes! This shouldn't happen.")}bytesAfterPut = dataSerialize(blockId, valuesAfterPut)}replicate(blockId, bytesAfterPut, putLevel)logDebug("Put block %s remotely took %s".format(blockId, Utils.getUsedTimeMs(remoteStartTime)))}}BlockManager.dispose(bytesAfterPut)if (putLevel.replication > 1) {logDebug("Putting block %s with replication took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))} else {logDebug("Putting block %s without replication took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))}updatedBlocks}}
对于 doPut 函数,主要做了以下几个操作:
- 创建 BlockInfo 对象存储 block 信息。
- 将 BlockInfo 加锁,然后根据 Storage Level 判断存储到 Memory 还是 Disk。同时,对于已经准备好读的 BlockInfo 要进行解锁。
- 根据 block 的副本数量决定是否向远程发送副本。
6.11.5.1 序列化与否
写入的具体内容可以是序列化之后的 bytes 也可以是没有序列化的 value。此处有一个对 scala 的语法中 Either, Left, Right 关键字的理解。
6.11.6 数据读取过程分析
def get(blockId: BlockId): Option[Iterator[Any]] = {val local = getLocal(blockId)if (local.isDefined) {logInfo("Found block %s locally".format(blockId))return local}val remote = getRemote(blockId)if (remote.isDefined) {logInfo("Found block %s remotely".format(blockId))return remote}None}
6.11.6.1 本地读取
首先在查询本机的 MemoryStore 和 DiskStore 中是否有所需要的 block 数据存在,如果没有则发起远程数据获取。
6.11.6.2 远程读取
远程获取调用路径, getRemote —> doGetRemote, 在 doGetRemote 中最主要的就是调用 BlockManagerWorker.syncGetBlock 来从远程获得数据。
syncGetBlock 代码:
def syncGetBlock(msg: GetBlock, toConnManagerId: ConnectionManagerId): ByteBuffer = {val blockManager = blockManagerWorker.blockManagerval connectionManager = blockManager.connectionManagerval blockMessage = BlockMessage.fromGetBlock(msg)val blockMessageArray = new BlockMessageArray(blockMessage)val responseMessage = connectionManager.sendMessageReliablySync(toConnManagerId, blockMessageArray.toBufferMessage)responseMessage match {case Some(message) => {val bufferMessage = message.asInstanceOf[BufferMessage]logDebug("Response message received " + bufferMessage)BlockMessageArray.fromBufferMessage(bufferMessage).foreach(blockMessage => {logDebug("Found " + blockMessage)return blockMessage.getData})}case None => logDebug("No response message received")}null}
上述这段代码中最有意思的莫过于 sendMessageReliablySync,远程数据读取毫无疑问是一个异步 i/o 操作,这里的代码怎么写起来就像是在进行同步的操作一样呢。也就是说如何知道对方发送回来响应的呢? 别急,继续去看看 sendMessageReliablySync 的定义:
def sendMessageReliably(connectionManagerId: ConnectionManagerId, message: Message): Future[Option[Message]] = {val promise = Promise[Option[Message]]val status = new MessageStatus(message, connectionManagerId, s => promise.success(s.ackMessage))messageStatuses.synchronized {messageStatuses += ((message.id, status))}sendMessage(connectionManagerId, message)promise.future}
要是我说秘密在这里,你肯定会说我在扯淡,但确实在此处。注意到关键字 Promise 和 Future 没? 如果这个 future 执行完毕,返回 s.ackMessage。我们再看看这个 ackMessage 是在什么地方被写入的呢。看一看 ConnectionManager.handleMessage 中的代码片段:
case bufferMessage: BufferMessage =>{if (authEnabled) {val res = handleAuthentication(connection, bufferMessage)if (res == true) {logDebug("After handleAuth result was true, returning")return}}if (bufferMessage.hasAckId) {val sentMessageStatus = messageStatuses. synchronized {messageStatuses.get(bufferMessage.ackId) match {case Some(status) =>{messageStatuses -= bufferMessage.ackIdstatus}case None =>{throw new Exception("Could not find reference for received ack message " +message.id)null}}}sentMessageStatus. synchronized {sentMessageStatus.ackMessage = Some(message)sentMessageStatus.attempted = truesentMessageStatus.acked = truesentMessageStaus.markDone()}}}
注意:此处的所调用的 sentMessageStatus.markDone 就会调用在 sendMessageReliablySync 中定义的 promise.Success,不妨看看 MessageStatus 的定义:
class MessageStatus(val message: Message,val connectionManagerId: ConnectionManagerId,completionHandler: MessageStatus => Unit) {var ackMessage: Option[Message] = Nonevar attempted = falsevar acked = falsedef markDone() { completionHandler(this) }}
6.11.7 Partition 如何转化为 Block
在 storage 模块里面所有的操作都是和 block 相关的,但是在 RDD 里面所有的运算都是基于 partition 的,那么 partition 是如何与 block 对应上的呢? RDD 计算的核心函数是 iterator() 函数:
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {if (storageLevel != StorageLevel.NONE) {SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)} else {computeOrReadCheckpoint(split, context)}}
如果当前 RDD 的 storage level 不是 NONE 的话,表示该 RDD 在 BlockManager 中有存储,那么调用 CacheManager 中的 getOrCompute() 函数计算 RDD,在这个函数中 partition 和 block 发生了关系:
- 首先根据 RDD id 和 partition index 构造出 block id (rdd_xx_xx)。
- 接着从 BlockManager 中取出相应的 block:
- 如果该 block 存在,表示此 RDD 在之前已经被计算过和存储在 BlockManager 中,因此取出即可,无需再重新计算。
- 如果该 block 不存在则需要调用 RDD 的
**computeOrReadCheckpoint()**函数计算出新的 block,并将其存储到 BlockManager 中。
需要注意的是 block 的计算和存储是阻塞的,若另一线程也需要用到此 block 则需等到该线程 block 的 loading 结束。
关键代码:
def getOrCompute[T](rdd:RDD[T],split:Partition,context:TaskContext,storageLevel:StorageLevel):Iterator[T] = {val key = "rdd_%d_%d".format(rdd.id, split.index)logDebug("Looking for partition " + key)blockManager.get(key) match {case Some(values) =>return values.asInstanceOf[Iterator[T]]case None =>loading. synchronized {if (loading.contains(key)) {logInfo("Another thread is loading %s, waiting for it to finish...".format(key))while (loading.contains(key)) {try {loading.wait()} catch {case _:Throwable =>}}logInfo("Finished waiting for %s".format(key))blockManager.get(key) match {case Some(values) =>return values.asInstanceOf[Iterator[T]]case None =>logInfo("Whoever was loading %s failed; we'll try it ourselves".format(key))loading.add(key)}} else {loading.add(key)}}try {logInfo("Partition %s not found, computing it".format(key))val computedValues = rdd.computeOrReadCheckpoint(split, context)if (context.runningLocally) {return computedValues}val elements = new ArrayBuffer[Any]elements++ = computedValuesblockManager.put(key, elements, storageLevel, true)return elements.iterator.asInstanceOf[Iterator[T]]} finally {loading. synchronized {loading.remove(key)loading.notifyAll()}}}
这样 RDD 的 transformation、action 就和 block 数据建立了联系,虽然抽象上我们的操作是在 partition 层面上进行的,但是 partition 最终还是被映射成为 block,因此实际上我们的所有操作都是对 block 的处理和存取。
6.11.8 partition 和 block 的对应关系
在 RDD 中,核心的函数是 iterator():
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {if (storageLevel != StorageLevel.NONE) {SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)} else {computeOrReadCheckpoint(split, context)}}
如果当前 RDD 的 storage level 不是 NONE 的话,表示该 RDD 在 BlockManager 中有存储,那么调用 CacheManager 中的 getOrCompute 函数计算 RDD,在这个函数中 partition 和 block 就对应起来了:getOrCompute 函数会先构造 RDDBlockId,其中 RDDBlockId 就把 block 和 partition 联系起来了,RDDBlockId 产生的 name 就是 BlockId 的 name 属性,形式是:rdd_rdd.id_partition.index。
getOrCompute 代码:
def getOrCompute[T](rdd: RDD[T],partition: Partition,context: TaskContext,storageLevel: StorageLevel): Iterator[T] = {val key = RDDBlockId(rdd.id, partition.index)logDebug(s"Looking for partition $key")blockManager.get(key) match {case Some(blockResult) =>val existingMetrics = context.taskMetrics.getInputMetricsForReadMethod(blockResult.readMethod)existingMetrics.incBytesRead(blockResult.bytes)val iter = blockResult.data.asInstanceOf[Iterator[T]]new InterruptibleIterator[T](context, iter) {override def next(): T = {existingMetrics.incRecordsRead(1)delegate.next()}}case None =>val storedValues = acquireLockForPartition[T](key)if (storedValues.isDefined) {return new InterruptibleIterator[T](context, storedValues.get)}try {logInfo(s"Partition $key not found, computing it")val computedValues = rdd.computeOrReadCheckpoint(partition, context)if (context.isRunningLocally) {return computedValues}val updatedBlocks = new ArrayBuffer[(BlockId, BlockStatus)]val cachedValues = putInBlockManager(key, computedValues, storageLevel, updatedBlocks)val metrics = context.taskMetricsval lastUpdatedBlocks = metrics.updatedBlocks.getOrElse(Seq[(BlockId, BlockStatus)]())metrics.updatedBlocks = Some(lastUpdatedBlocks ++ updatedBlocks.toSeq)new InterruptibleIterator(context, cachedValues)} finally {loading.synchronized {loading.remove(key)loading.notifyAll()}}}}
同时 getOrCompute 函数会对 block 进行判断:
- 如果该 block 存在,表示此 RDD 在之前已经被计算过和存储在 BlockManager 中,因此取出即可,无需再重新计算。
- 如果该 block 不存在则需要调用 RDD 的
computeOrReadCheckpoint()函数计算出新的 block,并将其存储到 BlockManager 中。
需要注意的是 block 的计算和存储是阻塞的,若另一线程也需要用到此 block 则需等到该线程 block 的 loading 结束。

若有收获,就点个赞吧
0 人点赞
