9.1 内存管理机制问题及挑战
(1)内存消耗来源多种多样,难以统一管理。
第1个方面是框架本身在处理数据时需要消耗内存,第2个方面是数据缓存,第3个方面是用户代码消耗的内存。
(2)内存消耗动态变化、难以预估,为内存分配和回收带来困难。
(3)task之间共享内存,导致内存竞争。
在Hadoop MapReduce中,框架为每个task启动一个单独的JVM运行,task之间没有内存竞争。在Spark中,多个task以线程方式运行在同一个Executor JVM中,task之间还存在内存共享和内存竞争,如何平衡内存共享和内存竞争的问题也具有挑战性。
9.2 应用内存消耗来源及影响因素
Hadoop MapReduce应用内存消耗指的是map/reduce task进程的内存消耗。对于Spark应用来说,其task(名为ShuffleMapTask或ResultTask)以线程方式运行在Executor JVM中。因此,Spark应用内存消耗在微观上指的是task线程的内存消耗,在宏观上指的是Executor JVM的内存消耗。由于Exectuor JVM中可以同时运行多个task,存在内存竞争,为了简化分析,我们主要关注单个task的内存消耗,必要时再分析Executor JVM的内存消耗。
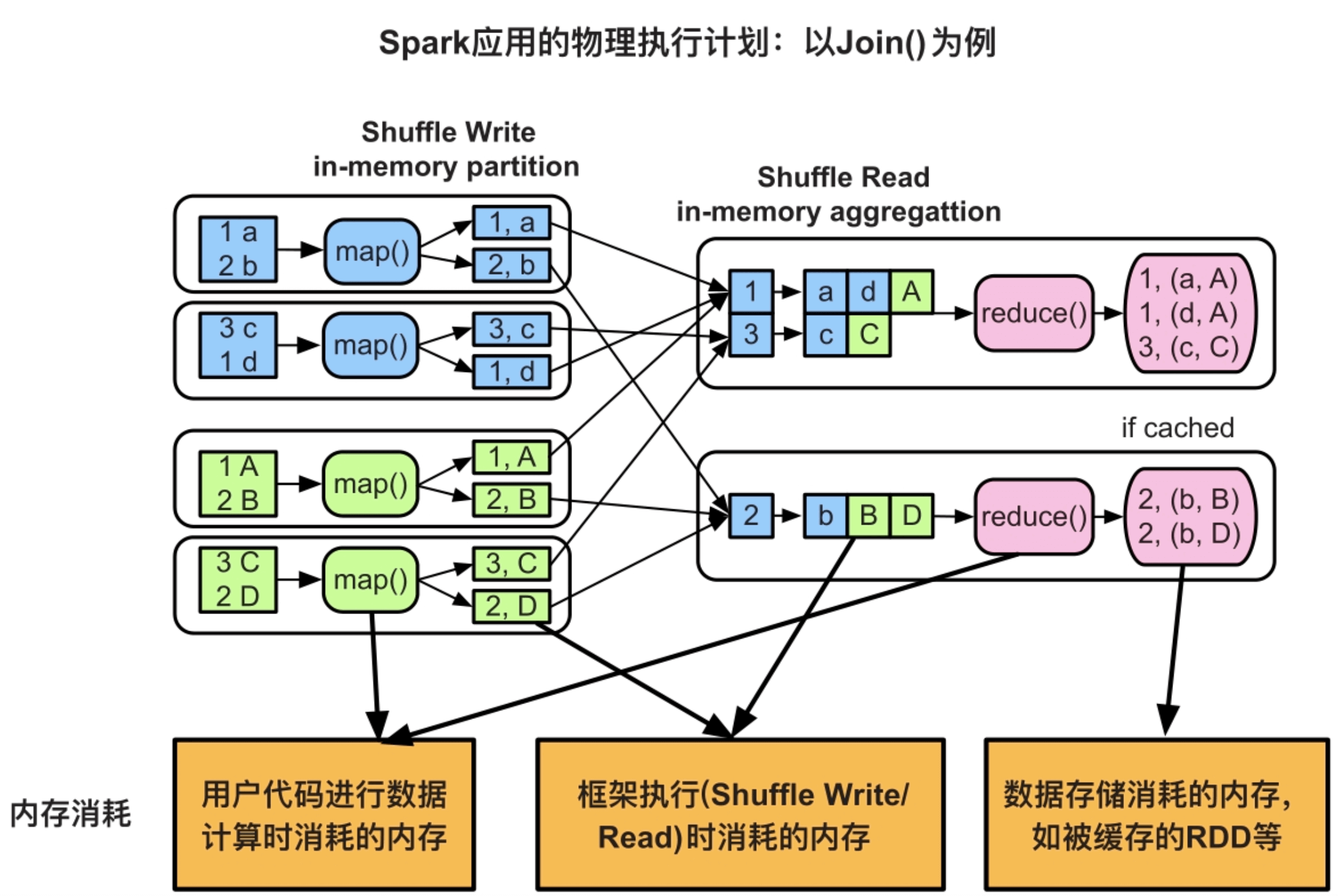
9.2.1 内存消耗来源1:用户代码
一种是每读入一条数据,立即调用func进行处理并输出结果,产生的中间计算结果并不进行存储;另一种是对中间计算结果进行一定程度的存储,比如,用户在flatMap()操作中定义了名为arr1的数组,并在该数组存放了中间计算结果,这些中间计算结果会造成内存消耗。
至于这些record会产生多大的中间计算结果,中间计算结果又有多少会被存放在内存中由用户代码的空间复杂度决定,难以预先估计。
9.2.2 内存消耗来源2:Shuffle机制中产生的中间数据
Shuffle Write阶段:如果需要进行combine()聚合,那么Spark会将record存放到类似HashMap的数据结构中进行聚合,这个过程中HashMap会占用大量内存空间。最后,Spark会按照partitionId或者Key对record进行排序,这个过程中可能会使用数组保存record,也会消耗一定的内存空间。
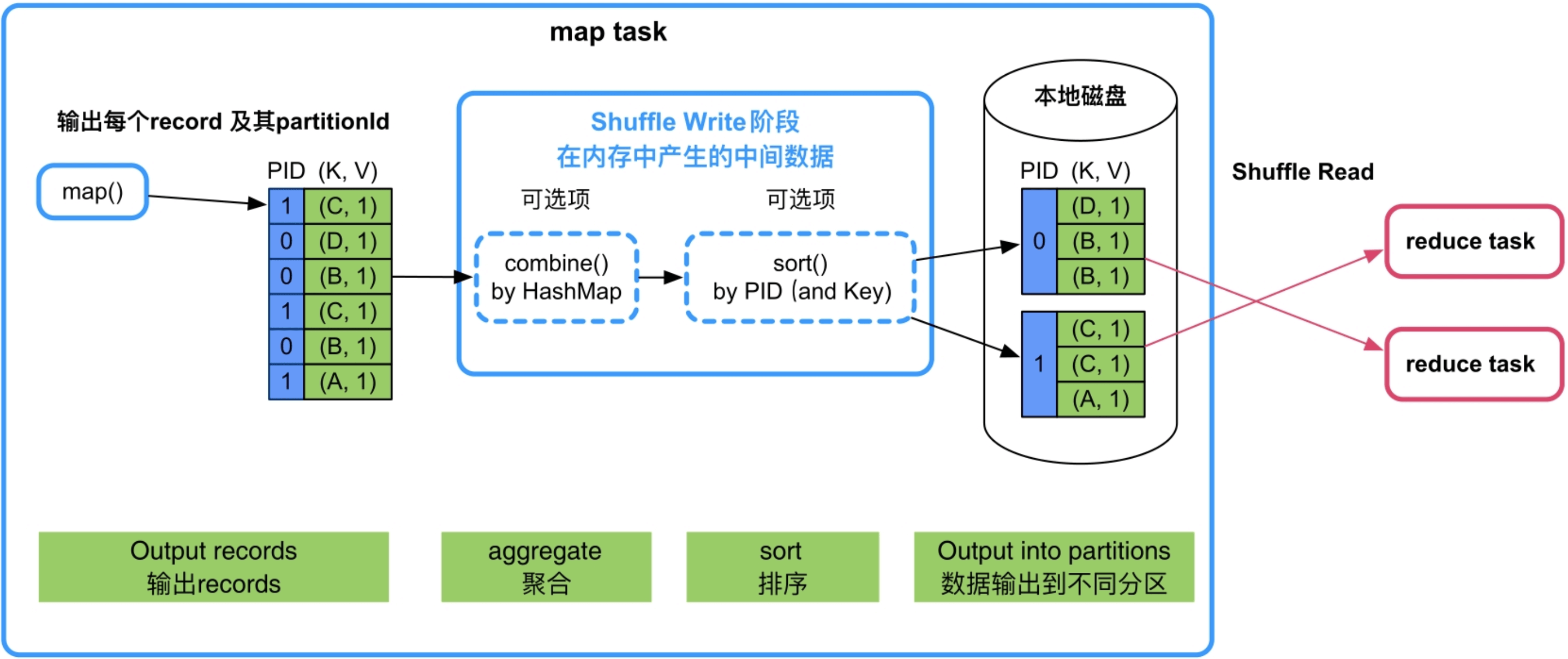
图9.2 Shuffle Write过程中的分区(partition)、聚合(aggregate)和排序(sort)过程
Shuffle Read阶段:如果需要对数据进行聚合,那么Spark将采用类似HashMap的数据结构对这些record进行聚合,会占用大量内存空间。最后,如果需要对Key进行排序,那么可能会建立数组来进行排序,需要消耗一定的内存空间。
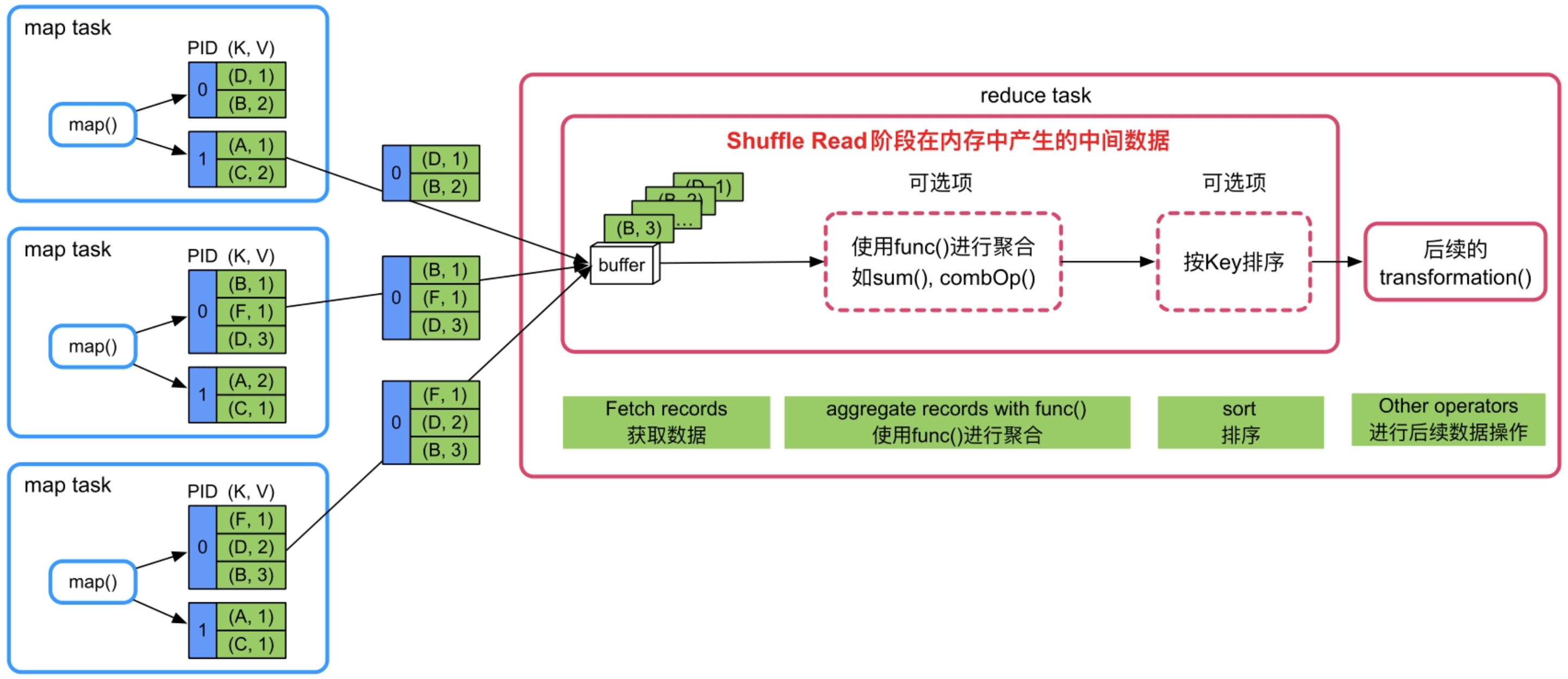
图9.3 Shuffle Read过程中数据获取(Fetch records)、聚合(aggregate)和排序(sort)过程
_
这些内存消耗也难以在task运行前进行估计,因此Spark采用动态监测的方法,在Shuffle机制中动态监测HashMap等数据结构大小,动态调整数据结构长度,并在内存不足时将数据spill到磁盘中。
9.2.3 内存消耗来源3:缓存数据
当前job在运行中产生的数据可能被后续job重用。因此,Spark会将一些重用数据缓存到内存中,提升应用性能。
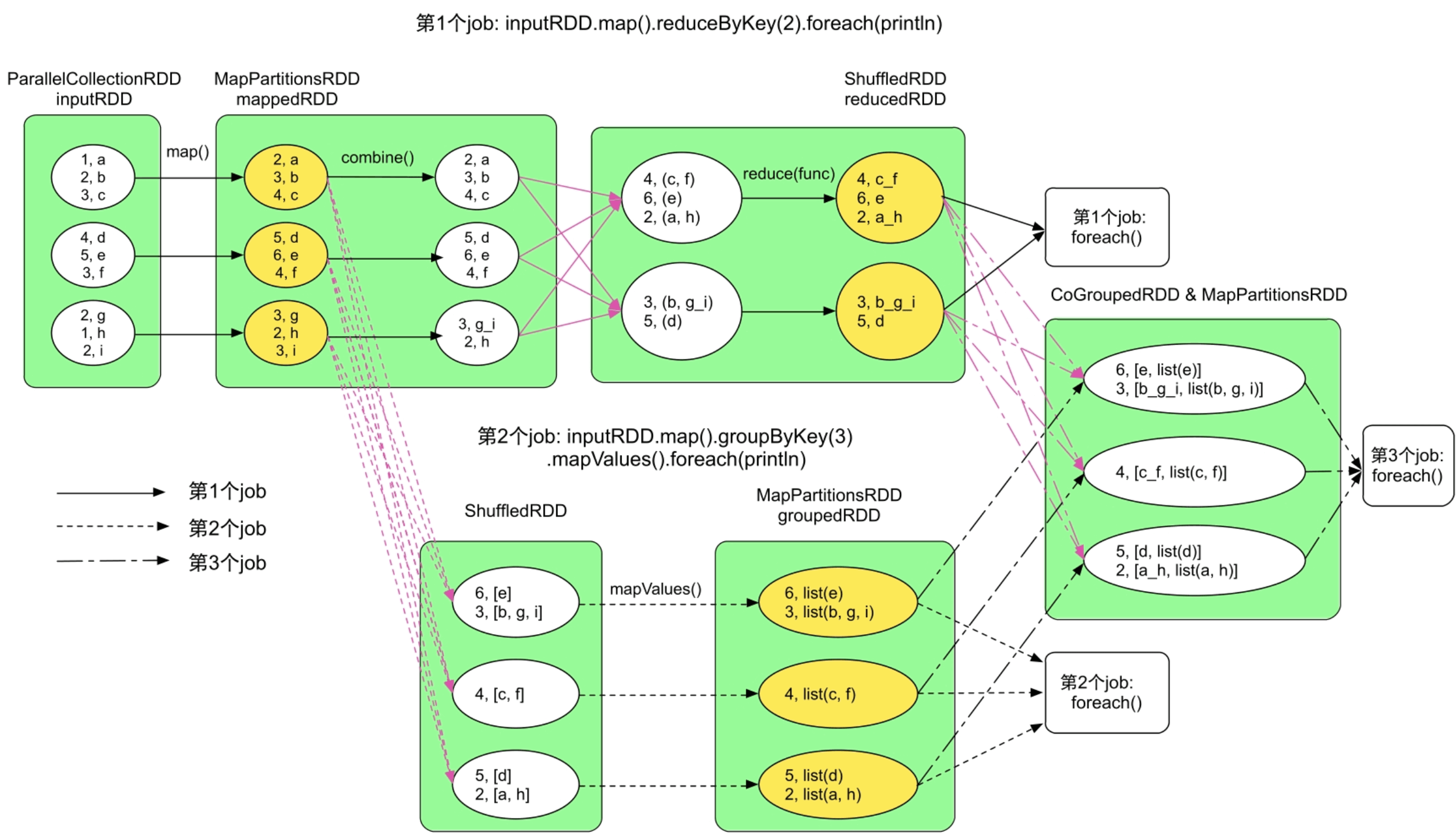
图9.4 一个复杂应用中的缓存数据
_
Spark无法提前预测缓存数据大小,只能在写入过程中动态监控当前缓存数据的大小。另外,缓存数据还存在替换和回收机制,因此缓存数据在运行过程中大小也是动态变化的。
9.3 Spark框架内存管理模型
9.3.1 静态内存管理模型
一个简单的解决方法是将内存空间划分为3个分区,每个分区负责存储3种内存消耗来源中的一种,并根据经验确定三者的空间比例。
Spark早期版本(Spark 1.6之前的版本)采用了这个方法,用静态内存管理模型(StaticMemoryManger)将内存空间划分为如下3个分区:
- 数据缓存空间(Storage memory):约占60%的内存空间,用于存储RDD缓存数据、广播数据(如第5章中的参数w)、task的一些计算结果等。
- 框架执行空间(Execution memory):约占20%的内存空间,用于存储Shuffle机制中的中间数据。
- 用户代码空间(User memory):约占20%的内存空间,用于存储用户代码的中间计算结果、Spark框架本身产生的内部对象,以及Executor JVM自身的一些内存对象等。
这种静态划分方式的优点是各个分区的角色分明、实现简单,缺点是分区之间存在“硬”界限,难以平衡三者的内存消耗。为了缓解这个问题,Spark允许用户自己设定三者的空间比例,但对于普通用户来说很难确定一个合适的比例,而且内存用量在运行过程中不断变化,并不存在一个最优的静态比例,也就容易造成内存资源浪费、内存溢出等问题。
9.3.2 统一内存管理模型
最理想的方法是为三者分配一定的内存配额,并且在运行时根据三者的实际内存用量,动态调整配额比例。
所以,优化后的内存管理主要是根据监控得到的内存用量信息,来动态调节用于Shuffle机制和用于缓存数据内存空间的。另外,当三者的内存消耗量超过实际内存大小时怎么办?因此,除了内存动态调整还需要进行一定的内存配额限制。一个解决方案是为每个内存消耗来源设定一个上下界,其内存配额在上下界范围内动态可调。
Spark从1.6版本开始,设计实现了更高效的统一内存管理模型(UnifiedMemoryManager),仍然将内存划分为3个分区:数据缓存空间、框架执行空间和用户代码空间,与静态内存管理模型不同的是,统一内存管理模型使用“软”界限来调整分区的占用比例。
数据缓存空间和框架执行空间组成(共享)了一个大的空间,称为Framework memory。Framework memory大小固定,且为数据缓存空间和框架执行空间设置了初始比例,但这个比例可以在应用执行过程中动态调整,如框架执行空间不足时可以借用数据存储空间来“Shuffle”中间数据。同时,两者之间比例也有上下界,使得一方不能完全“侵占”另一方的空间,从而避免因为某一方空间占满导致后续的数据缓存操作或Shuffle操作无法执行。对于用户代码空间,Spark将其设定为固定大小,原因是难以在运行时获取用户代码的真实内存消耗,也就难以动态设定用户代码空间的比例。
如图9.5所示,Spark统一内存管理模型将Executor JVM的内存空间划分如下。该内存管理模型可以使用Executor JVM的堆内内存和堆外内存。
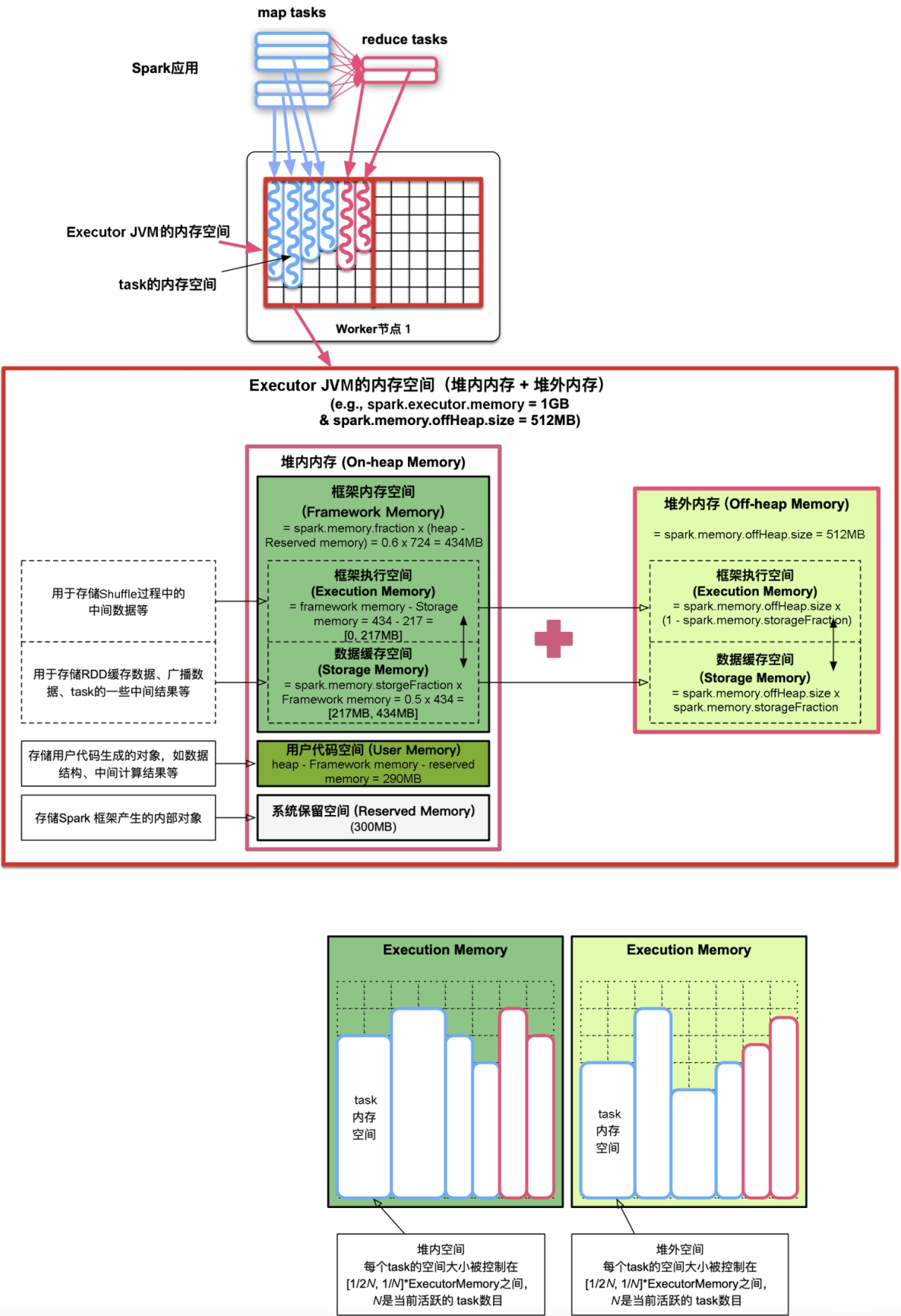
图9.5 Spark统一内存管理模型对Executor JVM内存空间划分与使用
Executor JVM的整个内存空间划分为以下3个部分。
(1)系统保留内存(Reserved Memory)
系统保留内存使用较小的空间存储Spark框架产生的内部对象(如Spark Executor对象,TaskMemoryManager对象等Spark内部对象),系统保留内存大小通过spark.testing.ReservedMemory默认设置为300MB。
(2)用户代码空间(User Memory)
用户代码空间被用于存储用户代码生成的对象,如map()中用户自定义的数据结构。用户代码空间默认约为40%的内存空间。
(3)框架内存空间(Framework Memory)
框架内存空间包括框架执行空间(Execution Memory)和数据缓存空间(Storage Memory)。总大小为spark.memory.fraction (default 0.6)×(heap-Reserved memory),约等于60%的内存空间。两者共享这个空间,其中一方空间不足时可以动态向另一方借用。具体地,当数据缓存空间不足时,可以向框架执行空间借用其空闲空间,后续当框架执行需要更多空间时,数据缓存空间需要“归还”借用的空间,这时候Spark可能将部分缓存数据移除内存来归还空间。同样,当框架执行空间不足时,可以向数据缓存空间借用空间,但至少要保证数据缓存空间具有约50%左右(spark.memory.storageFraction (default 0.5)×Framework memory大小)的空间。在框架执行时借走的空间不会归还给数据缓存空间,原因是难以代码实现。
Framework Memory的堆外内存空间:为了减少垃圾回收(GC)开销,Spark的统一内存管理机制也允许使用堆外内存。堆外内存类似使用C/C++语言分配的malloc空间,该空间不受JVM垃圾回收机制管理,在结束使用时需要手动释放空间。因为堆外内存主要存储序列化对象数据,而用户代码处理的是普通Java对象,因此堆外内存只用于框架执行空间和数据缓存空间,而不用于用户代码空间。如图9.5所示,如果用户定义了堆外内存,其大小通过spark.memory.offHeap.size设置,那么Spark仍然会按照堆内内存使用的spark.memory.storageFraction比例将堆外内存分为框架执行空间和数据缓存空间,而且堆外内存的管理方式和功能与堆内内存的Framework Memory一样。在运行应用时,Spark会根据应用的Shuffle方式及用户设定的数据缓存级别来决定使用堆内内存还是堆外内存,如后面介绍的SerializedShuffle方式可以利用堆外内存来进行Shuffle Write,再如用户使用rdd.persist(OFF_HEAP)后可以将rdd存储到堆外内存。
虽然Spark内存模型可以限制框架使用的空间大小,但无法控制用户代码的内存消耗量。用户代码运行时的实际内存消耗量可能超过用户代码空间的界限,侵占框架使用的空间,此时如果框架也使用了大量内存空间,则可能造成内存溢出。
9.4 Spark框架执行内存消耗与管理
内存共享与竞争
由于Executor中存在多个task,因此框架执行空间实际上是由多个task(ShuffleMapTask或ResultTask)共享的。在运行过程中,Executor中活跃的task数目在[0,#ExectuorCores]内变化,#ExectuorCores表示为每个Executor分配的CPU个数。为了公平性,每个task可使用的内存空间被均分,也就是空间大小被控制在[1/2N,1/N]×ExecutorMemory内,N是当前活跃的task数目。在图9.6中,假设一个Executor中最初有4个活跃task,且只使用堆内内存,那么每个task最多可以占用1/4的On-heap Execution Memory,当其中2个task完成而又新加入4个task后,活跃task变为6个,那么后加入的每个task最多使用1/6的On-heap Execution Memory。这个策略也适用于堆外内存中的Executition Memory。
内存使用
前面提到过,框架执行空间主要用于Shuffle阶段,Shuffle阶段的主要工作是对上游stage的输出数据进行划分,并将其传递到下游stage进行聚合等进一步处理。在这个过程中需要对数据进行partition、sort、merge、fetch、aggregate等操作,执行这些操作需要buffer、HashMap之类的数据结构。由于中间数据量很大,这些数据结构会消耗大量内存。当框架执行内存不足时,Spark会像MapReduce一样将部分数据spill到磁盘中,然后通过排序等方式来merge内存和磁盘上的数据,并用于下一步数据操作。
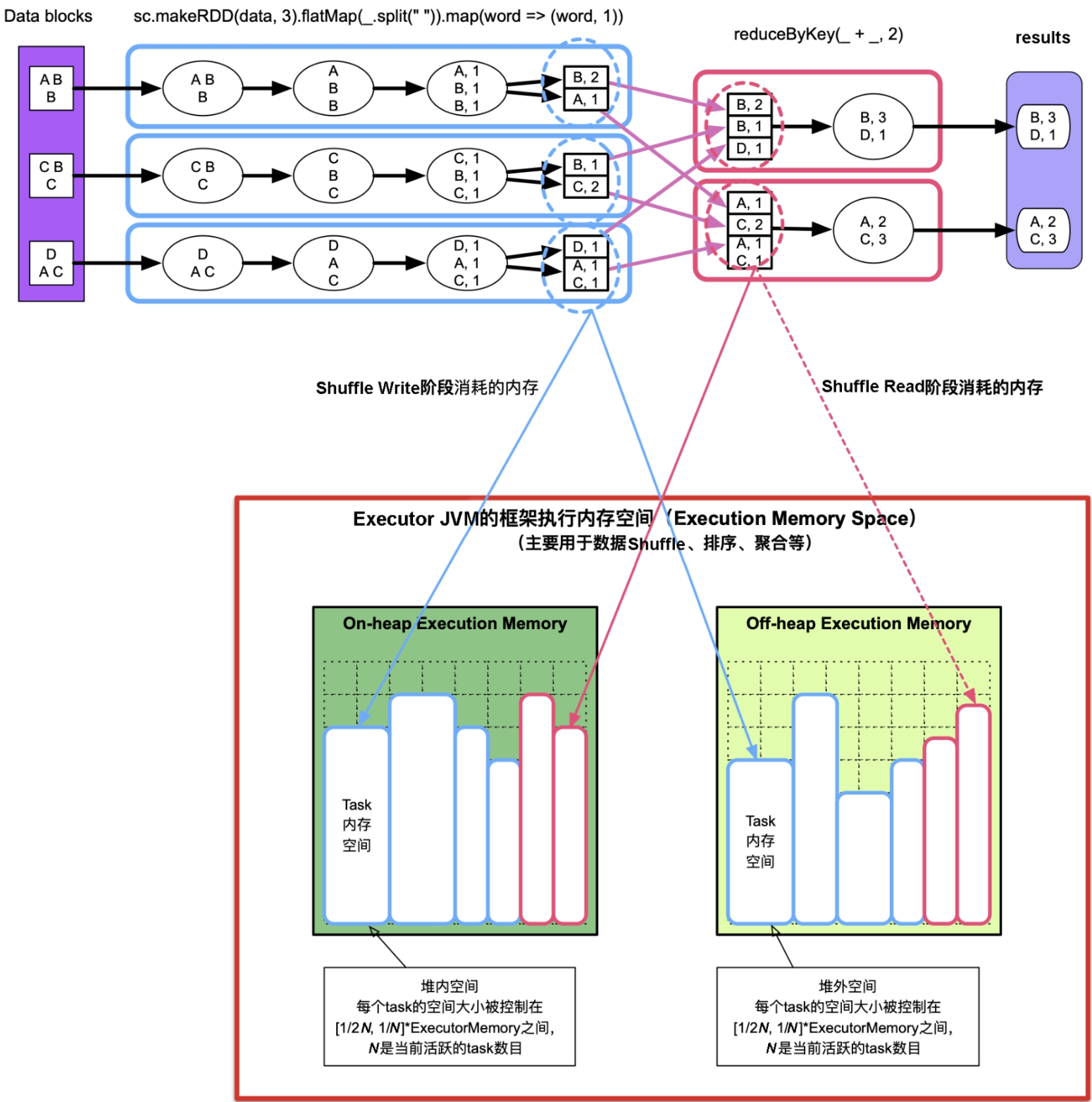
图9.6 框架执行内存空间(Execution Memory),包括堆内空间和堆外空间,由多个task共享
_
9.4.1 Shuffle Write阶段内存消耗及管理
我们根据Spark应用是否需要map()端聚合(combine),是否需要按Key进行排序,将Shuffle Write方式分为4种:
- map()端聚合、无排序且partition个数不超过200的情况:采用基于buffer的BypassMergeSortShuffle-Writer方式。
- 无map()端聚合、无排序且partition个数大于200的情况:采用Serialized ShuffleWriter。
- 无map()端聚合但需要排序的情况:采用基于数组的SortShuffleWriter(KeyOrdering=true)方式。
- 有map()端聚合的情况:采用基于HashMap的SortShuffleWriter(mapSideCombine=true)方式。
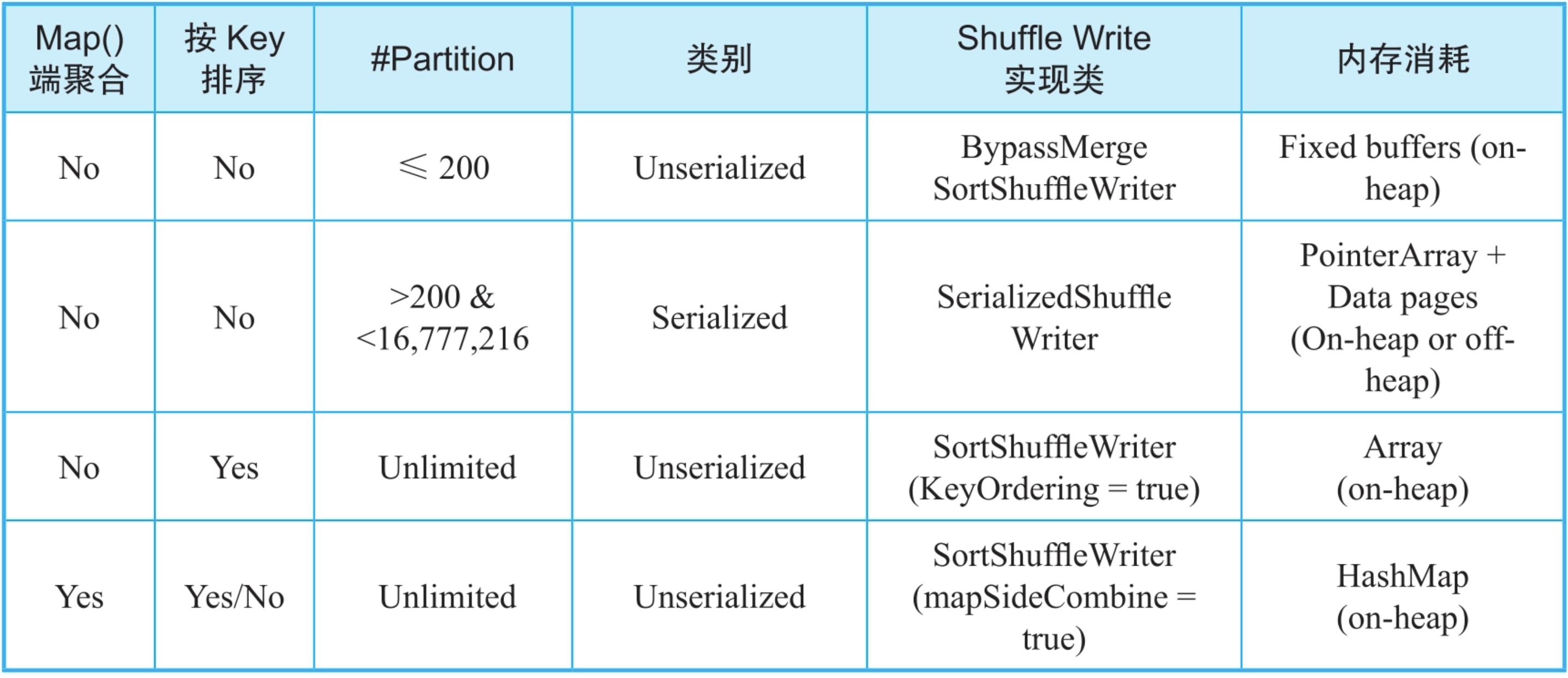
图9.7 不同的Shuffle Write方式及特点
_
第1、2、4这三种方式都是利用堆内内存来聚合、排序record对象的,属于Unserialized Shuffle方式。这种方式处理的record对象是普通Java对象,有较大的内存消耗,也会造成较大的JVM垃圾回收开销。Spark为了提高Shuffle效率,在2.0版本中引入了Serialized Shuffle方式,核心思想是直接在内存中操作序列化后的record对象(二进制数据),降低内存消耗和GC开销,同时也可以利用堆外内存。然而,由于Serialized Shuffle方式处理的是序列化后的数据,也有一些适用性上的不足,如在Shuffle Write中,只用于无map()端聚合且无排序的情况。
(1)不需要map()端聚合,不需要按Key进行排序,且分区个数较小(≤200)。
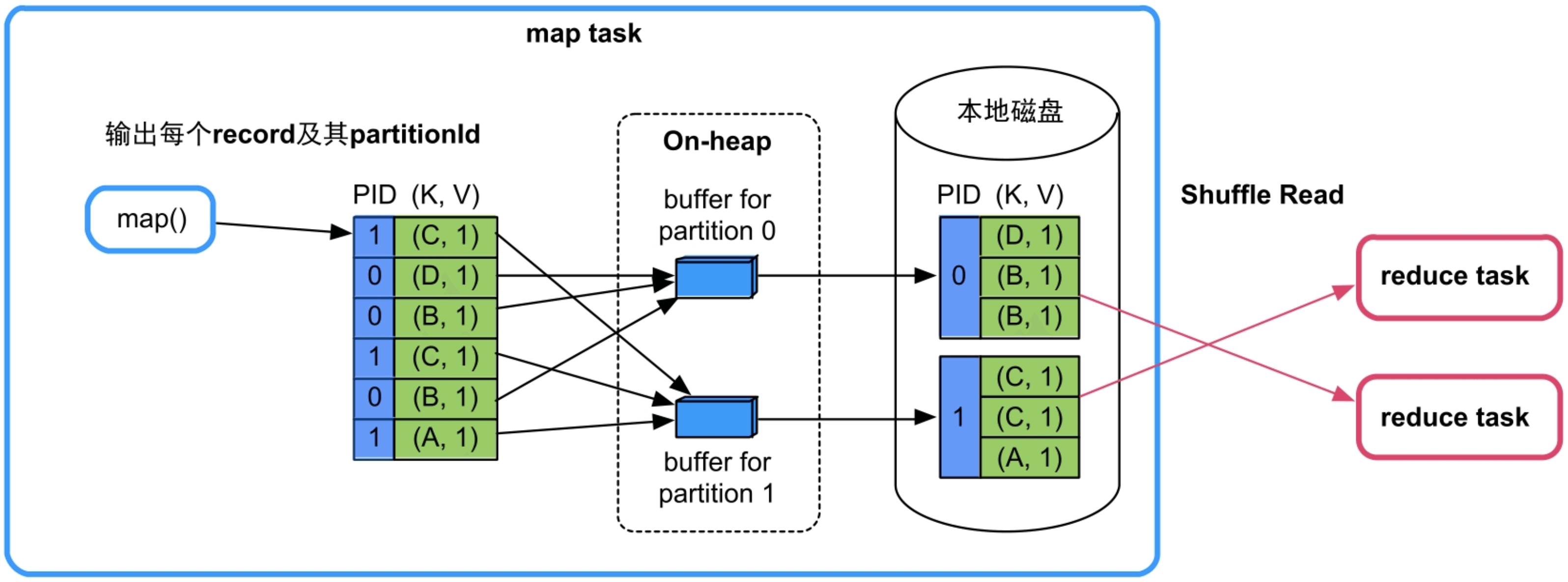
图9.8 不需要map()端聚合、不需要按Key进行排序的Shuffle Write流程(BypassMergeSortShuffleWriter)
_
内存消耗:整个Shuffle Write过程中只有buffer消耗内存,buffer被分配在堆内内存(On-heap)中,buffer的个数与分区个数相等,并且生命周期直至Shuffle Write结束。因此,每个task的内存消耗为BufferSize(默认32KB)×partition number。如果partition个数较多,task数目也较多,那么总的内存消耗会很大。所以,该Shuffle方式只适用于分区个数较小(如小于200)的情况。
(2)不需要map()端聚合,不需要按Key进行排序,且分区个数较大(>200)。
BypassMergeSortShuffleWriter的缺点是,在分区个数太多时buffer内存消耗过大,那么有没有办法降低内存消耗呢?有,可以采用基于数组排序的方法,核心思想是分配一个大的数组,将map()输出的
更具体地,使用Serialized Shuffle的优点包括:
- 序列化后的record占用的内存空间小。
- 不需要连续的内存空间。如图9.9所示,Serialized Shuffle将存储record的数组进行分页,分页可以利用内存碎片,不需要连续的内存空间,而普通数组需要连续的内存空间。
- 排序效率高。对序列化后的record按partitionId进行排序时,排序的不是record本身,而是record序列化后字节数组的指针(元数据)。由于直接基于二进制数据进行操作,所以在这里面没有序列化和反序列化的过程,内存和GC开销降低。
- 可以使用cache-efficient sort等优化技术,提高排序性能。
- 可以使用堆外内存,分页也可以方便统一管理堆内内存和堆外内存。
使用Serialized Shuffle需要满足4个条件:
- 不需要map()端聚合,也不需要按Key进行排序。
- 使用的序列化类(serializer)支持序列化Value的位置互换功能(relocation of serialized Value),目前KryoSerializer和Spark SQL的custom serializers都支持该功能。
- 分区个数小于16 777 216。
- 单个Serialized record小于128MB。
实现方式:前面介绍过Serliazed Shuffle采用了分页技术,像操作系统一样将内存空间划分为Page,每个Page大小在1MB~64MB,既可以在堆内内存上分配,也可以在堆外内存上分配。Page由Executor中的TaskMemoryManager对象来管理,TaskMemoryManager包含一个PageTable,可以最多寻址8192个Page。
如图9.9所示,对于map()输出的每个
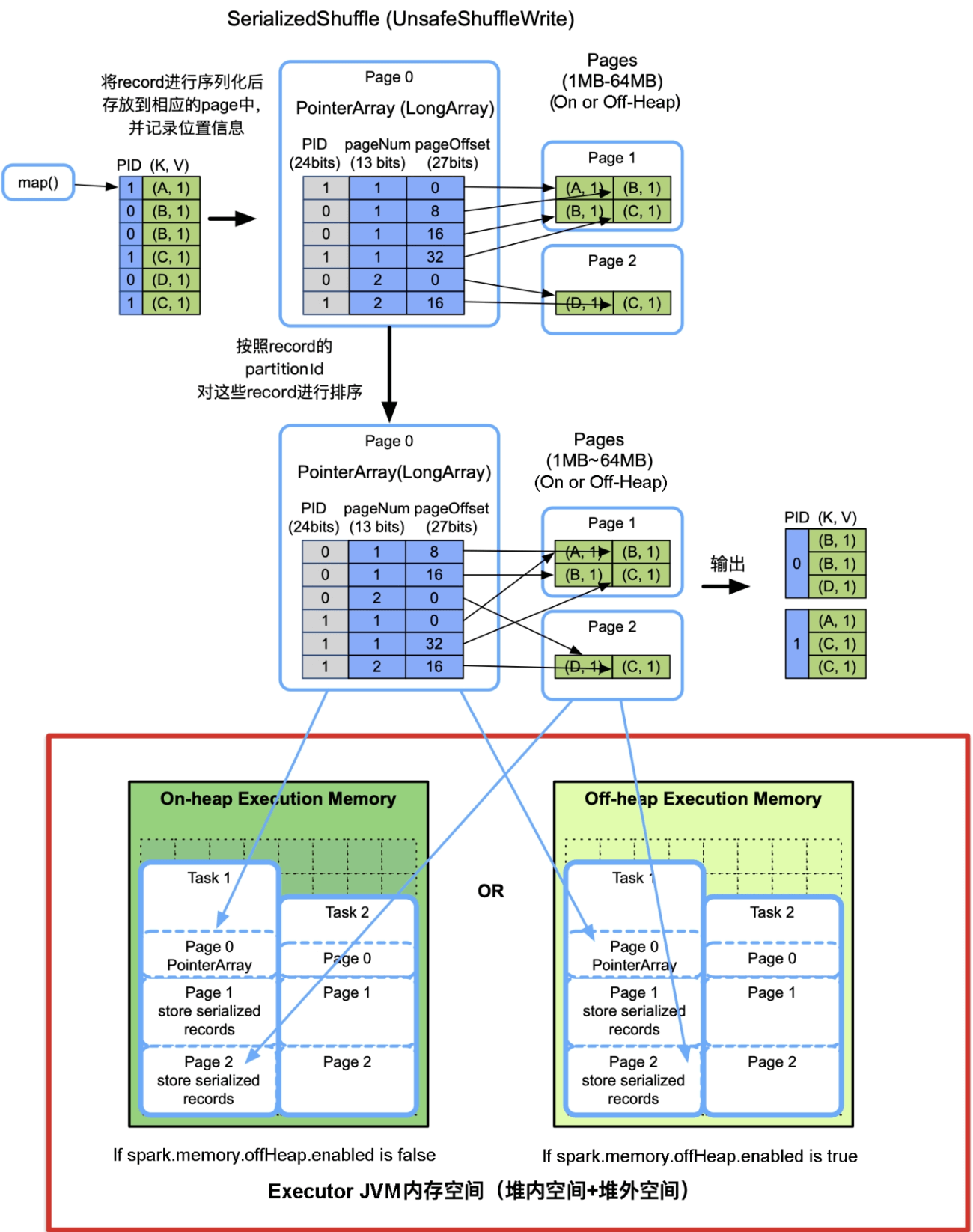
图9.9 不需要聚合、不需要排序的序列化Shuffle Write流程(SerializedShuffleWriter)
当Page总大小达到了task的内存限制时,如Task 1中的Page 0+Page 1+Page 2大小超过Task 1的内存界限,将这些Page中的record按照partitionId进行排序,并spill到磁盘上。这样,在Shuffle Write过程中可能会形成多个spill文件。最后,task将这些spill文件归并即可。
更具体的实现细节:首先将新来的
内存消耗:PointerArray、存储record的Page、sort算法所需的额外空间,总大小不超过task的内存限制。需要注意的是,单个数据结构(如PointerArray、serialized record)不能同时使用堆内内存和堆外内存,因此Serialized Shuffle使用堆外内存最大的问题是,在Shuffle Write时不能同时利用堆内内存和堆外内存,可能会造成更多的spill次数。
(3)不需要map()端combine,但需要排序。
在这种情况下需要按照partitionId+Key进行排序。
如图9.10所示,Spark采用了基于数组的排序方法,名为SortShuffleWriter(KeyOrdering=true)。具体方法是建立一个Array (图9.10中的PartitionedPairBuffer)来存放map()输出的record,并对Array中元素的Key进行精心设计,将每个
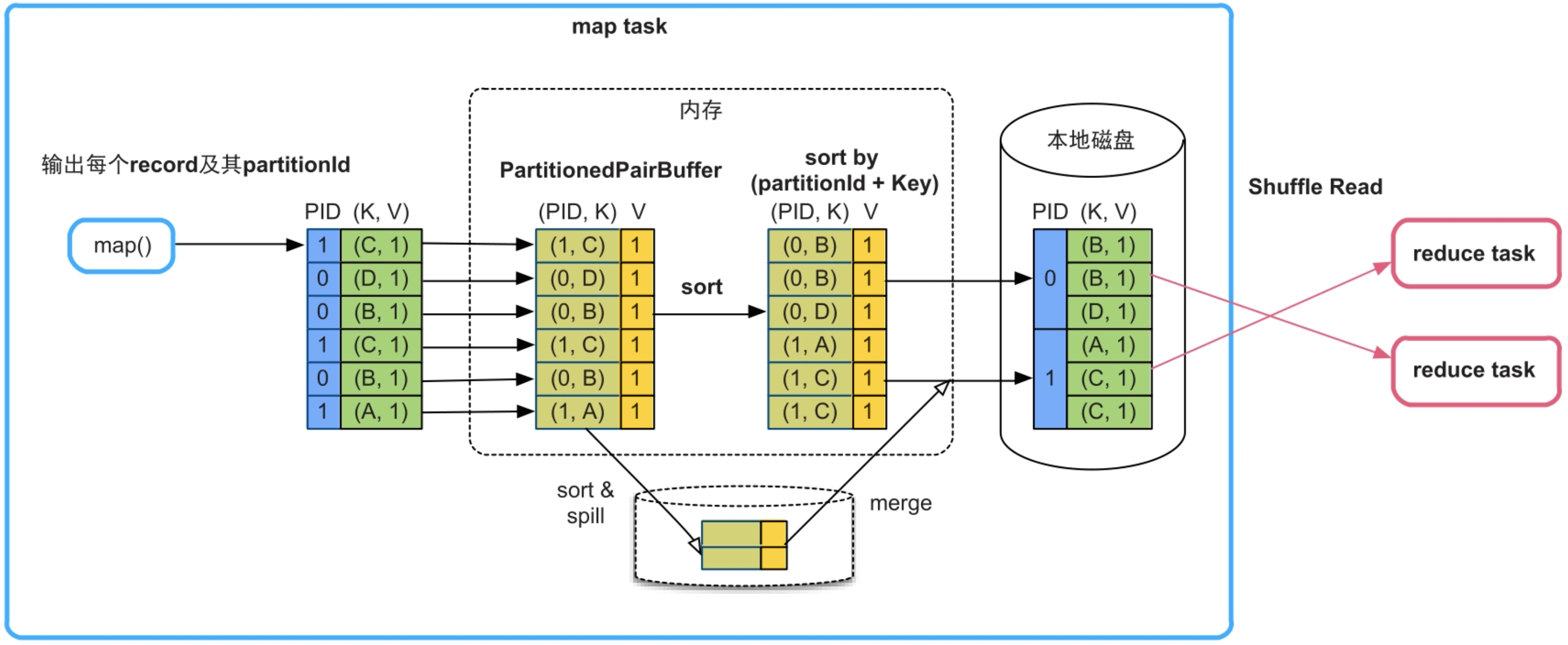
图9.10 不需要map()端combine,需要排序的Shuffle Write流程SortShuffleWriter(KeyOrdering=true)
如果Array存放不下,就会先扩容,如果还存放不下,就将Array中的元素排序后spill到磁盘上,等待map()输出完以后,再将Array中的元素与磁盘上已排序的record进行全局排序,得到最终有序的record,并写入文件中。
内存消耗:最大的内存消耗是存储record的数组PartitionedPairBuffer,占用堆内内存,具有扩容能力,但大小不超过task的内存限制。
(4)需要map()端聚合,需要或者不需要按Key进行排序。
在这种情况下,如图9.11的上图所示,Spark采用基于HashMap的聚合方法,具体实现方法是建立一个类似HashMap的数据结构PartitionedAppendOnlyMap对map()输出的record进行聚合,HashMap中的Key是“partitionId+Key”,HashMap中的Value是经过相同combine()的聚合结果。如果不需要按Key进行排序,则只根据partitionId进行排序,如图9.11中的上图所示;如果需要按Key进行排序,那么根据partitionId+Key进行排序,如图9.11中的下图所示。最后,将排序后的record写入一个分区文件中。
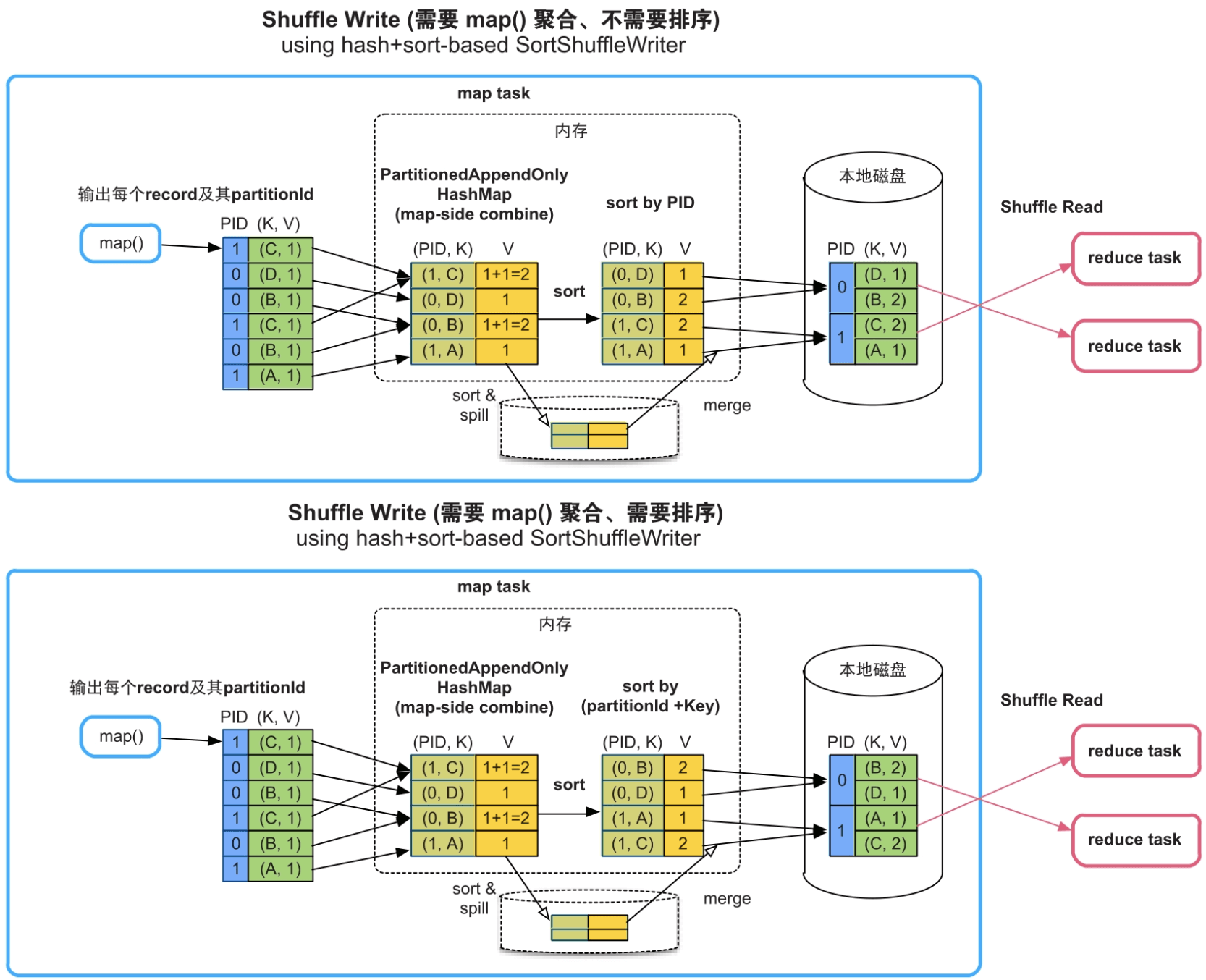
图9.11 需要map()端聚合,需要或不需要排序的Shuffle Write流程SortShuffleWriter (mapSideCombine=true)
内存消耗:HashMap在堆内分配,需要消耗大量内存。如果HashMap存放不下,则会先扩容为两倍大小,如果还存放不下,就将HashMap中的record排序后spill到磁盘上。放入堆内HashMap或buffer中的record大小,如果超过task的内存限制,那么会spill到磁盘上。该Shuffle方式的优点是通用性强、对分区个数也无限制,缺点是内存消耗高(record是普通Java对象)、不能使用堆外内存。
9.4.2 Shuffle Read阶段内存消耗及管理
Spark为了支持所有的情况,设计了一个通用的Shuffle Read框架,框架的计算顺序为“数据获取→聚合→排序”。
根据Shuffle Read端是否需要聚合(Aggregate),是否需要按Key进行排序,将Shuffle Read方式分为3种:
- 无聚合且无排序的情况:采用基于buffer获取数据并直接处理的方式,适用的典型操作如partitionBy()。
- 无聚合但需要排序的情况:采用基于数组排序的方式,适用的典型操作如sortByKey()。
- 有聚合的情况:采用基于HashMap聚合的方式,适用的典型操作如reduceByKey()。这3种方式都是利用堆内内存来完成数据处理的,属于UnSerialized Shuffle方式。

图9.12 不同的Shuffle Read方式及特点
_
由于第一种情况“无聚合且无排序”的内存消耗非常简单,只包含一个大小为spark.reducer.maxSizeInFlight=48MB的缓冲区,我们主要讨论后两种情况的内存消耗。
(1)无聚合但需要排序的情况
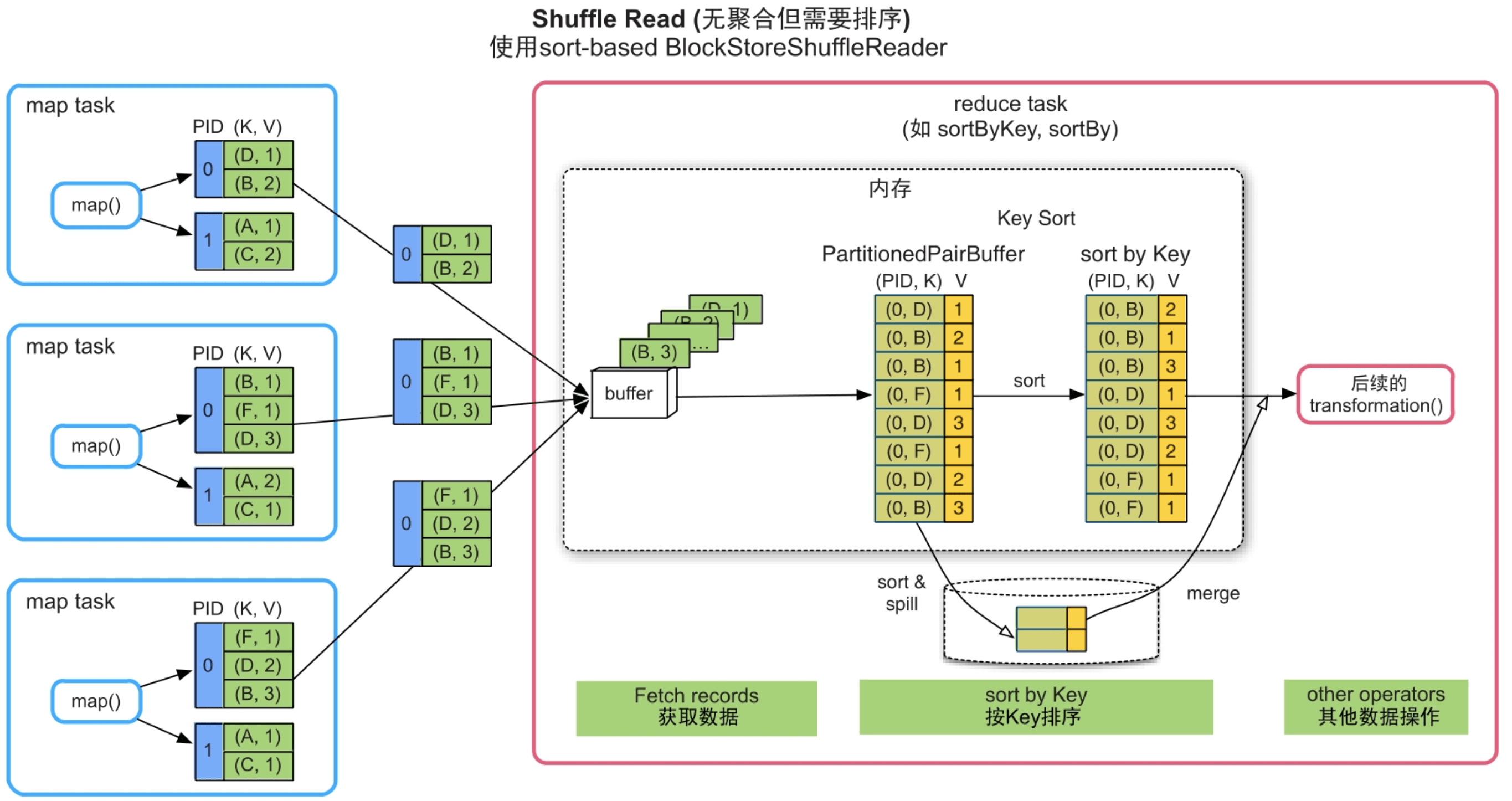
图9.13 无聚合但需要排序的Shuffle Read流程
内存消耗:由于Shuffle Read端获取的是各个上游task的输出数据,因此需要较大的Array(PartitionedPairBuffer)来存储和排序这些数据。Array大小可控,具有扩容和spill到磁盘上的功能,并在堆内分配。
(2)有聚合的情况
Spark采用基于HashMap的聚合方法和基于数组的排序方法。
如图9.13的上图所示,获取record后,Spark建立一个类似HashMap的数据结构(ExternalAppendOnlyMap)对buffer中的record进行聚合,HashMap中的Key是record中的Key,HashMap中的Value是具有相同Key的record经过聚合函数(func)计算后的结果。由于ExternalAppendOnlyMap底层实现是基于数组来存放
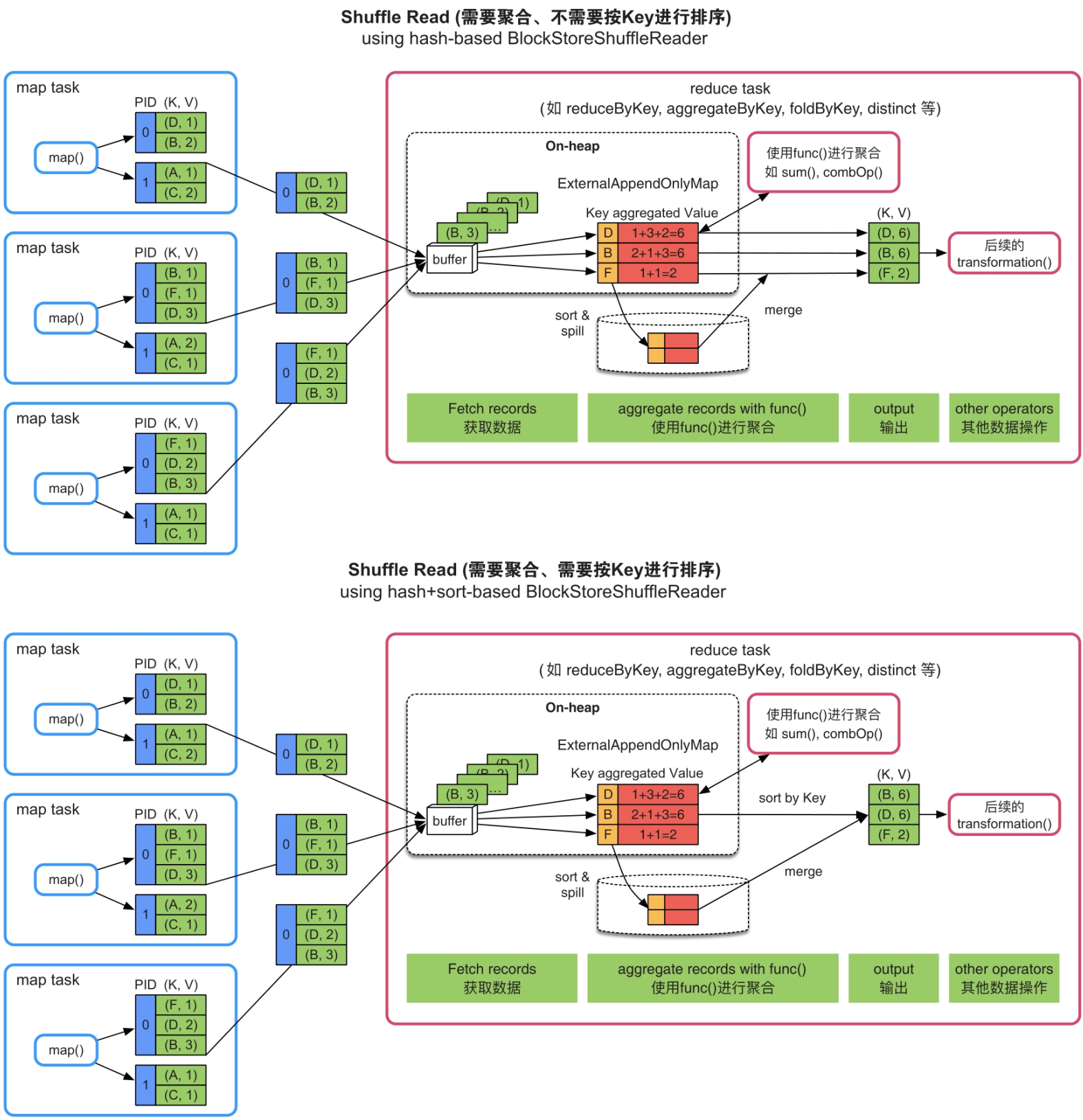
图9.13 需要聚合,不需要或需要按Key进行排序的Shuffle Read流程
内存消耗:由于Shuffle Read端获取的是各个上游task的输出数据,用于数据聚合的HashMap结构会消耗大量内存,而且只能使用堆内内存。当然,HashMap的内存消耗量也与record中不同Key的个数及聚合函数的复杂度相关。HashMap 具有扩容和spill到磁盘上的功能,支持小规模到大规模数据的聚合。
9.5 数据缓存空间管理
如图9.14所示,数据缓存空间主要用于存放3种数据:RDD缓存数据(RDD partition)、广播数据(Broadcast data),以及task的计算结果(TaskResult)。另外,还有几种临时空间,如用于反序列化(展开iterator为Array[])的临时空间、用于存放Netty网络数据传输的临时空间等。
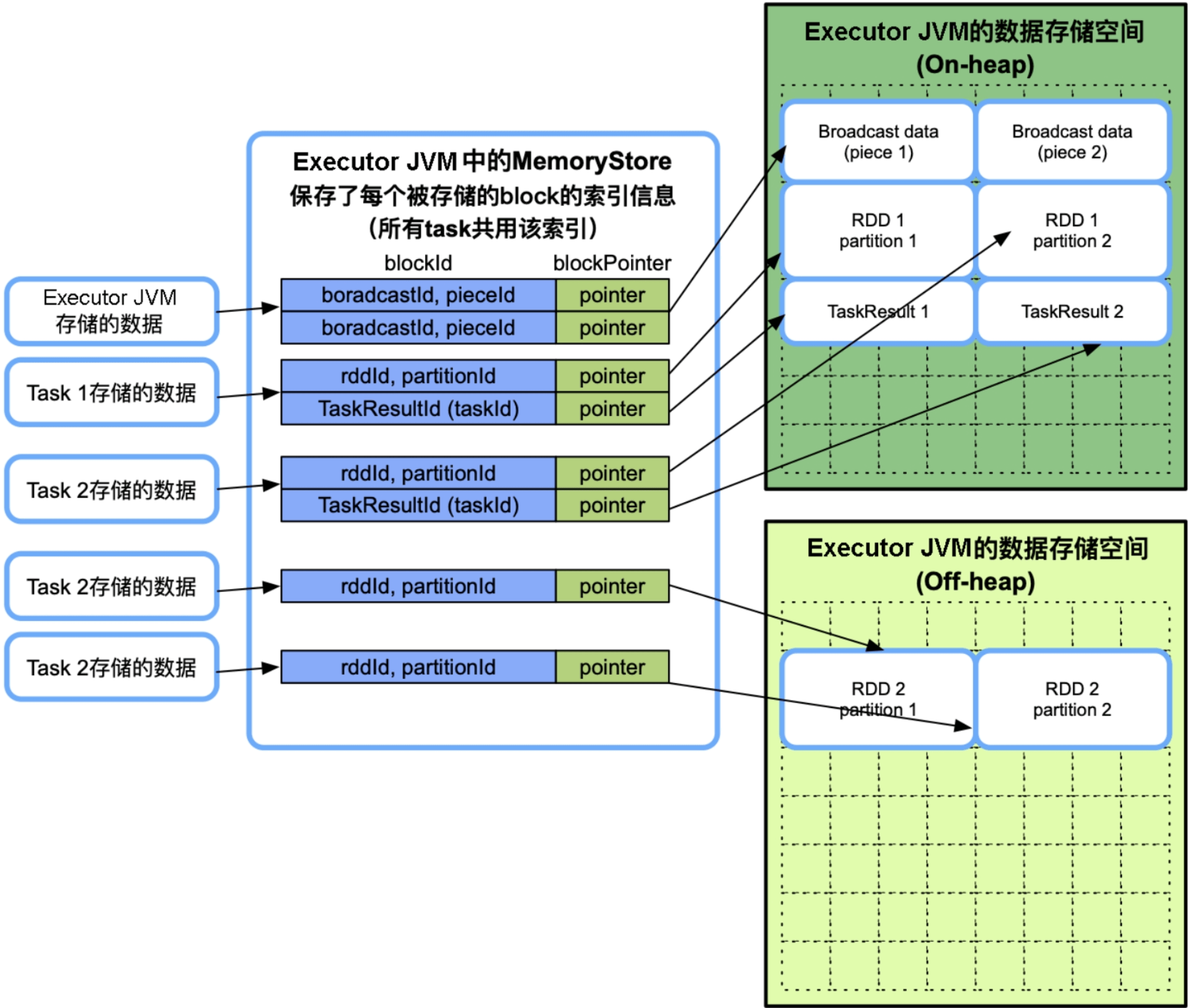
图9.14 Storage Memory模型及可以缓存的数据
_
与框架执行内存空间一样,数据缓存空间也可以同时存放在堆内和堆外,而且由task共享。不同的是,每个task的存储空间并没有被限制为1/N。在缓存时如果发现数据缓存空间不够,且不能从框架执行内存空间借用空间时,就只能采取缓存替换或者直接丢掉数据的方式,缓存替换方式在前面已经详细介绍,这里主要讨论缓存数据的内存消耗问题。
9.5.1 RDD缓存数据
(1)MEMORY_ONLY/MEMROY_AND_DISK模式
实现方式:如图9.15所示,蓝色的MapPartitionsRDD是需要被缓存的数据,task在计算该RDD partition的过程中会将该partition缓存到Executor的memoryStore中,可以认为memoryStore代表了堆内的数据缓存空间。在前面介绍过,memoryStore持有一个链表(LinkedHashMap)来存储和管理缓存的RDD partition。如图9.15所示,在链表中,Key的形式是(rddId=m,partitionId=n),表示其Value存储的数据来自RDD m的第n个分区;Value是该partition的引用,引用指向一个名为DeserializedMemoryEntry的对象。该对象包含一个Vector,里面存放了partition中的record。由于缓存级别没有被设置为序列化存储,这些record以普通Java对象的方式存放在Vector中。需要注意的是,一个Executor中可能同时运行多个task,因此,链表被多个task共用,即数据缓存空间由多个task共享。
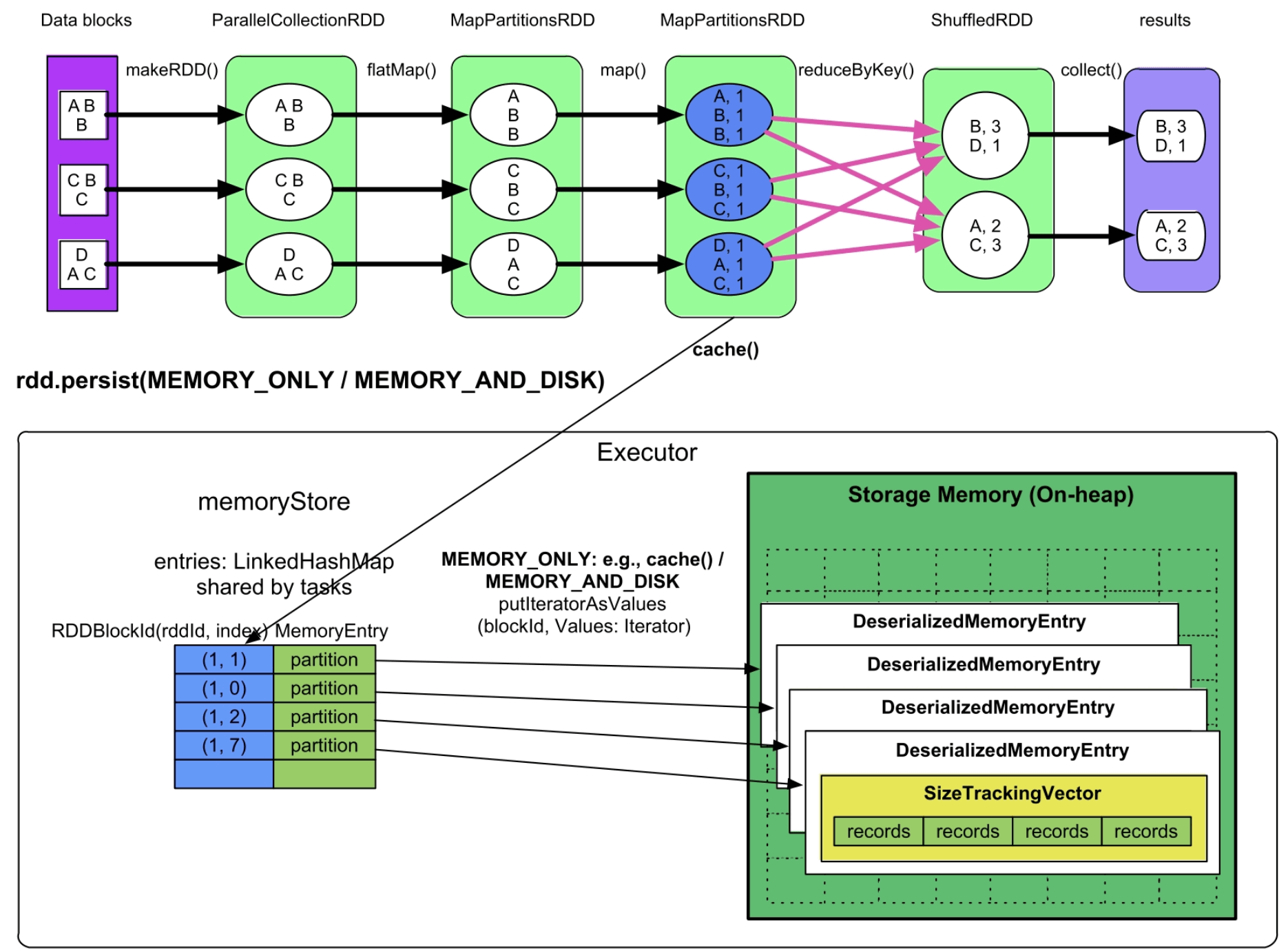
图9.15 MEMORY_ONLY和MEMORY_AND_DISK缓存模式的内存使用情况
内存消耗:数据缓存空间的内存消耗由存放到其中的RDD record大小决定,即等于所有task缓存的RDD partition的record总大小。
(2)MEMORY_ONLY_SER/MEMORY_AND_DISK_SER模式
实现方式:与MEMORY_ONLY的实现方式基本相同,唯一不同是,这里的partition中的record以序列化的方式存储在一个ChunkedByteBuffer(不连续的ByteBuffer数组)中,如图9.16所示。使用不连续的ByteBuffer数组的目的是方便分配和回收,因为如果record非常多,序列化后就需要一个非常大的数组来存储,而此时的内存空间如果没有连续的一大块空间,就无法存储。在之前的MEMORY_ONLY模式中不存在这个问题,因为单个普通Java对象可以存放在内存中的任意位置。
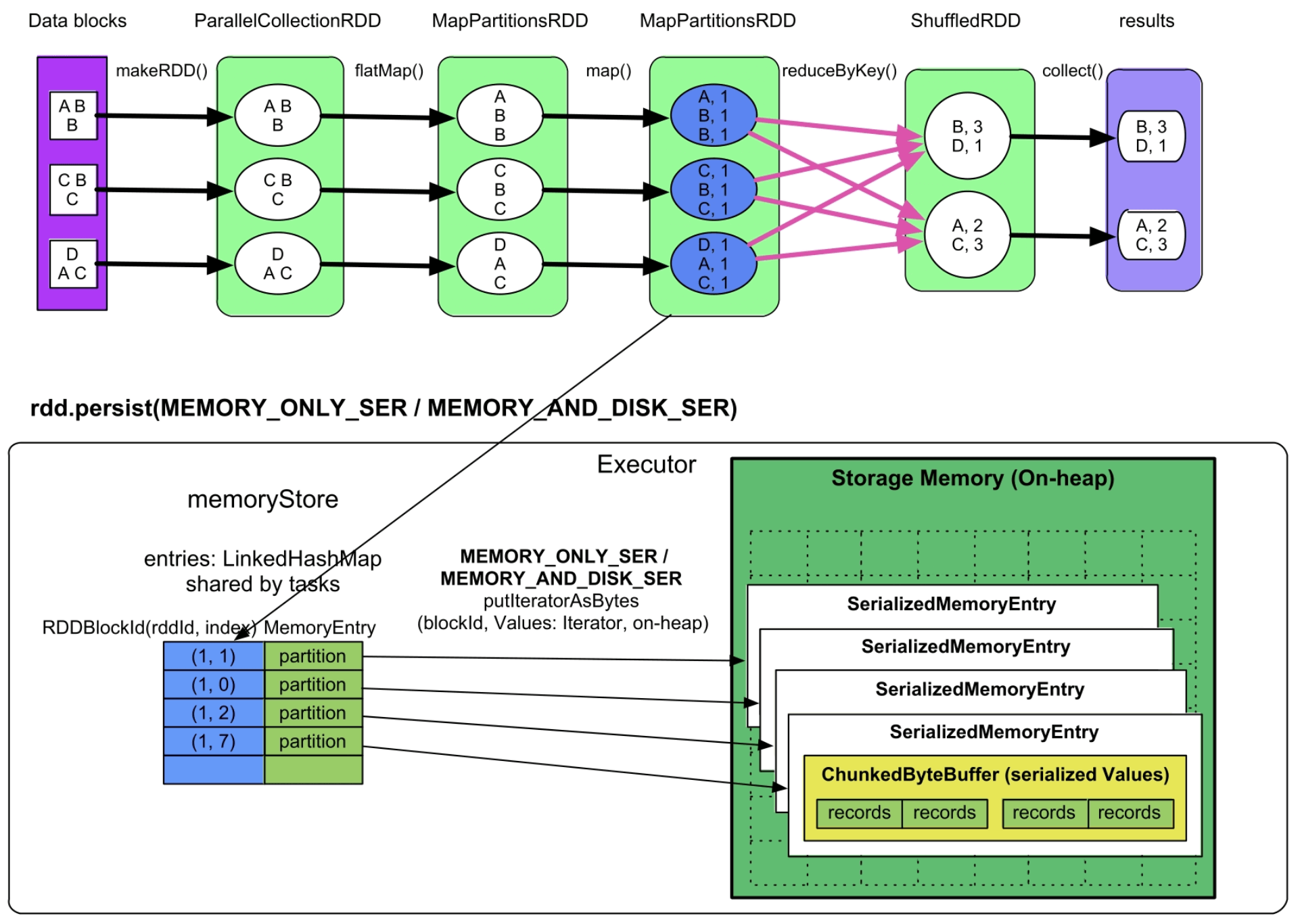
图9.16 MEMORY_ONLY_ONLY和MEMORY_AND_Disk_SER序列化缓存模式
_
内存消耗:由存储的record总大小决定,即等于所有task缓存的RDD partition的record序列化后的总大小。
(3)OFF_HEAP模式
实现方式:如图9.17所示,该缓存模式的存储方式与MEMORY_ONLY_SER/MEMORY_AND_DISK_SER模式基本相同,需要缓存的partition中的record也是以序列化的方式存储在一个ChunkedByteBuffer(不连续的ByteBuffer数组)中的,只是存放位置是堆外内存。
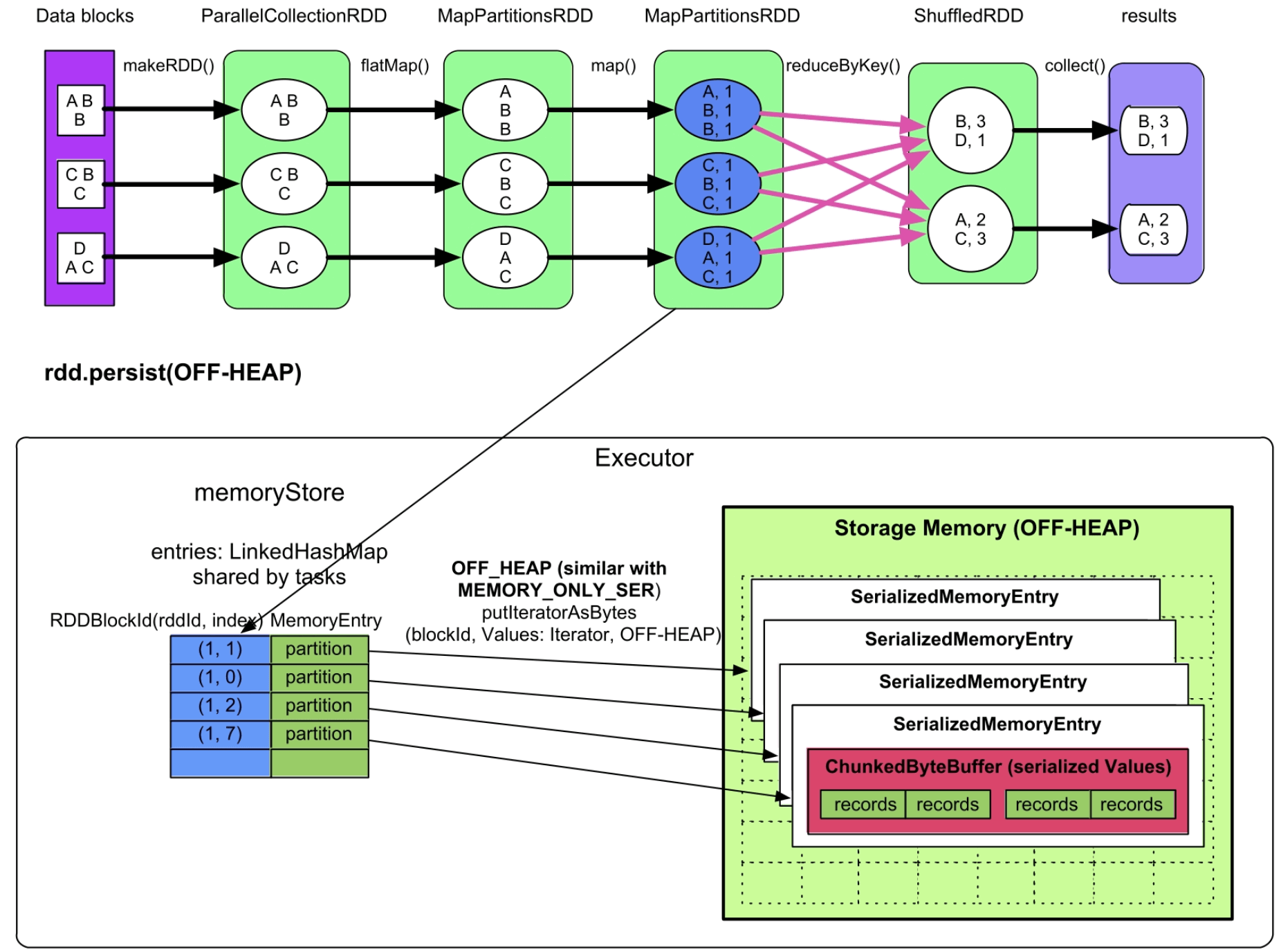
图9.17 OFF-HEAP序列化缓存模式
_
内存消耗:存放到OFF-HEAP中的partition的原始大小。
通过以上分析可以看到,目前堆内内存和堆外内存还是独立使用的,并没有可以同时存放到堆内内存和堆外内存的缓存级别,即堆内内存和堆外内存并没有协作。
9.5.2 广播数据
当map stage中的task都需要一部词典时,可以先将该词典广播给各个Executor,然后每个task从Executor中读取词典,因此广播数据的存储位置是Executor的数据缓存空间。
实现方式:Broadcast默认使用类似BT下载的TorrentBroadcast方式。如图9.18所示,需要广播的数据一般预先存储在Driver端,Spark在Driver端将要广播的数据划分大小为spark.Broadcast.blockSize=4MB的数据块(block),然后赋予每个数据块一个blockId为BroadcastblockId(id,“piece”+i),id表示block的编号,piece表示被划分后的第几个block。之后,使用类似BT的方式将每个block广播到每个Executor中。Executor接收到每个block数据块后,将其放到堆内的数据缓存空间的ChunkedByteBuffer里面,缓存模式为MEMORY_AND_DISK_SER,因此,这里的ChunkedByteBuffer构造与MEMORY_ONLY_SER模式中的一样,都是用不连续的空间来存储序列化数据的。
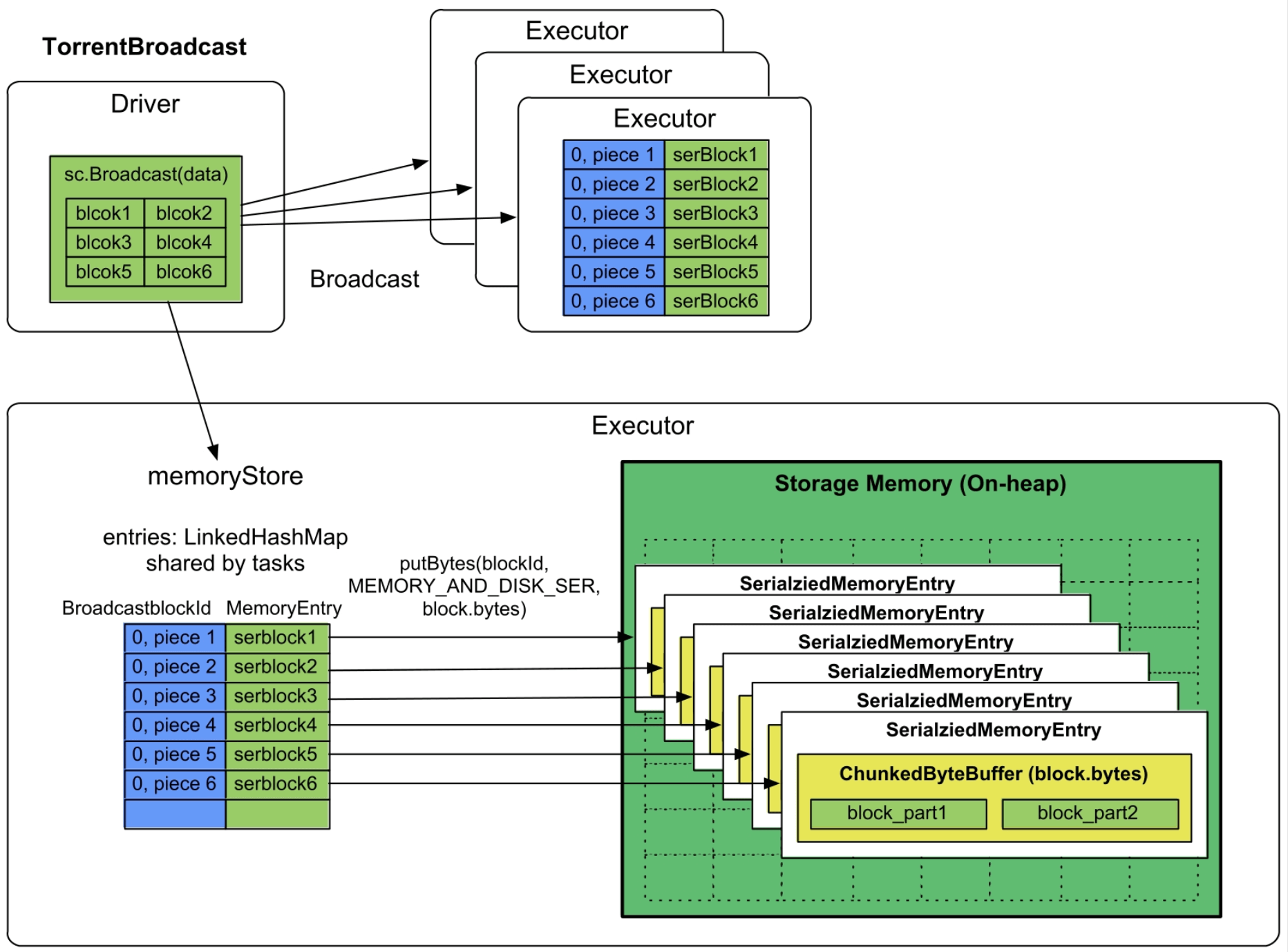
图9.18 对广播数据进行缓存
内存消耗:序列化后的Broadcast block总大小。
内存不足:Broadcast data的存放方式是内存+磁盘,内存不足时放入磁盘。
9.5.3 task的计算结果
许多应用需要在Driver端收集task的计算结果并进行处理,如调用了rdd.collect()的应用。当task的输出结果大小超过spark.task.maxDirectResultSize=1MB且小于1GB时,需要先将每个task的输出结果缓存到执行该task的Executor中,存放模式是MEMORY_AND_DISK_SER,然后Executor将task的输出结果发送到Driver端进一步处理。
如图9.19所示,Driver端需要收集task1和task2的计算结果,那么task1和task2计算得到结果Result1和Result2后,先将其缓存到Executor的数据缓存空间中,缓存级别为MEMORY_AND_DISK_SER,缓存结构仍然采用ChunkedByteBuffer。然后,Executor将Result1和Result2发送到Driver端进行进一步处理。
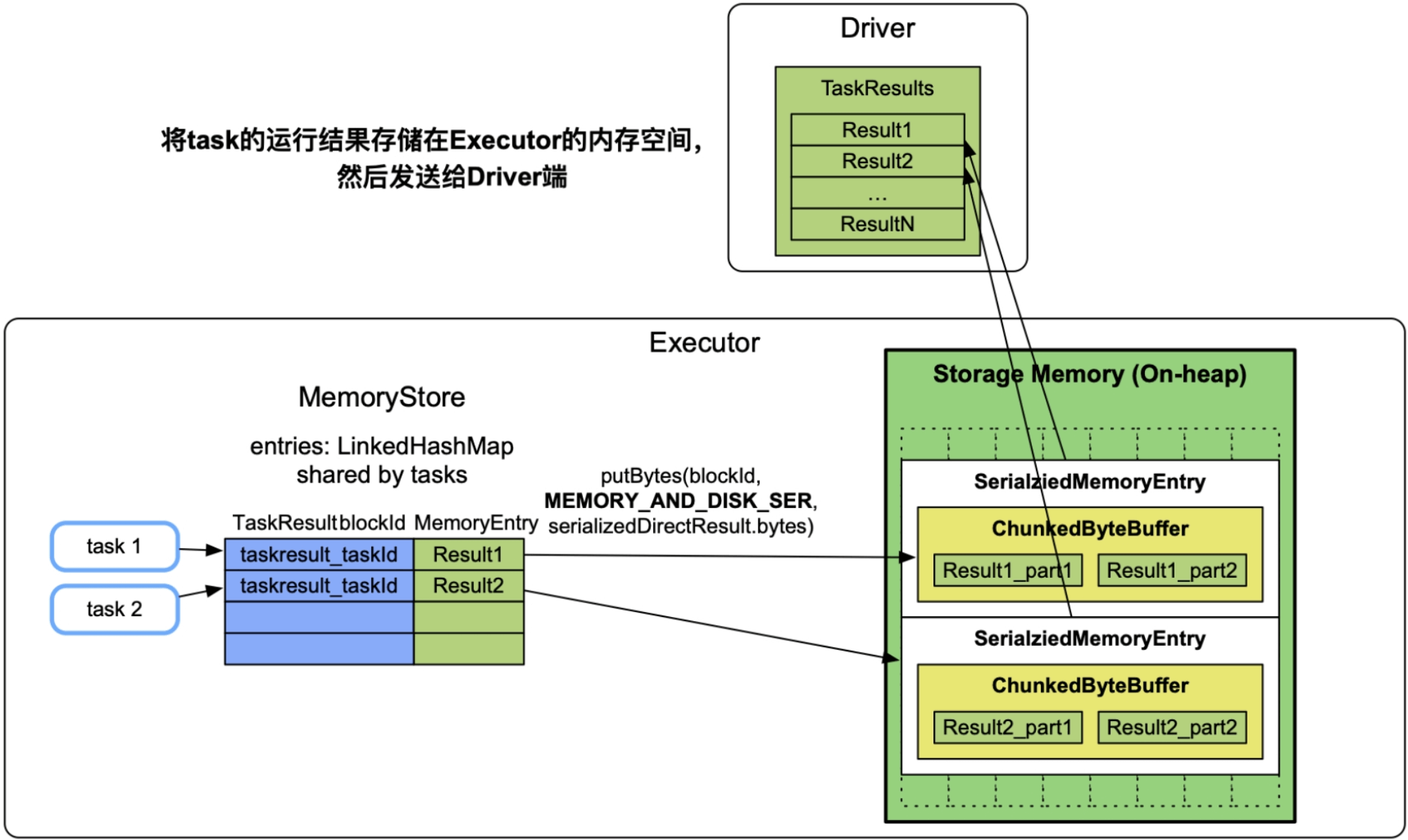
图9.19 对task的计算结果进行缓存
_
内存消耗:序列化后的task输出结果大小,不超过1GB。在Executor中一般运行多个task,如果每个task都占用了1GB以上的话,则会引起Executor的数据缓存空间不足。
内存不足:因为缓存方式是内存+磁盘,所以在内存不足时放入磁盘。
9.6 小结
内存管理方法总结
**
(1)内存消耗来源多种多样,难以统一管理。Spark在运行时的内存消耗主要包括3个方面:Shuffle数据、数据缓存、用户代码运行。由于内存空间有限,如何对这些缓存数据和计算过程中的数据进行统一管理呢?Spark采用的主要方法是将内存划分为3个区域,每个区域分别负责存储和管理一项内存消耗来源。如何平衡数据计算与缓存的内存消耗?Spark采用的统一内存管理模型通过“硬界限+软界限”的方法来限制每个区域的内存消耗,并通过内存共享达到平衡。硬界限指的是Spark将内存分为固定大小的用户代码空间(User memory)和框架内存空间(Framework memory)。软界限指的是框架内存空间(Framework memory)由框架执行空间(Execution memory)和数据缓存空间(Storage memory)共享。如何解决内存空间不足的问题?框架执行空间或者数据缓存空间不足时可以向对方借用,如果还不够,则会采取spill到磁盘上、缓存数据替换、丢弃等方法。
(2)内存消耗动态变化难以预估,为内存分配和回收带来困难。Spark在运行时的内存消耗与多种因素相关,难以预估。用户代码的内存用量与func的计算逻辑、输入数据量有关,也难以预估。而且这些内存消耗来源产生的内存对象的生命周期不同,如何分配大小合适的内存空间,何时对这些对象进行回收?由于内存消耗难以提前估计,Spark采取的方法是边监控边调整,如通过监控Shuffle Write/Read过程中数据结构大小来观察是否达到框架执行空间界限、监控缓存数据大小观察是否达到数据缓存空间界限,如果达到界限,则进行数据结构扩容、空间借用或者将缓存数据移出内存。
(3)task之间共享内存,导致内存竞争。在Spark中,多个task以线程方式运行在同一个Executor JVM中,task之间还存在内存共享和内存竞争,如何平衡内存共享和内存竞争呢?在Spark的统一内存管理模型中,框架执行空间和数据缓存空间都是由并行运行的task共享的,为了平衡task间的内存消耗,Spark采取均分的方法限制每个task的最大使用空间,同时保证task的最小使用空间。
内存管理优化
**
(1)堆内内存和堆外内存管理问题:目前,Spark主要利用堆内内存来进行数据Shuffle和数据缓存,内存消耗高、GC开销大。虽然部分Shuffle方式可以利用堆外内存,但主要适用于无聚合、无排序的场景,而且需要用户自己设定堆外内存大小。使用堆外内存虽然可以降低GC开销,但也有弊端,如应用场景受限,也容易出现内存泄漏等问题。所以,Spark还需要提高堆内内存和堆外内存的利用能力,降低用户负担,提高内存利用率。
(2)存储与计算分离问题:当前,Spark的统一内存管理模型将数据缓存和数据计算都放在一个内存空间中进行,会产生内存竞争问题。实际上,Spark团队已经意识到这个问题,设计实现了分布式内存文件系统Alluxio(之前名为Tachyon)来分离数据存储和数据计算:将数据缓存在Alluxio的内存空间里,而Executor内存空间主要用于用户代码和框架执行Shuffle Write/Read。
(3)更高效的Shuffle方式:在本章中讨论了不同Shuffle Write/Read方式的内存消耗,也讨论了Serialized Shuffle的优势。然而,针对RDD操作,Spark目前只提供了Serialized Shuffle Write方式,没有提供Serialized Shuffle Read方式。实际上,在SparkSQL项目中,Spark利用SQL操作的特点(如SUM、AVG计算结果的等宽性),提供了更多的Serilaized Shuffle方式,直接在序列化的数据上实现聚合等计算,详情可以参考UnsafeFixedWidthAggregationMap、ObjectAggregationMap等数据结构的实现。未来,希望能将这些Serialized Shuffle方式应用在RDD操作上。

若有收获,就点个赞吧
0 人点赞
