2.1 RDD 概述
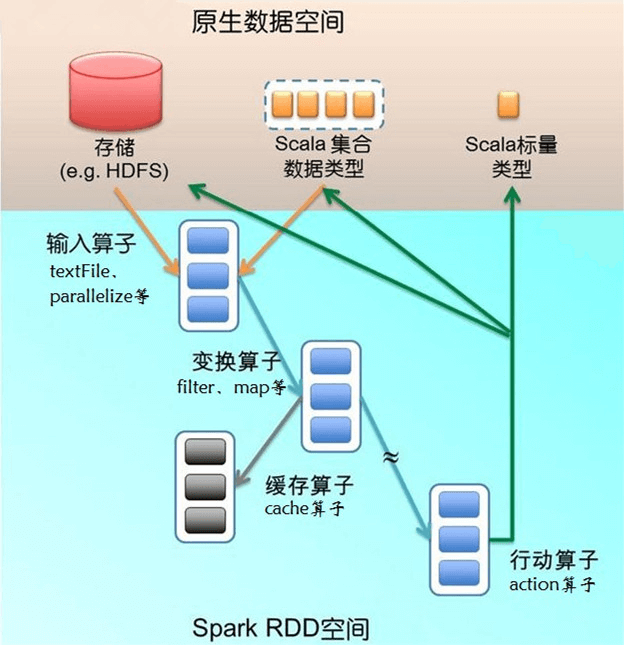
概念:RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,它代表一个不可变、可分区、里面元素可并行计算的集合。Spark 采用惰性计算模式。RDD 一般分为数值 RDD 和键值对 RDD。
属性:
- 一组分片(Partition),即数据集的基本组成单位。
- 一个计算每个分区的函数。
- RDD 之间的依赖关系。
- 一个 Partitioner,即 RDD 的分片函数。
- 一个列表,存储存取每个 Partition 的优先位置(preferred location)。
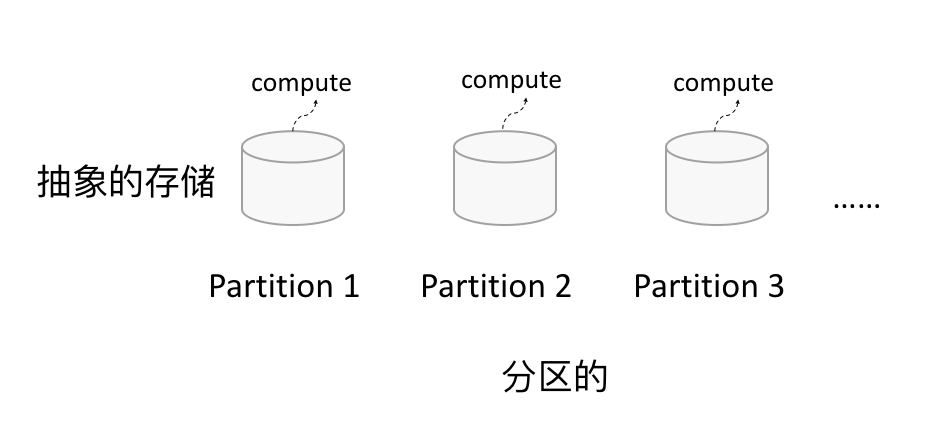
弹性:
- 自动进行内存和磁盘数据存储的切换。
- 基于血统的高效容错机制,在 RDD 进行转换和动作的时候,会形成 RDD 的 Lineage 依赖链。
- Task 如果失败会自动进行特定次数的重试。
- Stage 如果失败会自动进行特定次数的重试。
- Checkpoint 和 Persist 可主动或被动触发。
- 数据调度弹性,Spark 把这个 JOB 执行模型抽象为通用的有向无环图 DAG,可以将多 Stage 的任务串联或并行执行,调度引擎自动处理 Stage 的失败以及 Task 的失败。
- 数据分片的高度弹性,可以根据业务的特征,动态调整数据分片的个数,提升整体的应用执行效率。
特点:
- 分区:RDD 逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个 compute 函数得到每个分区的数据。如果 RDD 是通过已有的文件系统构建,则 compute 函数是读取指定文件系统中的数据,如果 RDD 是通过其他 RDD 转换而来,则 compute 函数是执行转换逻辑将其他 RDD 的数据进行转换。
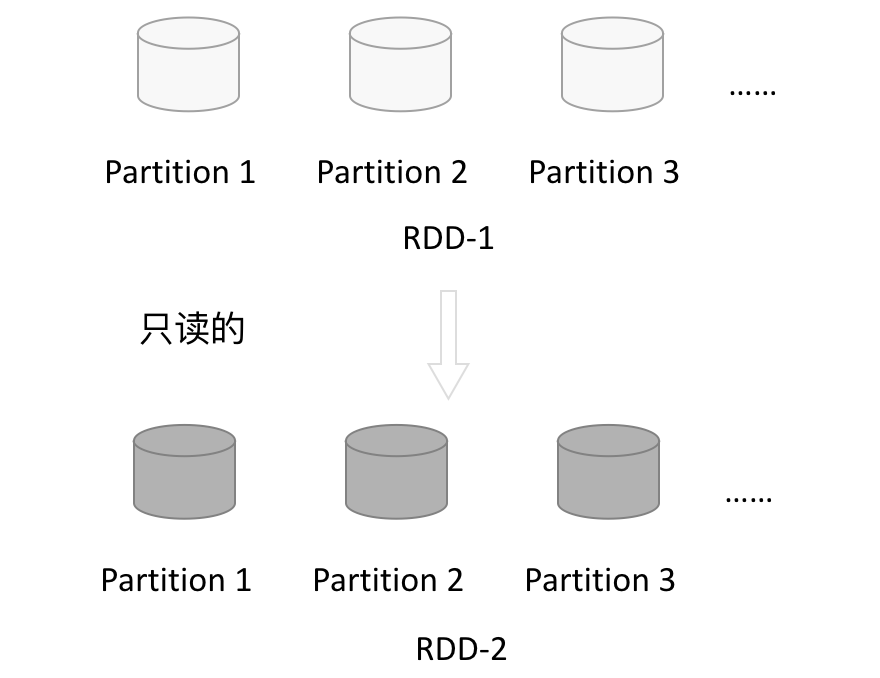
- 只读:RDD 是只读的,要想改变 RDD 中的数据,只能在现有的 RDD 基础上创建新的 RDD。
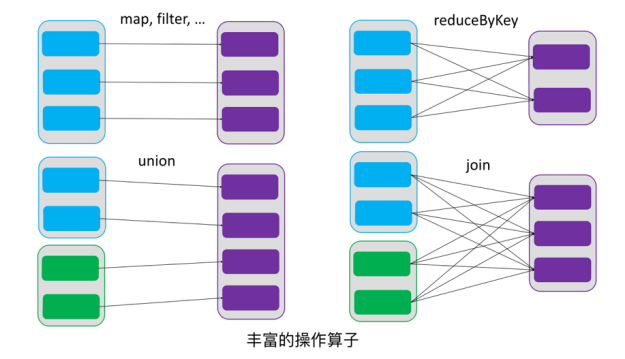
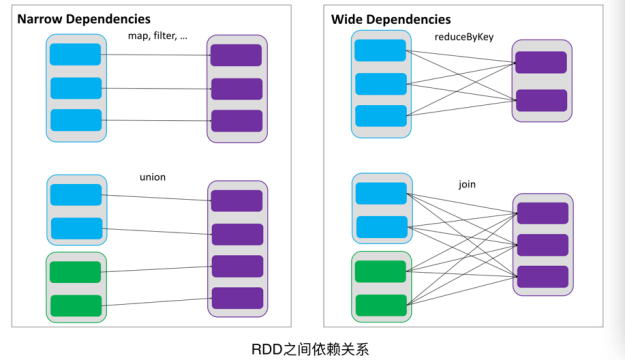
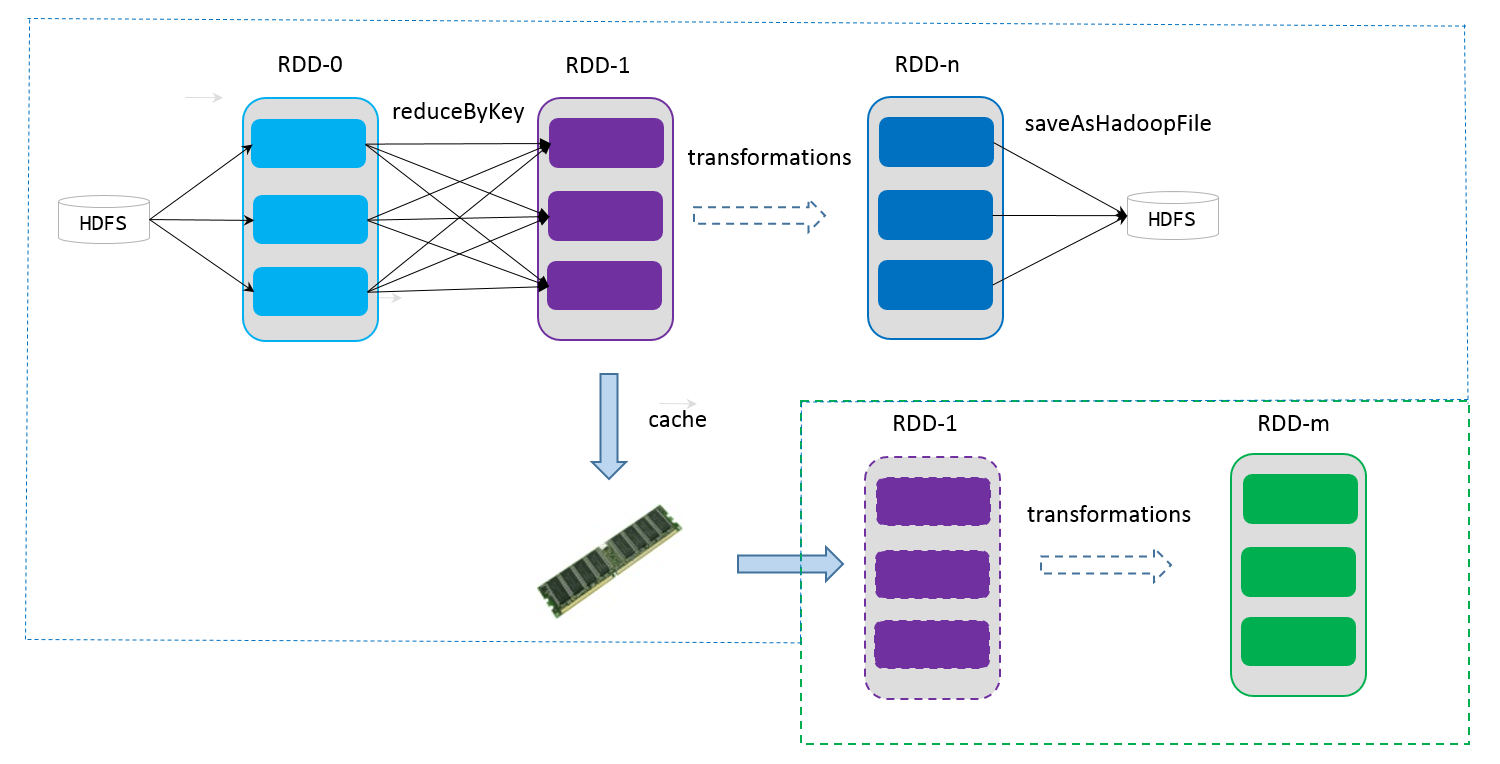
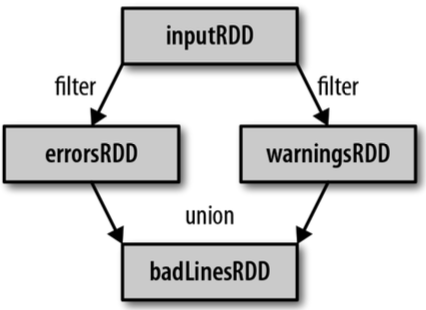
- 依赖:RDDs 通过操作算子进行转换,转换得到的新 RDD 包含了从其他 RDDs 衍生所必需的信息,RDDs 之间维护着这种血缘关系,也称之为依赖。窄依赖,RDDs之间分区是一一对应的;另一种是宽依赖,宽依赖,下游 RDD 的每个分区与上游 RDD (也称之为父 RDD)的每个分区都有关,是多对多的关系。RDDs 之间这种依赖关系,一个任务流可以描述为 DAG,宽依赖对应于 Shuffle (下图中的 reduceByKey 和 join),窄依赖中的所有转换操作可以通过类似于管道的方式一气呵成执行(下图中 map 和 union 可以一起执行)。
- 缓存:如果在应用程序中多次使用同一个 RDD,可以将该 RDD 缓存起来,后面使用会直接从缓存处取而不用再根据血缘关系计算。
- checkpoint:RDD 支持 checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关系。

2.2 RDD 编程
2.2.1 编程模型
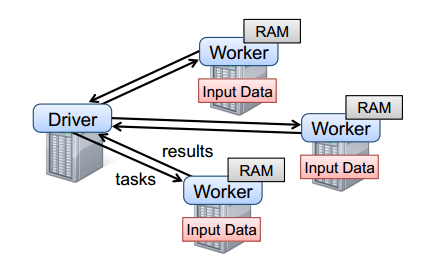
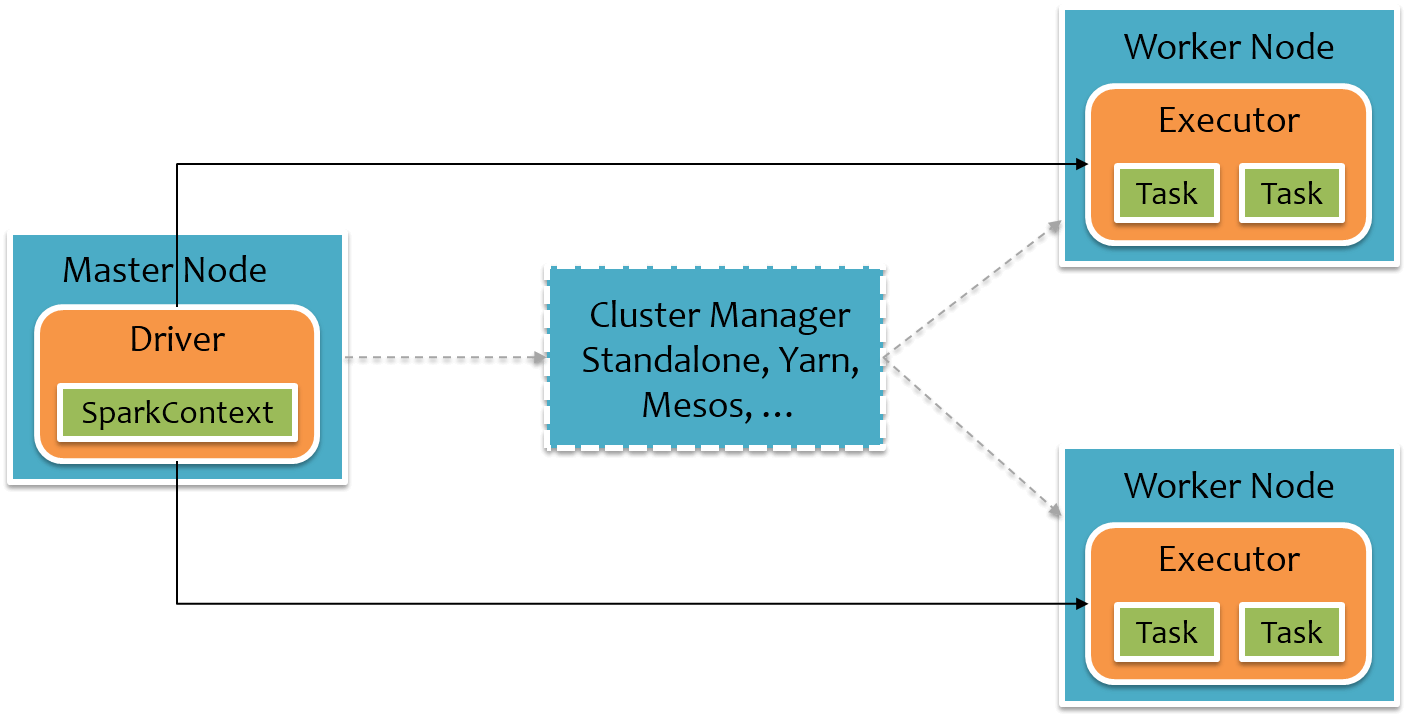
在 Spark 中,RDD 被表示为对象,通过对象上的方法调用来对 RDD 进行转换。要使用 Spark,开发者需要编写一个 Driver 程序,它被提交到集群以调度运行 Worker,如下图所示。Driver 中定义了一个或多个 RDD,并调用 RDD 上的 action,Worker 则执行 RDD 分区计算任务。
2.2.2 创建 RDD
在 Spark 中创建 RDD 的创建方式大概可以分为三种:
- 从集合中创建 RDD:集合中创建 RDD,parallelize 和 makeRDD。parallelize 函数可以自己指定分区的数量,而 makeRDD 函数固定为 seq 参数的 size 大小。当调用
parallelize()方法的时候,不指定分区数的时候,使用系统给出的分区数,而调用**makeRDD()**方法的时候,会为每个集合对象创建最佳分区,而这对后续的调用优化很有帮助。 - 从外部存储创建 RDD:由外部存储系统的数据集创建,textFile。包括本地的文件系统,还有所有 Hadoop 支持的数据集,如 HDFS、Cassandra、HBase 等。
- 从其他 RDD 创建:通过转换和行动操作得到新的 RDD。
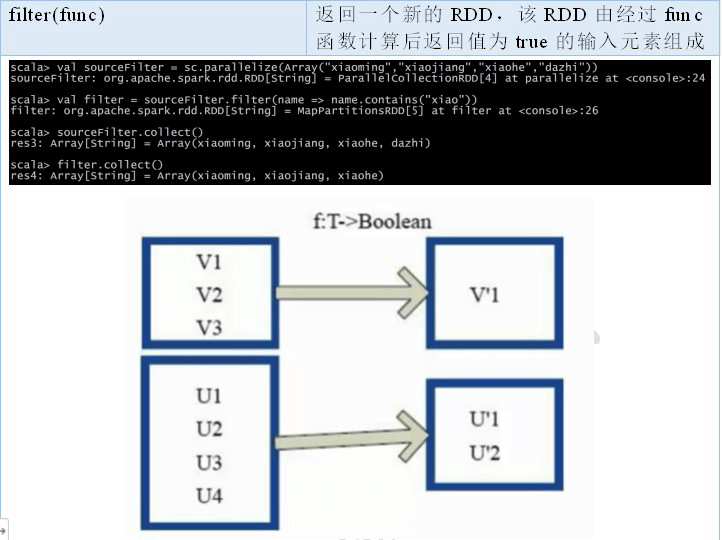
2.2.3 RDD 之 Transformation

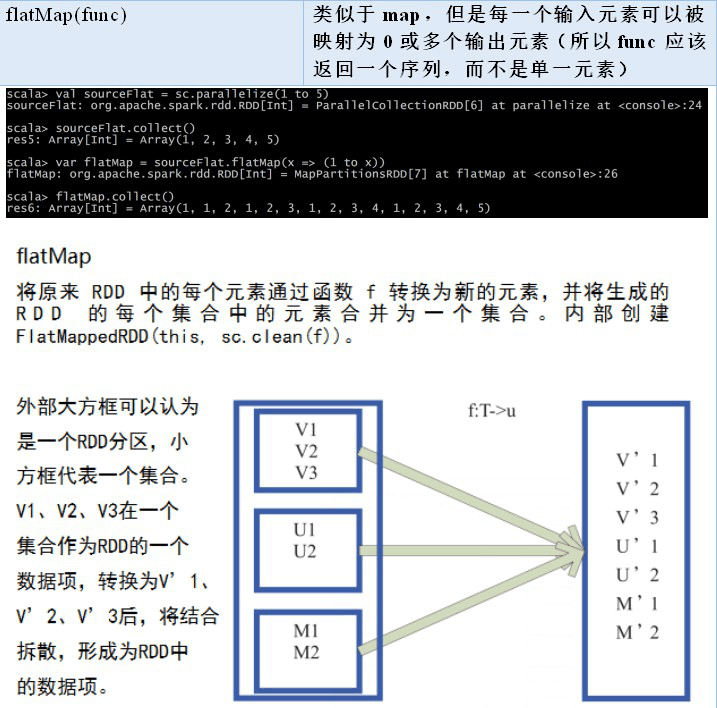

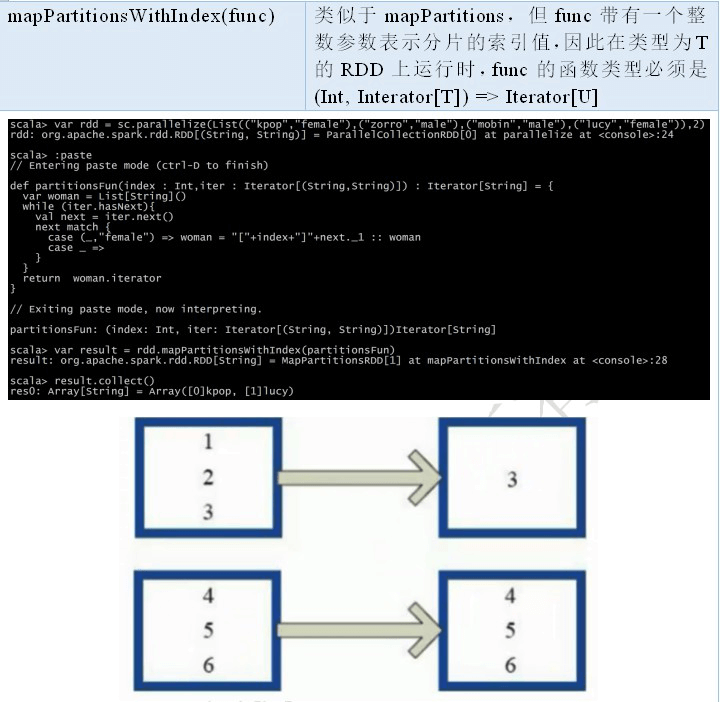
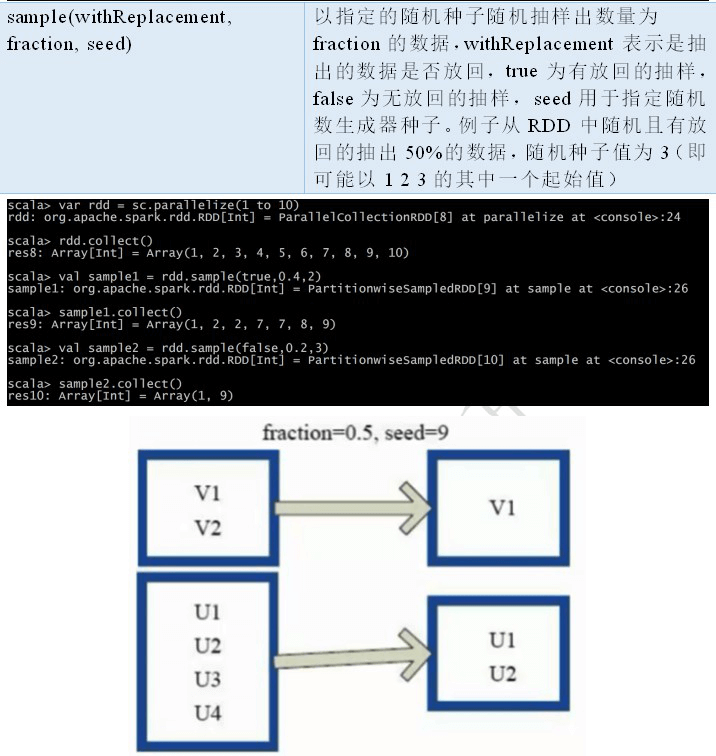
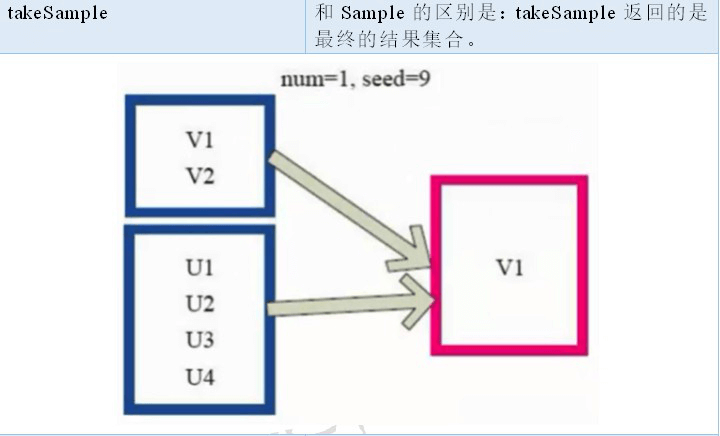




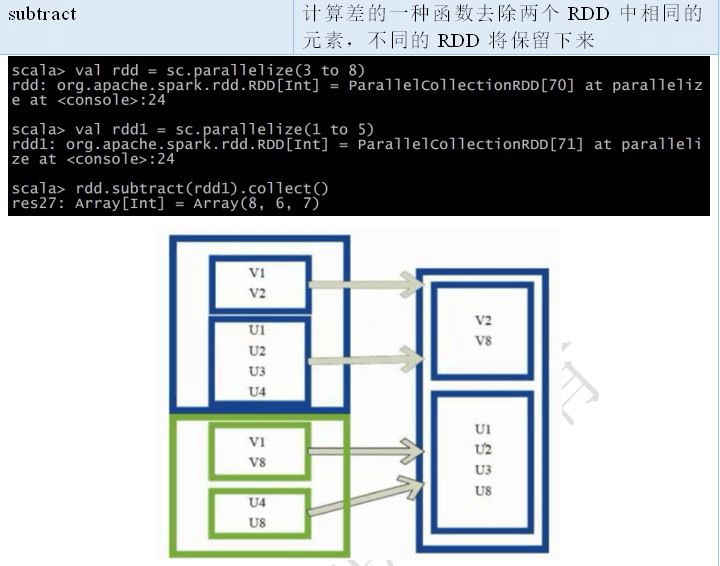
2.2.4 RDD 之 Action
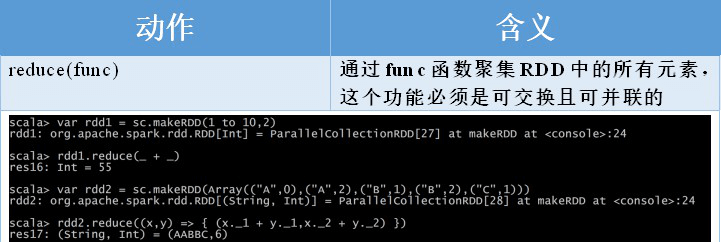
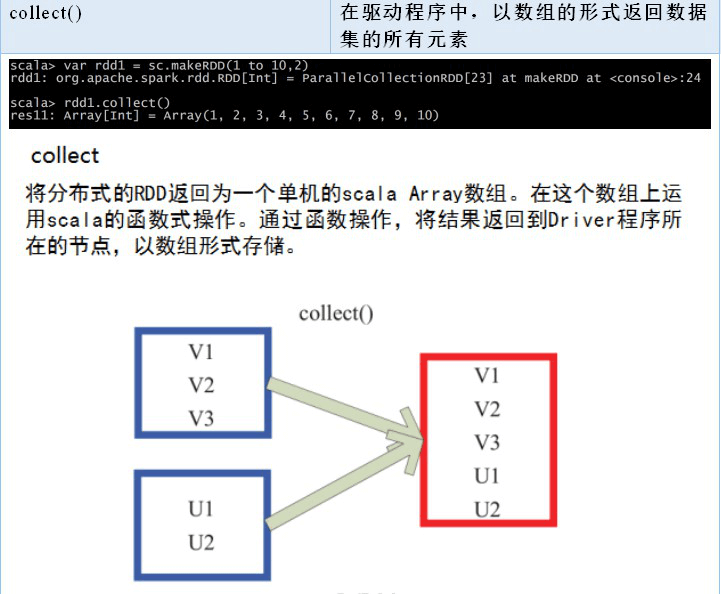




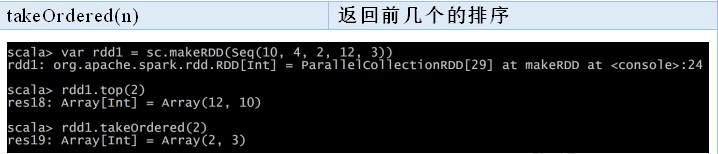
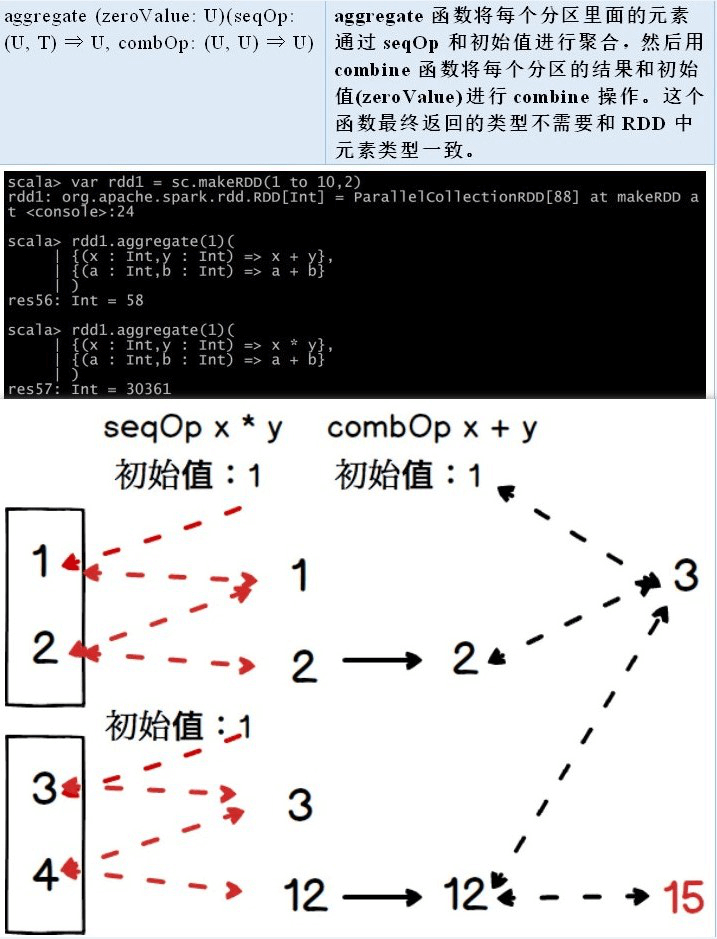
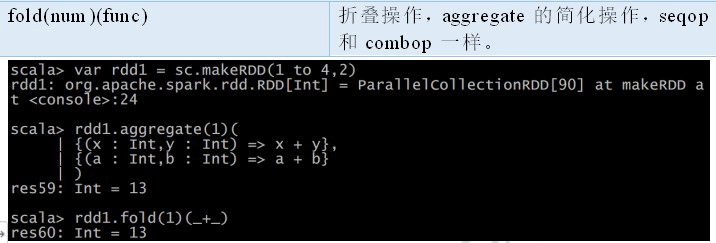

2.2.5 数值 RDD 的统计操作

2.2.6 向 RDD 操作传递函数注意
传递的函数及其引用的数据需要是可序列化的(实现了 Java 的 Serializable 接口)。 传递一个对象的方法或者字段时,会包含对整个对象的引用。
2.2.7 在不同 RDD 类型间转换
有些函数只能用于特定类型的 RDD,比如 mean() 和 variance() 只能用在数值 RDD 上, 而 join() 只能用在键值对 RDD 上。在 Scala 中,将 RDD 转为有特定函数的 RDD(比如在 RDD[Double] 上进行数值操作)是由隐式转换来自动处理的。
2.3 RDD 持久化
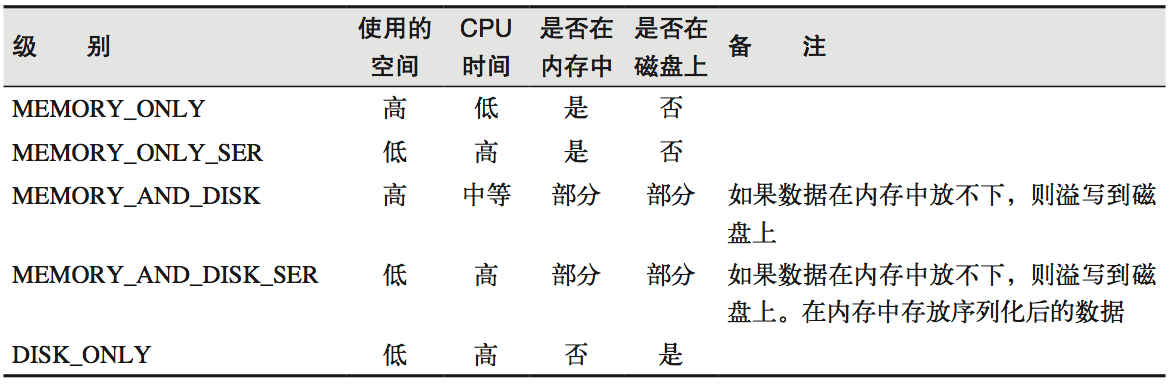
cache 和 persist。cache 最终也是调用了 persist 方法,默认的存储级别都是仅在内存存储一份,在存储级别的末尾加上“_2”来把持久化数据存为两份。

2.4 RDD 检查点机制
检查点 checkpoint 概述
检查点(本质是通过将 RDD 写入 Disk 做检查点)是为了通过 lineage 做容错的辅助,lineage 过长会造成容错成本过高。如果之后有节点出现问题而丢失分区,从做检查点的 RDD 开始重做 Lineage,就会减少开销。检查点通过将数据写入到 HDFS 文件系统实现了 RDD 的检查点功能。
cache 和 checkpoint 区别
缓存把 RDD 计算出来然后放在内存中,但是 RDD 的依赖链(相当于数据库中的redo 日志), 也不能丢掉, 当某个点某个 executor 宕了,上面 cache 的 RDD 就会丢掉, 需要通过依赖链重放计算出来。不同的是, checkpoint 是把 RDD 保存在 HDFS 中, 是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链, 是通过复制实现的高容错。
使用场景
DAG 中的 Lineage 过长,如果重算,则开销太大(如在PageRank中)。在宽依赖上做 Checkpoint 获得的收益更大。
配置
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用**SparkContext.setCheckpointDir()**设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
checkpoint 写流程
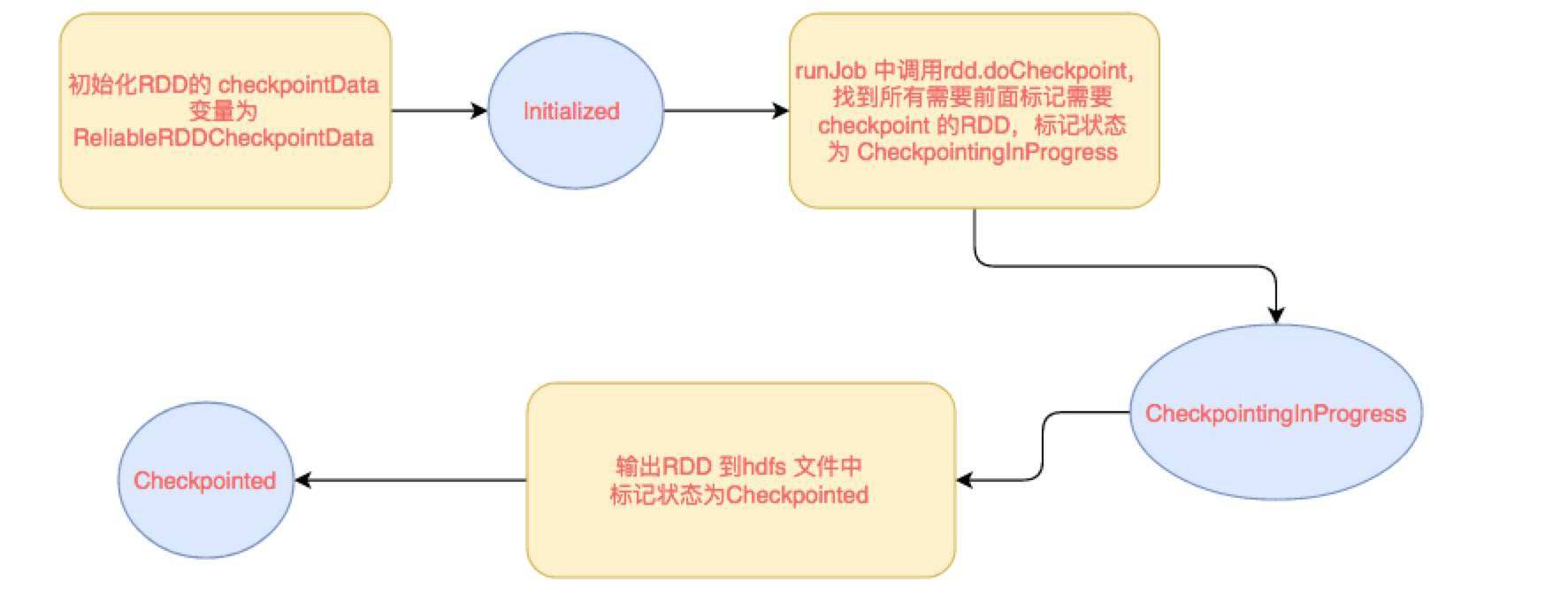
RDD checkpoint 过程中会经过这几个状态:[ Initialized → marked for checkpointing → checkpointing in progress → checkpointed ]
流程:
**data.checkpoint**这个函数调用中,设置的目录中,所有依赖的 RDD 都会被删除,函数必须在 job 运行之前调用执行,强烈建议 RDD 缓存在内存中(又提到一次,要注意),否则保存到文件的时候需要从头计算。初始化 RDD 的 checkpointData 变量为 ReliableRDDCheckpointData。这时候标记为 Initialized 状态。- 在所有 job action 的时候,runJob 方法中都会调用
**rdd.doCheckpoint**, 这个会向前递归调用所有的依赖的 RDD, 看看需不需要 checkpoint。如果需要 checkpoint,然后调用**checkpointData.getCheckpoint()**, 里面标记状态为 CheckpointingInProgress,里面调用 ReliableRDDCheckpointData 的 doCheckpoint 方法。 - doCheckpoint -> writeRDDToCheckpointDirectory, 注意这里会把 job 再运行一次,如果已经 cache 了,就可以直接使用缓存中的 RDD 了,就不需要重头计算一遍了(怎么又说了一遍), 这时候直接把 RDD 输出到 hdfs, 每个分区一个文件, 会先写到一个临时文件, 如果全部输出完,进行 rename , 如果输出失败就回滚 delete。
- 标记状态为 Checkpointed, markCheckpointed 方法中清除所有的依赖, 怎么清除依赖的呢, 就是把 RDD 变量的强引用设置为 null, 垃圾回收了,会触发 ContextCleaner 里面监听清除实际 BlockManager 缓存中的数据。
checkpoint 读流程
如果一个 RDD 被 checkpoint 了,那么这个 RDD 中对分区和依赖的处理都是使用的 RDD 内部的 checkpointRDD 变量,具体实现是 ReliableCheckpointRDD 类型。这个是在 checkpoint 写流程中创建的。依赖和获取分区方法中先判断是否已经 checkpoint,若已经 checkpoint了,就斩断依赖,用 ReliableCheckpointRDD 来处理依赖和获取分区。获取分区数据就是读取 checkpoint 到 hdfs 目录中不同分区保存下来的文件。
2.5 RDD 的依赖关系
依赖
窄依赖:指的是每一个父RDD的 Partition 最多被子 RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
宽依赖:指的是多个子 RDD 的 Partition 会依赖同一个父 RDD 的 Partition,会引起 shuffle,宽依赖我们形象的比喻为超生。
Lineage
RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
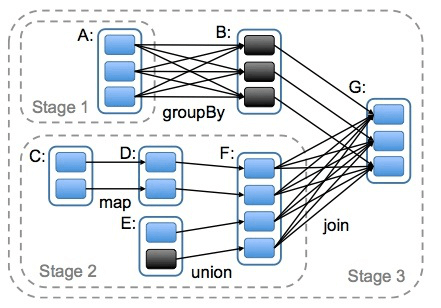
DAG 的生成
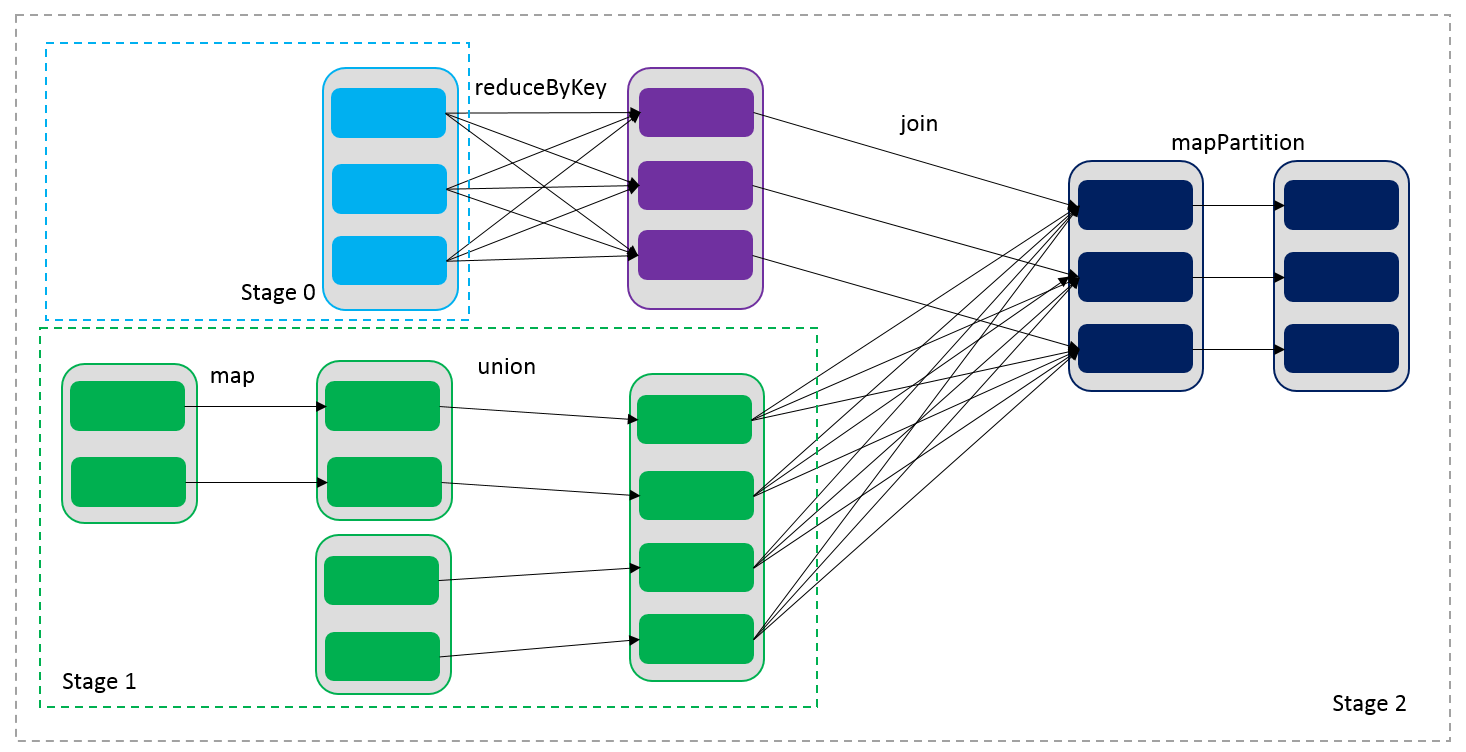
DAG(Directed Acyclic Graph) 叫做有向无环图,原始的 RDD 通过一系列的转换就就形成了 DAG,根据 RDD 之间的依赖关系的不同将 DAG 划分成不同的 Stage,对于窄依赖,partition 的转换处理在 Stage 中完成计算。对于宽依赖,由于有 Shuffle 的存在,只能在 parent RDD 处理完成后,才能开始接下来的计算,因此宽依赖是划分 Stage 的依据。
RDD 相关概念关系
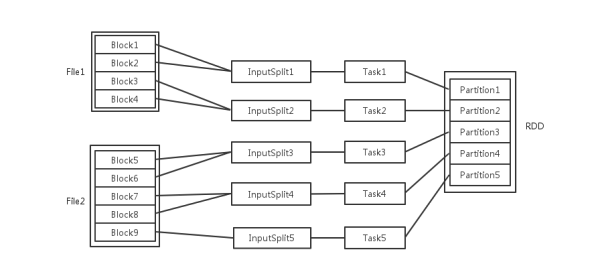
概念:
- Block:输入可能以多个文件的形式存储在 HDFS 上,每个 File 都包含了很多块,称为 Block。
- InputSplit:当 Spark 读取这些文件作为输入时,会根据具体数据格式对应的 InputFormat 进行解析,一般是将若干个 Block 合并成一个输入分片,称为 InputSplit,InputSplit 不能跨越文件。
- Task:随后将为这些输入分片生成具体的 Task。InputSplit 与 Task 是一一对应的关系。
- Executor:随后这些具体的 Task 每个都会被分配到集群上的某个节点的某个 Executor 去执行。每个节点可以起一个或多个 Executor,每个 Executor 由若干 core 组成,每个 Executor 的每个 core(这里的 core 是虚拟的 core 而不是机器的物理 CPU 核,可理解为 Executor 的一个工作线程)一次只能执行一个 Task,
**Task 被执行的并发度 = Executor 数目 * 每个 Executor 核数**。 - partiton:每个 Task 执行的结果就是生成了目标 RDD 的一个 partiton。partition的数目:
- 对于数据读入阶段,例如 sc.textFile,输入文件被划分为多少 InputSplit 就会需要多少初始 Task。
- 在 Map 阶段 partition 数目保持不变。
- 在 Reduce 阶段,RDD 的聚合会触发 shuffle 操作,聚合后的 RDD 的 partition 数目跟具体操作有关,例如 repartition 操作会聚合成指定分区数,还有一些算子是可配置的。
RDD 在计算的时候,每个分区都会起一个 task,所以 RDD 的分区数目决定了总的 task 数目。申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的 task。比如:
- RDD 有 100 个分区,那么计算的时候就会生成 100 个 task,你的资源配置为 10 个计算节点,每个两 2 个核,同一时刻可以并行的 task 数目为 20,计算这个 RDD 就需要 5 个轮次。
- 如果计算资源不变,你有 101 个 task 的话,就需要 6 个轮次,在最后一轮中,只有一个 task 在执行,其余核都在空转。
- 如果资源不变,你的 RDD 只有 2 个分区,那么同一时刻只有 2 个 task 运行,其余 18 个核空转,造成资源浪费。这就是在 spark 调优中,增大 RDD 分区数目,增大任务并行度的做法。
2.6 键值对 RDD
键值对 RDD 是 Spark 中许多操作所需要的常见数据类型。Spark 为包含键值对类型的 RDD 提供了一些专有的操作,在 PairRDDFunctions 专门进行了定义。这些 RDD 被称为 pair RDD。有很多种方式创建 pair RDD,一般如果从一个普通的 RDD 转 pair RDD 时,可以调用 map() 函数来实现,传递的函数需要返回键值对。
2.6.1 键值对 RDD 转化操作
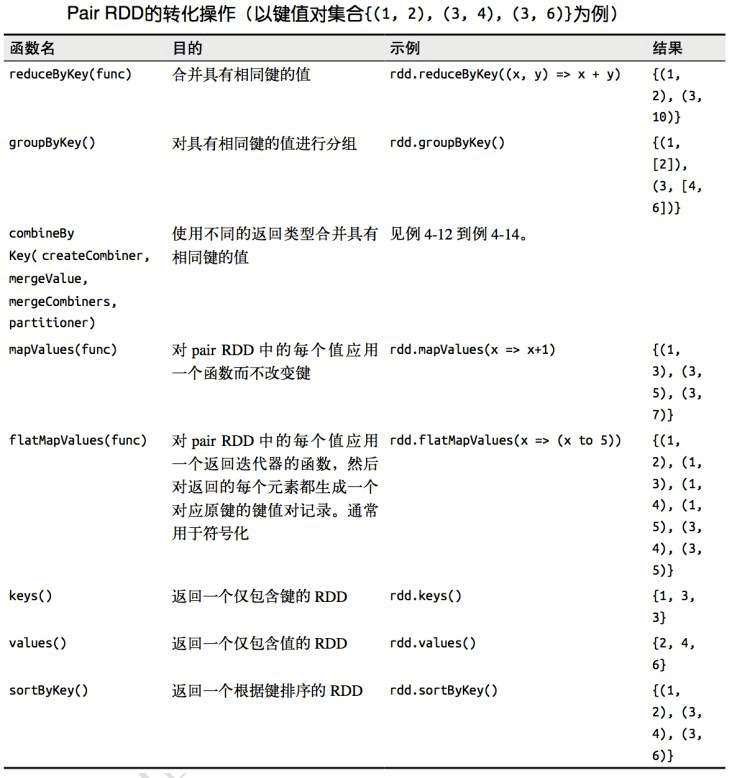

2.6.2 聚合操作
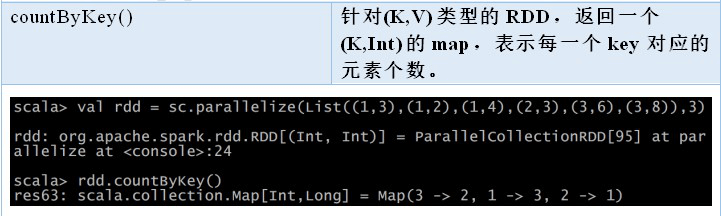
reduceByKey
reduceByKey() 与 reduce() 相当类似;它们都接收一个函数,并使用该函数对值进行合并。本地的数据先进行 merge 然后再传输到不同节点再进行 merge,最终得到最终结果。因为数据集中可能有大量的键,所以 **reduceByKey()** 没有被实现为向用户程序返回一个值的行动操作,只是记录了转换的操作。
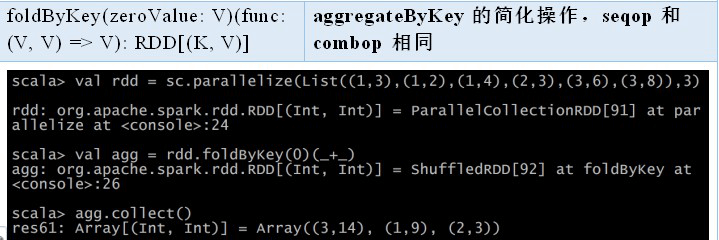
foldByKey
foldByKey() 则与 fold() 相当类似;它们都使用一个与 RDD 和合并函数中的数据类型相同的零值作为初始值。
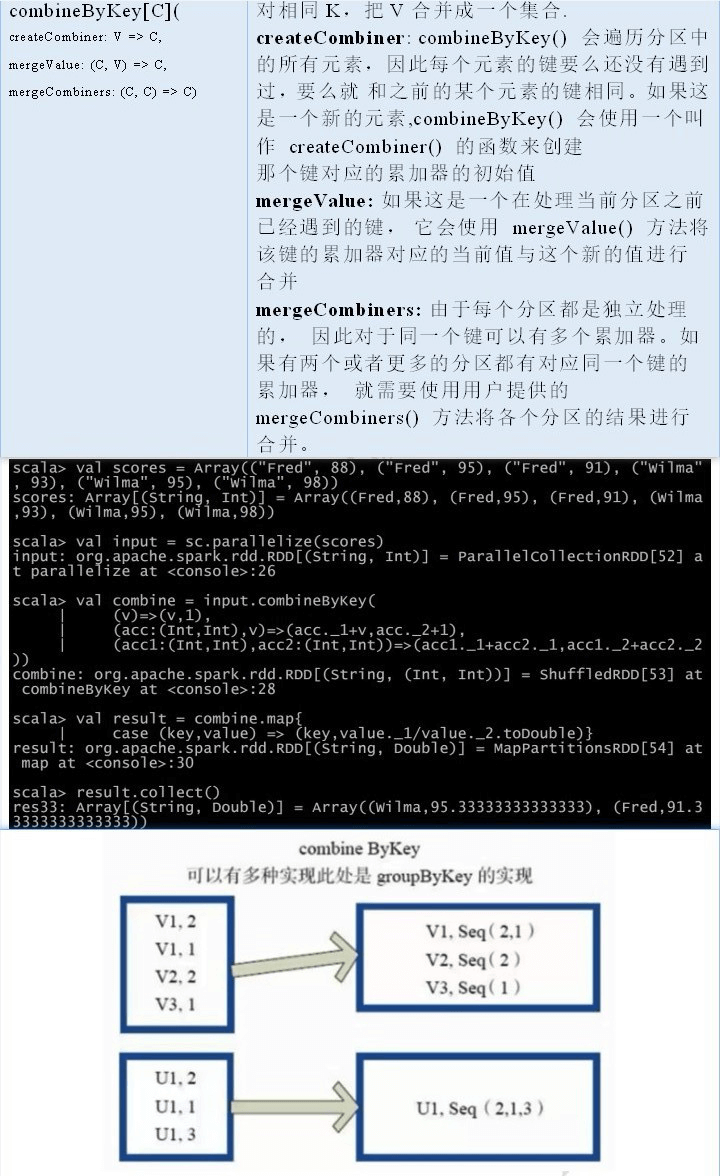
combineByKey
combineByKey() 是最为常用的基于键进行聚合的函数。大多数基于键聚合的函数都是用它实现的。和 aggregate() 一样,combineByKey() 可以让用户返回与输入数据的类型不同的返回值。
2.6.3 数据分组
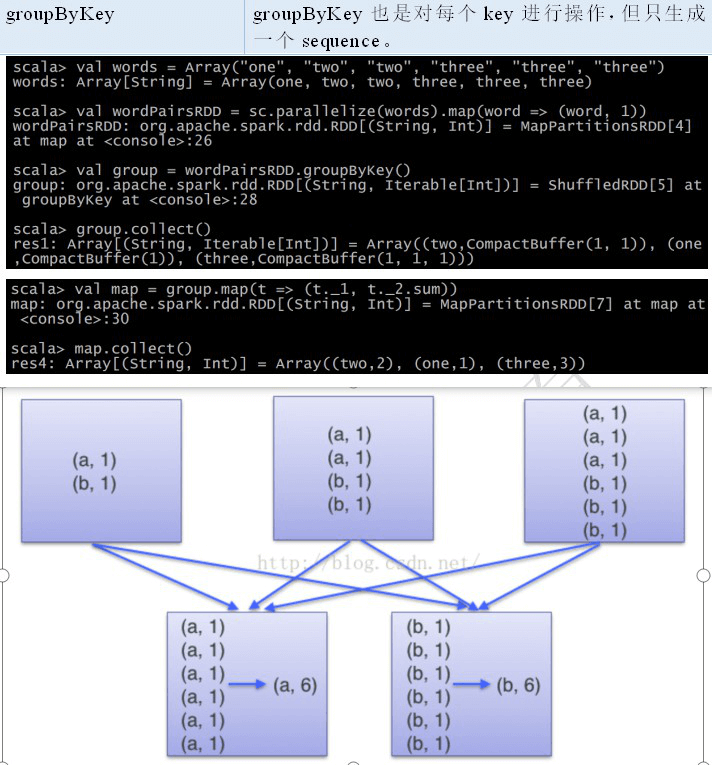
groupByKey
groupByKey() 就会使用 RDD 中的键来对数据进行分组。对于一个由类型 K 的键和类型 V 的值组成的 RDD,所得到的结果 RDD 类型会是 **[K, Iterable[V]]**。
groupBy
groupBy() 可以用于未成对的数据上,也可以根据除键相同以外的条件进行分组。它可以接收一个函数,对源 RDD 中的每个元素使用该函数,将返回结果作为键再进行分组。
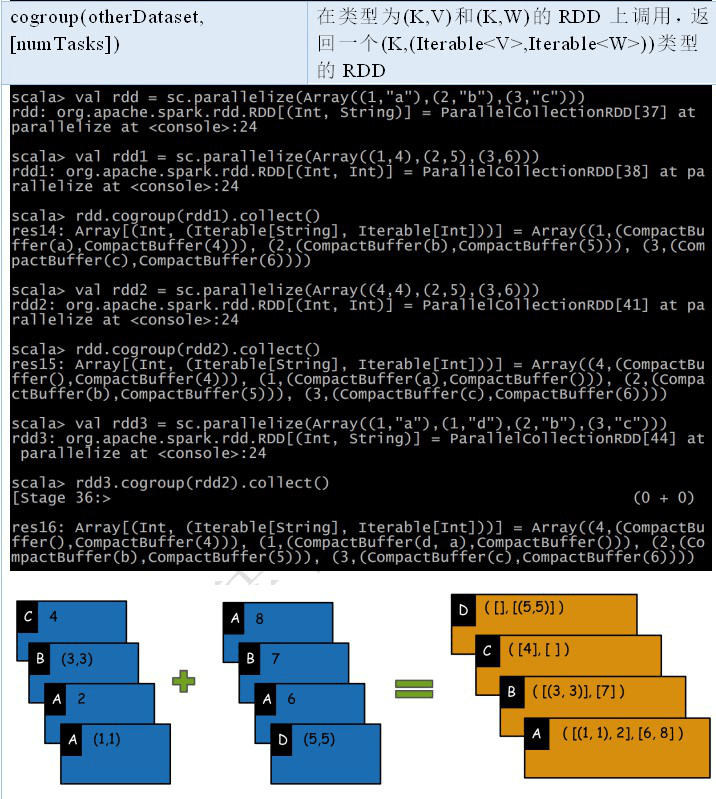
cogroup
cogroup() 的函数对多个共享同一个键的 RDD 进行分组。对两个键的类型均为 K 而值的类型分别为 V 和 W 的 RDD 进行 cogroup() 时,得到的结果 RDD 类型为 **[(K, (Iterable[V], Iterable[W]))]**。
2.6.4 连接
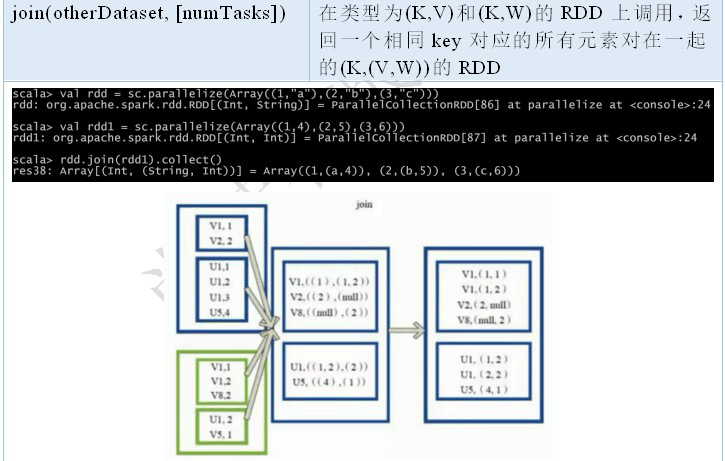
inner join
普通的 join 操作符表示内连接。只有在两个 pair RDD 中都存在的键才叫输出。当一个输入对应的某个键有多个值时,生成的pair RDD会包括来自两个输入RDD的每一组相对应的记录。
leftOuterJoin
leftOuterJoin() 产生的pair RDD中,源RDD的每一个键都有对应的记录。每个键相应的值是由一个源 RDD 中的值与一个包含第二个 RDD 的值的 Option(在 Java 中为 Optional)对象组成的二元组。
rightOuterJoin
rightOuterJoin() 几乎与 leftOuterJoin() 完全一样,只不过预期结果中的键必须出现在第二个 RDD 中,而二元组中的可缺失的部分则来自于源 RDD 而非第二个 RDD。

2.6.5 数据排序
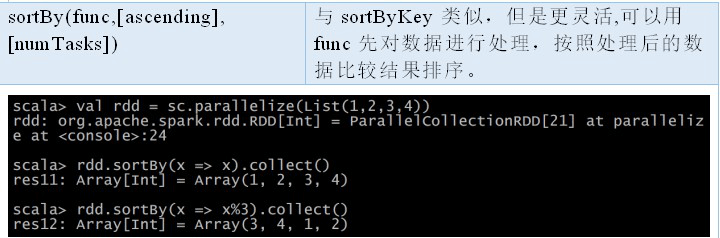
sortByKey
sortByKey() 函数接收一个叫作 ascending 的参数,表示我们是否想要让结果按升序排序(默认为 true)。
2.6.6 键值对 RDD 的行动操作

2.6.7 数据分区
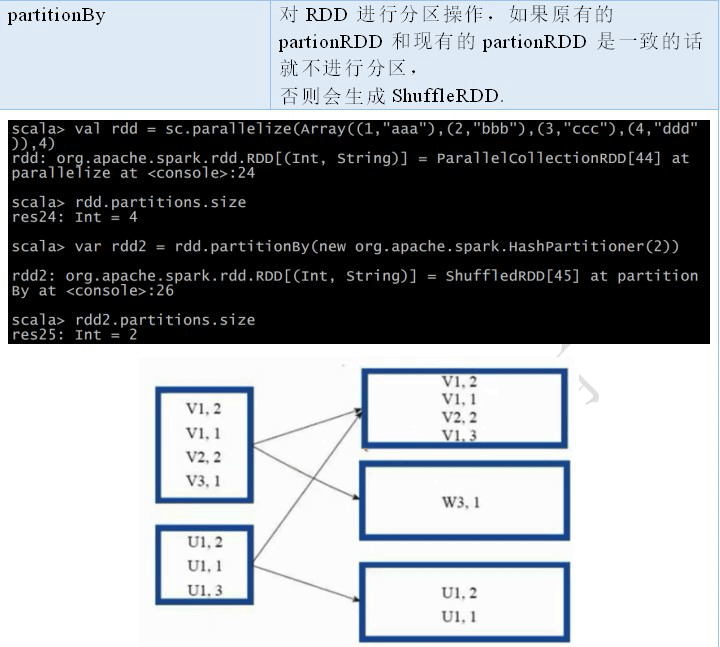
Spark目前支持 Hash 分区和 Range 分区,用户可以自定义分区,Hash 分区为当前的默认分区,Spark中分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 过程属于哪个分区和 Reduce 的个数。
注意:
- 只有 Key-Value 类型的 RDD 才有分区的(注意分区数和分区 partitioner ),非 Key-Value 类型的 RDD 分区的值是None。
- 每个 RDD 的分区 ID 范围:0~numPartitions-1,决定这个值是属于那个分区的。
获取 RDD 的分区方式
可以通过使用 RDD 的 partitioner 属性来获取 RDD 的分区方式。它会返回一个 scala.Option 对象, 通过 get 方法获取其中的值。

Hash 分区方式
HashPartitioner:对于给定的 key,计算其 hashCode,并除于分区的个数取余,如果余数小于 0,则用余数+分区的个数,最后返回的值就是这个 key 所属的分区 ID。
HashPartitioner 分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有 RDD 的全部数据。
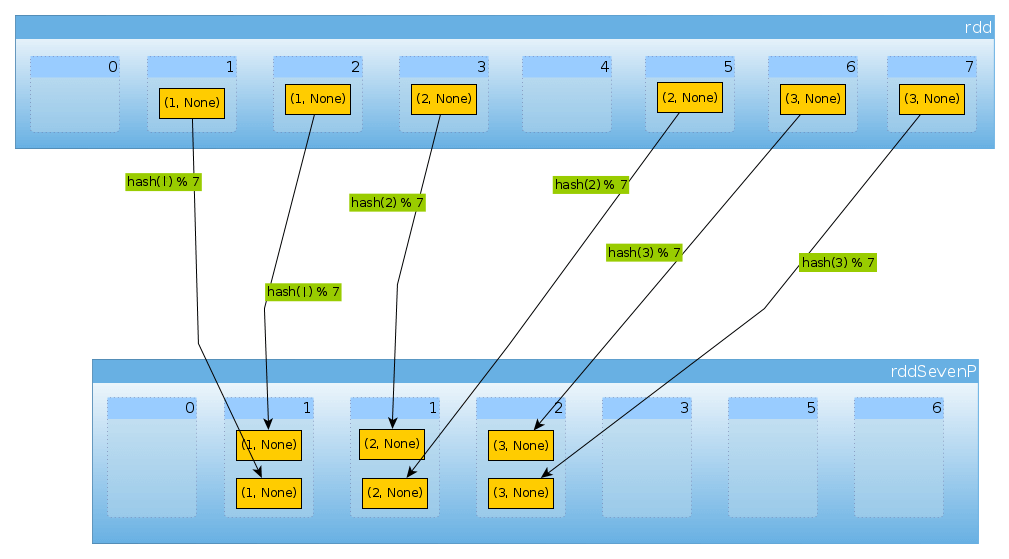
Range 分区方式
RangePartitioner:将一定范围内的数映射到某一个分区内,在实现中,分界的算法尤为重要。用到了水塘抽样算法。
RangePartitione分区优势:尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大。缺点是分区内的元素是不能保证顺序的。
自定义分区方式
要实现自定义的分区器,需要继承 **org.apache.spark.Partitioner** 类并实现下面三个方法:
- numPartitions:返回创建出来的分区数。
- getPartition:返回给定键的分区编号(0 到 numPartitions-1)。
- equals:判断相等性的标准方法。这个方法的实现非常重要,Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个 RDD 的分区方式是否相同。
自定义分区实例
//自定义分区class CustomerPartitioner(numParts:Int) extends Partitioner {//覆盖分区数override def numPartitions: Int = numParts//覆盖分区号获取函数override def getPartition(key: Any): Int = {val ckey: String = key.toStringckey.substring(ckey.length-1).toInt%numParts}}object CustomerPartitioner {def main(args: Array[String]) {val conf=new SparkConf().setAppName("partitioner")val sc=new SparkContext(conf)val data=sc.parallelize(List("aa.2","bb.2","cc.3","dd.3","ee.5"))//只要把它传给 partitionBy() 方法即可data.map((_,1)).partitionBy(new ustomerPartitioner(5)).keys.saveAsTextFile("hdfs://master01:9000/partitioner")}}
分区 Shuffle 优化
需求:有这样的一个应用,它在内存中保存着一张很大的用户信息表—— 也就是一个由(UserID,UserInfo) 对组成的 RDD,其中 UserInfo 包含一个该用户所订阅的主题的列表。该应用会周期性地将这张表与一个小文件进行组合,这个小文件中存着过去五分钟内发生的事件——其实就是一个由 (UserID, LinkInfo) 对组成的表,存放着过去 五分钟内某网站各用户的访问情况。

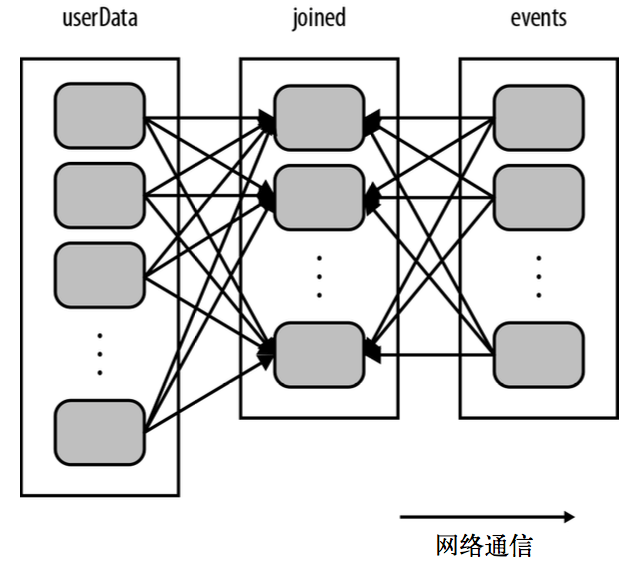

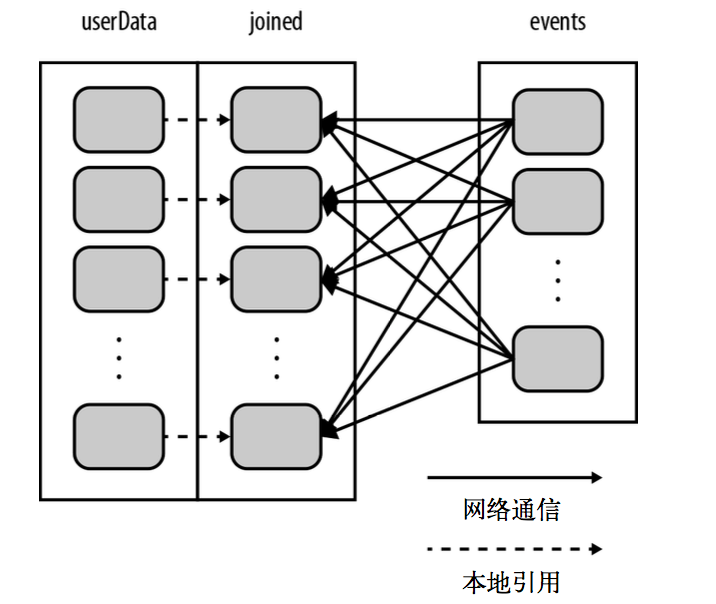
我们在构建 userData 时调用了 **partitionBy(100)**,Spark 就知道了该 RDD 是根据键的哈希值来分区的,这样在调用 **join()** 时,Spark 就会利用到这一点。具体来说,当调用 userData. join(events) 时,Spark 只会对 events 进行数据混洗操作,将 events 中特定 UserID 的记录发送到 userData 的对应分区(总的100个分区)所在的那台机器上。这样,需要通过网络传输的数据就大大减少了,程序运行速度也可以显著提升了。
基于分区进行操作
基于分区对数据进行操作可让我们避免为每个数据元素进行重复配置工作。诸如打开数据库连接或创建随机数生成器等操作,都是我们应尽量避免为每个元素都配置一次的工作。Spark 提供基于分区的 mapPartition 和 foreachPartition,让你的部分代码只对 RDD 的每个分区运行一次,这样可以帮助降低这些操作的代价。
从分区中获益的操作
能从数据分区中获得性能提升的操作有 **cogroup()**、**groupWith()**、**join()**、**leftOuterJoin()**、**rightOuterJoin()**、**groupByKey()**、**lookup()**、**reduceByKey()**、**combineByKey()** 等。
2.7 数据读取与保存主要方式
文本文件输入输出
当我们将一个文本文件读取为 RDD 时,输入的每一行都会成为 RDD 的一个元素。
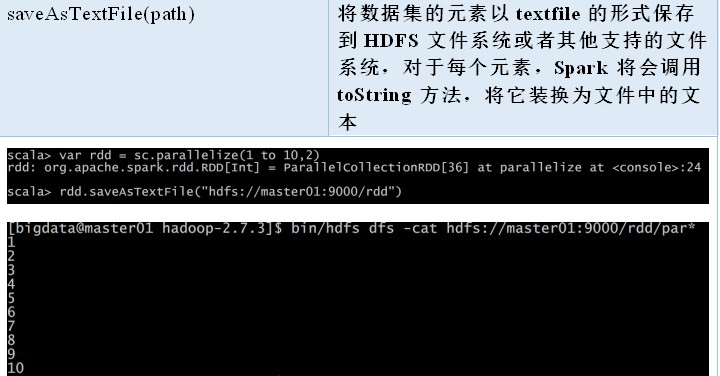
//(1) 输入,wholeTextFiles()对于大量的小文件读取效率比较高val input = sc.textFile("./README.md")//(2) 输出result.saveAsTextFile(outputFile)
JSON 文件输入输出
如果 JSON 文件中每一行就是一个 JSON 记录,那么可通过将 JSON 文件当做文本文件来读取,然后利用相关的 JSON 库对每一条数据进行 JSON 解析。如下:
var result = sc.textFile("examples/people.json")
如果 JSON 数据是跨行的,那么只能读入整个文件,然后对每个文件进行解析。JSON 数据的输出主要是通过在输出之前将由结构化数据组成的 RDD 转为字符串 RDD,然后使用 Spark 的文本文件 API 写出去。
CSV 文件输入输出
读取 CSV/TSV 数据和读取 JSON 数据相似,都需要先把文件当作普通文本文件来读取数据,然后通过将每一行进行解析实现对 CSV 的读取。
CSV/TSV 数据的输出也是需要将结构化 RDD 通过相关的库转换成字符串 RDD,然后使用 Spark 的文本文件 API 写出去。
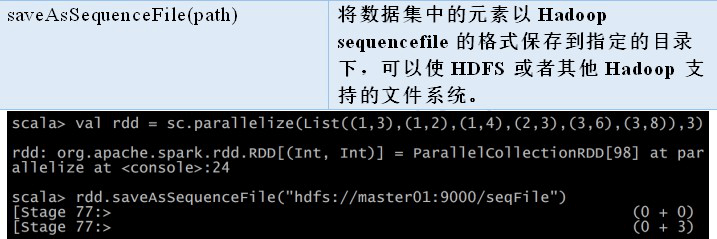
SequenceFile文 件输入输出
Spark 有专门用来读取 SequenceFile 的接口。在 SparkContext 中,可以调用 **sequenceFile[keyClass, valueClass]()**。
val sdata = sc.sequenceFile[Int,String]("hdfs://master01:9000/sdata/p*")
可以直接调用 **saveAsSequenceFile(path)** 保存你的PairRDD,它会帮你写出数据。需要键和值能够自动转为 Writable 类型。

对象文件输入输出
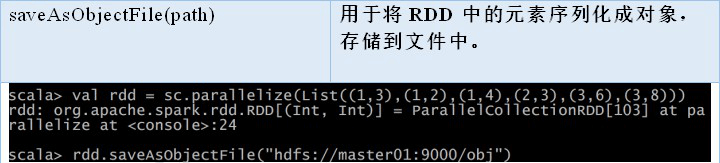
可以通过 **objectFile[k,v] (path)** 函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用 **saveAsObjectFile()** 实现对对象文件的输出。因为是序列化所以要指定类型。对象文件是将对象序列化后保存的文件,采用 Java 的序列化机制。
Hadoop 输入输出格式
主要提供 hadoop 接口。hadoopRDD 和 newHadoopRDD 是最为抽象的两个函数接口,主要包含以下四个参数:
- 输入格式(InputFormat): 制定数据输入的类型,如 TextInputFormat 等,新旧两个版本所引用的版本分别是
org.apache.hadoop.mapred.InputFormat和org.apache.hadoop.mapreduce.InputFormat(NewInputFormat)。 - 键类型: 指定 [K,V] 键值对中K的类型。
- 值类型: 指定 [K,V] 键值对中V的类型。
- 分区值: 指定由外部存储生成的 RDD 的 partition 数量的最小值,若没有指定,系统会使用默认值 default-MinSplits。
使用方法:
- 输入
**sc.newAPIHadoopFile(...)** - 输出
**data.saveAsNewAPIHadoopFile(...)**
文件系统的输入输出
Spark 支持读写很多种文件系统, 像本地文件系统、Amazon S3、HDFS 等。
数据库的输入输出
支持通过 Java JDBC 访问关系型数据库。需要通过 **JdbcRDD(...)** 进行访问。写入通过遍历 RDD,使用 prepareStatement 语句写入。
HBase 数据库。**newAPIHadoopRDD(...)** 访问,saveAsHadoopDataset(…) 写入。
2.8 RDD 编程进阶
累加器
如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。通过在驱动器中调用 **SparkContext.accumulator(initialValue)** 方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T] 对象,其中 T 是初始值 initialValue 的类型。
驱动器程序可以调用累加器的 value 属性(在 Java 中使用 value() 或 setValue()) 来访问累加器的值。工作节点上的任务不能访问累加器的值。从这些任务的角度来看,累加器是一个只写变量。对于要在行动操作中使用的累加器,Spark 只会把每个任务对各累加器的修改应用一次。因此,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在 **foreach()** 这样的行动操作中。转化操作中累加器可能会发生不止一次更新。
自定义累加器
实现自定义类型累加器需要继承 AccumulatorV2 并至少覆写下例中出现的方法。下面这个累加器可以用于在程序运行过程中收集一些文本类信息,最终以 Set[String] 的形式返回。
代码:
class LogAccumulator extends AccumulatorV2[String, java.util.Set[String]] {private val _logArray: java.util.Set[String] = new java.util.HashSet[String]()override def isZero: Boolean = {_logArray.isEmpty}override def reset(): Unit = {_logArray.clear()}override def add(v: String): Unit = {_logArray.add(v)}override def merge(other:AccumulatorV2[String,java.util.Set[String]]): Unit = {other match {case o: LogAccumulator => _logArray.addAll(o.value)}}override def value: java.util.Set[String] = {java.util.Collections.unmodifiableSet(_logArray)}override def copy():AccumulatorV2[String,java.util.Set[String]] = {val newAcc = new LogAccumulator()_logArray.synchronized{newAcc._logArray.addAll(_logArray)}newAcc}}// 过滤掉带字母的object LogAccumulator {def main(args: Array[String]) {val conf=new SparkConf().setAppName("LogAccumulator")val sc=new SparkContext(conf)val accum = new LogAccumulatorsc.register(accum, "logAccum")val sum = sc.parallelize(Array("1", "2a", "3", "4b", "5", "6","7d", "8", "9"), 2).filter(line => {val pattern = """^-?(\d+)"""val flag = line.matches(pattern)if (!flag) {accum.add(line)}flag}).map(_.toInt).reduce(_ + _)println("sum: " + sum)for (v <- accum.value) print(v + "")println()sc.stop()}}
广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。
使用广播变量的过程:
- 通过对一个类型T的对象调用
**SparkContext.broadcast**创建出Broadcast[T]对象,任何可序列化的类型都可以这么实现。 - 通过 value 属性访问该对象的值(在 Java 中为
value()方法)。 - 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
2.9 实例练习
计算独立 IP 数
思路:
- 从每行日志中筛选出 IP 地址。
- 去除重复的 IP 得到独立 IP 数。
过程:
flatMap(x=>IPPattern findFirstIn(x))通过正则取出每行日志中 IP 地址;map(x=>(x,1))将每行中的 IP 映射成(IP,1),形成一个Pair RDD;reduceByKey((x,y)=>x+y)将相同的 IP 合并,得到 (IP,数量);sortBy(.2,false)按 IP 大小排序。
统计每个视频独立 IP 数
思路
- 筛选视频文件将每行日志拆分成 (文件名,IP地址)形式 。
- 按文件名分组,相当于数据库的 Group by,这时 RDD 的结构为(文件名,[IP1,IP1,IP2,…]),这时IP有重复 。
- 将每个文件名中的 IP 地址去重,这时 RDD 的结果为(文件名, [IP1,IP2,…]),这时 IP 没有重复。
过程:
filter(x=>x.matches(“.([0-9]+).mp4.“))筛选日志中的视频请求。map(x=>getFileNameAndIp(x))将每行日志格式化成 (文件名,IP)这种格式。groupByKey()按文件名分组,这时 RDD 结构为 (文件名,[IP1,IP1,IP2….]),IP有重复。map(x=>(x.1,x.2.toList.distinct))去除 value 中重复的IP地址。sortBy(.2.size,false)按 IP 数排序。
统计一天中每个小时间的流量
思路:
- 将日志中的访问时间及请求大小两个数据提取出来形成 RDD(访问时间,访问大小),这里要去除 404 之类的非法请求。
- 按访问时间分组形成 RDD(访问时间,[大小1,大小2,….])。
- 将访问时间对应的大小相加形成 (访问时间,总大小)。
过程:
filter(x=>isMatch(httpSizePattern,x)).filter(x=>isMatch(timePattern,x))过滤非法请求。map(x=>getTimeAndSize(x))将日志格式化成 RDD(请求小时,请求大小)。groupByKey()按请求时间分组形成 RDD(请求小时,[大小1,大小2,….])。map(x=>(x.1,x.2.sum))将每小时的请求大小相加,形成 RDD(请求小时,总大小)。

若有收获,就点个赞吧
0 人点赞
