2019年,Spark 3.x会闪亮登场,百尺竿头,更进一步,在人工智能与机器学习领域开始发力。
2.1 Spark架构
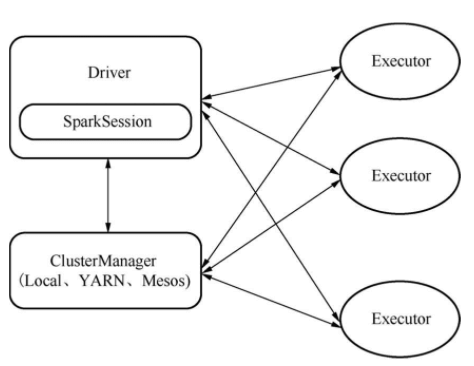
Spark架构
_
Spark程序的入口是Driver中的SparkContext。与Spark 1.x相比,在Spark2.0中,有一个变化是用SparkSession统一了与用户交互的接口,曾经熟悉的SparkContext、SqlContext、HiveContext都是SparkSession的成员变量,这样更加简洁。
SparkContext的作用是连接用户编写的代码与运行作业调度和任务分发的代码 。
当用户启动一个Driver程序时,会通过SparkContext向集群发出命令,Executor会遵照指令执行任务,ClusterManager负责所有Executor的资源管理和调度。
Driver解析用户编写的代码,并序列化字节级别的代码,这些代码将会被分发至将要执行的Executor上。当执行Spark作业时,这些计算过程实际上是在每个节点本地计算并完成。实际过程下图所示:
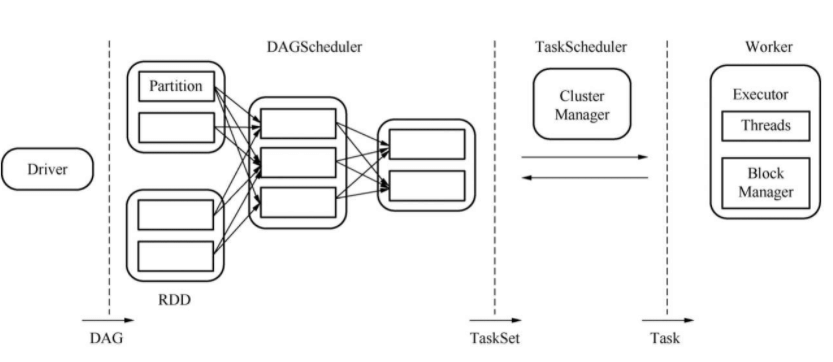
Spark执行过程
_
首先Driver根据用户编写的代码生成一个计算任务的有向无环图(Directed Acyclic Graph, DAG),接着,DAG会根据RDD(弹性分布式数据集)之间的依赖关系被DAGScheduler切分成由Task组成的Stage(TaskSet), TaskScheduler会通过ClusterManager将任务调度到Executor上执行。
在DAG中,每个Task的输入就是一个Partition(分区),而一个Executor同时只能执行一个Task,但一个Worker(物理节点)上可以同时运行多个Executor。
在Spark的架构中,Driver主要负责作业调度工作,是整个架构中最重要的角色,它通过监控和管理整个执行过程保证了一切按照计划正常运行,此外它还在Spark容错中起到了重要的作用。
MapReduce这类型的计算框架中,中间结果的传输是整个计算过程中最重要的一个步骤,Spark也是如此,在Spark作业中,这也是Stage划分的依据,我们称之为数据混洗(Shuffle)。
**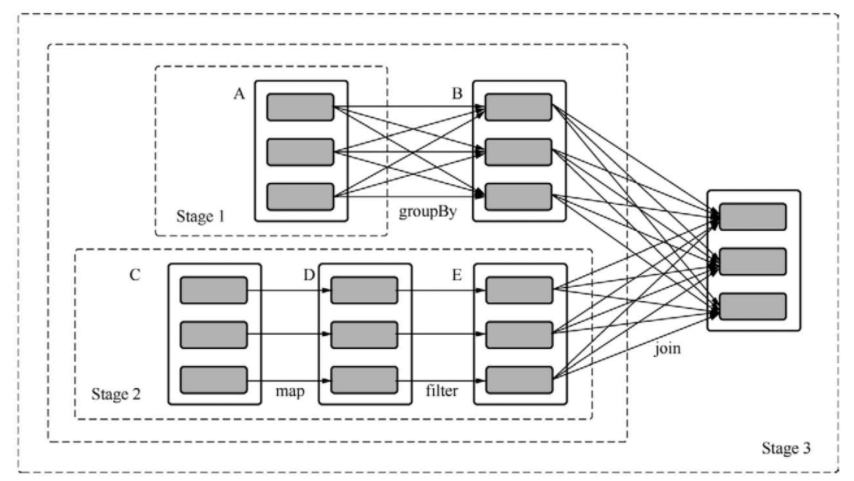
Spark的计算任务DAG图
_
2.2 Spark 2.x与Spark 3.x
Spark 2.x的新特性主要体现在3个方面,即性能优化(Tungsten项目)、接口优化(统一Dataset和DataFrame接口)和流处理上。
**
2.2.1 Tungsten项目
Spark开发团队希望开发一个新的Spark核心执行引擎来尽可能地压榨出CPU和内存的性能极限。2015年,Tungsten项目诞生了。
Tungsten目前分为两个阶段,下面先介绍第一阶段。
内存管理与二进制处理
Tungsten旨在利用应用程序语义显式管理内存,消除JVM对象模型和垃圾回收的开销。Tungsten的目的就是摆脱JVM的垃圾回收器,自己管理内存。
Tungsten绕过了JVM提供的安全内存托管系统,而使用了sun.misc.Unsafe包中的类,它允许Tungsten自主管理其内存。使用Unsafe类构建的数据结构在存储和访问性能上也大大优于JVM对象模型。

UnsafeRow数据结构
_
一个行对象由空位设置域(该字段是否为空)、定长值域(符合定长长度:8字节,要么是固定长度的值)和变长值域(可变长度的字段)3个域组成。
在实际使用中也发现了java.util.HashMap的一些缺点:
- 使用对象作为键和值导致内存额外开销。
- 采用对缓存非常不友好的内存布局方式。
- 不能通过计算偏移量直接定位字段。
因此Tungsten自己实现了一种新的数据结构,称为BytesToBytesMap,它提升了内存本地性,并且通过避免使用重量级的Java对象来减少内存开销,也很适合顺序扫描。顺序扫描这种操作对缓存是非常友好的,因为对内存的访问往往是连续的。经过测试,在大量数据的压力下,Tungsten的BytesToBytesMap几乎没有性能衰减,而java.util.HashMap则最终被GC压垮。
缓存感知计算
现代计算机系统使用64位地址指针指向64位内存块。而Tungsten也总是使用8字节的数据集来和64位内存块对齐。在CPU内核和内存之间,有一个L1、L2和L3高速分层存储,它们随着CPU数量增加而增加。
应始终避免随机存储访问模式,通常越顺序存储访问执行得越快。
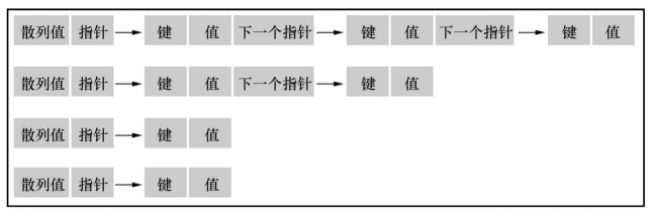
HashMap的存储布局
java.util.HashMap这些指针指向的是随机内存区域。因此,顺序扫描是不可能的,为了提升顺序扫描性能,Tungsten采取了不同的办法:指针不仅存储目标值内存地址,还会保存键本身,
我们已经了解了UnsafeRow的概念,8字节的存储区域用来保存两个整型值,例如,键和指向值的指针。这种存储布局下图所示:
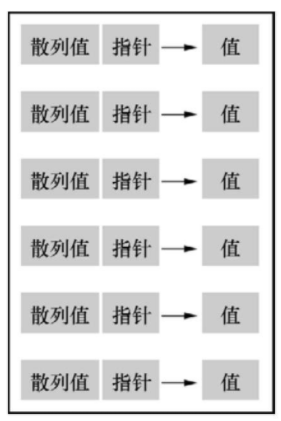
改进的存储布局
_
当排序时,键和指针的组合存储区域会被到处移动,存储值的地方却不会变。虽然这些值可以随机分布在存储器中,但是键和指针的组合存储区域被以顺序布局。
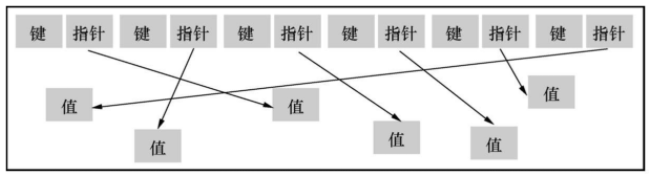
键和指针可以顺序遍历
前面介绍的BytesToBytesMap也同样具有缓存友好的特性。
_
代码生成
Tungsten引入了代码推断用于表达式估计。Tungsten实际做的是将某个表达式转换为字节码**并将其发送到执行者线程中。
JVM的工作流如下:
- Java源代码被编译为字节码。
- Java字节码被JVM翻译。
- JVM将字节码转换成特定平台的机器指令并将其发送到目标CPU。
目前,还没有人想过在运行时直接生成字节码,这就是代码生成想要实现的。Tungsten分析将要被执行的任务,而不是依赖预编译组件,它会生成由人编写的在JVM上执行的特定的高性能字节码。
**
前面提到的特性主要是Tungsten阶段1(Tungsten Phase 1)带来的成果。Tungsten阶段2(Tungsten Phase 2)的优化主要集中在以下3个方面:
- 提升Catalyst优化器性能。
- 全阶段代码生成。
- 列式存储。
2.2.2 统一Dataset和DataFrame接口

若有收获,就点个赞吧
0 人点赞
