上篇 内核解密
电光石火间体验Spark 2.x开发实战
Spark核心概念图解
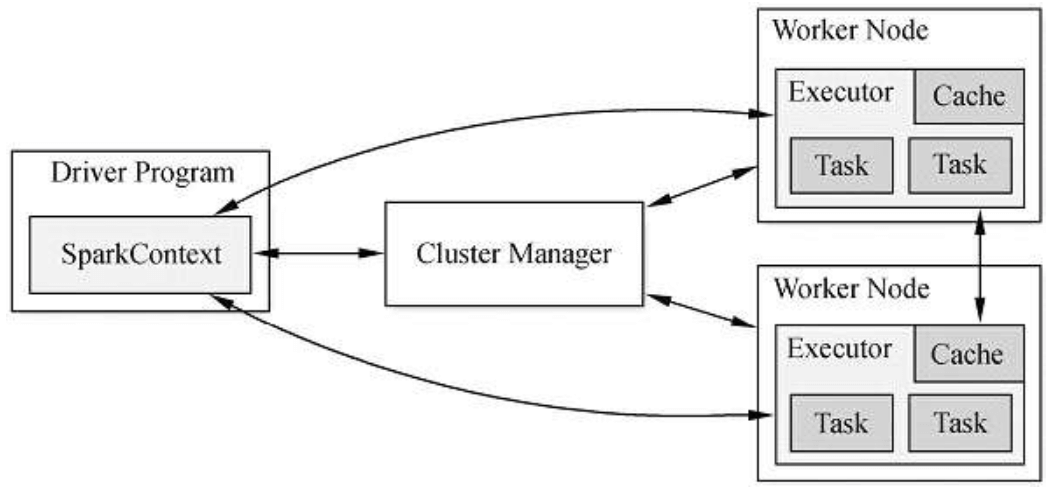
图1-1 Spark运行架构图
Master(图1-1中的Cluster Manager):就像Hadoop有NameNode和DataNode一样,Spark有Master和Worker。Master是集群的领导者,负责管理集群资源,接收Client提交的作业,以及向Worker发送命令。
Worker(图1-1中的Worker Node):集群中的Worker,执行Master发送的指令,来具体分配资源,并在这些资源中执行任务。
Driver:一个Spark作业运行时会启动一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage,并调度Task到Executor上。
Executor:真正执行作业的地方。Executor分布在集群中的Worker上,每个Executor接收Driver的命令来加载和运行Task,一个Executor可以执行一到多个Task。
SparkContext:是程序运行调度的核心,由高层调度器DAGScheduler划分程序的每个阶段,底层调度器TaskScheduler划分每个阶段的具体任务。SchedulerBackend管理整个集群中为正在运行的程序分配的计算资源Executor。
DAGScheduler:负责高层调度,划分stage并生成程序运行的有向无环图。
TaskScheduler:负责具体stage内部的底层调度,具体task的调度、容错等。
Job:(正在执行的叫ActiveJob)是Top-level的工作单位,每个Action算子都会触发一次Job,一个Job可能包含一个或多个Stage。
Stage:是用来计算中间结果的Tasksets。Tasksets中的Task逻辑对于同一个RDD内的不同partition都一样。Stage在Shuffle的地方产生,此时下一个Stage要用到上一个Stage的全部数据,所以要等到上一个Stage全部执行完才能开始。Stage有两种:ShuffleMapStage和ResultStage,除了最后一个Stage是ResultStage外,其他Stage都是ShuffleMapStage。ShuffleMapStage会产生中间结果,以文件的方式保存在集群里,Stage经常被不同的Job共享,前提是这些Job重用了同一个RDD。
Task:任务执行的工作单位,每个Task会被发送到一个节点上,每个Task对应RDD的一个partition。
RDD:是不可变的、Lazy级别的、粗粒度的(数据集级别的而不是单个数据级别的)数据集合,包含了一个或多个数据分片,即partition。
Spark程序中有两种级别的算子:Transformation和Action。Transformation算子会由DAGScheduler划分到pipeline中,是Lazy级别的不会触发任务的执行;Action算子会触发Job来执行pipeline中的运算。
Spark程序的固定框架
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD_Movie_Users_Analyzer")/*** Spark 2.0 引入 SparkSession 封装了 SparkContext 和 SQLContext,并且会在* builder的getOrCreate方法中判断是否有符合要求的SparkSession存在,有则使用,* 没有则进行创建*/val spark = SparkSession.builder.config(conf).getOrCreate()//获取SparkSession的SparkContextval sc = spark.sparkContext//把Spark程序运行时的日志设置为warn级别,以方便查看运行结果sc.setLogLevel("warn")//把用到的数据加载进来转换为RDD,此时使用sc.textFile并不会读取文件,而是标记了有//这个操作,遇到Action级别算子时才会真正去读取文件val usersRDD = sc.textFile(dataPath + "")/**具体数据处理的业务逻辑*///最后关闭SparkSessionspark.stop

若有收获,就点个赞吧
0 人点赞
