7.1 数据缓存的意义
数据缓存机制主要目的是加速计算。具体地,在应用执行过程中,数据缓存机制对某些需要多次使用(重用)的数据进行缓存。这样,当应用需要再次访问这些数据时,可以直接从缓存中读取,避免再次计算,从而减少应用的执行时间。例如,迭代型应用如果每轮迭代时都需要读取一个固定数据(如训练数据的特征矩阵或输入图)来进行计算,那么可以将这个固定数据进行缓存,加快读取和计算速度。再例如,交互式应用(如交互式SQL)需要不断地对一个固定数据进行查询分析(执行不同的SQL语句),如果对这个固定数据进行缓存,则可以加快查询分析速度。
7.2 数据缓存机制的设计原理
既然数据缓存能够加速计算,那么如何设计一个高效的缓存机制呢?这其中涉及决定哪些数据需要被缓存,包含数据缓存操作的逻辑处理流程和物理执行计划,缓存级别,缓存数据的写入方法,缓存数据的读取方法,用户接口的设计,缓存数据的替换与回收方法等内容。
7.2.1 决定哪些数据需要被缓存
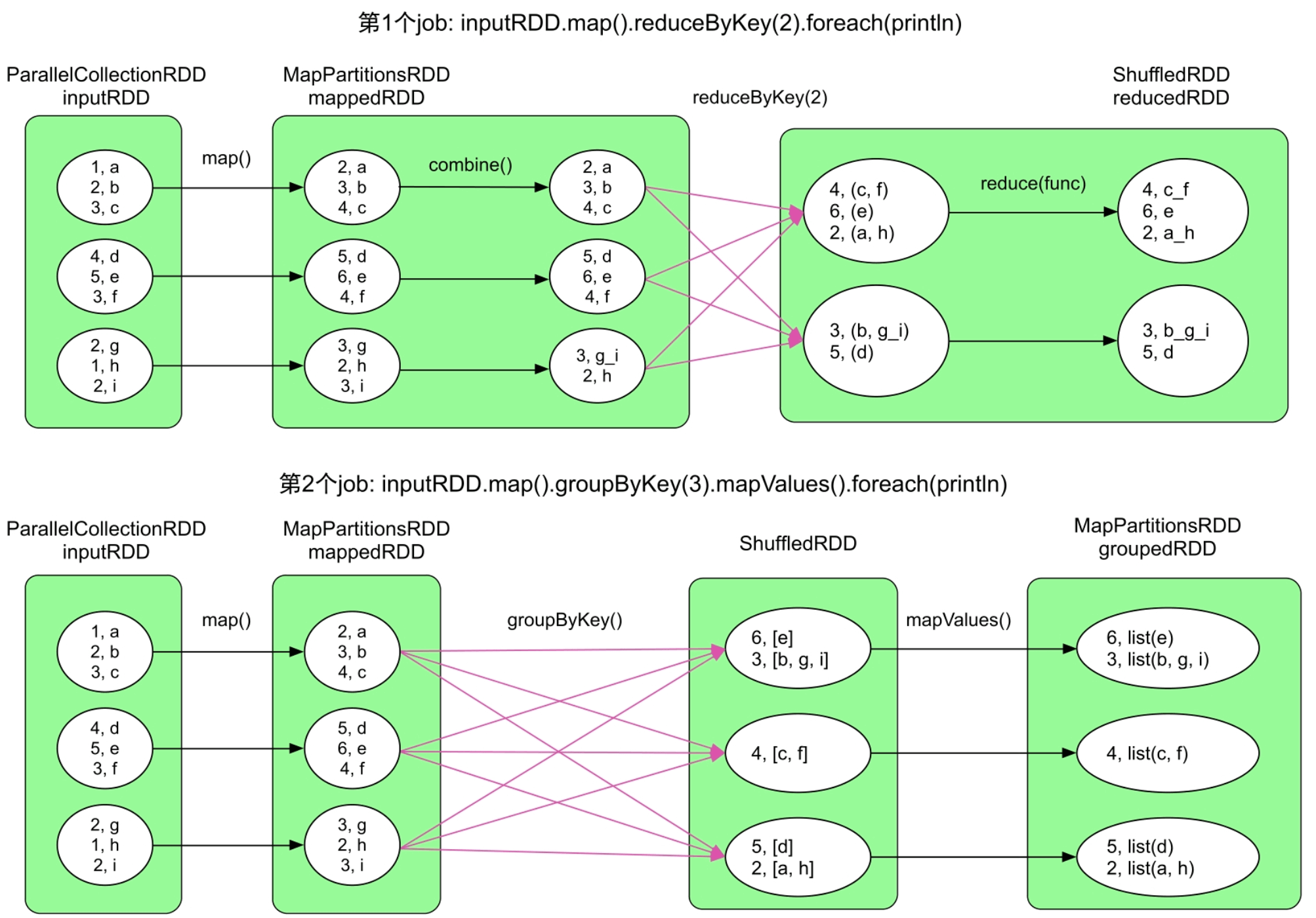
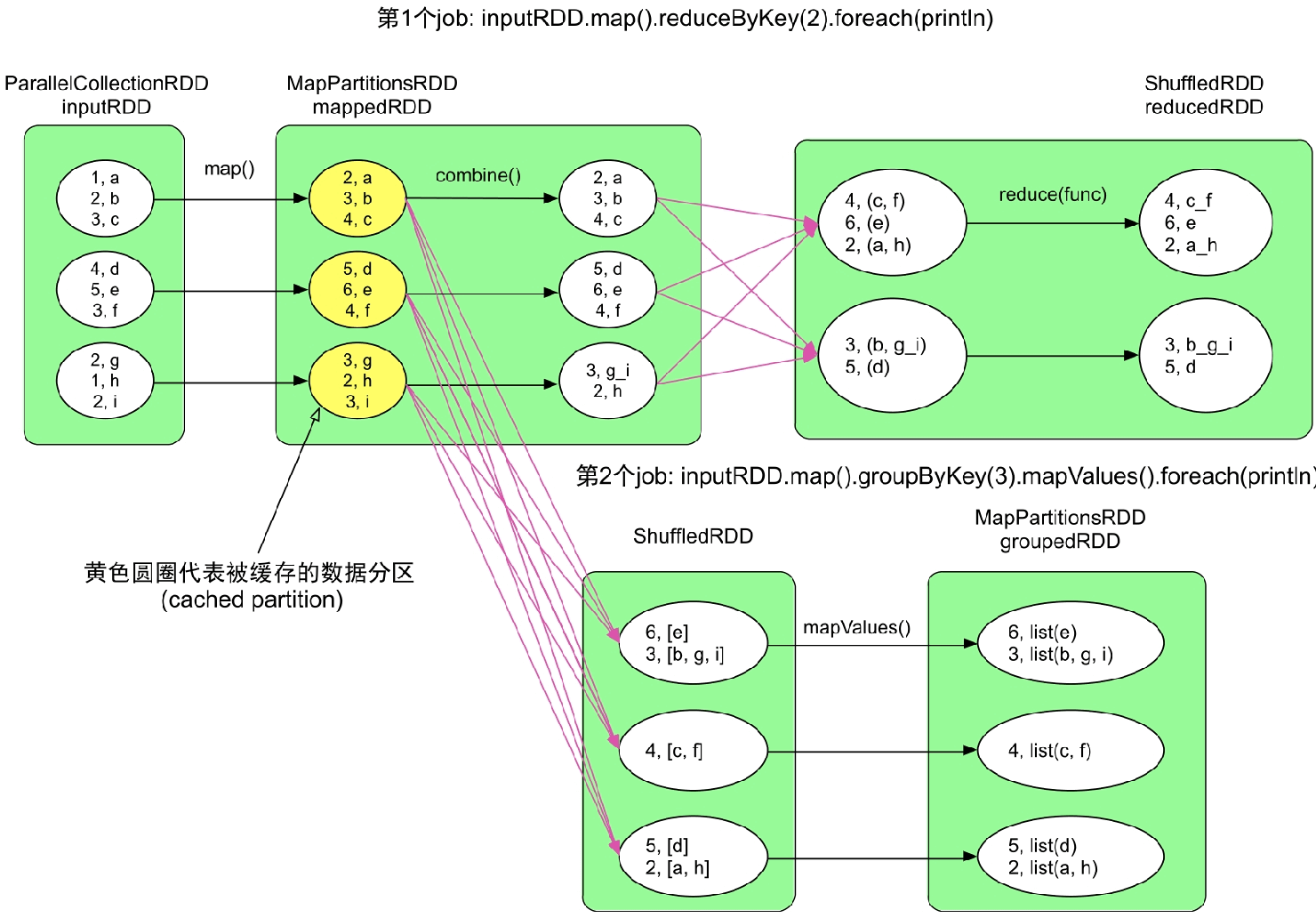
图7.1 示例程序生成的两个job,红色箭头表示具有ShuffleDependency
示例应用首先对输入数据进行map()计算,得到mappedRDD,然后对mappedRDD依次进行两种计算:一种是reduceByKey+foreach(println),另一种是groupByKey+foreach(println)。由于该应用有两个foreach()操作,所以会形成两个job。这两个job虽然都是在mappedRDD上进行计算的,但由于用户没有对mappedRDD进行缓存,Spark仍然认为这两个job都是从inputRDD开始计算的。
观察图7.1可以发现,生成的两个job中inputRDD=>mappedRDD的计算流程一样,那么理论上第2个job可以直接从mappedRDD开始进行计算。理想中的数据处理流程应该如图7.2所示,第1个job不变,第2个job变为mappedRDD:MapPartitionsRDD=>ShuffledRDD=>groupedRDD:MapPartitionsRDD。为了实现图7.2中的流程,用户可以在程序中声明mappedRDD需要被缓存,即在foreach()操作之前添加mappedRDD.cache()语句。
需要注意的是,①cache()操作表示将数据(此处是mappedRDD)直接写入内存。②cache()操作是lazy操作,不是立即执行的,即执行到mappedRDD.cache()时,只标记mappedRDD需要被缓存到内存中,此时并不真正执行缓存操作,只有等到reducedRDD.foreach(println)生成job,job运行时再将mappedRDD写入内存。③cache()操作只是将数据缓存到内存中,如果用户想将数据缓存到内存和磁盘中,那么可以使用persist(MEMORY_AND_DISK)接口。
图7.2 对mappedRDD进行缓存后生成的两个job,黄色圆圈表示被缓存的数据分区
回到图7.2中,对mappedRDD进行缓存后可以避免第2个job再进行map()计算,但代价是需要占用空间来存储mappedRDD。当mappedRDD很大时,如包含上亿个record,存储mappedRDD会消耗大量存储空间,这时,需要权衡计算代价和存储代价。在这个例子中,我们发现map()操作的计算逻辑很简单,只需要非常少量的计算(仅仅对Key加1)即可从原始数据inputRDD中得到mappedRDD。也就是说,mappedRDD的计算代价很低。此时,若mappedRDD需要很大存储空间时,那么我们可以不对mappedRDD进行缓存,而直接从原始数据中计算得到,因此,是否缓存数据不仅需要考虑数据的计算代价,也需要考虑存储代价。
总的来说,缓存机制实际上是一种空间换时间的方法。具体地,如果数据满足以下3条,就可以进行缓存。如下:
- 会被重复使用的数据。更确切地,会被多个job共享使用的数据。被共享使用的次数越多,那么缓存该数据的性价比越高。一般来说,对于迭代型和交互型应用非常适合。
- 数据不宜过大。过大会占用大量存储空间,导致内存不足,也会降低数据计算时可使用的空间。虽然缓存数据过大时也可以存放到磁盘中,但磁盘的I/O代价比较高,有时甚至不如重新计算快。
- 非重复缓存的数据。重复缓存的意思是如果缓存了某个RDD,那么该RDD通过OneToOneDependency连接的parent RDD就不需要被缓存了。例如,在图7.2中,我们已经对mappedRDD进行了缓存,就没有必要再对inputRDD进行缓存了,除非有新的job需要使用inputRDD,且该job不使用mappedRDD。
除了RDD可以被缓存,广播数据和task计算结果数据也可以被缓存。另外,面向结构化的数据结构DataSet、DataFrame与RDD一样也可以被缓存。
7.2.2 包含数据缓存操作的逻辑处理流程和物理执行计划
包含数据缓存操作的应用执行流程生成的规则:Spark首先假设应用没有数据缓存,按照规则正常生成逻辑处理流程(RDD之间的数据依赖关系),然后从第2个job开始,将cached RDD之前的RDD都去掉,得到削减后的逻辑处理流程。最后,按照正常规则将逻辑处理流程转化为物理执行计划。
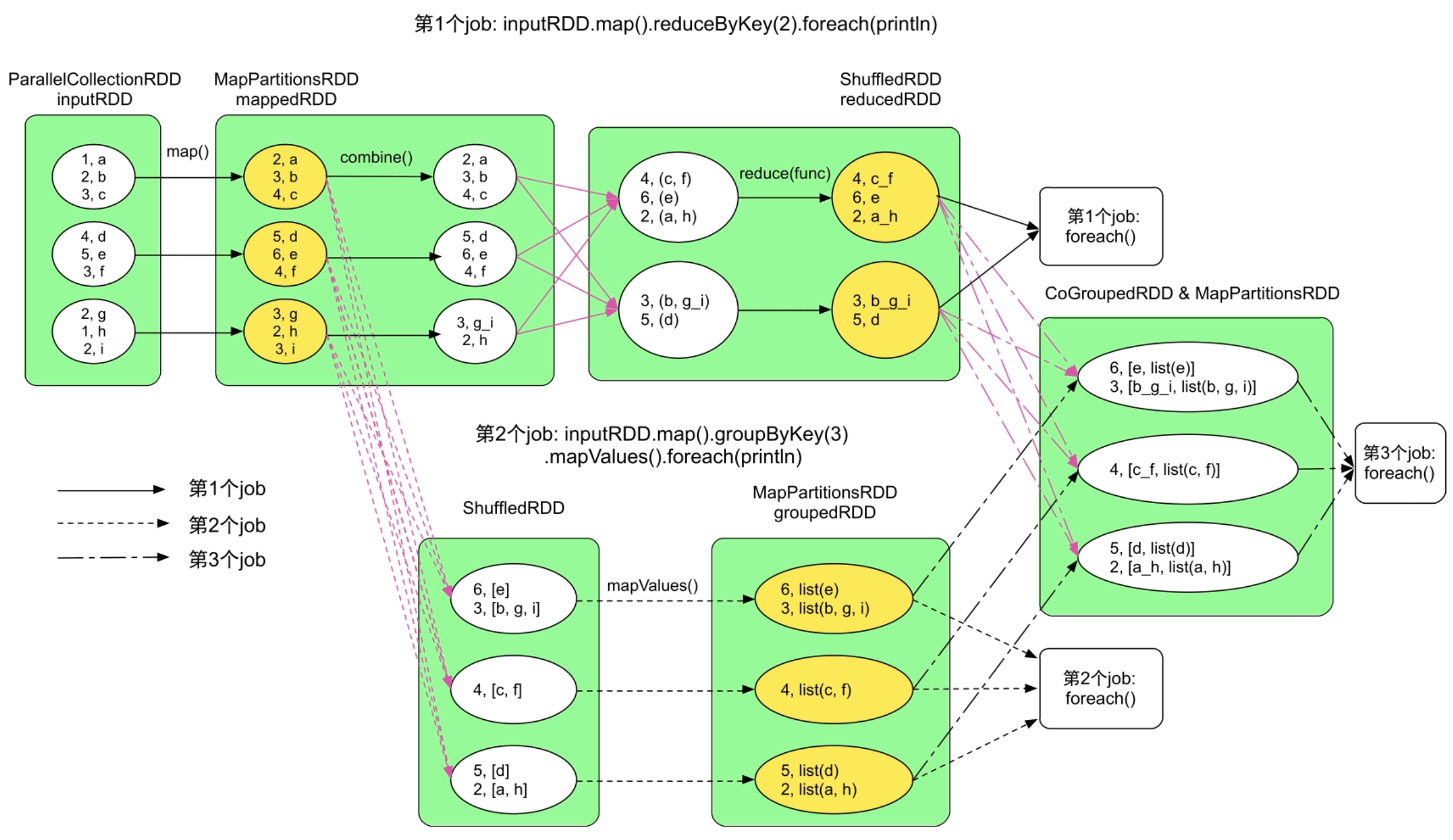
图7.3 包含3个RDD cached()操作的复杂应用生成的3个job,黄色圆圈表示被缓存的分区
如果我们查看job的Web UI界面,则也会发现生成了3个job,如图7.4所示。但这3个job一共生成了8个stage,如图7.5所示,其中还有2个stage被忽略了(skipped)

图7.4 复杂应用生成的3个job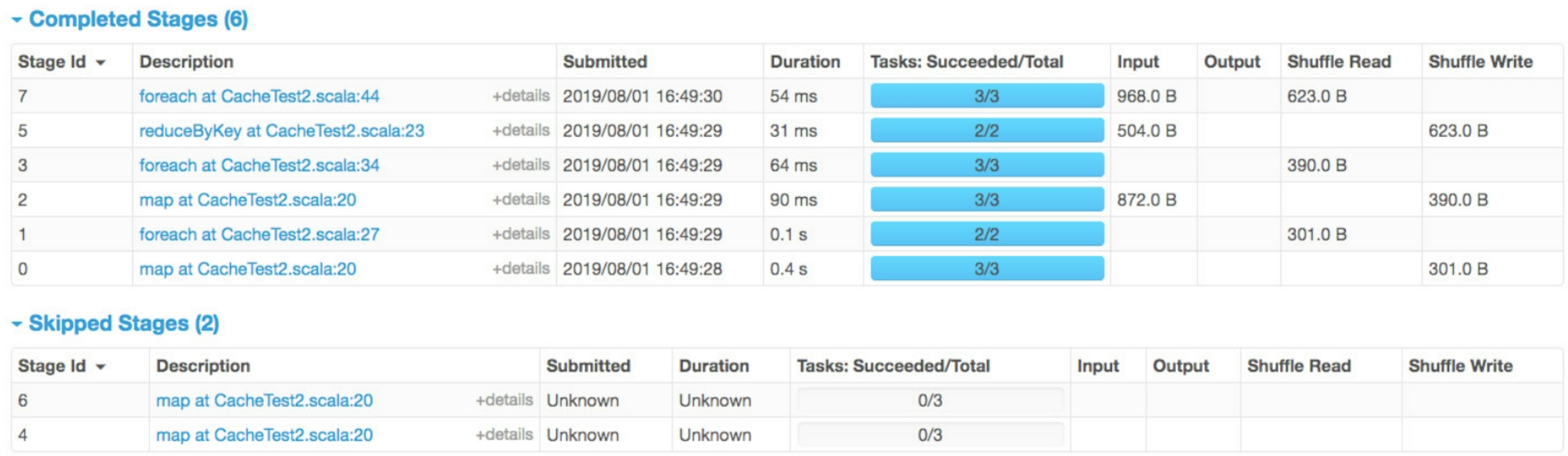
图7.5 复杂应用生成的8个stage
按照本节给出的生成规则,在没有cache()操作的情况下,确实会生成8个stage,如图7.6所示。cache()使得一些stage可以不必实际运行,我们通过删除线来删除不需要运行的stage及不需要计算的RDD,这样可以得到6个实际被运行的stage。

图7.6 复杂应用生成的8个stage
7.2.3 缓存级别
Spark从3个方面考虑了缓存级别(Storage_Level):
- 存储位置。可以将数据缓存到内存和磁盘中,内存空间小但读写速度快,磁盘空间大但读写速度慢。
- 是否序列化存储。如果对数据(record以Java objects形式)进行序列化,则可以减少存储空间,方便网络传输,但是在计算时需要对数据进行反序列化,会增加计算时延。
- 是否将缓存数据进行备份。将缓存数据复制多份并分配到多个节点,可以应对节点失效带来的缓存数据丢失问题,但需要更多的存储空间。
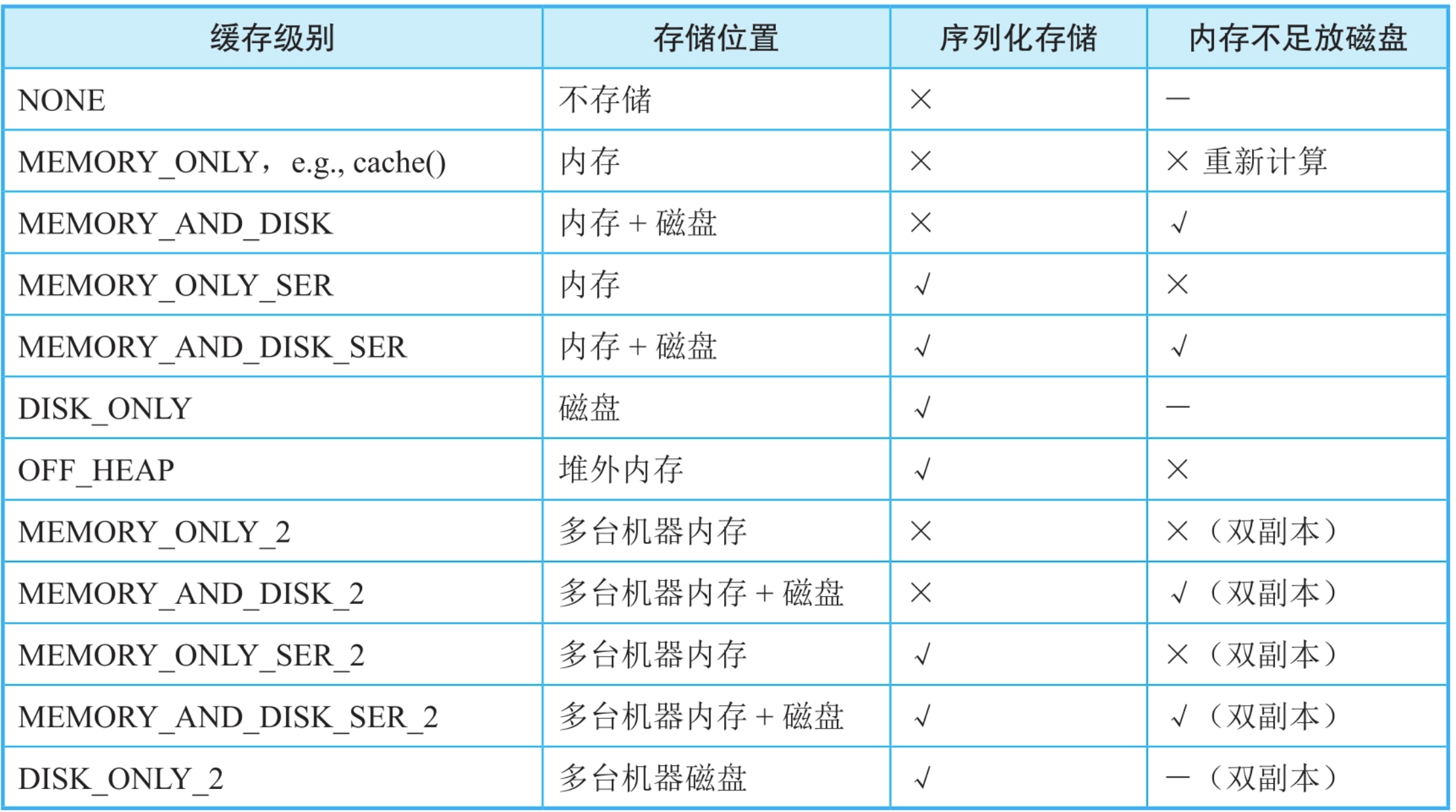
图7.7 Spark中的数据缓存级别
_
缓存级别针对的是RDD中的全部分区,即对RDD中每个分区中的数据(record)都进行缓存。对于MEMORY_ONLY级别来说,只使用内存进行缓存,如果某个分区在内存中存放不下,就不对该分区进行缓存。当后续job中的task计算需要这个分区中的数据时,需要重新计算得到该分区。
例如,在图7.8中,如果mappedRDD中的第1个分区没有被缓存,那么需要先执行task0,算出mappedRDD第1个分区中的数据,然后才能执行task1、task2、task3。
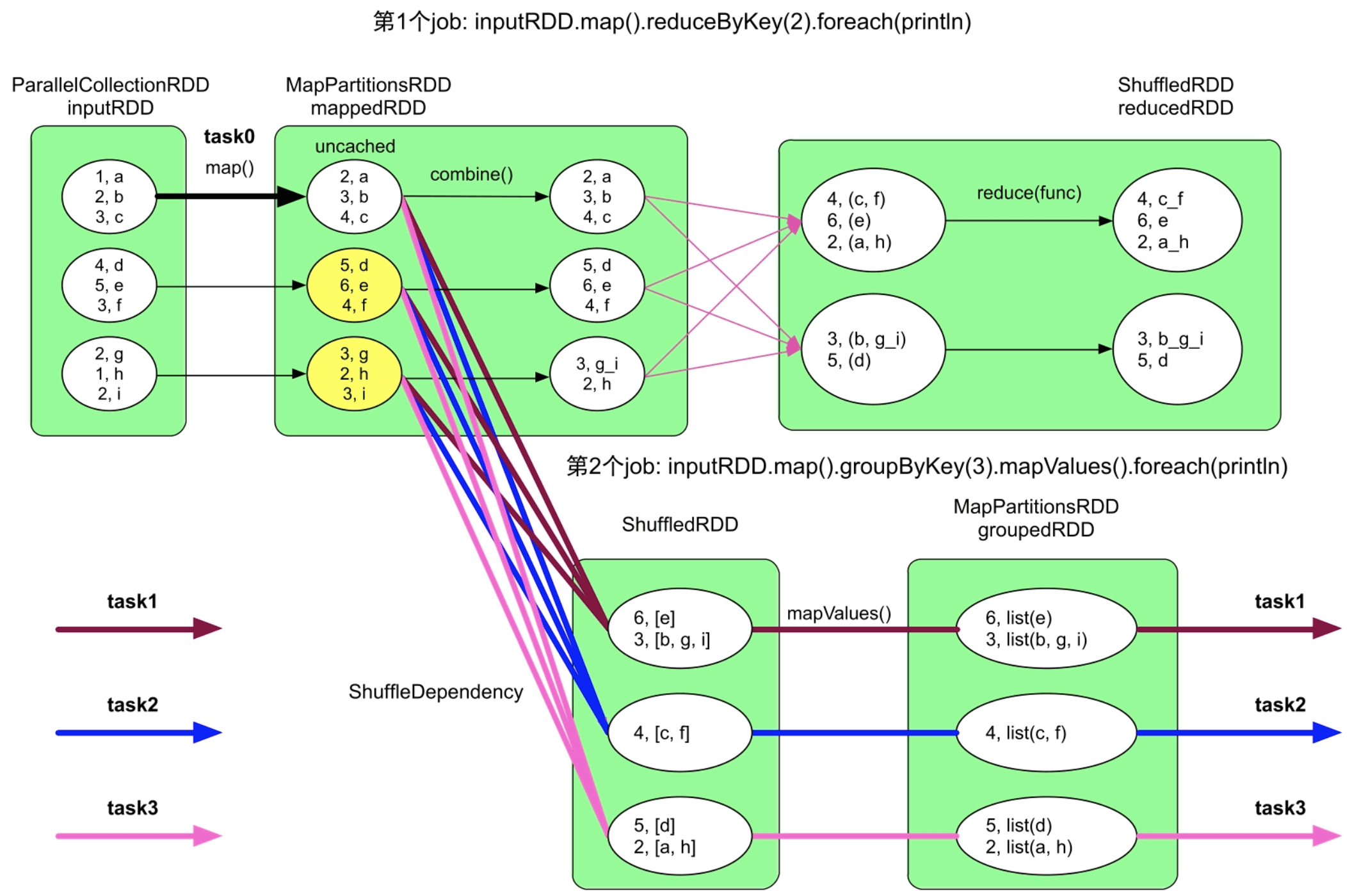
图7.8 对mappedRDD进行部分缓存后生成的计算任务
对于MEMORY_AND_DISK缓存级别,如果内存不足时,则会将部分数据存放到磁盘上。而DISK_ONLY级别只使用磁盘进行缓存。MEMORY_ONLY_SER和MEMORY_AND_DISK_SER将数据按照序列化方式存储,以减少存储空间,但需要序列化/反序列化,会增加计算延时。因为存储到磁盘前需要对数据进行序列化,所以DISK_ONLY级别也需要序列化存储。
目前,Spark需要用户在缓存数据时自己选择缓存级别。不同应用的缓存级别需求不同,用户选择时需要考虑两个问题:
- 是否有足够内存、磁盘空间进行缓存?没有足够的内存、磁盘空间但又需要进行数据缓存,可以选择MEMORY_AND_DISK或者MEMORY_AND_DISK_SER级别缓存数据。
- 如果数据缓存到磁盘上,那么读取数据的时间是否大于重新计算出该数据的时间?如果是,则可以选择不缓存或者分配更大的内存来进行缓存。
7.2.4 缓存数据的写入方法
缓存操作是lazy操作,只有等到action()操作触发job运行时才实际执行缓存操作。
rdd.cache()只是对RDD进行缓存标记的,不是立即执行的,实际在action()操作的job计算过程中进行缓存。当需要缓存的RDD中的record被计算出来时,及时进行缓存,再进行下一步操作。
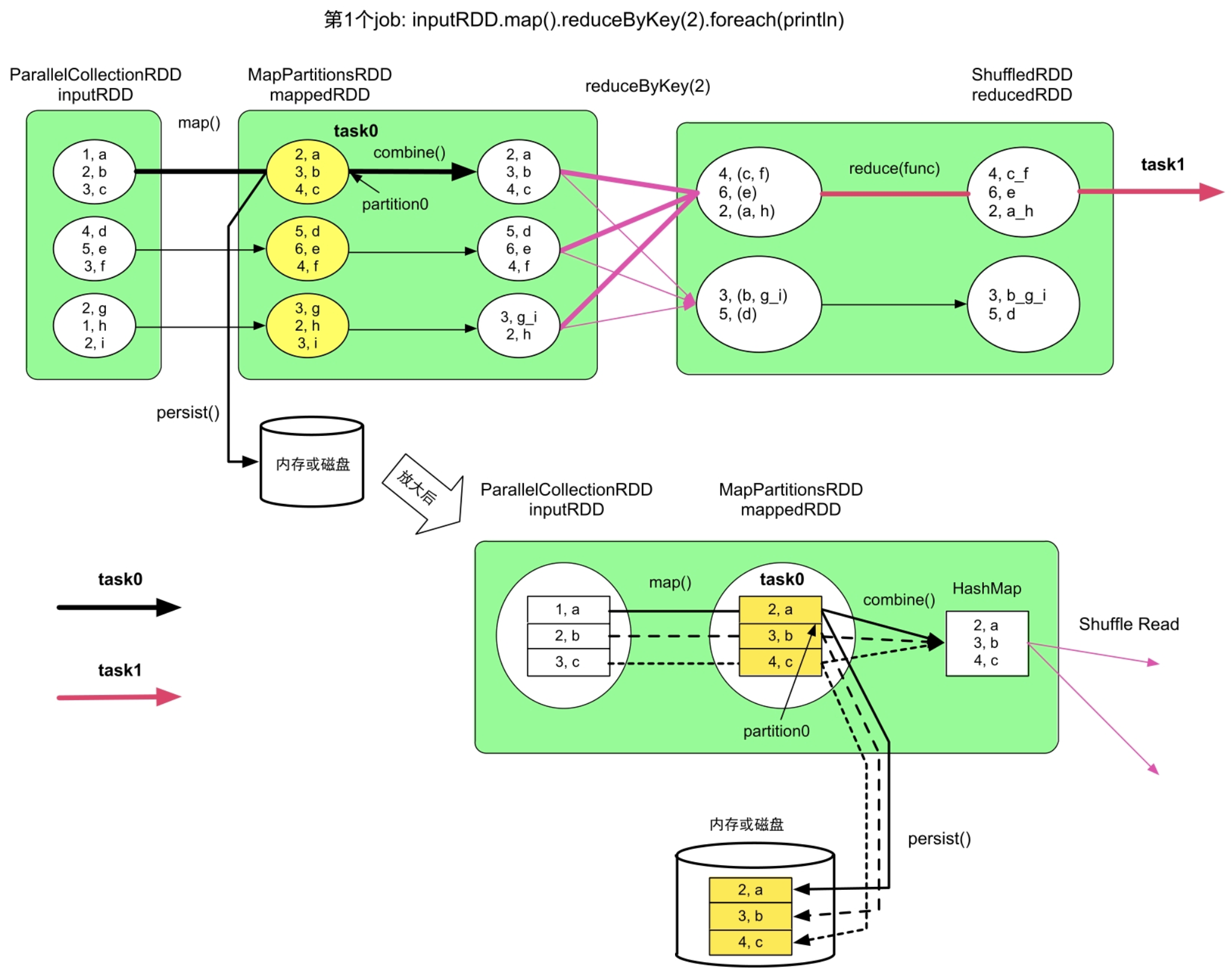
图7.9 数据缓存与下一步操作的计算顺序问题(先执行缓存再执行下一步操作)
_
缓存数据写入的实现细节:在实现中,Spark在每个Executor进程中分配一个区域,以进行数据缓存,该区域由BlockManager来管理。
在图7.10中,task0和task1运行在同一个Executor进程中。对于task0,当计算出mappedRDD中的partition0后,将partition0存放到BlockManager中的memoryStore内。memoryStore包含了一个LinkedHashMap,用来存储RDD的分区。该LinkedHashMap中的Key是blockId,即rddId+partitionId,如rdd_1_1,Value是分区中的数据,LinkedHashMap基于双向链表实现。在图7.10,task0和task1都将各自需要缓存的分区存放到了LinkedHashMap中。
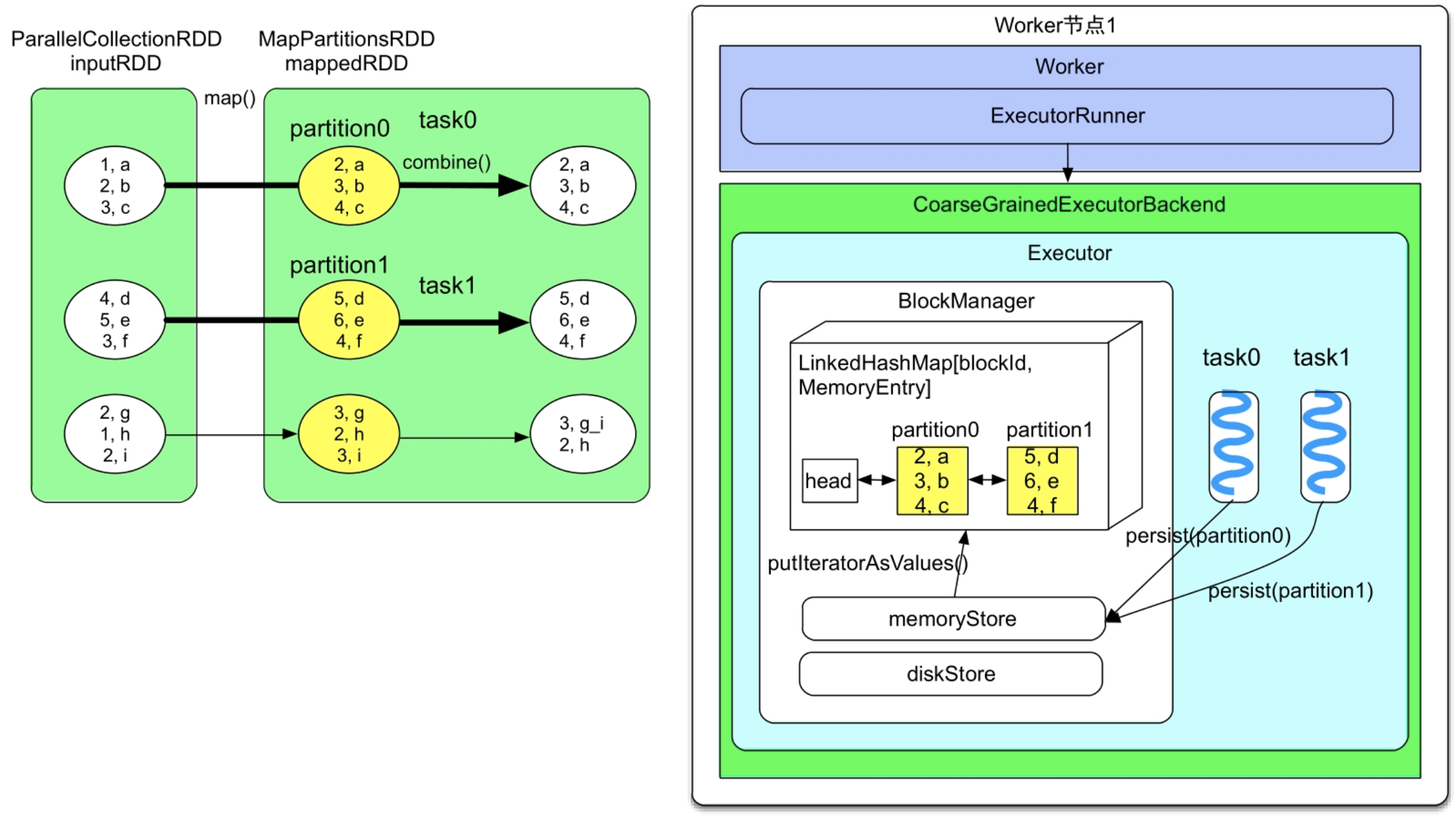
图7.10 在task0和task1运行过程中对partition0和partition1进行缓存
_
7.2.5 缓存数据的读取方法
首先,Spark如何判断一个job是否需要读取缓存数据?当某个RDD被缓存后,该RDD的分区成为CachedPartitions。
比如,在一个例子中当mappedRDD:MapPartitionsRDD被缓存后,mappedRDD的3个分区成为CachedPartitions。我们可以使用reducedRDD.toDebugString()来查看mappedRDD的3个CachedPartitions的存储位置及占用的空间大小。如下所示,mappedRDD被缓存到了内存中,占用872.0B的内存空间。


绍过RDD的分区被缓存到BlockManager的memoryStore(也就是Linked HashMap)中,假设mappedRDD的partition0和partition1被Worker节点1中的BlockManager缓存,而partition2被Worker节点2中的BlockManager缓存,那么当第2个job需要读取mappedRDD中的分区时,首先去本地的BlockManager中查找该分区是否被缓存。在图7.11中,第2个job的3个task都被分到了Worker节点1上,其中task3和task4对应的CachedPartition在本地,因此直接通过Worker节点1的memoryStore读取即可。而task5对应的CachedPartition在Worker节点2上,需要通过远程访问,也就是通过getRemote()读取。远程访问需要对数据进行序列化和反序列化,远程读取时是一条条record读取,并得到及时处理的。
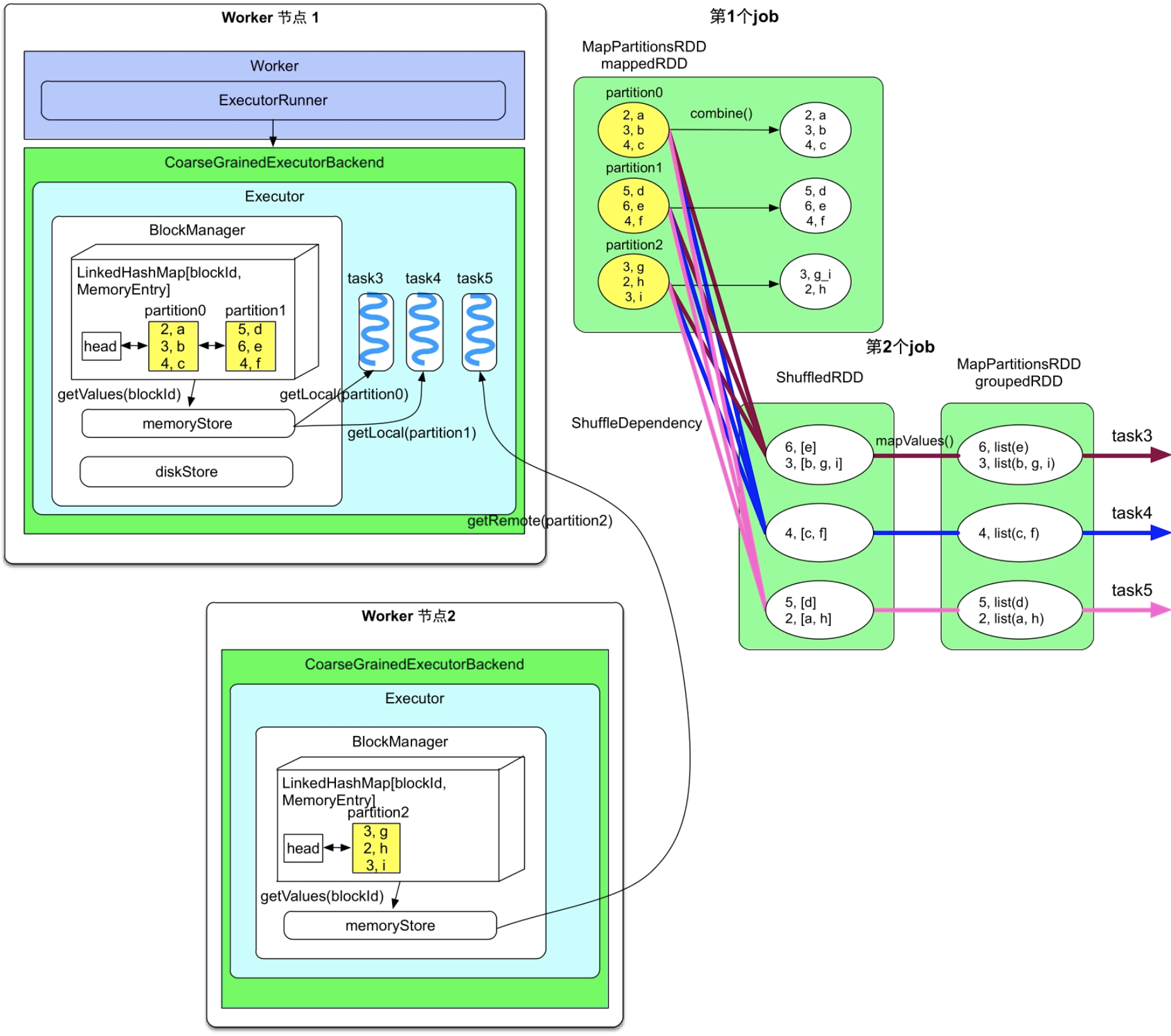
图7.11 Spark task读取本地和远程缓存数据的过程
_
7.2.6 用户接口的设计
Spark提供了一个通用的缓存操作rdd.persist(Storage_Level),可以使用不同类型的缓存级别,如mappedRDD.persist(MEMORY_AND_DISK)。对于cache(),实际上等同于persist(MEMORY_ONLY)。那么,当用户想回收缓存数据时怎么办呢?Spark也提供了一个unpersisit()操作来回收缓存数据,如mappedRDD.unpersist()。
需要注意的是,不管persist()还是unpersist()都只能针对用户可见的RDD进行操作。如图7.12所示,在intersection()操作中,用户在程序中可见的是蓝色部分的RDD,即rdd1、rdd2和rdd3,在执行过程中的MapPartitionsRDD和CoGroupedRDD由Spark自动生成,并不能被用户操作。
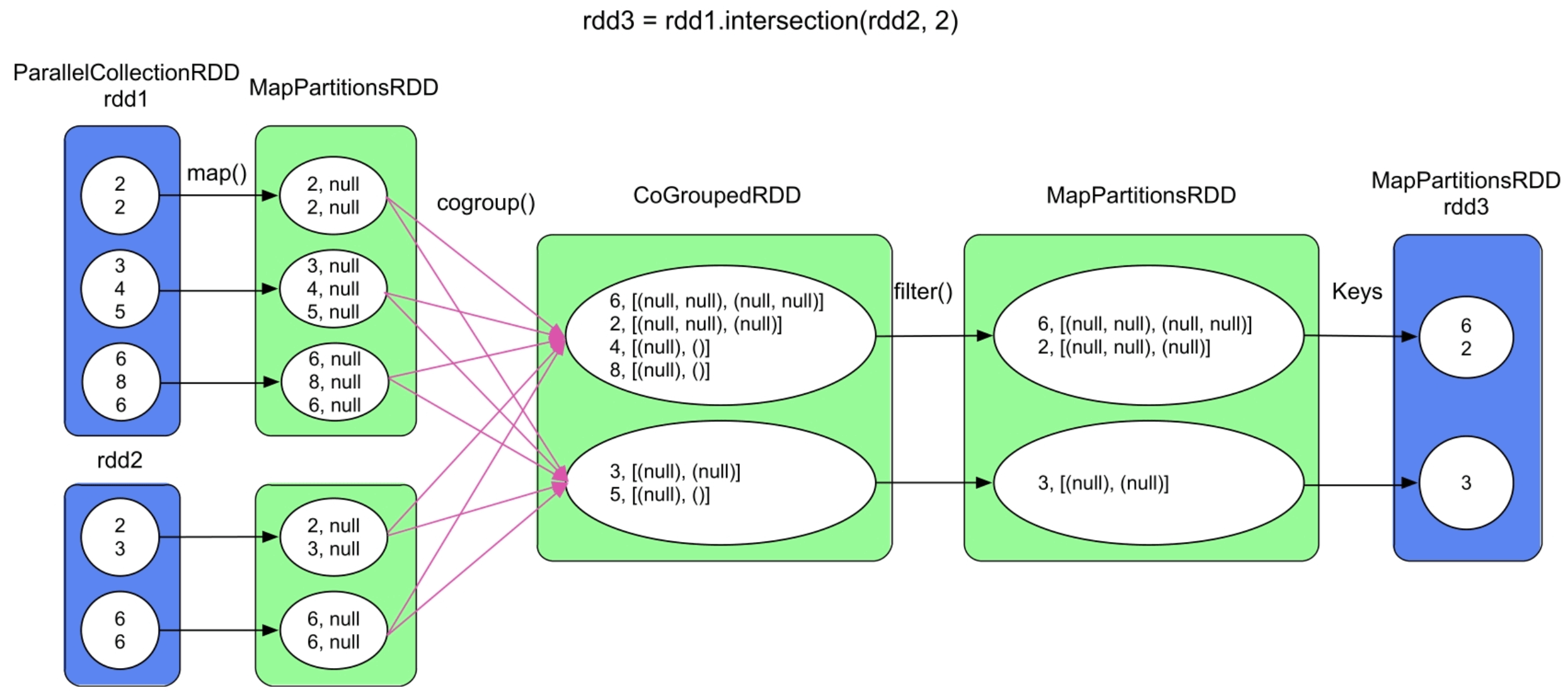
图7.12 intersection()的逻辑处理流程示例
7.2.7 缓存数据的替换与回收方法
如图7.13所示,我们缓存了3个RDD,mappedRDD、reducedRDD和groupedRDD。实际上,当对reducedRDD和groupedRDD完成缓存后,可以回收mappedRDD,因为第3个job只需要使用reducedRDD和groupedRDD。另外,在内存不足时,我们可以进行缓存替换。例如,当需要缓存reducedRDD而内存空间不足时,可以及时将mappedRDD进行替换,以腾出空间存储reducedRDD。因此,在内存空间有限的情况下,Spark需要缓存替换与回收机制。
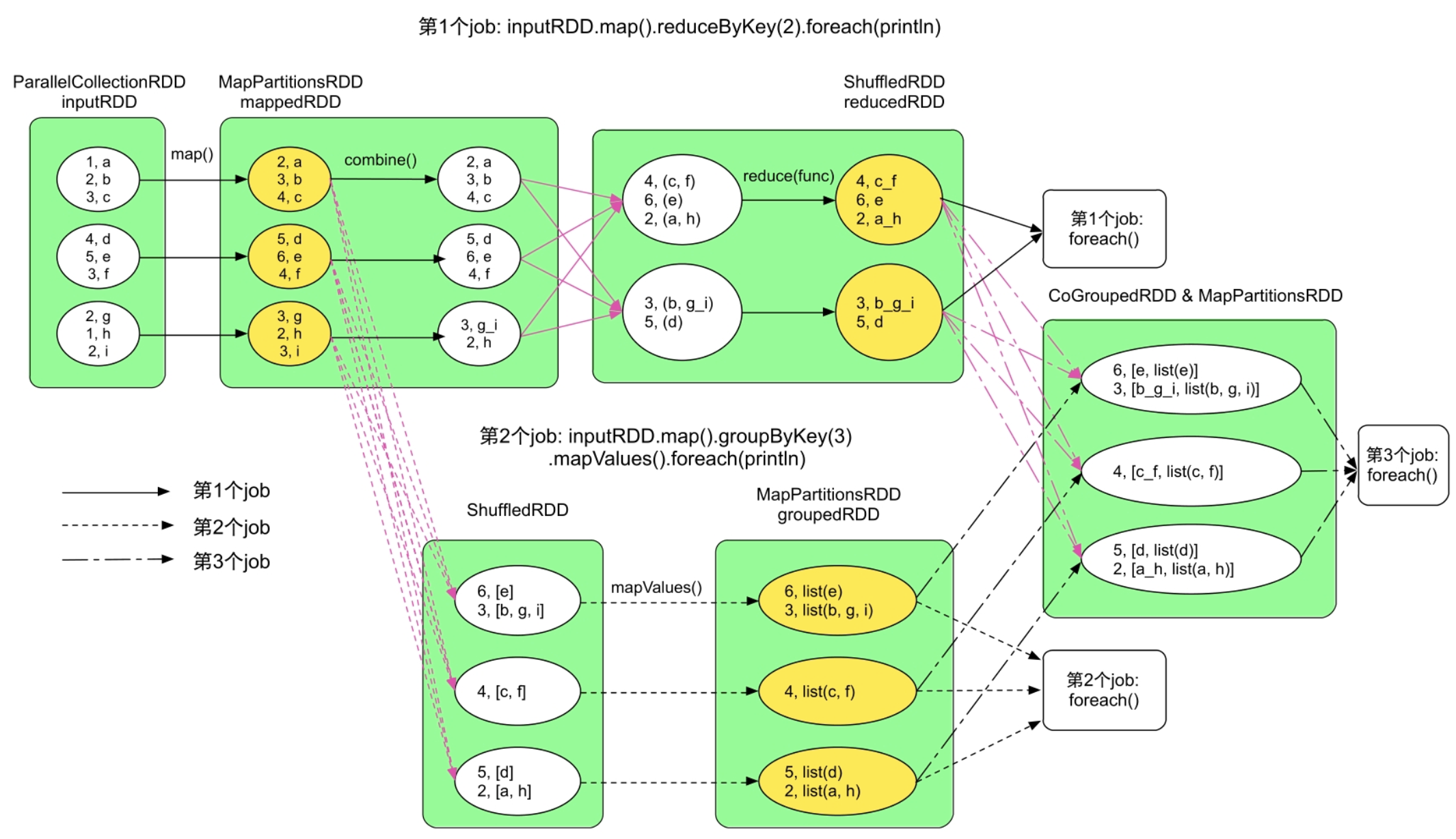
图7.13__ 包含3个RDD cached()操作的复杂应用生成的3个job,黄色圆圈表示被缓存的分区
研究人员针对缓存管理问题开发了多种缓存替换算法,如先入先出(FIFO,First Input First Output)替换算法、最近最久未使用(LRU,Least Recently Used)替换算法、最近最常被使用(MRU,Most Recently Used)替换算法等。
自动缓存替换
缓存替换指的是当需要缓存的RDD大于当前可利用的空间时,使用新的RDD替换旧的RDD(可能有多个)。
(1)选择哪些RDD进行替换?
直观上来讲,如果旧的RDD会被再次利用,那么不应该被替换。然而,当前Spark采用动态生成job的方式,即在执行到一个action()操作时才会生成一个job,仅当遇到下一个action()时再生成下一个job。在执行过程中,Spark只知道cached RDD是否会被当前job用到,而不能预知cached RDD是否会被后续的job用到,因此,Spark决定一个cached RDD是否要被替换的权衡之计是根据该cached RDD的访问历史来判断。目前Spark采用LRU替换算法,即优先替换掉当前最长时间没有被使用过的RDD。这种方式有可能替换掉后续还会被使用的RDD。
(2)需要替换多少个旧的RDD,才开始存储新的RDD?
前面章节讨论过,如果需要缓存某个RDD,那么Spark会在计算该RDD过程中对其进行缓存,而且是每计算一个record就进行存储,因此,在缓存结束前,Spark不能预知该RDD需要的存储空间,也就无法判断需要替换多少个旧的RDD。为了解决这个问题,Spark采用动态替换策略,在当前可用内存空间不足时,每次通过LRU替换一个或多个RDD(具体数目与一个动态的阈值相关),然后开始存储新的RDD,如果中途存放不下,就暂停,继续使用LRU替换一个或多个RDD,依此类推,直到存放完新的RDD。当然,如果替换掉所有旧的RDD都存不下新的RDD,那么需要分两种情况处理:如果新的RDD的存储级别里包含磁盘,那么可以将新的RDD存放到磁盘中;如果新的RDD的存储级别只是内存,那么就不存储该RDD了。
Spark LRU算法的实现及讨论
LRU替换策略的确切含义是优先替换掉当前最久未被使用的RDD。
实际上,Spark直接利用了之前介绍的LinkedHashMap自带的LRU功能实现了缓存替换。LinkedHashMap使用双向链表实现,每当Spark插入或读取其中的RDD分区数据时,LinkedHashMap自动调整链表结构,将最近插入或者最近被读取的分区数据放在表头,这样链表尾部的分区数据就是最近最久未被访问的分区数据,替换时直接将链表尾部的分区数据删除。因此,LinkedHashMap本身就形成了一个LRU cache。LinkedHashMap中的Key存放blockId,如blockId=rdd_0_1表示rdd0的第2个分区。Spark目前采用LRU替换策略,但同时也在开发新的策略。
用户主动回收缓存数据
上面我们提到Spark难以获取cached RDD的生命周期,也就难以精确、智能地进行缓存替换。Spark为了弥补这个缺点,允许用户自己设置进行回收的RDD和回收的时间。方法是使用unpersist(),不同于persist()的延时生效,unpersist()操作是立即生效的。用户还可以设定unpersist()是同步阻塞的还是异步执行的,如unpersist(blocking=true)表示同步阻塞,即程序需要等待unpersist()结束后再进行下一步操作,这也是Spark的默认设定。而unpersist(blocking=false)表示异步执行,即边执行unpersist()边进行下一步操作。
由于unpersit()和persist()执行方式的区别,导致如果unpersist()语句设置的位置不当,则会造成与用户预期效果不一致的结果。

(1)将mappedRDD.unpersist()直接放在reducedRDD之后、foreach之前:导致的结果是不会对mappedRDD进行缓存。由于在action()之前既执行了cache()又执行了unpersist(),所以删除了Spark刚设置的mappedRDD缓存,意味着不对mappedRDD进行缓存。
(2)将mappedRDD.unpersist()放在groupedRDD之后、foreach之前:该情况可以正常对mappedRDD进行缓存,但第2个job无法读到缓存数据。由于在第1个job中,即reducedRDD.foreach()运行前设置了mappedRDD.cache(),所以mappedRDD被正常缓存。然而,由于在第2个job中,即groupedRDD.foreach()运行前设置了mappedRDD.unpersist(),该操作立即回收了mappedRDD,因此在第2个job执行时不能读取到cached mappedRDD数据,需要重新计算mappedRDD,也没有绿色点出现。
(3)mappedRDD.unpersist()被设置在末尾:该情况可以正常缓存和读取数据。由于unpersist()被设置在末尾,第1个job和第2个job正常执行,mappedRDD在第1个job中被缓存,也被第2个job正常读取。因此,如图7.14所示,两个job都以绿色点出现。两个job都结束后,mappedRDD被回收。此时如果还有下一个job且下一个job没有直接或间接使用mappedRDD,那么当前mappedRDD.unpersist()设置的位置是合理的。
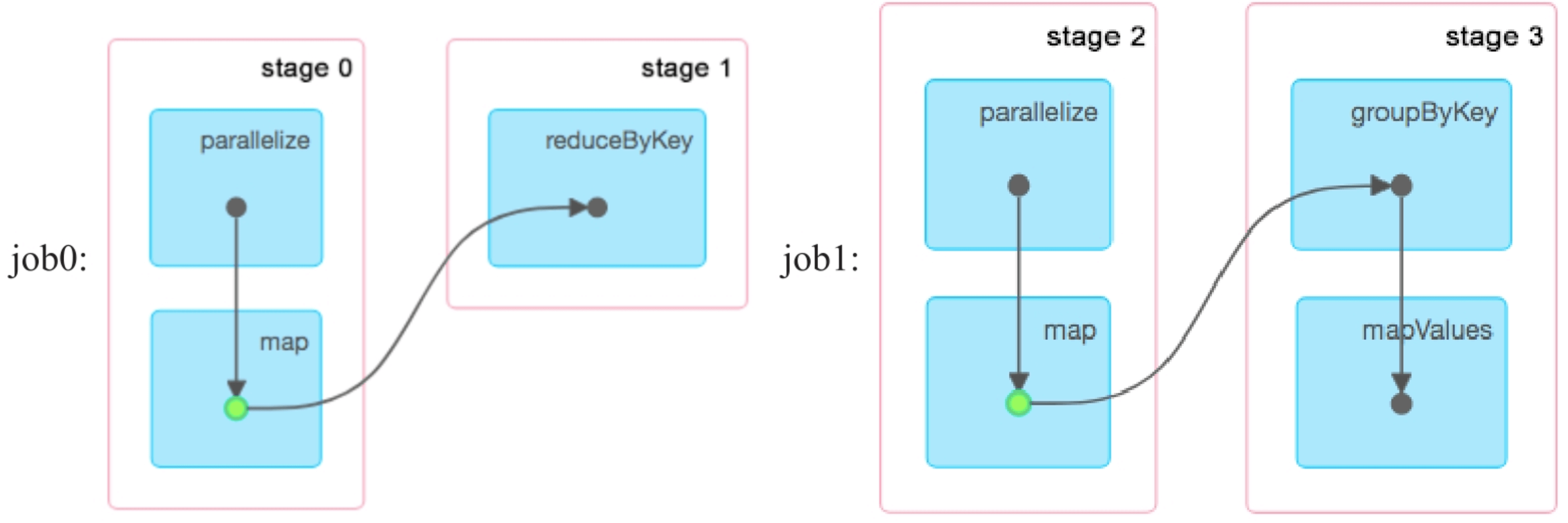
图7.14 unpersist()被设置在末尾,两个job都可以正常缓存和读取数据,绿点表示缓存
_
7.3 与Hadoop MapReduce的缓存机制进行对比
Hadoop MapReduce虽然设计了一个DistributedCache缓存机制,但不是用于存放job运行的中间结果的,而是用于缓存job运行所需的文件的,如所需的jar文件、每个map task需要读取的辅助文件(如一部词典)、一些文本文件等。而且DistributedCache将缓存文件存放在每个worker的本地磁盘上,并不是内存中。Spark job一般包含多个操作,按照DAG图方式执行,也适用于迭代型应用,因此会产生大量中间数据和可复用的数据。Spark为这些数据设计了基于内存和磁盘的缓存机制,可以更好地加速应用执行。
当前Spark的缓存机制也不是完美的,还存在很多缺陷。例如,缓存的RDD数据是只读的,不能修改;当前的缓存机制不能根据RDD的生命周期进行自动缓存替换等。
当前的缓存机制只能用在每个Spark应用内部,即缓存数据只能在job之间共享,应用之间不能共享缓存数据。例如,当一个用户提交的WordCount1应用计算出了RDD后,即使对其进行缓存,也不能用于该用户的另一个WordCount2应用。为了解决应用间缓存数据共享问题,Spark研究者又开发了分布式内存文件系统Alluxio。
总结:Spark独特的缓存机制,如果用户设置某个RDD需要被缓存,那么Spark会在计算得到这个RDD时,及时将其存放到内存或者磁盘上,同时进行下一步操作。缓存数据可以被后续job读取,从而节省计算时间。当有多个RDD需要缓存且内存不足时,可能会引发缓存替换与回收问题,Spark设计了相应的自动替换机制,同时也为用户开放了缓存回收接口,允许用户自己回收数据。本章的知识点将有助于开发效率更高的Spark应用,也有助于研究人员进一步优化缓存机制。

若有收获,就点个赞吧
0 人点赞
